1. Introduction
Human brain has an excellent visual system that the main content of a scene can be captured in less than one second. As an important research aspect in neuroscience, it is significant to record brain signals and decode visual information from these signals [
1]. With brain decoding techniques, we are able to understand the high-level recognition abilities and diagnose the psychological illness. Magnetoencephalography (MEG) is an advanced technique for recording brain magnetic signals within hundreds of channels. Based on the MEG technique, neuroscientists are able to study brain function in-depth [
2,
3,
4,
5]. Moreover, the sampling rate of MEG signal can be quite high that it can record brain magnetic signals in milliseconds. With high temporal resolution, MEG signals can be used to study the dynamic changes of brain function [
6,
7,
8].
However, due to the low signal-to-noise ratio and the structural or functional variability of MEG signals between different subjects, conventional machine learning methods perform poorly in decoding MEG signals. In addition, the existing MEG decoding techniques were rare and had never been evaluated on common benchmark database. In the existing publications, MEG decoding methods were evaluated by different databases that the experimental performance varied a lot. As a result, the corresponding results maybe not quite convincing. Therefore, to facilitate the development of MEG decoding techniques, a MEG decoding experimental dataset was released [
4,
8].
The experimental procedure of this dataset is shown in
Figure 1. During the experiments, the subject was asked to look at pictures with face image or scrambled face image. In the meanwhile, a MEG recording system will record his/her brain magnetic signals. As shown in
Figure 1, we can find that the MEG signals in different scalp locations had different signal components. Based on the recorded MEG signals and the corresponding visual stimulations, a decoding model can be built to predict the visual information (face or scrambled face image) from MEG signals. Consequently, different MEG decoding methods can be trained and evaluated by a common dataset [
4,
8].
According to previous research, conventional methods usually rely on ensemble averaging technique to deal with the low signal-to-noise ratio of brain signals and acquire reliable detection [
9]. However, the ensemble averaging technique might erase some important information in each trial of ERP signals [
10]. According to some neuroscience researches, continuous gamma effect was found in the averaged brain signals in multiple trials [
11,
12]. It means that studying single-trial signals is essential for understanding the dynamic change of human brain. Moreover, decoding brain signals in an inter-subject manner is significant in neuroscience researches [
4,
13,
14]. For example, a transductive transfer learning (TTL) algorithm was proposed for inter-subject MEG decoding with single-trial samples [
4]. To extract manifold features of MEG signals, a new MEG decoding method based on riemannian metric was applied, which achieved a high decoding accuracy [
15]. Moreover, as a popular machine learning approach in many areas, random forest was applied for MEG decoding [
16]. The random forest algorithm can effectively extract MEG features of different subjects and improve inter-subject MEG decoding performance.
In the past few years, deep learning methodology was widely used and achieved remarkable results in many areas. As for brain signal processing, deep learning methods also worked well in extracting features, detecting abnormal components, classifications and so on. For example, deep network based on restricted Boltzmann machine (RBM) achieved good performance in processing electroencephalogram(EEG) signals [
17,
18]. Convolutional neural network (CNN) was firstly applied for detecting event-related potentials from EEG signals [
19]. Moreover, deep learning method was utilized to study the dynamics of scene representations in the human brain revealed by MEG [
20]. To analyze the MEG signals with high temporal resolution, a CNN-based model was proposed that the experimental results demonstrated its efficiency [
21]. Logistic regression with
ℓ1 penalization (termed Pool) was proposed to model MEG data of many subjects [
4,
22,
23]. Inspired by deep learning methodology, two logistic regression layers were stacked that a new MEG decoding method termed stacked generation (SG) was proposed and achieved better performance than the Pool model [
4,
24]. Additionally, inspired by deep learning models, logistic regression and random forest were combined in a deep structure (called linear regression and random forest—LRRF model) which achieved a good MEG decoding performance [
25]. A deep network based on riemannian metric was proposed for decoding MEG signals evoked by the stimulation of face or scrambled face images [
15,
26].
However, there are still many problems in the existing MEG decoding methods. We need to find a more effective approach to model numerous high-dimensional MEG signals, extract their features and further improve MEG decoding performance. The main contributions of this paper can be summarized as follows:
A hybrid gated recurrent network (HGRN) was proposed for inter-subject visual MEG decoding.
The proposed HGRN is able to model high-dimensional MEG signal, extract its features, and distinguish the signal evoked by different visual stimulations.
Experimental results demonstrated that the proposed model is able to achieve a good MEG decoding performance. More importantly, the proposed method can be utilized as a new analyzing tool for MEG signals.
The remainder of this paper is organized as follows. The proposed hybrid gated recurrent network (HGRN) is presented in
Section 2. In
Section 3, numerical inter-subject MEG decoding experiments are carried out. In addition, the performance of different MEG decoding methods are presented and compared. Some discussions are presented in
Section 4. Conclusions of this paper are given in
Section 5.
2. Proposed Method
For many conventional methods, a multi-channel MEG sample with spatial-temporal structure must be reshaped as a feature vector that its original spatial/temporal structure will be corrupted. This maybe one of the main reasons for their low performance. To deal with the spatial-temporal structure of MEG signal, we proposed a hybrid gated recurrent network (HGRN) which is a modified recurrent network based on gate recurrent units (GRU). To our best knowledge, the HGRN is the first gated recurrent network for MEG decoding. Compared with the conventional methods, the HGRN can directly process multichannel MEG signal, extract its spatial-temporal features and decode it within one network.
The gated recurrent unit (GRU) is a special network structure which utilizes multiple gating units to store or regulate information [
27,
28,
29]. In a GRU structure, its gated units are only activated by the current inputs and the previous inputs. Compared with the other kind of recurrent network structure, the GRU consists of less parameters and is converged faster as well. The GRU can adaptively capture the dependencies of the input data on different time scales. Many researches showed that the deep networks based on GRU achieved high performance in the sequence processing tasks [
30,
31,
32].
In
Figure 2, the internal structure of GRU is shown. The output of GRU at time
t is
where
j denotes the
j-th element. The
can be obtained by linear interpolation between the previous output
and the current candidate output
as follow:
where
is the
j element of update gate
. The
determines the updated scale of the output of GRU.
Here, the update gate
can be obtained by the following statement:
where
denotes the input value at time
t,
is the previous output at time
.
As the traditional recurrent unit, the candidate output
is computed by:
where
is the reset gate, ⊙ is the Hadamard product (element-wise product), the
is a nonlinear function which is computed by
Following the update gate, the reset gate
is defined as
When the reset gate is closed, i.e.,
, the GRU will forget the previous states, and read the current input sequence instead. Based on the update gate
and the reset gate
, the GRU can remember and update its states which is helpful for adaptively capturing the dependencies of input sequences in different time scales.
Based on the GRU structure, the proposed HGRN is built to adaptively capture the dependencies of MEG signals in different time scales. In
Figure 3, the structure of the proposed HGRN is shown. The proposed HGRN consists of two GRU-based layers, two down-sampling layers and an output layer. In the GRU-based layers, there are two GRUs, the GRU1 and GRU2 layer. Located in two different layers, GRU1 and GRU2 consist of 100 and 10 output units, respectively. The GRU layers are able to extract spatial features at the current time point and the previous ones. Compared with the other kinds of network structures, the HGRN model with GRU layer can efficiently process spatial-temporal data with a simple structure. In the down-sampling layers, max pooling (Max-Pool) operation is applied [
33]. The Max-Pool(5) indicates that the max activation value at 5 contiguous time points is considered as the sampled value. Then the temporal features within 20 ms and 100 ms scale can be extracted by the first and second max pooling layers. Moreover, the output layer of HGRN is a fully connected layer with two output units. The spatial and temporal features can be combined to achieve better MEG decoding performance. Similar to many other deep networks, the HGRN applies softmax function for the activations of its output units. Then, the outputs of HGRN can be obtained that the visual stimulation of the current input MEG signal is predicted.
Accordingly, the HGRN model can be optimized by minimizing the cross-entropy between its predictions and the true labels. Therefore, the corresponding loss function of the proposed model is defined as follow:
where
denotes the MEG signal evoked by face image,
denotes the MEG signal evoked by scrambled face image,
is the probability of the HGRN model to detect a MEG signal evoked by face image,
is the probability corresponding to scrambled face image stimulation,
indicate the ground truth of the input signal. If the input MEG signal is stimulated by face image, the ground truth is
, otherwise,
.
In the next section, a series of experiments will be carried out to evaluate the proposed HGRN model. In addition, the corresponding experimental results of our method will be presented and compared with the other methods.
3. Experiments
In this section, the experimental procedure and results of the proposed HGRN will be presented. In the experiments, the proposed method and some other popular MEG decoding methods are tested by a common dataset. For ease of reproduction, the details of data preprocessing and normalization will be illustrated. Moreover, the training procedure and the parameter settings of the proposed model are given as well.
In our experiments, the hardware and software configuration of our system is a desktop with Intel i7 3.6 Ghz CPU, 16 G DDR3 RAM, Nvidia Titan X, Ubuntu 16.04 and Keras with tensorflow backend.
3.1. MEG Signal Preprocessing
According to the experiments of the public visual MEG decoding dataset [
4,
8], the subject will stimulated by two different visual stimulations, face and scrambled face images. Sixteen subjects took part in the MEG decoding experiment. During the experiment, each subject received about 580 visual stimulations. The corresponding MEG signals were recorded by a MEG equipment with 306 channels. The provided MEG signals were down-sampled to a rate of 250 Hz. Before each stimulation, the subject can rest 0.5 s and then receive a stimulation which will last one second. Firstly, the MEG signals evoked by each stimulation will be extracted. Secondly, each MEG signal was filtered by a [0.1, 20] Hz 4-order Butterworth filter. Lastly, each signal was normalized by subtracting its mean, and then dividing its standard deviation.
Consequently, the MEG data of all 16 subjects will be applied for leave-one-out cross-validation (LOOCV) in the following experiment.
3.2. Experimental Procedure
In order to train the proposed HGRN model, the Adam optimizer [
34] was applied for minimizing the model’s loss function (as shown in (
6)). In each round of LOOCV experiment, the MEG data of 15 subjects were selected as training database, and the remaining one subject’s MEG data were considered as validation database. During the training procedure, 90 percent of the samples in training database was randomly chosen as the training set while the remaining 10 percent was chosen as the observation set for monitoring the training procedure. Then the proposed HGRN model was trained by Adam optimizer with a learning rate of
, a learning rate decay parameter of
, a drop-out rate of 0.1 and mini-bath size of 100. The drop-out operation was only applied in the training procedure for randomly blocking the output of GRUs. During the training procedure, the model loss on the observation set was monitored. As the monitored loss was minimized, the training procedure was stopped.
3.3. Experimental Result
Once the proposed HGRN model was trained, it could be tested by the validation database that its MEG decoding performance can be evaluated. For the public MEG decoding database of 16 subjects, the LOOCV experiments were carried out 16 times so that the corresponding results could be considered as the performance references of different MEG decoding methods.
In
Table 1, the results of the proposed HGRN model are presented. In addition, the experimental results of some state-of-the-art MEG decoding methods are also presented for comparison. To be clear, these methods are all supervised learning approaches which do not require any information of the testing data. Although some semi-supervised learning methods may achieve higher accuracy, they just utilized the information of the testing data which is not quite reasonable in practice [
4]. In the method termed Pool [
4,
22,
23], logistic regression with
ℓ1 penalization was used to model the MEG data of multiple subjects, and applied for decoding MEG signals of new subject. The Pool method did not consider the differences between different subjects that the corresponding inter-subject MEG decoding performance was not very well. By applying two logistic regression layers, the stacked generalization (SG) model achieved better performance than the Pool method [
4,
24]. Considering the differences between subjects, stacked generalization with covariate shift (SG+CS) was proposed that different weighted parameters were applied for different subjects in the seconde logistic layer of SG+CS model [
4,
35]. Moreover, the MEG decoding method based on Riemannian geometry achieved a good performance [
15,
26]. To imitate deep structure of deep network, a method termed linear regression and random forest (LRRF) was proposed. The first layer of LRRF consisted of multiple logistic regression classifiers, and the output probabilities of the first layer was fed into a random forest for MEG decoding [
25].
As shown in
Table 1, the proposed HGRN achieved higher performance than many other methods in the LOOCV experiments of 16 subjects. Specifically, the averaged MEG decoding accuracy of HGRN was
which was the highest in the table. The experimental results demonstrated that the proposed HGRN is an effective model for inter-subject MEG decoding.
In order to compare the performance of the proposed method with the other methods, the Wilcoxon signed-rank test was applied for statistical analysis. As shown in
Table 2, the Wilcoxon signed-rank test results between the proposed HGRN and the other methods are presented. Accordingly, the statistical analysis demonstrated that the HGRN achieved significantly better performance than the methods like Pool, SG, SG+CS and Gen. Although the proposed model did not achieve a significant better performance than LRRF, its averaged accuracy was a little higher than the LRRF as shown in
Table 1. These results indicated the effectiveness of the proposed HGRN on MEG decoding performance.
In the next section, we will discuss and analyze the internal properties of the proposed model. It may be significant for further research.
4. Discussion
Based on GRU structure, the proposed HGRN model was built to capture the features of MEG signals and decode the signals. In this section, the proposed HGRN model will be discussed in details. First of all, the performance of the proposed model to decode face image stimulation and scrambled face image stimulation were presented in confusion matrix. Based on confusion matrix, the decoding performance difference between the two stimulations can be analyzed. Secondly, the weights of MEG sensors on the scalp for decoding signals are extracted. Consequently, the spatial distribution of the MEG signals in the decoding experiments can be determined. Lastly, the MEG signals evoked by two different stimulations will be extracted for analysis.
To analyze the MEG decoding performance of HGRN, confusion matrix is applied and presented in
Figure 4. Specifically, the MEG signals evoked by face images were considered as positive class, while the MEG signals evoked by scrambled face images were categorized as the negative class. In the experiment, the true positive category indicated that the predicted results and the ground truth are all positive class. Likewise, the true negative category indicated that the predicted results and the ground truth are the same negative class. The false positive indicated that the predicted results are positive class while the ground truth is negative. The false negative indicated that the predicted results are negative class while the ground truth is positive. The
,
,
and
denote the number of samples in the categories of true positive, true negative, false positive and false negative, respectively. Then, the true positive rate (TPR), true negative rate (TNR), false positive rate (FPR) and false negative rate (FNR) are calculated. These results were calculated with all 16 subjects’ results in the LOOCV experiments.
As shown in
Figure 4, the number of samples in the categories of true positive, true negative, false positive and false negative are presented in the confusion matrix. Moreover, the corresponding TPR, TNR, FPR and FNR are also presented. According to
Figure 4, the TPR and TNR were closed to
. The corresponding recall, precision and F1 scores are
,
and
, respectively. These results demonstrated that the HGRN model can evenly distinguish the positive samples and negative samples (i.e., MEG signals evoked by face images and scrambled face images). The accuracy is a proper metric to evaluate balance datasets according to the previous study [
37]. In the used dataset, the number of the positive and negative samples are 4693 and 4721 that it can be considered as a balance dataset. The accuracies presented in
Table 1 can be used for the comparison between the performance of the other models and ours. In addition, about 30 percent of samples were incorrectly categorized. That is to say, there was still a lot of room for improving MEG decoding performance.
In order to study the spatial features of MEG signals, we applied a leave-one-alone strategy that only one MEG channel was reserved for analysis while the rest channels were clamped to zero. Next, the new MEG signals were tested by the HGRN model which is trained previously. Then, the MEG decoding result corresponding to each reserved channel can be obtained. To a certain extent, these results can be considered as the contributions of MEG channels in the decoding experiments. By normalizing these results to [0, 1], the weight of each channel for MEG decoding is calculated. Then, the spatial feature of each subject can be obtained. As shown in
Figure 5, the spatial feature of MEG signals of Subject 1 is presented that its top view and side view are presented in the left subfigure and right subfigure, respectively. For ease of reading, the nose and ears of the subject were also presented for references in
Figure 5. Likewise, the spatial features of MEG signals of all 16 subjects are obtained and presented in
Figure 6. As shown in
Figure 5 and
Figure 6, the MEG channel with the highest weight is usually located in the occipital region of each subject. This finding conformed to many previous research that the visual perception organization of the human brain is mainly located in the occipital region [
7]. The experimental results and analysis indicate that the proposed HGRN model can be used for analyzing the spatial features of MEG signals. It shows a potential value of the proposed HGRN in the application of brain-computer interface and neuroscience research.
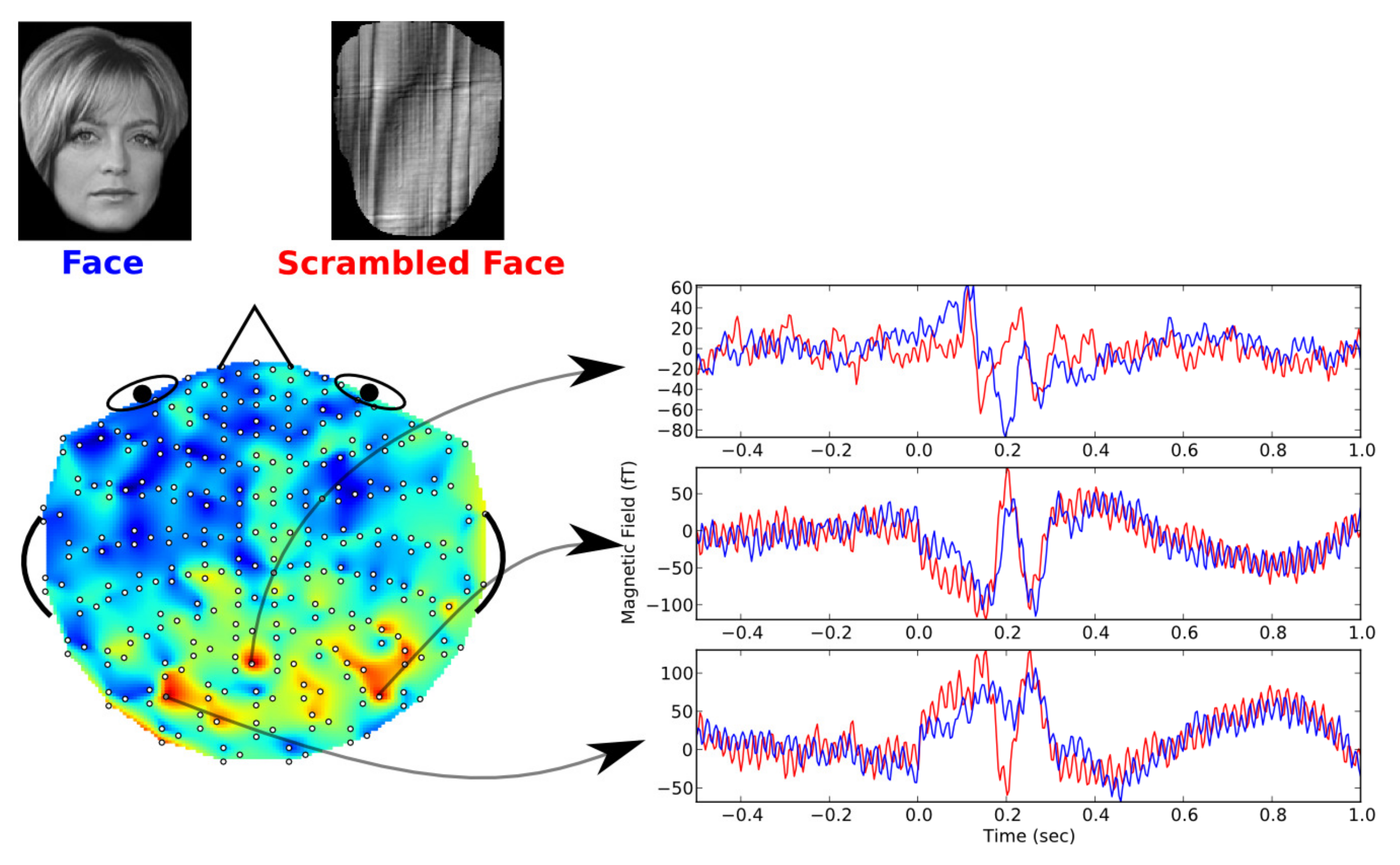
According to the spatial feature in
Figure 6, the MEG channel with largest weight of each subject can be determined. To some certain extent, the signals at this channel can be considered as typical MEG signals for the decoding experiments. By averaging the MEG signals at the highest-weighted channel, the typical MEG waveforms evoked by face or scrambled face image stimulation are obtained. As shown in
Figure 7, the typical MEG waveforms evoked by the two different stimulations are presented. From the figure, we can find that the waveforms evoked by face and scrambled face images were quite different at about
s. The waveforms corresponding to face image stimulation usually had lower amplitude at about
s according to the previous studies [
4,
13,
14].
The extraction and analysis methods of the above MEG waveform can be applied in the research of neuroscience. For example, the change of brain cognitive activity over time can be explored. The proposed method can be considered as a new tool for further exploration of advanced human brain cognitive behavior.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}