
DCC Terminology Service—An Automated CI/CD Pipeline for Converting Clinical and Biomedical Terminologies in Graph Format for the Swiss Personalized Health Network

Abstract
:1. Introduction
2. Materials and Methods
2.1. Design
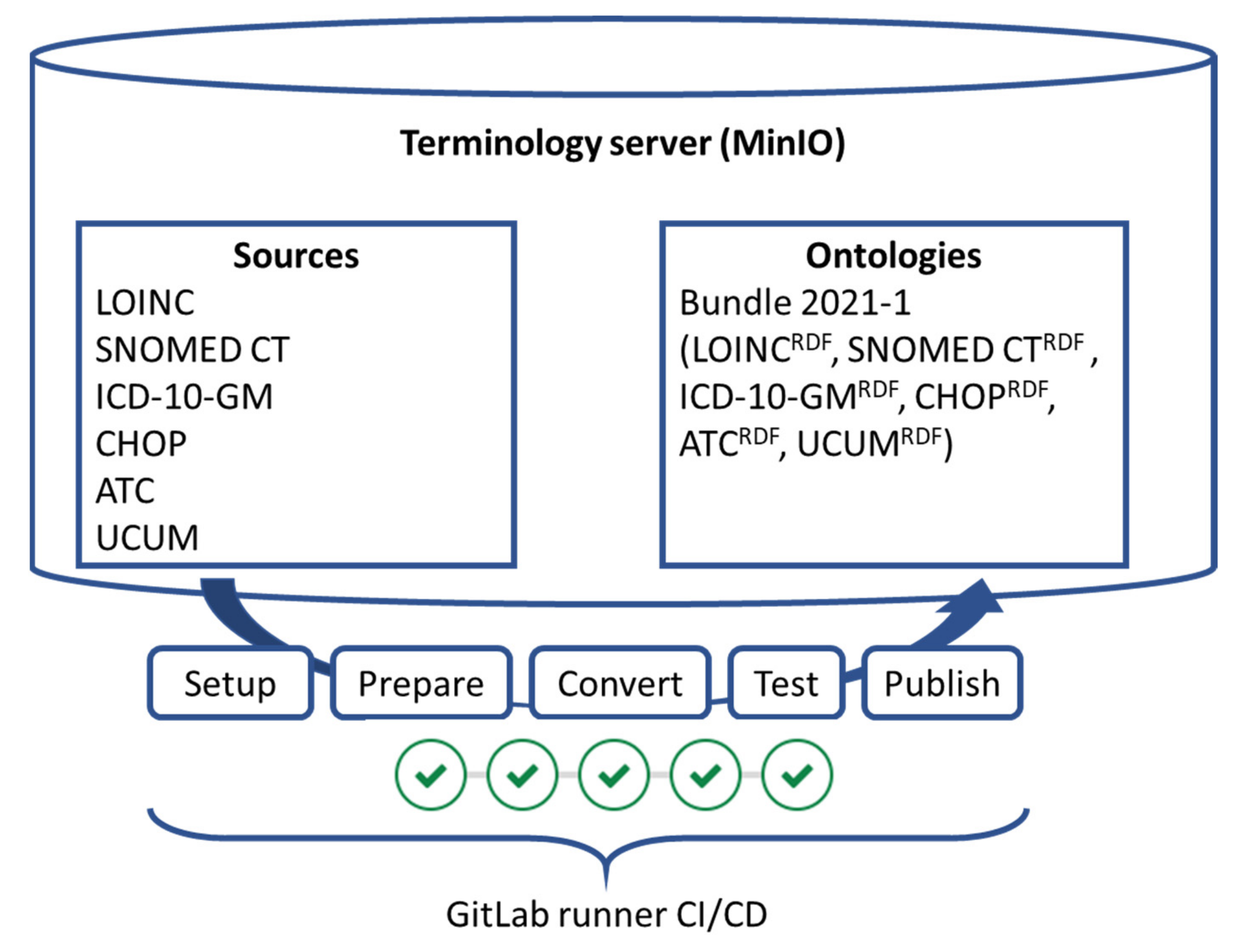
2.2. Implementation
2.2.1. Data Collection
2.2.2. Conversion Scripts
2.2.3. Test
2.2.4. Bundling
2.2.5. GitLab Runner Pipeline
- Setup: The pipeline run is initialized and some local temporary exchanges are created.
- Prepare: The files are loaded from the sources/current folder on the virtual machine (VM) where the GitLab runner is executed.
- Convert: The provided terminology is converted with the corresponding conversion script. Each terminology has its own job that is only executed in case there is valid input data for the job.
- Test: Technical and semantic tests are run. All tests are run in a single job.
- Publish: A single zip file is created containing all the newest RDF files of SNOMED CT, LOINC, ATC, ICD-10-GM, UCUM and CHOP. This bundle is signed and copied to the MinIO server in the ontologies/current folder. The previous bundle is moved to the ontologies/archive folder. If all steps are successful, the source files are moved from sources/current to sources/archive.
2.2.6. Containerized Execution
- GitLab Runner: This is the main container that registers to the GitLab CI/CD pipeline. Besides the MinIO service, it is the only prerequisite to be installed on a machine in order for it to be able to execute the pipelines.
- Python: Besides the pipeline for SNOMED CT, all pipelines use Python in their conversion. The Python container gives a simple abstraction of a plain Linux with a basic Python installation. Additional packages that are needed are installed using a requirements.txt file through the Python package manager, pip, in the “install” target of the Makefile of the individual pipeline.
- Ubuntu Linux: For the SNOMED CT conversion, Java is used. As additional tools are needed in the conversion, the generic Ubuntu Linux container is used, and the necessary tools are installed using the “install” target of the Makefile. The generic Ubuntu Linux container is also used for interaction with MinIO using the mc client tool.
- Apache Jena Fuseki: As part of the pipeline, the triplestore Apache Jena Fuseki is used to test the terminologies in RDF. To be able to make use of the scripts locally in a hospital or BioMedIT node, the triplestore is also offered as a docker container. The same docker container is used in the testing step to ensure correctness. For service providers that do not have a local triplestore of choice, this container can be used to deploy a triplestore. Apache Jena Fuseki is open-source software under the Apache 2.0 license.
3. Results
- CHOP (including historical versions since 2016)
- ICD-10-GM (including historical versions since 2014)
- SNOMED CT (including historical versions since 31 January 2021)
- LOINC (including historical versions since v2.69)
- ATC (2021 version)
- UCUM
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Code Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lawrence, A.K.; Selter, L.; Frey, U. SPHN—The Swiss Personalized Health Network Initiative. Stud. Health Technol. Inform. 2020, 270, 1156–1160. [Google Scholar] [CrossRef] [PubMed]
- Österle, S.; Touré, V.; Crameri, K. The SPHN Ecosystem Towards FAIR Data. Preprints 2021. [CrossRef]
- Gaudet-Blavignac, C.; Raisaro, J.L.; Touré, V.; Österle, S.; Crameri, K.; Lovis, C. A national, semantic-driven, three-pillar strategy to enable health data secondary usage interoperability for research within the swiss personalized health network: Methodological study. JMIR Med. Inform. 2021, 9, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. Comment: The FAIR Guiding Principles for Scientific Data Management and Stewardship. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- SNOMED CT. Available online: https://www.snomed.org/ (accessed on 1 October 2021).
- McDonald, C.J.; Huff, S.M.; Suico, J.G.; Hill, G.; Leavelle, D.; Aller, R.; Forrey, A.; Mercer, K.; DeMoor, G.; Hook, J.; et al. LOINC, a universal standard for identifying laboratory observations: A 5-year update. Clin. Chem. 2003, 49, 624–633. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- ICD-10 GM. Available online: https://www.dimdi.de/dynamic/en/classifications/icd/icd-10-gm (accessed on 1 October 2021).
- Bundesamt für Statistik. Medizinisches Kodierungshandbuch. Der Offizielle Leitfaden der Kodierrichtlinien in der Schweiz. 2022. Available online: https://www.bfs.admin.ch/bfs/de/home/statistiken/gesundheit.assetdetail.17304223.html (accessed on 26 November 2021).
- Schweizerische Operationsklassifikation (CHOP). Bundesamt für Statistik, 2021 (BFS). Available online: https://www.bfs.admin.ch/bfs/de/home/statistiken/kataloge-datenbanken/publikationen.assetdetail.14880301.html (accessed on 1 October 2021).
- ATC. Available online: https://www.whocc.no (accessed on 1 October 2021).
- UCUM. Available online: http://unitsofmeasure.org (accessed on 1 October 2021).
- Whetzel, P.L.; Noy, N.F.; Shah, N.H.; Alexander, P.R.; Nyulas, C.; Tudorache, T.; Musen, M. BioPortal: Enhanced functionality via new Web services from the National Center for Biomedical Ontology to access and use ontologies in software applications. Nucleic Acids Res. 2011, 39, 541–545. [Google Scholar] [CrossRef] [PubMed]
- Metke-Jimenez, A.; Steel, J.; Hansen, D.P.; Lawley, M. Ontoserver: A Syndicated Terminology Server. J. Biomed. Semant. 2018, 9, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Ontoserver. Available online: http://ontoserver.csiro.au/ (accessed on 16 October 2021).
- LOINC FHIR Terminology Server. Available online: https://loinc.org/fhir/ (accessed on 17 October 2021).
- Bodenreider, O. The Unified Medical Language System (UMLS): Integrating Biomedical Terminology. Nucleic Acids Res. 2004, 32, D267–D270. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- De Quirós, F.G.B.; Otero, C.; Luna, D. Terminology Services: Standard Terminologies to Control Health Vocabulary. Yearb. Med Inform. 2018, 27, 227–233. [Google Scholar] [CrossRef] [Green Version]
- Coman Schmid, D.; Crameri, K.; Oesterle, S.; Rinn, B.; Sengstag, T.; Stockinger, H. SPHN—The BioMedIT Network: A Secure IT Platform for Research with Sensitive Human Data. Stud. Health Technol. Inform. 2020, 270, 1170–1174. [Google Scholar] [CrossRef] [PubMed]
- WC3 RDF. Available online: https://www.w3.org/RDF/ (accessed on 1 September 2021).
- Shahin, M.; Babar, M.A.; Zhu, L. Continuous Integration, Delivery and Deployment: A Systematic Review on Approaches, Tools, Challenges and Practices. IEEE Access 2017, 5, 3909–3943. [Google Scholar] [CrossRef]
- SNOMED OWL Toolkit. Available online: https://github.com/IHTSDO/snomed-owl-toolkit (accessed on 1 September 2021).
- UCUM list. Available online: https://ucum.org/trac/wiki/adoption/common (accessed on 5 August 2021).
- Apache Jena Fuseki. Available online: https://jena.apache.org/documentation/fuseki2/ (accessed on 3 July 2021).
- SPARQL ASK. Available online: https://www.w3.org/TR/2013/REC-sparql11-query-20130321/#ask (accessed on 26 November 2021).
- Makefiles. Available online: https://www.gnu.org/software/make/manual/make.html (accessed on 29 November 2021).
- Schweizer Spezialitätenliste. Available online: http://www.spezialitätenliste.ch/ (accessed on 29 November 2021).


{kind=link}
{kind=link}
| ID | Description |
|---|---|
| Q0 | Every element must be at least of type rdfs:Class |
| Q1 | Only the listed roots are present in the terminology |
| Q2 | The number of concepts is between x and y |
| Q3 | Every concept must have at least one rdfs:label |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krauss, P.; Touré, V.; Gnodtke, K.; Crameri, K.; Österle, S. DCC Terminology Service—An Automated CI/CD Pipeline for Converting Clinical and Biomedical Terminologies in Graph Format for the Swiss Personalized Health Network. Appl. Sci. 2021, 11, 11311. https://doi.org/10.3390/app112311311
Krauss P, Touré V, Gnodtke K, Crameri K, Österle S. DCC Terminology Service—An Automated CI/CD Pipeline for Converting Clinical and Biomedical Terminologies in Graph Format for the Swiss Personalized Health Network. Applied Sciences. 2021; 11(23):11311. https://doi.org/10.3390/app112311311
Chicago/Turabian StyleKrauss, Philip, Vasundra Touré, Kristin Gnodtke, Katrin Crameri, and Sabine Österle. 2021. "DCC Terminology Service—An Automated CI/CD Pipeline for Converting Clinical and Biomedical Terminologies in Graph Format for the Swiss Personalized Health Network" Applied Sciences 11, no. 23: 11311. https://doi.org/10.3390/app112311311