
Predicting Academic Performance Using an Efficient Model Based on Fusion of Classifiers


 and
and
Abstract
:1. Introduction
2. Literature Review
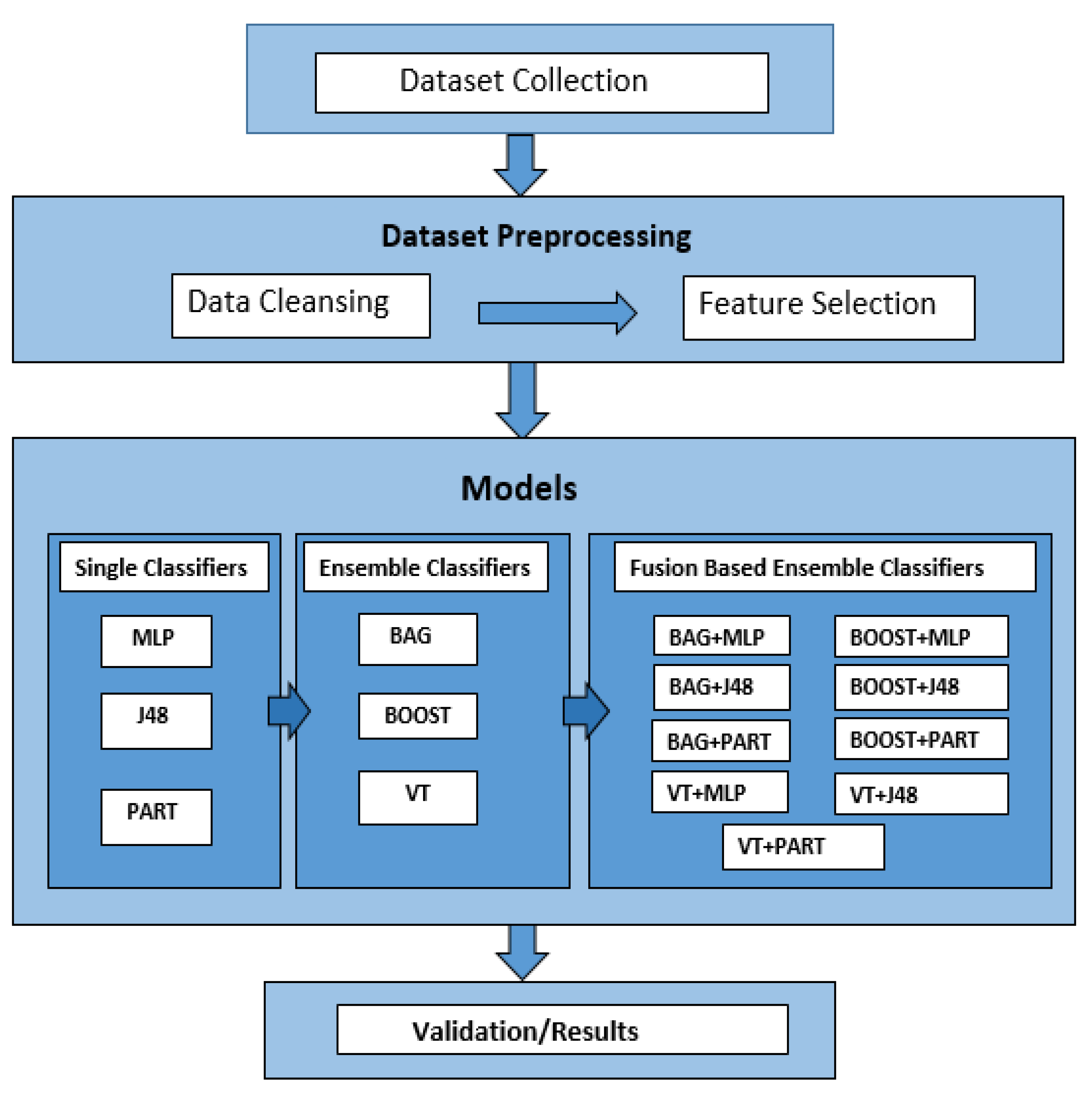
3. Research Methodology
3.1. Phase 1: Classification Using Base Classifier
3.1.1. Multilayer Perceptron Classifier
3.1.2. J48 Classifier
3.1.3. PART Classifier
3.2. Phase 2: Building Model by Ensemble Methods
3.2.1. Bagging
3.2.2. Boosting
3.2.3. Voting
3.3. Phase 3: Building Model by Hybrid Ensemble Methods
3.4. Phase 4: Performance Comparison Analysis
4. Experiments and Evaluation
4.1. Experiments with Base Classifiers and Ensemble Base Classifiers
4.2. Experiments with Fusion Ensemble-Based Models
4.3. Comparative Analysis of Applied Techniques
4.4. Comparison of Applied Approach with Existing Approaches
5. Limitations
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kamran, S.; Nawaz, I.; Aslam, S.; Zaheer, S.; Shaukat, U. Student’s performance in the context of data mining. In Proceedings of the 2016 19th International Multi-Topic Conference (INMIC), Islamabad, Pakistan, 5–6 December 2016; pp. 1–8. [Google Scholar]
- Kamran, S.; Nawaz, I.; Aslam, S.; Zaheer, S.; Shaukat, U. Student’s Performance: A Data Mining Perspective; LAP Lambert Academic Publishing: Koln, Germany, 2017. [Google Scholar]
- Iqbal, M.S.; Luo, B. Prediction of educational institution using predictive analytic techniques. Educ. Inf. Technol. 2018, 24, 1469–1483. [Google Scholar] [CrossRef]
- Kaur, A.; Umesh, N.; Singh, B. Machine Learning Approach to Predict Student Academic Performance. 2018. Available online: www.ijraset.com734 (accessed on 16 July 2021).
- Aslam, M.; Malik, R.; Rawal, S.; Rose, P.; Vignoles, A. Do government schools improve learning for poor students? Evidence from rural Pakistan. Oxf. Rev. Educ. 2019, 45, 802–824. [Google Scholar] [CrossRef] [Green Version]
- Abid, A.; Kallel, I.; Blanco, I.; Benayed, M. Selecting relevant educational attributes for predicting students’ academic performance. In Intelligent Systems Design and Applications, Proceedings of the 17th International Conference on Intelligent Systems Design and Applications (ISDA 2017), Delhi, India, 14–16 December 2017; Springer: Cham, Switzerland, 2018; pp. 650–660. [Google Scholar] [CrossRef]
- Shahrazad, H. Knowledge economy: Characteristics and dimensions. Manag. Dyn. Knowl. Econ. 2017, 5, 203–225. [Google Scholar]
- Baneres, D.; Rodriguez-Gonzalez, M.E.; Serra, M. An Early Feedback Prediction System for Learners At-Risk within a First-Year Higher Education Course. IEEE Trans. Learn. Technol. 2019, 12, 249–263. [Google Scholar] [CrossRef]
- Imran, M.; Latif, S.; Mehmood, D.; Shah, M.S. Student Academic Performance Prediction using Supervised Learning Techniques. Int. J. Emerg. Technol. Learn. 2019, 14, 92–104. [Google Scholar] [CrossRef] [Green Version]
- Phua, E.J.; Batcha, N.K. Comparative analysis of ensemble algorithms’ prediction accuracies in education data mining. J. Crit. Rev. 2020, 7, 37–40. [Google Scholar]
- Abu, A. Educational data mining & students’ performance prediction. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 212–220. [Google Scholar]
- Romero, C.; Ventura, S. Educational Data Mining: A Review of the State of the Art. IEEE Trans. Syst. Man Cybern. Part. C (Appl. Rev.) 2010, 40, 601–618. [Google Scholar] [CrossRef]
- Arun, D.K.; Namratha, V.; Ramyashree, B.V.; Jain, Y.P.; Choudhury, A.R. Student academic performance prediction using educational data mining. In Proceedings of the 2021 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 27–29 January 2021; pp. 1–9. [Google Scholar]
- Alturki, S.; Alturki, N. Using Educational Data Mining to Predict Students’ Academic Performance for Applying Early Interventions. J. Inf. Technol. Educ. Innov. Pract. 2021, 20, 121–137. [Google Scholar] [CrossRef]
- Trautwein, U.; Lüdtke, O.; Marsh, H.W.; Köller, O.; Baumert, J. Tracking, grading, and student motivation: Using group composition and status to predict self-concept and interest in ninth-grade mathematics. J. Educ. Psychol. 2006, 98, 788–806. [Google Scholar] [CrossRef] [Green Version]
- Li, F.; Zhang, Y.; Chen, M.; Gao, K. Which Factors Have the Greatest Impact on Student’s Performance. J. Phys. Conf. Ser. 2019, 1288, 012077. [Google Scholar] [CrossRef]
- Francis, B.K.; Babu, S.S. Predicting Academic Performance of Students Using a Hybrid Data Mining Approach. J. Med. Syst. 2019, 43, 162. [Google Scholar] [CrossRef]
- Md Zubair Rahman, A.M.J. Model of Tuned J48 Classification and Analysis of Performance Prediction in Educational Data Mining. 2018. Available online: http://www.ripublication.com (accessed on 5 July 2021).
- Tomasevic, N.; Gvozdenovic, N.; Vranes, S. An overview and comparison of supervised data mining techniques for student exam performance prediction. Comput. Educ. 2019, 143, 103676. [Google Scholar] [CrossRef]
- Aucejo, E.M.; French, J.; Ugalde Araya, M.P.; Zafar, B. The impact of COVID-19 on student experiences and expectations: Evidence from a survey. J. Public Econ. 2020, 191, 104271. [Google Scholar] [CrossRef] [PubMed]
- Zollanvari, A.; Kizilirmak, R.C.; Kho, Y.H.; Hernandez-Torrano, D. Predicting Students’ GPA and Developing Intervention Strategies Based on Self-Regulatory Learning Behaviors. IEEE Access 2017, 5, 23792–23802. [Google Scholar] [CrossRef]
- Abu Amrieh, E.; Hamtini, T.; Aljarah, I. Mining Educational Data to Predict Student’s academic Performance using Ensemble Methods. Int. J. Database Theory Appl. 2016, 9, 119–136. [Google Scholar] [CrossRef]
- Hutt, S.; Gardener, M.; Kamentz, D.; Duckworth, A.L.; D’Mello, S.K. Prospectively predicting 4-year college graduation from student applications. In Proceedings of the LAK ‘18: International Conference on Learning Analytics and Knowledge, Sydney, Australia, 7–9 March 2018; pp. 280–289. [Google Scholar] [CrossRef]
- Xu, J.; Moon, K.H.; van der Schaar, M. A Machine Learning Approach for Tracking and Predicting Student Performance in Degree Programs. IEEE J. Sel. Top. Signal. Process. 2017, 11, 742–753. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Chen, S.; Liu, D.; Li, J. Performance Comparison and Current Challenges of Using Machine Learning Techniques in Cybersecurity. Energies 2020, 13, 2509. [Google Scholar] [CrossRef]
- Hassan, H.; Ahmad, N.B.; Anuar, S. Improved students’ performance prediction for multi-class imbalanced problems using hybrid and ensemble approach in educational data mining. J. Phys. Conf. Ser. 2020, 1529, 052041. [Google Scholar] [CrossRef]
- Wood, L.; Kiperman, S.; Esch, R.C.; Leroux, A.J.; Truscott, S.D. Predicting dropout using student- and school-level factors: An ecological perspective. Sch. Psychol. Q. 2017, 32, 35–49. [Google Scholar] [CrossRef]
- Nahar, K.; Shova, B.I.; Ria, T.; Rashid, H.B.; Islam, A.H.M.S. Mining educational data to predict students performance. Educ. Inf. Technol. 2021, 26, 6051–6067. [Google Scholar] [CrossRef]
- Madni, H.A.; Anwar, Z.; Shah, M.A. Data mining techniques and applications—A decade review. In Proceedings of the International Conference on Automation and Computing (ICAC), Huddersfield, UK, 7–8 September 2017; pp. 1–7. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Cenitta, D.; Arjunan, R.V.; Prema, K.V. Missing data imputation using machine learning algorithm for supervised learning. In Proceedings of the 2021 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 27–29 January 2021; pp. 1–5. [Google Scholar]
- Alam, T.M.; Shaukat, K.; Hameed, I.A.; Luo, S.; Sarwar, M.U.; Shabbir, S.; Li, J.; Khushi, M. An Investigation of Credit Card Default Prediction in the Imbalanced Datasets. IEEE Access 2020, 8, 201173–201198. [Google Scholar] [CrossRef]
- Kanchan, J.; Saha, S. Incorporation of multimodal multi objective optimization in designing a filter based feature selection technique. Appl. Soft Comput. 2021, 98, 106823. [Google Scholar]
- Krishnan, N.; Karthikeyan, M. IEEE signal processing/computational intelligence/computer joint societies chapter. In Proceedings of the 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, India, 18–20 December 2014. [Google Scholar]
- Salloum, S.A.; Alshurideh, M.; Elnagar, A.; Shaalan, K. Mining in educational data: Review and future directions. In Proceedings of the Joint European—US Workshop on Applications of Invariance in Computer Vision, Ponta Delgada, Portugal, 9–14 October 2020; pp. 61–70. [Google Scholar]
- Sakri, S.; Alluhaidan, A.S. RHEM: A robust hybrid ensemble model for students’ performance assessment on cloud computing course. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 388–396. [Google Scholar] [CrossRef]
- Musiliu, B. Single Classifiers and Ensemble Approach for Predicting Student’s Academic Performance. 2020. Available online: www.rsisinternational.org (accessed on 10 August 2021).
- Ali, S.; Smith, K.A. On learning algorithm selection for classification. Appl. Soft Comput. J. 2006, 6, 119–138. [Google Scholar] [CrossRef]
- Rokach, L. Taxonomy for characterizing ensemble methods in classification tasks: A review and annotated bibliography. Comput. Stat. Data Anal. 2009, 53, 4046–4072. [Google Scholar] [CrossRef] [Green Version]
- Livieris, I.E.; Iliadis, L.; Pintelas, P. On ensemble techniques of weight-constrained neural networks. Evol. Syst. 2021, 12, 155–167. [Google Scholar] [CrossRef]
- Ahmad, I.; Yousaf, M.; Yousaf, S.; Ahmad, M.O. Fake News Detection Using Machine Learning Ensemble Methods. Complexity 2020, 2020, 8885861. [Google Scholar] [CrossRef]
- Yang, X.; Lo, D.; Xia, X.; Sun, J. TLEL: A two-layer ensemble learning approach for just-in-time defect prediction. Inf. Softw. Technol. 2017, 87, 206–220. [Google Scholar] [CrossRef]
- Riestra-González, M.; del Puerto Paule-Ruíz, M.; Ortin, F. Massive LMS log data analysis for the early prediction of course-agnostic student performance. Comput. Educ. 2021, 163, 104108. [Google Scholar] [CrossRef]
- Hoque, I.; Azad, A.K.; Tuhin, M.A.H.; Salehin, Z.U. University Students Result Analysis and Prediction System by Decision Tree Algorithm. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 115–122. [Google Scholar] [CrossRef]
- Panigrahi, R.; Borah, S. Rank Allocation to J48 Group of Decision Tree Classifiers using Binary and Multiclass Intrusion Detection Datasets. Procedia Comput. Sci. 2018, 132, 323–332. [Google Scholar] [CrossRef]
- Bauer, E.; Kohavi, R. An empirical comparison of voting classification algorithms: Bagging, boosting, and variants. Mach. Learn. 1999, 36, 105–139. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Y.; Cheng, H.; Zhou, F.; Yin, B. An Unsupervised Ensemble Clustering Approach for the Analysis of Student Behavioral Patterns. IEEE Access 2021, 9, 7076–7091. [Google Scholar] [CrossRef]
- Ashraf, M.; Zaman, M.; Ahmed, M. An Intelligent Prediction System for Educational Data Mining Based on Ensemble and Filtering approaches. Procedia Comput. Sci. 2020, 167, 1471–1483. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Xu, M. A Survey on Machine Learning Techniques for Cyber Security in the Last Decade. IEEE Access 2020, 8, 222310–222354. [Google Scholar] [CrossRef]
- Sun, Y.; Li, Z.; Li, X.; Zhang, J. Classifier Selection and Ensemble Model for Multi-class Imbalance Learning in Education Grants Prediction. Appl. Artif. Intell. 2021, 35, 290–303. [Google Scholar] [CrossRef]
- Schapire, R.E. A brief introduction to boosting. Ijcai 1999, 99, 1401–1406. [Google Scholar]
- Shaukat, K.; Masood, N.; Mehreen, S.; Azmeen, U. Dengue Fever Prediction: A Data Mining Problem. J. Data Min. Genom. Proteom. 2015, 6, 3. [Google Scholar] [CrossRef] [Green Version]
- Adejo, O.W.; Connolly, T. Predicting student academic performance using multi-model heterogeneous ensemble approach. J. Appl. Res. High. Educ. 2018, 10, 61–75. [Google Scholar] [CrossRef]
- Dutta, S.; Bandyopadhyay, S.K. Forecasting of Campus Placement for Students Using Ensemble Voting Classifier. Asian J. Res. Comput. Sci. 2020, 1–12. [Google Scholar] [CrossRef]
- Alabi, E.O.; Adeniji, O.D.; Awoyelu, T.M.; Fasae, O.D. Hybridization of Machine Learning Techniques in Predicting Mental Disorder. Int. J. Hum. Comput. Stud. 2021, 3, 22–30. [Google Scholar]
- Wasif, M.; Waheed, H.; Aljohani, N.R.; Hassan, S.-U. Understanding student learning behavior and predicting their performance. In Cognitive Computing in Technology-Enhanced Learning; IGI Global: Hershey, PN, USA, 2019; pp. 1–28. [Google Scholar] [CrossRef]
- Emmanuel, A.A.; Aderoju, M.A.; Falade, A.A.F.; Atanda, A. An appraisal of online gambling on undergraduate students’ academic performance in university of Ilorin, Nigeria. Int. J. Innov. Technol. Integr. Educ. 2019, 3, 45–54. [Google Scholar]
- Yousafzai, B.K.; Hayat, M.; Afzal, S. Application of machine learning and data mining in predicting the performance of intermediate and secondary education level student. Educ. Inf. Technol. 2020, 25, 4677–4697. [Google Scholar] [CrossRef]
- Alam, T.M.; Mushtaq, M.; Shaukat, K.; Hameed, I.A.; Sarwar, M.U.; Luo, S. A Novel Method for Performance Measurement of Public Educational Institutions Using Machine Learning Models. Appl. Sci. 2021, 11, 9296. [Google Scholar] [CrossRef]
- Ajibade, S.-S.M.; Ahmad, N.B.B.; Shamsuddin, S.M. Educational Data Mining: Enhancement of Student Performance model using Ensemble Methods. IOP Conf. Ser. Mater. Sci. Eng. 2019, 551, 012061. [Google Scholar] [CrossRef]
- Ragab, M.; Aal, A.M.K.A.; Jifri, A.O.; Omran, N.F. Enhancement of Predicting Students Performance Model Using Ensemble Approaches and Educational Data Mining Techniques. Wirel. Commun. Mob. Comput. 2021, 2021, 6241676. [Google Scholar] [CrossRef]
- Saleem, F.; Ullah, Z.; Fakieh, B.; Kateb, F. Intelligent Decision Support System for Predicting Student’s E-Learning Performance Using Ensemble Machine Learning. Mathematics 2021, 9, 2078. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Student Attributes | Possible Values Used in All Research Papers While Implementing the DM Algorithm |
|---|---|
| Academic Attributes | Internal and external assessment, lab marks, sessional marks, attendance, Cumulative Grade Point Average (CGPA), semester marks, grade, seminar performance, assignment, attendance, schools marks, previous academic marks, etc. |
| Personal Attributes | Age, gender, height, weight, Emotional Intelligence (EI), student interest, level of motivation, communication, sports person, hobbies and ethnicity, etc. |
| Family Attributes | Qualification, occupation, income, status, support, siblings, responsibilities, etc. |
| Social Attributes | Number of friends, social networking, girls’/boys’ friends, movies, travel outings, friends’ parties, etc. |
| School Attributes | Teaching medium, accommodation, infrastructure, water and toilet facilities, transportation system, class size, school reputation, school status, class size, school type, teaching methodology, etc. |
| S. No | Attributes | Description |
|---|---|---|
| 1 | GE | Gender (Male, Female) |
| 2 | HA | Home Address Urban, Rural) |
| 3 | PCA | Parent Cohabitation Status (Living together, Apart) |
| 4 | QFR | Quality of family Relationship (Very Good, Good, Not Good) |
| 5 | MJ | Mother Job (Yes, No) |
| 6 | FJ | Father Job (Yes, No) |
| 7 | ME | Mother Education (None, Elementary, Secondary, Higher) |
| 8 | FE | Father Education (None, Elementary, Secondary, Higher) |
| 9 | FS | Family Size (Less than 3, Greater or equal to 3) |
| 10 | GF | Going out with friends (Yes, No) |
| 11 | PF | Past Failures (Yes, No) |
| 12 | NS | Attended Nursery School (Yes, No) |
| 13 | HE | Want to take Higher Education (Yes, No) |
| 14 | R | Relationship (Yes, No) |
| 15 | IA | Internet access at home (Yes, No) |
| 16 | ECA | Extra-Curricular Activities (Yes, No) |
| 17 | DST | Daily Study Time (<2 h, 2 to 5 h, 5 to 10 h, >10 h) |
| 18 | HST | Home to school Travel Time (<15 min, 15 to 30 min, 30 min to 1 h, >1 h) |
| 19 | EG | 8th Class Grades (A+, A, B+, B, C, D) |
| 20 | NG1 | 9th Class First Term Grades (A+, A, B+, B, C, D, F) |
| 21 | NG2 | 9th Class Final Term Grades (A+, A, B+, B, C, D, F) |
| Correctly Classified Instances | 1185 | 98.7 % | |||
| Incorrectly Classified Instances | 15 | 1.24 % | |||
| TP Rate | FP Rate | Precision | Recall | F-Measure | Class |
| 0.997 | 0.008 | 0.976 | 0.997 | 0.986 | A+ |
| 0.996 | 0.001 | 0.996 | 0.996 | 0.996 | B |
| 0.983 | 0.001 | 0.994 | 0.983 | 0.988 | B+ |
| 0.994 | 0.007 | 0.983 | 0.994 | 0.989 | A |
| 0.969 | 0.000 | 1.000 | 0.969 | 0.984 | C |
| 0.909 | 0.000 | 1.000 | 0.909 | 0.952 | F |
| 0.943 | 0.000 | 1.000 | 0.988 | 0.971 | D |
| Weighted Average | |||||
| 0.988 | 0.004 | 0.988 | 0.986 | 0.987 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Siddique, A.; Jan, A.; Majeed, F.; Qahmash, A.I.; Quadri, N.N.; Wahab, M.O.A. Predicting Academic Performance Using an Efficient Model Based on Fusion of Classifiers. Appl. Sci. 2021, 11, 11845. https://doi.org/10.3390/app112411845
Siddique A, Jan A, Majeed F, Qahmash AI, Quadri NN, Wahab MOA. Predicting Academic Performance Using an Efficient Model Based on Fusion of Classifiers. Applied Sciences. 2021; 11(24):11845. https://doi.org/10.3390/app112411845
Chicago/Turabian StyleSiddique, Ansar, Asiya Jan, Fiaz Majeed, Adel Ibrahim Qahmash, Noorulhasan Naveed Quadri, and Mohammad Osman Abdul Wahab. 2021. "Predicting Academic Performance Using an Efficient Model Based on Fusion of Classifiers" Applied Sciences 11, no. 24: 11845. https://doi.org/10.3390/app112411845
APA StyleSiddique, A., Jan, A., Majeed, F., Qahmash, A. I., Quadri, N. N., & Wahab, M. O. A. (2021). Predicting Academic Performance Using an Efficient Model Based on Fusion of Classifiers. Applied Sciences, 11(24), 11845. https://doi.org/10.3390/app112411845