
A Multi-Channel Uncertainty-Aware Multi-Resolution Network for MR to CT Synthesis

 , , ,
, , ,  , and
, and
Abstract
1. Introduction
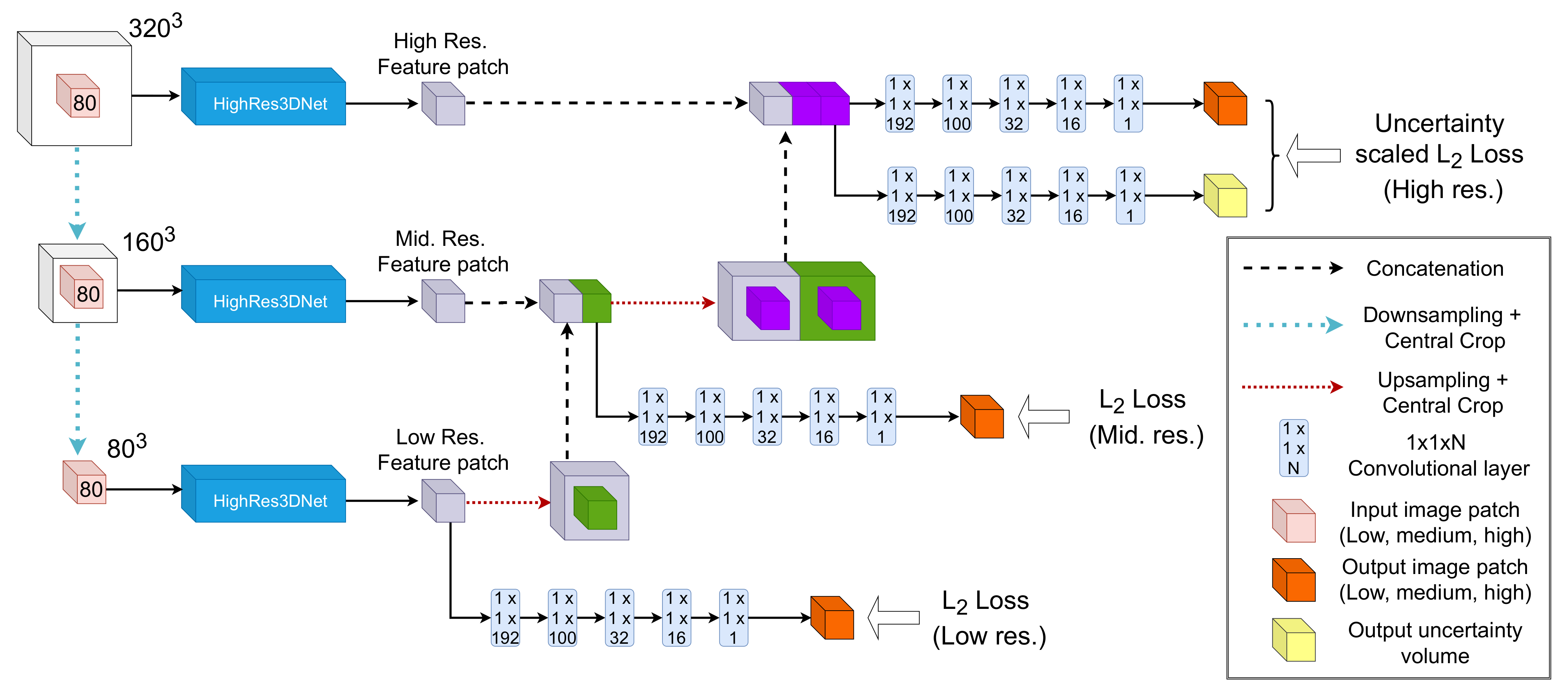
2. Methods
2.1. Modelling Heteroscedastic Uncertainty
2.2. Modelling Epistemic Uncertainty
2.3. Implementation Details
2.4. Data
2.5. Experiments
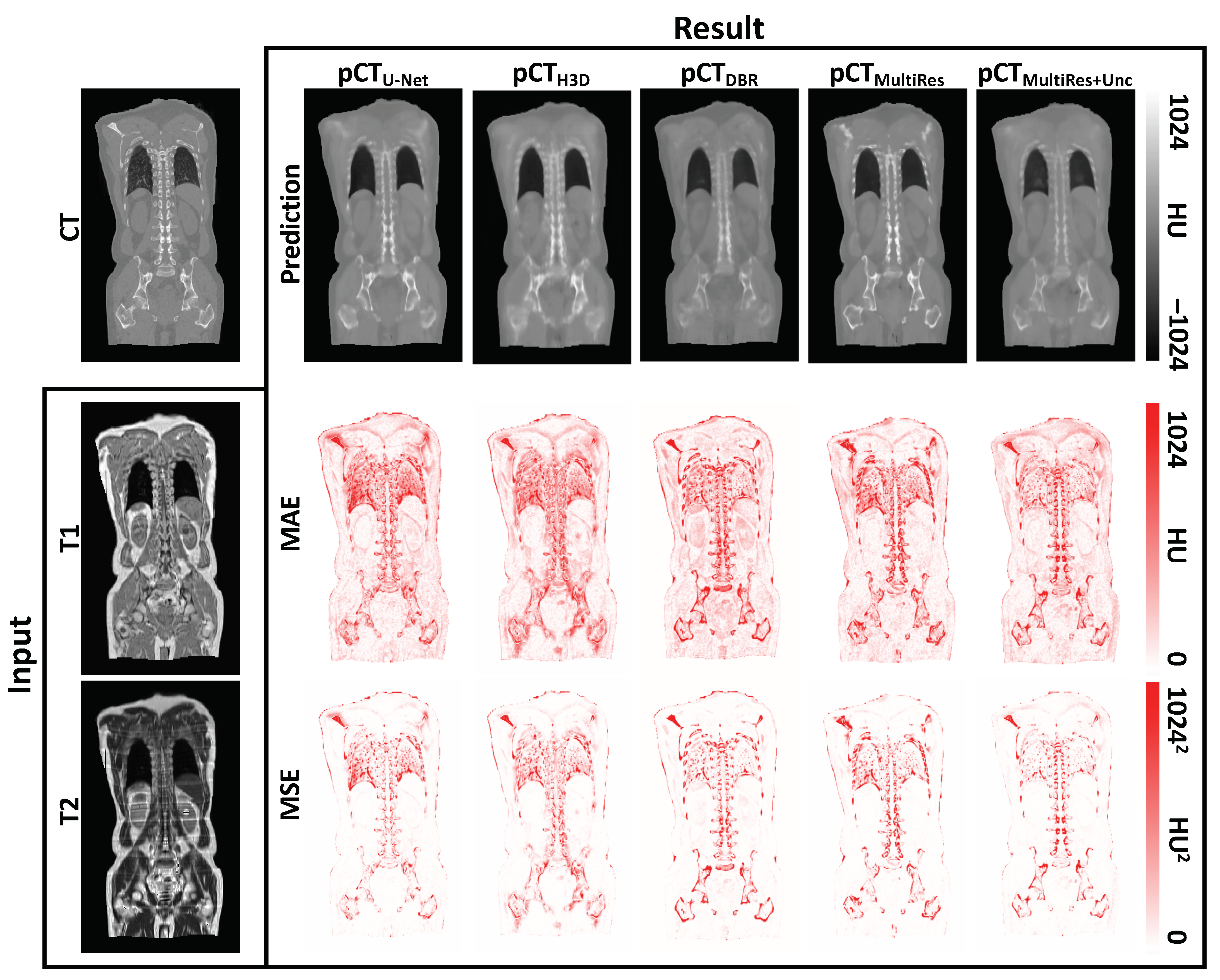
3. Results
3.1. Quantitative Evaluation
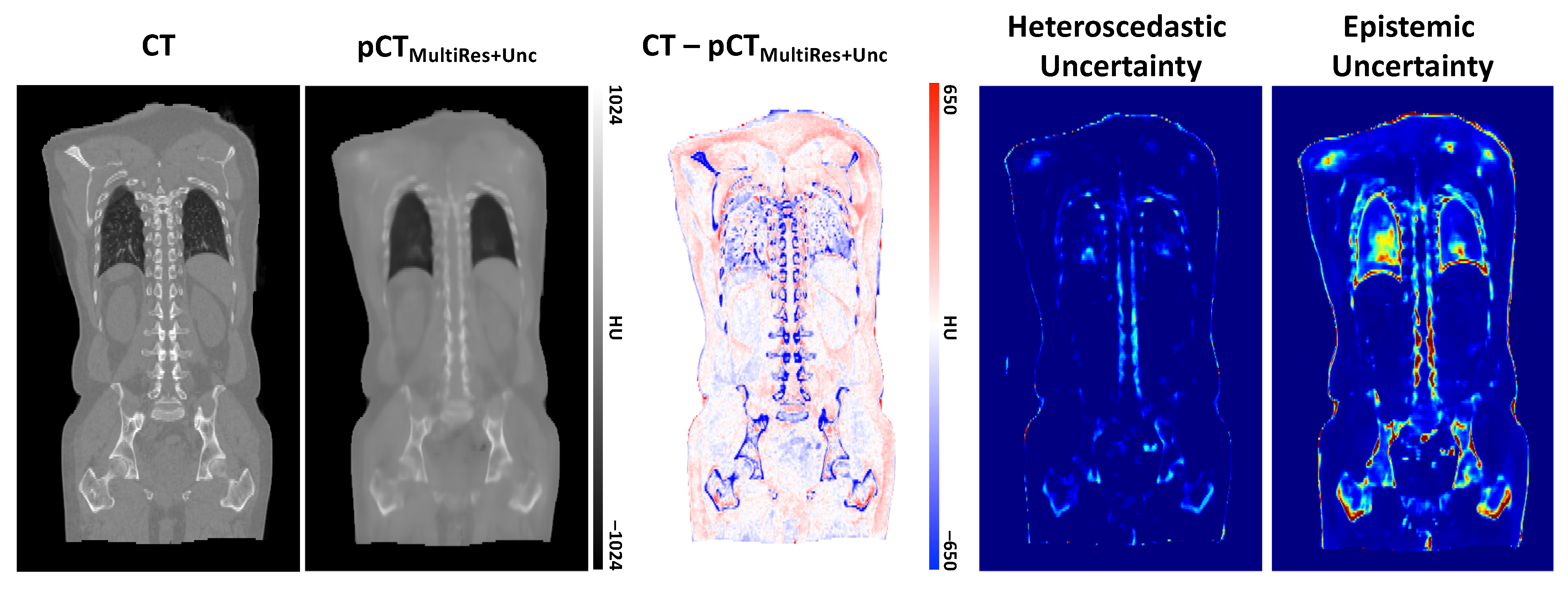
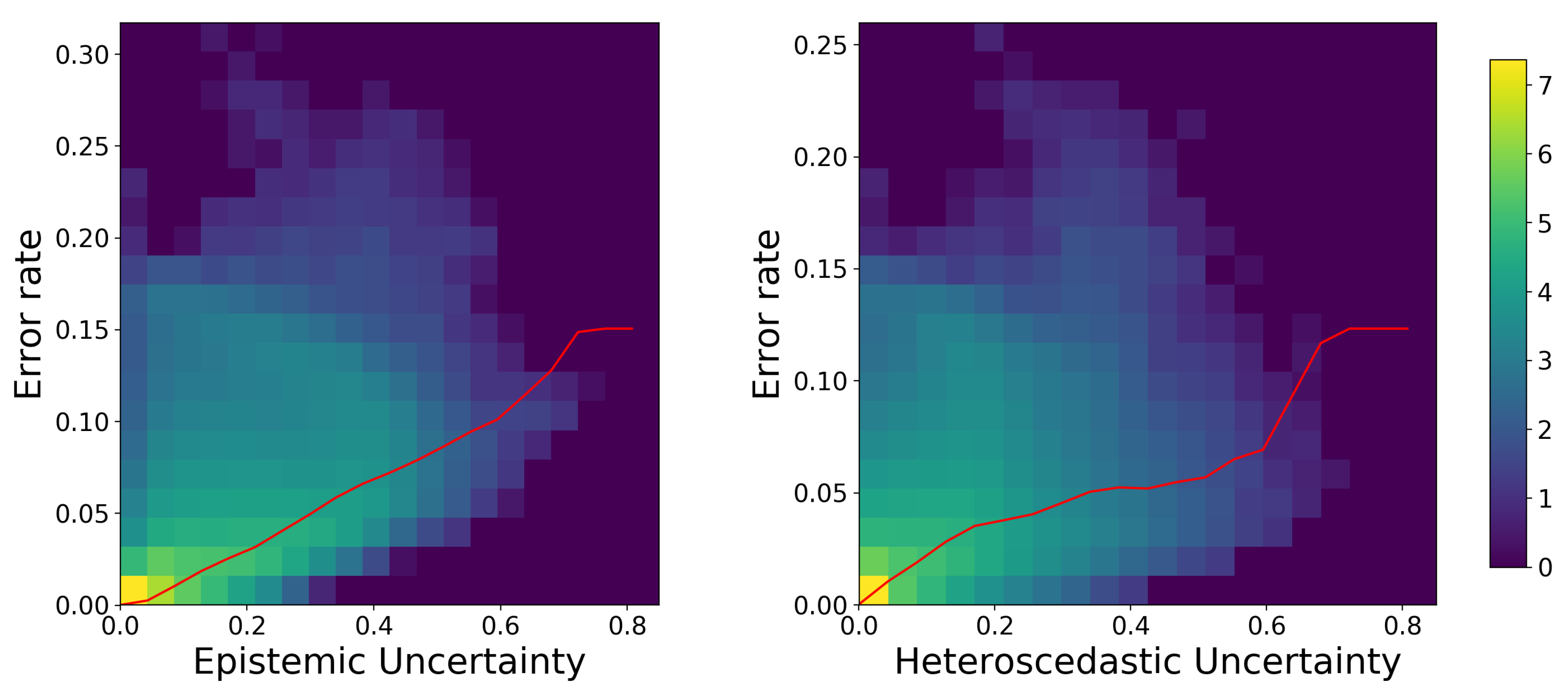
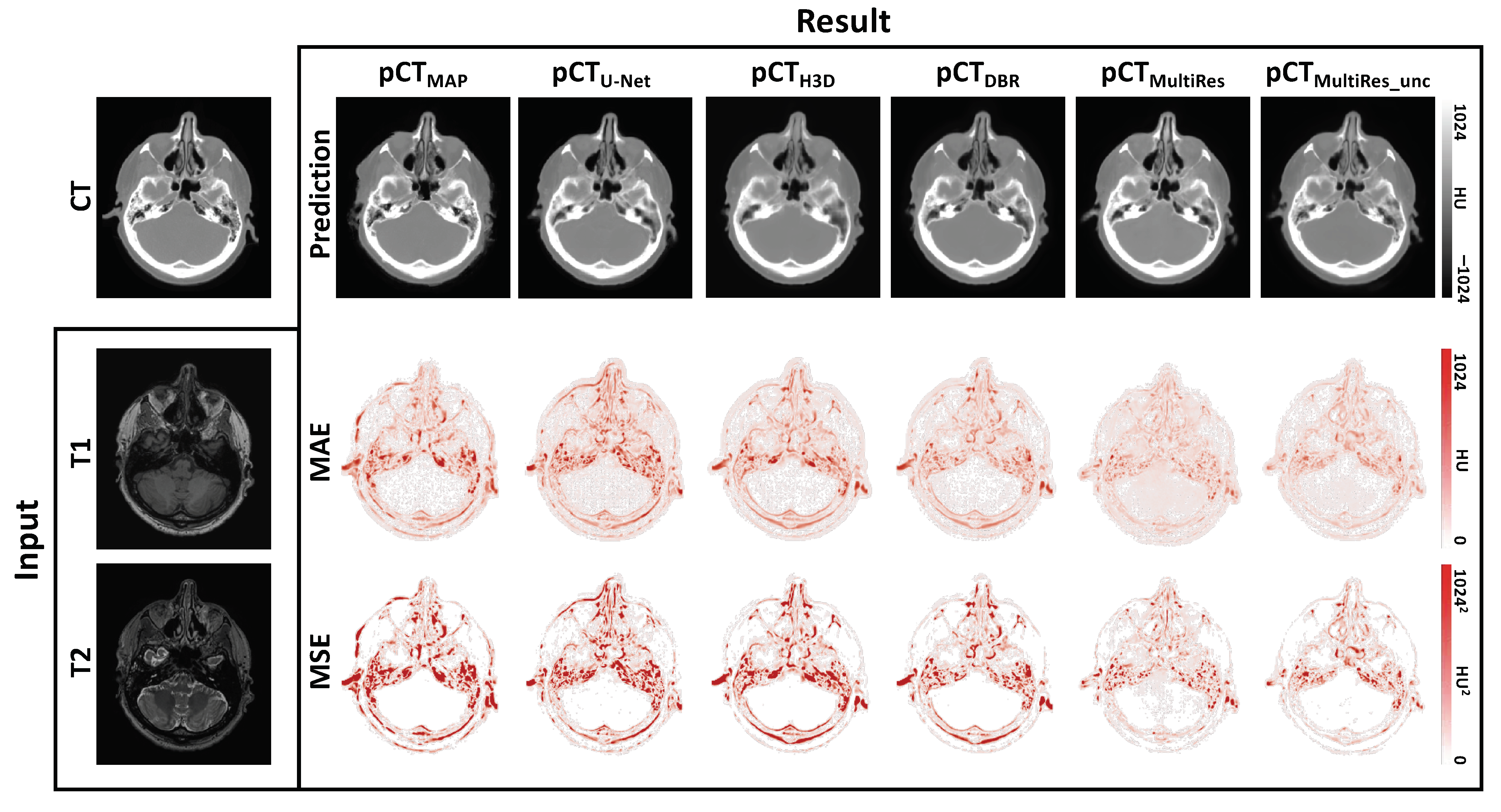
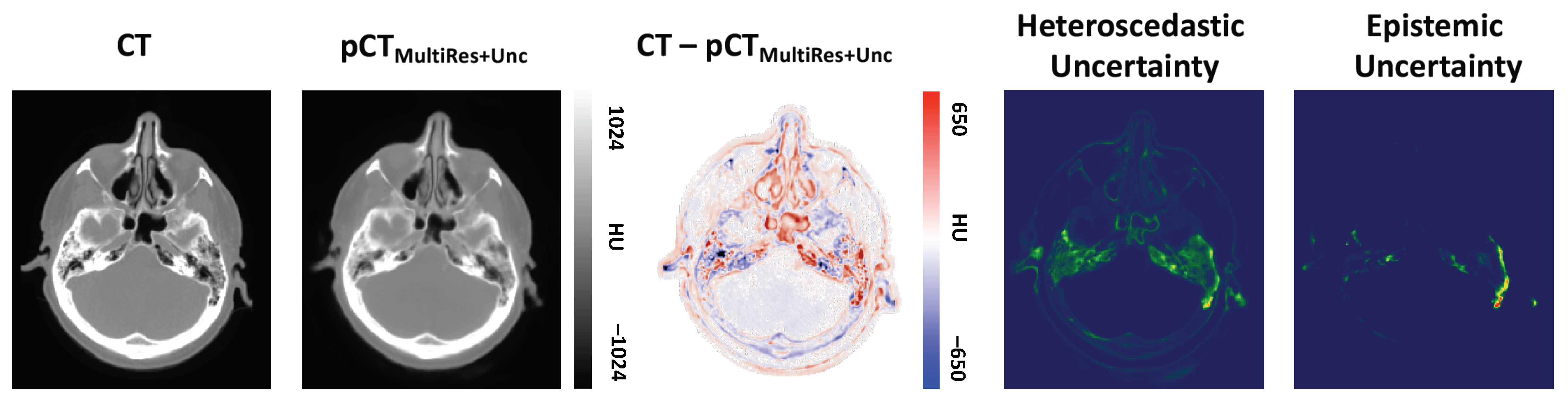
3.2. Qualitative Evaluation
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AC | Attenuation Correction |
| ADAM | Adaptive moment estimation |
| CNN | Convolutional neural network |
| CT | Computed Tomography |
| DBR | Deep Boosted Regression |
| HU | Hounsfield unit |
| MRI | Magnetic Resonance Imaging |
| PET | Positron Emission Tomography |
| MAE | Mean absolute error |
| MSE | Mean squared error |
| MultiRes | Multi-resolution network |
| MultiRes | Uncertainty aware multi-resolution network |
| -map | Attenuation map |
| pCT | pseudo CT |
| Spin-lattice relaxation time | |
| Spin-spin relaxation time |
References
- Ladefoged, C.N.; Law, I.; Anazodo, U.; Lawrence, K.S.; Izquierdo-Garcia, D.; Catana, C.; Burgos, N.; Cardoso, M.J.; Ourselin, S.; Hutton, B.; et al. A multi-centre evaluation of eleven clinically feasible brain PET/MRI attenuation correction techniques using a large cohort of patients. Neuroimage 2017, 147, 346–359. [Google Scholar] [CrossRef] [PubMed]
- Kläser, K.; Markiewicz, P.; Ranzini, M.; Li, W.; Modat, M.; Hutton, B.F.; Atkinson, D.; Thielemans, K.; Cardoso, M.J.; Ourselin, S. Deep boosted regression for MR to CT synthesis. In International Workshop on Simulation and Synthesis in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2018; pp. 61–70. [Google Scholar]
- Wolterink, J.M.; Dinkla, A.M.; Savenije, M.H.; Seevinck, P.R.; van den Berg, C.A.; Išgum, I. Deep MR to CT synthesis using unpaired data. In International Workshop on Simulation and Synthesis in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2017; pp. 14–23. [Google Scholar]
- Ge, Y.; Xue, Z.; Cao, T.; Liao, S. Unpaired whole-body MR to CT synthesis with correlation coefficient constrained adversarial learning. Med. Imaging Image Process. Int. Soc. Opt. Photonics 2019, 10949, 1094905. [Google Scholar]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. arXiv 2014, arXiv:1406.2283. [Google Scholar]
- Kawahara, J.; Hamarneh, G. Multi-resolution-tract CNN with hybrid pretrained and skin-lesion trained layers. In International Workshop on Machine Learning in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2016; pp. 164–171. [Google Scholar]
- Zamzmi, G.; Rajaraman, S.; Antani, S. Accelerating Super-Resolution and Visual Task Analysis in Medical Images. Appl. Sci. 2020, 10, 4282. [Google Scholar] [CrossRef]
- Kamnitsas, K.; Ledig, C.; Newcombe, V.F.; Simpson, J.P.; Kane, A.D.; Menon, D.K.; Rueckert, D.; Glocker, B. Efficient multi-scale 3D CNN with fully connected CRF for accurate brain lesion segmentation. Med. Image Anal. 2017, 36, 61–78. [Google Scholar] [CrossRef] [PubMed]
- Bragman, F.J.; Tanno, R.; Eaton-Rosen, Z.; Li, W.; Hawkes, D.J.; Ourselin, S.; Alexander, D.C.; McClelland, J.R.; Cardoso, M.J. Uncertainty in multitask learning: Joint representations for probabilistic MR-only radiotherapy planning. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Nair, T.; Precup, D.; Arnold, D.L.; Arbel, T. Exploring uncertainty measures in deep networks for multiple sclerosis lesion detection and segmentation. Med. Image Anal. 2020, 59, 101557. [Google Scholar] [CrossRef] [PubMed]
- Tanno, R.; Worrall, D.; Kaden, E.; Ghosh, A.; Grussu, F.; Bizzi, A.; Sotiropoulos, S.N.; Criminisi, A.; Alexander, D.C. Uncertainty quantification in deep learning for safer neuroimage enhancement. arXiv 2019, arXiv:1907.13418. [Google Scholar]
- Der Kiureghian, A.; Ditlevsen, O. Aleatory or epistemic? Does it matter? Struct. Saf. 2009, 31, 105–112. [Google Scholar] [CrossRef]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? arXiv 2017, arXiv:1703.04977. [Google Scholar]
- Reinhold, J.C.; He, Y.; Han, S.; Chen, Y.; Gao, D.; Lee, J.; Prince, J.L.; Carass, A. Validating uncertainty in medical image translation. In Proceedings of the IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 4 April 2020; pp. 95–98. [Google Scholar]
- Kläser, K.; Borges, P.; Shaw, R.; Ranzini, M.; Modat, M.; Atkinson, D.; Thielemans, K.; Hutton, B.; Goh, V.; Cook, G.; et al. Uncertainty-Aware Multi-resolution Whole-Body MR to CT Synthesis. In International Workshop on Simulation and Synthesis in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2020; pp. 110–119. [Google Scholar]
- Çiçek, Ö. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2016; pp. 424–432. [Google Scholar]
- Hou, S.; Wang, Z. Weighted channel dropout for regularization of deep convolutional neural network. Proc. AAAI Conf. Artif. Intell. 2019, 33, 8425–8432. [Google Scholar] [CrossRef]
- Li, W.; Wang, G.; Fidon, L.; Ourselin, S.; Cardoso, M.J.; Vercauteren, T. On the compactness, efficiency, and representation of 3D convolutional networks: Brain parcellation as a pretext task. In International Conference on Information Processing in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2017; pp. 348–360. [Google Scholar]
- Gibson, E.; Li, W.; Sudre, C.; Fidon, L.; Shakir, D.I.; Wang, G.; Eaton-Rosen, Z.; Gray, R.; Doel, T.; Hu, Y.; et al. NiftyNet: A deep-learning platform for medical imaging. Comput. Methods Programs Biomed. 2018, 158, 113–122. [Google Scholar] [CrossRef]
- Burgos, N.; Cardoso, M.J.; Thielemans, K.; Modat, M.; Pedemonte, S.; Dickson, J.; Barnes, A.; Ahmed, R.; Mahoney, C.J.; Schott, J.M.; et al. Attenuation correction synthesis for hybrid PET-MR scanners: Application to brain studies. IEEE Trans. Med. Imaging 2014, 33, 2332–2341. [Google Scholar] [CrossRef]
- Modat, M.; Ridgway, G.R.; Taylor, Z.A.; Lehmann, M.; Barnes, J.; Hawkes, D.J.; Fox, N.C.; Ourselin, S. Fast free-form deformation using graphics processing units. Comput. Methods Programs Biomed. 2010, 98, 278–284. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiments | Model Parameters | MAE (HU) | MSE (HU) |
|---|---|---|---|
| 3D U-Net | 14.49M | 92.89 ± 13.30 | 37,358.07 ± 11,266.56 |
| HighRes3DNet | 0.81M | 89.05 ± 8.77 | 23,346.09 ± 3828.22 |
| DBR | 1.62M | 77.58 ± 3.20 | 19,026.56 ± 2779.69 |
| MultiRes | 2.54M | 72.87 ± 2.33 | 18,532.23 ± 1538.41 |
| MultiRes | 2.61M | 73.90 ± 6.24 | 16,007.56 ± 2164.76 |
| Experiments | Model Parameters | MAE (HU) | MSE (HU) |
|---|---|---|---|
| Multi-Atlas | N/A | 132.15 ± 68.89 | 75,364.30.07 ± 62,627.20 |
| 3D U-Net | 14.49M | 86.18 ± 9.95 | 21,624.78 ± 6095.86 |
| HighRes3DNet | 0.81M | 70.52 ± 10.80 | 19,876.87 ± 5804.39 |
| DBR | 1.62M | 65.21 ± 13.01 | 17,308.84 ± 6923.93 |
| MultiRes | 2.54M | 57.52 ± 17.79 | 9611.25 ± 6251.68 |
| MultiRes | 2.61M | 57.01 ± 17.96 | 7291.80 ± 2857.76 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Klaser, K.; Borges, P.; Shaw, R.; Ranzini, M.; Modat, M.; Atkinson, D.; Thielemans, K.; Hutton, B.; Goh, V.; Cook, G.; et al. A Multi-Channel Uncertainty-Aware Multi-Resolution Network for MR to CT Synthesis. Appl. Sci. 2021, 11, 1667. https://doi.org/10.3390/app11041667
Klaser K, Borges P, Shaw R, Ranzini M, Modat M, Atkinson D, Thielemans K, Hutton B, Goh V, Cook G, et al. A Multi-Channel Uncertainty-Aware Multi-Resolution Network for MR to CT Synthesis. Applied Sciences. 2021; 11(4):1667. https://doi.org/10.3390/app11041667
Chicago/Turabian StyleKlaser, Kerstin, Pedro Borges, Richard Shaw, Marta Ranzini, Marc Modat, David Atkinson, Kris Thielemans, Brian Hutton, Vicky Goh, Gary Cook, and et al. 2021. "A Multi-Channel Uncertainty-Aware Multi-Resolution Network for MR to CT Synthesis" Applied Sciences 11, no. 4: 1667. https://doi.org/10.3390/app11041667
APA StyleKlaser, K., Borges, P., Shaw, R., Ranzini, M., Modat, M., Atkinson, D., Thielemans, K., Hutton, B., Goh, V., Cook, G., Cardoso, J., & Ourselin, S. (2021). A Multi-Channel Uncertainty-Aware Multi-Resolution Network for MR to CT Synthesis. Applied Sciences, 11(4), 1667. https://doi.org/10.3390/app11041667