
POCS-Augmented CycleGAN for MR Image Reconstruction



Abstract
:1. Introduction
2. Materials and Methods
2.1. Problem Definition and Notations
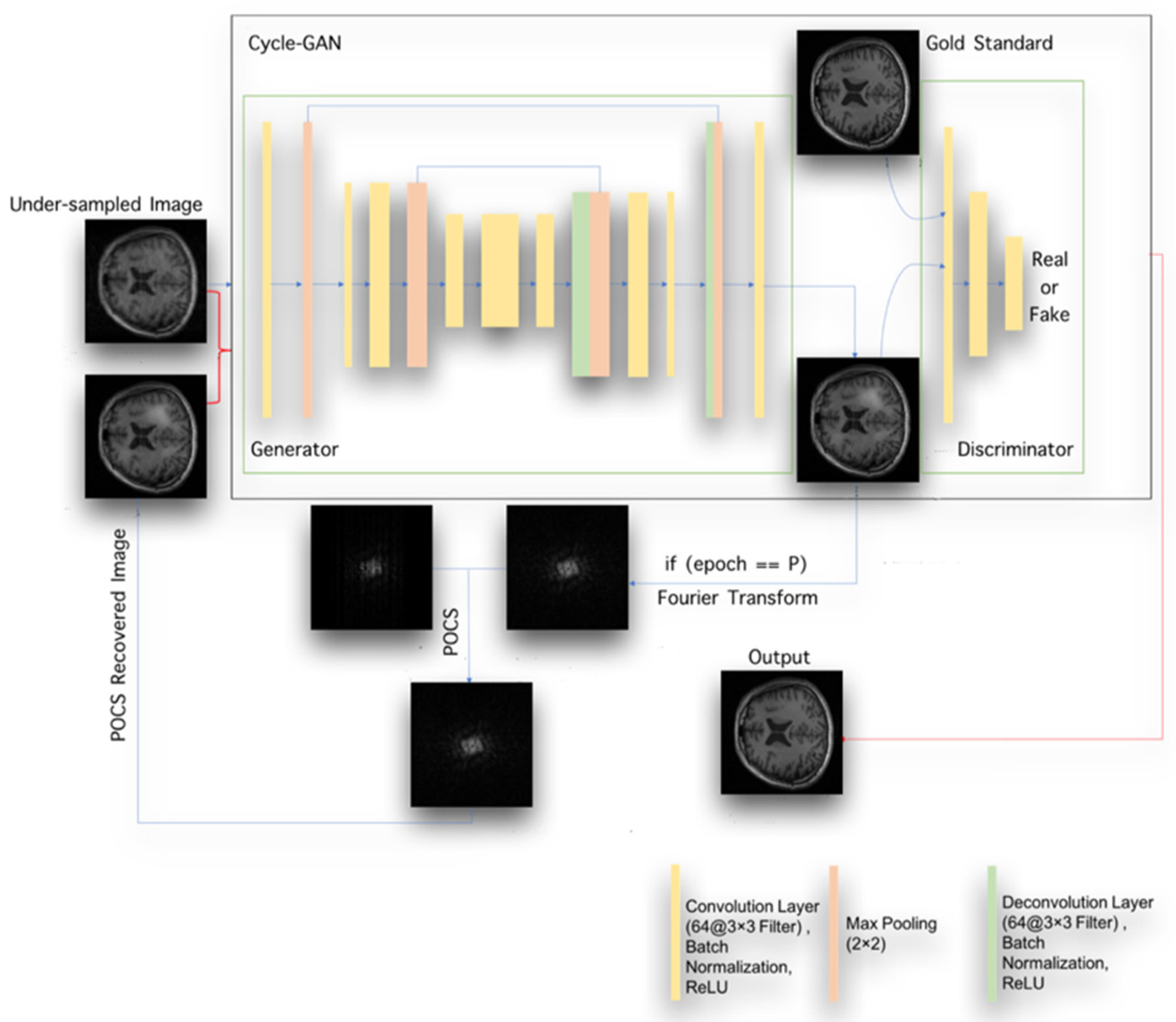
2.2. The Structure of the Entire POCS-Augmented CycleGAN (POCS-CycleGAN)
| Algorithm 1 POCS-CycleGAN training. | |
| Input: | |
| : | image from under-sampled k-space dataset |
| : | image from fully-sampled k-space dataset |
| : | under-sampled image generated from model |
| : | fully-sampled image generated from model |
| P: | total epoch number |
| M: | epoch number to perform POCS |
| : | k-space image |
| mask: | undersample mask |
| : | Fourier transformation |
| q: | POCS sample selection number |
| Output: | |
| for epoch = 0 to P do | |
| tem=0 /* a temporary variable to store the data processed by POCS */ | |
| ← | |
| ← | |
| if epoch % M == 0 then | |
| , | |
| end | |
| ← | |
| , | |
| end | |
2.3. Architectures of the Generator and Discriminator
2.4. Loss Function
2.4.1. Discriminator’s Loss
2.4.2. Generator’s Loss
2.4.3. Adversarial Loss
2.4.4. Cycle Loss
2.5. POCS
3. Experiments
3.1. Datasets
3.2. Data Prepration
3.3. Network Training Procedures
3.4. Compared Methods
3.5. Evaluation
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Acknowledgments
Conflicts of Interest
References
- Twieg, D.B. The k-trajectory formulation of the NMR imaging process with applications in analysis and synthesis of imaging methods. Med. Phys. 1983, 10, 610–621. [Google Scholar] [CrossRef]
- Griswold, M.A.; Jakob, P.M.; Heidemann, R.M.; Nittka, M.; Jellus, V.; Wang, J.; Kiefer, B.; Haase, A. Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magn. Reson. Med. An Off. J. Int. Soc. Magn. Reson. Med. 2002, 47, 1202–1210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pruessmann, K.P.; Weiger, M.; Scheidegger, M.B.; Boesiger, P. SENSE: Sensitivity encoding for fast MRI. Magn. Reson. Med. An Off. J. Int. Soc. Magn. Reson. Med. 1999, 42, 952–962. [Google Scholar] [CrossRef]
- Sodickson, D.K.; Manning, W.J. Simultaneous acquisition of spatial harmonics (SMASH): Fast imaging with radiofrequency coil arrays. Magn. Reson. Med. 1997, 38, 591–603. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Wang, J.; Detre, J.A. Improved data reconstruction method for GRAPPA. Magn. Reson. Med. An Off. J. Int. Soc. Magn. Reson. Med. 2005, 54, 738–742. [Google Scholar] [CrossRef]
- Wang, Z.; Fernández-Seara, M.A. 2D partially parallel imaging with k-space surrounding neighbors-based data reconstruction. Magn. Reson. Med. An Off. J. Int. Soc. Magn. Reson. Med. 2006, 56, 1389–1396. [Google Scholar] [CrossRef]
- Lustig, M.; Donoho, D.L.; Santos, J.M.; Pauly, J.M. Compressed sensing MRI. IEEE Signal Process. Mag. 2008, 25, 72–82. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Xie, D.; Bai, L.; Wang, Z. Denoising Arterial Spin Labeling Cerebral Blood Flow Images Using Deep Learning. arXiv 2018, arXiv:1801.09672. [Google Scholar]
- Li, Y.; Xie, D.; Cember, A.; Nanga, R.P.R.; Yang, H.; Kumar, D.; Hariharan, H.; Bai, L.; Detre, J.A.; Reddy, R.; et al. Accelerating GluCEST imaging using deep learning for B0 correction. Magn. Reson. Med. 2020, 84, 1724–1733. [Google Scholar] [CrossRef]
- Zhang, L.; Xie, D.; Li, Y.; Camargo, A.; Song, D.; Lu, T.; Jeudy, J.; Dreizin, D.; Melhem, E.R.; Wang, Z.; et al. Improving Sensitivity of Arterial Spin Labeling Perfusion MRI in Alzheimer’s Disease Using Transfer Learning of Deep Learning-Based ASL Denoising. J. Magn. Reson. Imaging 2021. [Google Scholar] [CrossRef]
- Dreizin, D.; Zhou, Y.; Fu, S.; Wang, Y.; Li, G.; Champ, K.; Siegel, E.; Wang, Z.; Chen, T.; Yuille, A.L. A multiscale deep learning method for quantitative visualization of traumatic hemoperitoneum at CT: Assessment of feasibility and comparison with subjective categorical estimation. Radiol. Artif. Intell. 2020, 2, e190220. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Wang, S.; Su, Z.; Ying, L.; Peng, X.; Zhu, S.; Liang, F.; Feng, D.; Liang, D. Accelerating magnetic resonance imaging via deep learning. In Proceedings of the 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI), Prague, Czech Republic, 13–16 April 2016; pp. 514–517. [Google Scholar]
- Lee, D.; Yoo, J.; Ye, J.C. Deep residual learning for compressed sensing MRI. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, Australia, 18–21 April 2017; pp. 15–18. [Google Scholar]
- Yang, Y.; Sun, J.; Li, H.; Xu, Z. Deep ADMM-Net for compressive sensing MRI. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Hyun, C.M.; Kim, H.P.; Lee, S.M.; Lee, S.; Seo, J.K. Deep learning for undersampled MRI reconstruction. Phys. Med. Biol. 2018, 63, 135007. [Google Scholar] [CrossRef] [PubMed]
- Quan, T.M.; Nguyen-Duc, T.; Jeong, W.-K. Compressed sensing MRI reconstruction using a generative adversarial network with a cyclic loss. IEEE Trans. Med. Imaging 2018, 37, 1488–1497. [Google Scholar] [CrossRef] [Green Version]
- Haacke, E.M.; Lindskogj, E.D.; Lin, W. A fast, iterative, partial-Fourier technique capable of local phase recovery. J. Magn. Reson. 1991, 92, 126–145. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Yang, H.; Wang, Z. POCS-augmented CycleGAN for MR image reconstruction. In Proceedings of the ISMRM Workshop on Machine Learning Part II, Washington, DC, USA, 25–28 October 2018. [Google Scholar]
- Schlemper, J.; Caballero, J.; Hajnal, J.V.; Price, A.N.; Rueckert, D. A deep cascade of convolutional neural networks for dynamic MR image reconstruction. IEEE Trans. Med. Imaging 2017, 37, 491–503. [Google Scholar] [CrossRef] [Green Version]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the ICML, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Larsen, A.B.L.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding beyond pixels using a learned similarity metric. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1558–1566. [Google Scholar]
- Haacke, E.M.; Liang, Z.-P.; Boada, F.E. Image reconstruction using projection onto convex sets, model constraints, and linear prediction theory for the removal of phase, motion, and Gibbs artifacts in magnetic resonance and ultrasound imaging. Opt. Eng. 1990, 29, 555–567. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, L.; Luo, J.; Zhu, Y. MRI reconstruction from 2D partial k-space using POCS algorithm. In Proceedings of the 2009 3rd International Conference on Bioinformatics and Biomedical Engineering, Beijing, China, 11–13 June 2009; pp. 1–4. [Google Scholar]
- Zbontar, J.; Knoll, F.; Sriram, A.; Murrell, T.; Huang, Z.; Muckley, M.J.; Defazio, A.; Stern, R.; Johnson, P.; Bruno, M.; et al. fastMRI: An open dataset and benchmarks for accelerated MRI. arXiv 2018, arXiv:1811.08839. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Goodfellow, I.J.; Abadie, J.P.; Mirza, M.; Xu, B.; Farley, D.W.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.-Y.; Isola, P.; Saenko, K.; Efros, A.; Darrell, T. Cycada: Cycle-consistent adversarial domain adaptation. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1989–1998. [Google Scholar]
- Samsonov, A.A.; Kholmovski, E.G.; Parker, D.L.; Johnson, C.R. POCSENSE: POCS-based reconstruction for sensitivity encoded magnetic resonance imaging. Magn. Reson. Med. An Off. J. Int. Soc. Magn. Reson. Med. 2004, 52, 1397–1406. [Google Scholar] [CrossRef] [PubMed]
- McGibney, G.; Smith, M.R.; Nichols, S.T.; Crawley, A. Quantitative evaluation of several partial Fourier reconstruction algorithms used in MRI. Magn. Reson. Med. 1993, 30, 51–59. [Google Scholar] [CrossRef] [PubMed]
- Yang, G.; Yu, S.; Dong, H.; Slabaugh, G.; Dragotti, P.L.; Ye, X.; Liu, F.; Arridge, S.; Keegan, J.; Guo, Y.; et al. DAGAN: Deep de-aliasing generative adversarial networks for fast compressed sensing MRI reconstruction. IEEE Trans. Med. Imaging 2017, 37, 1310–1321. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hammernik, K.; Klatzer, T.; Kobler, E.; Recht, M.P.; Sodickson, D.K.; Pock, T.; Knoll, F. Learning a variational network for reconstruction of accelerated MRI data. Magn. Reson. Med. 2018, 79, 3055–3071. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sampling Rate | 10% | 20% |
|---|---|---|
| U-Net | 19.67 ± 1.89 | 25.11 ± 1.86 |
| GAN | 20.51 ± 1.67 | 26.05 ± 1.75 |
| CycleGAN | 21.55 ± 1.79 | 26.05 ± 1.82 |
| RefineGAN | 22.83 ± 1.54 | 26.79 ± 1.84 |
| POCS-CycleGAN | 24.58 ± 2.59 | 27.86 ± 1.92 |
| Sampling Rate | 10% | 20% |
|---|---|---|
| U-Net | 0.33 ± 0.09 | 0.39 ± 0.10 |
| GAN | 0.34 ± 0.09 | 0.46 ± 0.10 |
| CycleGAN | 0.38 ± 0.08 | 0.46 ± 0.07 |
| RefineGAN | 0.40 ± 0.08 | 0.52 ± 0.08 |
| POCS-CycleGAN | 0.42 ± 0.09 | 0.59 ± 0.10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Yang, H.; Xie, D.; Dreizin, D.; Zhou, F.; Wang, Z. POCS-Augmented CycleGAN for MR Image Reconstruction. Appl. Sci. 2022, 12, 114. https://doi.org/10.3390/app12010114
Li Y, Yang H, Xie D, Dreizin D, Zhou F, Wang Z. POCS-Augmented CycleGAN for MR Image Reconstruction. Applied Sciences. 2022; 12(1):114. https://doi.org/10.3390/app12010114
Chicago/Turabian StyleLi, Yiran, Hanlu Yang, Danfeng Xie, David Dreizin, Fuqing Zhou, and Ze Wang. 2022. "POCS-Augmented CycleGAN for MR Image Reconstruction" Applied Sciences 12, no. 1: 114. https://doi.org/10.3390/app12010114
APA StyleLi, Y., Yang, H., Xie, D., Dreizin, D., Zhou, F., & Wang, Z. (2022). POCS-Augmented CycleGAN for MR Image Reconstruction. Applied Sciences, 12(1), 114. https://doi.org/10.3390/app12010114