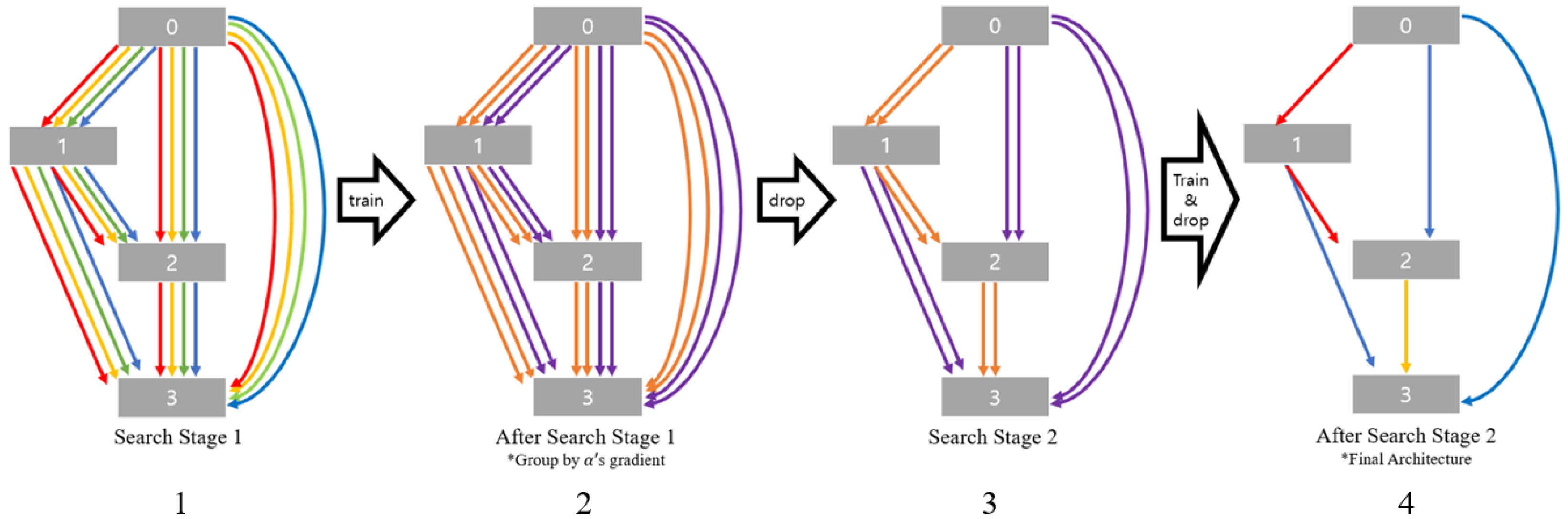
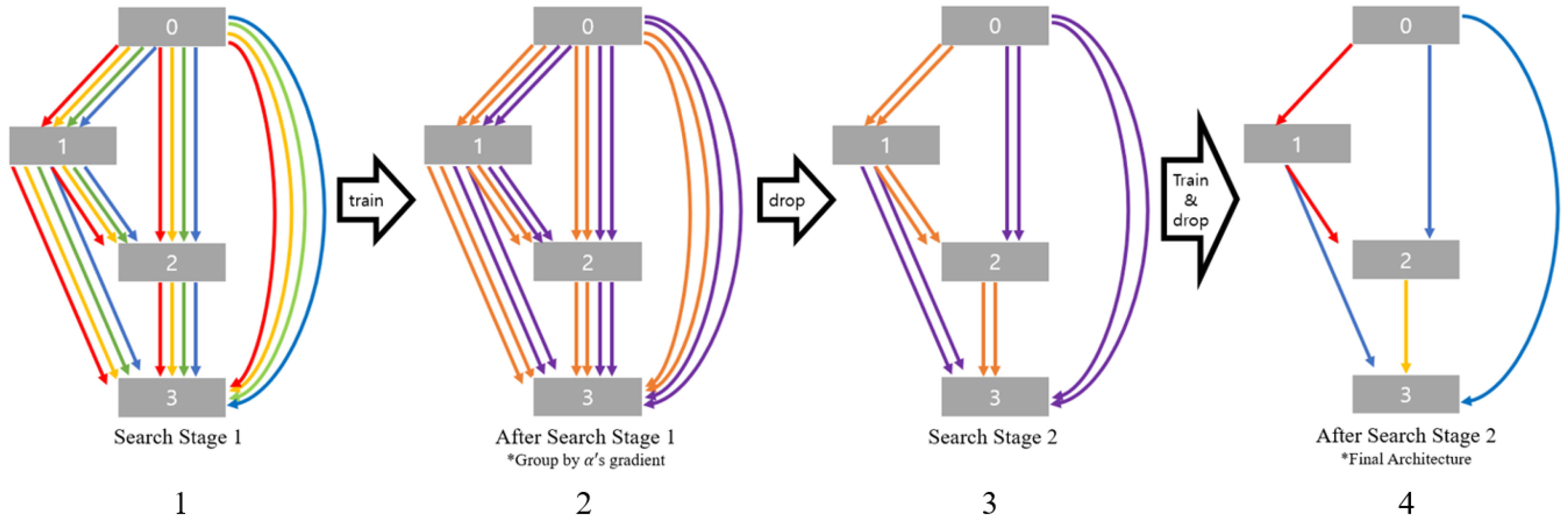
Figure 1 and Algorithm 2 show the process of DG-DART developed in this study. DG-DARTS has parameters and search space that are the same as those of DARTS. Applying Algorithm 2, the top-
k operations with the largest architecture parameter are selected, and then, the final cells are decided. In this study,
k = 1, as shown in
Figure 1. Another view of the DG-DARTS algorithm is shown in
Figure 2. The following are the primary distinctions between Algorithm 1 of DARTS and Algorithm 2 of DG-DARTS:
An example of a vote dispersion problem and its resolution by DG-DARTS can be addressed as follows: We suppose a case in which an edge between nodes 1 and 2 is a convolutional operation that minimizes the loss function. In this case, as the training is processed, the architecture parameter ratio of the convolutional operation is increased by the SoftMax function, as described in Equation (
2), while the remaining operations are decreased.
where
is the node output and
is the architecture parameter.
If there are four types of convolution operations, each of the four operations shares the largest weight; thus, the weight of each operation is eventually lower than those of the other operations. Therefore, other operations, such as skip connections, can be selected as the final operation.
Figure 2.
Another view of the DG-DARTS algorithm.
Such problems are critical once operations in the search space of DARTS [
3] are added or changed. For example, once a good and meaningful operation that was found in another study is added to the existing search space, the newly added operation can have its own shares of weights in the existing search space. If DARTS is applied to a new dataset, a new search space is also composed, then the ratio of the operation group needs to be tuned by analyzing the relations of each operation; otherwise, a vote dispersion problem may occur. To resolve the vote dispersion problem, DG-DARTS was constructed in this study.
3.2.1. Clustering Criteria: Gradient of Architecture Parameter
DG-DART uses a gradient, i.e., a derivative, of the architecture parameter
in order to determine the relationship between operations in the search space, apart from previous works. DG-DARTS repeats the epochs of the training, and
is updated in each epoch.
Figure 3 and
Figure 4 show the gradient of the weight over epochs,. The gradient of
can be used as a hint to determine the relationship between operations because it varies with the training epochs. For example, if one specific edge requires a
filter for the convolution operation,
and
also have higher weights in the search space of DARTS, while the weights of the other operations decrease. Thus, the Elkan K-means cluster [
12] algorithm is introduced to cluster operations based on the criteria of the gradient of the weight. Since each operation has several gradient changes of
with respect to the epochs, operations without
are considered labels, and their gradients are considered data. After clustering, the weight sum for each cluster is used to add clusters with large weights to the search space
for use in the next stage. Once we have a deficient number of operations for the next stage, higher-ranked operations from the second-ranked clusters are also added to the search space. With this new search space
composed, which is a subset of
, stage 2 is processed in the same manner as stage 1.
Here, we present a detailed example.
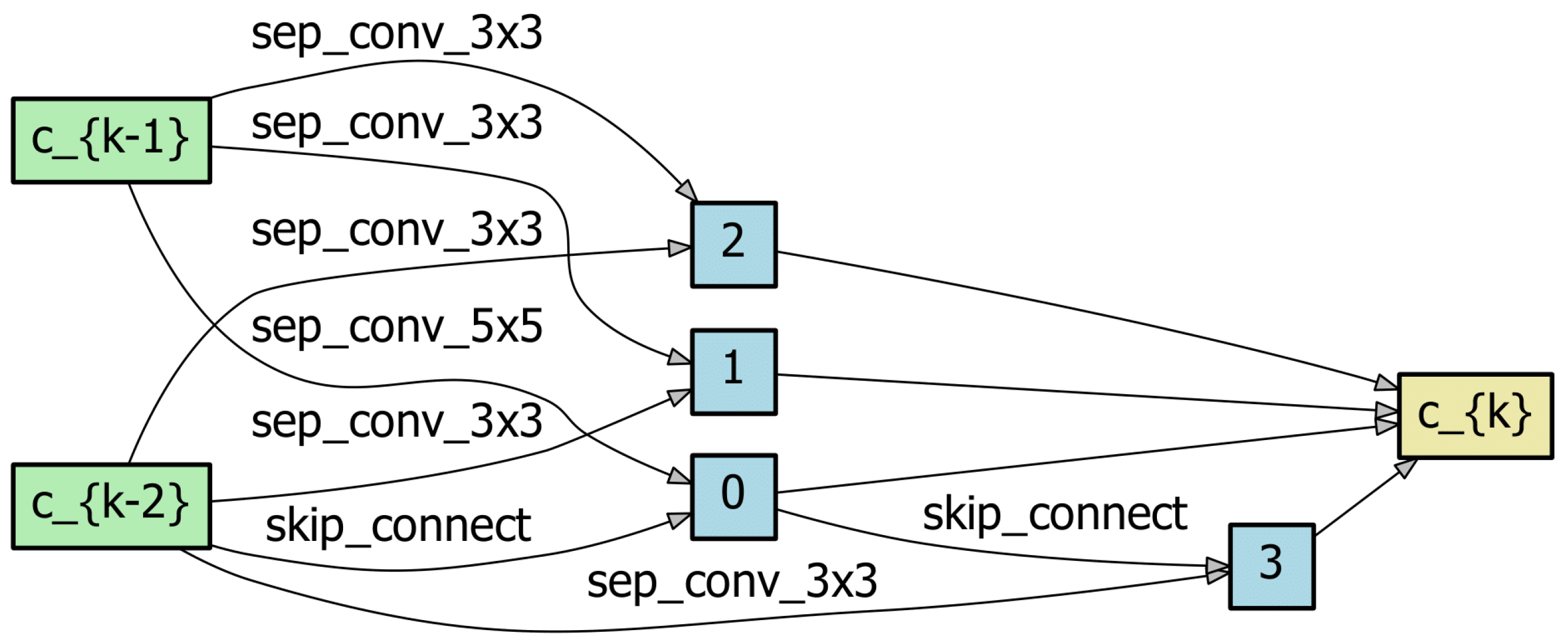
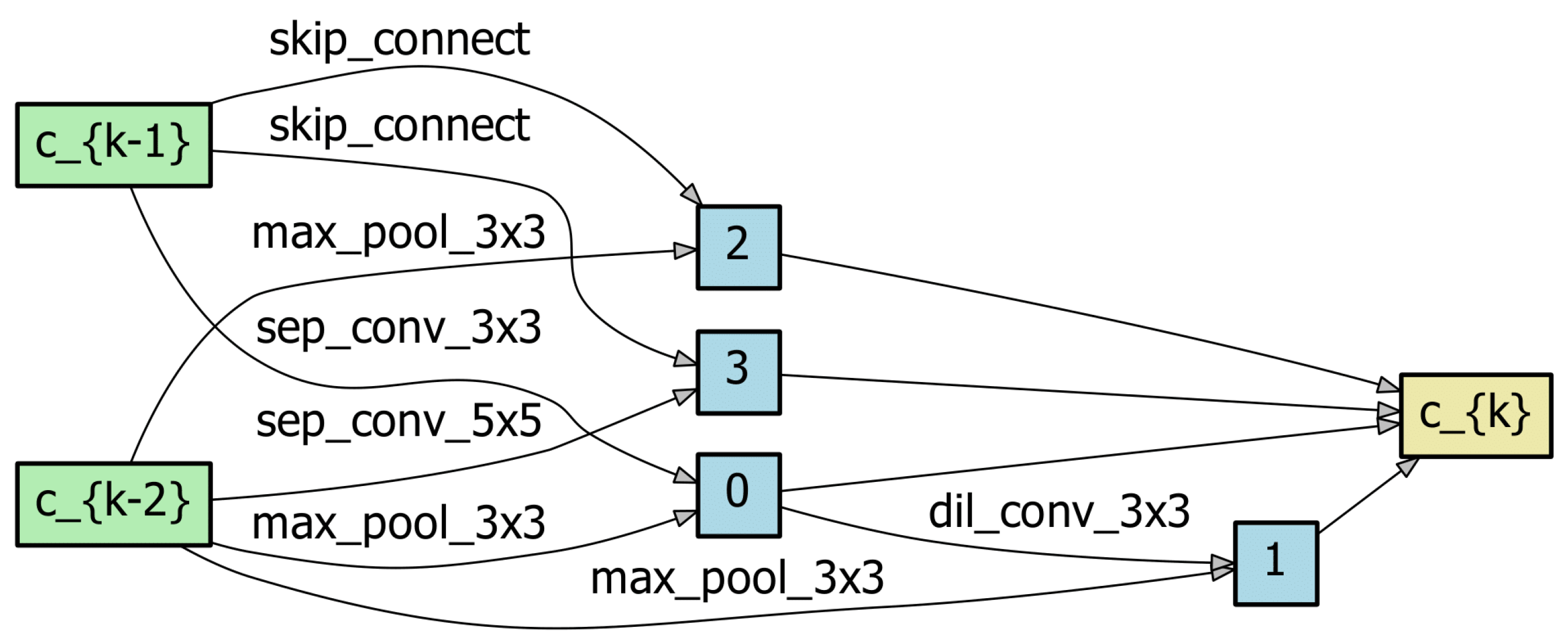
Table 1 shows the detailed weights of the clusters, especially for the seventh mixed operation after stage 1. According to the methods described in
Section 3.2.1, cluster numbers, operation names, architecture parameters, and the sum of the architectures for each cluster are shown. In the case of DARTS,
with 0.1059 is selected, and the architecture search is completed, as
has the largest architecture parameter is excluded by DART’s policy. In the case of DG-DARTS, half of the operations from the search space of stage 1 are selected, and a new search space is generated for stage 2. In other words, according to the policy of DG-DARTS, four operations among eight operations of the search space are selected:
.
Without grouping of the operations,
might be selected with a third-ranked weight; on the contrary, grouping of operations discards
from the search space for stage 2 per the criteria of the sum of clusters. As mentioned in
Section 3.2.1,
is excluded for clustering but is included in the selection process of the new search space.
Figure 5 shows a virtualization of
Figure 3b according to the clusters, along with the PCA results. The operations in the clusters are as follows: Cluster 1:
,
,
; Cluster 2:
,
; Cluster 3:
,
. The PCA results show that similar operations are grouped, which are similar to the K-means results.
Figure 6 depicts a visualization of
Figure 4b according to the clusters, along with the PCA results. The operations in the clusters are as follows: Cluster 1:
,
,
; Cluster 2:
,
,
; Cluster 3:
.
Figure 6 shows that
is an extraordinary operation, as clearly observed in
Figure 6c,d operation
has a lower
but a larger sum of
, such that it includes a new search space per the DG-DARTS policy.
3.2.2. Bebefit: Regularization and Search Cost Decrease
The major advantage of DG-DARTS is twofold. The first is the regularization of a specific operation, and the second is the reduced search cost. The benefits of DG-DARTS are obtained from the two-stage architecture search and operation clustering.
DARTS [
3] shows a negative phenomenon in which the number of skip connections is dramatically increased, known as collapse [
9], as the epochs progress. Empirically, once the number of skip connections is greater than three, the performance of the final architecture decreases significantly [
7,
9]. Recent DARTS-based approaches have focused on solving the weight monopoly problem of the skip connection [
7,
8,
10,
11,
13].
P-DARTS [
7] uses drop-out in units of operation, tries to regulate the skip connection’s amount of training, and the number of skip connections of the final architecture is manually limited to two. Fair-DARTS [
10] uses a sigmoid activation function instead of SoftMax to overcome the unfair competition of the over-selection of skip connection. PC-DARTS [
8] applies regularization weight-free operations, such as skip connection and max-pooling, using edge normalization. DARTS+ [
9] prevents excessive skip connections because the final architecture has two skip connections that produce the best performance. To prevent additional selection of skip connections, DARTS+ limits the number of skip connections or performs an early stop using the architecture parameter; here, DARTS+ used two stages of 25 epochs, which produced an effect similar to the early stopping of DARTS+.
3.2.3. Relationship to Previous Work
Several features of previous studies inspired this study. DG-DARTS has a similar concept to StacNAS [
11] in that similar types of operations are grouped. StacNAS clusters operations with the criteria from the feature map by calculating candidate operations regarding the dataset before the architecture search. From the four clusters, one representative operation was selected, and the
operation was added. Five operations,
,
,
,
, and
, compose the search space for stage 1, and the selected operations are used in stage 2. Several studies have focused on the feature map of the operations to improve the search space, and all of them require pre-calculation to obtain the feature map [
10,
11,
13].
In comparison, DG-DARTS does not require pre-calculation of the feature map; therefore, DG-DARTS requires no additional calculation time. Both the relationships between the positions of the operations and the relationships of the operations inside the cell are considered because clustering in DG-DARTS is performed for all edges, for example, mixed operation. Therefore, the dynamic nature of DG-DARTS can help obtain dynamic and situation-oriented clusters, apart from predefined clustering. For example, mixed operation number 0 is clustered with clustering, whereas mixed operation number 13 can have clusters with and according to the filter size criteria.
Dividing stages to reduce the search space is one of the ideas of P-DARTS [
7]. P-DARTS has three stages, each with 25 epochs, and the number of cells in the search network increases with the number of stages, thus solving the depth-gap problem. In this process, a negative phenomenon can occur where the skip connection is over-selected, eventually leading to the poor performance of the model. To regularize this phenomenon, drop-out is introduced in terms of operations and limits the number of skip connections by two to select the final architecture. DG-DARTS regularizes skip connections by operation clustering, and collapse [
9] can be prevented without additional work.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}