
Outlier Detection with Explanations on Music Streaming Data: A Case Study with Danmark Music Group Ltd.

 ,
,  and
and 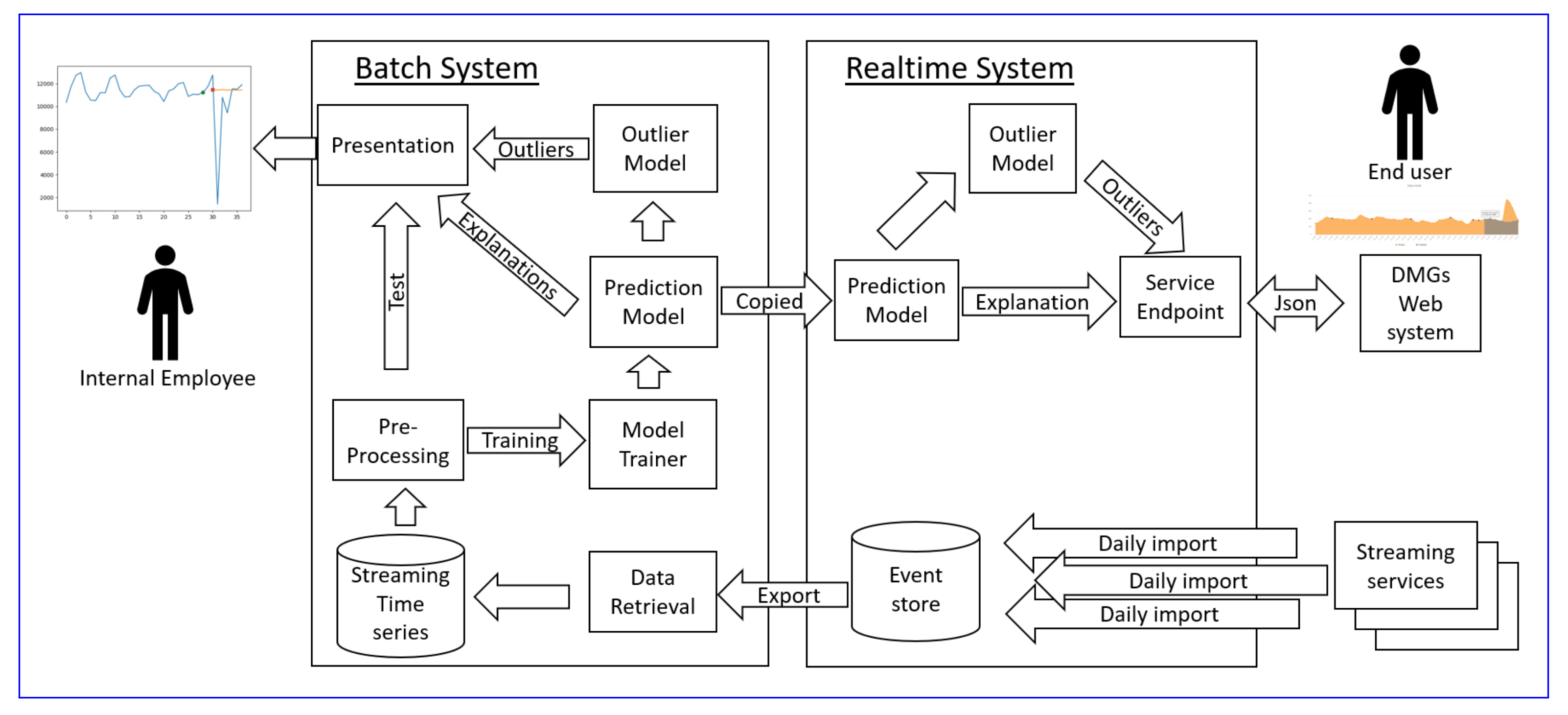{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- A novel unsupervised LSTM based outlier method;
- Two levels of contextual outlier explanations;
- Discussion of challenges in a real-life application of unsupervised contextual outlier detection and explanation;
- Quantitative and qualitative evaluation with end-users;
- A discussion of context-dependent and personalized outlier detection based on empirical findings.
2. Related Work
3. Material and Methods
3.1. Background and Challenges
3.1.1. The Use Case
3.1.2. Formalizing the Problem
3.1.3. Challenges
3.2. Application Case Study
3.2.1. Data Retrieval
3.2.2. Training and Test Data
3.2.3. The Prediction Model
3.2.4. Prediction-Based Outlier Scores
3.2.5. Outlier Score Customization
3.2.6. Level 1 Explanation
3.2.7. Level 2 Explanation
3.2.8. Presentation
3.3. Evaluation Setup
4. Results
4.1. Quantitative Results
4.1.1. Training Parameters
4.1.2. Precision Versus Quality of Outlier Scores
4.1.3. Outlier Calculation
4.1.4. Total Number of Streamings and Outliers Score
4.2. Qualitative Evaluation
4.2.1. The Value of Detecting Outliers
4.2.2. The Value of Outlier Explanation
5. Discussion
5.1. Evaluation and Adoption of The System
5.2. Finding the Best Parameters
5.3. The Complexity of Outlierness
5.3.1. Personalization
5.3.2. Non-Outlier Information
5.3.3. Outlier Grouping
5.3.4. Outlier Explanations
5.4. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Moscato, V.; Picariello, A.; Sperli, G. An emotional recommender system for music. IEEE Intell. Syst. 2020, 1. [Google Scholar] [CrossRef]
- Amato, F.; Moscato, V.; Picariello, A.; Sperlí, G. Recommendation in Social Media Networks. In Proceedings of the 2017 IEEE Third International Conference on Multimedia Big Data (BigMM), Laguna Hills, CA, USA, 19–21 April 2017; pp. 213–216. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. arXiv 2016, arXiv:1602.04938. [Google Scholar] [CrossRef]
- Mehrmolaei, S.; Keyvanpourr, M.R. A Brief Survey on Event Prediction Methods in Time Series. Artificial Intelligence Perspectives and Applications; Silhavy, R., Senkerik, R., Oplatkova, Z.K., Prokopova, Z., Silhavy, P., Eds.; Springer: Cham, Switzerland, 2015; pp. 235–246. [Google Scholar] [CrossRef]
- Guralnik, V.; Srivastava, J. Event Detection from Time Series Data. In Proceedings of the SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 33–42. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection for Discrete Sequences: A Survey. IEEE TKDE 2012, 24, 823–839. [Google Scholar] [CrossRef]
- Schubert, E.; Weiler, M.; Zimek, A. Outlier Detection and Trend Detection: Two Sides of the Same Coin. In Proceedings of the IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015. [Google Scholar] [CrossRef]
- Gupta, M.; Gao, J.; Aggarwal, C.C.; Han, J. Outlier Detection for Temporal Data: A Survey. IEEE Trans. Know. Data Eng. 2014, 26, 2250–2267. [Google Scholar] [CrossRef]
- Schubert, E.; Zimek, A.; Kriegel, H.P. Local Outlier Detection Reconsidered: A Generalized View on Locality with Applications to Spatial, Video, and Network Outlier Detection. Data Min. Knowl. Disc. 2014, 28, 190–237. [Google Scholar] [CrossRef]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G.M. LSTM-based Encoder-Decoder for Multi-sensor Anomaly Detection. arXiv 2016, arXiv:1607.00148. [Google Scholar]
- Provotar, O.I.; Linder, Y.M.; Veres, M.M. Unsupervised Anomaly Detection in Time Series Using LSTM-Based Autoencoders. In Proceedings of the 2019 IEEE International Conference on Advanced Trends in Information Theory (ATIT), Kyiv, Ukraine, 18–20 December 2019; pp. 513–517. [Google Scholar] [CrossRef]
- Markou, M.; Singh, S. Novelty Detection: A Review—Part 2: Neural Network Based Approaches. Signal Process. 2003, 83, 2499–2521. [Google Scholar] [CrossRef]
- Miljković, D. Review of novelty detection methods. In Proceedings of the 33rd International Convention MIPRO, Opatija, Croatia, 24–28 May 2010; pp. 593–598. [Google Scholar]
- Hyndman, R.; Athanasopoulos, G. Forecasting: Principles and Practice, 2nd ed.; OTexts: Melbourne, VIC, Australia, 2018. [Google Scholar]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. A Comparison of ARIMA and LSTM in Forecasting Time Series. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1394–1401. [Google Scholar] [CrossRef]
- Malhotra, P.; Vig, L.; Shroff, G.M.; Agarwal, P. Long Short Term Memory Networks for Anomaly Detection in Time Series. In Proceedings of the European Symposium on Artificial Neural Networks (ESANN 2015), Bruges, Belgium, 22–24 April 2015. [Google Scholar]
- Gunning, D.; Aha, D. DARPA’s Explainable Artificial Intelligence Program. AI Mag. 2019, 40, 44–58. [Google Scholar] [CrossRef]
- Lipton, Z.C. The Mythos of Model Interpretability: In Machine Learning, the Concept of Interpretability is Both Important and Slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Goebel, R.; Chander, A.; Holzinger, K.; Lecue, F.; Akata, Z.; Stumpf, S.; Kieseberg, P.; Holzinger, A. Explainable AI: The New 42? In Machine Learning and Knowledge Extraction; Holzinger, A., Kieseberg, P., Tjoa, A.M., Weippl, E., Eds.; Springer: Cham, Switzerland, 2018; pp. 295–303. [Google Scholar]
- Knorr, E.M.; Ng, R.T. Finding Intensional Knowledge of Distance-Based Outliers. In Proceedings of the International Conference on Very Large Data Bases, Edinburgh, UK, 7–10 September 1999; pp. 211–222. [Google Scholar]
- Zhang, J.; Gao, Q.; Wang, H.H. A Novel Method for Detecting Outlying Subspaces in High-dimensional Databases Using Genetic Algorithm. In Proceedings of the 6th IEEE International Conference on Data Mining (ICDM 2006), Hong Kong, China, 18–22 December 2006; pp. 731–740. [Google Scholar] [CrossRef] [Green Version]
- Duan, L.; Tang, G.; Pei, J.; Bailey, J.; Campbell, A.; Tang, C. Mining outlying aspects on numeric data. Data Min. Knowl. Disc. 2015, 29, 1116–1151. [Google Scholar] [CrossRef]
- Kriegel, H.P.; Schubert, M.; Zimek, A. Angle-Based Outlier Detection in High-dimensional Data. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 11–14 August 2008; pp. 444–452. [Google Scholar] [CrossRef] [Green Version]
- Kriegel, H.P.; Kröger, P.; Schubert, E.; Zimek, A. Outlier Detection in Axis-Parallel Subspaces of High Dimensional Data. In Proceedings of the 13th Pacific-Asia Knowledge Discovery and Data Mining Conference, Bangkok, Thailand, 27–30 April 2009; pp. 831–838. [Google Scholar] [CrossRef] [Green Version]
- Dang, X.H.; Micenková, B.; Assent, I.; Ng, R. Local Outlier Detection with Interpretation. In Proceedings of the ECML-PKDD 2013: European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, Prague, Czech Republic, 23–27 September 2013; pp. 304–320. [Google Scholar]
- Dang, X.H.; Assent, I.; Ng, R.T.; Zimek, A.; Schubert, E. Discriminative Features for Identifying and Interpreting Outliers. In Proceedings of the IEEE International Conference on Data Engineering (ICDE 2014), Chicago, IL, USA, 31 March–4 April 2014; pp. 88–99. [Google Scholar] [CrossRef]
- Hawkins, D. Identification of Outliers; Chapman and Hall: London, UK, 1980. [Google Scholar]
- Zimek, A.; Filzmoser, P. There and back again: Outlier detection between statistical reasoning and data mining algorithms. Data Min. Know. Discov. 2018, e1280. [Google Scholar] [CrossRef] [Green Version]
- Rousseeuw, P.J.; Hubert, M. Robust statistics for outlier detection. Data Min. Know. Discov. 2011, 1, 73–79. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Herskind Sejr, J.; Christiansen, T.; Dvinge, N.; Hougesen, D.; Schneider-Kamp, P.; Zimek, A. Outlier Detection with Explanations on Music Streaming Data: A Case Study with Danmark Music Group Ltd. Appl. Sci. 2021, 11, 2270. https://doi.org/10.3390/app11052270
Herskind Sejr J, Christiansen T, Dvinge N, Hougesen D, Schneider-Kamp P, Zimek A. Outlier Detection with Explanations on Music Streaming Data: A Case Study with Danmark Music Group Ltd. Applied Sciences. 2021; 11(5):2270. https://doi.org/10.3390/app11052270
Chicago/Turabian StyleHerskind Sejr, Jonas, Thorbjørn Christiansen, Nicolai Dvinge, Dan Hougesen, Peter Schneider-Kamp, and Arthur Zimek. 2021. "Outlier Detection with Explanations on Music Streaming Data: A Case Study with Danmark Music Group Ltd." Applied Sciences 11, no. 5: 2270. https://doi.org/10.3390/app11052270
APA StyleHerskind Sejr, J., Christiansen, T., Dvinge, N., Hougesen, D., Schneider-Kamp, P., & Zimek, A. (2021). Outlier Detection with Explanations on Music Streaming Data: A Case Study with Danmark Music Group Ltd. Applied Sciences, 11(5), 2270. https://doi.org/10.3390/app11052270