
A Layered KNN-SVM Approach to Predict Missing Values of Functional Requirements in Product Customization



Abstract
:1. Introduction
- Explore the interconnections among different orders from customers to predict the missing values of FR.
- Determine the optimal predicted values with a feasible framework and algorithms for missing values prediction of FR.
2. Literature Review
2.1. Requirements Prediction in Product Customized Design
2.2. Imputation Approaches for Missing Values
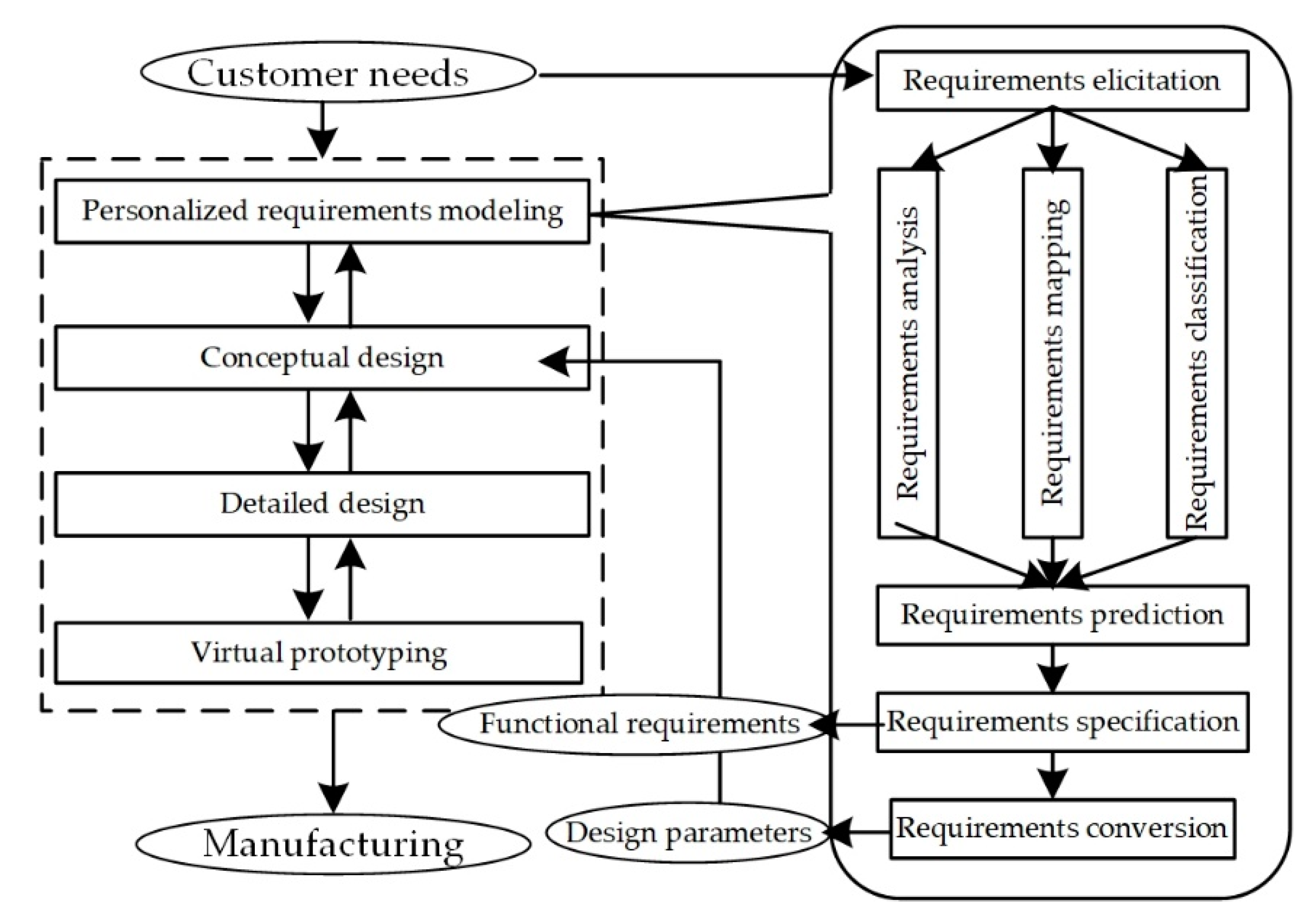
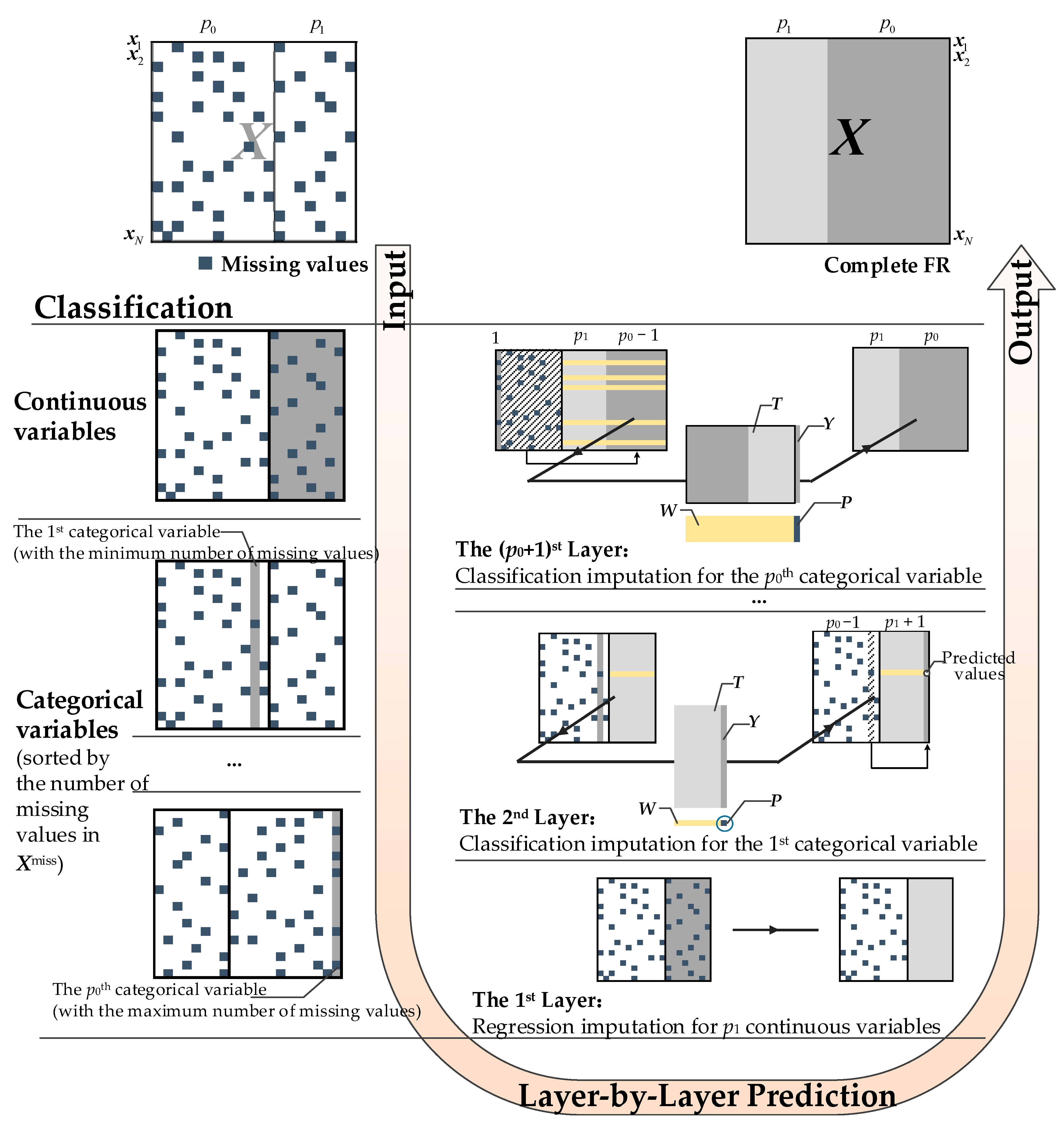
3. Multi-Layer Framework for Missing Values Prediction
3.1. Problem Description
3.2. Framework Formulation
| Algorithm 1. Prediction workflow of the proposed framework. |
| Input: Xmiss, M0, M1, c = 1 |
| Output: X |
| 1 Normalize Xmiss, transfer categorical into continuous variables |
| 2 Impute the missing values using regression method R |
| 3 |
| 4 J = {K1, K2, …, Kp0} = {|M0 : (i,j)|j=1,2,…,p0} |
| 5 While existing missing values |
| 6 c = c + 1 //cth layer |
| 7 Ka = min(J) |
| 8 , , , |
| 9 [T, Y, W, P] = separate() |
| 10 Train classifier C using T and Y |
| 11 P = C(W) |
| 12 J = J/Ka |
| 13 |
| 14 End while |
4. Layered KNN-SVM Methodology
4.1. Continuous Variable Prediction Using KNN
4.2. Categorical Variable Prediction Using SVM
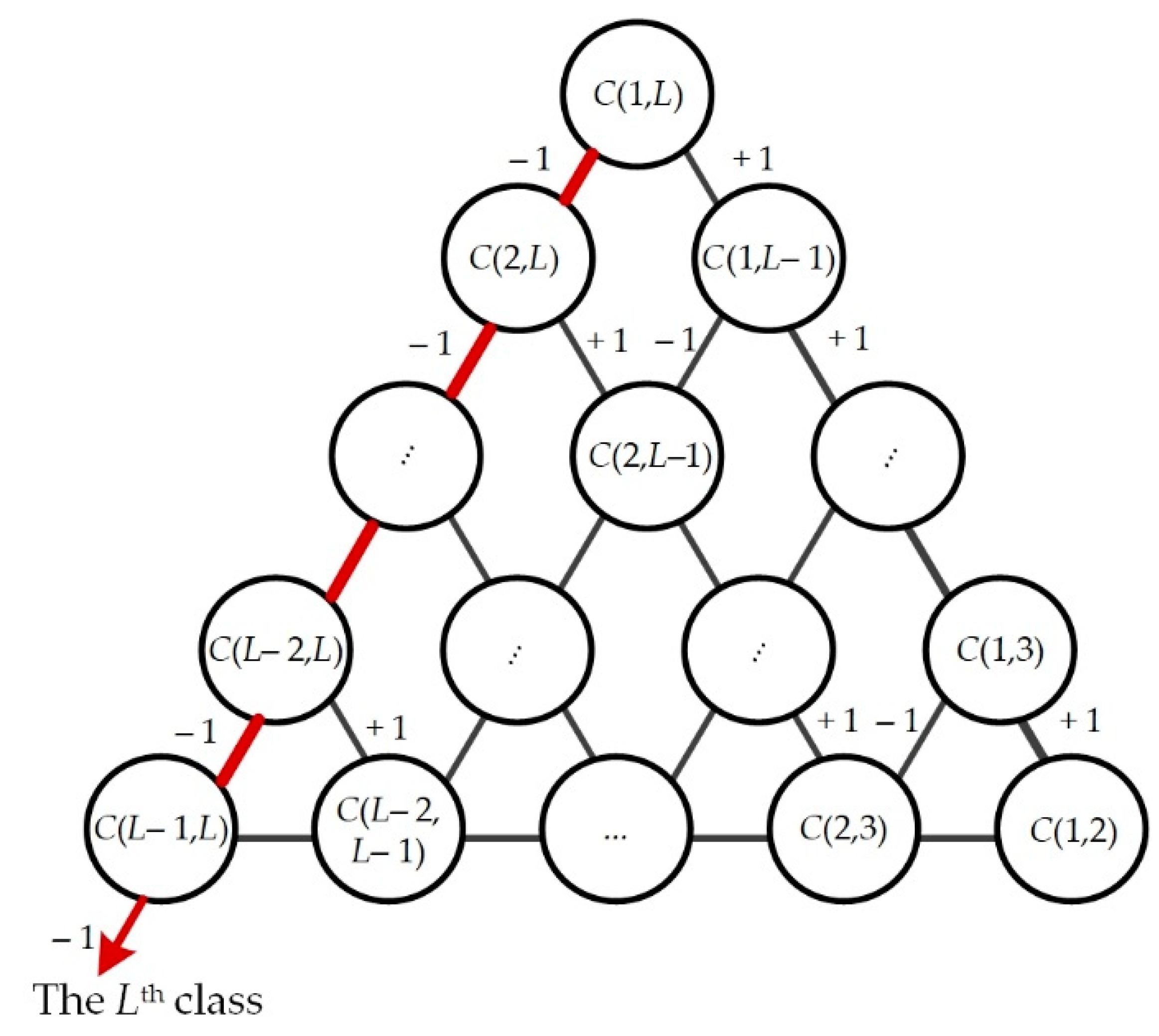
4.2.1. Multi-Class Classification with Directed Acyclic Graph
4.2.2. SVM for Binary Classification
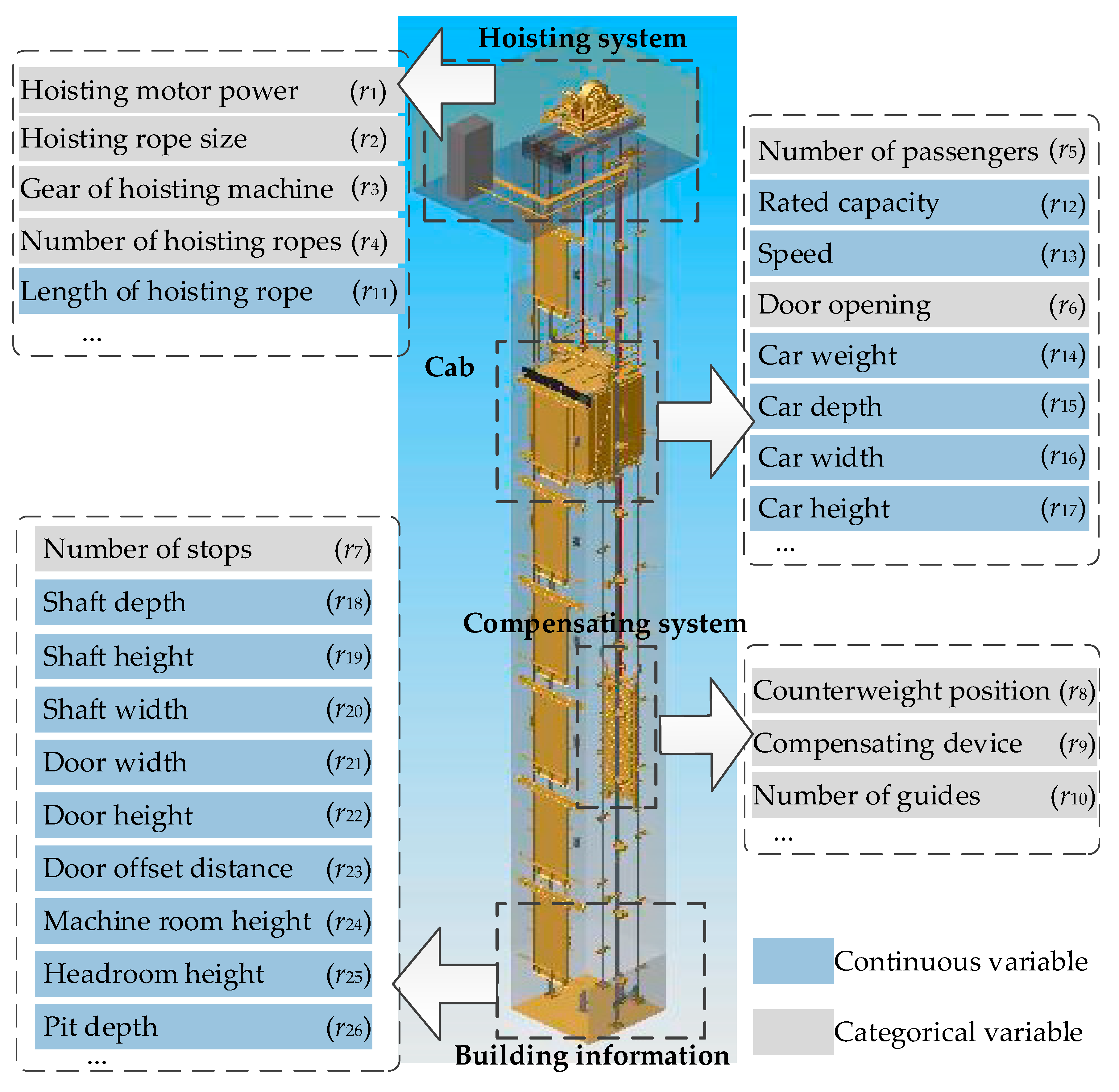
5. Case Study
- The benefit of the proposed framework for predicting the missing values of FR.
- Why we integrate KNN and SVM for continuous and categorical variables prediction, respectively?
- The adaption of proposed approach in the cold- and warm-start scenarios.
5.1. Experimental Setup
5.1.1. Dataset and Compared Methods
5.1.2. Evaluation Metrics
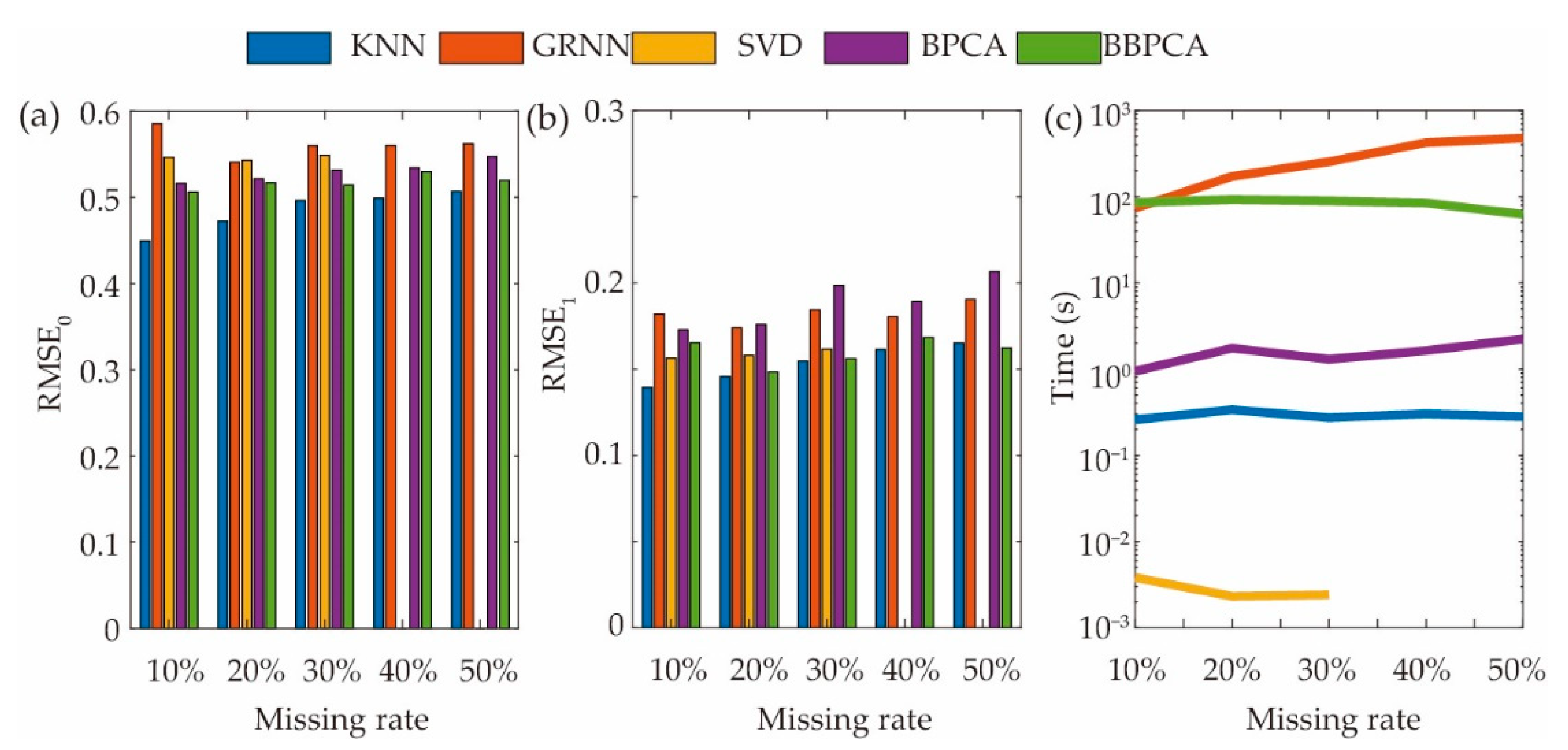
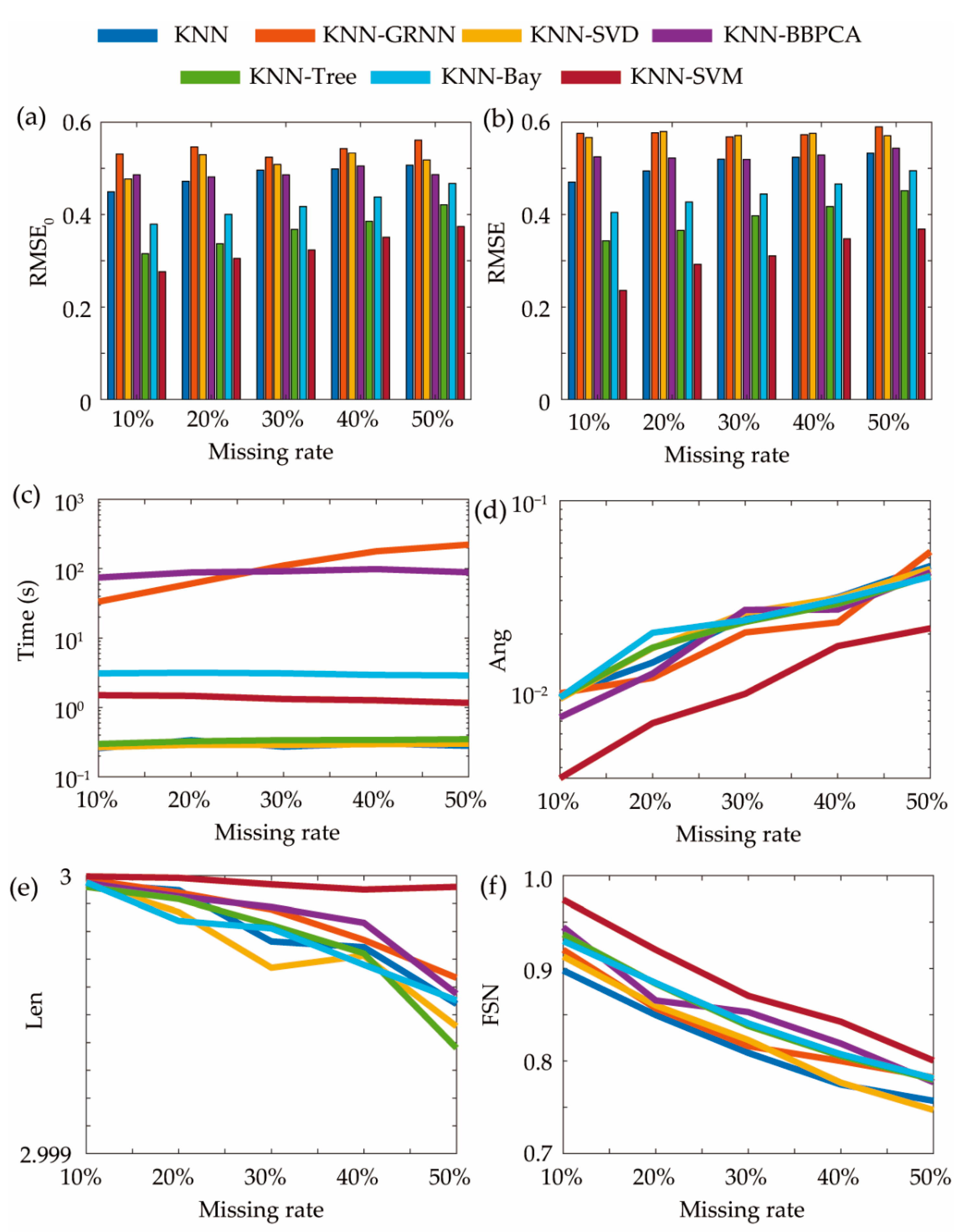
5.2. Experimental Results and Comparison
5.3. Case Analysis
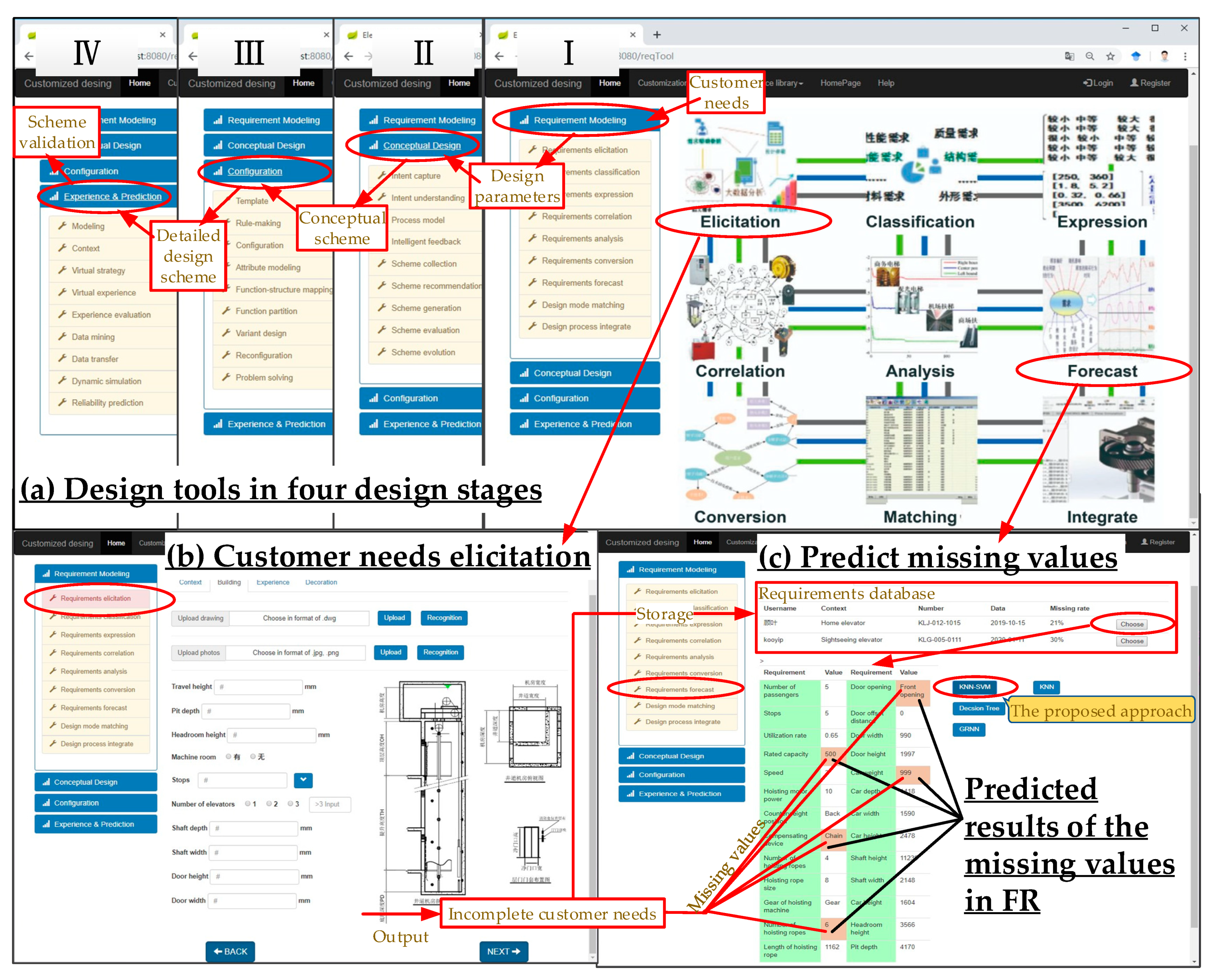
5.4. Application and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Chinese Mechanical Engineering Society. Technology Roadmaps of Chinese Mechanical Engineeringe, 2nd ed.; Science and Technology of China Press: Beijing, China, 2016. [Google Scholar]
- Zhang, S.Y.; Xu, J.H.; Gou, H.W.; Tan, J.R. A research review on the key technologies of intelligent design for customized products. Engineering 2017, 3, 631–640. [Google Scholar] [CrossRef]
- Neira-Rodado, D.; Ortíz-Barrios, M.; De la Hoz-Escorcia, S.; Paggetti, C.; Noffrini, L.; Fratea, N. Smart product design process through the implementation of a fuzzy Kano-AHP-DEMATEL-QFD approach. Appl. Sci. 2020, 10, 1792. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez-Parada, L.; Mayuet, P.F.; Gámez, A.J. Custom design of packaging through advanced technologies: A case study applied to apples. Materials 2019, 12, 467. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, C.-H.; Chen, C.-H.; Lin, C.; Li, F.; Zhao, X. Developing a quick response product configuration system under Industry 4.0 based on customer requirement modelling and optimization method. Appl. Sci. 2019, 9, 5004. [Google Scholar] [CrossRef] [Green Version]
- Jimeno-Morenilla, A.; Sánchez-Romero, J.S.; Salas-Pérez, F. Augmented and virtual reality techniques for footwear. Comput. Ind. 2013, 64, 1371–1382. [Google Scholar] [CrossRef] [Green Version]
- Gao, X.J.; Shi, M.L.; Song, X.G.; Zhang, C. Recurrent neural networks for real-time prediction of TBM operating parameters. Automat. Constr. 2018, 98, 225–235. [Google Scholar] [CrossRef]
- Suh, N.P. The Principle of Design; Oxford University Press: Oxford, UK, 1990. [Google Scholar]
- Yan, W.-J.; Chiou, S.-C. Dimensions of customer value for the development of digital customization in the clothing industry. Sustainability 2020, 12, 4639. [Google Scholar] [CrossRef]
- Clarkson, J.; Eckert, C. Design Process Improvement; Springer: London, UK, 2005. [Google Scholar]
- Adams, K.M. Nonfunctional Requirements in Systems Analysis and Design; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Guo, Q.; Xue, C.Q.; Yu, M.J. A new user implicit requirements process method oriented to product design. J. Comput. Inform. Sci. Eng. 2019, 19, 011010. [Google Scholar] [CrossRef]
- Qi, J.Y.; Zhang, Z.P.; Jeon, S.M.; Zhou, Y.Q. Mining customer requirements from online reviews: A product improvement perspective. Inform. Manag. 2016, 53, 951–963. [Google Scholar] [CrossRef]
- Yan, Y.W.; Huang, C.C.; Wang, Q.; Hu, B. Data mining of customer choice behavior in internet of things within relationship network. Int. J. Inform. Manag. 2018, 50, 566–574. [Google Scholar] [CrossRef]
- Jiang, H.M.; Kwong, C.K.; Park, W.Y.; Yu, K.M. A multi-objective PSO approach of mining association rules for affective design based on online customer reviews. J. Eng. Des. 2018, 29, 381–403. [Google Scholar] [CrossRef]
- Zhou, F.; Jiao, J.R.; Linsey, J.S. Latent customer needs elicitation by use case analogical reasoning from sentiment analysis of online product reviews. J. Mech. Des. 2015, 137, 071401. [Google Scholar] [CrossRef]
- Song, W.Y.; Ming, X.G.; Xu, Z.T. Integrating Kano model and grey–Markov chain to predict customer requirement states. Proc. Inst. Mech. Eng. B 2013, 227, 1232–1244. [Google Scholar] [CrossRef]
- Raharjo, H.; Xie, M.; Brombacher, A.C. A systematic methodology to deal with the dynamics of customer needs in quality function deployment. Expert. Syst. Appl. 2011, 38, 653–3662. [Google Scholar] [CrossRef]
- Min, H.; Yun, J.; Geum, Y. Analyzing dynamic change in customer requirements: An approach using review-based Kano analysis. Sustainability 2018, 10, 746. [Google Scholar] [CrossRef] [Green Version]
- Fan, W.; Li, J.; Ma, S.; Tang, N.; Yu, W. Towards certain fixes with editing rules and master data. VLDB J. 2012, 21, 213–238. [Google Scholar] [CrossRef] [Green Version]
- Grzymala-Busse, J.Z.; Goodwin, L.K.; Grzymala-Busse, W.J.; Zheng, X. Handling missing attribute values in preterm birth data sets. In Rough Sets, Fuzzy Sets, Data Mining, and Granular Computing, Proceedings of the International Workshop on Rough Sets, Fuzzy Sets, Data Mining, and Granular-Soft Computing, Regina, SK, Canada, 31 August–3 September 2005; Springer: Berlin, Germany, 2005; pp. 342–351. [Google Scholar] [CrossRef] [Green Version]
- Schneider, T. Analysis of incomplete climate data: Estimation of mean values and covariance matrices and imputation of missing values. J. Clim. 2001, 14, 853–871. [Google Scholar] [CrossRef]
- Honaker, J.; Gary King, G.; Blackwell, M. Amelia II: A program for missing data. J. Stat. Softw. 2011, 45, 1–47. [Google Scholar] [CrossRef]
- Zhang, S. Nearest neighbor selection for iteratively kNN imputation. J. Syst. Softw. 2012, 85, 2541–2552. [Google Scholar] [CrossRef]
- Kim, K.; Kim, B.; Yi, G. Reuse of imputed data in microarray analysis increases imputation efficiency. BMC Bioinform. 2004, 5, 160. [Google Scholar] [CrossRef] [Green Version]
- Gheyas, I.A.; Smith, L.S. A neural network-based framework for the reconstruction of incomplete data sets. Neurocomputing 2010, 73, 16–18. [Google Scholar] [CrossRef]
- Shigeyuki, O.; Sato, M.A.; Takemasa, I.; Monden, M.; Matsubara, K.; Ishii, S. A Bayesian missing value estimation method for gene expression profile data. Bioinformatics 2003, 19, 2088–2096. [Google Scholar] [CrossRef]
- Meng, F.; Cai, C.; Yan, H. A bicluster-based Bayesian principal component analysis method for microarray missing value estimation. IEEE J. Biomed. Health Inform. 2014, 18, 863–871. [Google Scholar] [CrossRef]
- Stekhoven, D.J.; Bühlmann, P. MissForest—Non-parametric missing value imputation for mixed-type dat. Bioinformatics 2012, 28, 112–118. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Troyanskaya, O.; Cantor, M.; Sherlock, G. Missing value estimation methods for DNA microarrays. Bioinformatics 2001, 17, 520–525. [Google Scholar] [CrossRef] [Green Version]
- Dinh, T.; Huynh, V.N. k-CCM: A center-based algorithm for clustering categorical data with missing values. In Modeling Decisions for Artificial Intelligence, Proceedings of the International Conference on Modeling Decisions for Artificial Intelligence, Palma de Mallorce, Spain, 15–18 October 2018; Springer: Cham, Switzerland, 2018; pp. 267–270. [Google Scholar] [CrossRef]
- Bertsimas, D.; Pawlowski, C.; Zhuo, Y.D. From predictive methods to missing data imputation: An optimization approach. J. Mach. Learn. Res. 2017, 18, 7133–7171. [Google Scholar]
- Ye, C.; Wang, H.Z.; Li, J.Z.; Gao, H.; Cheng, S.Y. Crowdsourcing-enhanced missing values imputation based on Bayesian network. In Database Systems for Advanced Applications, Proceedings of the International Conference on Database Systems for Advanced Applications, Dallas, TX, USA, 16–19 April 2016; Springer: Cham, Switzerland, 2016; pp. 67–81. [Google Scholar] [CrossRef]
- Wang, H.; Qi, Z.; Shi, R.; Li, J.; Gao, H. COSSET+: Crowdsourced missing value imputation optimized by knowledge base. J. Comput. Sci. Technol. 2017, 32, 845–857. [Google Scholar] [CrossRef]
- Zhang, S.; Li, X.; Zong, M.; Zhu, X.; Cheng, D. Learning k for kNN classification. ACM Trans. Intell. Syst. Technol. 2017, 8, 43. [Google Scholar] [CrossRef] [Green Version]
- Shakhnarovish, G.; Darrell, T.; Indyk, P. Nearest-neighbor Methods in Learning and Vision; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Chen, P.; Liu, S. An improved DAG-SVM for multi-class classification. In Proceedings of the International Conference on Natural Computation, Tianjin, China, 14–16 August 2009; IEEE: Los Alamitos, CA, USA, 2009; pp. 460–462. [Google Scholar]
- Hruschka, E.R.; Hruschka, E.R.; Ebecken, N.F.F. Bayesian networks for imputation in classification problems. J. Intell. Inf. Syst. 2007, 29, 231–252. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Model/Methodology | Continuous Variables | Categorical Variables | Application |
|---|---|---|---|---|
| Rule-based | Imputation with master data and a class of editing rules [20] | √ | Two real-word datasets | |
| Five strategies used for different attributes [21] | √ | √ | Preterm birth datasets | |
| Statistics-based | Estimation of mean values and covariance matrices [22] | √ | Surface temperature data | |
| Expectation maximization with bootstrapping [23] | √ | √ | Amelia II (software) | |
| Model-based | Gray KNN [24] | √ | √ | Six real-world datasets |
| Sequential KNN [25] | √ | DNA microarray analysis | ||
| Generalized regression neural network (GRNN) [26] | √ | 30 synthetic datasets + 67 public datasets + one new real-world dataset | ||
| Bayesian principal component analysis (BPCA) [27] | √ | Gene expression profile data | ||
| Bicluster-based BPCA [28] | √ | DNA microarray analysis | ||
| Random forest [29] | √ | √ | Four datasets for continuous, three datasets for categorical, and three datasets for mixed variables | |
| Singular value decomposition (SVD) with KNN [30] | √ | DNA microarray analysis | ||
| Kernel density clustering combined with decision tree [31] | √ | Eight real-world datasets | ||
| Formal optimization framework with KNN, SVM, and decision trees [32] | √ | √ | 84 real-word datasets | |
| Human–computer interaction | Crowdsourcing optimized by knowledge base [33] | √ | √ | Two real-world datasets |
| Crowdsourcing with Bayesian network [34] | √ | Two real-world datasets |
| Method | RMSE0 | RMSE | Time (s) | Ang | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10% | 30% | 50% | 10% | 30% | 50% | 10% | 30% | 50% | 10% | 30% | 50% | |
| KNN-GRNN | 0.53 | 0.52 | 0.56 | 0.58 | 0.57 | 0.59 | 33 | 111 | 222 | 0.01 | 0.02 | 0.05 |
| GRNN | 0.59 | 0.56 | 0.56 | 0.61 | 0.59 | 0.59 | 73 | 254 | 479 | 0.03 | 0.10 | 0.13 |
| KNN-SVD | 0.48 | 0.51 | 0.52 | 0.57 | 0.57 | 0.57 | 0.27 | 0.29 | 0.30 | 0.01 | 0.03 | 0.04 |
| SVD | 0.55 | 0.55 | _ | 0.64 | 0.60 | _ | <0.01 | <0.01 | _ | 0.02 | 0.04 | _ |
| KNN-BBPCA | 0.49 | 0.49 | 0.49 | 0.53 | 0.52 | 0.54 | 74 | 91 | 88 | 0.01 | 0.03 | 0.04 |
| BBPCA | 0.51 | 0.51 | 0.52 | 0.52 | 0.53 | 0.54 | 85 | 89 | 62 | 0.01 | 0.03 | 0.05 |
| Method | RMSE | Ang | FSN | Time (s) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10% | 30% | 50% | 10% | 30% | 50% | 10% | 30% | 50% | 10% | 30% | 50% | |
| Cold-start scenario 1: 10 incomplete FRs without reference | ||||||||||||
| KNN-SVM | 0.44 | 0.52 | 0.63 | 0.04 | 0.09 | 0.17 | _ | _ | _ | 1.13 | 0.51 | 1.56 |
| KNN-Bay | 0.58 | 0.56 | 0.78 | 0.06 | 0.14 | 0.26 | _ | _ | _ | 2.19 | 1.92 | 3.19 |
| KNN-Tree | 0.56 | 0.53 | 0.76 | 0.11 | 0.14 | 0.30 | _ | _ | _ | 0.19 | 0.11 | 0.18 |
| KNN | _ | _ | _ | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| GRNN | 0.59 | 0.71 | 0.66 | 0.04 | 0.22 | 0.26 | _ | _ | _ | 9 | 11 | 18 |
| Warm-start scenario 1: 10 incomplete FRs with rest 81 complete FRs for reference | ||||||||||||
| KNN-SVM | 0.09 | 0.18 | 0.23 | 4 × 10‒5 | 1 × 10‒3 | 1 × 10‒3 | 1.00 | 1.00 | 1.00 | 0.33 | 0.69 | 0.60 |
| KNN-Bay | 0.28 | 0.37 | 0.38 | 1 × 10‒3 | 2 × 10‒3 | 4 × 10‒3 | 0.99 | 0.97 | 0.96 | 1.36 | 1.68 | 1.81 |
| KNN-Tree | 0.32 | 0.33 | 0.29 | 1 × 10‒3 | 3 × 10‒3 | 5 × 10‒3 | 0.99 | 0.97 | 0.96 | 0.24 | 0.27 | 0.28 |
| KNN | 0.49 | 0.53 | 0.50 | 1 × 10‒3 | 2 × 10‒3 | 4 × 10‒3 | 0.98 | 0.96 | 0.96 | 0.19 | 0.21 | 0.20 |
| GRNN | 0.63 | 0.56 | 0.60 | 3 × 10‒3 | 6 × 10‒3 | 1 × 10‒2 | 0.98 | 0.97 | 0.96 | 5 | 15 | 24 |
| Cold-start scenario 2: 50 incomplete FRs without reference | ||||||||||||
| KNN-SVM | 0.31 | 0.39 | 0.42 | 0.01 | 0.02 | 0.04 | 1.00 | 0.99 | 0.99 | 0.50 | 0.49 | 0.42 |
| KNN-Bay | 0.56 | 0.59 | 0.59 | 0.06 | 0.10 | 0.17 | 0.95 | 0.86 | 0.92 | 3.54 | 2.77 | 2.18 |
| KNN-Tree | 0.51 | 0.59 | 0.55 | 0.04 | 0.08 | 0.14 | 0.96 | 0.90 | 0.90 | 0.63 | 0.21 | 0.16 |
| KNN | 0.68 | 0.62 | 0.61 | 0.07 | 0.15 | 0.17 | 0.95 | 0.92 | 0.93 | 0.08 | 0.07 | 0.05 |
| GRNN | 0.66 | 0.66 | 0.67 | 0.09 | 0.16 | 0.21 | 0.94 | 0.91 | 0.91 | 29 | 95 | 127 |
| Warm-start scenario 2: 50 incomplete FRs with rest 41 complete FRs for reference | ||||||||||||
| KNN-SVM | 0.14 | 0.30 | 0.30 | 3 × 10‒3 | 6 × 10‒3 | 1.2 × 10‒2 | 1.00 | 0.95 | 0.92 | 0.76 | 0.78 | 0.80 |
| KNN-Bay | 0.26 | 0.31 | 0.36 | 5 × 10‒3 | 9 × 10‒3 | 1.0 × 10‒2 | 0.98 | 0.94 | 0.91 | 1.87 | 1.85 | 1.86 |
| KNN-Tree | 0.18 | 0.33 | 0.33 | 6 × 10‒3 | 9 × 10‒3 | 1.5 × 10‒2 | 0.97 | 0.94 | 0.91 | 0.29 | 0.30 | 0.30 |
| KNN | 0.29 | 0.53 | 0.49 | 5 × 10‒3 | 9 × 10‒3 | 1.5 × 10‒2 | 0.98 | 0.94 | 0.90 | 0.22 | 0.27 | 0.23 |
| GRNN | 0.46 | 0.53 | 0.55 | 1 × 10‒2 | 2 × 10‒2 | 41 × 10‒3 | 0.97 | 0.94 | 0.89 | 26 | 73 | 119 |
| Index | FR | Ground Truth | Predicted Values in Different Cases | |||
|---|---|---|---|---|---|---|
| Case 1 | Case 2 | Case 3 | Case 4 | |||
| r1 | Hoisting motor power | 10 kW | 11 kW | |||
| r2 | Hoisting rope size | ϕ 10 | ϕ 10 | ϕ 10 | ||
| r3 | Gear of hoisting machine | Gearless | Gearless | |||
| r4 | Number of hoisting ropes | 2 | 4 | |||
| r5 | Number of passengers | 9 | 8 | |||
| r6 | Door opening | Front and rear opening | Front and rear opening | |||
| r7 | Number of stops | 15 | ||||
| r8 | Counterweight position | Side | Side | Side | ||
| r9 | Compensating device | Rope | Rope | |||
| r10 | Number of guides | 2 | 2 | |||
| r11 | Length of hoisting rope | 1219 | 1188.4 | |||
| r12 | Rated capacity | 900 kg | 840 kg | |||
| r13 | Speed | 4.1 m/s | 3.64 m/s | 3.64 m/s | ||
| r14 | Car weight | 1053 | 972.4 | |||
| r15 | Car depth | 1328 | 1328 | |||
| r16 | Car width | 1534 | 1570.6 | |||
| r17 | Car height | 2729 | 2795.8 | |||
| r18 | Shaft depth | 2076 | 2130.3 | 2119.3 | ||
| r19 | Shaft height | 43,086 | ||||
| r20 | Shaft width | 1997 | ||||
| r21 | Door width | 939 | 1043.2 | 1024.9 | ||
| r22 | Door height | 2232 | 2070.4 | 2057.2 | ||
| r23 | Door offset distance | 0 | ||||
| r24 | Machine room height | 1638 | ||||
| r25 | Headroom height | 3386 | 3974.2 | |||
| r26 | Pit depth | 4024 | 4845.2 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, Y.; Zhang, S.; Qiu, L.; Wang, Z.; Zhang, L. A Layered KNN-SVM Approach to Predict Missing Values of Functional Requirements in Product Customization. Appl. Sci. 2021, 11, 2420. https://doi.org/10.3390/app11052420
Gu Y, Zhang S, Qiu L, Wang Z, Zhang L. A Layered KNN-SVM Approach to Predict Missing Values of Functional Requirements in Product Customization. Applied Sciences. 2021; 11(5):2420. https://doi.org/10.3390/app11052420
Chicago/Turabian StyleGu, Ye, Shuyou Zhang, Lemiao Qiu, Zili Wang, and Lichun Zhang. 2021. "A Layered KNN-SVM Approach to Predict Missing Values of Functional Requirements in Product Customization" Applied Sciences 11, no. 5: 2420. https://doi.org/10.3390/app11052420
APA StyleGu, Y., Zhang, S., Qiu, L., Wang, Z., & Zhang, L. (2021). A Layered KNN-SVM Approach to Predict Missing Values of Functional Requirements in Product Customization. Applied Sciences, 11(5), 2420. https://doi.org/10.3390/app11052420