
You Don’t Need Labeled Data for Open-Book Question Answering


Abstract
:1. Introduction
- Introducing a new dataset in open-book QA.
- Proposing a two-module architecture to find answers without context.
- Experimenting on ready-to-use information-retrieval systems.
- Inferring text and yes–no–none answers in a single forward pass once we find the right document.
2. Related Work
2.1. QA Approaches
2.2. Our Inspirations
3. Data
3.1. AWS Documentation Dataset
3.1.1. Questions and Answers
3.1.2. Annotation Process
- Question validation: Annotators determine whether a question is valid or invalid. A valid question is a fact-seeking question that has a clear and unambiguous answer. An invalid question is incomprehensible, vague, opinion-seeking, or not plainly a query for factual information. Annotators must determine this by the question’s content only.
- Document selection: Annotators select the right source document from the AWS Documentation corpus that contains the answer. Every valid question in the dataset must have an accompanying source document.
- Text answer: If a question is valid and has a valid source document, annotators select the correct answer from the source document. Every question must have a clear and unambiguous text answer. For example, for the question “What is the maximum number of rows in a dataset in Amazon Forecast?”, there is one and only one answer which is “1 billion”.
- YNN answer: In the final step, annotators flag the answer’s YNN answer as “Yes”, “No”, or “None”, depending on the question and the source document. Every question must have a clear and unambiguous YNN answer. For example, for the question “Can I run codePipeline in a VPC?”, there is one and only one answer, which is “Yes”.
3.2. SQuAD Datasets
3.3. Natural Questions Dataset
4. Approach
4.1. Retrievers
4.1.1. Whoosh
4.1.2. Amazon Kendra
- Document ranking (DR)—Similar to any traditional search engine, Kendra returns a ranked list of relevant documents based on the input query to fulfill their information needs. A deep semantic search model is used to understand natural language questions in addition to the keyword search.
- Passage ranking (PR)—Kendra ranks the passages and tries to find the top relevant passages with a deep reading comprehension model.
- FAQ matching (FAQM)—If there exists frequently answered questions and their corresponding answers, Kendra will automatically match a newcoming query with FAQs and extract the answer if a strong match is found.
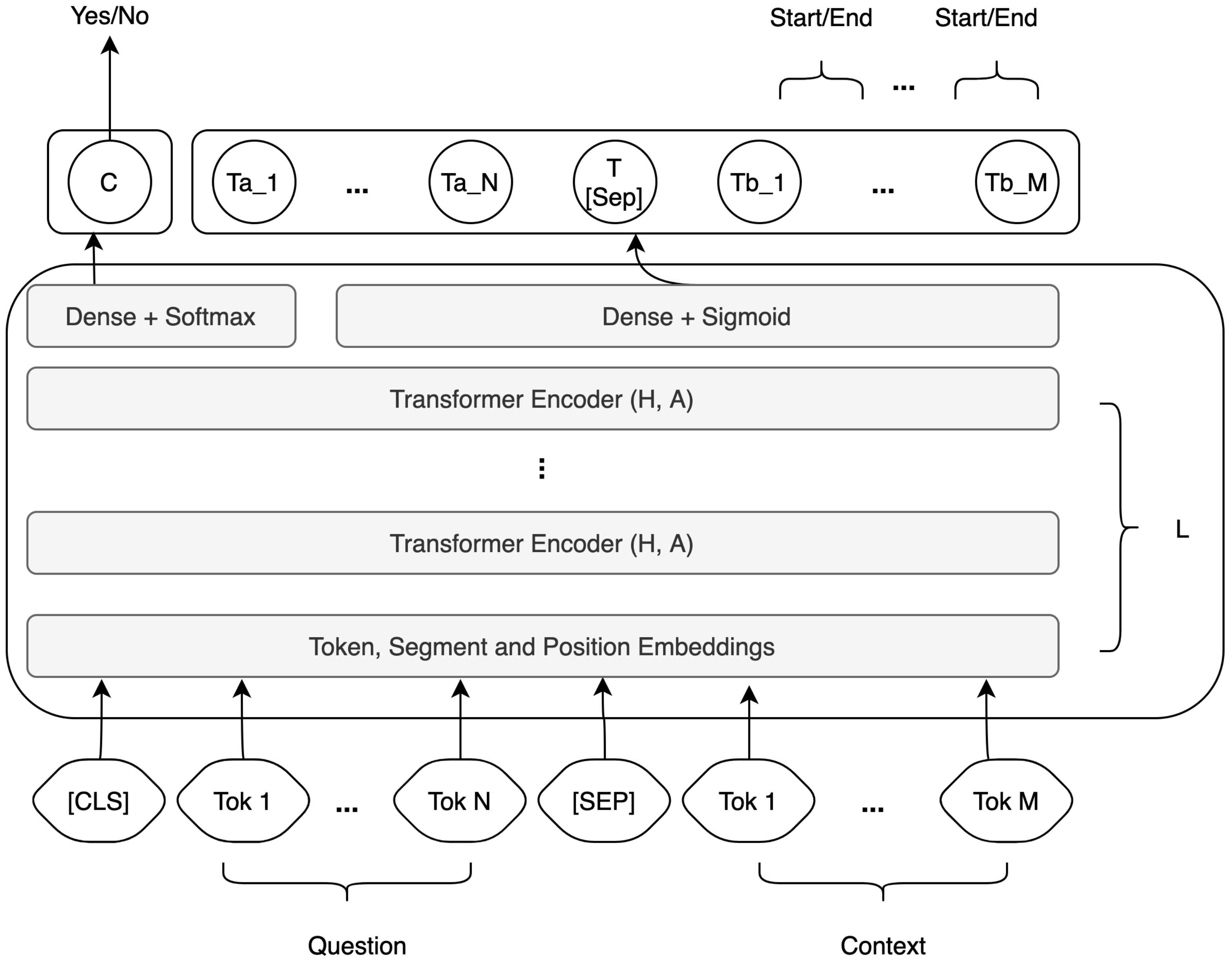
4.2. Extractors
4.2.1. Extractor Model Data Processing
4.2.2. Extractor Model
5. Experiments
5.1. Retriever Experiments
5.2. Extractor Experiments
5.3. Error Analysis
5.3.1. Exact Matches
5.3.2. Retriever Errors
5.3.3. Partial Answers
5.3.4. Table Extraction Errors
5.3.5. Wrong Predictions
6. Limitations and Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Voorhees, E.M. The TREC-8 question answering track report. Trec. Citeseer 1999, 99, 77–82. [Google Scholar]
- Moldovan, D.; Harabagiu, S.; Pasca, M.; Mihalcea, R.; Girju, R.; Goodrum, R.; Rus, V. The structure and performance of an open-domain question answering system. In Proceedings of the 38th annual meeting of the Association for Computational Linguistics, Hong Kong, China, 10–12 October 2000; pp. 563–570. [Google Scholar]
- Brill, E.; Dumais, S.; Banko, M. An analysis of the AskMSR question-answering system. In Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP 2002), Philadelphia, PA, USA, 6–7 July 2002; pp. 257–264. [Google Scholar]
- Ferrucci, D.; Brown, E.; Chu-Carroll, J.; Fan, J.; Gondek, D.; Kalyanpur, A.A.; Lally, A.; Murdock, J.W.; Nyberg, E.; Prager, J.; et al. Building Watson: An overview of the DeepQA project. AI Mag. 2010, 31, 59–79. [Google Scholar] [CrossRef] [Green Version]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 2383–2392. [Google Scholar]
- Kwiatkowski, T.; Palomaki, J.; Redfield, O.; Collins, M.; Parikh, A.; Alberti, C.; Epstein, D.; Polosukhin, I.; Devlin, J.; Lee, K.; et al. Natural questions: A benchmark for question answering research. Trans. Assoc. Comput. Linguist. 2019, 7, 453–466. [Google Scholar] [CrossRef]
- Joshi, M.; Choi, E.; Weld, D.S.; Zettlemoyer, L. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 12–15 July 2017; Volume 1: Long Papers, pp. 1601–1611. [Google Scholar]
- Khashabi, D.; Chaturvedi, S.; Roth, M.; Upadhyay, S.; Roth, D. Looking beyond the surface: A challenge set for reading comprehension over multiple sentences. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), Melbourne, Australia, 15–20 July 2018; Volume 1 (Long Papers), pp. 252–262. [Google Scholar]
- Richardson, M.; Burges, C.J.; Renshaw, E. Mctest: A challenge dataset for the open-domain machine comprehension of text. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 193–203. [Google Scholar]
- Lai, G.; Xie, Q.; Liu, H.; Yang, Y.; Hovy, E. RACE: Large-scale ReAding Comprehension Dataset From Examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 785–794. [Google Scholar]
- Reddy, S.; Chen, D.; Manning, C.D. Coqa: A conversational question answering challenge. Trans. Assoc. Comput. Linguist. 2019, 7, 249–266. [Google Scholar] [CrossRef]
- Choi, E.; He, H.; Iyyer, M.; Yatskar, M.; Yih, W.T.; Choi, Y.; Liang, P.; Zettlemoyer, L. QuAC: Question Answering in Context. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 30 October–2 November 2018; pp. 2174–2184. [Google Scholar]
- Tafjord, O.; Clark, P.; Gardner, M.; Yih, W.T.; Sabharwal, A. Quarel: A dataset and models for answering questions about qualitative relationships. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7063–7071. [Google Scholar]
- Mitra, A.; Clark, P.; Tafjord, O.; Baral, C. Declarative question answering over knowledge bases containing natural language text with answer set programming. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3003–3010. [Google Scholar]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional attention flow for machine comprehension. arXiv 2016, arXiv:1611.01603. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; NIPS: Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar]
- Zhang, S.; Zhang, X.; Wang, H.; Cheng, J.; Li, P.; Ding, Z. Chinese Medical Question Answer Matching Using End-to-End Character-Level Multi-Scale CNNs. Appl. Sci. 2017, 7, 767. [Google Scholar] [CrossRef]
- Boban, I.; Doko, A.; Gotovac, S. Improving Sentence Retrieval Using Sequence Similarity. Appl. Sci. 2020, 10, 4316. [Google Scholar] [CrossRef]
- Pota, M.; Esposito, M.; De Pietro, G.; Fujita, H. Best Practices of Convolutional Neural Networks for Question Classification. Appl. Sci. 2020, 10, 4710. [Google Scholar] [CrossRef]
- Sarhan, I.; Spruit, M. Can We Survive without Labelled Data in NLP? Transfer Learning for Open Information Extraction. Appl. Sci. 2020, 10, 5758. [Google Scholar] [CrossRef]
- Mutabazi, E.; Ni, J.; Tang, G.; Cao, W. A Review on Medical Textual Question Answering Systems Based on Deep Learning Approaches. Appl. Sci. 2021, 11, 5456. [Google Scholar] [CrossRef]
- Jin, D.; Pan, E.; Oufattole, N.; Weng, W.H.; Fang, H.; Szolovits, P. What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams. Appl. Sci. 2021, 11, 6421. [Google Scholar] [CrossRef]
- Phakmongkol, P.; Vateekul, P. Enhance Text-to-Text Transfer Transformer with Generated Questions for Thai Question Answering. Appl. Sci. 2021, 11, 267. [Google Scholar] [CrossRef]
- Ali, W.; Zuo, W.; Ali, R.; Zuo, X.; Rahman, G. Causality Mining in Natural Languages Using Machine and Deep Learning Techniques: A Survey. Appl. Sci. 2021, 11, 64. [Google Scholar] [CrossRef]
- Banerjee, P.; Pal, K.K.; Mitra, A.; Baral, C. Careful Selection of Knowledge to Solve Open Book Question Answering. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 6120–6129. [Google Scholar]
- Yasunaga, M.; Ren, H.; Bosselut, A.; Liang, P.; Leskovec, J. QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 535–546. [Google Scholar]
- Hobbs, J.R. Abduction in natural language understanding. In Handbook of Pragmatics; Wiley: Hoboken, NJ, USA, 2004; pp. 724–741. [Google Scholar]
- Pérez-Agüera, J.R.; Arroyo, J.; Greenberg, J.; Iglesias, J.P.; Fresno, V. Using BM25F for semantic search. In Proceedings of the 3rd International Semantic Search Workshop, Raleigh, NC, USA, 26–30 April 2010; pp. 1–8. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Karpukhin, V.; Oguz, B.; Min, S.; Lewis, P.; Wu, L.; Edunov, S.; Chen, D.; Yih, W.T. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual Conference, 16–20 November 2020; pp. 6769–6781. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]



{kind=link}
{kind=link}
| Question | Text Answer | YNN Answer |
|---|---|---|
| What is the maximum number of rows in a dataset in Amazon Forecast? | 1 billion | None |
| Can I stop a DB instance that has a read replica? | You can’t stop a DB instance that has a read replica. | No |
| What is the size of a null attribute in DynamoDB? | length of attribute name + 1 byte | None |
| In Amazon RDS, what is the storage for all DB instances? | 100 TB | None |
| Can I run codePipeline in a VPC? | AWS CodePipeline now supports Amazon Virtual Private Cloud (Amazon VPC) endpoints powered by AWS PrivateLink | Yes |
| Is AWS IoT Greengrass HIPAA compliant? | Third-party auditors assess the security and compliance of AWS IoT Greengrass as part of multiple AWS compliance programs. These include SOC PCI FedRAMP HIPAA and others. | Yes |
| Question: | What Are the Amazon RDS Storage Types? |
|---|---|
| Retriever set of documents: | CHAP_Storage.txt, CHAP_Limits.txt, CHAP_BestPractices.txt |
| Extractor Text Answer: | General Purpose, SSD, Provisioned IOPS, Magnetic |
| Extractor Yes/No Answer: | None |
| Retriever | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Whoosh | 0.05 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 |
| Kendra | 0.66 | 0.79 | 0.86 | 0.87 | 0.9 | 0.91 | 0.92 | 0.93 | 0.94 | 0.95 |
| Extractor Base Model | L | H | F1 | EM |
|---|---|---|---|---|
| BERT Tiny | 2 | 128 | 0.128 | 0.09 |
| RoBERTa Base | 12 | 768 | 0.154 | 0.09 |
| DistilBERT | 12 | 768 | 0.158 | 0.08 |
| AlBERT Base | 12 | 768 | 0.199 | 0.11 |
| BERT Base | 12 | 768 | 0.245 | 0.16 |
| BERT Large | 24 | 1024 | 0.247 | 0.16 |
| AlBERT XXL | 12 | 4096 | 0.422 | 0.39 |
| Category | Percentage |
|---|---|
| Retriever error | 10% |
| Partial answer | 7% |
| Table extraction | 24% |
| Wrong prediction | 20% |
| Exact match | 39% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gholami, S.; Noori, M. You Don’t Need Labeled Data for Open-Book Question Answering. Appl. Sci. 2022, 12, 111. https://doi.org/10.3390/app12010111
Gholami S, Noori M. You Don’t Need Labeled Data for Open-Book Question Answering. Applied Sciences. 2022; 12(1):111. https://doi.org/10.3390/app12010111
Chicago/Turabian StyleGholami, Sia, and Mehdi Noori. 2022. "You Don’t Need Labeled Data for Open-Book Question Answering" Applied Sciences 12, no. 1: 111. https://doi.org/10.3390/app12010111
APA StyleGholami, S., & Noori, M. (2022). You Don’t Need Labeled Data for Open-Book Question Answering. Applied Sciences, 12(1), 111. https://doi.org/10.3390/app12010111