
Lifelong Learning Courses Recommendation System to Improve Professional Skills Using Ontology and Machine Learning



Abstract
:Featured Application
Abstract
1. Introduction
2. Related Studies
3. Materials and Methods
3.1. Materials
3.2. Methods
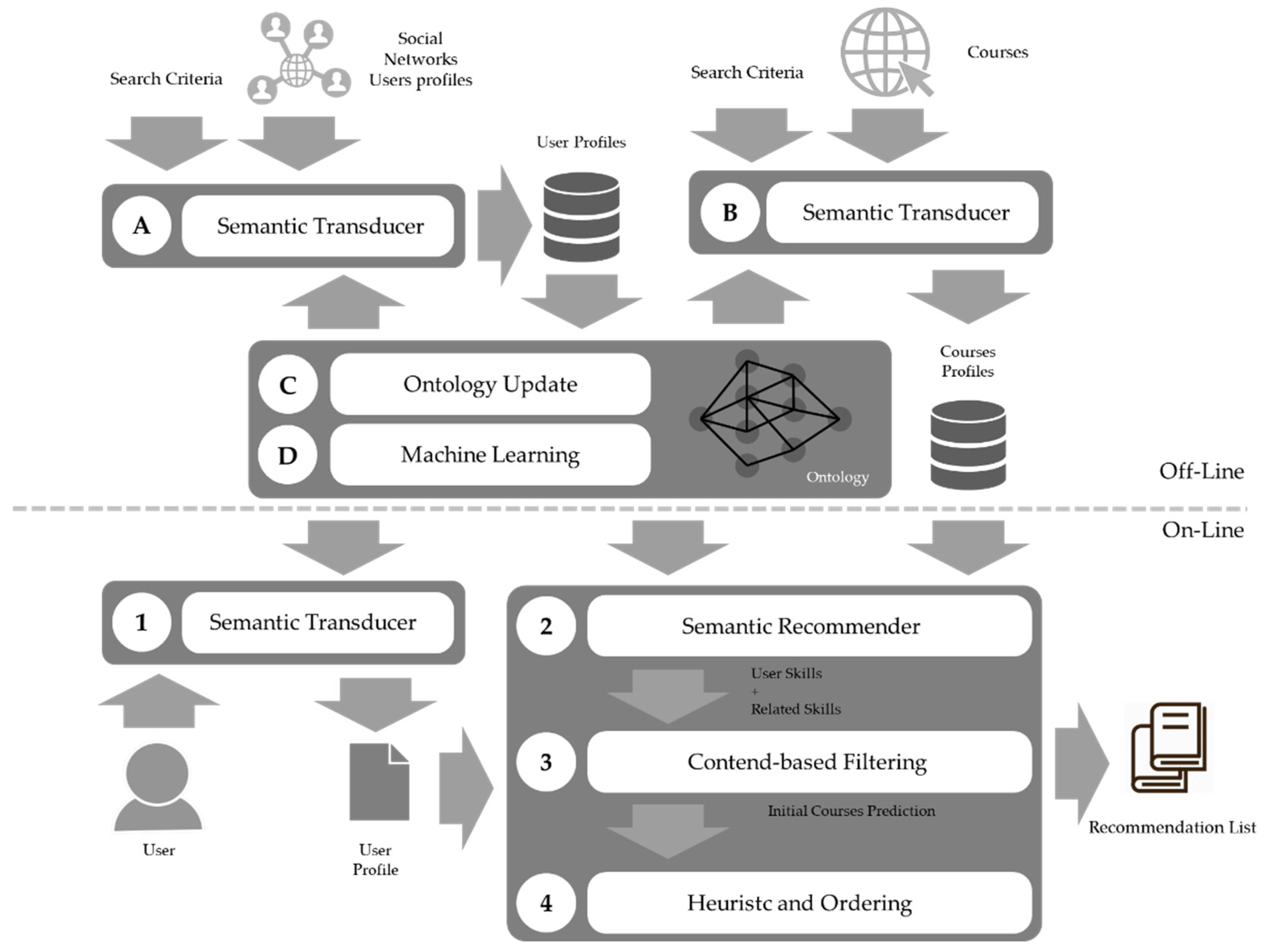
3.2.1. Off-Line Phase
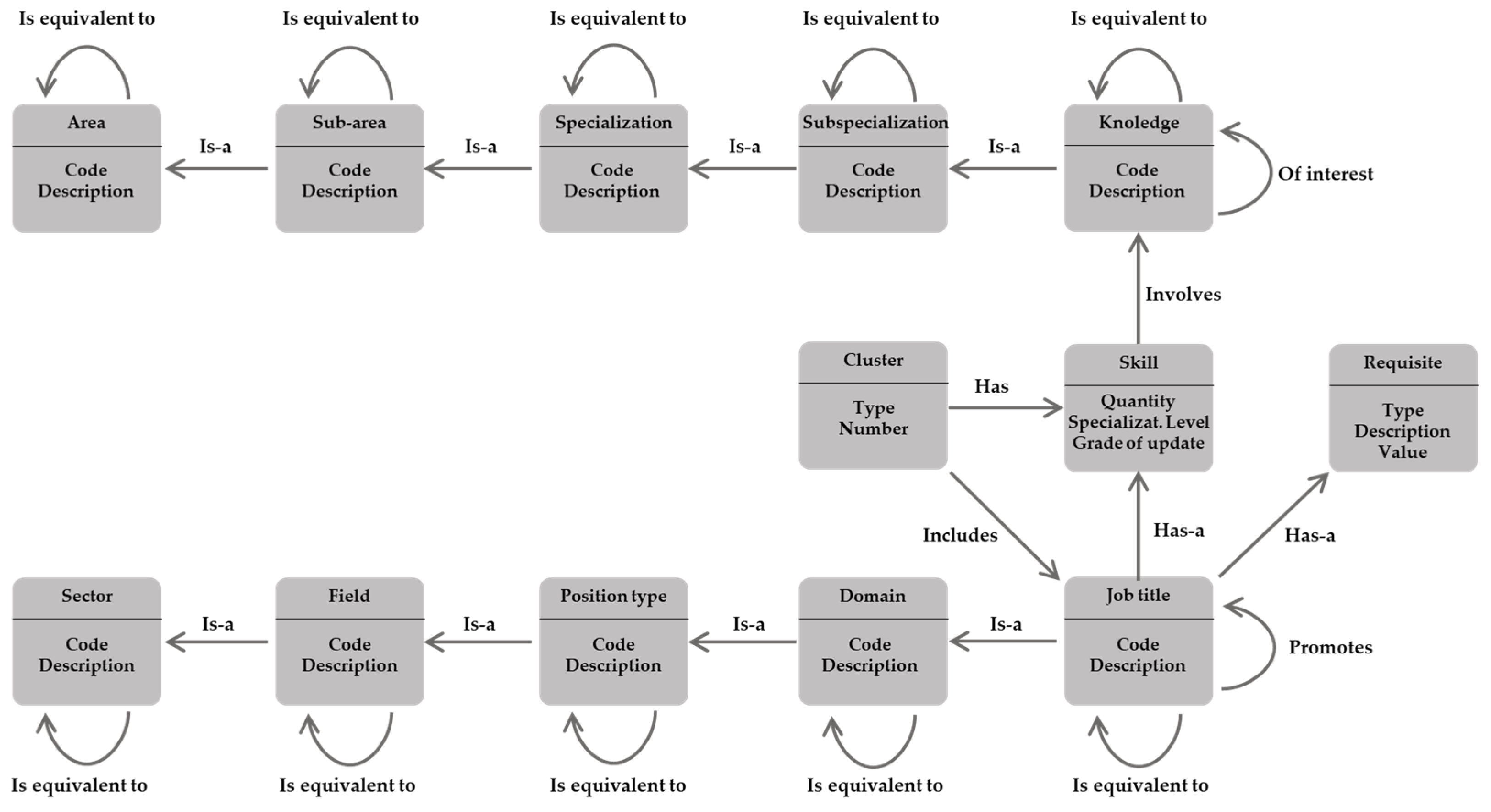
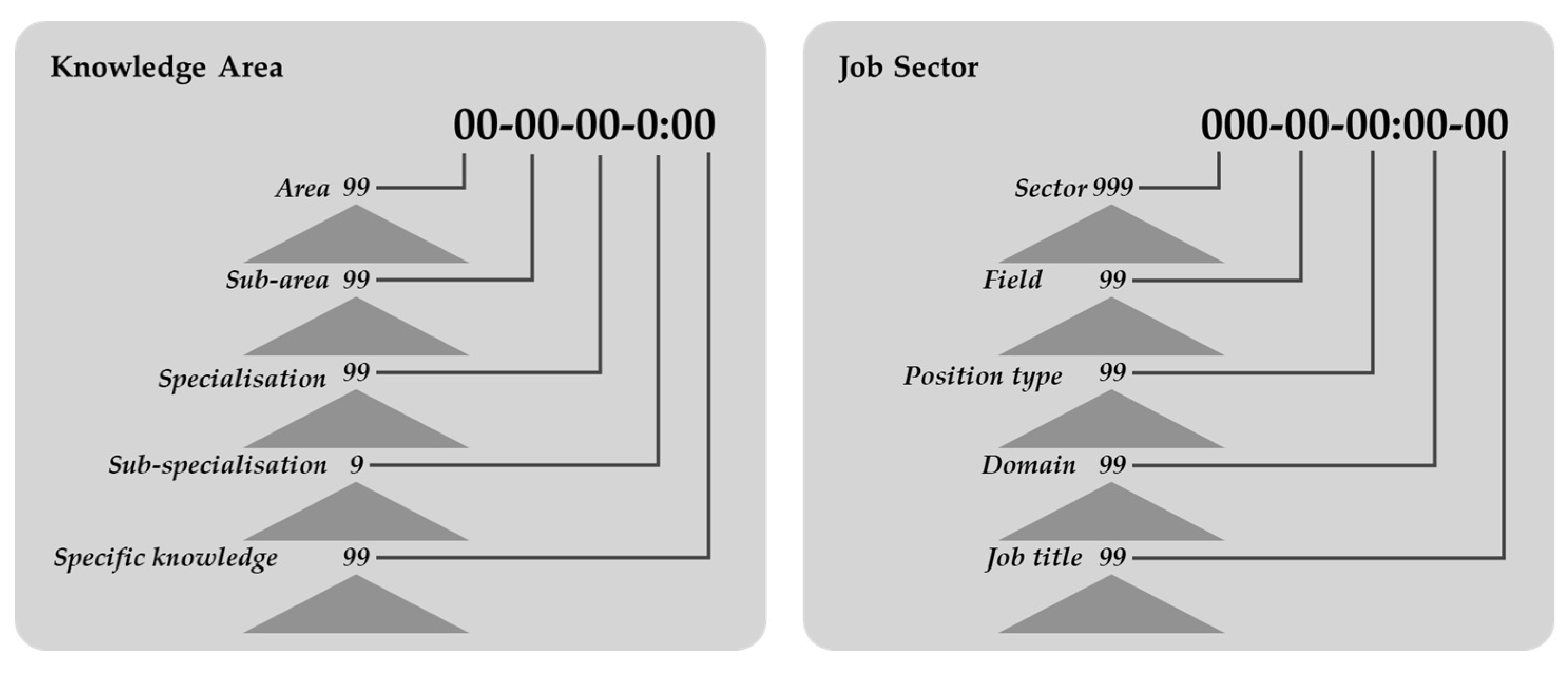
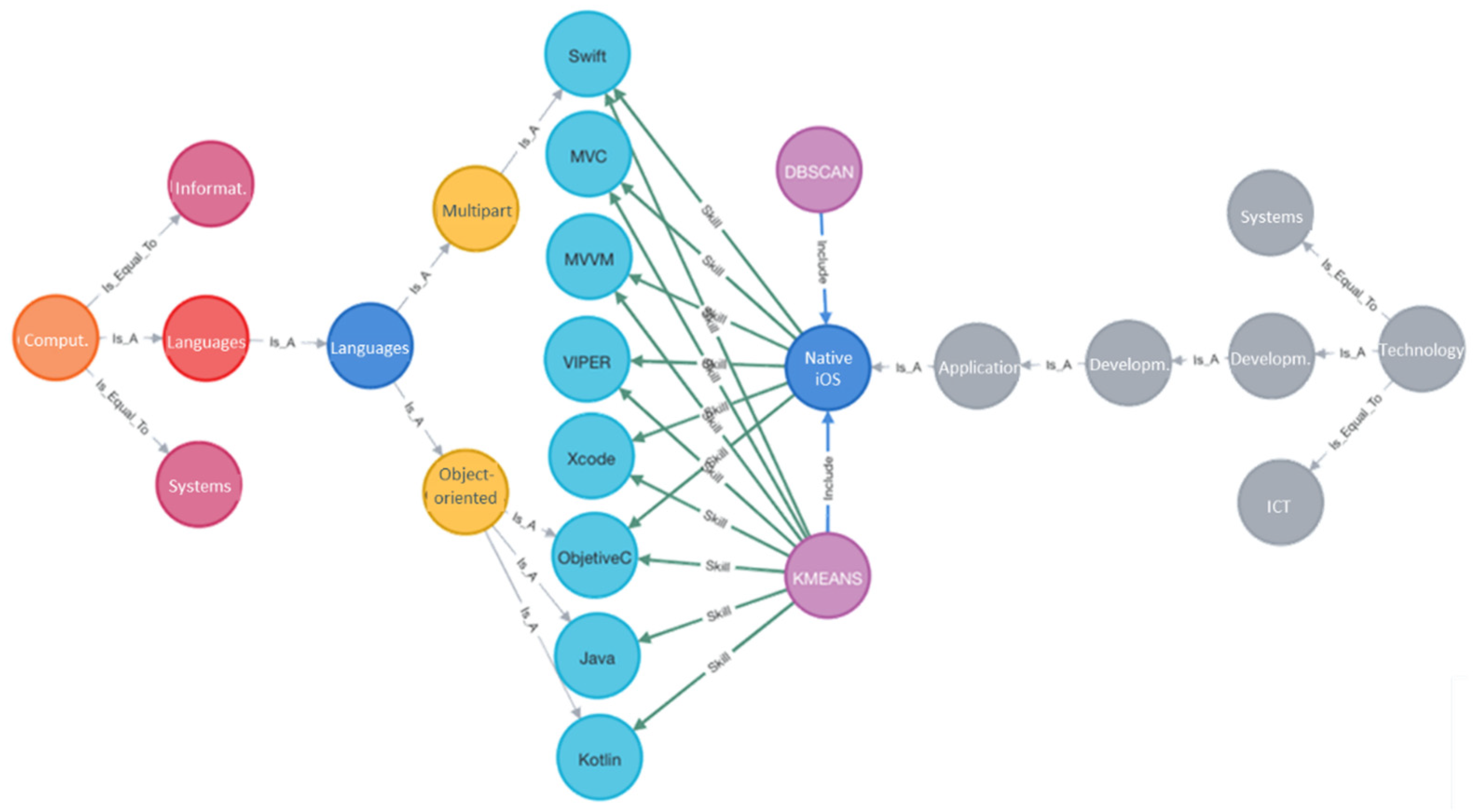
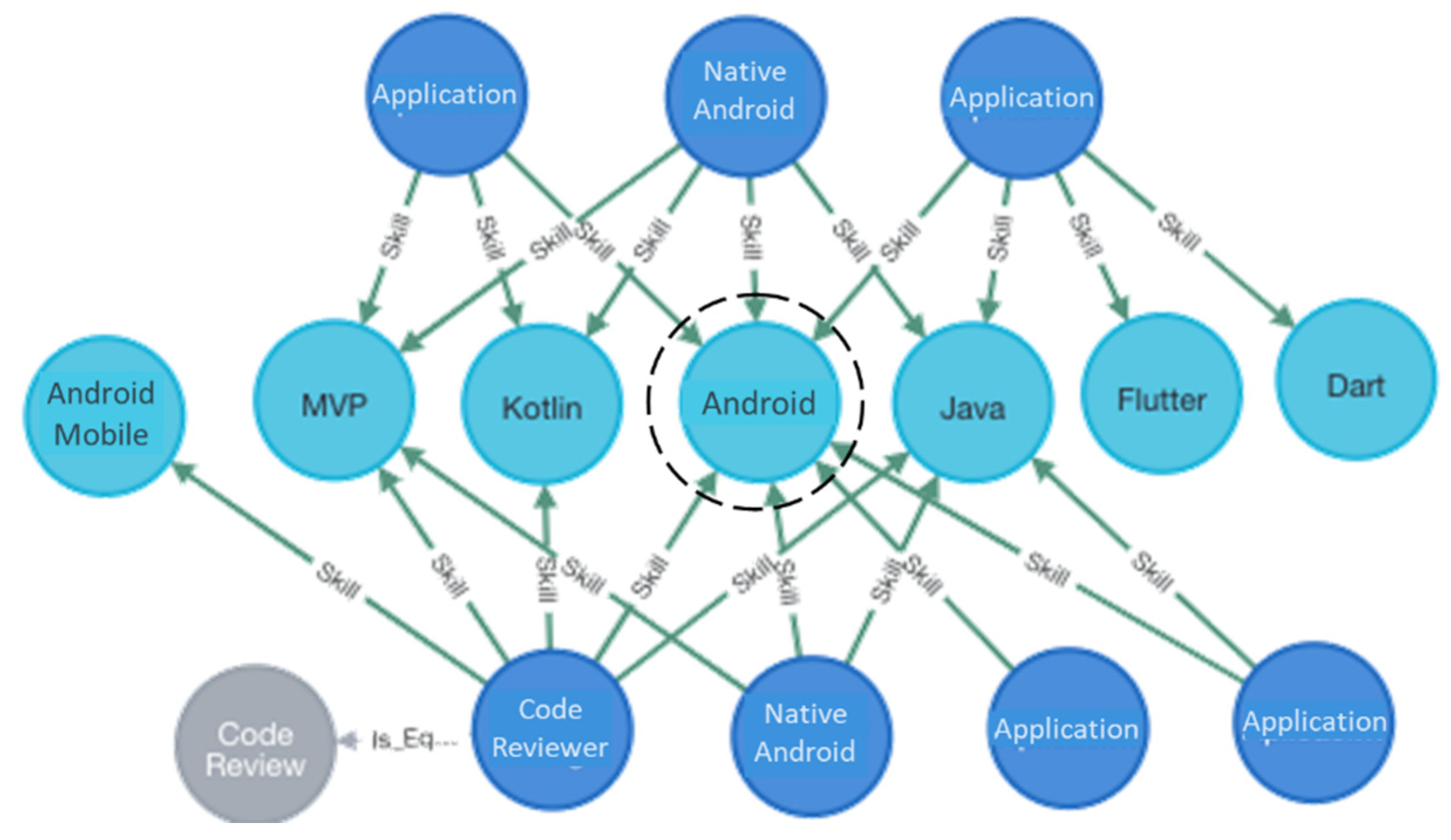
Ontology
3.2.2. On-Line Phase
User Profiles
Course Profiles
Similarity Functions
Taxonomic Similarity for Job Sectors
- Job sectors.
- : Depth of taxonomy.
- : Constant for relevance of level l in the taxonomy.
- : Level l function comparison, with wildcard support and
Taxonomic Similarity for Areas of Knowledge
Similarity of User Skills
Assessment of Skill Development
- : Skill set i.
- : Skill set j.
- : Cut-off threshold for the taxonomic similarity function.
- .
- .
Cosine Similarity Function for User Skills
Pearson’s Similarity Function for User Skills
Recommendation Process
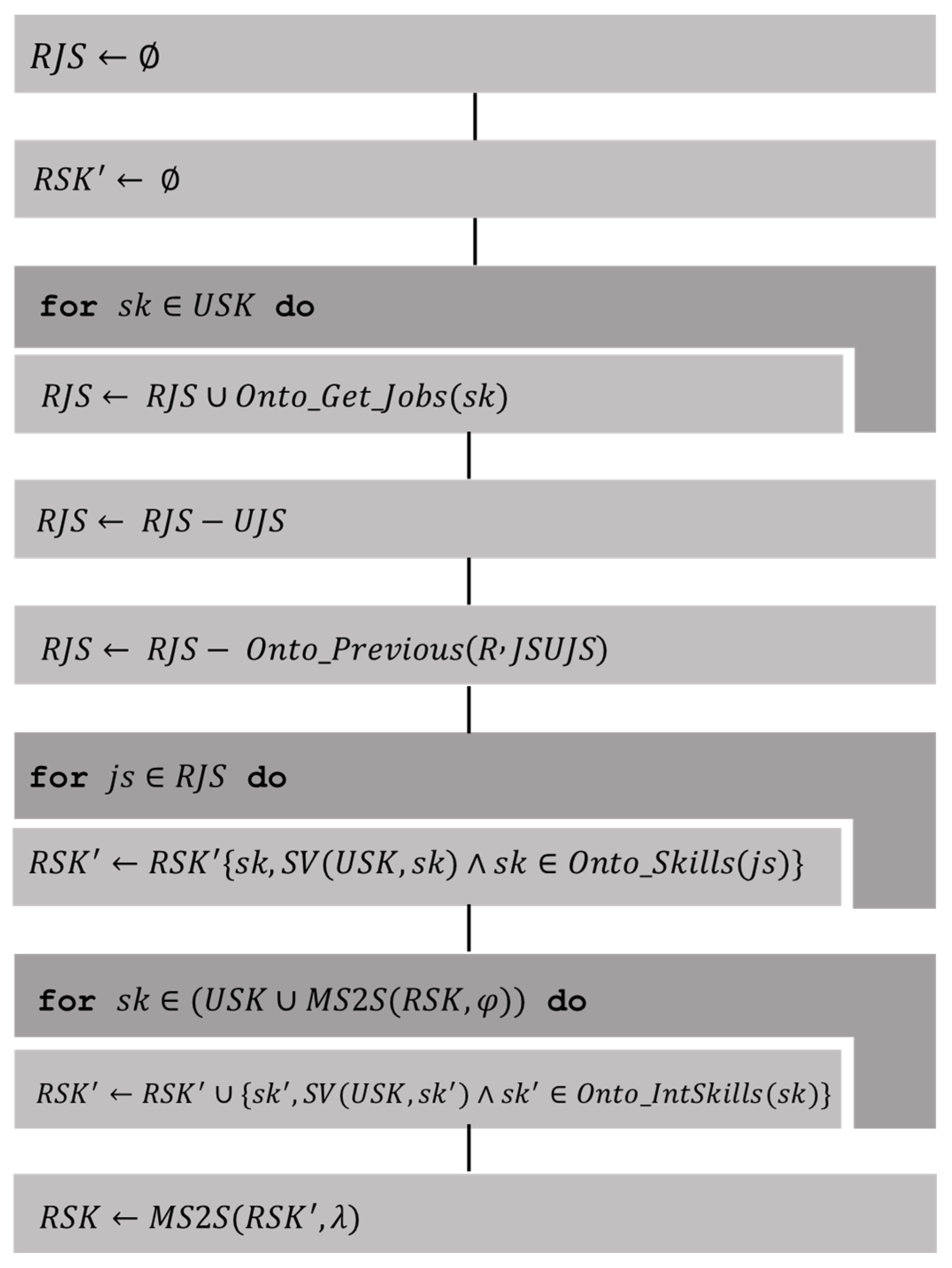
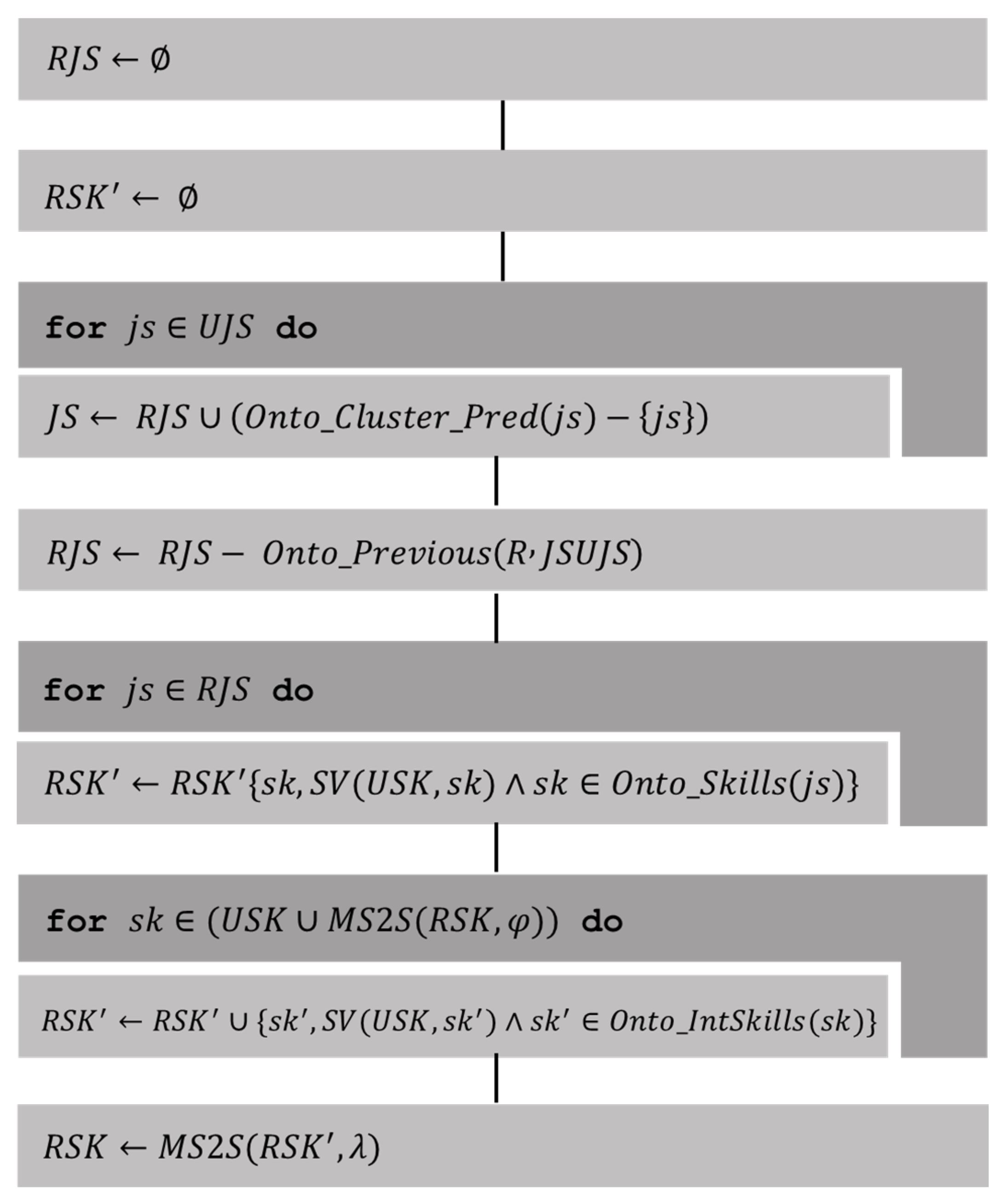
Determining Related Job Sectors (2)
- , job sectors where users have the skill recorded through events in the ontology.
- predicts the cluster for a job sector according to clustering by ML in the ontology.
- , the previous sectors in to according to the orderly relationship given by the hierarchy in the ontology.
- are the skills represented in the ontology, which are the product of an event-driven update of user profiles.
- are the skills of interest associated with the skills represented in the ontology.
- , function that verifies that the skill is valuable for the skills .
- constructs a set with the most frequent elements in the multiset .
- , Multiset of related skills.
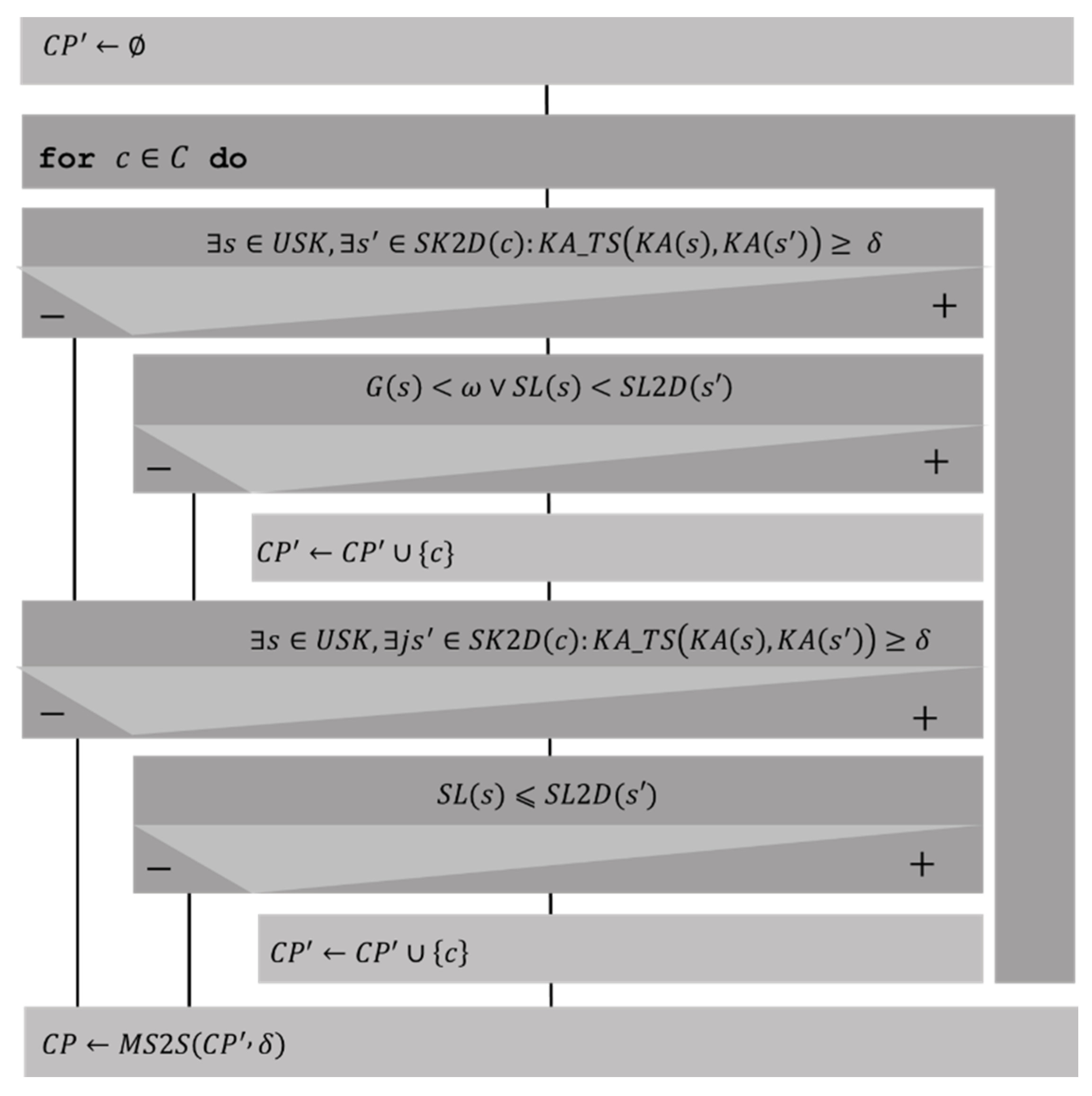
Initial Course Prediction (3)
Filtering Heuristics and Course Ordering (4)
- Users possessed the necessary skills to take the courses; otherwise, courses were selected to develop those skills, applying demographic restrictions.
- User demographic restrictions were applied to the initial course prediction, and to the result of the previous phase.
- In the prediction of courses, courses where the skills to be developed were the same or a subset of another were deleted, and the best-rated prediction was kept.
Measurements for the Evaluation of RSs
4. Results
- Content filtering using user’s own and associated skills; no related skills were determined.
- Collaborative filtering using only user’s own job sectors; semantically related skills were determined.
- Semantic filtering using rules to determine related job sectors and related skills.
- Semantic filtering using 75% coverage of user skills to determine related job sectors, i.e., those job sectors that covered 75% of the user’s skills were selected and used to determine related skills.
- Semantic filtering using 50% coverage of user skills to determine related job sectors, i.e., those job sectors that covered 50% of the user’s skills were selected and used to determine related skills.
- Semantic filtering using DBSCAN clustering to determine related job sectors and semantic rules to establish related skills.
- Semantic filtering using K-Means clustering to determine related job sectors and semantic rules to establish related skills.
- Semantic filtering using DBSCAN and K-Means clustering to determine related job sectors and semantic rules for related skills using the predicted job sectors with both clusters, and related skills were determined based on both clusters.
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Raitskaya, L.; Tikhonova, E. Skills and Competencies in Higher Education and Beyond. J. Lang. Educ. 2019, 5, 4–8. [Google Scholar] [CrossRef]
- Kenayathulla, H.B.; Ahmad, N.A.; Abdul, R.I. Gaps between competence and importance of employability skills: Evidence from Malaysia. High. Educ. Eval. Dev. 2019, 13, 97–112. [Google Scholar] [CrossRef] [Green Version]
- Kálmán, A.; Molnár, G.; Szűts, Z. Issues of Lifelong Learning—Behavioral ends of teaching and learning through ICT. In Proceedings of the 9th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Budapest, Hungary, 22–24 August 2018; pp. 395–398. [Google Scholar] [CrossRef]
- Stromquist, N.P.; da Costa, R.B. Popular universities: An alternative vision for lifelong learning in Europe. Int. Rev. Educ. 2017, 63, 725–744. [Google Scholar] [CrossRef]
- Van Laar, E.; van Deursen, A.J.A.M.; van Dijk, J.A.G.M.; de Haan, J. The relation between 21st-century skills and digital skills: A systematic literature review. Comput. Hum. Behav. 2017, 72, 577–588. [Google Scholar] [CrossRef]
- Knowles, M.S.; Elwood, F.H., III; Swanson, R.A. The Adult Learner: The Definitive Classic in Adult Education and Human Resource Development; Routledge: London, UK, 2007; pp. 132–139. [Google Scholar]
- Laal, M. Lifelong learning: What does it mean? Procedia Soc. Behav. Sci. 2011, 28, 470–474. [Google Scholar] [CrossRef] [Green Version]
- Keinänen, M.; Ursin, J.; Nissinen, K. How to measure students’ innovation competences in higher education: Evaluation of an assessment tool in authentic learning environments. Stud. Educ. Eval. 2018, 58, 30–36. [Google Scholar] [CrossRef]
- van Deursen, A.J.A.M.; Verlage, C.; van Laar, E. Social Network Site Skills for Communication Professionals: Conceptualization, Operationalization, and an Empirical Investigation. IEEE Trans. Prof. Commun. 2019, 62, 43–54. [Google Scholar] [CrossRef]
- Melão, N.; Reis, J. Using Social Networks in Personnel Selection: A Survey of Human Resource Professionals. In Proceedings of the 2020 15th Iberian Conference on Information Systems and Technologies (CISTI), Sevilla, Spain, 24–27 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Ponte, M.C.U.; Zorilla, A.M.; Ruiz, I.O. Taxonomy-based hybrid recommendation system for lifelong learning to improve professional skills. In Proceedings of the 2020 IEEE International Conference on Engineering, Technology and Education (TALE), Shenzhen, China, 8–11 December 2020. [Google Scholar]
- Aggarwal, C. Recommender Systems. The Textbook; Springer: New York, NY, USA, 2016. [Google Scholar]
- Akmaliah, F.; Krisnadhi, A.A.; Sensuse, D.I.; Rahayu, P.; Wulandari, I.A. Role of Ontology and Machine Learning in Recommender Systems. In Proceedings of the 2018 Electrical Power, Electronics, Communications, Controls and Informatics Seminar (EECCIS), Batu, Indonesia, 9–11 October 2018; pp. 371–376. [Google Scholar] [CrossRef]
- Shao, J. Research on Fuzzy Ontology E-learning Based on User Profile. In Proceedings of the 2017 International Conference on E-Education, E-Business and E-Technology (ICEBT 2017), Toronto, ON, Canada, 10–12 September 2017; pp. 46–49. [Google Scholar] [CrossRef]
- Xu, Z.; Tifrea-Marciuska, O.; Lukasiewicz, T.; Martinez, M.V.; Simari, G.I.; Chen, C. Lightweight Tag-Aware Personalized Recommendation on the Social Web Using Ontological Similarity. IEEE Access 2018, 6, 35590–35610. [Google Scholar] [CrossRef]
- Pereira, C.; Campos, F.; Ströele, V.; David, J.; Braga, R. BROAD-RSI—Educational recommender system using social networks interactions and linked data. J. Internet Serv. Appl. 2018, 9, 7. [Google Scholar] [CrossRef] [Green Version]
- Gil Robles, M. Organizational Transformation during COVID-19. IEEE Eng. Manag. Rev. 2020, 48, 31–36. [Google Scholar] [CrossRef]
- Bakhshinategh, B.; Spanakis, G.; Zaïane, O.; ElAtia, S. A Course Recommender System based on Graduating Attributes. In Proceedings of the 9th International Conference on Computer Supported Education, Porto, Portugal, 21–23 April 2017. [Google Scholar]
- Patel, B.; Kakuste, V.; Eirinaki, M. CaPaR: A Career Path Recommendation Framework. In Proceedings of the 2017 IEEE Third International Conference on Big Data Computing Service and Applications (BigDataService), San Francisco, CA, USA, 6–9 April 2017; pp. 23–30. [Google Scholar] [CrossRef]
- Bañeres, D.; Conesa, J. eOrient@—A Recommender System toAddress Life-Long Learning and Promote Employability. In Proceedings of the 2016 International Conference on Intelligent Networking and Collaborative Systems (INCoS), Ostrawva, Czech Republic, 7–9 September 2016; pp. 351–356. [Google Scholar] [CrossRef]
- Ibrahim, M.; Yang, Y.; Ndzi, D.; Yang, G.; Al-Maliki, M. Ontology-Based Personalized Course Recommendation Framework. IEEE Access 2019, 7, 5180–5199. [Google Scholar] [CrossRef]
- Diaby, M.; Viennet, E. Taxonomy-based job recommender systems on Facebook and LinkedIn profiles. In Proceedings of the 2014 IEEE Eighth International Conference on Research Challenges in Information Science (RCIS), Marrakech, Morocco, 28–30 May 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Kuznetsov, S.; Kordík, P.; Řehořek, T.; Dvořák, J.; Kroha, P. Reducing cold start problems in educational recommender systems. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3143–3149. [Google Scholar] [CrossRef]
- Koh, M.; Chew, Y. Intelligent Job Matching with Self-learning Recommendation Engine. Procedia Manuf. 2015, 3, 1959–1965. [Google Scholar] [CrossRef] [Green Version]
- Valentin, C.D.; Emrich, A.; Lahann, J.; Werth, D.; Loos, P. Adaptive Social Media Skills Trainer for Vocational Education and Training: Concept and Implementation of a Recommender System. In Proceedings of the 2015 48th Hawaii International Conference on System Sciences, Kauai, HI, USA, 5–8 January 2015; pp. 1951–1960. [Google Scholar] [CrossRef]
- Tarus, J.K.; Niu, Z.; Yousif, A. A hybrid knowledge-based recommender system for e-learning based on ontology and sequential pattern mining. Future Gener. Comput. Syst. 2017, 72, 37–48. [Google Scholar] [CrossRef]
- Harrathi, M.; Touzani, N.; Braham, R. A Hybrid Knowlegde-Based Approach for Recommending Massive Learning Activities. In Proceedings of the 2017 IEEE/ACS 14th International Conference on Computer Systems and Applications (AICCSA), Hammamet, Tunisia, 30 October–3 November 2017. [Google Scholar] [CrossRef]
- Cerón-Figueroa, S.; López-Yáñez, I.; Alhalabi, W.; Camacho-Nieto, O.; Villuendas-Rey, Y.; Aldape-Pérez, M.; Yáñez-Márquez, C. Instance-based ontology matching for e-learning material using an associative pattern classifier. Comput. Hum. Behav. 2017, 69, 218–225. [Google Scholar] [CrossRef]
- Balachander, Y.; Moh, T. Ontology Based Similarity for Information Technology Skills. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 30 August 2018; pp. 302–305. [Google Scholar] [CrossRef]
- Gugnani, V.K.; Kasireddy, R.; Ponnalagu, K. Generating Unified Candidate Skill Graph for Career Path Recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 328–333. [Google Scholar] [CrossRef]
- Obeid, C.; Lahoud, I.; Khoury, H.E.; Champin, P. Ontology-based Recommender System in Higher Education. In Proceedings of the Companion Proceedings of the Web Conference, Lyon, France, 23–27 April 2018. [Google Scholar]
- Aissaoui, O.E.; Oughdir, L. A learning style-based Ontology Matching to enhance learning resources recommendation. In Proceedings of the 2020 1st International Conference on Innovative Research in Applied Science, Engineering and Technology (IRASET), Meknes, Morocco, 19–20 March 2020. [Google Scholar] [CrossRef]
- Liu, H.; Jiang, G.; Su, L.; Cao, Y.; Diao, F.; Mi, L. Construction of power projects knowledge graph based on graph database Neo4j. In Proceedings of the 2020 International Conference on Computer, Information and Telecommunication Systems (CITS), Hangzhou, China, 5–7 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B. Recommender Systems Handbook, 2nd ed.; Springer: New York, NY, USA, 2015; pp. 265–308. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Objective | Techniques | Ontology | Assessment | Results |
|---|---|---|---|---|---|---|
| [24] | 2015 | Job recommendations | Ontology Similarity algorithms | Job vacancies Tasks | Not provided | Not provided |
| [25] | 2015 | Social media recommender systems for the development of social media skills | Ontology Filtering by content and context | Social media | Quality of results and integration of functions by users | 3.62/5 |
| [26] | 2017 | Educational resources recomendations | Ontology Sequential pattern mining (SPM) | Students’ educational resources | Comparison of user satisfaction between the proposed system and other RSs, without ontology, and without SPM. | 94% |
| [27] | 2017 | Recommendation of massive learning activities | OntologyKnowledge-based filtering | Students’ Learning Activities | Not provided | Not provided |
| [28] | 2017 | Recommendation of learning materials | Ontology Canopy-K means Collaborative filtering | Educational Material | Comparison with other algorithm | Improved precision by 2.8 |
| [29] | 2018 | Job recommendations | Ontology | Skills | Calculating similarity scores of Pointwise Mutual Information (PMI) | 0.975 |
| [30] | 2018 | Career path recommendation | Ontology | Skills | Calculation of information recall related parameters | Precision: 80.54% Recall: 86.44% |
| [31] | 2019 | Recommending the right degree and university for each person | Ontology K-means | Higher education institution. Student Work | Proposal | Proposal |
| [32] | 2020 | Recommendation of e-learning resources | Ontology Content-based filtering | Student Learning content | Proposal | Proposal |
| Measurement | Description | Calculation for the User | Calculation for System |
|---|---|---|---|
| MAE | Mean absolute error of the given recommendation vs. the recommendation expected by the user | ||
| RMSE | Root mean square error | ||
| Coverage | Users to whom the system has made a recommendation, CRi set of recommendations from ui ∈U | ||
| Precision: | The fraction of the recommendation that is relevant to the user. | ||
| Recall: | Calculates the ratio between recommendation and user preference, where CEi is the preference group of ui ∈U | ||
| Novelty | The portion of recommendations made to the user that the user is not familiar with or has not seen before | ||
| Serendipity | The fraction of the recommendation that is unexpected and valuable to the user. | Where: |
| Setting | MAE | RMSE | Coverage | Precision | Recall | Novelty | Serendipity |
|---|---|---|---|---|---|---|---|
| 1 | 0.58 | 9.13 | 0.64 | 1.00 | 0.36 | 0.14 | 0.09 |
| 2 | 0.51 | 8.22 | 0.73 | 0.97 | 0.41 | 0.21 | 0.07 |
| 3 | 0.25 | 4.44 | 0.91 | 0.83 | 0.82 | 0.46 | 0.07 |
| 4 | 0.22 | 3.65 | 0.82 | 0.93 | 0.71 | 0.45 | 0.07 |
| 5 | 0.38 | 6.62 | 0.91 | 0.80 | 0.74 | 0.39 | 0.07 |
| 6 | 0.18 | 2.92 | 0.91 | 0.91 | 0.80 | 0.52 | 0.07 |
| 7 | 0.49 | 9.25 | 0.91 | 0.67 | 0.63 | 0.31 | 0.04 |
| 8 | 0.30 | 5.24 | 0.95 | 0.80 | 0.80 | 0.48 | 0.04 |
| 9 1 | - | - | 0.91 | 0.91 | 0.70 | 0.52 | 0.06 |
| Setting | MAE | RMSE | Coverage | Precision | Recall | Novelty | Serendipity |
|---|---|---|---|---|---|---|---|
| 1 | 0.59 | 11.05 | 0.61 | 0.99 | 0.37 | 0.11 | 0.06 |
| 2 | 0.50 | 9.49 | 0.71 | 0.97 | 0.45 | 0.17 | 0.05 |
| 3 | 0.25 | 5.16 | 0.94 | 0.82 | 0.87 | 0.39 | 0.06 |
| 4 | 0.23 | 4.49 | 0.81 | 0.94 | 0.73 | 0.39 | 0.05 |
| 5 | 0.34 | 7.03 | 0.87 | 0.84 | 0.75 | 0.34 | 0.06 |
| 6 | 0.27 | 5.63 | 0.94 | 0.84 | 0.86 | 0.45 | 0.05 |
| 7 | 0.51 | 11.72 | 0.94 | 0.62 | 0.65 | 0.25 | 0.04 |
| 8 | 0.35 | 7.64 | 0.97 | 0.75 | 0.86 | 0.42 | 0.03 |
| Setting | MAE | RMSE | Coverage | Precision | Recall | Novelty | Serendipity |
|---|---|---|---|---|---|---|---|
| 1 | 0.62 | 6.24 | 0.56 | 0.96 | 0.41 | 0.04 | 0.00 |
| 2 | 0.47 | 4.75 | 0.67 | 0.96 | 0.56 | 0.07 | 0.00 |
| 3 | 0.23 | 2.64 | 1.00 | 0.80 | 1.00 | 0.24 | 0.04 |
| 4 | 0.26 | 2.63 | 0.78 | 0.96 | 0.78 | 0.26 | 0.00 |
| 5 | 0.25 | 2.60 | 0.78 | 0.94 | 0.78 | 0.21 | 0.02 |
| 6 | 0.43 | 5.42 | 1.00 | 0.67 | 1.00 | 0.28 | 0.00 |
| 7 | 0.56 | 7.24 | 1.00 | 0.49 | 0.69 | 0.12 | 0.06 |
| 8 | 0.45 | 5.79 | 1.00 | 0.62 | 1.00 | 0.28 | 0.00 |
| Setting | Test 1 | Test 2 | Test 3 |
|---|---|---|---|
| 1 | 0.53 | 0.54 | 0.57 |
| 2 | 0.58 | 0.61 | 0.71 |
| 3 | 0.82 | 0.84 | 0.89 |
| 4 | 0.81 | 0.82 | 0.86 |
| 5 | 0.77 | 0.79 | 0.85 |
| 6 | 0.85 | 0.85 | 0.8 |
| 7 | 0.65 | 0.63 | 0.57 |
| 8 | 0.8 | 0.8 | 0.77 |
| 9 | 0.79 | - | - |
| [25] | [27] | [31] | [11] | Author’s Proposal | |
|---|---|---|---|---|---|
| Type | Hybrid RS | Hybrid RS | Hybrid RS | Hybrid RS | Hybrid RS |
| Items to be recommended | MOOC | MOOC | University courses | Lifelong learning | Lifelong learning |
| Use of social network | Yes | - | No | Yes | Yes |
| Semantic | Yes | Yes | Yes | No | Yes |
| Ontology | Yes | Yes | Yes | No | Yes |
| Machine learning | No | No | Yes | No | Yes |
| Types of data | - | - | Structured | Semi-structured/ Unstructured | Semi-structured/ Unstructured |
| Future scenarios | No | No | Yes | Yes | Yes |
| Harmonic mean | - | - | - | 0.79 | 0.85 ML/DB-SCAN |
| Novelty/Serendipity | - | - | - | 0.52/0.06 | 0.52/0.07 ML/DB-SCAN |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Urdaneta-Ponte, M.C.; Méndez-Zorrilla, A.; Oleagordia-Ruiz, I. Lifelong Learning Courses Recommendation System to Improve Professional Skills Using Ontology and Machine Learning. Appl. Sci. 2021, 11, 3839. https://doi.org/10.3390/app11093839
Urdaneta-Ponte MC, Méndez-Zorrilla A, Oleagordia-Ruiz I. Lifelong Learning Courses Recommendation System to Improve Professional Skills Using Ontology and Machine Learning. Applied Sciences. 2021; 11(9):3839. https://doi.org/10.3390/app11093839
Chicago/Turabian StyleUrdaneta-Ponte, María Cora, Amaia Méndez-Zorrilla, and Ibon Oleagordia-Ruiz. 2021. "Lifelong Learning Courses Recommendation System to Improve Professional Skills Using Ontology and Machine Learning" Applied Sciences 11, no. 9: 3839. https://doi.org/10.3390/app11093839
APA StyleUrdaneta-Ponte, M. C., Méndez-Zorrilla, A., & Oleagordia-Ruiz, I. (2021). Lifelong Learning Courses Recommendation System to Improve Professional Skills Using Ontology and Machine Learning. Applied Sciences, 11(9), 3839. https://doi.org/10.3390/app11093839