1. Introduction
As the demand for untact technology in various fields increases and machine learning technologies advance, the need for computer-assisted second language (L2) learning contents has increased [
1,
2,
3,
4]. The widely used method for learning a second language is to practice listening, repeating, and speaking language. A GenieTutor, one of the second language (English at present) systems, plays the role of a language tutor by asking questions to the learners, recognizing their speech, which is answered in second language, checking grammatical errors, evaluating the learners’ spoken English proficiency, and providing feedbacks to help L2 learners practice their English proficiency. The system comprises several topics, and the learners can select a topic to have communication with the system based on the role-play scenarios. After the learner finishes the speaking of each sentence, the system measures various fluency factors such as pronunciation score, word score, grammar error, stress pattern, and intonation curve, and provides feedback to learners about them compared with the fluency factors of the native speakers [
5,
6,
7].
The stress and rhythm scores are one of the important factors for fluency evaluation in English speaking, and they are computed by comparing the stress pattern and the rhythm distribution of the L2 speaker with those of native speakers. However, in some cases, the phonemic sequences of speeches uttered by the L2 speaker and the native speaker are recognized differently according to the pronunciation of the learner. Learners may mispronounce or pronounce different words from the referred one. In such cases, the stress and rhythm scores cannot be computed using the previous pattern comparison methods [
8,
9,
10,
11,
12,
13,
14].
In order to solve this problem, we proposed a dynamic time-warping (DTW)-based stress and rhythm scores measurement method. We aligned the learner’s phonemic sequence with the native speaker’s phonemic sequence by using the DTW approach, and then computed the stress patterns and rhythm distributions from the aligned phonemic sequences [
15,
16,
17,
18,
19]. By using the aligned phonemic sequences, we detected the learner’s pronunciation error phonemes and computed an error-tagged stress pattern and scores which are deducted by the presence of error phonemes if there is an erroneous phoneme. We computed two stress scores: a word stress score and a sentence stress score. The word stress score is measured by comparing the stress patterns of the content words, and the sentence stress score was computed for the entire sentence. The rhythm scores are measured by computing the mean and standard deviation of the time distances between stressed phonemes. Two stress scores and rhythm scores are used to evaluate the English-speaking proficiency of the learner with other fluency features.
The proposed method uses an automatic speech recognition (ASR) system to recognize the speech uttered by the L2 learner and perform a forced-alignment to obtain the time-aligned phonemic sequences. Deep learning has been applied successfully to ASR systems by relying on hierarchical representations that are commonly learned with a large amount of training data. However, non-native speakers’ speech significantly degrades the performance of the ASR due to the pronunciation variability in non-native speech, and it is difficult to collect enough non-native data to train. For better performance of the ASR for non-native speakers, we augment the non-native training speech dataset by using a variational autoencoder-based speech conversion model and train an acoustic model (AM) with the augmented training dataset. Data augmentation has been proposed as a method to generate additional training data, increase the quantity of training data, and reduce overfitting for ASR systems [
20,
21,
22,
23,
24,
25].
The speech conversion (SC) technique is to convert the speech signal from a source domain to that of a target domain, while preserving its linguistic content information. Variational autoencoder (VAE) is a widely used method for speech modeling and conversion. In the VAE framework, the spectral features of the speech are encoded to a speaker-independent latent variable space. After sampling from the latent variable space, sampled features are decoded back to the speaker-dependent spectral features. A conditional VAE, one of the VAE-based speech conversion methods, employs speaker identity information to feed the decoder with the sampled features. With this conditional decoder, the VAE framework can reconstruct or convert input speech by choosing speaker identity information [
26,
27,
28,
29,
30,
31,
32,
33]. Recently, generative adversarial networks (GANs)-based SC and some frameworks that jointly train a VAE and GAN were proposed [
34,
35,
36,
37,
38,
39,
40,
41,
42,
43,
44]. However, most conversion frameworks usually assume and learn a deterministic or unimodal mapping, so their significant limitation is the lack of diversity in the converted outputs.
We build up the proposed conversion model based on the VAE, due to its potential in employing latent space to represent hidden aspects of speech signal. In order to improve speech conversion without conditional information and learn more meaningful speaker characteristic information, we proposed a VAE-based multimodal unsupervised speech conversion method. In the proposed method, we assume that the spectral features of speech are divided into a speaker-invariant content factor (phonetic information in speech) and a speaker-specific style factor [
45,
46,
47]. We employ a single shared content encoder network and an individual style encoder network for each speaker to train the encoder models robustly. The encoded content factor is fed into a decoder with a target style factor to generate converted spectral features. By sampling different style factors, the proposed model is able to generate diverse and multimodal outputs. In addition, we train our speech conversion model from nonparallel data because parallel data of the source and target speakers are not available in most practical applications and it is difficult to collect such data. By transferring some speech characteristics and converting the speech, we generate additional training data with nonparallel data and train the AM with the augmented training dataset.
We evaluated the proposed method on the corpus of English read speech for the spoken English proficiency assessment [
48]. In our experiments, we evaluated the fluency scoring ability of the proposed method by measuring fluency scores and comparing them with the fluency scores of native speakers, and the results demonstrate that the proposed DTW-based fluency scoring method can compute stress patterns and measure stress and rhythm scores effectively even if there are pronunciation errors in the learner’s utterances. The spectral feature-related outputs demonstrate that the proposed conversion model can efficiently generate diverse signals while keeping the linguistic information of the original signal. Proficiency evaluation test and speech recognition results with and without an augmented speech dataset also show that the data augmentation with the proposed speech conversion model contributed to improving speech recognition accuracy and proficiency evaluation performance compared to a method employing conventional AMs.
The remainder of this paper is organized as follows.
Section 2 briefly describes the second language learning system used in this work.
Section 3 describes a description of the proposed DTW-based fluency scoring and VAE-based nonparallel speech conversion method. In
Section 4, experimental results are reported, and finally, we conclude and discuss this paper in
Section 5.
2. Previous Work
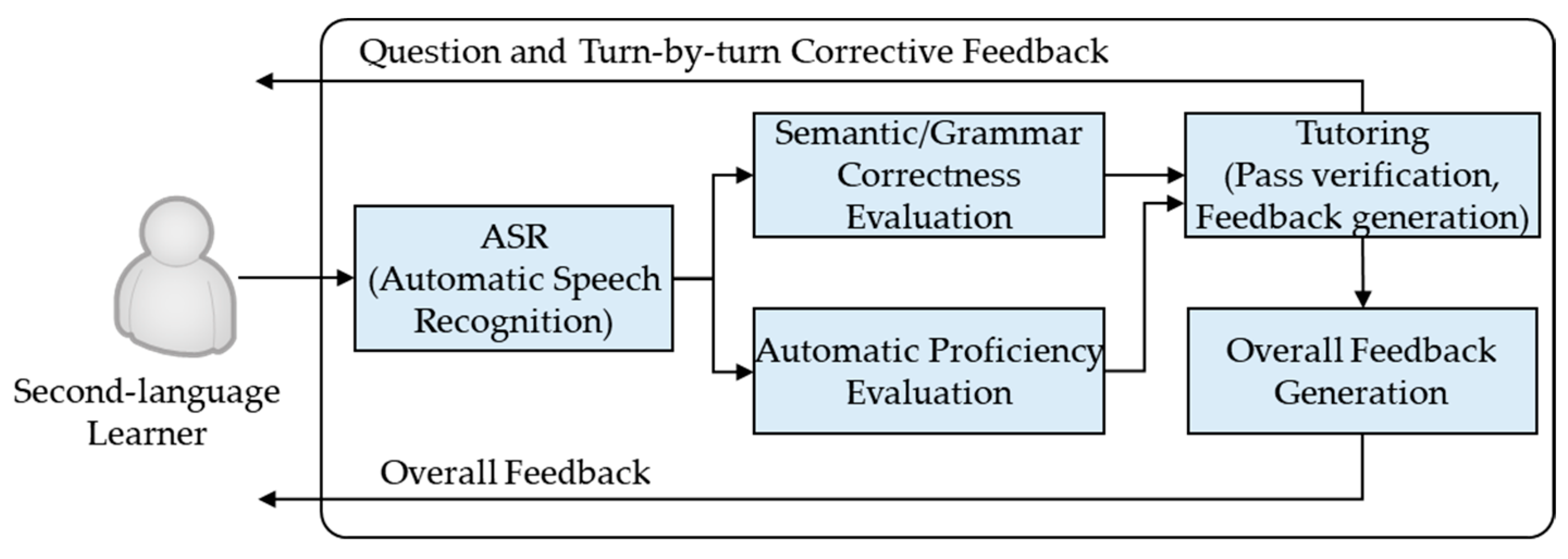
GenieTutor is a computer-assisted second language (English at present) learning system. In order to help learners practice their English proficiency, the system recognizes the learners’ spoken English responses for given questions, checks content properness, automatically checks and corrects grammatical errors, evaluates spoken English proficiency, and provides educational feedback to learners.
Figure 1 shows the schematic diagram of the system [
7].
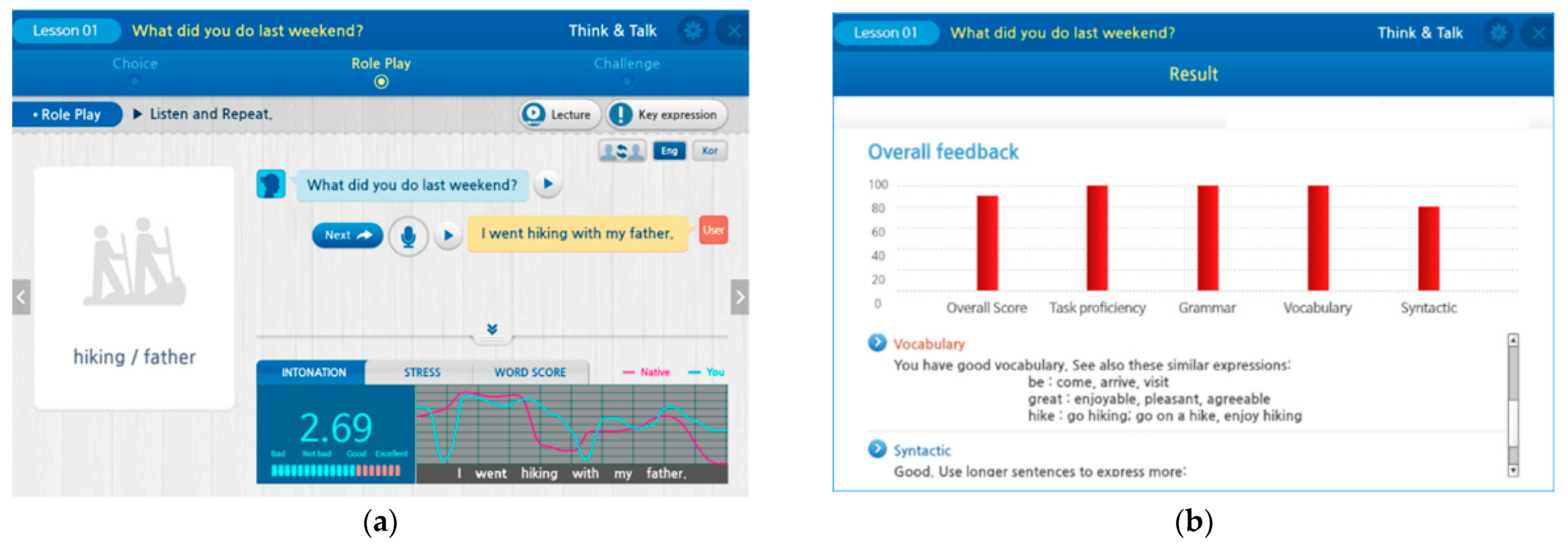
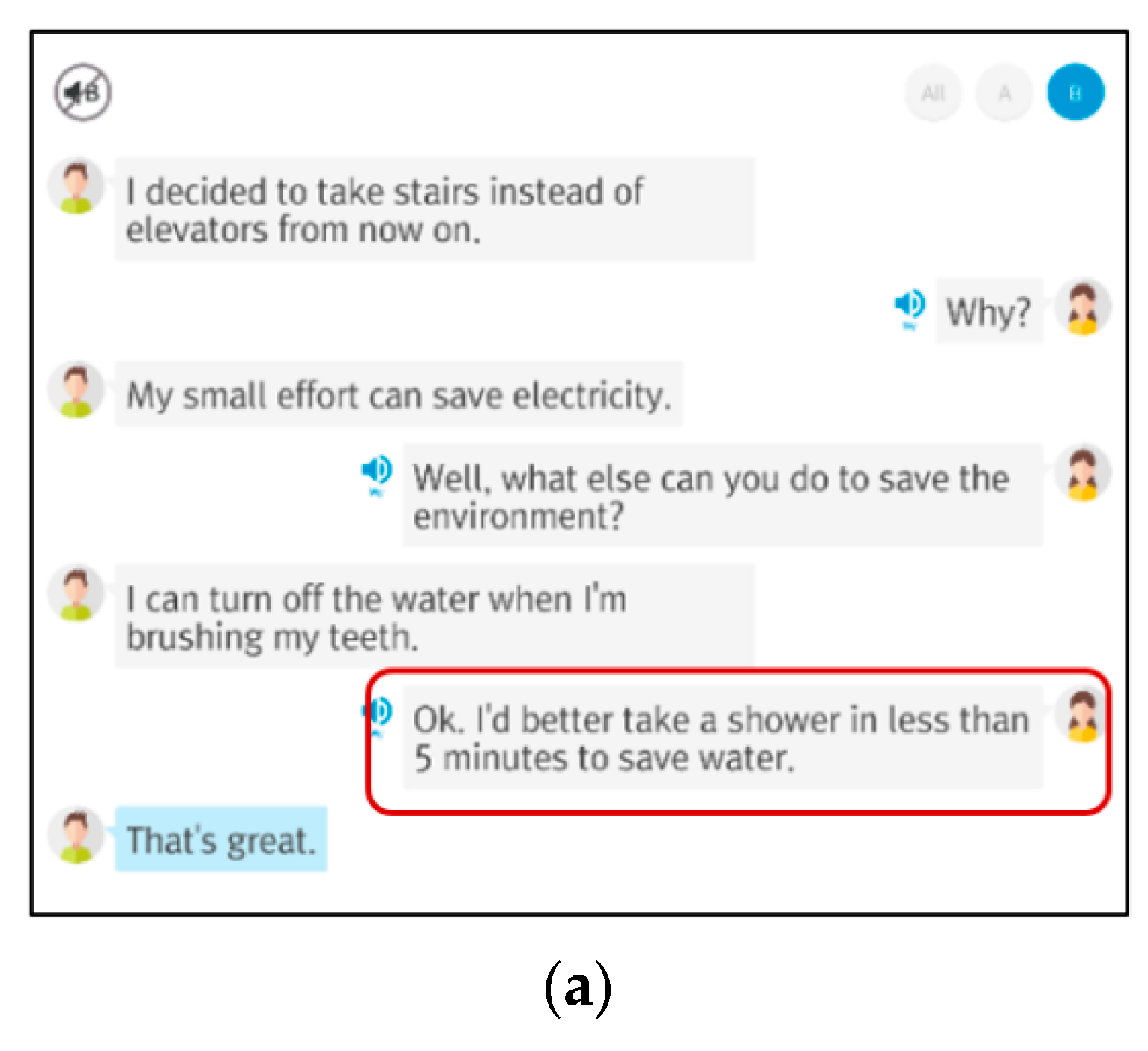
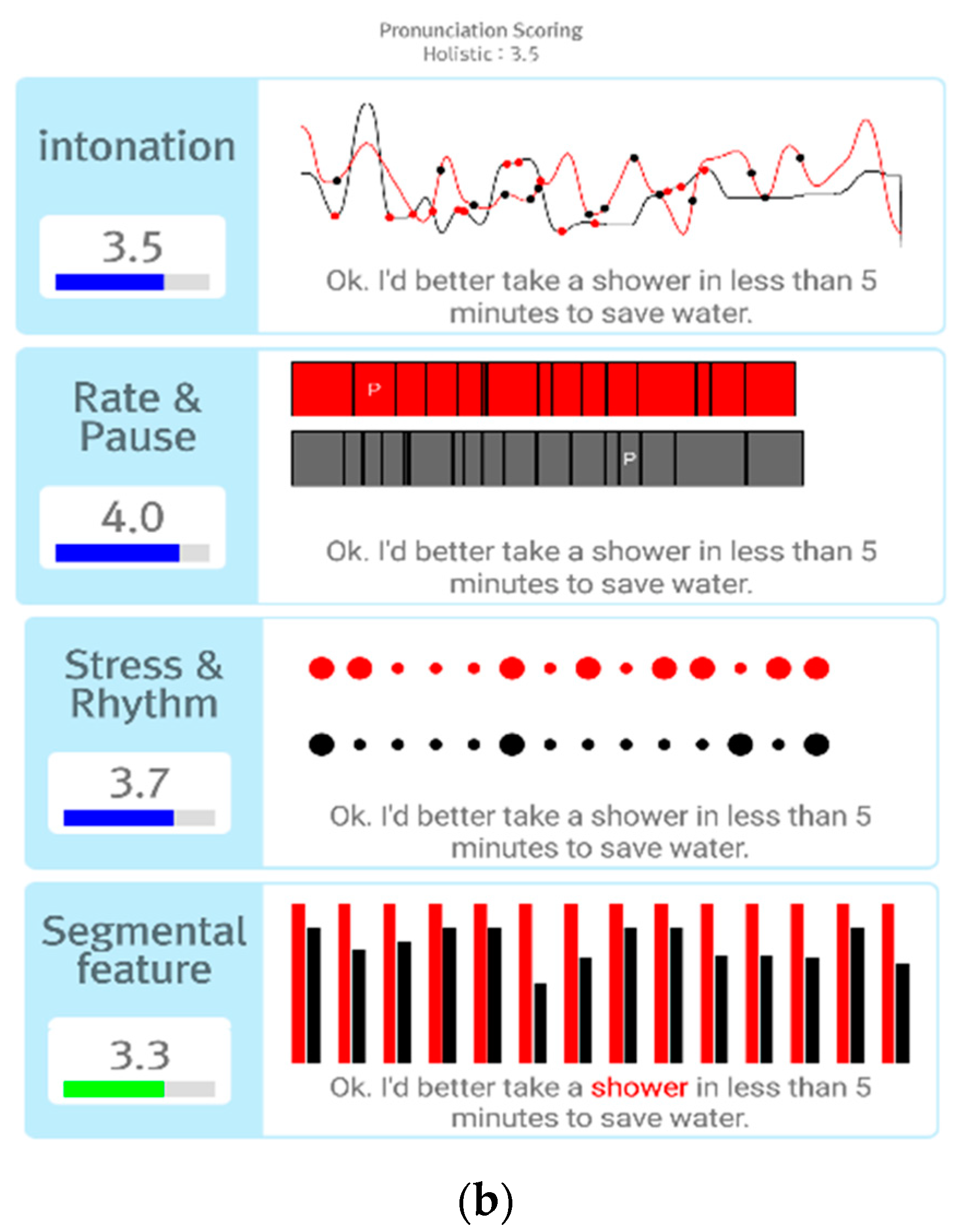
The system comprises two learning stages: Think&Talk and Look&Talk. The Think&Talk stage has various subjects, and each subject comprises several fixed role-play dialogues. In this stage, an English learner can select a study topic and a preferred scenario, and then talk with the system based on the selected role-play scenario. After the learner’s spoken English response for each given question is completed, the system computes an intonation curve, a sentence stress pattern, and word pronunciation scores. The learner’s and a native speaker’s intonation curve patterns are plotted as a graph, and the stress patterns of the learner and native speaker are plotted by circles with different sizes below the corresponding word to represent the intensity of each word at a sentence stress level. Once the learner has finished all conversations on the selected subject or all descriptions of the selected picture, the system semantically and grammatically evaluates the responses, and provides overall feedback.
Figure 2 shows an example of a role-play scenario and educational overall feedback with the system. In the Look&Talk stage, the English learner can select a picture and then describe the selected picture to the system.
3. Proposed Fluency Scoring and Automatic Proficiency Evaluation Method
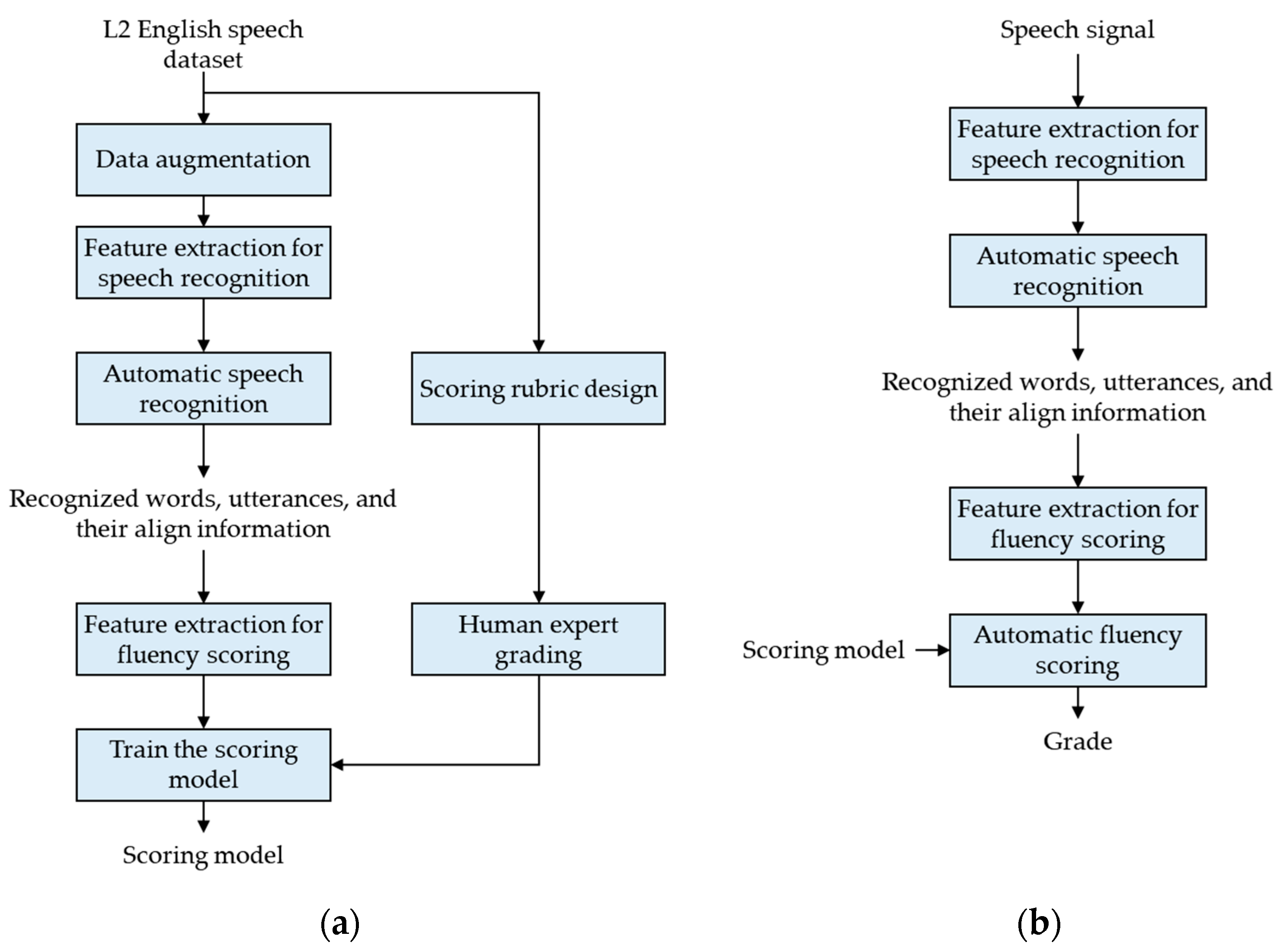
Proficiency evaluation with the proposed method consists of fluency features extraction for scoring each proficiency area, proficiency evaluation model training with fluency features, and automatic evaluation of pronunciation proficiency. The proposed method computes various acoustic features, such as speech rate, intonation, and segmental features, from spoken English uttered by non-native speakers according to a rubric designed to evaluate pronunciation proficiency. In order to compute the fluency features, speech signals are recognized using the automatic speech recognition system and time-aligned sequences of words and phonemes are computed using a forced-alignment algorithm. Each time-aligned sequence contains start and end times for each word and phoneme and acoustic scores. Using the time-aligned sequences, the fluency features are extracted in various aspects of each word and sentence. Proficiency evaluation models are trained using the extracted fluency features and scores from human expert raters, and proficiency scores are computed using the fluency features and scoring models.
Figure 3 shows a block diagram of the proficiency evaluation model training and evaluating system for automatic proficiency evaluation.
3.1. DTW-Based Feature Extraction for Fluency Scoring
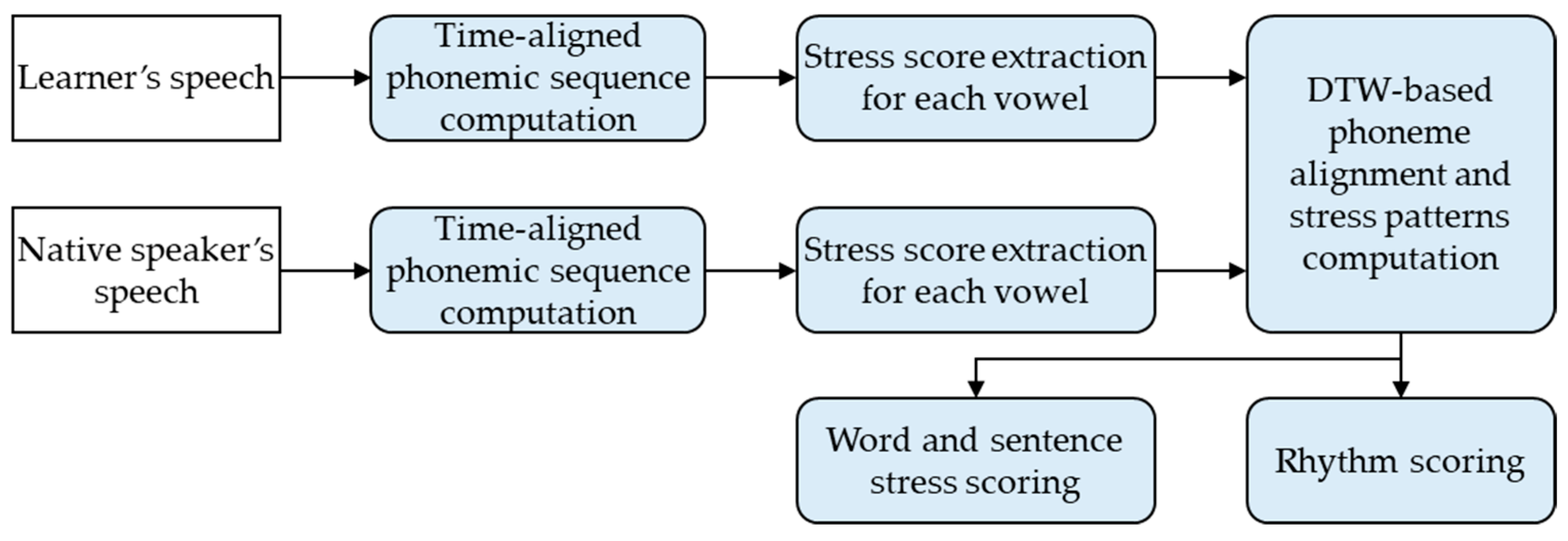
Most language learning systems evaluate and score the learners’ spoken English compared to the native speaker’s one. However, in realistic speaking situations, a learner’s English pronunciation often differs from that of native speakers. For example, learners may pronounce given words incorrectly or pronounce different words from the referred one. In such cases, some fluency features, especially stress and rhythm scores, cannot be measured using previous pattern comparison methods. To solve this problem and measure more meaningful scores, the proposed method aligns the phonemic sequence of the sentence uttered by the learner with the native speaker’s phonemic sequence through dynamic time-warping (DTW) alignment and computes the stress patterns, stress scores, and rhythm scores from the aligned phonemic sequences.
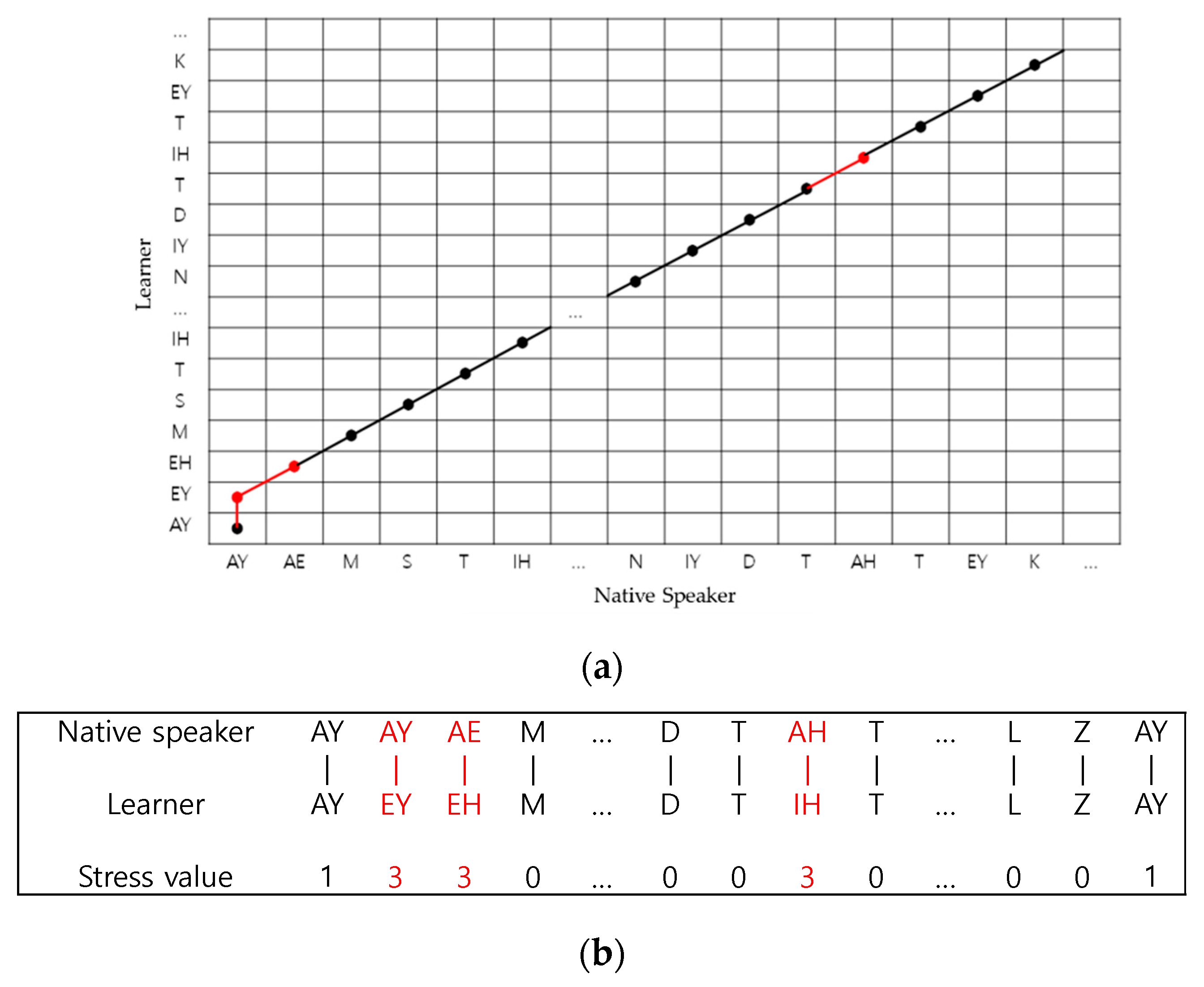
Figure 4 shows a block diagram of the proposed DTW-based stress and rhythm scoring method.
3.1.1. DTW-Based Phoneme Alignment
Dynamic time-warping is a well-known technique for finding an optimal alignment between two time-dependent sequences by comparing them [
15]. To compare and align two phonemic sequences uttered by learner and native speaker (reference), we compute a local cost matrix of two phonemic sequences defined by the Euclidean distance. Typically, if a learner and a native speaker are similar to each other, the local cost matrix is small, and otherwise, the local cost matrix is large. The total cost of an alignment path between the learner’s and native speaker’s phonemic sequences is obtained by summing the local cost measurement values for each pair of elements in two sequences. An optimal alignment path is the alignment path having minimal total cost among all possible alignment paths, and the goal is to find the optimal alignment path and align between two phonemic sequences with the minimal overall cost.
Figure 5 shows an example of DTW-based phonemic sequence alignment and stress patterns’ computation results. Error phonemes caused by phoneme mismatch are marked in red, and the stress value of error phonemes was set to 3, which is not a standard stress value indicated by 0 (no stress), 1 (secondary stress), or 2 (primary stress) in order to compute the deducted stress score according to the presence of the phonemic errors. By tagging error phonemes, the proposed method evaluates the learner’s utterance more accurately and helps L2 learners practice their English pronunciation.
3.1.2. Stress and Rhythm Scoring
Given the aligned phonemic sequences, the proposed method computes the word stress score, sentence stress score, and rhythm scores. In order to measure the word and sentence stress scores, word stress patterns are computed for each content word in the given sentence, and sentence stress patterns are computed for the entire sentence. Then, the word and sentence stress scores are measured by computing the similarity between the learner’s stress patterns and the native speaker’s stress patterns.
The rhythm scores are measured by computing the mean and standard deviation of the time intervals between the stressed phonemes. An example of computing the rhythm score in the sentence “I am still very sick. I need to take some pills.” is as follows:
Compute the stress patterns from the aligned phonemic sequences.
Table 1 shows an example of the sentence stress pattern. The start times of the stressed phonemes, including the start and end times of the sentence, are highlighted (bold in
Table 1) to compute the rhythm features.
Select the stressed phonemes (highlighted point in
Table 1), and compute the mean and standard deviation of the time intervals between them:
- (1)
Mean time interval:
(0.2 + 0.2 + 0.6 + 0.5 + 1.5)/5 = 0.6
- (2)
Standard deviation of the time interval:
(0.16 + 0.16 + 0.0 + 0.01 + 0.81)/5 = 0.23
Table 2 shows an example of the mean values of the mean time interval and the standard deviation of the time interval for each pronunciation proficiency level evaluated by human raters. Proficiency scores 1, 2, 3, 4, and 5 indicate very poor, poor, acceptable, good, and perfect, respectively. As shown in
Table 2, the lower the proficiency level, the greater the mean and standard deviation values of the time intervals between the stressed phonemes. Two stress scores and rhythm scores are used for spoken English proficiency evaluation with other features.
3.2. Automatic Proficiency Evaluation with Data Augmentation
The speech recognition system is optimized for non-native speakers as well as natives for educational purposes and smooth interaction. Speech features for computing fluency scores are extracted and decoded into time-aligned sequences by forced-alignment using the non-native acoustic model (AM). In addition, multiple AM scores are used to evaluate proficiency. In order to improve speech recognition accuracy and time-alignment performance, and to compute AM scores more accurately and meaningfully, we augment the training speech dataset and train non-native AM using the augmented training dataset.
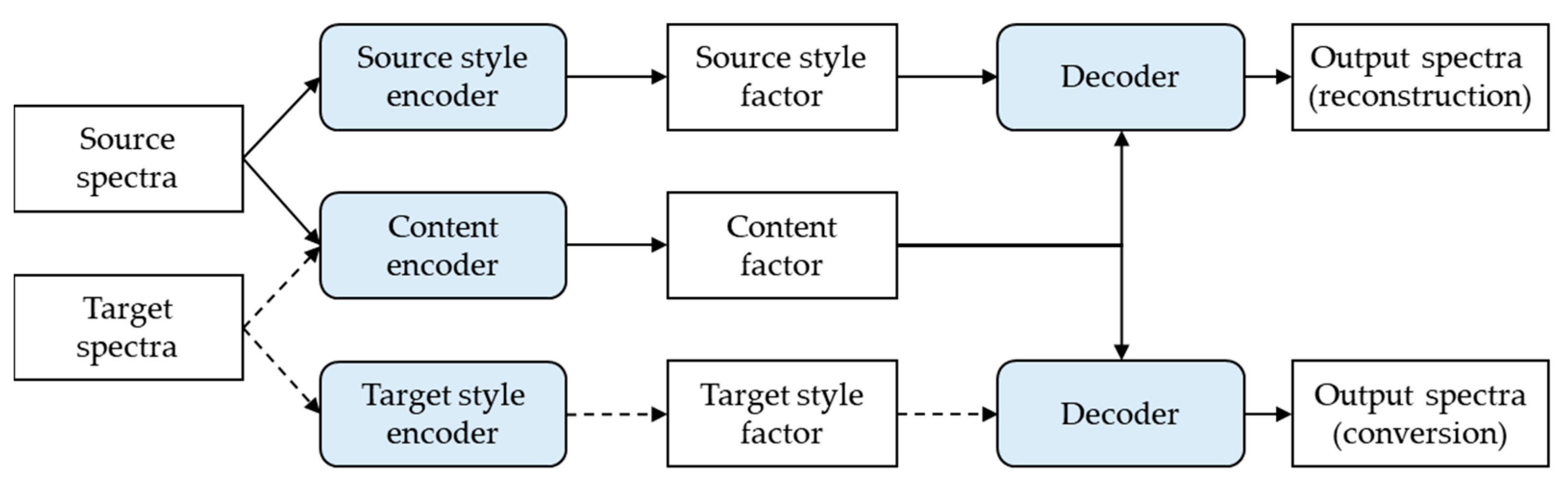
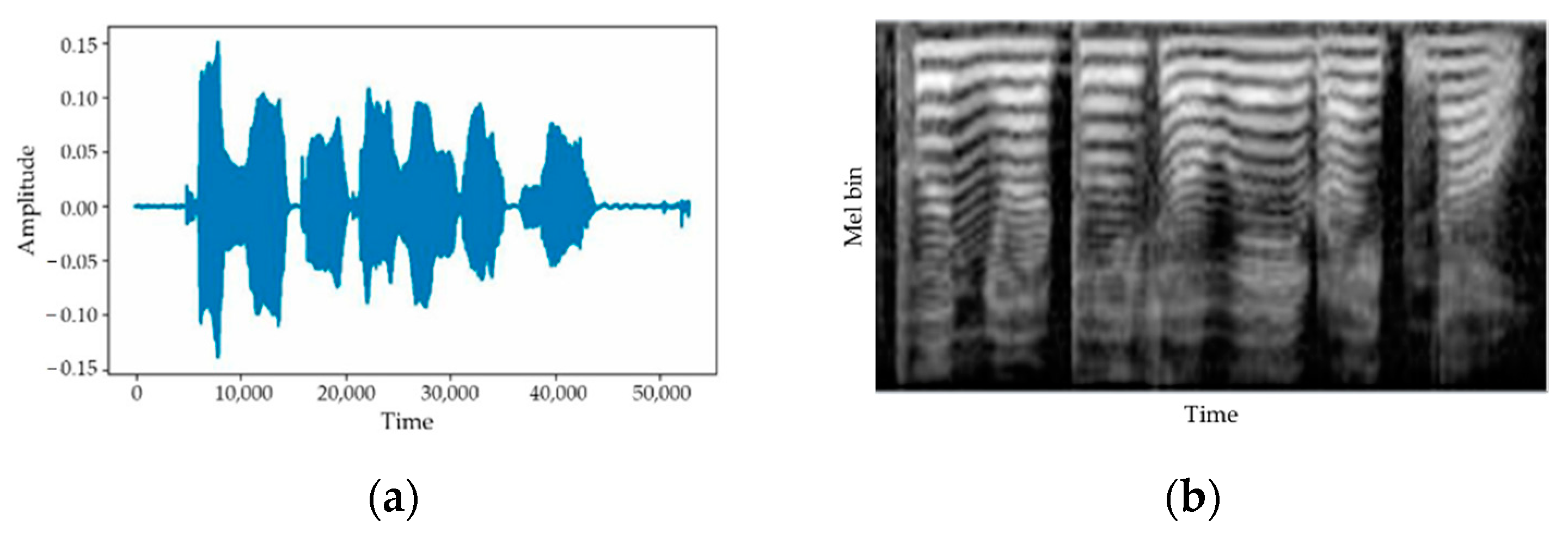
In this work, we convert some speech characteristics (style) to generate speech data for augmentation. In the proposed speech conversion model, we assume that each spectral feature of the speech signal is decomposed into a speaker-independent content factor desired to be maintained and each speaker-specific style factor we want to change in latent space. After extracting the content factor from the source speech signal, the proposed conversion model converts the source speech to the desired speech style by extracting the style factor of target speech and recombining it with the extracted content factor. By simply choosing the style factor for this recombination as a source style factor or target style factor, the conversion model can reconstruct or convert speech:
where
and
are the reconstructed and converted spectra,
and
are the source and target speech spectra,
is the decoder, and
,
, and
denote the content encoder, source style encoder, and target style encoder, respectively. The content encoder network is shared across both speakers, and the style encoder networks are domain-specific networks for individual speakers.
Figure 6 shows a block diagram of the proposed speech conversion method.
As shown in
Figure 6, the content encoder network extracts the content factor and is shared across all domains. All convolutional layers of the content encoder were followed by instance normalization (IN) to remove the speech style information and learn domain-independent content information (phoneme in speech). The style encoder network computes the domain-specific style factor for each domain and is composed of multiple separate style encoders (source style encoder and target style encoder in
Figure 6) for individual domains. In the style encoders, IN was not used, because it removes the speech style information.
We jointly train the encoders and decoder with multiple losses. To keep encoder and decoder as inverse operations and ensure the proposed system should be able to reconstruct the input spectral features after encoding and decoding, we consider reconstruction loss as follows:
For the content factor and style factors, we apply a semi-cycle loss in latent variable → speech spectra → latent variable coding direction as the latent space is partially shared. Here, a content reconstruction loss encourages the translated content latent factor to preserve the semantic content information of input spectral features, and a style reconstruction loss encourages style latent factors to extract and change speaker-specific speaking style information. Two semi-cycle losses for source speech are computed as follows:
where
denotes the content factor, and
and
denote the target style factor and source style factor, respectively. The losses for target speech are similarly computed. The full loss of the proposed speech conversion method is the weighted sum of all losses, which is defined as follows:
where
,
, and
control the weights of the components.
5. Conclusions and Future Work
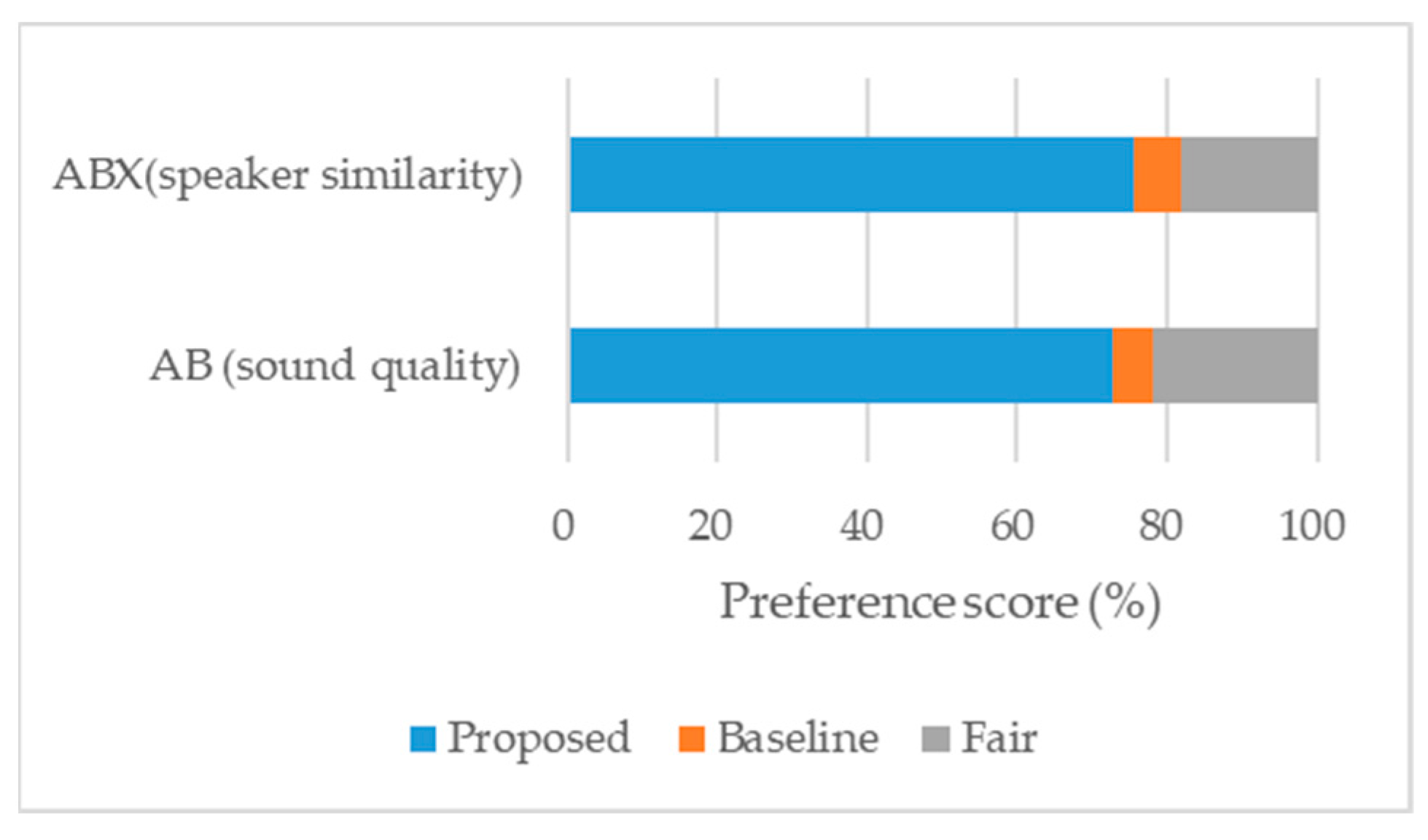
We proposed an automatic proficiency evaluation method for L2 learners in spoken English. In the proposed method, we augmented the training dataset using the VAE-based speech conversion model and trained the acoustic model (AM) with an augmented training dataset to improve the speech recognition accuracy and time-alignment performance for non-native speakers. After recognizing the speech uttered by the learner, the proposed method measured various fluency features and evaluated the proficiency. In order to compute the stress and rhythm scores even when the phonemic sequence errors occur in the learner’s speech, the proposed method aligned the phonemic sequences of the spoken English sentences by using the DTW, and then computed the error-tagged stress patterns and the stress and rhythm scores. In computer experiments with the English read speech dataset, we showed that the proposed method effectively computed the error-tagged stress patterns, stress scores, and rhythm scores. Moreover, we showed that the proposed method efficiently measured proficiency scores and improved the averaged correlation between human expert raters and the proposed method for all proficiency areas compared to the method employing conventional AM trained without data augmentation.
The proposed method can also be used for most signal processing and generation problems, such as sound conversion between instruments or generation of various images. However, the current style conversion framework has a limitation that the conversion model learns the domain-level style factors and generates the converted speech signal rather than diverse pronunciation styles of multiple speakers included in each domain. In order to learn more meaningful and diverse style factors and perform many-to-many speech conversion, we plan to address the issues of automatic speaker label estimation and expansion to each speaker-specific style encoder in the future work.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}