1. Introduction
Models represent concepts by capturing the ideas, observations, notions, theories, insights, and intents that people conceive of and wish to express and communicate to others [
1]. A Conceptual model uses the syntax and semantics of a modeling language to describe concepts. A popular example for concept modeling depicts Isaac Newton’s observation and conception of gravity in the falling of an apple from a tree, and the ensuing formulation of Newton’s Theory of Gravity. Models represent scientific concepts, as projections of theories on phenomena; they describe and abstract phenomena, while relying on theories that may be hypothetical or partially validated [
2]. Likewise, models represent engineered, man-made systems in their current or future state [
3].
Models also inform concepts: we can enrich our concept, perception, and subject matter understanding by capturing, manipulating, contextualizing, composing, and analyzing modeled concepts and aspects. Conceptual models play a central and growingly more critical role in complex systems engineering, development and operation. Models are supposed to capture and represent various relations and interactions, which are fundamental for comprehending solutions, designs, or operational processes. Models are also important for facilitating stakeholder communication and discussion. The concept–model duo is therefore a binary self-enhancing system.
Model-Based systems engineering (MBSE) is the formalized application of models in systems engineering [
4]. MBSE facilitates the digital transformation of systems engineering: generating and communicating digitally-encoded and interchangeable systems engineering deliverables up and down the value chain [
5]. Digital systems engineering (DSE) increases the dependency on MBSE, which gradually evolves from a model-focused practice to a value-focused approach and to a critical asset for systems engineering in digital enterprises [
6,
7,
8,
9].
Generating stakeholder value out of model-based platforms is a primary expected outcome of DSE. Transforming system models into analyzable and reusable artifacts, decision-supporting information, and machine-generated insight is therefore a critical contribution to enterprise-wide DSE. A DSE ecosystem architecture defined in [
10] specifies modeling, infrastructure, data services, simulation, testing, analysis, and repositories (MIDSTAR
1) as primary DSE services. Management tools, interoperability services, digital representations, systems, things, auditing, and reporting services (MIDSTAR
2) are regarded as primary interfaces. We shall refer collectively to such results or artifacts following model processing or analysis as
views of those models.
Model-based views abstract, highlight, or pivot specific aspects, and become increasingly more important as models grow bigger and more complicated. Observing, reasoning about, processing, analyzing, and deciding according to such views results in ongoing concept revisions [
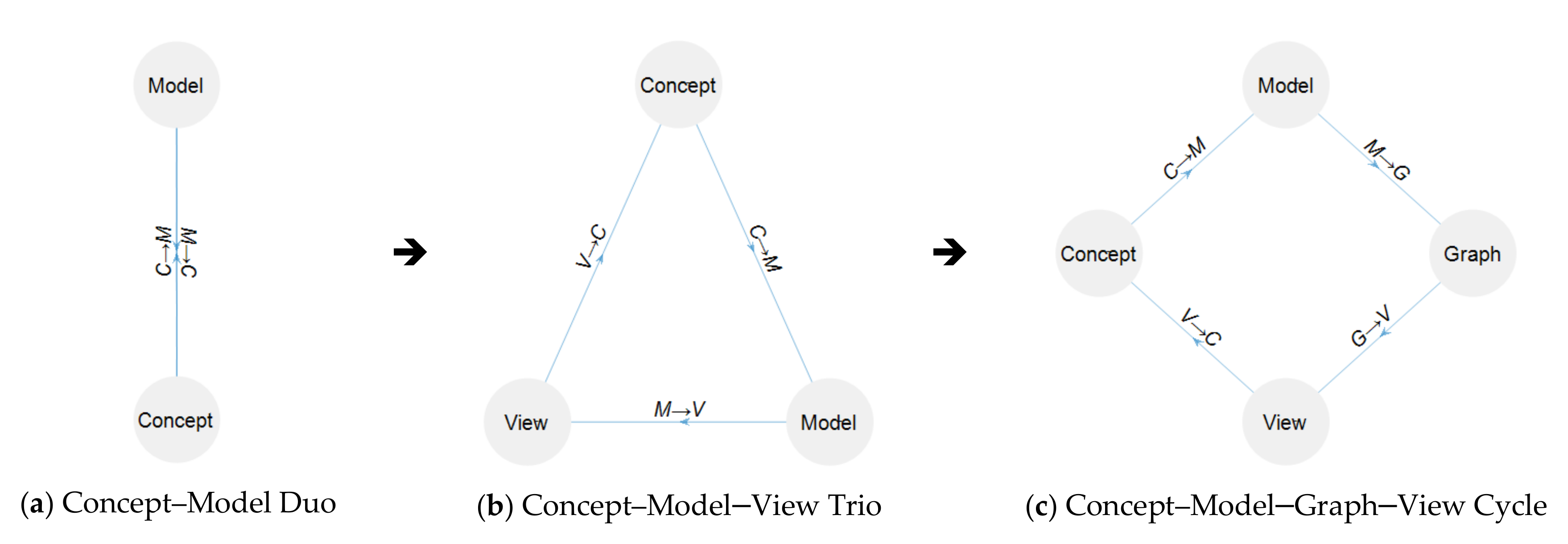
11]. The self-enhancing concept–model–view triangular cycle extends the concept–model duo. However, the potential combination of modeling languages (MLs), models, and views explodes: if every model were to be represented by every necessary view, the number of mappings would be a product of the number of models
by the number of views
, i.e.,
.
In the absence of dynamic and robust model-to-view transforms, concept understanding is shaped by ML-bound views. A generic representation (GR) across a wide variety of models that MLs could map into, and views could map out of, can make a difference. Graph data structures (GDS) can serve as GRs [
12,
13,
14,
15]. A GDS is simple, robust, scalable, and amenable to both relational and graph-theoretic algorithms. Graph and GDS are not completely interchangeable concepts: A graph is a visual representation of a subset of the GDS, and a GDS is a logical data structure that represents relations, which can be illustrated in graphs. Nevertheless, the term
graph is used for brevity and intuition for the GDS. A graph rendition of any portion of a GDS, whether raw or processed, is indeed a view of the model. A robust transformation of models into GDS, and generation of views from GDS, shall make models and views interoperable and interchangeable, and extend the collection of views that support model analysis. A concept–model–graph–view quadratic cycle is potentially a more effective, extensive, and efficient cognitive–computational concept modeling and analysis process than the concept–model–view trio. The evolution from the concept–model duo through concept–model–view trio to concept–model–graph–view cycle (CMVGVC) is illustrated in
Figure 1.
Matrices are useful views of models. Matrices facilitate analyzing quantitative and qualitative relations. A matrix is a bidimensional discrete data structure that lends itself to various mathematical or logical analyses. Matrices are common, intuitive, and easy to work with for scientists, engineers, and analysts. As graphic MLs evolved, matrices had not found a place as formal representation modalities, although matrix-like structures or layouts remained present to some extent in modeling frameworks. The IDEF0 notation advocates a diagonal layout of blocks that resembles the N
2 matrix of inter-component dependencies [
16]. UML Activity Diagrams assume a “swimlane” layout that helps divide complex multi-participant activities with columns. Sequence Diagrams apply a similar idea, using vertically-aligned lifelines as anchors for input and output exchange steps [
17].
Simple matrices are two-dimensional and non-hierarchical. This construct is insufficient for describing complex architectures. Requirements or structural elements are leaves in an asymmetric hierarchy, which may differ in depth and detail level. Therefore, the matrix kernel must be integrated with hierarchical representations of row and column entities. Advanced matrix representations for systems engineering include the Verification Cross-Reference Matrix (VCRM), Design Structure Matrix (DSM), and System Architecture Matrix (SAM). The Department of Defense Architecture Framework (DoDAF) advocates the use of matrices in some of its views [
18].
We collectively refer to advanced purpose-driven matrices as described above as Stakeholder-Informing Matrices (SIMs). A SIM is any matrix, matrix-like, or matrix-based data representation, whose purpose is to inform stakeholders, decision-makers, analysts, and other readers, to help them reason, make better decisions, and take informed action. SIMs organize, summarize, and contextualize information that may be scattered across multiple models or sections of models.
Various attempts to represent models with SIMs were mostly model-, aspect-, language-, or visualization-specific (see
Section 2.3). A mathematically sound and robust framework for transforming models to views is needed. In fact, since models are instantiations of MLs, and modeling consists of instantiations of ML patterns, we ought to transform the ML’s set of patterns into a superset of representable data structures, rather than a specific model into a specific view.
This paper defines the CMGVC and introduces the cognitive and computational transforms it includes. Our framework relies on Category Theory [
19]. A mathematical category consists of objects and morphisms. An object represents a type, and a morphism is a mapping between types. The Curry–Howard–Lambek Correspondence states that categories, theories, and programming languages are equivalent, and that writing a software program is like defining a category and like proving a theory [
20,
21]. The observation that software programming is like theory-building and the importance of explicit encoding of the underlying knowledge and concept as part of the software program, rather than as implicit in the designer’s mind was discussed by Naur [
22].
The categorical equivalence of programs, concepts, and theories has inspired us to assert that modeling languages are categories, and that mappings within and between modeling categories are powerful means of robust model transformations for various applications. This assertion substantiates a formal, holistic approach for perceiving and implementing concept transformations, particularly in complex systems. Such an approach is instrumental for reasoning about complex concepts using the reasoning mechanisms of people’s choice, rather than the representation mechanisms originally used for capturing those concepts. In complex systems, this idea of concept representation interchangeability is critical for a paradigm shift, cohesion of modeling and reasoning practices, and enabling digital systems engineering [
10].
This paper advances the state of the art in several ways: (a) asserting and proving that modeling languages are categories; (b) augmenting the emerging model-based systems engineering paradigm with robust foundations using Category Theory, rather than supplanting such system representation and analysis approaches with categorical or otherwise-algebraic representations; (c) offering a holistic systems perspective over the entire life cycle, metamorphosis, and evolution of the concept, from its inception, through modeling, generic representation, and informative rendering; (d) providing mathematical evidence that this approach is superior to both direct and language-bound mappings, (e) synergistically integrating and fusing category theory, graph theory, modeling theory, systems theory, and informatics to facilitate a multi-faceted pipeline of representations, transformations, and visualizations, which is a critical building-block for the digital engineering paradigm; and (f) providing a concrete example for a concept transformation cycle that renders conceptual models built with Object–process Methodology (OPM) as graph data structures, and graph data structures as stakeholder-informing matrices, in a significantly more structured and robust manner, which allows for both additional visualization of OPM models and matrix visualization of graphs of other MLs.
The rest of this paper is organized as follows: we review related work, relevant MLs, Graph Theory, and Category Theory in
Section 2. We describe the methods to conduct the CMGVC in
Section 3. We briefly describe the software implementation of the framework in
Section 4. We assess the framework in
Section 5. We demonstrate our method in
Section 6, and discuss the results in
Section 7. Conclusions, and potential, ongoing, and future research appear in
Section 8.
3. Methods
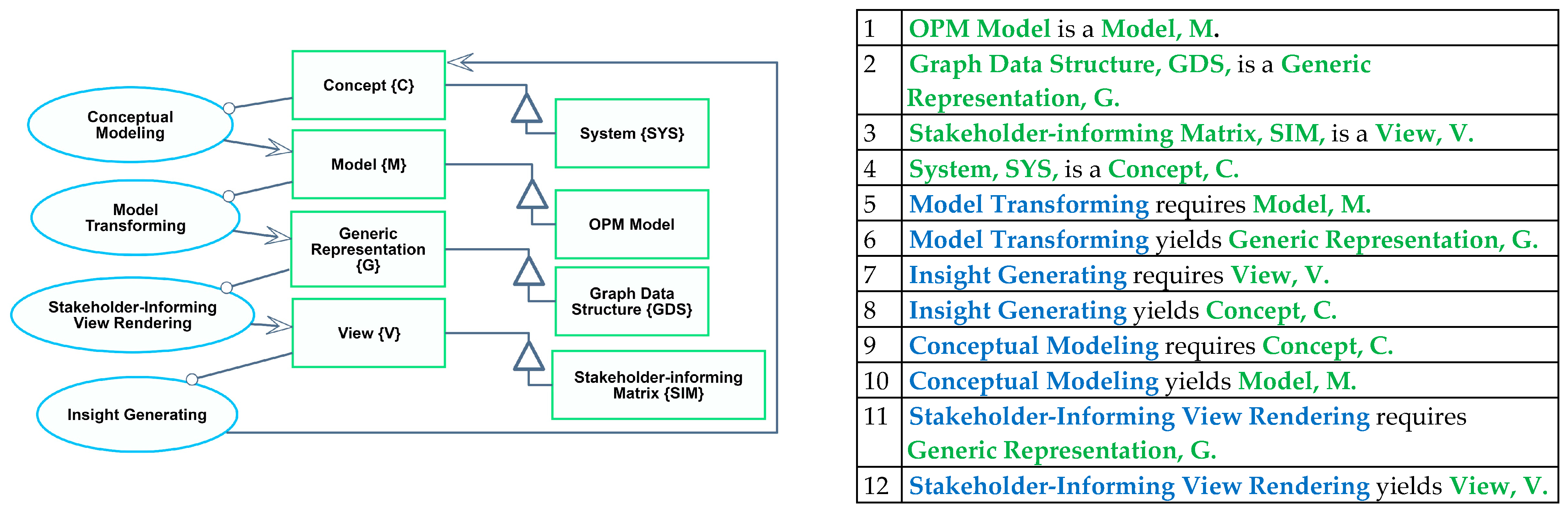
We describe a category-theoretic framework and methods for architecting and executing the CMGVC, which consists of four processes: (a) Conceptual Modeling: the transformation of concepts to models; (b) Model Transforming: converting models into generic, language-agnostic artifacts; (c) Stakeholder-Informing View Rendering: transforming generic representations into visualizations or representations; and (d) Reasoning, the cognitive process of rationalizing, understanding, perceiving, deciding, and revising the concept. This process is specified using an OPM model and illustrated in
Figure 5.
The framework defines mappings between the conceptual and computational phases of the CMGVC: the concept phase (
Section 3.1), the model phase (
Section 3.2), the generic representation phase (
Section 3.3), the view phase (
Section 3.4), and the iteration (
Section 3.5). While the CMGVC is universal, we focus on conceptual system architectures as an instance of C, on the OPM modeling language (M), on graph data structures as a global representation (G), and on stakeholder-informing matrices as views (V). This specialization is also shown in
Figure 5.
We present a series of propositions regarding the possibility, validity, and superiority of creating views from models through a robust mechanism. Our main assertion in Proposition 1 is that a transform from any model M to any view V through an intermediate GDS representation G is superior to a set of direct transformations from all models M1, …, MM, to all views V1, …, VV.
Proposition 1: GDS-based transform is superior to direct transforms. A graph-mediated transform M→G→V is superior to direct model-to-view transforms M→V:.
Proposition 2 asserts that a transform from any model M to any view V through an intermediate GDS representation G is also superior to a transform from all models through an ML-bound generic representation GR to all views .
Proposition 2: GDS-based transform is superior to language-specific transform. A graph-mediated transformation M→G→V is superior to an ML-bound mediating representation-based transformation MRV:.
MGV is a composition of M→G and G→V. Proposition 3 asserts that a transform M→G exists. Proposition 4 asserts that a transform G→V exists.
Proposition 3: A model-to-GDS transform exists. Let ML be a modeling language and M a model in ML. There exists a formal, valid, and feasible model-to-graph transform MG:ML→GDS.
Proposition 4: A GDS-to-view transform exists. Let V be a view and G a set of GDS tuples. There exists a formal, valid, and feasible graph-to-view transform GV: GDS→V.
Specifically focusing on SIMs, Proposition 5 asserts that SIMs are valid views of GDS.
Proposition 5. A GDS-to-SIM transform exists. Let SIM be a stakeholder-informing view and G a set of GDS tuples. There exists a formal, valid, and feasible graph-to-SIM transform GV: GDS→SIM.
3.1. The Conceptual System Architecture as a Category
Wymore’s definition of
systems [
44], in conjunction with the conventional representation of system architecture as a combination of structure and behavior [
3], gives rise to a System category,
, with the following types: Structure, Input–Output (or interchangeably, Onput [
81]), Resource, and State. Onputs and Resources can be referred to as Operands. The morphisms include Behaviors (which transform Operands) and Relations (which map types to themselves and to each other). A morphism
is a behavior of the system at any level, which transforms a combination (denoted as a Cartesian product) of operands (
) and the system’s state (
) to another combination of operands and state. The morphism
is a composition of input→state and state→output:
A system is an instantiation of the category . Wymore’s system morphism is a functor that maps a category to itself, or endofunctor, denoted as .
Cyber-physical systems (CPS) reside concurrently in the physical and cybernetic spaces, and constitute a primary concern of systems engineering. In our categorization, CPS behaviors/functions are morphisms, and system components (sensors, processors, actuators, etc.) and operands (Currency, Data, Energy, and Matter—CDEM) are types. CPS components carry out functions that convert input operands to output operands. Some examples are shown in
Table 3. CPS functions can be composed to create higher-level functionalities, for example, sensing, then actuating:
. We can also define functions as Cartesian products, e.g., a plant’s function is:
Input data (e.g., commands), matter (e.g., raw material), and energy (e.g., electrical power) are converted to output data (statuses, reports), matter (finished goods, byproducts), and energy (heat). Some sequences may not be valid within particular system domains. For instance, in logistics, manufacturing a device (an actuator or sensor) is possible, but in an operational system such as an aircraft or autonomous vehicles, manufacturing a new part may not make sense. On the other hand, sensor “manufacturing” of images from signals may be valid.
Our categorical formulation views systems as behavior-enabling structures, which affect operands. Operands are also types. In fact, a system can be an operand, and an operand can be a system. Imagine a vehicle exiting the production line as an operand, and emerging as a system, or software delivered as a file, i.e., as an operand, and emerging as an executable, i.e., a system.
Conceptual architecting usually specifies the function before the form, while physical architecting typically does the opposite. Attributing a functional–behavioral morphism to a structural entity implies or entails a relational morphism that assigns a function to a function-performing system component, and a dual that allocates a component to perform a function. This mapping of morphism to type and type to morphism implies a type–morphism duality of system behavior.
3.2. The Modeling Language as a Category
Modeling languages are categories, since they are essentially programming languages [
82], and programming languages are categories [
20,
21]. Moreover, programs are equivalent to theories [
22], and likewise, models are equivalent to system concepts, which can be thought of as ‘theories’ about how a system works or might work. System models are instantiations of MLs, much like software programs are instantiations of programming languages. Similarly, representation languages for creating graphs, matrices, trees, or animations may also be thought of as categories. Transitions across representations are essential for gaining system understanding, and for implementing the system or parts of the system. For example, transforming functional models into visual animations, hardware and software designs, text specifications, etc. may further explain the system.
The assertion that MLs are categories must be backed up by valid categorical representation. MLs like OPM and SysML [
83] capture structural, behavioral, and relational entities syntactically. The concept set constitutes a syntactic domain-agnostic ontology that accommodates a wide range of instantiations. The
Block, for instance, is a fundamental SysML concept. SysML Blocks are modeled in Block Definition Diagrams (BDDs) and Internal Block Diagrams (IBDs). BDDs capture relations among blocks, while IBDs capture interactions among blocks and their internal structure. A block may be both structural and functional, which is both useful and confusing. For example, a block can specify both the sensor and its sensing function,
.
In SysML and its predecessor, the Unified Modeling Language (UML) [
84], capturing a component’s behavior, rather than its structure or function, requires behavioral notation such as Activity Diagram or State Chart. In the Activity Diagram notation, activities and actions are ‘boxes’ (types), while control or data flows are ‘arrows’ (morphisms). In the State Chart notation states are ‘boxes’ and state-transitions are ‘arrows’. The different semantics applied to ‘boxes’ and ‘arrows’ in SysML diagrams can be confusing, although experienced analysts know which notation to use to interpret various diagrams to make sense. Transforming SysML models through categorical specifications into a unified notation requires tremendous effort. We defer this endeavor to future research.
Conversely, OPM models use a minimal ontology of objects, processes, and relations, in which semantic ambiguity and redundancy are eliminated or minimized. Since OPM’s fundamental building blocks are objects that represent structure and processes that represent behavior, with a relatively small set of relations among them, a category of the OPM language is likely to be small and handy. The challenge is in correctly representing the language domain. One apparent categorical specification could define an OPM category with objects as types and processes as morphisms.
Types in one category can be morphisms in another category. OPM makes no syntactic distinction between component-representing objects and operand-representing objects. In fact, the same object can be both an operand of one system and the operator in another. Therefore, objects can be morphisms if they perform processes, and operands if they feed into or out of processes. Processes and relations represent system morphisms but are captured as graphical shapes, which may be puzzling. Processes and relations also have attributes of their own (durations, cardinalities, etc.).
Any model element is a type, including those that might appear to have operational semantics, such as processes, functions, transitions, etc. This also makes sense from a visual perspective: each shape on the canvas must be explicitly defined, regardless of its geometry or semantics. Both the ‘boxes’ and ‘arrows’ of the modeled system must be captured in MLs as types.
If operational entities are types, rather than morphisms—then what are the morphisms? Every model has a logical layer that underlies the visual layer. Therefore, every model element must be captured logically, otherwise it is no more than a meaningless sketch. It follows that there exists a hidden type, Specification (Spec), that captures the logical representation of the visual model. Thus, specifying—mapping visual elements to Spec—is a morphism.
There is another kind of morphism: modeling, which leads us through model creation or transformation. As modelers, we can take various modeling steps based on the state of our mode: (a) start with a blank diagram; (b) add an object, or process—transforming our diagram into a diagram with an object or a process; (c) create a new diagram to specify the details of an object or process; (d) add a state to an object; (e) add a relation between an entity (object, process, or state) and another entity—and so on. Hence, a set of modeling morphisms emerges: Diagram→Object, Diagram→Process, Object→Diagram, Process→Diagram, Object→State, Entity→Relation, and Relation→Entity—modeling morphisms. OPM does not permit creating a Diagram from a State or Relation—although such an extension can be theoretically valid and possible. Challenging the existence or absence of a modeling morphism may help enhance the ML.
Computational commands implement manual on-screen modeling operations and programmatic modeling commands. This allows for automated modeling and for creating models based on other formal representations. To the best of our knowledge OPM does not have a programming interface, but if provided in the future, it can adhere to our categorical formulation.
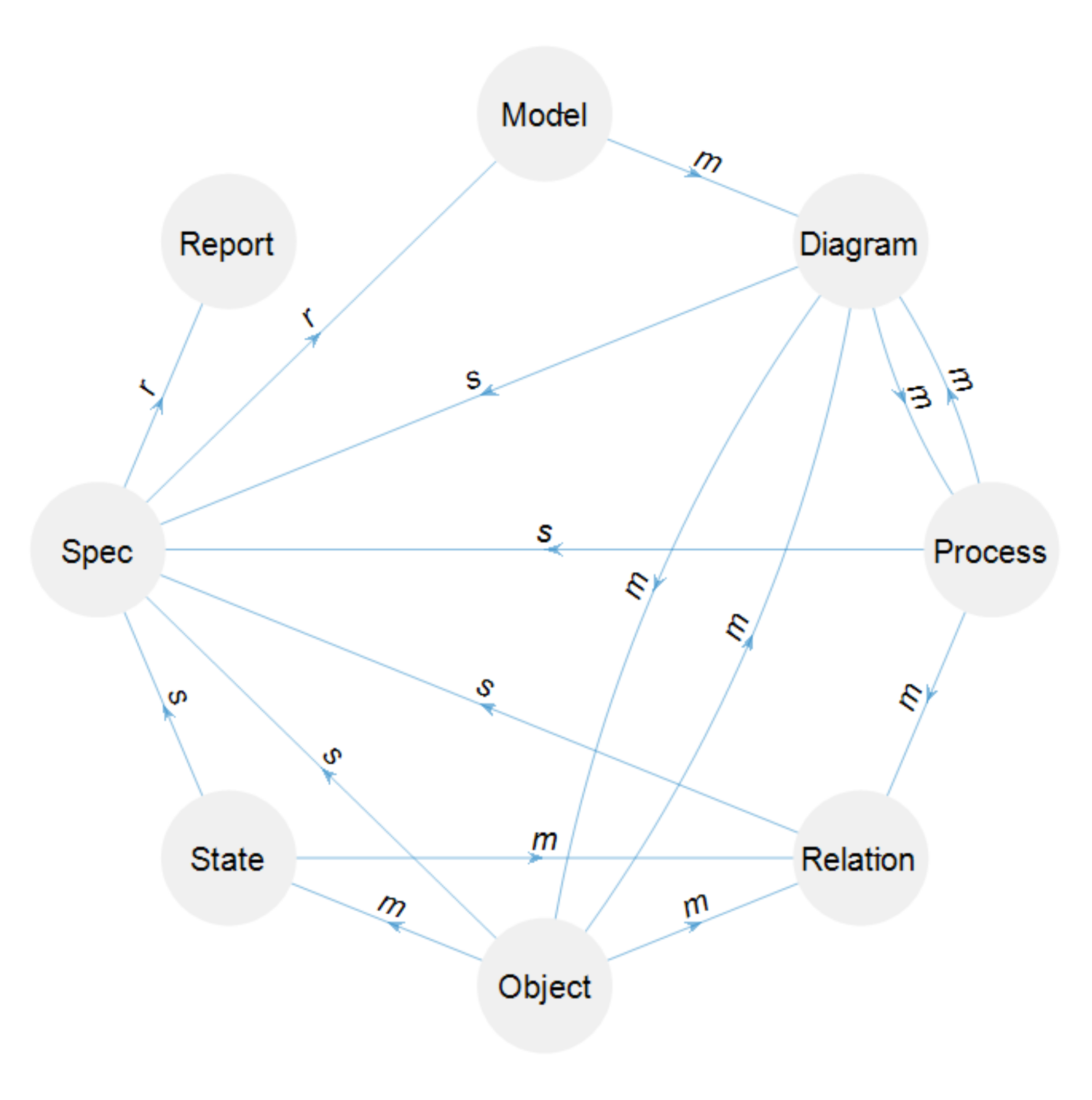
Reconstructing a model from its specifications gives rise to a third morphism to transform Spec statements into visual geometries or textual/logical reports: rendering. The pair specifying—rendering is isomorphic if a Spec allows complete model reconstruction (rendering). OPML also renders part of the Spec as its textual modality: the OPL specification.
The notion that
modeling,
specifying, and
rendering are morphisms in an ML category is illustrated in
Figure 6 for the OPM ML Category,
OPML. The Spec is a critical type as it enables reconstructing, composing, transforming, and comparing models. Rendering the Spec as a processable mediating Report artifact that represents the model substantiates mapping to another representation—a functor that maps the ML to another category. OPCloud’s Exported Report is a mediating artifact. Both Specs and Reports are C-Sets.
Model entities are its interfaces to the System category,
SYS. Model, Diagram, and Spec are not real System concepts—they merely help us manage system complexity. This System-to-Model mapping constitutes the C→M portion of the CMGVC. The OPML→GDS functor maps all the types in OPML to GDS tuples. This C→M→G segment of the CMGVC is illustrated in
Table 4.
3.3. Transforming Models to Graphs
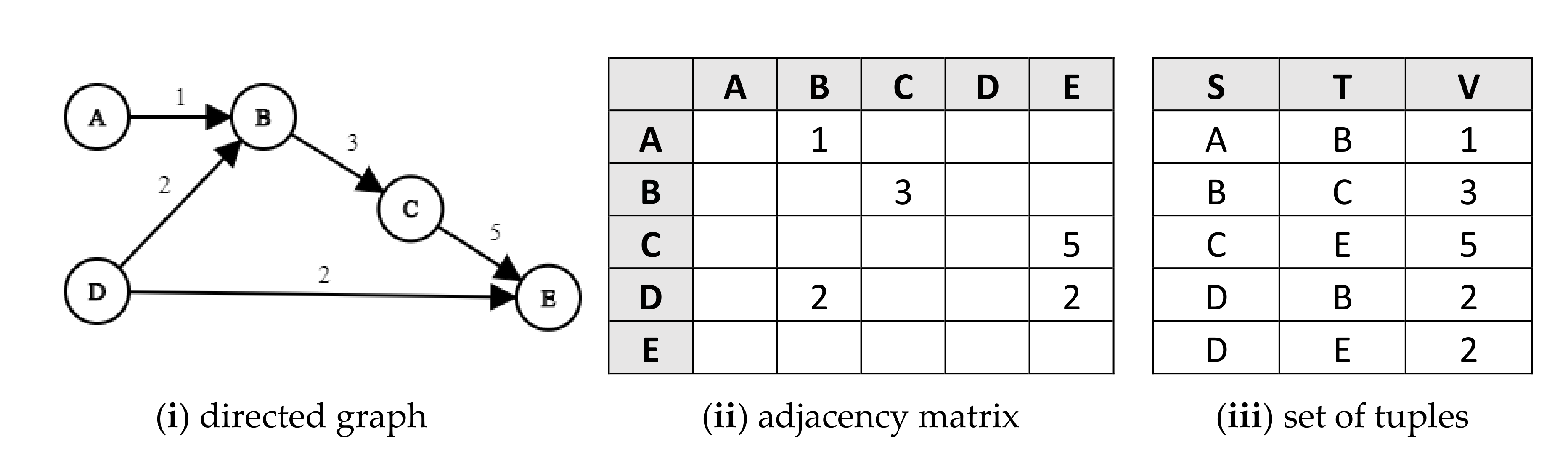
The MGV transform is a composition of a transform from a model into a uniform GDS representation (M→G), with a second transform from GDS into view (G→V). Transforms into GDS require mapping each ML construct to type in the GDS category. Graphs have only two elements:
nodes and
edges. GDS has only one element:
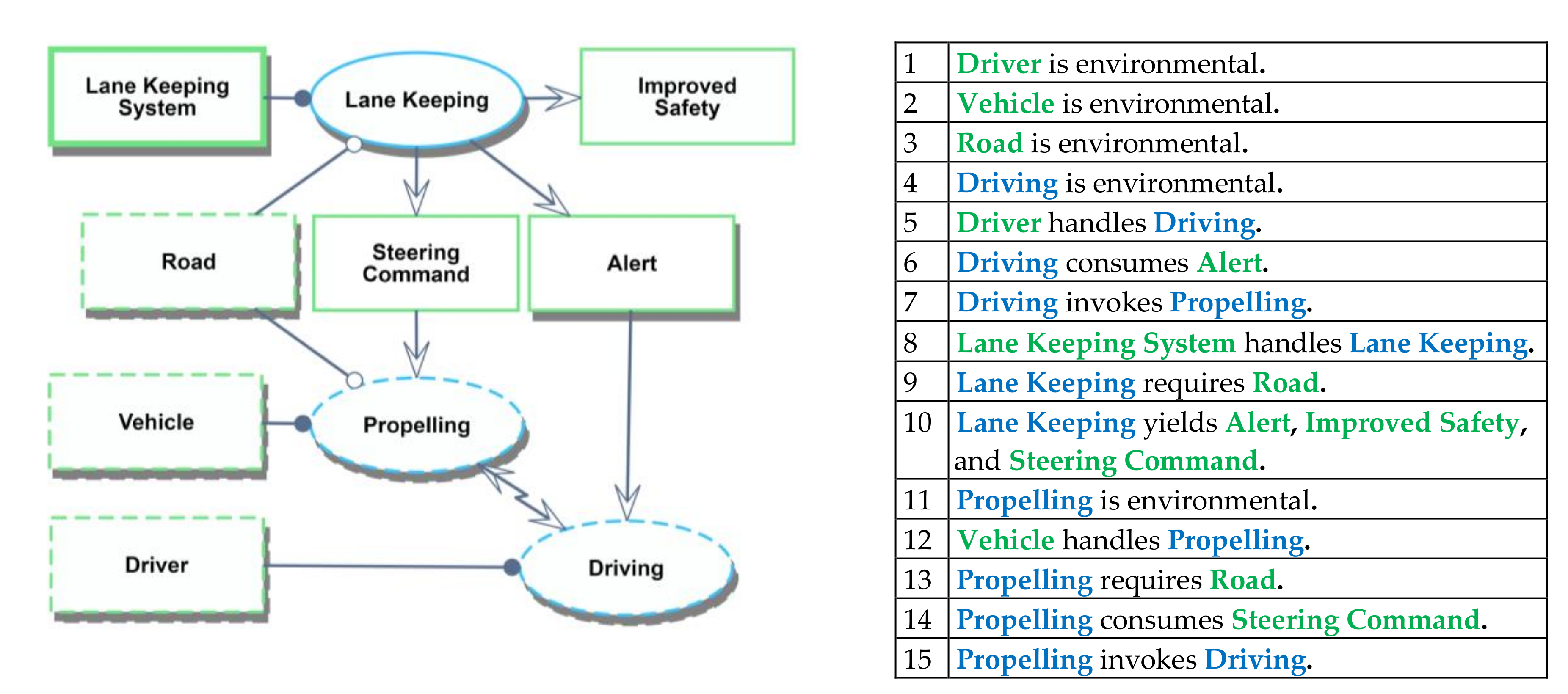
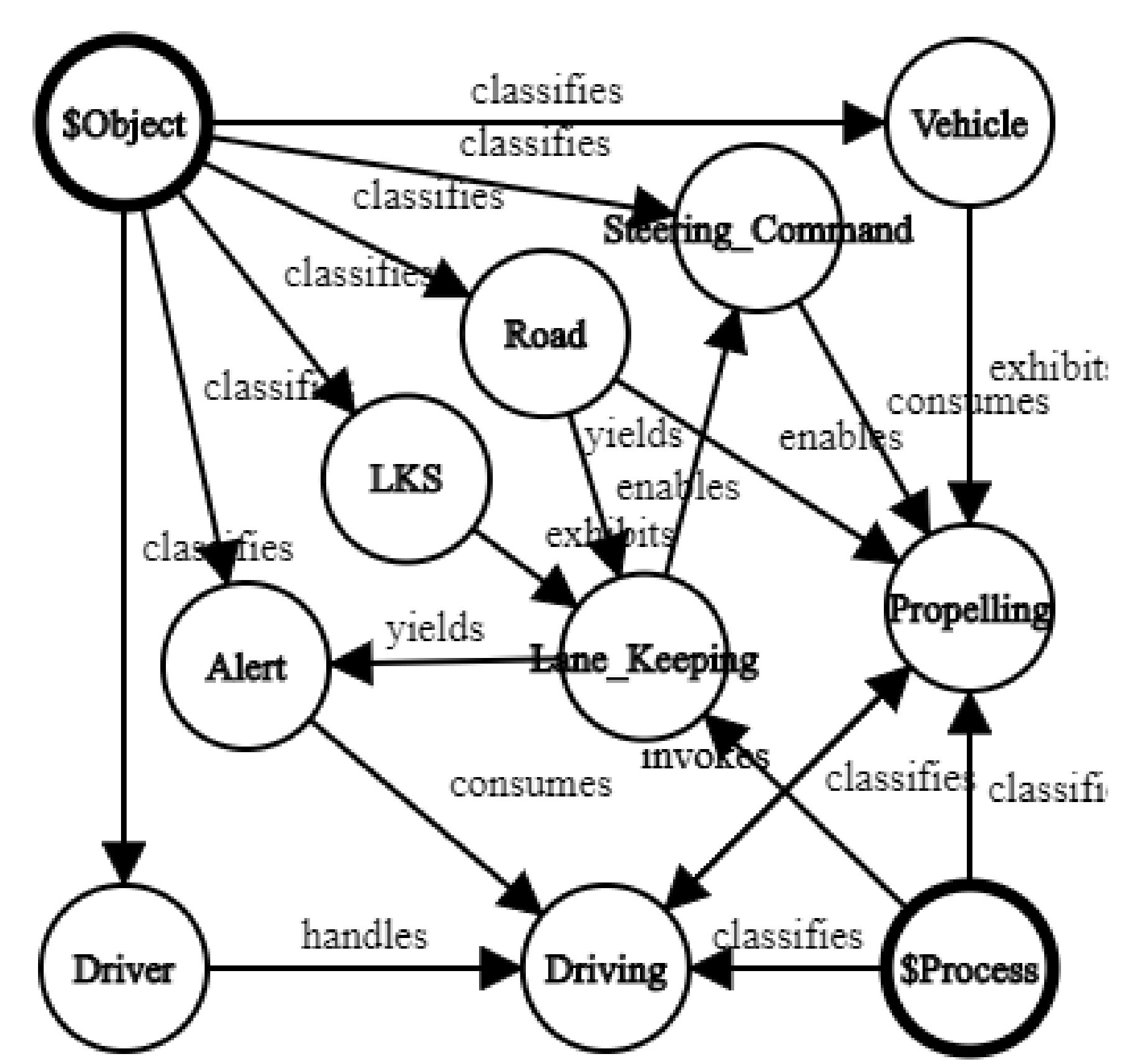
tuple (an abstraction and extension of a node–edge–node triplet). A graph is merely a view on GDS. Such transforms are possible on graphic MLs, although graphics do not always map to simple graphs—for instance, when shapes are contained inside other shapes or overlap with other shapes (as in Venn diagrams). OPCloud’s Exported Report includes the textual OPL specification and lists of the objects, processes, and relations in the model. This helps in mapping all model entities and relations and translating them to GDS tuples. The final product G is a set of tuples, which includes a relation R, a source node S, a target node T, a unique identifier U, and a valuator V, denoted as the RSTUV tuple. V is useful for various applications such as quantification, verification, validation, versioning, and configuration control. Let us revisit the lane keeping system model in
Figure 2 and transform it into a GDS. The graph of the model is shown in
Figure 7.
RSTUV is sufficient for representing model data. It also captures aspects that are not specifically illustrated in the model. For example, it specifies the model’s inclusion of the diagrams, as well as each diagram’s inclusion of visualized objects and processes. The set of RSTUV tuples is obtained by executing the following functorial rules from
to
(also summarized in
Table 5):
- 0.
ML types are defined as RSTUV identity tuples. This step is only done once per ML.
- 1.
Entities are mapped to their OPM entity type (model, diagram, object, process, etc.) using a Classification relation.
- 2.
Relations, such that Ei and Ej are entities connected by relation R, are mapped as is.
- 3.
Each entity Ej is mapped to any diagram Di that includes it by an Inclusion relation.
- 4.
Relations are mapped to any diagram that includes them by an Inclusion relation.
- 5.
Affiliations of entities (systemic/environmental) are mapped as Affiliation relations.
- 6.
Essences of entities (physical/informatical) are mapped as Essence relations [
4].
According to Category Theory, each object must be connected to itself through an identity morphism [
51]. Thus two more mappings are required:
- 7.
Entities are mapped to universally-unique identification numbers (UUIDs) as an Identity relation that constitutes the identity morphism of each entity onto itself.
- 8.
Relations are mapped to UUIDs through an Identity relation that constitutes the identity morphism of each relation onto itself.
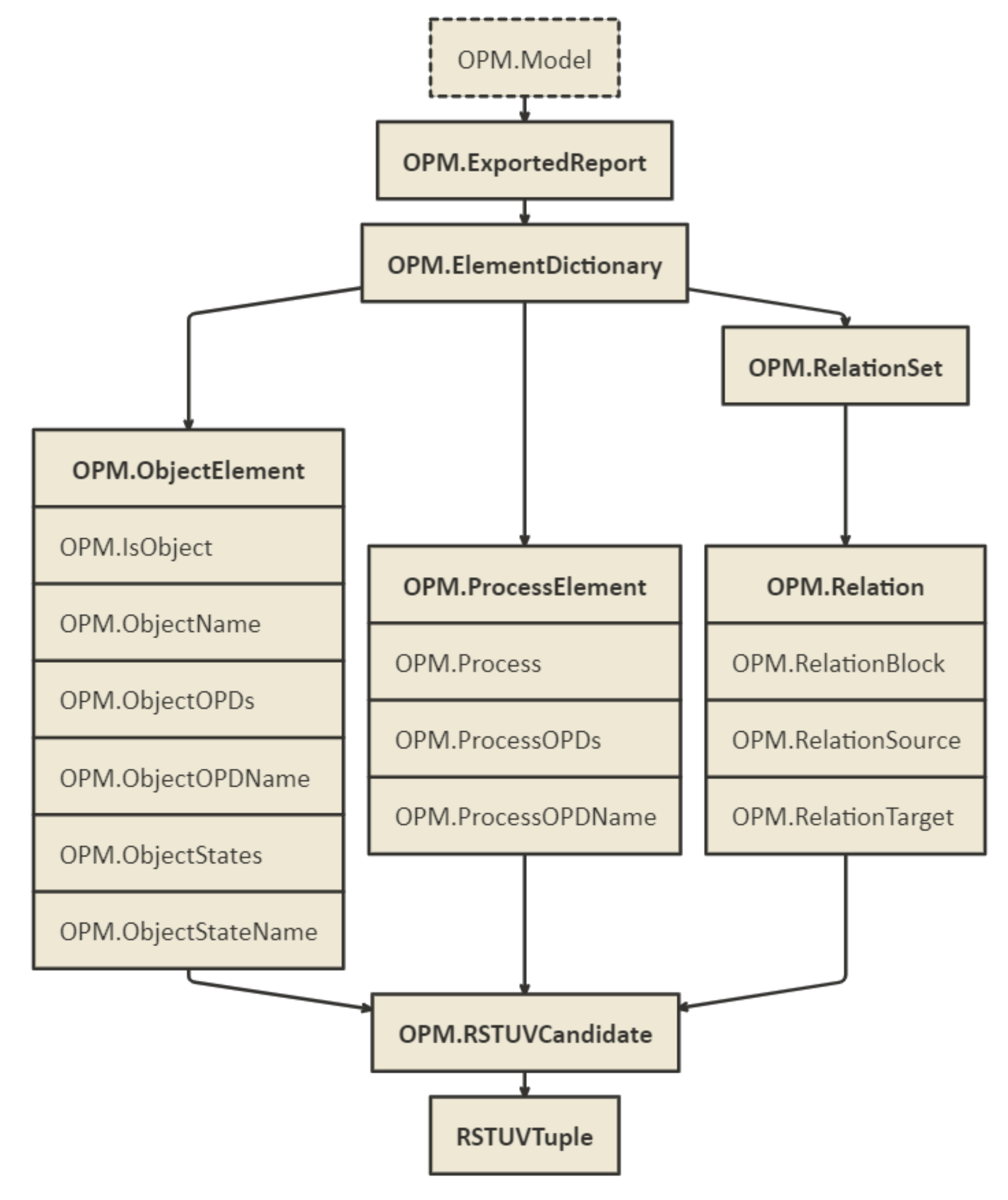
The OPML→GDS C-Set functor that executes the above mappings is illustrated in
Figure 8. The functor extracts the OPM elements from the report generated by OPCloud (
OPM.ExportedReport).
ExportedReport provides most of the information needed for analyzing an OPM model (It does not include shape positions in the diagrams, and therefore, it is not possible to reconstruct the diagrams with the shapes’ exact positioning, but only up to the participation of elements in each diagram).
From ExportedReport, we generate two interim categories: ElementDictionary and OPLSpec. We refer to both objects as sets, but due to the complicated and heterogenous structure of set members, we need further decomposition and transformation of set members to their appropriate data structures. For example, we need to find the OPDs in which each Object and Process appear (ObjectOPDs and ProcessOPDs).
ElementDictionary does not specify appearance of relations in OPDs, but the statements referring to the relations are specified in the OPL text accompanying each OPD. To extract this information, we need to analyze OPLSpec, identify the sentence that specifies each relation under the diagrams in which it is shown, and match the OPD→OPLStatement relation to the right Relation.
A generic transformation function, OntologyMapping, converts or extends ontological terms and executes all parts of the OPML→GDS functor. OntologyMapping starts from the raw input representing external models and other sources of information (e.g., OPM.ExportedReport). It continues recursively to either create new items or extend existing ones. The ExportedReport→ElementDictionary transform and the following three transforms ElementDictionary→{ObjectElement, ProcessElement, RelationSet} create new items sets. RelationSet is further transformed into a new set of Relation items. This step is due to OPCloud’s exported report clustering of all relations of the same type in groups. OntologyMapping extends ObjectElement with attributes such as IsObject, ObjectName, and ObjectStates. It similarly extends ProcessElement with the attributes IsProcess, ProcessOPDs etc., and RelationSet with the attributes RelationBlock, RelationSource, and RelationTarget.
The strength and robustness of OntologyMapping allows it to recursively search for additional mappings needed due to the creation of new items, but it would first make sure all the extended attributes are computed, because those attributes might be needed for creating new items. For instance, to create RSTUVCandidates that cover all the relevant relations pertaining to the Process item, we need to know which OPDs the process is in, and create a separate RSTUVCandidate with R = ‘Inclusion’, S = ProcessElement(p).ProcessOPD, and T = ProcessElement(p).Process, where p is a member of the ProcessElement set, p = 1…,|ProcessElement|.
OntologyMapping also supports mapping and classifying items as Identity Attributes—attributes whose values are converted to Identity and Classification relations.
The Identity relation maps each entry to a universally unique ID (UUID).
The Classification relation maps each entry to its type, which is the attribute name. For example, each item in the Diagram column is mapped to an RSTUVTuple with R = ’Classification’, S = ‘OPM.Diagram’, and T = Item.UUID.
For pairs of Source and Target attributes with a specified relation, each pair of attribute values is transformed into an RST tuple with a specified relation. For example, the OPM.Object and OPM.ObjectState attributes are mapped to a set of RST tuples with R = StateSpecification, S = {item in OPM.Object: the ObjectElement}, and T = {items in OPM.ObjectState—one or more names of states}. For triplets of Source, Target, and Relation attributes, each triplet of attributes values maps directly into an RSTUVTuple. For example: under the OPM.Relation block, R = Relation, S = {one object, process, or state}, T = {one object, process, or state}.
The mapping combinatorically searches for all valid pair and triplet permutations and creates a set of unique RSTUV candidates. An RSTUVCandidate referring to the same relation, source, and target entities might be created from multiple blocks. For example, identity tuples for OPM.Diagram can be generated for both ObjectElement and ProcessElement. OPDs may have two RSTUVCandidates: one due to including an object, and one due to including a process. This is because diagram names are not defined separately in ElementDictionary, only indirectly through the listing of OPDs in which each object and process are visualized. Only one copy of each RST must be kept.
3.4. Transforming Graphs to Views and SIMs
The next step in the process is to define informative views on the model’s GDS (set of RSTUV tuples), such as the SIMs discussed in
Section 2.3. As shown in
Figure 2, the essential graph, adjacency matrix, and RST tuple set are equivalent representations. Therefore, any relational pattern in the model, captured in the GDS, can be represented in a matrix. Furthermore, mappings via selected relations or subsets of relations that make sense or helps in reasoning about a problem, support this reasoning process as a stakeholder-informing view, such as a matrix based on the GDS and thus on the model.
A SIM captures a mapping of row items to column items. We can specify a subset of relations and get a mapping of row items to column items according to the selected relations. We can also reconstruct or compose threads and spans of relations over the GDS. Additional analysis can include tallies, sums, minima, maxima, subtotals on indications, or associated/converted matrix cells values. For example, if the number of allowed relations in each intersection must be positive, we can quickly find the discrepancies (both visually and computationally).
3.5. Transforming Views into Concepts, and Concepts back into Models
The CMGVC’s cognitive segment, V→C→M consists of reasoning, decision-making, and action-taking. During this process, we study the views, mentally fuse, challenge, or corroberate the information with knowledge and beliefs, and create or revise a mental model, or concept. Based on the concepts we have in mind, we make decisions that alter the concept, or alter reality to match the revised concept. These cognitive view-to-concept and concept-to-model mappings close the loop by returning to the category of conceptual systems, . A model of an existing system explains hypotheses, theories, or facts about the system. A model of a future system serves to inform stakeholders about a system that will suit their concept. Stakeholders may later take action to execute decisions and inform model developers about the system’s expected structure and behavior to fulfill the concept that the system was meant to realize. The conceptual transformation is a cognitive process that closes the loop and allows us to re-iterate through conceptual models of described or prescribed systems. Rigorous formulation of these transforms requires substantial grounding in cognitive psychology, and is suggested as an extension of this research.
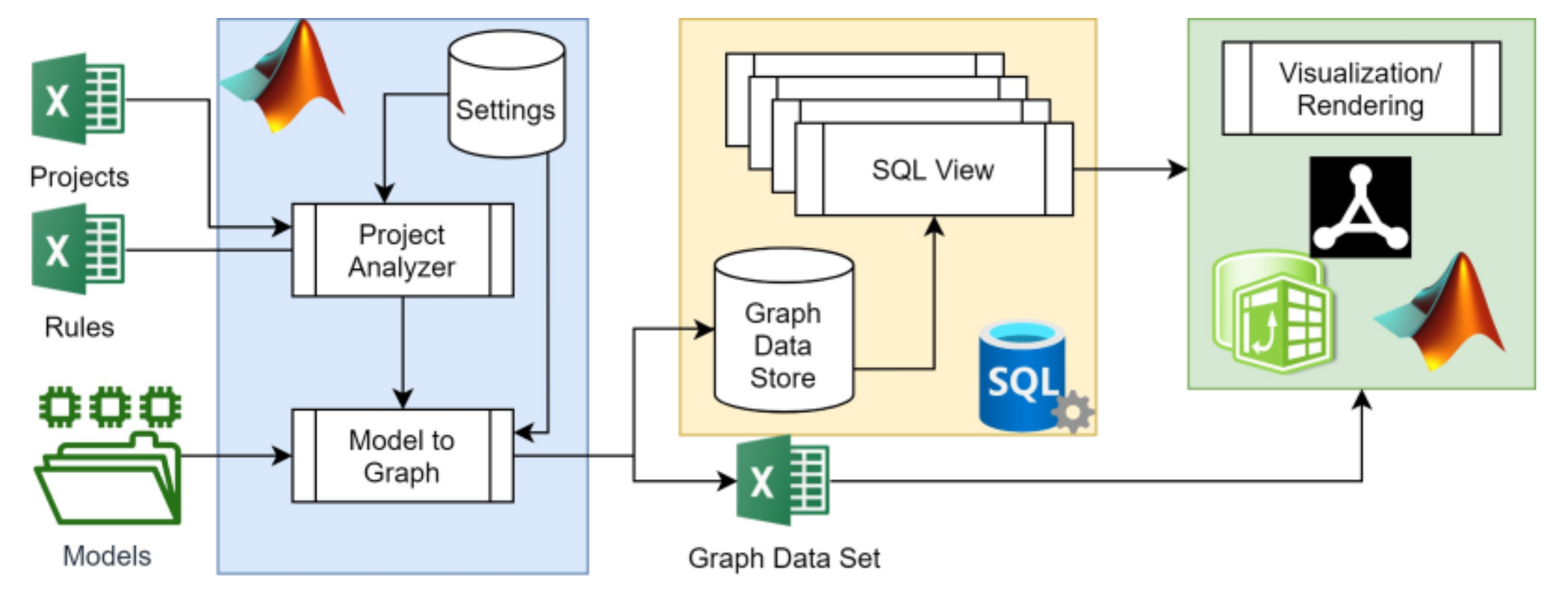
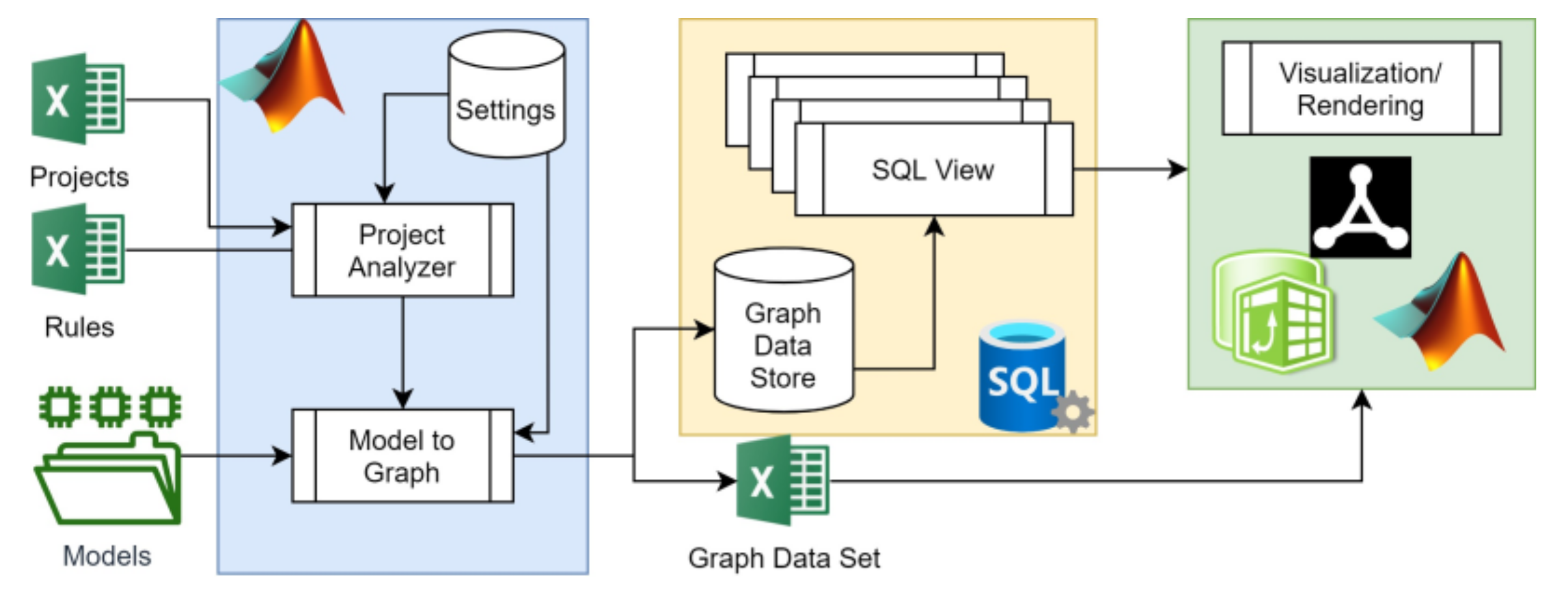
4. Implementation
This section focuses on a CMGVC software platform prototype, which automates parts of the described process. A high-level prototype architecture is illustrated in
Figure 9. The prototype consists of three main modules: the model transformation model, the storage module, and the visualization module. Several software development tools were used for implementing this architecture.
Model transformation functionality is implemented in MATLAB, using settings and input definitions, as well ontology mapping rules defined in MS Excel files. The Project Analyzer reads a set of projects with one or more model per project, from the Projects file, where each model is uniquely identified, and the ML for each model is defined. A project can support models in multiple MLs as well as folders with multiple model files. Raw model representations are provided as files or file directories. The paths to the models are stored in the Projects file. The Project Analyzer reads the raw model representing files and feeds them into the Model-to-Graph functionality.
The Model-to-Graph Transformation implements the OntologyMapping functionality. It first reads and transforms the raw data from the model files, which can be MS Excel, PDF, XML, or JSON. The Rules file defines a set of ontology mapping rules. The program reads these mapping rules for the ML of the processed model, and applies them to the raw model. Accordingly, intermediate representations are formed, and may be subject to additional mapping. Therefore, the processing is recursive and returns until no additional mapping rules are applicable to the resulting data set.
Some mapping rules can be defined as JavaScript Object Notation (JSON) data structure that defines required conversions for any item. An example of a JSON configuration for mapping
ProcessElement to
RSTUVCandidate is shown in
Figure 10. The JSON object can define identity attributes (
identityVars); Source-Target attribute pairs with a specified relation (
sourceTargetPairs); and Relation-Source-Target triplets (
relationSourceTargetTriplets). The mapping function combinatorically searches for all valid pair and triplet permutations and creates a set of unique RSTUV candidates. The mechanism only keeps the first appearance of similar RSTUV candidates with the same RST. Finally, a set of GDS tuples is created.
The platform stores the set of GDS tuples in either Microsoft SQL Server or Microsoft Excel files (as defined in the Projects file). Visualization and rendering of views on the GDS can be obtained through SQL views within the SQL Server database, or on the Excel output. Sequential SQL join queries make up functors from the raw GDS to matrix or tensor datasets [
86], which visualization and analysis tools can render as matrices. Microsoft Excel can import the query results from the database, construct a pivot table on top of the raw data, and render the appropriate visualization. Pivot tables have a flexible structure that allows the analyst to adjust, transpose, and organize the matrix hierarchically for various visualization needs. Readily-available data analysis tools like pivot tables simplify the analysis and minimize tool dependency. Additional modes of analysis and visualization are available via MATLAB, as well as via graph visualization tools like CSAcademy’s Graph Editor (
https://csacademy.com/app/graph_editor/), used throughout this paper.
5. Assessment
The CMGVC offers a significant departure from direct generation of views on models, and a more robust alternative to indirect generation of views based on DSML-specific representations. In
Section 3.1 we have defined five propositions for this research:
M→G→V (a GDS-mediated transformation from model to view) is superior to M→V (a direct transformation from model to view)
M→G→V is superior to M→R→V (a transformation mediated by a language-bound representation, LBR)
M→G is a feasible and valid transformation.
G→V is a feasible and valid transformation.
G→SIM is a feasible and valid transformation.
We have presented a categorical framework for converting conceptual system models from one ML, OPM, into a GDS, and deriving SIM views from the GDS. We have thus managed to validate Propositions 3, 4, and 5 regarding the existence of the building blocks of a composed transform M→G→V based on , where , .
To prove Propositions 1 and 2, we must compare the benefits and limitations of the CMGVC approach vis-à-vis the two alternative approaches:
MV: Direct generation of views from a model, that we denote V(M) or MV
MRV: Indirect generation of views from a model via a common DSML-specific representation, that we would demote V(RDSML(MDSML)) or MRV
We define four lower-is-better (LIB) criteria for comparison, which reflect stakeholders needs for efficiency (C1), flexibility (C2), robustness (C3), and resilience (C4):
C1—Efficiency is measured by the number of required transformations of M models to V views. For MGV, MRV: sum of model-to-graph transformations (M) and graph-to-view transformations (V); for MV: product of models by views ().
C2—Flexibility is measured by the effort of creating new views for existing models. For MGV, MRV: one effort unit per view (graph-to-view or LBR-to-view); for M: M effort units (models-to-view).
C3—Robustness is measured by the effort of creating existing views for new models: For MGV: a single effort unit (model-to-graph); for MV: V effort units (model-to-views); for MRV: V+1 effort units (model-to- LBR and LBR-to-views).
C4—Resilience is measured by the dependency on DSML updates: for MGV, MRV: a single effort unit for updates (model-to-graph or model-to-LBR); for MV: V effort units (model-to-views).
Since all criteria are LIB, the total score is also LIB.
Table 6 defines metrics for each criterion. Total scores for MGV, MV, and MRV are defined in Equations (1)–(3).
is superior to
(Proposition B) if
:
Cancelling equal terms, we obtain: .
Homogenizing, we obtain: .
This inequality always holds, and therefore
, and MGV is superior to any MRV with a DSML-specific representation:
Conditions for
superiority to
:
Homogenizing, we obtain the following:
We try Equation (5) with combinations of V = 1, V = 2, V > 2 with M = 1, M = 2, M > 2, as summarized in
Table 7. For all practical purposes, multiple MLs
, and at least two views (we already have three),
With this analysis, we have managed to corroborate Proposition 1 and Proposition 2.
7. Discussion
This paper has several results and outcomes to discuss at the methodological and empirical levels. The primary result of this study is the formulation of the CMGVC using robust category-theoretical foundations. In addition to the emerging overarching framework, we have results for each cycle phase at varying specification levels.
The emergence of the CMGVC is a promising direction for MBSE, as also indicated by both colleagues and the anonymous referees. Systems engineering is undergoing a digital transformation, compounded with the constant growth of systems complexity and interconnectedness. Conceptual modeling is becoming more common for representing complex systems, and more critical for generating deliverables that impact the digital value chain [
10]. Considering the challenge and opportunity associated with these trends, robust foundations for interoperability and collaboration across digital enterprises are likely to be significant enablers of digital systems engineering.
The assertion and demonstration that modeling languages are categories is an important contribution to the body of knowledge, as it extends the Curry–Howard–Lambek Correspondence from programing languages to modeling languages. We have used categorical structures to map system concepts to formal models, models to robust graph data structures (GDS), and GDS to stakeholder-informing views—graphs and matrices. With these representations defined as categories, a new category-theory-driven MBSE paradigm can emerge. Many more extensions of this paradigm are possible, including the definition of additional modeling languages as categories, and the definition of additional functorial mappings of GDS to views, including model-to-model translation.
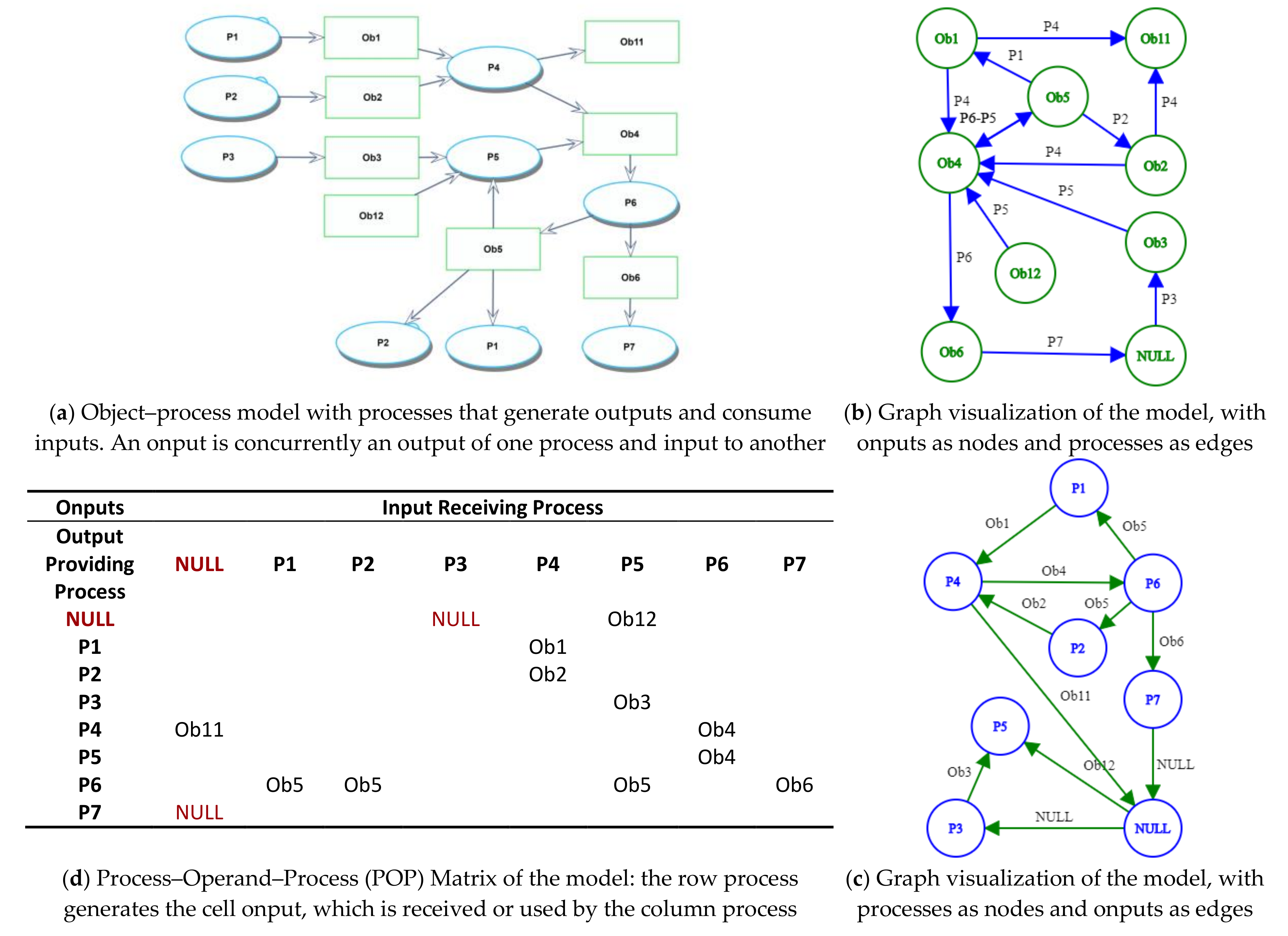
Stakeholder-informing visualizations, particularly matrices, are enhanced by this study with rigorous and robust foundations for generating, processing, and analyzing model-based data. The two graph renditions we generated are in fact duals: a process-on-node/onput-on-edge graph and an onput-on-node/process-on-edge graph. Both dual graph renditions have uses and advantages. Being able to generate both graphs from the same data structure is an important benefit, which also ensures consistency and complementarity. The SysML Internal Block Diagram (IBD) uses object-on-node semantics. The Activity Diagram is a process-on-node graph. State Charts use a state-on-node semantics. These three aspects can be generated from the same GDS of an OPM model. Therefore, GDS facilitates modeling language translation, a promising direction for future research.
The process–operand–process exchange matrix is an important architectural analysis tool. It captures a non-trivial mapping relation that we could build by composing relation segments in the GDS through robust data retrieval and integration queries. Obtaining and maintaining such a matrix manually is a significant cognitive effort. Dynamically visualizing the matrix using a pivot table is another strong benefit, due to its accessibility and ability to accommodate evolving needs. We have also shown how detected relation anomalies drive concept and model revisions. While such analyses can be based on manually constructed or otherwise-generated matrices, our approach provides additional confidence, since the data comes from the model and lends itself to any necessary composition or aggregation that can yield beneficial visualization. Our approach also sets the stage for a broad range of visual and digital representations. The latter can inform digital actors and greatly enhance interoperability and coordination across and among enterprises.
8. Conclusions
In this paper, we have explored the potential of Category Theory to serve as an underlying formalism for systems engineering, particularly in the context of MBSE. Category Theory is an appropriate holistic paradigm, a state of mind, and a formal foundation for the model transformation and reasoning pipeline, which is essential for a smooth, rational, and reliable MBSE cycle that constantly improves, corrects, and refines system architecture specifications.
The Concept–Model–Graph–View cycle (CMGVC) facilitates the transformation of conceptual models to stakeholder-informing and decision-supporting views. We have shown that it would be imperative to include an intermediate generic representation in the form of a GDS, which serves as a common outlet to all MLs, and a common basis for all views, visualizations, and reports. We have proven the superiority of our approach to direct and ML-bound mappings.
The CMGVC has several advantages:
Using the CMGVC, stakeholders and decision-makers will be able to derive critical information and insight regarding system development and operation from the system model, rather than through a disparate information gathering and presentation channel, which is the common practice today.
The preferential dominance that we have proven in
Section 5 facilitates efficiency in model analytics, and thus encourages further adoption.
The transition through GDS enhances system understanding by adding another modality: graphs, which map concepts and relations through one common substantial representation.
The simple-yet-robust GDS can be a prime facilitator of MBSE interoperability and collaboration across digital value chains.
Subject matter experts will be able to leverage the CMGVC via semantic and ontological frameworks to better represent emerging patterns and concepts.
We have demonstrated how a model can be represented in multiple ways—two visual graph renditions and a process-to-process operand exchange matrix—that are all based on its single GDS.
We plan to demonstrate that the CMGVC can be robustly suited for various other MLs and views. Particularly, we plan to explore the transformation of SysML and Simulink models via the CMGVC pipeline and to create meaningful source-agnostic views, including SIMs, sub-graphs, state spaces, and specifications in other MLs. Isomorphic mapping out of and back into the same ML to support round-trip engineering also pose a major challenge [
87].
Reconciling MBSE and Discrete Event Simulation (DEVS) paradigms is a recently trending effort [
88]. Ongoing collaboration between the MBSE and DEVS communities has been institutionalized in a joint workgroup of the International Council on Systems Engineering (INCOSE) and International Association for Engineering Modeling and Simulation (NAFEMS) [
89]. Our framework can facilitate interoperability across MBSE and DEVS platforms, tools, and models. It alleviates efforts to find and apply an interoperability standard that would appeal to both MBSE and DEVS. The reason is that graph-theoretic DEVS algorithms are abundant, and graph-representable problems have been studied with DEVS technology and methodology for decades, e.g., as part of the Agent-Based Modeling and Simulation (ABMS) paradigm [
90,
91].
One limitation in our approach is its scalability. We plan to build a service-oriented software platform that will provide robust transformation capabilities as web services to MBSE practitioners and researchers, who will be able to upload or plug-in live models and generate useful visualizations. MBSE experts would be able to define and manage mappings and sets of views to run on specific models. These will provide continuous visualization or integration with external systems across the digital enterprise. We plan to employ state-of-the-art graph database and information visualization techniques to provide stakeholders with flexible, dynamic, and elegant decision-supporting views.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}