
Mobile Robot Path Optimization Technique Based on Reinforcement Learning Algorithm in Warehouse Environment



Abstract
:1. Introduction
2. Related Work
2.1. Warehouse Environment
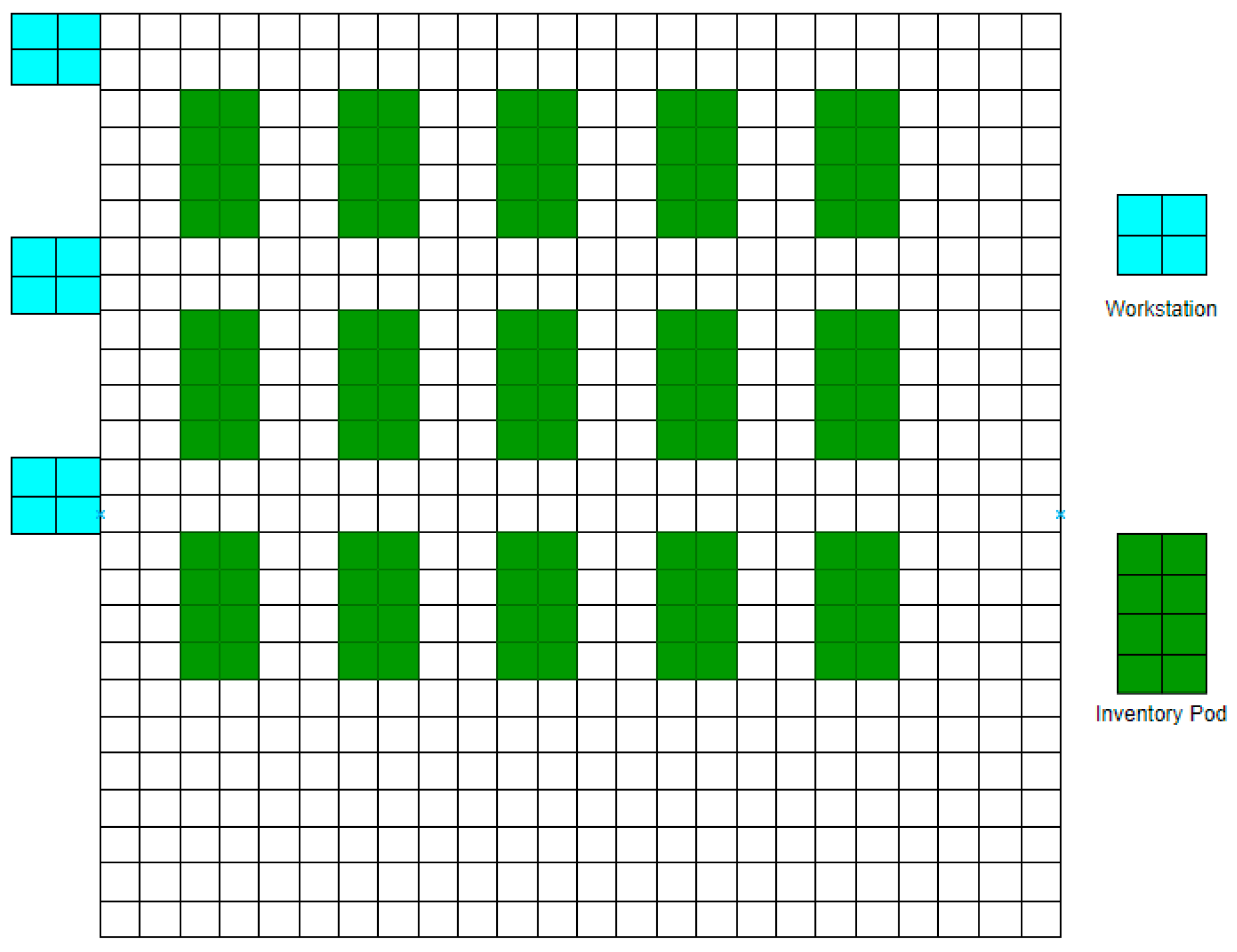
2.1.1. Warehouse Layout and Components
- Robot drive device: It instructs the robot from the center to pick or load goods between the workstation and the inventory pod.
- Inventory pod: This is a shelf rack that includes storage boxes. There are two standard sizes: a small pod can hold up to 450 kg, and a large pod can load up to 1300 kg.
- Workstation: This is the work area in which the worker operates and performs tasks such as replenishment, picking, and packaging.
2.1.2. Mobile Robot’s Movement Type
- move goods from the workstation to the inventory pod;
- move from one inventory pod to another to pick up goods;
- move goods from the inventory pod to the workstation
2.2. Path Planning for Mobile Robot
- Environmental modeling
- Optimization criteria
- Path finding algorithm
2.3. Reinforcement Learning Algorithm
2.3.1. Q-Learning
| Algorithm 1: Q-Learning. |
| Initialize Q(s, a) |
| Loop for each episode: |
| Initialize s (state) |
| Loop for each step of episode until s (state) is destination: |
| Choose a (action) from s (state) using policy from Q values |
| Take a (action), find r (reward), s’ (next state) |
| Calculate Q value and Save it into Q Table |
| Change s’ (next state) to s (state) |
2.3.2. Dyna-Q
| Algorithm 2: Dyna-Q. |
| Initialize Q(s, a) |
| Loop forever: |
| (a) Get s (state) |
| (b) Choose a (action) from s (state) using policy from Q values |
| (c) Take a (action), find r (reward), s’ (next state) |
| (d) Calculate Q value and Save it into Q Table |
| (e) Save s (state), a (action), r (reward), s’ (next state) in memory |
| (f) Loop for n times |
| Take s(state), a (action), r (reward), s’ (next state) |
| Calculate Q value and Save it into Q Table |
| (g) Change s’ (next state) to s (state) |
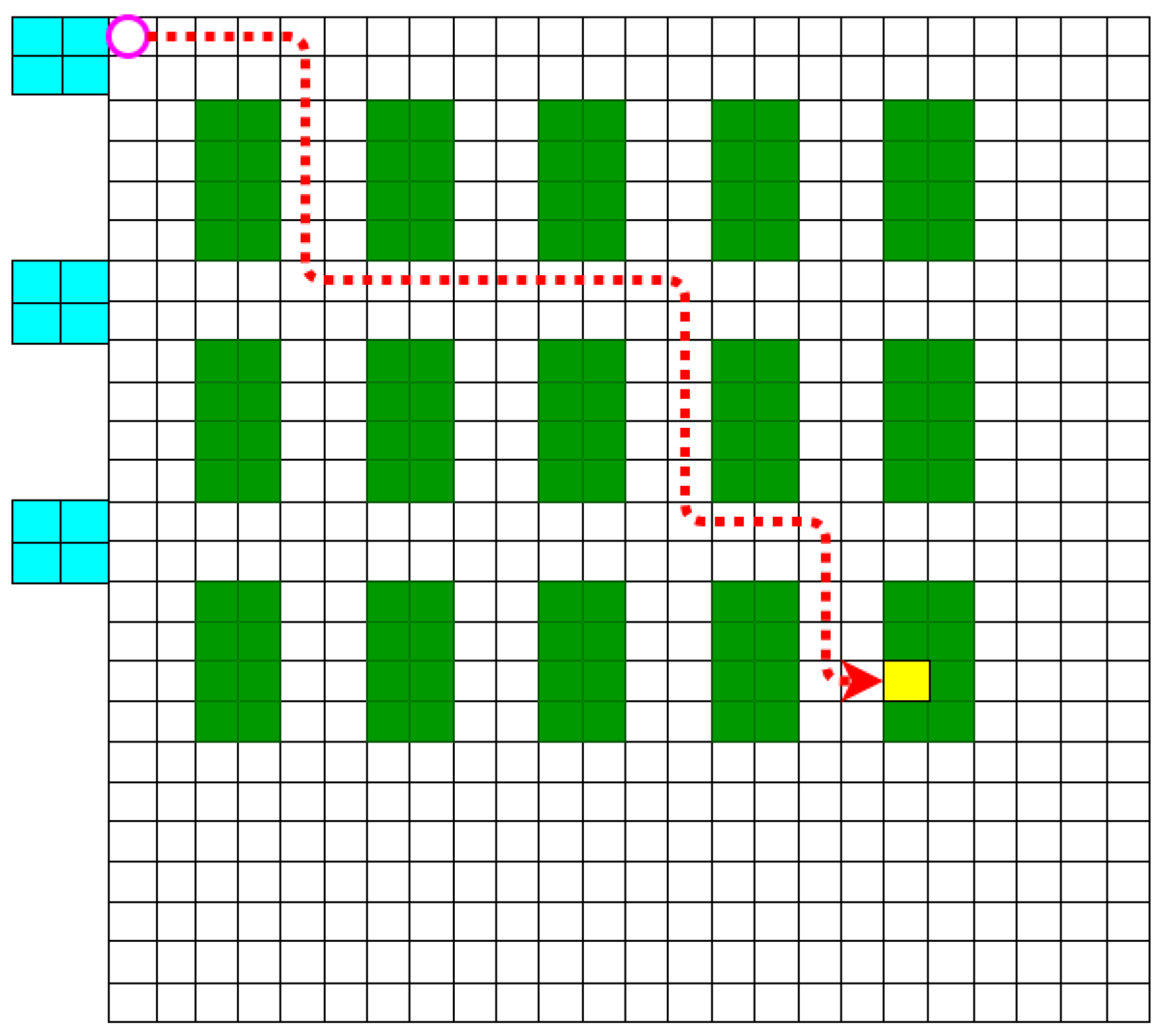
3. Reinforcement Learning-Based Mobile Robot Path Optimization
3.1. System Structure
3.2. Operation Procedure
3.3. Dynamic Reward Adjustment Based on Action
| Algorithm 3: Dynamic reward adjustment based on action. |
| 1. Get new destination to move |
| 2. Select a partial area near the target position. |
| 3. A higher positive reward value is assigned to the selected area, excluding the target point and obstacles. |
| (Highest positive reward value to target position) |
4. Test and Results
4.1. Warehouse Simulation Environment
4.2. Test Parameter Values
4.3. Test Reward Values
- Basic method: The obstacle was set as −1, the target position as 1, and the other positions as 0.
- Dynamic reward adjustment based on action: To check the efficacy of the proposal, an experiment was conducted designating set values that were similar to those in the proposed method as shown in Figure 10 [28,29,30]. The obstacle was set as −1, the target position as 10, the positions in the selected area (area close to target) as 0.3, and the other positions as 0.
4.4. Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hajduk, M.; Koukolová, L. Trends in Industrial and Service Robot Application. Appl. Mech. Mater. 2015, 791, 161–165. [Google Scholar] [CrossRef]
- Belanche, D.; Casaló, L.V.; Flavián, C. Service robot implementation: A theoretical framework and research agenda. Serv. Ind. J. 2020, 40, 203–225. [Google Scholar] [CrossRef] [Green Version]
- Fethi, D.; Nemra, A.; Louadj, K.; Hamerlain, M. Simultaneous localization, mapping, and path planning for unmanned vehicle using optimal control. SAGE 2018, 10, 168781401773665. [Google Scholar] [CrossRef] [Green Version]
- Zhou, P.; Wang, Z.-M.; Li, Z.-N.; Li, Y. Complete Coverage Path Planning of Mobile Robot Based on Dynamic Programming Algorithm. In Proceedings of the 2nd International Conference on Electronic & Mechanical Engineering and Information Technology (EMEIT-2012), Shenyang, China, 7 September 2012; pp. 1837–1841. [Google Scholar]
- Azadeh, K.; Koster, M.; Roy, D. Robotized and Automated Warehouse Systems: Review and Recent Developments. INFORMS 2019, 53, 917–1212. [Google Scholar] [CrossRef]
- Koster, R.; Le-Duc, T.; JanRoodbergen, K. Design and control of warehouse order picking: A literature review. EJOR 2007, 182, 481–501. [Google Scholar] [CrossRef]
- Jan Roodbergen, K.; Vis, I.F.A. A model for warehouse layout. IIE Trans. 2006, 38, 799–811. [Google Scholar] [CrossRef]
- Larson, T.N.; March, H.; Kusiak, A. A heuristic approach to warehouse layout with class-based storage. IIE Trans. 1997, 29, 337–348. [Google Scholar] [CrossRef]
- Kumara, N.V.; Kumarb, C.S. Development of collision free path planning algorithm for warehouse mobile robot. In Proceedings of the International Conference on Robotics and Smart Manufacturing (RoSMa2018), Chennai, India, 19–21 July 2018; pp. 456–463. [Google Scholar]
- Sedighi, K.H.; Ashenayi, K.; Manikas, T.W.; Wainwright, R.L.; Tai, H.-M. Autonomous local path planning for a mobile robot using a genetic algorithm. In Proceedings of the 2004 Congress on Evolutionary Computation, Portland, OR, USA, 19–23 June 2004; pp. 456–463. [Google Scholar]
- Lamballaisa, T.; Roy, D.; De Koster, M.B.M. Estimating performance in a Robotic Mobile Fulfillment System. EJOR 2017, 256, 976–990. [Google Scholar] [CrossRef] [Green Version]
- Merschformann, M.; Lamballaisb, T.; de Kosterb, M.B.M.; Suhla, L. Decision rules for robotic mobile fulfillment systems. Oper. Res. Perspect. 2019, 6, 100128. [Google Scholar] [CrossRef]
- Zhang, H.-Y.; Lin, W.-M.; Chen, A.-X. Path Planning for the Mobile Robot: A Review. Symmetry 2018, 10, 450. [Google Scholar] [CrossRef] [Green Version]
- Han, W.-G.; Baek, S.-M.; Kuc, T.-Y. Genetic algorithm based path planning and dynamic obstacle avoidance of mobile robots. In Proceedings of the 1997 IEEE International Conference on Systems, Man, and Cybernetics. Computational Cybernetics and Simulation, Orlando, FL, USA, 12–15 October 1997. [Google Scholar]
- Nurmaini, S.; Tutuko, B. Intelligent Robotics Navigation System: Problems, Methods, and Algorithm. IJECE 2017, 7, 3711–3726. [Google Scholar] [CrossRef] [Green Version]
- Johan, O. Warehouse Vehicle Routing Using Deep Reinforcement Learning. Master’s Thesis, Uppsala University, Uppsala, Sweden, November 2019. [Google Scholar]
- Hands-On Machine Learning with Scikit-Learn and TensorFlow by Aurélien Géron. Available online: https://www.oreilly.com/library/view/hands-on-machine-learning/9781491962282/ch01.html (accessed on 22 December 2020).
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning, 2nd ed.; MIT Press: London, UK, 2018; pp. 1–528. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming, 1st ed.; Wiley: New York, NY, USA, 1994; pp. 1–649. [Google Scholar]
- Deep Learning Wizard. Available online: https://www.deeplearningwizard.com/deep_learning/deep_reinforcement_learning_pytorch/bellman_mdp/ (accessed on 22 December 2020).
- Meerza, S.I.A.; Islam, M.; Uzzal, M.M. Q-Learning Based Particle Swarm Optimization Algorithm for Optimal Path Planning of Swarm of Mobile Robots. In Proceedings of the 1st International Conference on Advances in Science, Engineering and Robotics Technology, Dhaka, Bangladesh, 3–5 May 2019. [Google Scholar]
- Hsu, Y.-P.; Jiang, W.-C. A Fast Learning Agent Based on the Dyna Architecture. J. Inf. Sci. Eng. 2014, 30, 1807–1823. [Google Scholar]
- Sichkar, V.N. Reinforcement Learning Algorithms in Global Path Planning for Mobile Robot. In Proceedings of the 2019 International Conference on Industrial Engineering Applications and Manufacturing, Sochi, Russia, 25–29 March 2019. [Google Scholar]
- Jang, B.; Kim, M.; Harerimana, G.; Kim, J.W. Q-Learning Algorithms: A Comprehensive Classification and Applications. IEEE Access 2019, 7, 133653–133667. [Google Scholar] [CrossRef]
- Kirtas, M.; Tsampazis, K.; Passalis, N. Deepbots: A Webots-Based Deep Reinforcement Learning Framework for Robotics. In Proceedings of the 16th IFIP WG 12.5 International Conference AIAI 2020, Marmaras, Greece, 5–7 June 2020; pp. 64–75. [Google Scholar]
- Altuntas, N.; Imal, E.; Emanet, N.; Ozturk, C.N. Reinforcement learning-based mobile robot navigation. Turk. J. Electr. Eng. Comput. Sci. 2016, 24, 1747–1767. [Google Scholar] [CrossRef]
- Glavic, M.; Fonteneau, R.; Ernst, D. Reinforcement Learning for Electric Power System Decision and Control: Past Considerations and Perspectives. In Proceedings of the 20th IFAC World Congress, Toulouse, France, 14 July 2017; pp. 6918–6927. [Google Scholar]
- Wang, Y.-C.; Usher, J.M. Application of reinforcement learning for agent-based production scheduling. Eng. Appl. Artif. Intell. 2005, 18, 73–82. [Google Scholar] [CrossRef]
- Mehta, N.; Natarajan, S.; Tadepalli, P.; Fern, A. Transfer in variable-reward hierarchical reinforcement learning. Mach. Learn. 2008, 73, 289. [Google Scholar] [CrossRef] [Green Version]
- Hu, Z.; Wan, K.; Gao, X.; Zhai, Y. A Dynamic Adjusting Reward Function Method for Deep Reinforcement Learning with Adjustable Parameters. Math. Probl. Eng. 2019, 2019, 7619483. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Q-Learning | Dyna-Q |
|---|---|---|
| Learning Rate (α) | 0.01 | 0.01 |
| Discount Rate (γ) | 0.9 | 0.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, H.; Jeong, J. Mobile Robot Path Optimization Technique Based on Reinforcement Learning Algorithm in Warehouse Environment. Appl. Sci. 2021, 11, 1209. https://doi.org/10.3390/app11031209
Lee H, Jeong J. Mobile Robot Path Optimization Technique Based on Reinforcement Learning Algorithm in Warehouse Environment. Applied Sciences. 2021; 11(3):1209. https://doi.org/10.3390/app11031209
Chicago/Turabian StyleLee, HyeokSoo, and Jongpil Jeong. 2021. "Mobile Robot Path Optimization Technique Based on Reinforcement Learning Algorithm in Warehouse Environment" Applied Sciences 11, no. 3: 1209. https://doi.org/10.3390/app11031209