Quantum Modular Adder over GF(2n − 1) without Saving the Final Carry





Abstract
:1. Introduction
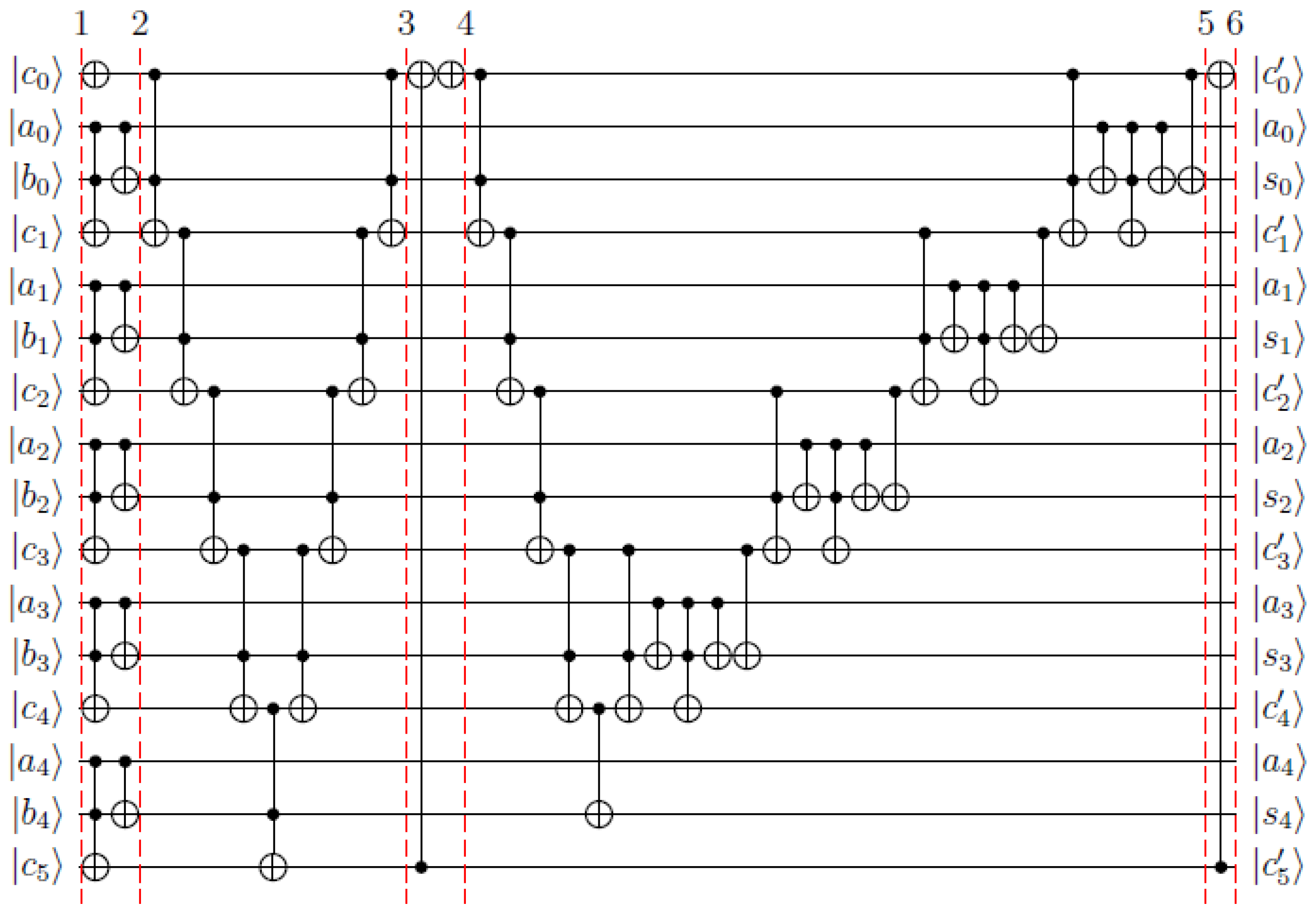
- We propose a lightweight quantum modular adder over using one full adder based on RCA and one carry-truncated adder. In contrast, the general modular adder usually uses multiple dividers or multipliers. The final carry in the carry-truncated adder affects the decision to add one or not for completing the modular operation and is not included in the results.
- We designed the algorithm of the proposed quantum modular adder as a quantum circuit, called a referenced quantum circuit. Then, we optimized the circuit as a more efficient circuit, called an optimized quantum circuit, by an equivalence rule of quantum circuits.
- We simulated the referenced quantum circuit and the optimized quantum circuit to add two numbers over via IBM’s ProjectQ when with 16 qubits, and compared them to other RCA-based quantum modular adders.
2. Related Works
2.1. Quantum Modular Adder Circuit
2.2. Residue Number System
3. Quantum Modular Adder over
- If is 0 and the sum of is not n, S represents .
- If is 0 and the sum of is n, S represents 0.
- If is 1, consists of -bit and S is represented by Equation (2).
4. Implementation and Results of the Simulation
- The number of qubits for OurO was six qubits less than V-AM.
- The number of gates for OurO was 26 gates, showing a 71.1% decrease from V-AM.
- The depth for OurO was 39, showing a 73.6% decrease from V-AM.
- The cost dropped tremendously thanks to reducing the number of qubits, the number of gates, and the depth by the proposed quantum circuit.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Michielsen, K.; Nocon, M.; Willsch, D.; Jin, F.; Lippert, T.; De Raedt, H. Benchmarking gate-based quantum computers. Comput. Phys. Commun. 2017, 220, 44–55. [Google Scholar] [CrossRef]
- Arute, F.; Arya, K.; Babbush, R.; Bacon, D.; Bardin, J.C.; Barends, R.; Biswas, R.; Boixo, S.; Brandao, F.G.; Buell, D.A.; et al. Quantum supremacy using a programmable superconducting processor. Nature 2019, 574, 505–510. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- IBM Quantum Experience. Available online: https://quantum-computing.ibm.com (accessed on 30 December 2020).
- Azure Quantum. Available online: https://azure.microsoft.com/en-us/services/quantum (accessed on 30 December 2020).
- Rigetti: Think Quantum. Available online: https://rigetti.com (accessed on 30 December 2020).
- Amazon: Braket. Available online: https://aws.amazon.com/braket (accessed on 30 December 2020).
- Guerreschi, G.G.; Hogaboam, J.; Baruffa, F.; Sawaya, N.P. Intel Quantum Simulator: A cloud-ready high-performance simulator of quantum circuits. Quantum. Sci. Technol. 2020, 5, 034007. [Google Scholar] [CrossRef] [Green Version]
- Kjaergaard, M.; Schwartz, M.E.; Braumüller, J.; Krantz, P.; Wang, J.I.J.; Gustavsson, S.; Oliver, W.D. Superconducting qubits: Current state of play. Annu. Rev. Condens. Matter Phys. 2020, 11, 369–395. [Google Scholar] [CrossRef] [Green Version]
- Wendin, G. Quantum information processing with superconducting circuits: A review. Reports on Progress in Physics. Rep. Prog. Phys. 2017, 80, 106001. [Google Scholar] [CrossRef] [Green Version]
- Beauregard, S.; Brassard, G.; Fernandez, J.M. Quantum arithmetic on Galois fields. arXiv 2003, arXiv:0301163. [Google Scholar]
- Vedral, V.; Barenco, A.; Ekert, A. Quantum networks for elementary arithmetic operations. Phys. Rev. A 1996, 54, 147. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Jiang, N.; Hu, H.; Ji, Z. Quantum adder for superposition states. Int. J. Theor. Phys. 2018, 57, 2575–2584. [Google Scholar] [CrossRef]
- Alhazmi, B.; Gebali, F. Fast Large Integer Modular Addition in GF(p) Using Novel Attribute-Based Representation. IEEE Access 2019, 7, 58704–58719. [Google Scholar] [CrossRef]
- Rines, R.; Chuang, I. High performance quantum modular multipliers. arXiv 2018, arXiv:1801.01081. [Google Scholar]
- Shor, P.W. Algorithms for quantum computation: Discrete logarithms and factoring. In Proceedings of the 35th Annual Symposium on Foundations of Computer Science, Santa Fe, NM, USA, 20–22 November 1994; IEEE: New York City, USA, 1994; pp. 124–134. [Google Scholar]
- Ekert, A.; Jozsa, R. Quantum computation and Shor’s factoring algorithm. Rev. Mod. Phys. 1996, 68, 733. [Google Scholar] [CrossRef] [Green Version]
- Beauregard, S. Circuit for Shor’s algorithm using 2n+ 3 qubits. arXiv 2002, arXiv:0205095. [Google Scholar]
- Monz, T.; Nigg, D.; Martinez, E.A.; Brandl, M.F.; Schindler, P.; Rines, R.; Wang, S.X.; Chuang, I.L.; Blatt, R. Realization of a scalable Shor algorithm. J. Sci 2016, 351, 1068–1070. [Google Scholar] [CrossRef] [Green Version]
- Harris, D.M.; Harris, S.L. Ch5 Digital Building Blocks. In Digital Design and Computer Architecture; Elsevier: Amsterdam, The Netherlands; Publishing House: Waltham, MA, USA, 2016; pp. 238–293. [Google Scholar]
- Zadeh, S.H.; Ytterdal, T.; Aunet, S. Ultra-Low Voltage Subthreshold Binary Adder Architectures for IoT Applications: Ripple Carry Adder or Kogge Stone Adder. In Proceedings of the 2019 IEEE Nordic Circuits and Systems Conference (NORCAS): NORCHIP and International Symposium of System-on-Chip (SoC), Helsinki, Finland, 29–30 October 2019; pp. 1–7. [Google Scholar]
- Padmavathy, T.V.; Saravanan, S.; Vimalkumar, M.N. Partial product addition in Vedic design-ripple carry adder design fir filter architecture for electro cardiogram (ECG) signal de-noising application. Microprocess. Microsy 2020, 76, 103113. [Google Scholar] [CrossRef]
- Sher, T.H.; Arab, S. Comparisons between Ripple-Carry Adder and Carry-Look-Ahead Adder; Technical Report; University of Southern California: Los Angeles, CA, USA, 2015. [Google Scholar]
- Balasubramanian, P.; Mastorakis, N. Performance comparison of carry-lookahead and carry-select adders based on accurate and approximate additions. Electronics 2018, 7, 369. [Google Scholar] [CrossRef] [Green Version]
- Bagwari, A.; Katna, I. Low Power Ripple Carry Adder Using Hybrid 1-Bit Full Adder Circuit. In Proceedings of the 11th International Conference on Computational Intelligence and Communication Networks (CICN), Honolulu, HI, USA, 3–4 January 2019; IEEE: New York City, USA, 2019; pp. 124–127. [Google Scholar]
- Ding, J.; Schmidt, D. Rainbow, a new multivariable polynomial signature scheme. In Proceedings of the International Conference on Applied Cryptography and Network Security, Berlin/Heidelberg, Germany, 7 January 2005; Springer: New York City, USA, 2005; pp. 164–175. [Google Scholar]
- Petzoldt, A. Efficient Key Generation for Rainbow. In Proceedings of the International Conference on Post-Quantum Cryptography, Paris, France, 15–17 April 2020; pp. 92–107. [Google Scholar]
- Barenco, A.; Bennett, C.H.; Cleve, R.; DiVincenzo, D.P.; Margolus, N.; Shor, P.; Sleator, T.; Smolin, J.A.; Weinfurter, H. Elementary gates for quantum computation. Phys. Rev. A 1995, 52, 3457–3467. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Soderstrand, M.A.; Jenkins, W.K.; Jullien, G.A.; Taylor, F.J. Residue Number System Arithmetic: Modern Applications in Digital Signal Processing; IEEE Press: New York, NY, USA, 1986. [Google Scholar]
- Juang, T.B.; Chiu, C.C.; Tsai, M.Y. Improved area-efficient weighted modulo 2n + 1 adder design with simple correction schemes. IEEE Trans. Circuits Syst. II Exp. Briefs 2010, 57, 198–202. [Google Scholar] [CrossRef]
- Kumar, R.; Jaiswal, R.K.; Mishra, R.A. Perspective and Opportunities of Modulo 2n − 1 Multipliers in Residue Number System: A Review. J. Circuits Syst. Comput. 2020, 29, 2030008. [Google Scholar] [CrossRef]
- Nozaki, H.; Motoyama, M.; Shimbo, A.; Kawamura, S. Implementation of RSA algorithm based on RNS Montgomery multiplication. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Berlin/Heidelberg, Germany, 14 May 2001; pp. 364–376. [Google Scholar]
- Schoinianakis, D. Residue arithmetic systems in cryptography: A survey on modern security applications. J. Cryptogr. Eng. 2020, 10, 249–267. [Google Scholar] [CrossRef]
- Garcia-Escartin, J.C.; Chamorro-Posada, P. Equivalent quantum circuits. arXiv 2011, arXiv:1110.2998. [Google Scholar]
- Cho, S.M.; Kim, A.; Choi, D.; Choi, B.S.; Seo, S.H. Quantum Modular Multiplication. IEEE Access 2020, 8, 213244–213252. [Google Scholar] [CrossRef]
- Steiger, D.S.; Häner, T.; Troyer, M. ProjectQ: An open source software framework for quantum computing. Quantum 2018, 2, 49. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Luo, M.; Li, H.; Qu, Z.; Wang, X. Improved quantum ripple-carry addition circuit. Sci. China Inform. Sci. 2016, 59, 042406. [Google Scholar] [CrossRef]
- Cuccaro, S.A.; Draper, T.G.; Kutin, S.A.; Moulton, D.P. A new quantum ripple-carry addition circuit. arXiv 2004, arXiv:0410184. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modular Adder | Qubits | CCNOT | Reduction rate of CCNOT | Depth | Reduction Rate of Depth |
|---|---|---|---|---|---|
| V-AM | 22 | 90 | - | 148 | - |
| C-AM | 17 | 45 | −50.0% | 88 | −40.5% |
| OurR | 16 | 33 | −63.3% | 46 | −68.9% |
| OurO | 16 | 26 | −71.1% | 39 | −73.6% |
| Modular Adder | Qubits | CCNOT Gates | Depth | Circuit for | Simulation |
|---|---|---|---|---|---|
| V-AM | Y | N | |||
| C-AM | N | N | |||
| OurR | Y | Y | |||
| OurO | Y | Y |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, A.; Cho, S.-M.; Seo, C.-B.; Lee, S.; Seo, S.-H. Quantum Modular Adder over GF(2n − 1) without Saving the Final Carry. Appl. Sci. 2021, 11, 2949. https://doi.org/10.3390/app11072949
Kim A, Cho S-M, Seo C-B, Lee S, Seo S-H. Quantum Modular Adder over GF(2n − 1) without Saving the Final Carry. Applied Sciences. 2021; 11(7):2949. https://doi.org/10.3390/app11072949
Chicago/Turabian StyleKim, Aeyoung, Seong-Min Cho, Chang-Bae Seo, Sokjoon Lee, and Seung-Hyun Seo. 2021. "Quantum Modular Adder over GF(2n − 1) without Saving the Final Carry" Applied Sciences 11, no. 7: 2949. https://doi.org/10.3390/app11072949
APA StyleKim, A., Cho, S.-M., Seo, C.-B., Lee, S., & Seo, S.-H. (2021). Quantum Modular Adder over GF(2n − 1) without Saving the Final Carry. Applied Sciences, 11(7), 2949. https://doi.org/10.3390/app11072949