
KeyNet: An Asymmetric Key-Style Framework for Watermarking Deep Learning Models


Abstract
:1. Introduction
Contributions and Plan of This Article
- KeyNet provides a strong link between the owner and her marked model by integrating two reliable authentication methods: A cryptographic hashing algorithm and a verification protocol. Furthermore, the use of a cryptographic hash improves the capacity of embedding WM information. Besides being robust against DL model modifications such as compression and fine-tuning, KeyNet does not allow the WM to be overwritten by attackers without losing the accuracy of the original task.
- We demonstrate the ability of our framework to scale and fingerprint different unique copies of a DL model for different users in the system. The information of a user is combined with the owner’s information, the carrier is signed with the combined information, and then a unique pair of a pretrained model along with its corresponding private model is fine-tuned before being delivered to the user. After that, the owner can identify the point of leakage with a small number of queries.
- We conduct extensive experiments and evaluate the proposed framework on different DL model architectures. The results show that KeyNet can successfully embed WMs with reliable detection accuracy while preserving the accuracy of the original task. Moreover, it yields a small number of false positives when tested with unmarked models.
2. Related Work
2.1. White-Box Watermarking
2.2. Black-Box Watermarking
3. Attack Model
- Model fine-tuning. In this attack, an attacker who has a small amount of the original data retrains the WM model with the aim of removing the WM while preserving the accuracy in the original task.
- Model compression. The compression of a DL model’s weights minimizes its size and speeds up its performance. Model compression may compromise the WM within the marked model, thereby affecting its detection and extraction.
- Watermark overwriting. This type of attack is a major threat to the WM because it might result in the attacker being able to overwrite the owner’s WM, or also to embed another WM of his own and thus seize ownership of the WM model. We make the following assumptions about the attacker. First, the attacker is assumed to have a small amount of training data when compared to the owner. Otherwise, he can use his data to train a new model from scratch, or use the predictions of the WM model to create an unmarked copy of it by predictive model-theft techniques [7]. Second, the attacker is assumed to be aware of the methodology used to embed the WM but to be unaware of the carrier set distribution, the owner’s signature, or the topology of the owner’s private model. An attack is considered to be successful if the attacker manages to overwrite the WM without losing much accuracy in the original task. The goal is to prevent the attacker from overwriting the WM without significantly impairing the original task accuracy, proportional to the amount of data he knows. To make a realistic trade-off, the relationship between the size of the data known by the attacker and the loss in original task accuracy should be inversely proportional: the smaller the attacker data, the greater the accuracy loss is.
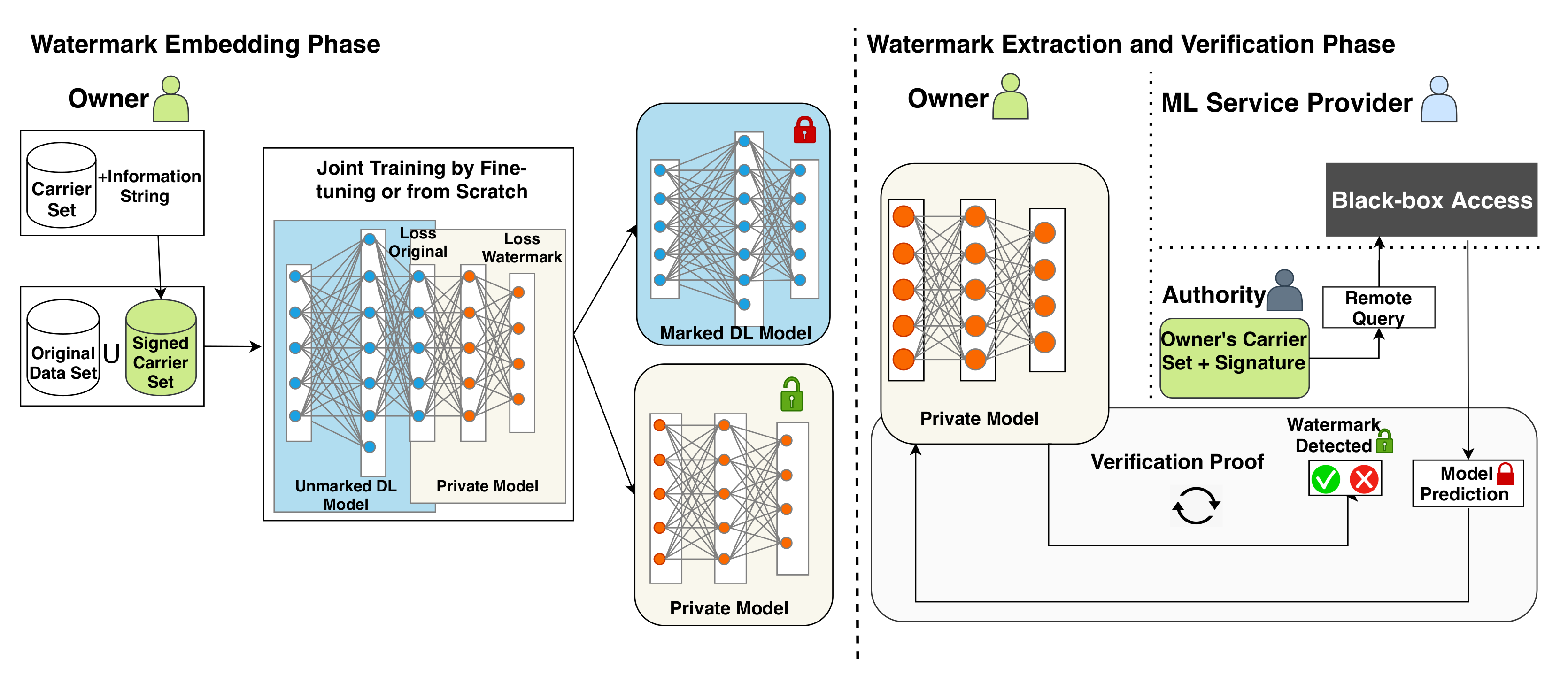
4. The KeyNet Framework
4.1. Problem Formulation
- Representation of the original, private, and combined models. Let be the original task data and be the WM carrier set data. Let h be the function of the original model and f be the function of the private model. Let the parameters of h and be the parameters of f. Let be the owner’s signature and be the set of predefined position–label pairs (e.g., position: top left, label: 1 and position: bottom right, label: 4) where z is the total number of positions at which the signature can be located on a WM carrier set sample. Let be the function that puts a on a carrier set sample c and returns the signed sample and its corresponding label as:Let be the signed carrier set samples that contain all the pairs. We use and to train both h and f to perform and .Typically, the function h tries to map each to its corresponding , that is, .Let be the composite function that aims at mapping each to its corresponding , that is, .
- Embedding phase. We formulate the embedding phase as an MTL problem where we jointly learn two tasks that share some parameters in the early layers and then have task-specific parameters in the later layers. The shared parameters in our case are , while are the WM task-specific parameters. We compute the weighted combined loss L aswhere represents the predictions on the original task samples, represents the predictions on samples, is the loss function that penalizes the difference between the original model outputs and the original data targets y, is the loss function that penalizes the difference between the composite model outputs and the signed WM carrier set’s target l, and is the combined weighted loss parameter. Then, we seek and that make L small enough to get acceptable accuracy on both and . Once this is done, the WM has been successfully embedded while preserving the accuracy of the original task .
- Verification phase. The verification function V checks whether a claimer (also known as the prover), who has delivered her and WM carrier set to the authority (also known as the verifier), is the legitimate owner of a remote model . If the prover is the legitimate owner of , he/she will be able to pass the verification process and thus prove her ownership of . That is, because he/she possesses the private model f, which was trained to decode predictions on her signed .Here, r represents the number of the required rounds in the verification process and T denotes the threshold needed to prove the ownership of . Note that the authority also knows the signing function used to sign samples in order to obtain pairs.The function V can be expressed as .
4.2. Watermark Carrier Set Signing and Labeling
- The owner’s information string that has been endorsed by the authority.
- The size of the signature s to be placed on the WM carrier set samples.
- The owner’s WM carrier set .
- The set of position–label pairs that defines the signature positions and their corresponding labels.
- A small set of samples from other distributions than .
| Algorithm 1 Signing a WM carrier Set |
Input: Owner’s information , owner’s signature size s, owner’s WM carrier set , signature positions/labels set , other distributions’ samples Output: signed labeled WM samples , signed samples from different distributions , owner’s signature
return
|
- We generate a fake information string by making a slight modification to . Then, we generate following steps similar to those above followed to generate the real owner’s signature . After that, we sign the samples each with a different fake signature and a randomly chosen position and, instead of assigning to the signed sample the corresponding label , we assign it the label 0. To obtain a new fake signature, we again make a slight random modification in and generate the fake signature in the same way as above.
- We take samples from other distributions and sign them with the real owner’s signature as we did with the samples. We assign them the label 0. We use samples from different distributions to avoid triggering the WM just with the owner’s real signature. In other words, we make the triggering of the WM from a marked model dependent on the carrier set distribution in addition to the pattern of the owner’s signature.
4.3. Watermark Embedding
| Algorithm 2 Watermark Embedding |
Input: Unmarked DL model h, private model f, original data set , signed WM carrier set , signed samples from other distributions , batch size , weighted loss parameter . Output: Marked model , corresponding private model f.
return , f |
4.4. Watermark Extraction and Verification
| Algorithm 3 Watermark Verification |
Input: Remote access to , threshold T, number of rounds r Output: Boolean decision d (True or False) on ’s ownership.
|
5. Experimental Results
5.1. Experimental Setup
5.2. Experiments and Results
- Model fine-tuning. Fine-tuning involves retraining a DL model with some amount of training data. It may remove or corrupt the WM information from a marked model because it causes the model to converge to another local minimum. In our experiments, we sampled of the original data and used them to fine-tune the marked model by optimizing its parameters based only the loss of the original task. Table 6 outlines the impact of fine-tuning on the WM detection accuracy with all benchmarks. We can notice that KeyNet is robust against fine-tuning and was able to preserve a WM detection accuracy of about after 200 epochs. The explanation for this strong persistence against fine-tuning is that KeyNet does not embed the WM information within the decision boundaries of the original task classes. Therefore, the effect of fine-tuning on the WM is very small.
- Model compression. We used the compression approach proposed in [47] to prune the weight parameters in the marked DL models. To prune a particular layer, we first sorted the weights in the specified layer by their magnitudes. Then, we masked to zero the smallest magnitude weights until the desired pruning level was reached. Figure 3 shows the impact of model compression on both WM detection accuracy and original task accuracy with different pruning rates. We see that KeyNet is robust against model compression, and the accuracy of the WM remains above the threshold as long as the marked model is still useful for the original task. This is consistent because when the marked model becomes useless due to excessive compression, the owner will not be interested in claiming its ownership.
- Watermark overwriting. Assuming that the attacker is aware of the methodology used to embed the WM, he may embed a new WM that may damage the original one. In our experiments, we assumed that the attacker knows the methodology but knows neither the owner’s carrier set nor the owner’s private model architecture. We studied the effect on the WM of the attacker’s knowing various fractions of the original training data, ranging from to . We chose the lower bound based on the work in [49]; the authors of that paper demonstrate that an attacker with less than of the original data is able to remove the watermark with a slight loss in the accuracy of the original task.
- We took a small set (say 6 samples) of the WM carrier set.
- We signed a copy of these samples in random places with User1’s joint signature; another copy was also signed in the same way for User2.
- We queried (the allegedly leaked model) with the samples signed by User1 to obtain their predictions. We did the same with User2 samples.
- We passed the predictions from samples signed with User1’s signature to her private model and calculated the accuracy at detecting the WM. We did the same with User2’s predictions and his private model.
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| DL | Deep learning |
| FMNIST5 | The samples that belong to the classes [0–4] in Fashion-MNIST data set. |
| IP | Intellectual property |
| MDPI | Multidisciplinary Digital Publishing Institute |
| ML | Machine learning |
| MLaaS | Machine learning as a service |
| MSE | Mean square error |
| MTL | Multi-task learning |
| SHA | Secure Hash Standard algorithm |
| SN | Serial number |
| WM | Watermark |
References
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A survey of deep learning and its applications: A new paradigm to machine learning. Arch. Comput. Methods Eng. 2019, 27, 1071–1092. [Google Scholar] [CrossRef]
- Adiwardana, D.; Luong, M.T.; So, D.R.; Hall, J.; Fiedel, N.; Thoppilan, R.; Yang, Z.; Kulshreshtha, A.; Nemade, G.; Lu, Y.; et al. Towards a human-like open-domain chatbot. arXiv 2020, arXiv:2001.09977. [Google Scholar]
- Ribeiro, M.; Grolinger, K.; Capretz, M.A. Mlaas: Machine learning as a service. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 896–902. [Google Scholar]
- Yao, Y.; Xiao, Z.; Wang, B.; Viswanath, B.; Zheng, H.; Zhao, B.Y. Complexity vs. performance: Empirical analysis of machine learning as a service. In Proceedings of the 2017 Internet Measurement Conference, London, UK, 1–3 November 2017; pp. 384–397. [Google Scholar]
- Tramèr, F.; Zhang, F.; Juels, A.; Reiter, M.K.; Ristenpart, T. Stealing machine learning models via prediction apis. In Proceedings of the 25th USENIX Security Symposium (USENIX Security 16), Austin, TX, USA, 10–12 August 2016; pp. 601–618. [Google Scholar]
- Wang, B.; Gong, N.Z. Stealing hyperparameters in machine learning. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 36–52. [Google Scholar]
- Hartung, F.; Kutter, M. Multimedia watermarking techniques. Proc. IEEE 1999, 87, 1079–1107. [Google Scholar] [CrossRef]
- Sebé, F.; Domingo-Ferrer, J.; Herrera, J. Spatial-domain image watermarking robust against compression, filtering, cropping, and scaling. In International Workshop on Information Security; Springer: Berlin/Heidelberg, Germany, 2000; pp. 44–53. [Google Scholar]
- Furht, B.; Kirovski, D. Multimedia Security Handbook; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- Lu, C.S. Multimedia Security: Steganography and Digital Watermarking Techniques for Protection of Intellectual Property: Steganography and Digital Watermarking Techniques for Protection of Intellectual Property; IGI Global: Hershey, PA, USA, 2004. [Google Scholar]
- Uchida, Y.; Nagai, Y.; Sakazawa, S.; Satoh, S. Embedding watermarks into deep neural networks. In Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval, Bucharest, Romania, 6–9 June 2017; pp. 269–277. [Google Scholar]
- Zhang, J.; Gu, Z.; Jang, J.; Wu, H.; Stoecklin, M.P.; Huang, H.; Molloy, I. Protecting intellectual property of deep neural networks with watermarking. In Proceedings of the 2018 on Asia Conference on Computer and Communications Security, Incheon, Korea, 4–8 June 2018; pp. 159–172. [Google Scholar]
- Adi, Y.; Baum, C.; Cisse, M.; Pinkas, B.; Keshet, J. Turning your weakness into a strength: Watermarking deep neural networks by backdooring. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 1615–1631. [Google Scholar]
- Chen, H.; Rouhani, B.D.; Fu, C.; Zhao, J.; Koushanfar, F. Deepmarks: A secure fingerprinting framework for digital rights management of deep learning models. In Proceedings of the 2019 International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 105–113. [Google Scholar]
- Le Merrer, E.; Perez, P.; Trédan, G. Adversarial frontier stitching for remote neural network watermarking. Neural Comput. Appl. 2020, 32, 9233–9244. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Wenger, E.; Zhao, B.Y.; Zheng, H. Piracy Resistant Watermarks for Deep Neural Networks. arXiv 2019, arXiv:1910.01226. [Google Scholar]
- Rouhani, B.D.; Chen, H.; Koushanfar, F. Deepsigns: A generic watermarking framework for ip protection of deep learning models. arXiv 2018, arXiv:1804.00750. [Google Scholar]
- Chen, H.; Rouhani, B.D.; Koushanfar, F. BlackMarks: Blackbox Multibit Watermarking for Deep Neural Networks. arXiv 2019, arXiv:1904.00344. [Google Scholar]
- Xu, X.; Li, Y.; Yuan, C. “Identity Bracelets” for Deep Neural Networks. IEEE Access 2020, 8, 102065–102074. [Google Scholar] [CrossRef]
- Boenisch, F. A Survey on Model Watermarking Neural Networks. arXiv 2020, arXiv:2009.12153. [Google Scholar]
- Wang, J.; Wu, H.; Zhang, X.; Yao, Y. Watermarking in deep neural networks via error back-propagation. Electron. Imaging 2020, 2020, 22-1–22-9. [Google Scholar] [CrossRef]
- Fan, L.; Ng, K.W.; Chan, C.S. Rethinking deep neural network ownership verification: Embedding passports to defeat ambiguity attacks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 4714–4723. [Google Scholar]
- Wang, T.; Kerschbaum, F. Robust and Undetectable White-Box Watermarks for Deep Neural Networks. arXiv 2019, arXiv:1910.14268. [Google Scholar]
- Guo, J.; Potkonjak, M. Watermarking deep neural networks for embedded systems. In Proceedings of the 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 5–8 November 2018; pp. 1–8. [Google Scholar]
- Hitaj, D.; Mancini, L.V. Have you stolen my model? evasion attacks against deep neural network watermarking techniques. arXiv 2018, arXiv:1809.00615. [Google Scholar]
- Li, Z.; Hu, C.; Zhang, Y.; Guo, S. How to prove your model belongs to you: A blind-watermark based framework to protect intellectual property of DNN. In Proceedings of the 35th Annual Computer Security Applications Conference, San Juan, Puerto Rico, 9–13 December 2019; pp. 126–137. [Google Scholar]
- Cao, X.; Jia, J.; Gong, N.Z. IPGuard: Protecting the Intellectual Property of Deep Neural Networks via Fingerprinting the Classification Boundary. arXiv 2019, arXiv:1910.12903. [Google Scholar]
- Wu, H.; Liu, G.; Yao, Y.; Zhang, X. Watermarking Neural Networks with Watermarked Images. IEEE Trans. Circuits Syst. Video Technol. 2020. [Google Scholar] [CrossRef]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Ruder, S. An overview of multi-task learning in deep neural networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Mrkšić, N.; Séaghdha, D.; Thomson, B.; Gašić, M.; Su, P.; Vandyke, D.; Wen, T.; Young, S. Multi-domain dialog state tracking using recurrent neural networks. In Proceedings of the ACL-IJCNLP 2015-53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 2, pp. 794–799. [Google Scholar]
- Li, S.; Liu, Z.Q.; Chan, A.B. Heterogeneous multi-task learning for human pose estimation with deep convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 482–489. [Google Scholar]
- Zhang, W.; Li, R.; Zeng, T.; Sun, Q.; Kumar, S.; Ye, J.; Ji, S. Deep model based transfer and multi-task learning for biological image analysis. IEEE Trans. Big Data 2016, 6, 322–333. [Google Scholar] [CrossRef]
- Neelakantan, A.; Vilnis, L.; Le, Q.V.; Sutskever, I.; Kaiser, L.; Kurach, K.; Martens, J. Adding gradient noise improves learning for very deep networks. arXiv 2015, arXiv:1511.06807. [Google Scholar]
- Ndirango, A.; Lee, T. Generalization in multitask deep neural classifiers: A statistical physics approach. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 15862–15871. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 22 January 2021).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- LeCun, Y. LeNet-5, Convolutional Neural Networks. Available online: http://yann.lecun.com/exdb/lenet (accessed on 22 January 2021).
- Coates, A.; Ng, A.; Lee, H. An Analysis of Single Layer Networks in Unsupervised Feature Learning. In Proceedings of the AISTATS 2011, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 215–223. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C.J.C. MNIST Handwritten Digit Database. 2010. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 22 January 2021).
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–11 December 2015; pp. 1135–1143. [Google Scholar]
- Shafieinejad, M.; Wang, J.; Lukas, N.; Li, X.; Kerschbaum, F. On the robustness of the backdoor-based watermarking in deep neural networks. arXiv 2019, arXiv:1906.07745. [Google Scholar]
- Aiken, W.; Kim, H.; Woo, S. Neural Network Laundering: Removing Black-Box Backdoor Watermarks from Deep Neural Networks. arXiv 2020, arXiv:2004.11368. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Requirement | Description |
|---|---|
| Fidelity | The accuracy of the marked model on the original task shall not be degraded as a result of watermark embedding. |
| Robustness | The watermark shall be robust against model modifications such as model fine-tuning, model compression or WM overwriting. |
| Reliability | Watermark extraction shall exhibit a minimal false negative rate to allow legitimate owners to detect the WM with high probability. |
| Integrity | Watermark extraction shall result in a minimal amount of false positives; unmarked models must not be falsely claimed. |
| Capacity | It must be possible to include a large amount of watermark information in the target model. |
| Security | The watermark must not leave a detectable footprint on the marked model; an unauthorized party must not be able to detect the existence of a WM. |
| Unforgeability | An attacker must not be able to claim ownership of another party’s watermark, or to embed additional watermarks into a marked model. |
| Authentication | A strong link between the owner and her watermark must be provided; reliable verification of the legitimate owner’s identity shall be guaranteed. |
| Generality | The watermarking methodology must be applicable to different DL architectures and data sets. |
| Efficiency | Embedding and extracting WMs shall not entail a large overhead. |
| Uniqueness | The watermarking methodology must be able to embed a unique watermark for each user in order to distinguish each distributed marked model individually. |
| Scalability | Unique watermarking must scale to many users. |
| Data Set | WM Carrier Set | DL Model | DL Model Architecture | Private Model Architecture |
|---|---|---|---|---|
| CIFAR10 | STL10 | ResNet18 VGG16 | See [40]. See [41]. | FC(10,20), FC(20,10), FC(10, 6) (496 learnable parameters) |
| FMNIST5 | MNIST | CNN | C(3,32,5,1,2), MP(2,1), C(32,64,3,1,2), MP(2,1), FC(4096,4096), FC(4096,5) | FC(5, 10), FC(10,20), FC(20,6) |
| LeNet | See [42]. | (411 learnable parameters) |
| Data Set | Owner’s WM Carrier Set | Attacker’s WM Carrier Set | Attacker’s Private Model Architecture |
|---|---|---|---|
| CIFAR10 | STL10 | Fashion-MNIST | FC(10,20),FC(20,30), FC(30, 6) (980 learnable parameters) |
| FMNIST5 | MNIST | STL10 | FC(5, 20), FC(20,10), FC(10,6) (360 learnable parameters) |
| Data Set | Black-Box DL Model | Watermark Detection Accuracy % |
|---|---|---|
| CIFAR10 | ResNet18 | 31.25 |
| VGG16 | 30.14 | |
| FMNIST5 | CNN | 34.42 |
| LeNet | 33.26 |
| Data Set | DL Model | Unmarked Model Accuracy % | Marked Model Accuracy % | Watermark Detection Accuracy % | ||
|---|---|---|---|---|---|---|
| By Fine-Tuning (30 Epochs) | From Scratch (250 Epochs) | By Fine-Tuning | From Scratch | |||
| CIFAR10 | ResNet18 | 91.96 | 92.07 | 92.53 | 99.96 | 99.97 |
| VGG16 | 90.59 | 90.52 | 91.74 | 99.68 | 99.89 | |
| FMNIST5 | CNN | 92.08 | 92.42 | 92.32 | 99.98 | 99.90 |
| LeNet | 90.68 | 89.94 | 89.94 | 99.55 | 99.79 | |
| Data Set | CIFAR10 | FMNIST5 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DL model | ResNet18 | VGG16 | CNN | LeNet | ||||||||
| Number of epochs | 50 | 100 | 200 | 50 | 100 | 200 | 50 | 100 | 200 | 50 | 100 | 200 |
| Marked model Accuracy % | 92.40 | 92.33 | 92.47 | 91.31 | 91.64 | 91.69 | 92.30 | 92.52 | 92.40 | 89.84 | 90.06 | 90.12 |
| Watermark detection Accuracy % | 98.19 | 98.05 | 99.12 | 97.20 | 94.72 | 96.67 | 97.35 | 97.02 | 96.92 | 98.23 | 97.42 | 96.4 |
| Dataset | CIFAR10 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DL Model | ResNet18 | VGG16 | ||||||||||
| Data fraction % | 1 | 3 | 6 | 10 | 20 | 30 | 1 | 3 | 6 | 10 | 20 | 30 |
| Marked model Accuracy before % | 92.53 | 92.53 | 92.53 | 92.53 | 92.53 | 92.53 | 91.74 | 91.74 | 91.74 | 91.74 | 91.74 | 91.74 |
| Marked model Accuracy after % | 39.05 | 63.75 | 83.31 | 86.35 | 89.91 | 90.9 | 34.61 | 71.86 | 81.2 | 83.9 | 88.07 | 89.67 |
| Owner’s WM detection Accuracy after % | 24.53 | 20.35 | 22.27 | 28.3 | 37.33 | 41.15 | 32.32 | 30.88 | 28.61 | 32.48 | 30.32 | 44.4 |
| Attacker’s WM detection Accuracy % | 99.97 | 99.89 | 99.95 | 99.9 | 99.94 | 99.97 | 99.69 | 99.68 | 99.89 | 99.87 | 99.9 | 99.96 |
| Dataset | FMNIST5 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DL Model | CNN | LeNet | ||||||||||
| Data fraction % | 1 | 3 | 6 | 10 | 20 | 30 | 1 | 3 | 6 | 10 | 20 | 30 |
| Marked model Accuracy before % | 92.32 | 92.32 | 92.32 | 92.32 | 92.32 | 92.32 | 89.94 | 89.94 | 89.94 | 89.94 | 89.94 | 89.94 |
| Marked model Accuracy after % | 76.18 | 81.88 | 87.86 | 89.1 | 91.38 | 91.84 | 74.64 | 79.44 | 86.36 | 88.86 | 89.58 | 89.52 |
| Owner’s WM detection Accuracy after % | 26.97 | 28.53 | 38.52 | 46.83 | 70 | 68.03 | 26.32 | 18.71 | 43.99 | 57.4 | 75.83 | 65.66 |
| Attacker’s WM detection Accuracy % | 100 | 100 | 100 | 100 | 100 | 100 | 99.25 | 99.65 | 99.84 | 99.92 | 99.89 | 99.92 |
| Dataset | DL Model | Watermark Detection Accuracy with Marked Models% | Watermark Detection Accuracy with Unmarked Models % | |||
|---|---|---|---|---|---|---|
| Same Topology | Accuracy | Different Topology | Accuracy | |||
| CIFAR10 | ResNet18 | 99.97% | ResNet18 | 18.92% | VGG16 | 19.80% |
| CIFAR10 | VGG16 | 99.89% | VGG16 | 7.92% | ResNet18 | 12.32% |
| FMNIST5 | CNN | 99.98% | CNN | 12.96% | LeNet | 10.97% |
| FMNIST5 | LeNet | 99.55% | LeNet | 17.93% | CNN | 17.75% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jebreel, N.M.; Domingo-Ferrer, J.; Sánchez, D.; Blanco-Justicia, A. KeyNet: An Asymmetric Key-Style Framework for Watermarking Deep Learning Models. Appl. Sci. 2021, 11, 999. https://doi.org/10.3390/app11030999
Jebreel NM, Domingo-Ferrer J, Sánchez D, Blanco-Justicia A. KeyNet: An Asymmetric Key-Style Framework for Watermarking Deep Learning Models. Applied Sciences. 2021; 11(3):999. https://doi.org/10.3390/app11030999
Chicago/Turabian StyleJebreel, Najeeb Moharram, Josep Domingo-Ferrer, David Sánchez, and Alberto Blanco-Justicia. 2021. "KeyNet: An Asymmetric Key-Style Framework for Watermarking Deep Learning Models" Applied Sciences 11, no. 3: 999. https://doi.org/10.3390/app11030999
APA StyleJebreel, N. M., Domingo-Ferrer, J., Sánchez, D., & Blanco-Justicia, A. (2021). KeyNet: An Asymmetric Key-Style Framework for Watermarking Deep Learning Models. Applied Sciences, 11(3), 999. https://doi.org/10.3390/app11030999