1. Introduction
Words in spoken and written languages can have multiple meanings for each word and, thus, could be ambiguous. The intended meaning of a word (
sense) depends strongly on its context. Word Sense Disambiguation (WSD) is the task of predicting the correct sense of a word that has multiple senses given its context [
1]. Many Computational Linguistics’ applications depend on the performance of WSD, such as Machine Translation, Text Summarization, Information Retrieval, and Question Answering [
2]. The Arabic language is particularly challenging for WSD. It was shown in [
3] that 43% of Arabic words that have diacritic marks are ambiguous. Moreover, that percentage increases to 72% when the diacritic marks are missing, which is the case for most written Arabic text [
4]. This is compared to 32% for the English language [
5].
We note here three main challenges in Arabic WSD. First, most written text does not have diacritic marks. As a result, the level of ambiguity for each word can increase. For example, the word ”عَلَمْ“ (meaning flag) and the word ”عِلْمْ“ (meaning science) are both written as ”علم“ . Secondly, even when diacritic marks are present, many words can have several possible part-of-speech (POS) tags that lead to different meanings. For example, the word ”عَرَضْ’“ can have the POS tag
verb (leading to the meaning of “showing something”). It can also have the POS tag
noun (leading to the meaning of “impermanent”). Third, a word with both a POS tag and diacritic marks can still have several senses depending on its context. For example, the word “اِسْتَعْرَضَ“ with POS tag
verb has the meaning of “parade” in the context “استعرض نفسه“ while having the meaning of “inspect” in the context “استعرض الجند“. In addition, Arabic is an agglutinative language that adds parts of speech to the stems or roots of words to give new meanings [
6]. For instance, the word “بالشارع“ (in the street) has a stem “شارع“ (a street) and two prefixes, “بِ“ (in) and “ال“ (the), which is the definite article. This problem has been addressed in the preprocessing phase in our work, which will be discussed shortly.
Bidirectional Encoder Representation from Transformers (BERT) [
7] is a neural language model based on transformer encoders [
8]. Recent Arabic Computational Linguistics’ studies show a large performance enhancement when pretrained BERT models are fine-tuned to perform many Arabic Natural Language Processing (NLP) tasks, for example, Question Answering (QA), Sentiment Analysis (SA), and Named Entity Recognition (NER) [
9,
10]. This performance enhancement stems from the fact that BERT can generate contextual word embeddings for each word in a context. These embeddings were shown to encode syntactic, semantic, and long-distance dependencies of the sentences [
11], thus making them ideal for many NLP tasks.
Contextual embedding methods (e.g., BERT [
7], Embeddings from Language Models (ELMO) [
12], and Generative Pre-trained Transformer (GPT) [
13]) learn sequence-level semantics by considering the sequence of all the words in the input sentence. In particular, BERT is trained to predict the masked word(s) of the input sentence; to do this, BERT learns
self-attention to weigh the relationship between each word in the input sentence and the other words in the same sentence. Each word then has a vector that represents the relationship with other words in the input sentence. Those vectors are used to generate word embedding, so the generated embeddings for each word depends on the other words in a given sentence. This is unlike Glove [
14] and Word2Vec [
15] that represent the word using a fixed embedding, regardless of its context. These traditional models depend on the cooccurrence of these words in the hole corpus. If two words usually have similar words in different contexts, they will have a similar representation.
WSD is classified into three main categories: supervised WSD, unsupervised WSD, and knowledge-based WSD. Knowledge-based WSD methods usually utilize language resources such as knowledge-graphs and dictionaries to solve the WSD problem. Knowledge-based WSD can be further subcategorized into graph-based approaches and gloss-based approaches [
16]. Graph-based approaches utilize language knowledge-graphs, such as WordNet, to represent the sense by its surrounding tokens in that graph. Gloss-based approaches measure the semantic similarity or the overlap between the context of the target word and the dictionary definition of that word (gloss of the word). Gloss-based methods require context-gloss datasets. In this paper, we explore utilizing pretrained BERT models to better represent gloss and context information in gloss-based Arabic WSDs. Fortunately, there are pretrained BERT models available for Arabic [
9,
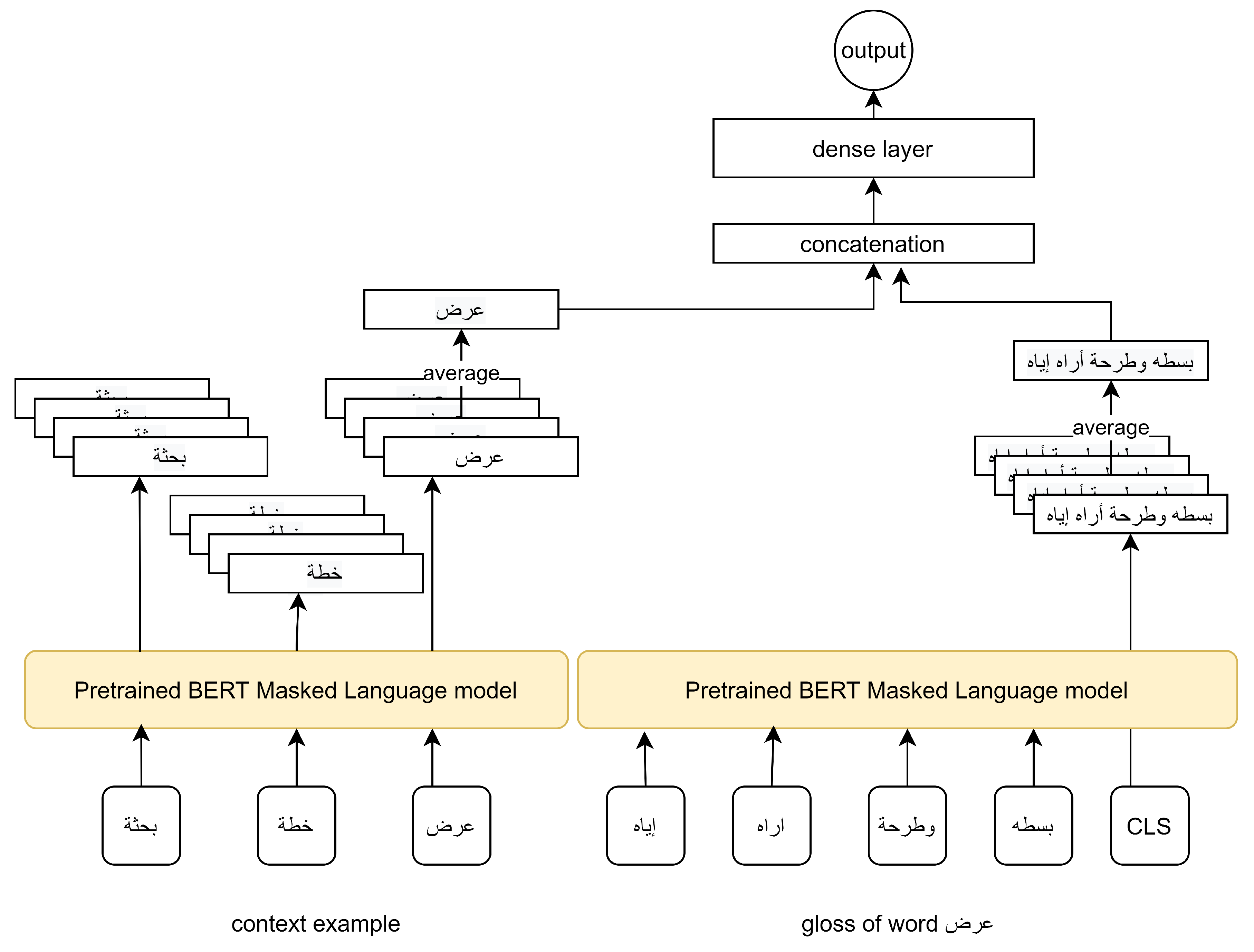
10]. We utilized these pretrained models to build two gloss-based WSD models. The first model uses the pretrained BERT models as a feature extractor without fine-tuning BERT layers to generate a contextual word embedding of the target word in its context. We also used it to generate a sentence vector representation of the gloss sentence. These representations’ vectors were then fed to a trainable dense layer to perform supervised WSD. In the second model, we fine-tuned BERT layers by training them with a
sentence pair classification objective. Our experiments showed that we outperform many of the state-of-the-art Arabic knowledge-based WSDs. The evaluation of WSD models suffers from a lack of standard benchmark datasets [
16]. Each author tests on a different and small (around 100 ambiguous words) dataset, which makes it difficult to compare results. We attempt to fix this issue by creating a publicly available benchmark dataset. We hope that such a dataset can help ease evaluating and comparing different WSD techniques.
The rest of the paper is organized as follows. In
Section 2, we discuss the related work.
Section 3 introduces the context-gloss benchmark. The background is presented in
Section 4.
Section 5 describes the proposed models. In
Section 6,
Section 7 and
Section 8, we present our experimental setup, results, and discussion. Finally, we conclude our paper in
Section 9.
2. Related Work
As mentioned previously, knowledge-based WSD is categorized into graph-based approaches and gloss-based approaches [
16]. Graph-based approaches depend on language knowledge graphs such as WordNet to represent the sense by its surrounding tokens in that graph. For example, the authors in [
17] introduced a
retrofit algorithm that utilized Arabic WordNet along with
Glove [
14] and
Word2Vec [
15] to generate context-dependent word vectors that carry sense information. Finally, they used cosine similarity between the generated word vector and vectors generated for WordNet synsets of that word and selected the sense with the highest similarity score. In [
18], the authors utilized Arabic WordNet (AWN) to map words to
concepts. A concept was defined as a specific word sense. They further utilized the English WordNet to extend the Arabic one by employing Machine Translation for the missing words in AWN. A concept was then selected for a target word by comparing the context of the target word to neighbors of the concept in the extended WordNet. Concepts with high match to the context were selected as the correct sense. In [
19], the authors used AWN to generate a list of words that can be potentially ambiguous. For each ambiguous word, they found Wikipedia articles that correspond to the different senses of those words. Those articles were then converted to real vectors by tf-idf [
20]. They also generated a context vector by tf-idf of the word in its context. Finally, they used cosine similarity between the two vectors and selected the sense with the highest similarity score.
The second type of knowledge base approaches is gloss-based approaches. These methods measure the semantic similarity or the overlap between the context of the target word and the dictionary definition of that word (gloss of the word). The authors in [
21] used the
Lesk algorithm to measure the relatedness of the target word’s context to its definition. They used AWN as a source for the word gloss. The authors of [
22] combined unsupervised and knowledge-based approaches. They used a string matching algorithm to match the root of salient words that appear in many contexts of a particular sense with the gloss definition. The authors of [
23] employed word2vec [
15] to generate a vector representation for the target word’s context sentence and the gloss sentence. Then, cosine similarity was used to match the gloss vector and the context vector. The authors in [
24] used Rough Set Theory and semantic short text similarity to measure the semantic relatedness between the target word’s context and multiple possible concepts (gloss). Recently, The authors in [
25] used FLAIR [
26], a character-level language model, to generate sentence representation vectors for both context and gloss sentences. The sentence’s vector was calculated by taking the mean of its word vectors, causing a loss of information, especially when the sequence is long. Cosine similarity was then used to measure the similarity between the word context sentence and the gloss sentence.
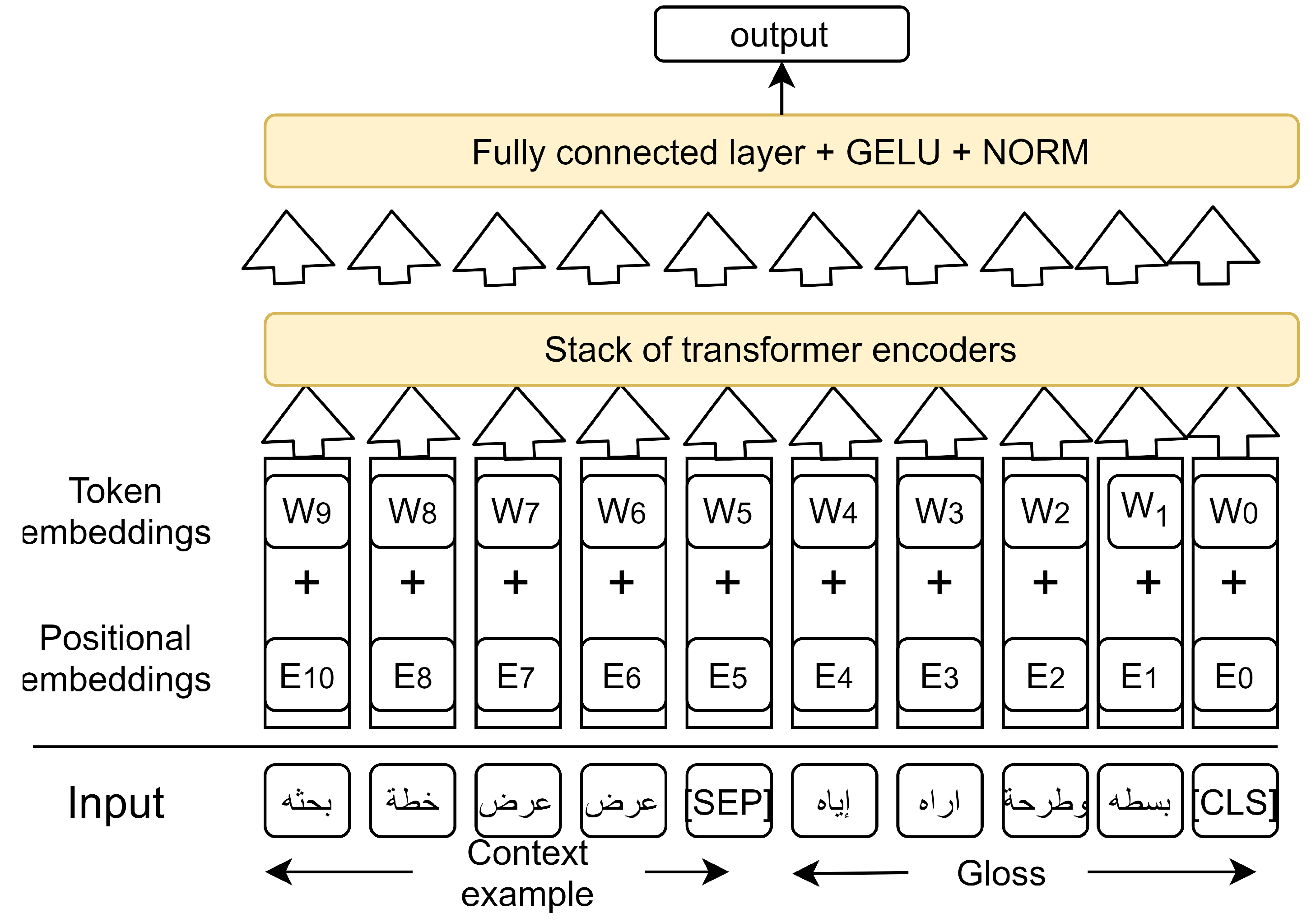
3. Benchmark
Arabic gloss WSD suffers from the lack of context-gloss pair datasets [
16]. Arabic Word Net (AWN), which is the only available gloss dataset, contains only word senses with gloss definitions but lacks context examples for these senses [
27]. Due to this limitation in AWN, we created a new Arabic WSD benchmark. This dataset is extracted from the “Modern Standard Arabic Dictionary” [
28]. To the best of our knowledge, our benchmark is the only available Arabic context-gloss pair dataset. It consists of 15,549 senses for 5347 unique words with an average of 3 senses for each word.
Figure 1 shows the histogram of sense counts per word. We can see that most of the words (4000+) have 2 to 4 senses, that about 750 word are between 4–6 senses per word, and that the count decreases as the number of senses increases. Each record in the dataset is a tuple of three elements: a word sense, a context example, and a definition of that word sense. In
Table 1, we present the statistics of the dataset. This dataset is available online (
https://github.com/MElrazzaz/Arabic-word-sense-disambiguation-bench-mark.git, accessed on 10 March 2021).
Table 2 shows examples of records in the benchmark’s dataset. We believe that the benchmark can contribute to standardizing the evaluation of WSD models.
7. Results
In this section, we present our experimental results.
Table 8 summarizes the results of Model I and Model II on the test set as measured by precision, recall, and the F1-score. For Model I and Model II, we experimented with three different configurations as follows:
AraBERTv2 as a pretrained BERT model without tokenizing the input sentences.
AraBERTv2 as a pretrained BERT model with tokenizing the input sentences.
ArBERT as a pretrained BERT model without tokenizing the input sentences.
As can be seen in
Table 8, both configurations that use AraBERTv2 seem to outperform ArBERT as the pretained BERT model. This holds for both Model I and Model II. For the tokenization configuration, Model II enhances the precision from 92% to 96% while decreasing the recall from 87% to 67%, which affects the F1-score and hence decreases from 89% to 79%. On the other hand, Model I is adversely affected by tokenization, leading to a decrease in precision from 69% to 67% and in F1-score from 74% to 72%. We can also see that Model II always outperforms Model I.
Table 9 compares our proposed models against other embedding based models that depend on representing gloss and the context sentences in the vector space such as in our model. We compare our proposed models with two models, Laatar [
25] and Laatar [
23] which are the most recent Arabic WSD works. The test data of the two models are not available; thus, in order to make a fair comparison, we redeveloped their models and tested them on our benchmark. Laatar [
25] used FLAIR [
26] to generate word embedding. FLAIR is a pretrained character level language model. Laatar [
25] represents each sentence by the mean of its words vectors. The authors in [
23] used Word2Vec [
15] language model to represent the words of the sentence in the vector space and then they represented the sentence by adding its words vector representation. After calculating the sentences’ vectors, both models measure the cosine similarity between the context sentence vector and the gloss sentences vector and choose the gloss with the highest similarity score.
Table 9 shows that our models outperform other embedding-based models in terms of precision, recall and F1 score.
Table 9 also shows the original paper results of other models according to their test set. We performed McNemar’s significance test [
32] between Model II and Laatar [
25] and between Model II and Laatar [
23]; we find that Model II is significantly better than Laatar [
25] and Laatar [
23] and that the
p-value is less than 0.01.
In
Table 10, we present the performance in comparison to other Arabic Knowledge based WSDs.
As shown in
Table 10, Model II with non-tokenized inputs outperforms all other Arabic knowledge-based WSD as measured by F1-score.










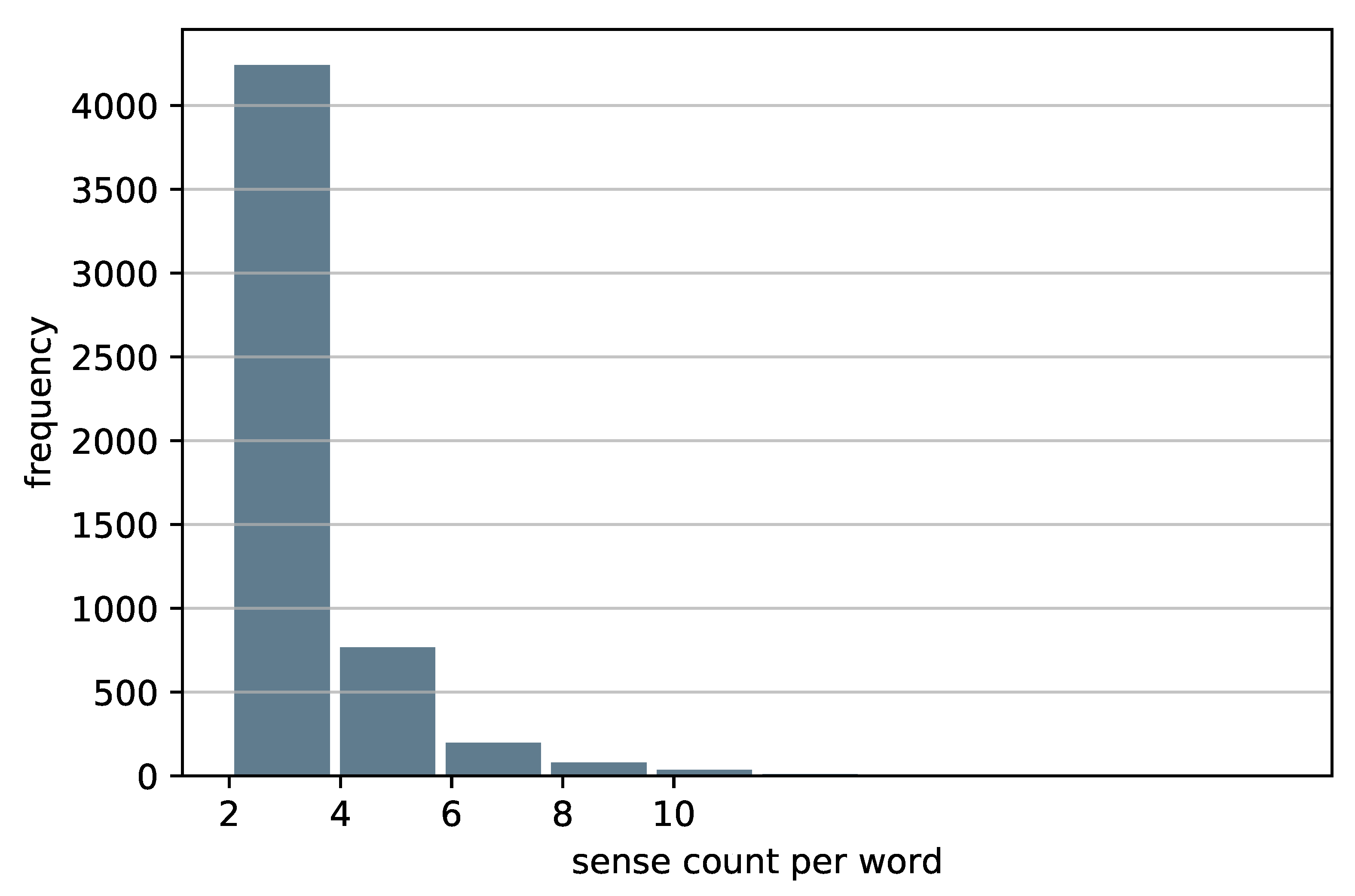{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}