
Frequency-Based Haze and Rain Removal Network (FHRR-Net) with Deep Convolutional Encoder-Decoder




Abstract
1. Introduction
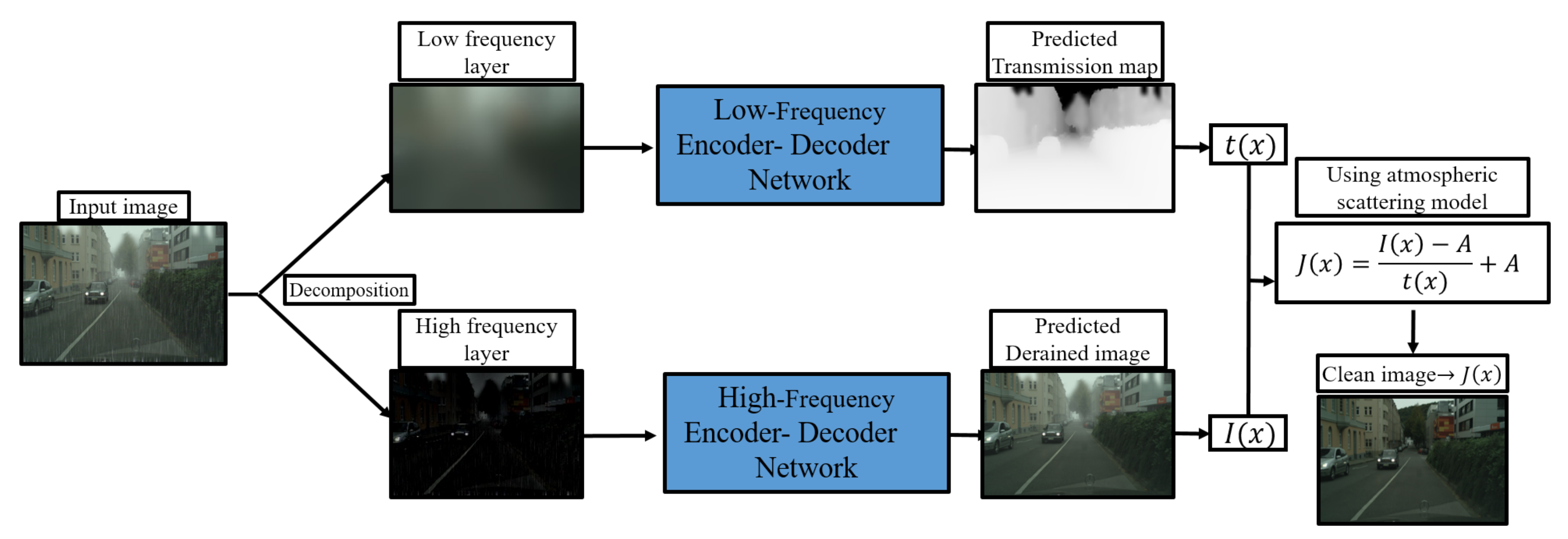
2. Proposed Frequency-Based Haze and Rain Removal Network (FHRR-Net) Framework
- Analysis of haze and rain models to create a synthesized training dataset.
- Image decomposition using a guided filter.
- Architecture of encoder-decoder networks.
- Image restoration using image degradation model.
2.1. Analysis of Haze and Rain Models for Creating Synthesized Training Dataset
2.1.1. Haze Model (Atmospheric Scattering Model)
2.1.2. Rain Model (Rain Streak Model)
2.1.3. Heavy Rain Model
2.2. Image Decomposition Using Guided Filter
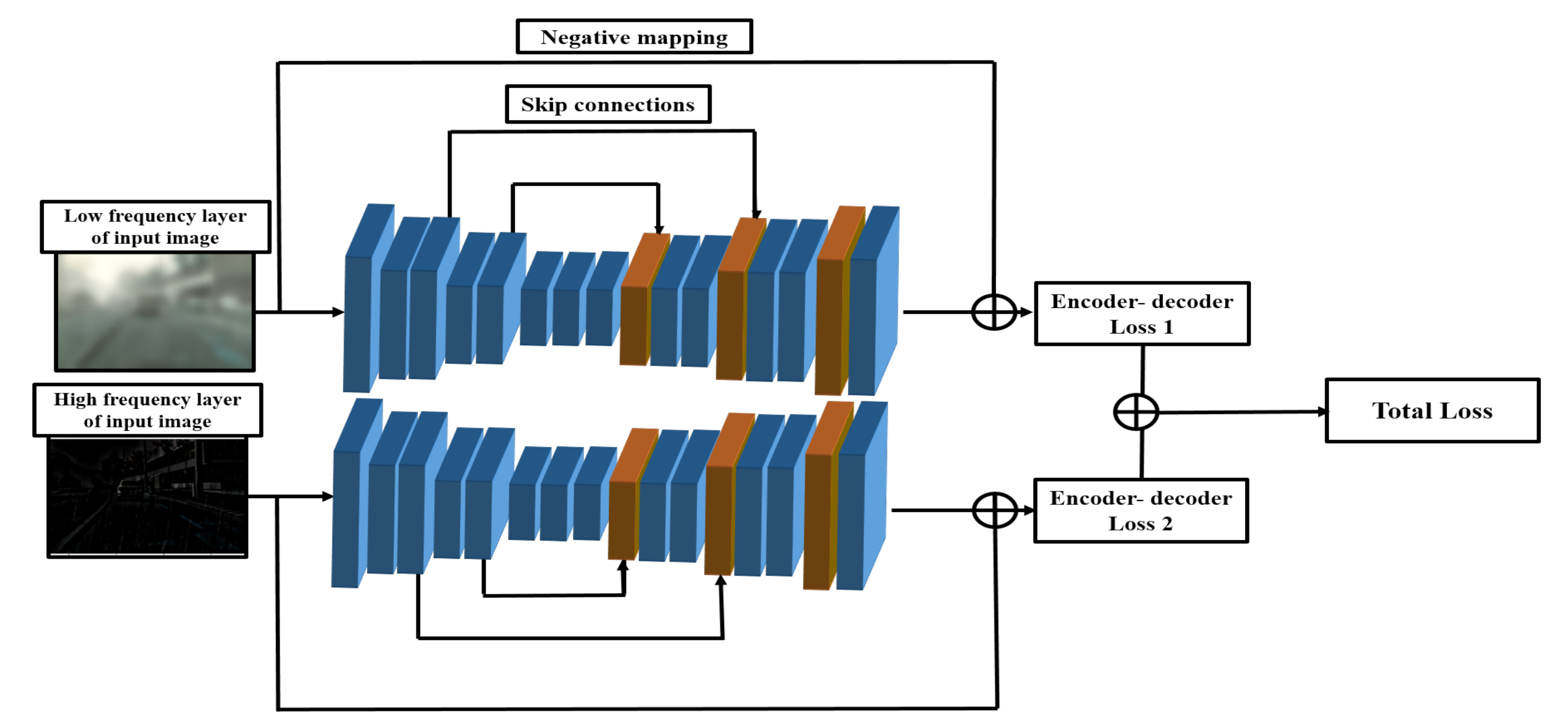
2.3. Frequency-Based Haze and Rain Removal Network (FHRR-Net) Architecture
2.3.1. Dilated Convolution
2.3.2. Symmetric Skip Connections and Negative Mapping
2.3.3. Loss Functions for Training
2.4. Image Restoration Using Atmospheric Scattering Model
3. Experimental Result
3.1. Experimental Environment
3.2. Creating the Synthesized Dataset
3.3. Performance Comparison with State-of-the-Art Methods
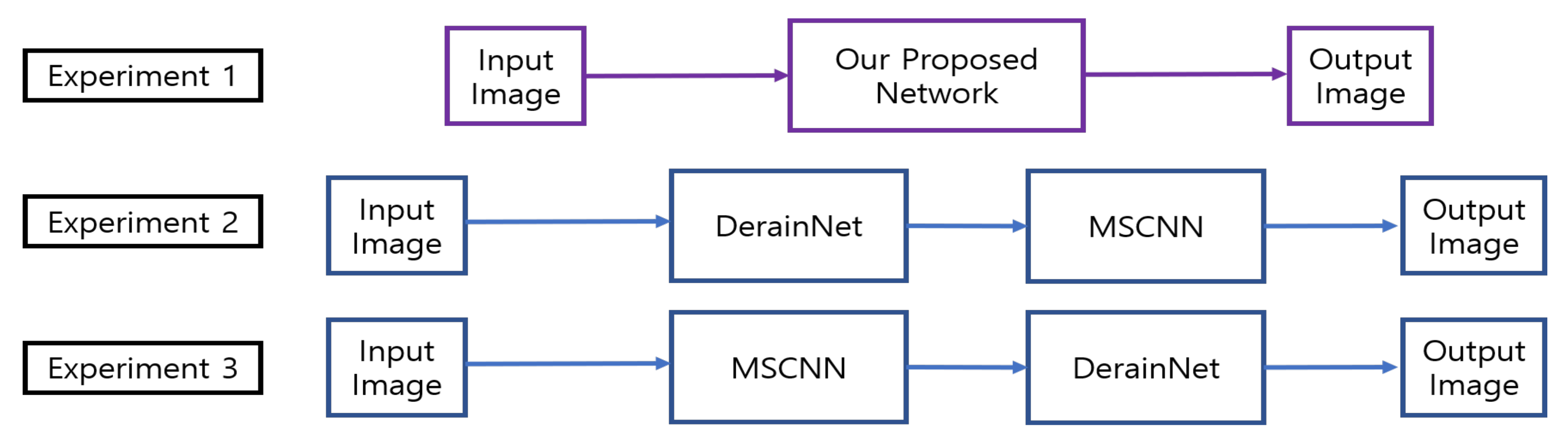
3.4. Comparison of Performance with Combined SOTA Methods (Derain + Dehaze)
3.5. Object Detection Results
3.6. Analysis of Proposed Architecture
3.6.1. Effectiveness of the Proposed Dilated Convolution and Negative Mapping
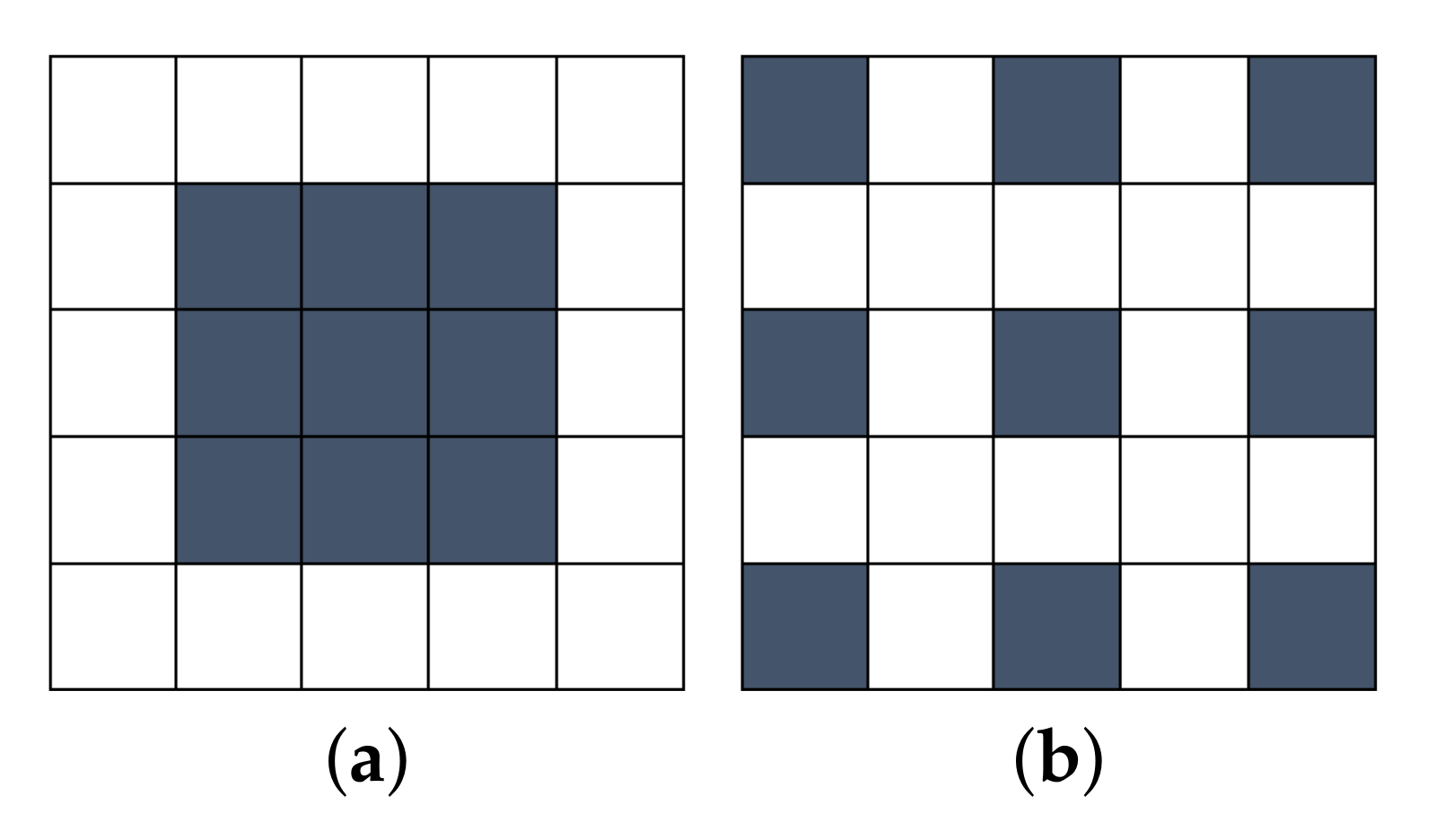
3.6.2. Comparison of Restoration Performance for Various Threshold Values
3.6.3. Effectiveness of Frequency Decomposition
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Instance-aware semantic segmentation via multi-task network cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3150–3158. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Kim, J.H.; Lee, C.; Sim, J.Y.; Kim, C.S. Single-image deraining using an adaptive nonlocal means filter. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 914–917. [Google Scholar]
- Li, Y.; Tan, R.T.; Guo, X.; Lu, J.; Brown, M.S. Rain streak removal using layer priors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2736–2744. [Google Scholar]
- Du, S.; Liu, Y.; Ye, M.; Xu, Z.; Li, J.; Liu, J. Single image deraining via decorrelating the rain streaks and background scene in gradient domain. Pattern Recognit. 2018, 79, 303–317. [Google Scholar] [CrossRef]
- Fu, X.; Huang, J.; Ding, X.; Liao, Y.; Paisley, J. Clearing the skies: A deep network architecture for single-image rain removal. IEEE Trans. Image Process. 2017, 26, 2944–2956. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Huang, J.; Zeng, D.; Huang, Y.; Ding, X.; Paisley, J. Removing rain from single images via a deep detail network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3855–3863. [Google Scholar]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Deep joint rain detection and removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1357–1366. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 154–169. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- McCartney, E.J. Optics of the Atmosphere: Scattering by Molecules and Particles; John Wiley and Sons, Inc.: New York, NY, USA, 1976; 421p. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Fattal, R. Single image dehazing. ACM Trans. Graph. 2008, 27, 72. [Google Scholar] [CrossRef]
- Caraffa, L.; Tarel, J.P. Markov random field model for single image defogging. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Gold Coast City, Australia, 23 June 2013; pp. 994–999. [Google Scholar]
- Huang, D.A.; Kang, L.W.; Yang, M.C.; Lin, C.W.; Wang, Y.C.F. Context-aware single image rain removal. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo, Melbourne, Australia, 9–13 July 2012; pp. 164–169. [Google Scholar]
- Fu, Y.H.; Kang, L.W.; Lin, C.W.; Hsu, C.T. Single-frame-based rain removal via image decomposition. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 1453–1456. [Google Scholar]
- Luo, Y.; Xu, Y.; Ji, H. Removing rain from a single image via discriminative sparse coding. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3397–3405. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Sun, J. Fast guided filter. arXiv 2015, arXiv:1505.00996. [Google Scholar]
- Yang, X.; Li, H.; Fan, Y.L.; Chen, R. Single Image Haze Removal via Region Detection Network. IEEE Trans. Multimed. 2019, 21, 2545–2560. [Google Scholar] [CrossRef]
- Wu, H.; Zheng, S.; Zhang, J.; Huang, K. Fast end-to-end trainable guided filter. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1838–1847. [Google Scholar]
- Mao, X.; Shen, C.; Yang, Y.B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. arXiv 2016, arXiv:1603.09056. [Google Scholar]
- Ren, W.; Zhang, J.; Xu, X.; Ma, L.; Cao, X.; Meng, G.; Liu, W. Deep video dehazing with semantic segmentation. IEEE Trans. Image Process. 2018, 28, 1895–1908. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss functions for image restoration with neural networks. IEEE Trans. Comput. Imaging 2016, 3, 47–57. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Dai, D.; Sakaridis, C.; Hecker, S.; Van Gool, L. Curriculum model adaptation with synthetic and real data for semantic foggy scene understanding. Int. J. Comput. Vis. 2020, 128, 1182–1204. [Google Scholar] [CrossRef]
- Sakaridis, C.; Dai, D.; Hecker, S.; Van Gool, L. Model adaptation with synthetic and real data for semantic dense foggy scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 687–704. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| High-Frequency Encoder-Decoder Network | ||||
|---|---|---|---|---|
| Layer | Kernel Size | Dilated Factor | Output Size | Skip Connections |
| Input | 256 × 256 | |||
| Encoder_conv 0 | 3 | 1 | 16 × 256 × 256 | |
| Encoder_conv 1_1 | 3 | 2 | 32 × 128 × 128 | |
| Encoder_conv 1_2 | 3 | 2 | 32 × 128 × 128 | Decoder_deconv 2 |
| Encoder_conv 2_1 | 3 | 2 | 64 × 64 × 64 | |
| Encoder_conv 2_2 | 3 | 2 | 64 × 64 × 64 | Decoder_deconv 1 |
| Encoder_conv 3_1 | 3 | 2 | 128 × 32 × 32 | |
| Encoder_conv 3_2 | 3 | 2 | 128 × 32 × 32 | |
| Decoder_deconv 1 | 2 | 2 | 64 × 64 × 64 | Encoder_conv 2_2 |
| Decoder_conv 1_1 | 3 | 2 | 64 × 64 × 64 | |
| Decoder_conv 1_2 | 3 | 2 | 64 × 64 × 64 | |
| Decoder_deconv 2 | 2 | 2 | 32 × 128 × 128 | Encoder_conv 1_2 |
| Decoder_conv 2_1 | 3 | 2 | 32 × 128 × 128 | |
| Decoder_conv 2_2 | 3 | 2 | 32 × 128 × 128 | |
| Decoder_deconv 3 | 2 | 2 | 32 × 256 × 256 | |
| Decoder_conv 3_1 | 3 | 2 | 16 × 256 × 256 | |
| Decoder_conv 3_2 | 3 | 2 | 16 × 256 × 256 | |
| Output | 3 | 2 | 3 × 256 × 256 | |
| Low-frequency Encoder-decoder network | ||||
| Layer | Kernel size | Dilated factor | Output size | Skip connections |
| Input | 256 × 256 | |||
| Encoder_conv 0 | 3 | 1 | 16 × 256 × 256 | |
| Encoder_conv 1_1 | 3 | 2 | 32 × 128 × 128 | |
| Encoder_conv 1_2 | 3 | 2 | 32 × 128 × 128 | Decoder_deconv 2 |
| Encoder_conv 2_1 | 3 | 2 | 64 × 64 × 64 | |
| Encoder_conv 2_2 | 3 | 2 | 64 × 64 × 64 | Decoder_deconv 1 |
| Encoder_conv 3_1 | 3 | 2 | 128 × 32 × 32 | |
| Encoder_conv 3_2 | 3 | 2 | 128 × 32 × 32 | |
| Decoder_deconv 1 | 2 | 2 | 64 × 64 × 64 | Encoder_conv 2_2 |
| Decoder_conv 1_1 | 3 | 2 | 64 × 64 × 64 | |
| Decoder_conv 1_2 | 3 | 2 | 64 × 64 × 64 | |
| Decoder_deconv 2 | 2 | 2 | 32 × 128 × 128 | Encoder_conv 1_2 |
| Decoder_conv 2_1 | 3 | 2 | 32 × 128 × 128 | |
| Decoder_conv 2_2 | 3 | 2 | 32 × 128 × 128 | |
| Decoder_deconv 3 | 2 | 2 | 32 × 256 × 256 | |
| Decoder_conv 3_1 | 3 | 2 | 16 × 256 × 256 | |
| Decoder_conv 3_2 | 3 | 2 | 16 × 256 × 256 | |
| Output | 3 | 2 | 1 × 256 × 256 | |
| Methods | Average PSNR | Average SSIM |
|---|---|---|
| DerainNet | = 18.79, = 1.58 | = 0.84, = 0.08 |
| MSCNN | = 20.01, = 1.08 | = 0.81, = 0.08 |
| FHRR-Net | = 22.02, = 1.20 | = 0.91, = 0.06 |
| Original Input + YOLOv3 | DerainNet +YOLOv3 | MSCNN +YOLOv3 | FHRR-Net +YOLOv3 | ||||
|---|---|---|---|---|---|---|---|
| mAP | Confidence | mAP | Confidence | mAP | Confidence | mAP | Confidence |
| 0.84 | 0.924 | 0.77 | 0.909 | 0.75 | 0.845 | 0.89 | 0.921 |
| Without Dilated Convolution | Without Negative Mapping | FHRR-Net | |
|---|---|---|---|
| Average PSNR | = 21.582, = 1.15 | = 21.96, = 1.23 | = 22.02, = 1.20 |
| Average SSIM | = 0.88, = 0.06 | = 0.89, = 0.07 | = 0.91, = 0.06 |
| Darkest 0.05% Pixel | Darkest 0.1% Pixel | Darkest 0.15% Pixel | Darkest 0.2% Pixel | |
|---|---|---|---|---|
| Average PSNR | = 21.96, = 1.21 | = 22.02, = 1.22 | = 22.00, = 1.23 | = 21.94, = 1.20 |
| Average SSIM | = 0.9105, = 0.0617 | = 0.9105, = 0.0616 | = 0.9105, = 0.0617 | = 0.9103, = 0.0612 |
| Methods | Average PSNR | Average SSIM |
|---|---|---|
| Without frequency-based method | = 21.02, = 1.55 | = 0.82, = 0.08 |
| FHRR-Net | = 22.02, = 1.20 | = 0.91, = 0.06 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, D.H.; Ahn, W.J.; Lim, M.T.; Kang, T.K.; Kim, D.W. Frequency-Based Haze and Rain Removal Network (FHRR-Net) with Deep Convolutional Encoder-Decoder. Appl. Sci. 2021, 11, 2873. https://doi.org/10.3390/app11062873
Kim DH, Ahn WJ, Lim MT, Kang TK, Kim DW. Frequency-Based Haze and Rain Removal Network (FHRR-Net) with Deep Convolutional Encoder-Decoder. Applied Sciences. 2021; 11(6):2873. https://doi.org/10.3390/app11062873
Chicago/Turabian StyleKim, Dong Hwan, Woo Jin Ahn, Myo Taeg Lim, Tae Koo Kang, and Dong Won Kim. 2021. "Frequency-Based Haze and Rain Removal Network (FHRR-Net) with Deep Convolutional Encoder-Decoder" Applied Sciences 11, no. 6: 2873. https://doi.org/10.3390/app11062873
APA StyleKim, D. H., Ahn, W. J., Lim, M. T., Kang, T. K., & Kim, D. W. (2021). Frequency-Based Haze and Rain Removal Network (FHRR-Net) with Deep Convolutional Encoder-Decoder. Applied Sciences, 11(6), 2873. https://doi.org/10.3390/app11062873