1. Introduction
Urban rail transit is a vehicle transportation system that adopts a track structure to carry and guide passengers. According to the requirements of the overall urban transportation plan, a fully enclosed or partially enclosed dedicated railway line is established. This is a public transportation method that transports a large number of passengers in the form of trains [
1]. Any fault of the system may cause significant casualties and property losses. Therefore, fault diagnosis is of great significance to ensure the passengers’ safety and social stability.
The urban rail transit industry has accumulated a large amount of data on intercity railways. Based on data collected from China national knowledge infrastructure (CNKI) and Wanfang Databases,
Figure 1 shows the number of lines, total distance, and the number of cities involved in China’s urban rail transit from 2015 to 2019. Detection and resolution of turn-back failures in time to avoid threats to the safety of people is a major challenge for managers. Thus, the diagnosis of train reentry failure is a meaningful research direction.
Three types of turn-back faults can occur in the operation of trains, : automatic turn-back (ATB), automatic end change (AEC), and point mode end change (PEC). Failures in the three reentry scenarios lead to major accidents; however, compared with ATB, few studies have been undertaken on AEC and PEC [
2,
3,
4]. In this study, the characteristics of AEC and PEC failures were obtained to contribute to the related research.
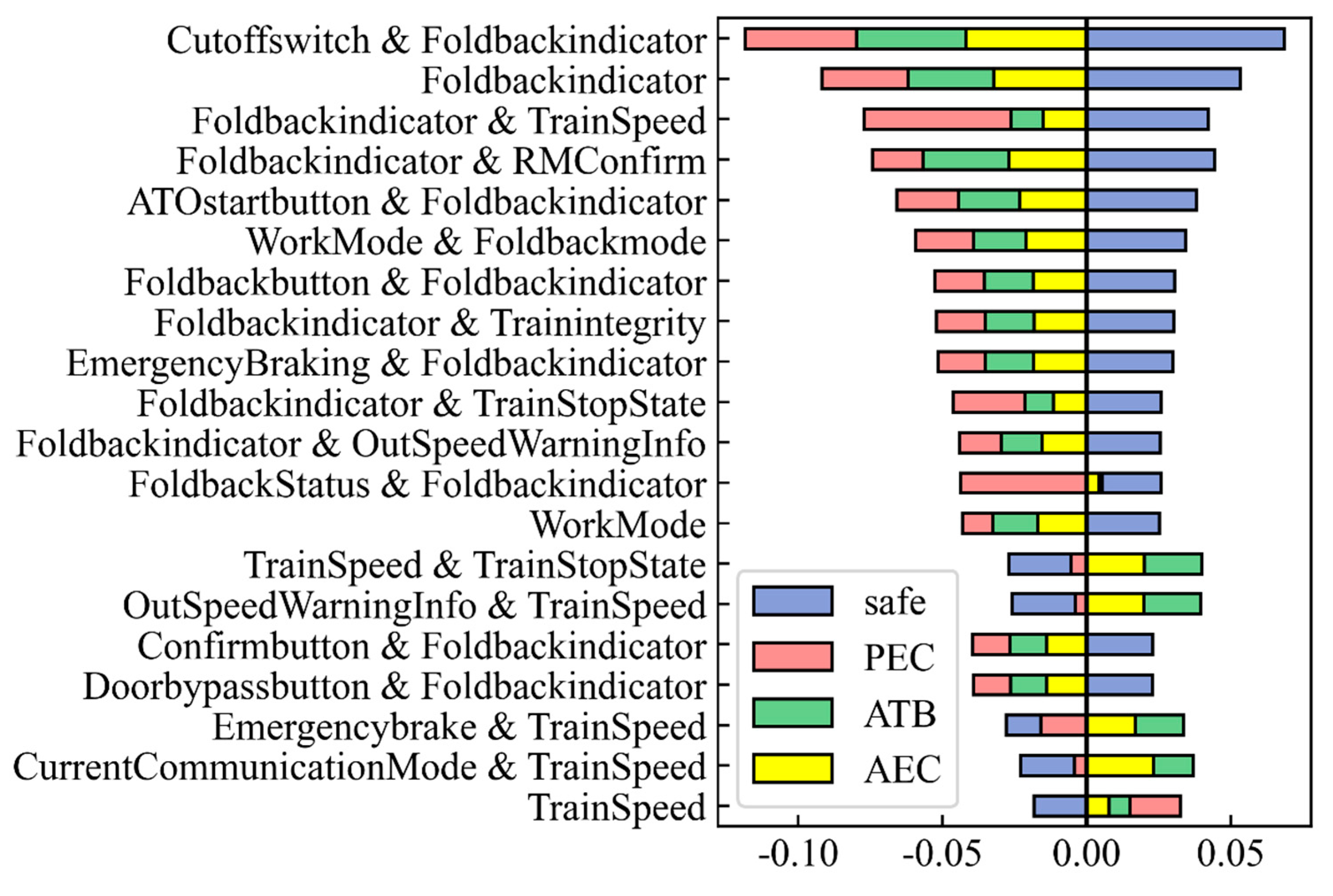
Research into the three different kinds of turn-back fault has been undertaken to help the system make an accurate and timely diagnosis. From a data-driven perspective, this research uses an overall framework for understanding train failure during reentry. Specifically, the research on urban rail transit can (1) mine different reentry rules; (2) combine rules and algorithms to improve the quality and accuracy of algorithms; and (3) help testers analyze, understand, and determine the faults.
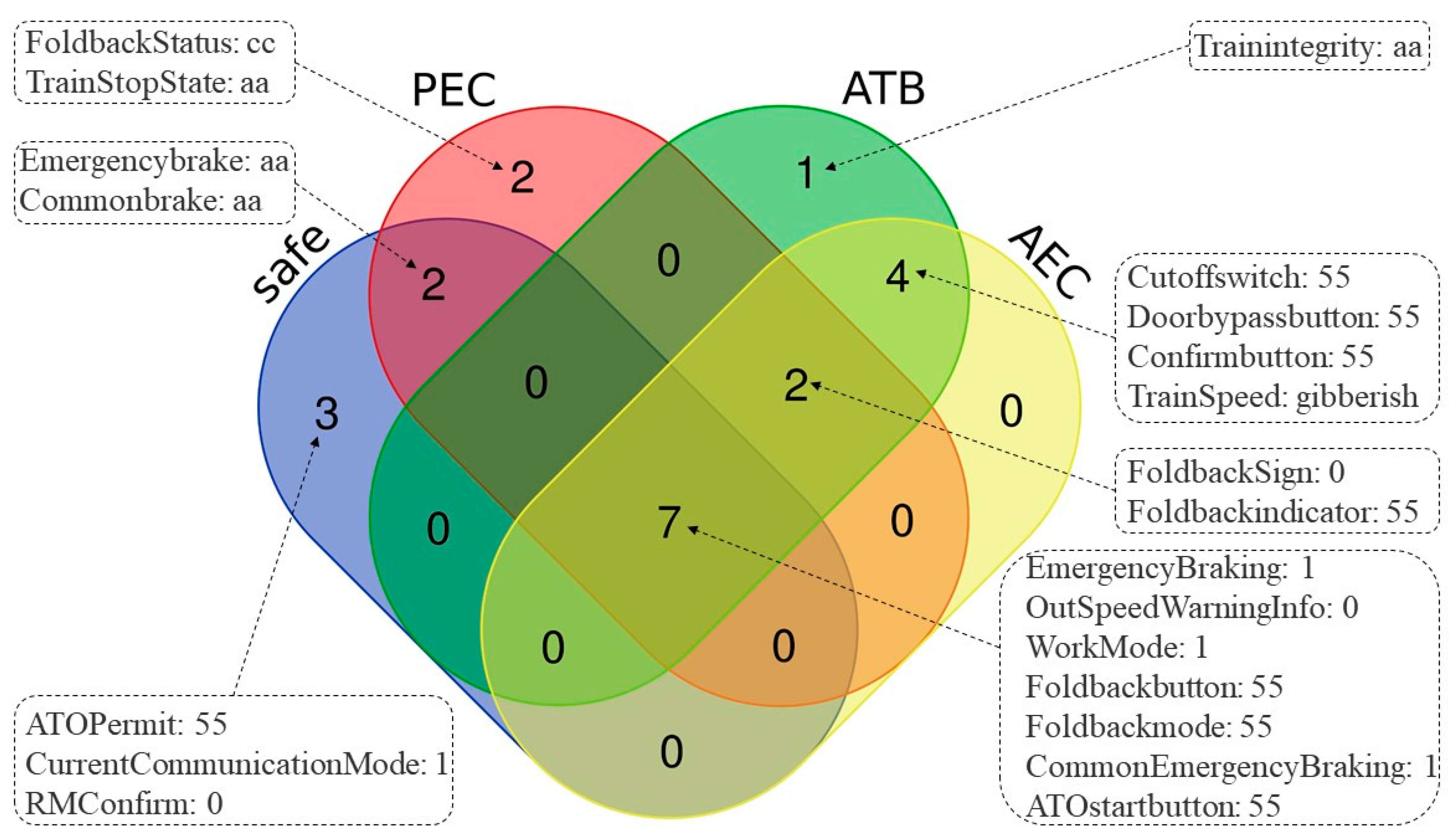
Based on the urban rail transit system, this study analyzed tabular and text data. We searched and cleaned the data in train work logs and daily work reports of field testers. As implied by the “no free lunch theorem” [
5], there is no universal optimal algorithm. This research combined real application scenarios and domain knowledge to conduct a comparative test of classification algorithms. We established a data set containing three types of turn-back failures. This data set is large, and the proportional distribution of fault categories was kept to be consistent with the real scene. The data set containing all three reentry scene failures is valuable for the field of urban rail transit failures.
Understanding these failures can improve the efficiency of the urban rail transit system and ensure the safety of passengers. The frequent itemset generation (FIG) algorithm can be used to mine the rules under different failure scenarios. Classification algorithms, such as random forest (RF) [
6], gradient boosting decision tree (GBDT) [
7], AdaBoost [
8], classification regression tree (CART) [
9], logistic regression (LR) [
10], support vector machine (SVM) [
11], and naïve Bayes [
12], are often used in the research of classification problems in industrial scenarios. In this study, we used the frequent itemset generation algorithm based on Spark to mine feature combinations that frequently appeared in the work log and performed feature crossover based on the frequent item sets. Then, we trained the classification algorithm to automatically determine when the failure occurs was an automatic turn-back (ATB), automatic end change (AEC), or point mode end change (PEC).
We used machine learning methods to understand and judge the reentry failures of urban rail transit. In this study, we proposed a framework to (1) generate the fault rules, and classify faults into different return categories based on these rules, and (2) analyze the probability distribution of the topics in the daily work report to understand the characteristics of turn-back faults. The framework can help machines, experts, and testers to cooperate in analyzing the failures of urban rail transit turn-back faults.
The reason for choosing this method in this study is the need to identify the type of failure for more efficient maintenance. Classification algorithms and topic modeling can be of assistance in this process.
The remainder of this paper is organized as follows: Chapter II reviews previous literature on urban rail transit, classification algorithms, and topic modeling. Chapter III describes the turn-back method and communication module of urban rail trains. Chapter IV introduces the data set and presents descriptive statistics. Chapter V presents the design of the overall framework. Chapter VI conducts simulation experiments and compares the results. Chapter VII presents conclusions.
2. Literature Review
Previous research involves three areas: (1) urban rail transit, (2) the classification algorithm, and (3) topic modeling.
2.1. Urban Rail Transit
Research on urban rail has mainly focused on modeling of the communication-based train control (CBTC) system of urban rail transit communication. Huang and Huang proposed the design of the communication subsystem of the urban rail transit CBTC system, which transmits information to trains through two-way channels in real time to ensure the safety of urban rail transit trains [
13]. Xiao and Zheng also studied the CBTC system of urban rail transit trains. They reordered the weights of various indicators through fuzzy decision trajectory and evaluation laboratory analysis of the process and the factors’ network, finally improving the service quality of urban rail transit [
14]. Srisooksai et al. used the deep learning approach to classify the transmission signal of the CBCT system [
15]. Castiglione and Lupu studied system information security issues by quantifying CBTC system signals and external attack signals [
16]. Singh and Mishra analyzed and compared the request to send/clear to send (RTS/CTS) media access mechanisms, noting that they are suitable for signal transmission in the CBTC system [
17].
Furthermore, other scholars have focused on research of the vehicle on-board controller (VOBC), which is one of CTBC’s subsystems. Gu et al. proposed a cloud sharing idea for real-time diagnostic data based on the diagnostic data of the VOBC system in urban rail transit, which provided a basis for solving the problem of sharing and analyzing these real-time diagnostic data [
18]. Wang et al. developed a hybrid online model-based testing (MBT) platform and tested it with real VOBC data [
19].
The goal of other researchers was to investigate and analyze the passenger volume of urban rail transit. Li et al. established a traffic flow prediction model using the seasonal autoregressive integrated moving average model (SARIMA) and a support vector machine (SVM). They concluded that the SARIMA-SVM model can fully characterize traffic flow changes and is suitable for the passenger flow prediction of urban rail transit [
20]. Su and Li used a hybrid logit model to construct an optimization model for collaborative control of urban rail transit network passenger flow, which describes the online distribution of passenger flow in the urban rail transit network [
21].
Our research is based on the above content. The focus of this study is on the analysis and identification of three different kinds of turn-back of urban rail transit trains: automatic end change (AEC), automatic turn-back (ATB), and point mode end change (PEC). We aimed to combine structured data and text data to analyze the return method and the characteristics of the communication code when a failure occurs.
2.2. Classification Algorithm
Various machine learning models have been explored in fault diagnosis to detect the occurrence of faults. There are two broad categories: supervised and unsupervised algorithms. The former is the dominant and more widely used method. The important difference between supervised machine learning and unsupervised machine learning is the existence (or lack thereof) of a training set that has a corresponding target output with multiple given inputs [
22].
Supervised learning has been widely used in the field of fault diagnosis. Wang et al. proposed a new hybrid method of random forest classifiers and applied it to the fault diagnosis of rolling bearings. Experiments show that their method has high diagnostic accuracy, but this method can only diagnose a single fault [
6]. Li et al. improved the C4.5 decision tree and performed fault classification by extracting fault features in the brake system. In the application scenarios of big data, the classification accuracy of the improved algorithm has been greatly improved [
23]. He et al. studied the superconducting fault current limiter and proposed a support vector machine fault diagnosis method, which was applied to a nonlinear regression between AC current and AC voltage [
24]. However, this study uses an image-oriented feature extraction method, which is very time-consuming.
Other scholars applied unsupervised learning to the field of fault diagnosis. Yang et al. proposed a fault diagnosis method for the analysis of dissolved gases in power transformers based on association rules and compared it with K-nearest neighbor (KNN), SVM, and other algorithms [
25]. Liu et al. used frequent pattern growth (FP-Growth) to propose a method for locating and diagnosing branch line faults in a distribution network with multiple data sources [
26]. Bashir et al. proposed a method of using pattern growth to mine fault tolerant frequent patterns. They stored the original data set in a highly concentrated environment, which avoided multiple scans of the data set, and used algorithms such as Apriori for comparison [
27]. Shawkat et al. used the FP-Growth algorithm to increase the speed of rule mining for new crown virus diagnosis, but a certain amount of memory overhead was generated during rule generation [
28].
Compared with the classification algorithm used in the above study, the combination of fault rules and algorithms is used in this study, which is more accurate than the study using only rules, and it improves the interpretability of supervised algorithms.
2.3. Topic Modeling
The topic model is a statistical model that clusters the hidden semantics in the text through unsupervised learning. It is mainly used by scholars for text mining and text analysis. The latent Dirichlet allocation (LDA) used in this study is one of the typical topic models. It generates each topic by mixing words and each document with mixed topics.
LDA has been used by many scholars for analysis in the field of fault diagnosis. Wei et al. used data mining for vehicle-mounted Chinese Train Control System (CTCS) equipment on the train to establish a fault information database and used an improved label-LDA to extract the semantics in the work log, classifying and comparing classification accuracy through particle swarm optimization (PSO)-SVM, traditional SVM, and KNN [
29]. Wang et al. proposed a text mining method based on two-layer feature extraction; that is, the feature weight χ
2 was used first, and then the traditional LDA model was used. Finally, it was used in the fault diagnosis of railway maintenance data. However, this method is less effective for the classification of unbalanced data [
30]. In the current study, LDA was used to analyze the semantics of daily work reports, so there is no need to consider this issue. Pyo et al. used the topic modeling method based on LDA to propose a unified topic model for grouping similar TV users through TV descriptors and recommending similar TV programs [
31]. Based on semi-supervised non-negative matrix factorization (NMF), Choo et al. proposed a topic modeling visual analysis system called UTOPIAN and compared the results with LDA analysis after applying it to different scenarios [
32]. Allahyari and Kochut introduced an entity topic modeling method called EntLDA and combined the semantic concepts in DBpedia with unsupervised learning approaches such as LDA [
33].
Compared with the above literature, the current research combined domain knowledge and used the LDA model to assist in analyzing the characteristics of the three reentrant failures in daily work reports, focusing on the semantic analysis of the text and the interpretability of the algorithm.
However, the above articles lack an in-depth analysis of the three types of faults during the turn-back faults of urban rail transit, and little attention has been paid to the data combined with the train communication code and the daily work report of testers.
7. Conclusions
Focusing on the common faults in urban rail transit systems, we studied the communication code characteristics of three different turn-back failures, established a general framework, and analyzed the topics’ probability distribution in the daily work. The data were provided by a research institute, and the dataset includes the work log of the urban rail train and the daily work report at the location. Our experimental results show that the framework demonstrates good performance in fault classification and topic analysis.
In this study, three types and characteristics of turn-back failures that are of practical significance were studied. Urban rail transit managers can use this framework to better understand the internal and external characteristics of the train when a turn-back failure occurs, thereby speeding up the handling of failures and ensuring the safety of passengers and property.
However, this study has limitations. Research on the maintenance plan for turn-back failures is scarce. Matching different turn-back failures and their maintenance plans will be investigated in the future. In future studies, we will also further exploit the research value of the data set that we established. Natural language processing technology can be applied to analyze and generate maintenance plans for urban rail transit. This framework can also be applied for the research and analysis of other faults of urban rail.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}