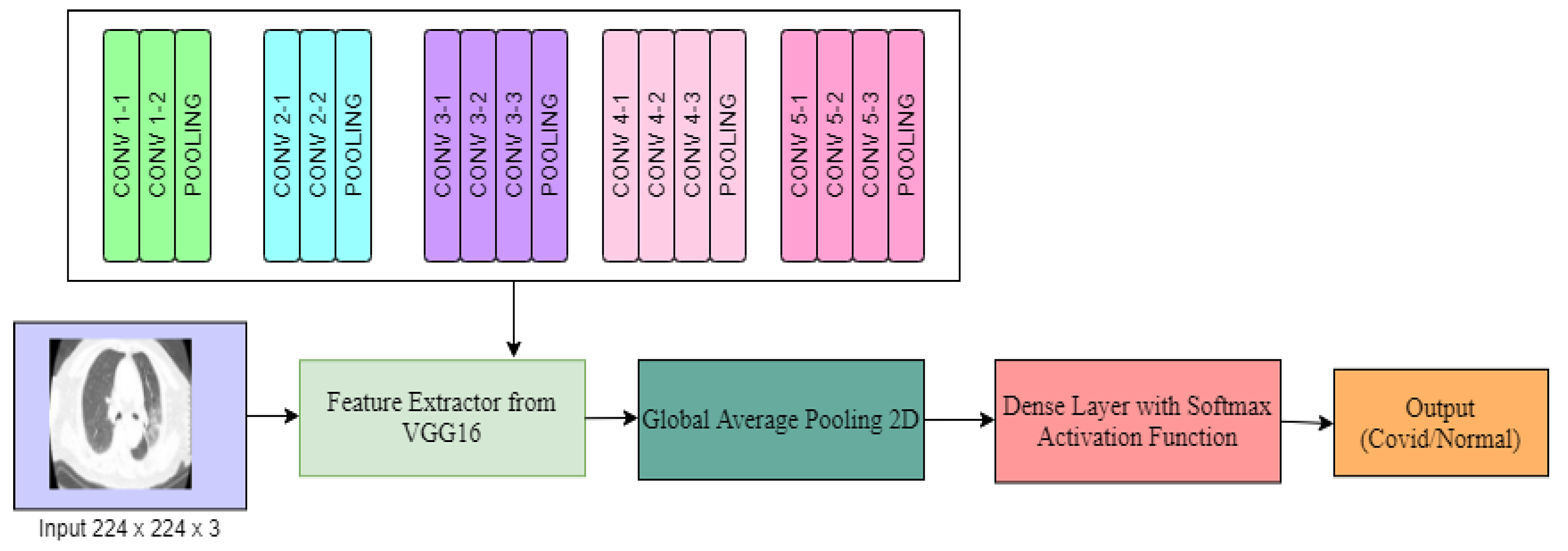
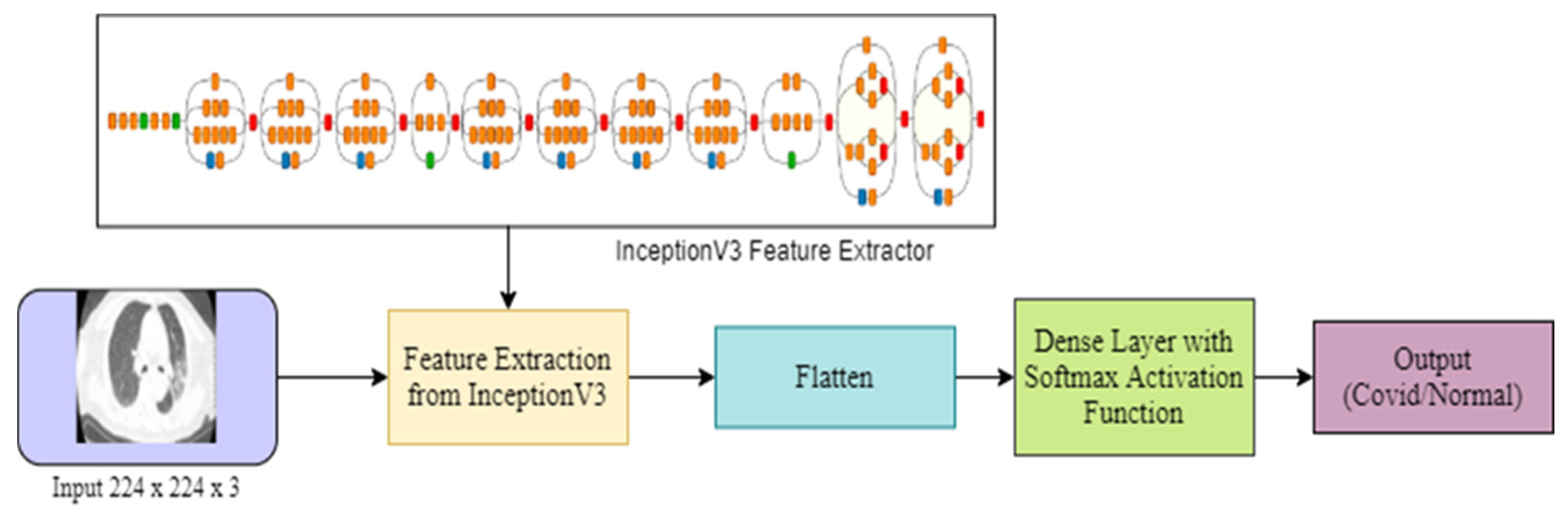
The Tensorflow deep learning library and python programming language were used to implement the code of DL models and FGSM attack. We experimented with four different approaches. To start with, we analyzed the performance of the VGG16 algorithm for COVID-19 classification from X-rays by using transfer learning followed by in-depth analysis of the drop of performance of this model as it suffers from FGSM attack. Later, we analyzed the performance degradation of VGG16 and the Inception-V3 algorithm for COVID-19 classification from X-ray and CT images.
3.1. Transfer Learning to Diagnose COVID-19 from Chest X-ray
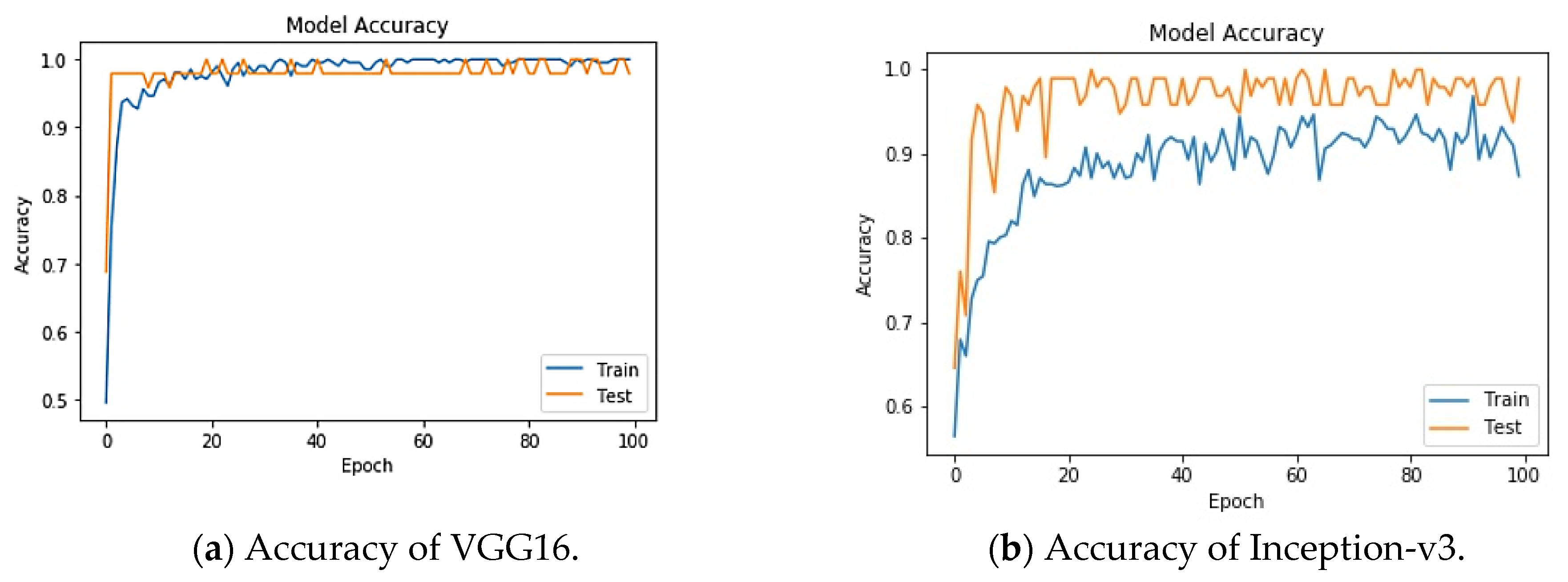
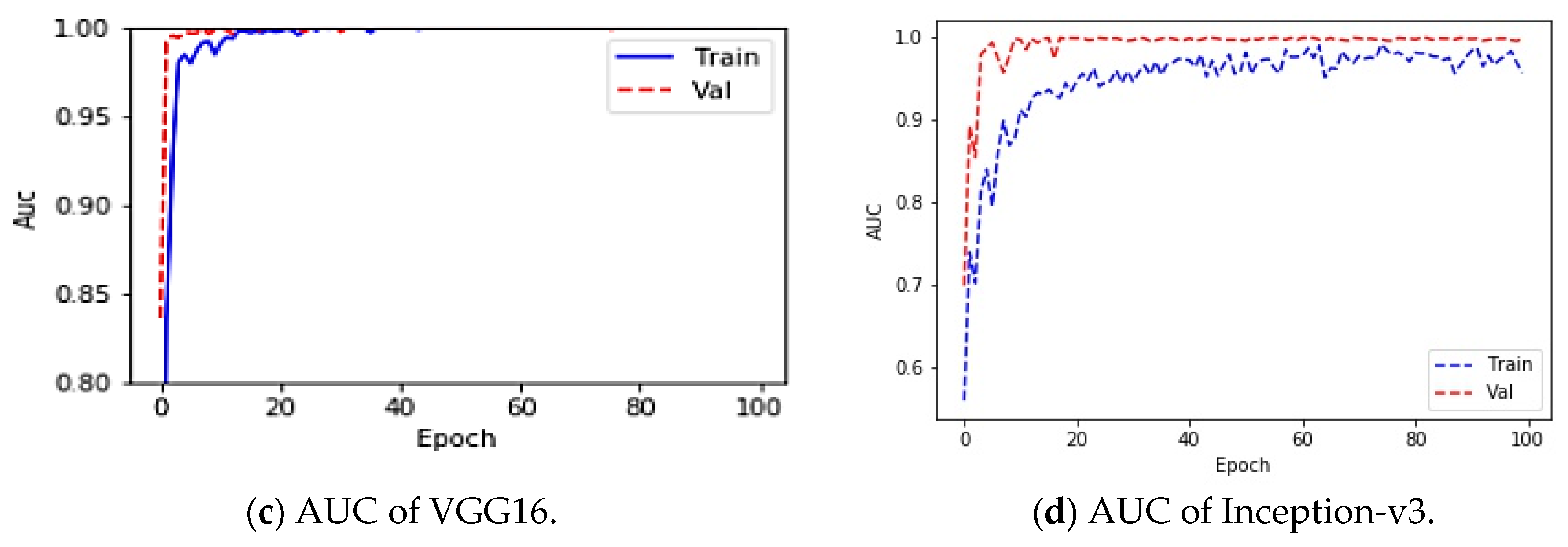
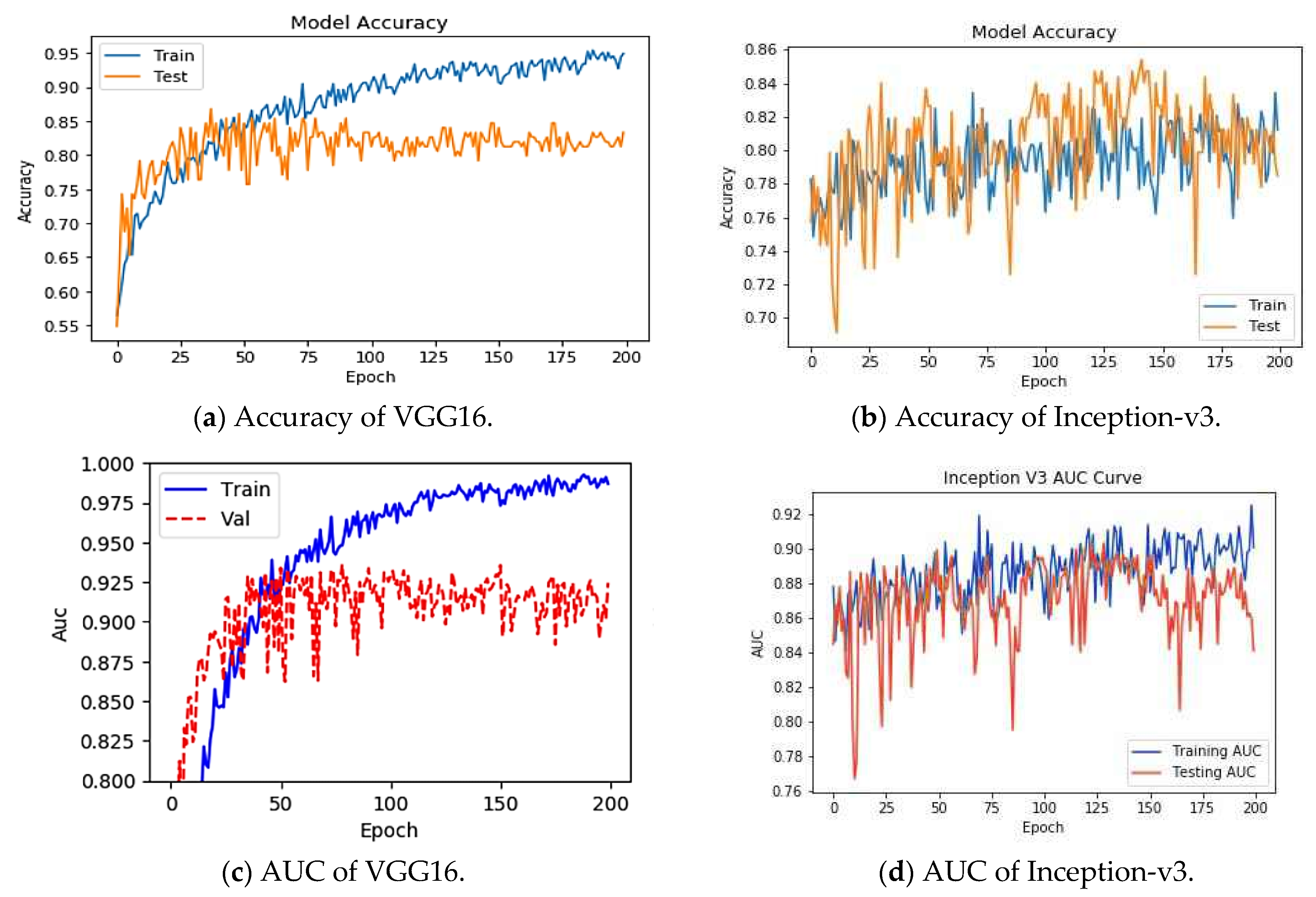
To understand the performance drop and vulnerability of VGG16 and Inception-v3 pre-trained DL models for COVID-19 detection, we first analyzed the performances of these models in an attack-free environment. We resized the images to 224 × 224 × 3 and fed them into the DL architecture. An 80:20 split was used to divide the images into training and test sets for chest X-ray images. The total number of training images was small enough; therefore, the training performance saturated quickly, as shown in
Figure 4 through the training and test accuracy.
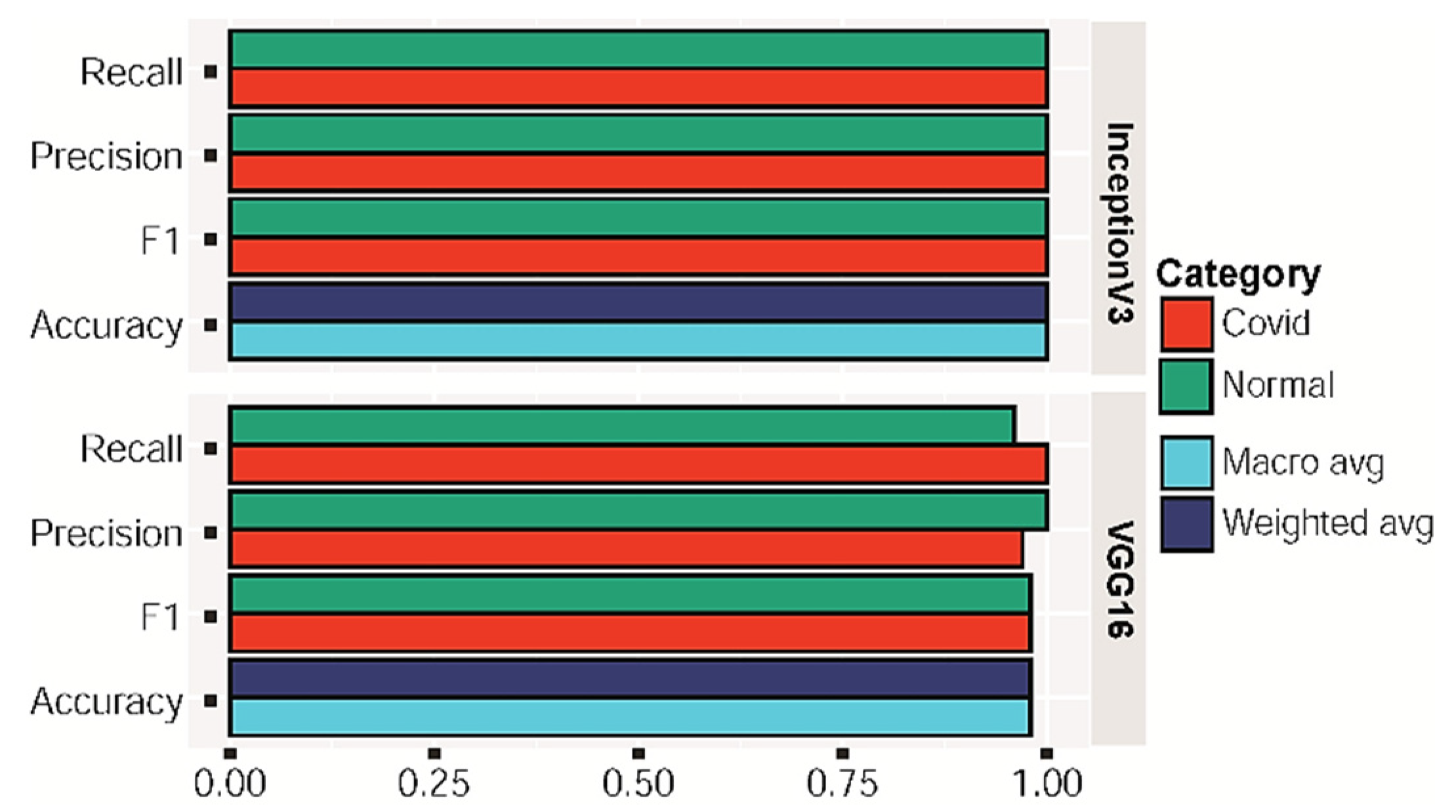
Table 2 and
Table 3 enlist the performance details of the VGG16 and Inception-v3 algorithm, respectively, using a confusion matrix.
Figure 4 and
Figure 5 show the corresponding accuracy, precision, recall, F1 score and AUC. The VGG16 model classifies COVID-19 models with high precision, recall, and F1 of 0.97, 1 and 0.98, respectively. Inception-v3 also came out with a similar accuracy. In the AUC curve, validation data were the same as the test data because we had very little data to train and test. From
Figure 4, it can be seen that the AUC for the performance is either equal to 1 or close to 1 during the best performance for VGG16 and Inception-v3. Thus, the model is found to be reliable in absence of FGSM attack to detect COVID-19-infected people.
3.2. FGSM Attack Analysis for Chest X-ray
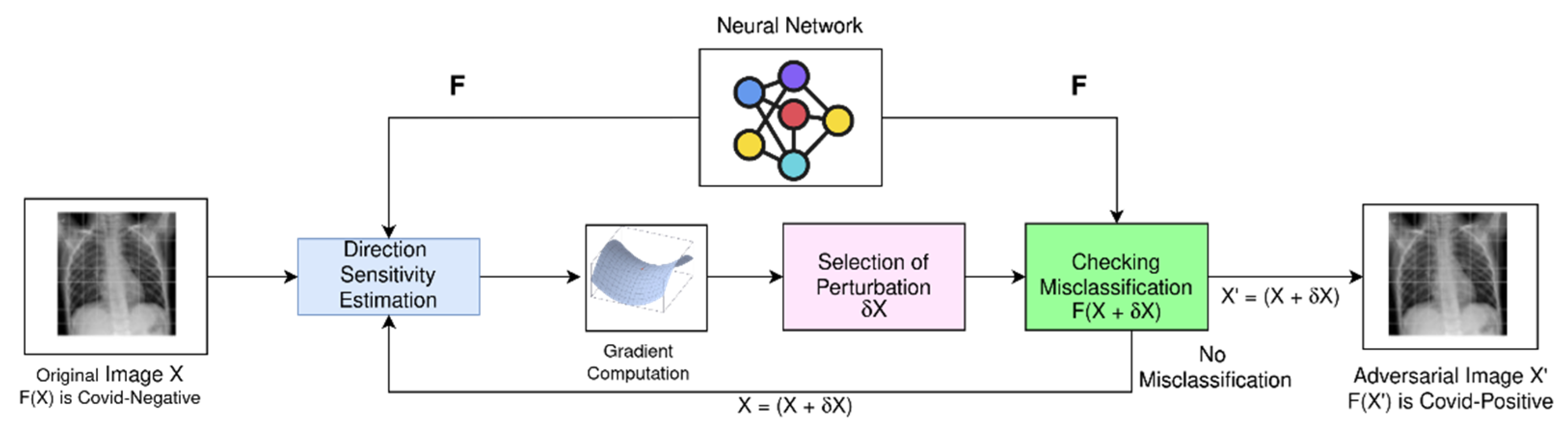
After developing the transfer learning-based models to classify COVID-19 samples, we applied the FGSM attack on the developed models. For the FGSM attack, we focused on the perturbation degree and corresponding perceptibility effect on chest X-ray images, to see whether subtle perturbation could create an adversarial image that can fool a human radiologist as well as a computer.
To illustrate the potential risk and performance drop due to the FGSM attack on promising transfer learning models for COVID-19 detection, we experimented by varying the amount of perturbation (
ε) in the training images. In
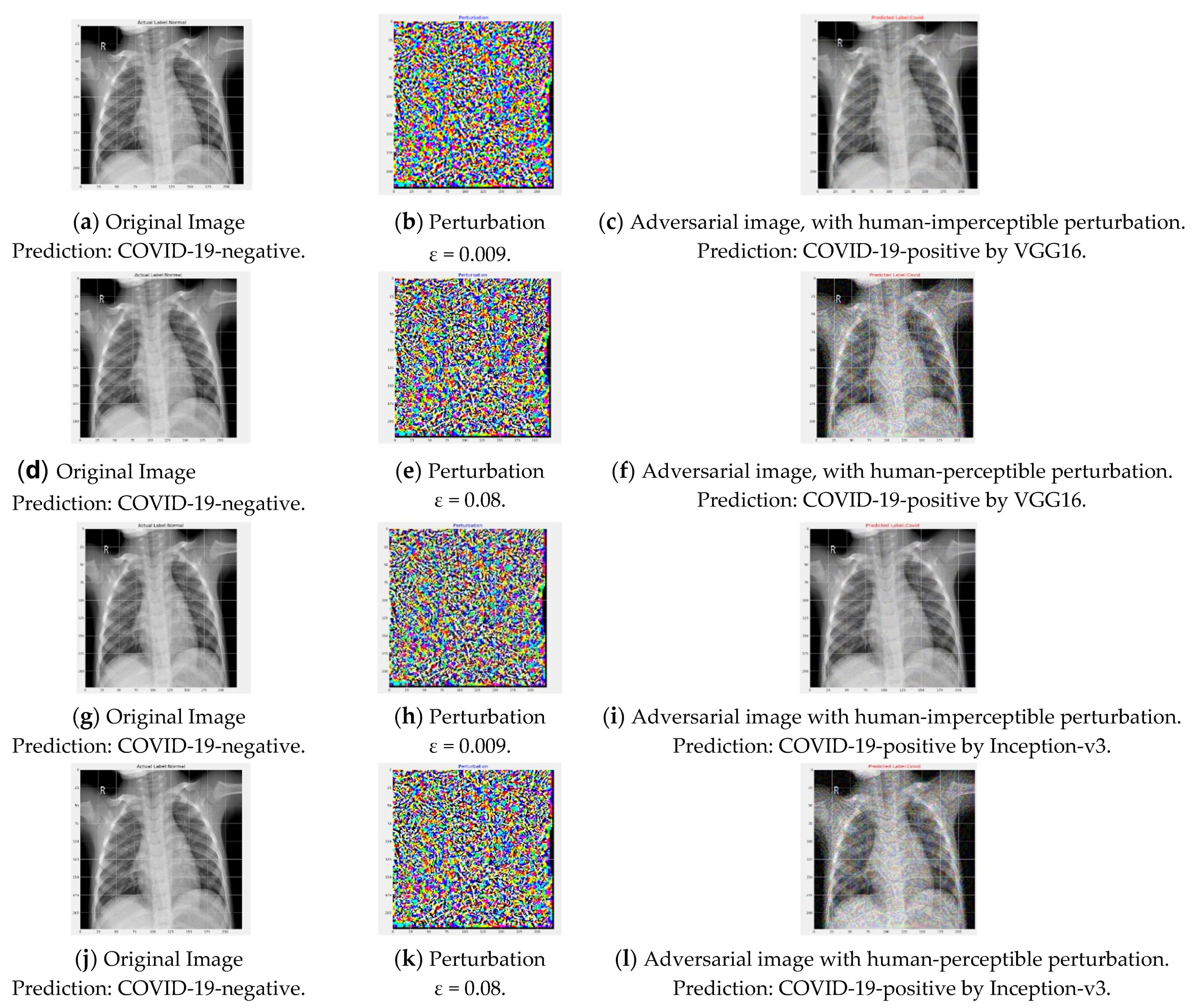
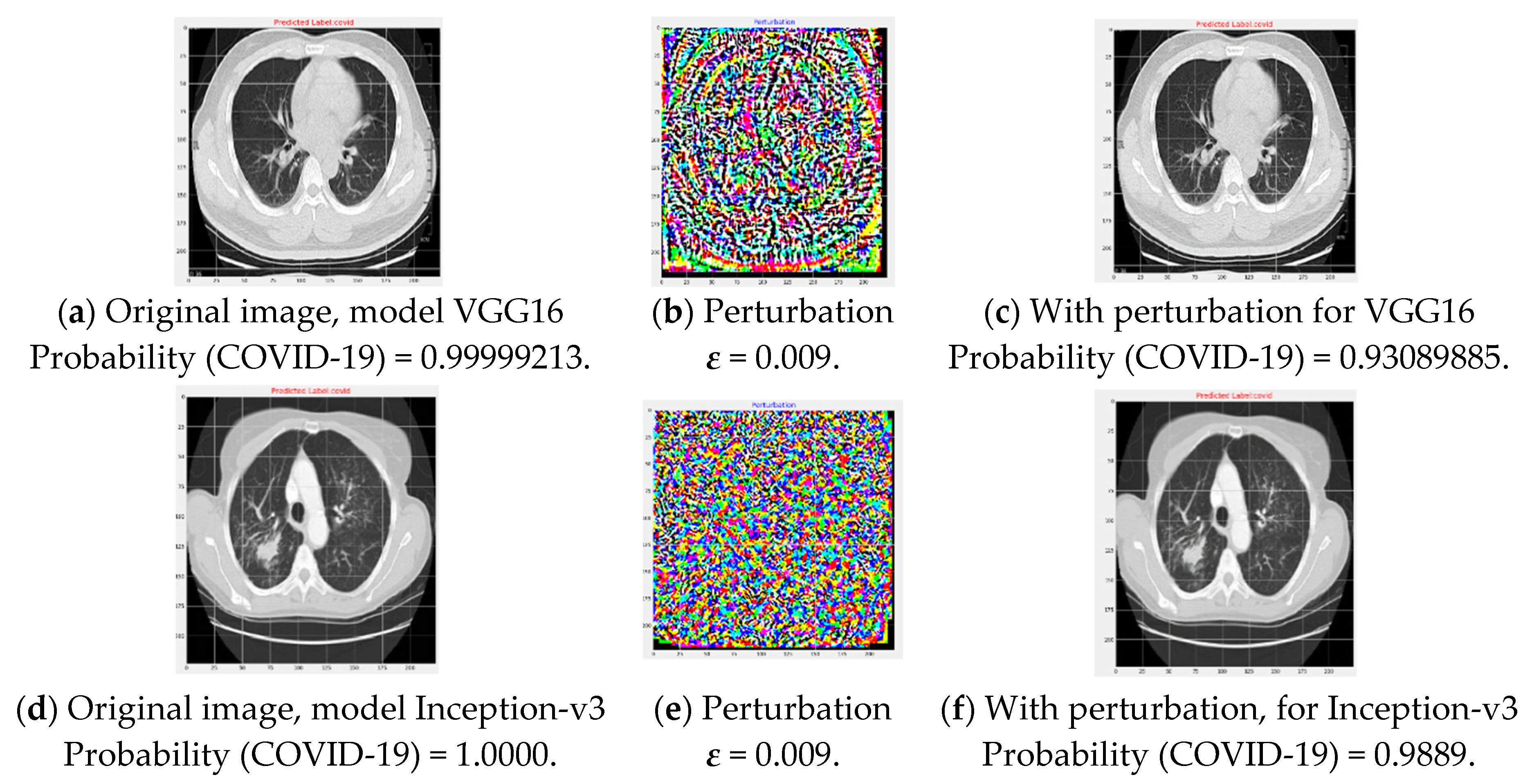
Figure 6, the left column figures are original images, and the right-most column figures are corresponding adversarial images generated by FGSM attack.
Figure 6c,i clearly depict that misclassification can occur with a very small perturbation and for both considered models.
ε of 0.009 successfully generated an adversarial image due to the FGSM attack, which is not recognizable by the human eye. For ease of discussion, we can define such perturbation as safe perturbation magnitude for the attacker. On the other hand, perturbation of 0.08 generated adversarial images that could be distinguished from the original images by the human eye, as seen in
Figure 6f,l.
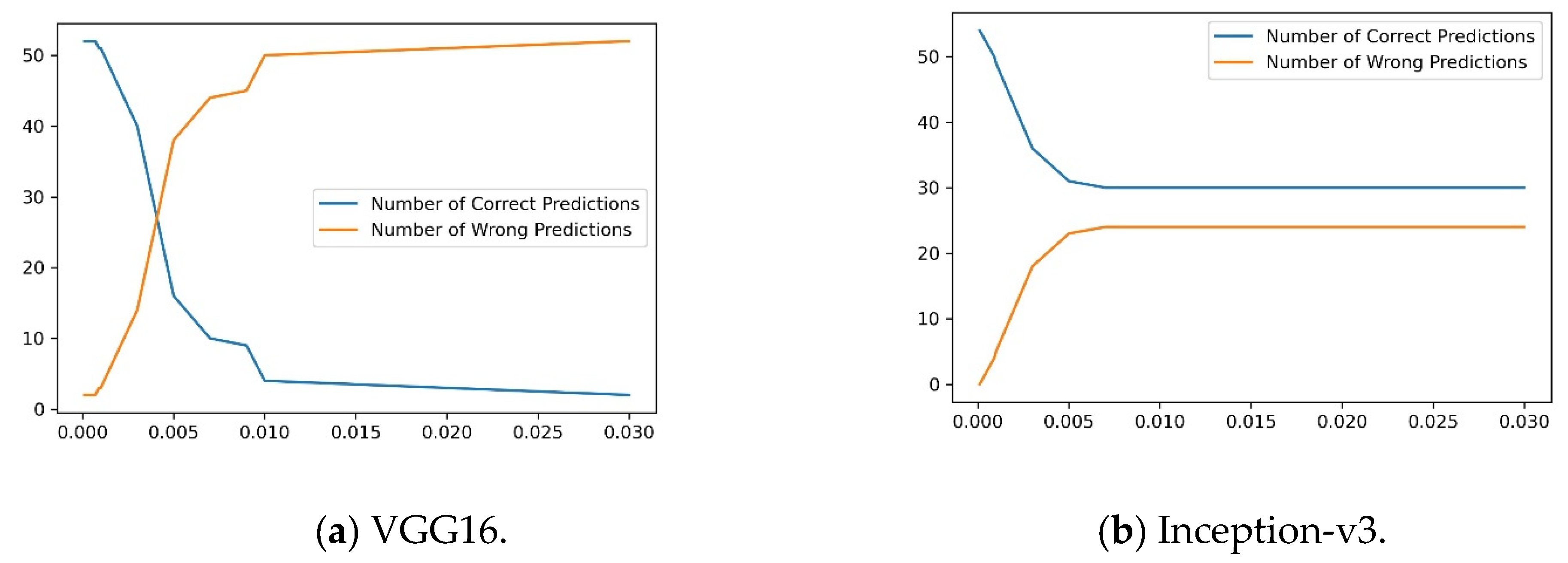
Table 4 and
Figure 7 clarify, in detail, that as the
ε increases, the number of incorrect predictions increases for the considered representative transfer learning models. It is illustrated that very small perturbation of the FGSM attack is sufficient to cause a catastrophic drop in diagnostic performance, while the adversarial images are safe to see in the human eye.
Table 4 and
Figure 7 elucidate that for a safe perturbation magnitude such as 0.009, the performance drops significantly to almost 16% for VGG16 and 55% for Inception-v3, making these models unusable for COVID-19 detection purpose as long as no protective screening or robust training is ensured.
Figure 6f,l also shows that with increasing
ε, the noise in adversarial images becomes recognizable by the human eye and the misclassification continues to occur for the mentioned model for these images. Experiments suggest that at higher noise magnitudes, the performance fall was caused by the image corruption from noise, although to a very small extent. Both human experts as well as a computer can be fooled through detecting the noise. Thus, the FGSM attack shows the vulnerability of state-of-the-art pre-trained DL COVID-19 detection models that were successfully classifying COVID-19 samples. Some medical images have significantly high attention regions. Rich biological textures in medical images often distract deep learning models to pay proper attention into the areas that are not important for the diagnosis. Subtle perturbations in these regions results in significant changes in model prediction.
Finally, we investigated the drop of class probability score for images belonging to the correctly predicted class. The deep transfer learning approaches learn transferable features with minimum perturbation; therefore, the model can classify some images successfully. Despite correct classification, for FGSM attack, the probability decreased for an image belonging to the correct class. We investigated and illustrated that the performance also drops in terms of probability score for successfully classified images.
For an original image
x, the correct classification probability was noted. For the same image, the classification score of corresponding adversarial image
x′ was investigated if both
x and
x′ were correctly classified.
Figure 8 shows that, for the same image, the FGSM attack resulted in a degradation of the probability score for the image to belong to a particular class. As shown in
Figure 8 for a
ε of 0.009, the probability for a COVID-19-positive image belonging to COVID-19-positive decreases to 0.91 from that of 1.00 for the VGG16 network. Additionally, for the Inception-v3 model, the probability also decreases, to 0.93 from that of 1.00. It is obvious that if the
ε is further increased, the probability will decrease and result in misclassification. Moreover, the decreased probability value is also dangerous because medical imaging requires high-precision performance.
Figure 6c,i shows that
ε of 0.009 can generate adversarial images where perturbations are not recognizable in the human eye;
Table 5 depicts that
ε of 0.008 can cause an average correct class probability drop of 0.24 for the VGG16 model. Thus, the confidence of the classifier to predict the correct class of a sample is reduced, causing the model to be less reliable. The Inception-v3 model was found to be robust to FGSM attack for this task.
3.4. FGSM Attack Analysis for Chest CT Images
CT scans are more significant compared to X-rays because of high-quality, detailed image generation capability. This sophisticated X-ray can take a 360-degree image of the internal organs by rotating an X-ray tube around the patient and make internal anatomy clearer by eliminating overlapping structures. However, efficient adversarial images can also be crafted for these images.
To illustrate the similar vulnerability of promising TL models for CT image-based COVID-19 detection, we investigated the effect of perturbation (
ε) variation in FGSM attack.
Figure 11c,i clearly show that misclassification can occur with a very minor perturbation and for both considered models.
ε of 0.003 or 0.0007 successfully generated adversarial images due to the FGSM attack, where noise was imperceptible to human eye but caused misclassification. On the other hand, perturbation of around 0.07 or 0.09 generated misclassified adversarial images which could be detected by the human eye, as seen in
Figure 11f,l.
Table 8 and
Figure 12 elucidate that for an imperceptible perturbation (
ε) such as 0.003, the classification performance drops significantly to 36% for VGG16, and for
ε of 0.0007, performance drops to 40% for Inception-v3, making these models unusable for COVID-19 detection purposes.
Finally, we investigated the drop in class probability score for correctly classified CT images based COVID-19 detection.
Figure 13 shows that for same image, FGSM attack resulted in a decrease in probability score for the image to belong to any class. As shown in
Figure 13, for a
ε of 0.009, the probability of a COVID-19-positive image belonging to COVID-19-positive decreases to 0.93 from that of 0.99 when VGG16 is used. The probability also decreases to 0.98 from that of 1.00 for the Inception-v3 network in the presence of adversarial images that are not recognizable by the human eye. Therefore, it proves the models to be vulnerable to physical deployment in medical systems.
Table 9 depicts that
ε of 0.008 can cause an average probability drop of 0.17 for the VGG16 model, reducing the confidence of the classifier to predict the correct class of a sample which also makes the model vulnerable. The Inception-v3 model was found to be comparatively robust for the correctly classified samples.


 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}