1. Introduction
For ship accidents that occur in the Korean ocean, the relevant personnel who are involved in the accident are judged in the first court by the regional maritime safety tribunal that is nearest to the location of the accident. The verdict on the accident is delivered through a decision process by the relevant personnel. If they are dissatisfied with the verdict, the central maritime safety tribunal, which acts as the second court, may proceed. For adjudicated accidents, the Korea Maritime Safety Tribunal (KMST) produces and publishes verdicts to ensure that the relevant personnel can share information on the judgment. The verdict contains classification information, such as the maritime safety tribunal in charge of the accident, accident name, and accident number. The information on the judgment also includes facts, reasons, and the actions of the persons involved in the accident and the main sentence. According to this, the relevant personnel can read the published verdicts to have a clear understanding of the accidents and can thus prevent the recurrence of such accidents.
However, the number of ship accidents occurring in the Korean ocean has steadily increased every year.
Table 1 shows the overall statistics of marine accidents from 2016 to 2020, published by KMST. As of 2020, there have been as many as 3156 cases; thus, it is difficult for the relevant personnel to learn various accident cases by only reading the verdicts. Therefore, there is an essential need for the assistance of an auxiliary system. This system should be able to easily access information on the accidents and the relevant personnel involved. Furthermore, the system should also predict the judgment results of additional accidents based on the collected information. Such systems are called automatic sentence prediction systems.
Automatically predicting sentences refers to analyzing the factual description of the case to determine the appropriate charge or sentence for the case [
1]. These technologies are similar to legal aid systems that allow users to search for similar cases or sentences by describing the cases either orally or verbally. In this study, only ship accidents that have occurred in the Korean ocean are used for sentence prediction. Nevertheless, it may be difficult for the general public to understand the legal data and terminology. Therefore, the general public must understand the legal basis for the cases that interest them.
However, predicting an appropriate sentence based on facts alone is not straightforward. This is mainly due to three reasons: (1) There are cases in which the contents are similar but the sentences are different. For example, to distinguish between willful murder and willful injury, it is necessary to determine whether the suspect intended to kill the victim or not based on facts alone. (2) The approach should be a multi-label classification task since multiple charges can be applied to a single case. (3) The most common approach employed is to train a classification model with a large amount of legal data and to label the case with the corresponding sentence to perform the sentence prediction task. However, it may be more beneficial for a legal aid system to provide users with the prediction and the articles supporting the predicted sentence as a legal basis. This issue is particularly important in countries that have statutory law as their legal system.
Attempts to predict charges or sentences have been conducted with a single-label classification problem using the k-nearest neighbors (k-NN) algorithm [
2,
3]; nonetheless, as mentioned before, the applied article is not identified. Moreover, many studies manually design features of specific charges and sentences to improve text understanding [
4]. However, it is not easy for them to apply these features to other charges or domains. Nonetheless, several studies predict applied articles [
3,
5]. These studies convert the problem into a multi-label classification task by considering the problem only within a fixed set of articles in the limited scope of the case or law. The lack of training data and low accuracy are still issues despite the increase in expertise in this limited field. To overcome this problem, a study was conducted to re-rank the classification results by simultaneously using word-level and article-level features [
6]. Through these studies, natural language processing could be developed as a legal search service for the relevant personnel and the general public. However, there is a disadvantage; it is a sentence prediction that uses legal expertise or a relatively simple classifier. In addition, when predicting the sentence, each task is handled independently.
Recently, a study was able to predict the applied articles by employing a novel technique: the attention mechanism [
7]. Judgments published by the Chinese court was used as training data for the neural network model. The top k articles were extracted by training the bi-directional gated recurrent unit (Bi-GRU) model [
8] through the attention between the factual information recorded in the verdict and the existing candidate articles. When the target article containing the factual information of the verdict was added to the learning model, the accuracy was 95%; however, when it was excluded, the accuracy was approximately 80%. However, through an experiment, it was shown that performance improved when additional features were provided through the attention mechanism with candidate articles than when simple factual information was provided.
An analysis of previous studies reveals that the factual information in a verdict is a shareable feature in terms of both the sentence and the article prediction. Furthermore, it can also be seen that the prediction performance can be improved through the attention mechanism. Therefore, in this study, an attention-mechanism-based multi-task learning model that shares factual information as input is presented as a solution. Multi-task learning is an approach where one neural network can perform several tasks simultaneously; it is an effective method when several problems share one feature [
9]. By performing multiple tasks with one common feature, neural networks determine the appropriate output for each task. Therefore, it has the advantage of preventing the overfitting of one specific task [
10]. The factual information of the verdict is used as an input for the shared layer and is delivered to three prediction tasks through the attention mechanism. The three prediction tasks are accident type, applied article, and sentence prediction. The attention mechanism is employed with sets of labels for each task. Through this process, each task can carefully capture the appropriate information from the shared features.
In this study, we evaluate a multi-task learning model that predicts accident types, applied articles, and sentences for ship accidents in the Korean ocean. KMST publishes a separate verdict for each ship accident that occurs on the Korean ocean. Since the verdict is structured data, factual explanations, applied articles, and sentences can be automatically extracted. After the shared layer automatically creates features from the extracted factual information, it delivers the appropriate features for the three tasks through the attention mechanism to perform the prediction tasks.
The structure of this paper is as follows. Section 2 introduces the verdicts published by KMST, the techniques used to construct the multi-task learning model, and the sentence prediction. In Section 3, the attention-mechanism-based multi-task learning sentence prediction model proposed in this study is described, and the prediction performance for each task is described and analyzed through experiments in Section 4. Section 5 states the conclusions and future works.
2. Related Works
2.1. The Verdicts
The maritime safety tribunal is a judicial institution that is in charge of special maritime-related domains among all incidents and accidents occurring in the Korean ocean. Four regional maritime safety tribunals deal with the first instance, Busan, Incheon, Mokpo, and Donghae; only the central maritime safety tribunal handles the second instance. The verdict is a document that summarizes the trial cases published by these judicial institutions. The title of the document contains the name of the institution that conducted the trial, the identification of the case, and the name of the case. The content includes the description and background information of the event, such as the facts, the cause of the accident, the main sentence, related maritime accidents, and the actions of the personnel involved in the accident.
In this study, verdicts published from 2010 to 2019 were selected for the training of the multi-task learning model. There were eight types of verdict: collision, stranding, contact, fire, sinking, engine damage, human casualty, and marine pollution, of which the frequency is greater than 30. Three parts of each verdict were extracted to create the training data. The first part is that the user of the legal service application has the same position as the user who entered the data. The second part is the legal articles that are to be applied according to the verdicts. The final part is the main sentence.
Figure 1 shows an example of facts, applied articles, and the main sentence obtained from the verdict published by the KMST. The first part is used for document embedding, which is the input of the multi-task model. The accident type, the applied article, and sentence in the title of the verdict are used as answer data for model training and experiments.
2.2. KorBERT Embedding Model
KorBERT is a language model distributed by the Electronics and Telecommunications Research Institute (ETRI) by training a large amount of Korean corpus on BERT [
11]. There are two types of language models: a morpheme-based language model and a WordPiece-based language model. In the case of using both word and sentence representation in the accident type classification experiment using factual information from the verdict, the accuracy using the universal sentence encoding model is the highest [
12,
13]; however, other studies have shown that classification results using KorBERT are more accurate [
1].
Therefore, in this study, using the KorBERT model, the factual information of the verdict and the label set of each task are produced as a sentence representation and used for learning and evaluation.
2.3. Attention Mechanism
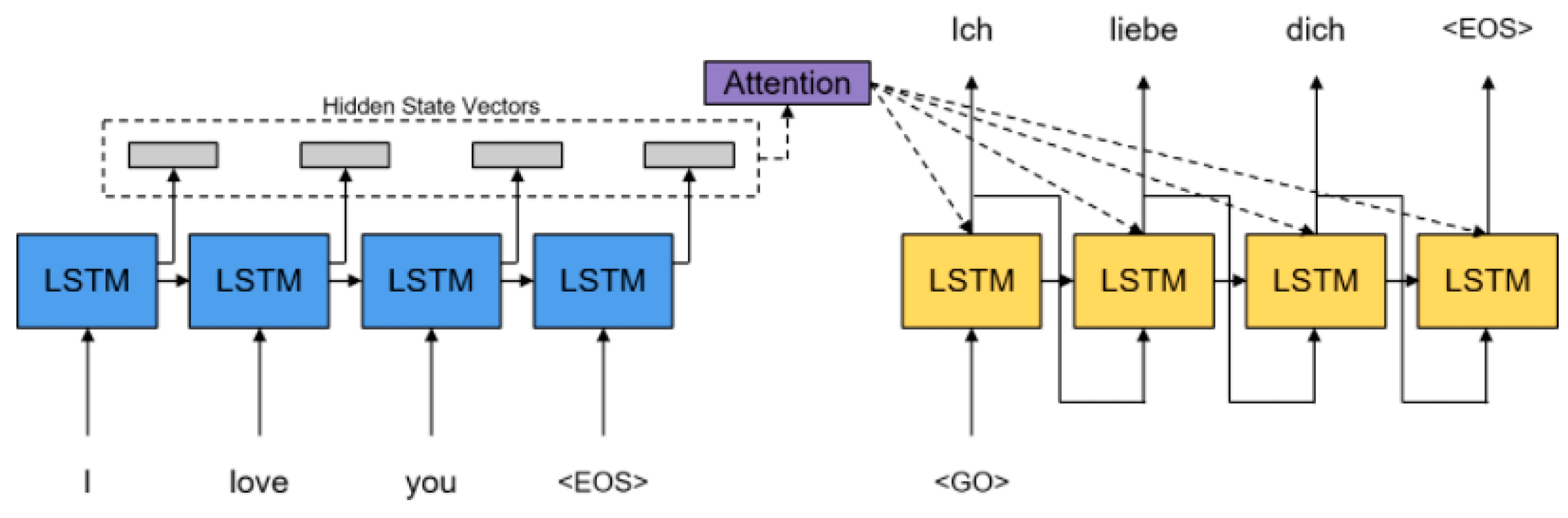
The attention mechanism refers to a technique that is employed to increase the performance of a neural network model by making it pay attention to a specific vector. It has emerged in the field of machine translation, where an encoder–decoder-type neural network model is applied. Since the encoder and the decoder use the same type of neural networks, the source sentence is encoded as a fixed-length vector. For the case of short sentences, there is no significant issue; however, as the length increases, more information is compressed into a fixed length, resulting in information loss. To solve this problem, the existing encoder–decoder model that provides the last output of the encoder as the first input of the decoder is improved, and the context vector generated as the output of all steps of the encoder is input to the decoder [
14]. This is called the attention mechanism.
Figure 2 shows an attention mechanism for the encoder–decoder model.
The context vector
in Equation (1) is a sum of hidden states
of the input sequence, weighted by alignment scores
, and is represented by ‘Attention’ in
Figure 2.
Instead of passing the last output of the encoder as the first input of the decoder, as in the existing encoder–decoder model, the problem of encoding the original sentence with a fixed length is solved by passing the context vector. In addition, the performance is greatly improved by providing the information that needs to be focused on at each stage of the decoder through the context vector.
In this study, sentence prediction is performed by applying the attention mechanism. The inner product is performed by replacing the hidden state of the encoder with the output of the shared layer, and replacing the previous hidden state of the decoder with the set of labels for each operation. Therefore, unlike the case where only simple factual information is used [
1], a context vector in which additional features are reflected in each task-specific layer is transmitted as an input.
2.4. Multi-Task Learning
Multi-task learning is an approach where one neural network can perform several tasks simultaneously; it is an effective method when several problems share one low-level feature [
9]. In multi-task learning, there is a hard-parameter sharing method [
15], and a soft-parameter sharing method [
16]. Hard-parameter sharing is a structure that shares the hidden layer of the neural network model and has an output layer optimized for each task, as shown in
Figure 3. This method is the most basic structure of multi-task learning, and it can prevent overfitting of a specific task because the model determines the appropriate output for each task [
10]. Soft-parameter sharing uses a different neural network model for each task, and multi-task learning is performed by regularizing the difference between the parameters of each model.
Multi-task learning can be normalized by ignoring or minimizing the noise present in the data when different tasks are being learned. As a result, a generalized latent representation can be learned for multiple tasks performed simultaneously [
9].
In this study, multi-task learning of the hard-parameter sharing method is performed. This is because the accident type, applied article, and sentence are predicted using only the factual information of one accident. Each task-specific layer that has received the same features through the shared layer extracts task-specific features from common features while learning.
2.5. Sentence Prediction
The sentence prediction task aims to find an appropriate sentence based on the facts of the case. Existing studies have performed multi-class classification, which uses factual explanations as inputs to machine learning models; these models output the sentence labels. Studies are predicting the sentences of representative case types in Taiwan using the k-NN model [
2,
3]. However, it is difficult to expand the case types because of the low accuracy of the k-NN model. Furthermore, similar types cannot be properly distinguished because of the word-level and phrase-level features used as training data. In order to overcome these shortcomings, a study was conducted to identify only two case types using manually fabricated features [
4]. However, this study did not solve the scalability issue because of the efforts used in manually creating features for each pair of case types. Therefore, in this study, we use a multi-task learning model and sentence-level features to comprehensively understand the factual information of thinking to classify similar sentence types. However, there are three problems in having one system predict all kinds of cases and accidents that occur in a country or the world. (1) It is almost impossible to extract or generate data for model learning. (2) Each country has a different social structure and legal system. Alternatively, even in a single country, the nature of the laws applied in each sector is different. (3) Overfitting may occur for frequently occurring cases and accident types; thus, sentence prediction is not performed properly for relatively rare cases or accident types. Therefore, in order to overcome the scalability issue, this study limits the field of incidents and accidents to ship accidents in the Korean ocean.
Expert systems such as sentence prediction require high accuracy and robustness. Therefore, several studies derived from the aspect of assistance systems for predicting articles exist. However, since the number of articles that can be combined according to law increases exponentially, some studies perform multi-class classification by considering only a fixed set of articles [
3,
5]. Alternatively, some studies rank the articles applicable to the case and then re-rank them [
6,
7]. In [
6], the support vector machine (SVM) [
17], a machine learning model, was used to create the first ranking of the appropriate article. Subsequently, it re-ranked the articles using the co-occurrence between words. In [
7], the top k candidate terms were extracted using the SVM and the fully connected layer. It changed the ranking through the attention mechanism of the extracted articles and factual information. Using a neural network simpler than the SVM produced a higher accuracy, and the model that used the attention mechanism showed sharp improvements in both precision and recall.
Another study predicted the overall outcome of a trial of a case. In [
18] a study was conducted to predict whether the present court would accept or cancel the judgment of the lower court.
3. Sentence Prediction Model for Ship Accidents
In this study, we propose a multi-task learning model based on the attention mechanism that simultaneously predicts accident types, applied articles, and sentences using factual information from the verdicts published by KMST. This Section describes the structure of the model and the multi-task learning process based on the attention mechanism.
Figure 4 shows the overall structure of the proposed sentence prediction model. It follows the basic form of the hard-parameter sharing model described in
Section 2.4; however, it is characterized by the addition of an attention layer between the shared layer and the task-specific layer.
The proposed multi-task learning model is largely composed of four layers. The first layer is an embedding layer, which converts the factual information extracted from the verdict and the label set of each task into a sentence-embedding vector through the KorBERT. The second layer is the shared layer, and the factual information converted into the sentence embedding is its input. The shared layer consists of a stacked structure of three LSTMs [
19]. The third layer is the attention layer, which takes the output of the shared layer in which factual information is expressed and the sentence embeddings of the label set of each task as inputs. The hidden vector and the output of the shared layer generate an attention value by performing matrix production with the sentence embeddings of the label set of each task. By the weighted sum of these attention values to the hidden vector, a context vector required for each task is produced. The fourth layer is a task-specific layer and receives as input a context vector constructed from the attention layer. The task-specific layer consists of one LSTM and one softmax layer. This is the layer where the prediction occurs.
3.1. Embedding Layer
The embedding layer converts the data required for the training and evaluation of the multi-task learning model into a sentence embedding vector.
Figure 5 shows the work process performed by the embedding layer. The language model for sentence embedding production (KorBERT), as described in
Section 2.2, which shows the best performance through experiments, is employed. The input data include factual information documents extracted from the verdict, eight types of ship accident that are predictive labels for the first task, and 40 legal articles of ‘Act on the Investigation of and Inquiry into Marine Accidents (AIIMA)’, which are the prediction labels for the second task. Furthermore, the nine sentences of AIIMA are used as the predictive label of the third task.
The output data is a sentence-embedding matrix of each input data point. The sentence-embedding matrix of the factual information is transferred to the shared layer, and the remaining sentence-embedding matrices , , and are used to generate context vectors in the attention layer.
3.2. Shared Layer
The shared layer performs the task of learning the neural network model with
, which is generated in the embedding layer as an input.
Figure 6 shows the work process performed by the shared layer.
We employ three LSTM neural network models with a stack structure to extract linguistic features for sentence prediction tasks from factual information. LSTM is a type of recurrent neural network (RNN) that has generally good performance for feature generation of sequential data.
In RNNs, should the length of the input data be sufficiently long, a long-term dependency problem occurs, in which the initial input data are not properly transmitted until the last step. To solve this problem, the LSTM adds a forget gate to the structure of the existing RNN. The factual information extracted from the verdict includes information on the aspect of the accident itself, such as an overview of the occurrence and information on the behavior of those involved in the accident. The LSTM is used to explicitly reflect the information onto the feature concerning the two aspects.
The factual information that has passed through three LSTMs becomes a hidden vector and is output from the shared layer. The feature representation generated through the shared layer is used for accurate prediction in each task-specific layer.
3.3. Attention Layer
The attention layer converts the hidden vector
of the factual information generated in the shared layer into a context vector
to be delivered to each task-specific layer.
Figure 7 shows the work process performed by the attention layer.
The three tasks of accident type, applied article, and sentence prediction are performed for the same accident. Therefore, to solve this problem, the choice of a multi-task learning model employing the hard-parameter sharing method is appropriate. However, the experimental results of [
13], which did not use the attentional mechanism, showed that there was a limit to the prediction accuracy by simply using the factual information of the verdicts. In particular, applied article prediction with a relatively large number of prediction labels stood out. A solution to this problem is to use the field limitations of the forecasting law described in
Section 2.5. The law applied to the proposed model deals only with AIIMA; thus, label extensions of each prediction task are unnecessary. Therefore, we perform the focus of attention between the fixed prediction labels and the factual information. This was inspired by [
7]; they demonstrated that the transfer of additional features through attention helped improve the performance of the model.
Equation (2) is an equation that is used in the attention layer to generate the context vector
.
denotes the type, article, and sentence of the accident, and
denotes the number of labels in
. By applying the bahdanau attention formula described in
Section 2.3, the context vector is generated through matrix production by reshaping
according to the number of labels. Through this, the context vectors to be delivered to each task-specific layer can secure additional features specialized for each prediction task, not just the features of the factual information itself.
3.4. Task-Specific Layer
The task-specific layer performs a practical prediction task based on the context vector transmitted from the attention layer.
Figure 8 shows the work process performed by the task-specific layer.
The LSTM used in the shared layer is used sequentially in the task-specific layer. Although additional features are reflected through the attention mechanism with predictive labels, the context vector still has the nature of sequential data. Therefore, after passing the context vector to one LSTM, prediction is performed through the softmax layer. Thus, the three task-specific layers can reflect the advantage of sharing the parameters of the shared layer as a multi-task learning model and an additional feature by using a context vector suitable for each task as an input.
Each task-specific layer equally uses cross-entropy as a loss function for learning because the task-specific layer finally classifies labels using the softmax function. Among the many candidates, predicting one label can be transformed into a classification task rather than a regression task. Therefore, unlike mean square error and mean absolute error, which use the output value of the model for loss calculation, cross-entropy is used as a loss function. The formula is as follows:
where
stands for the number of verdicts used for learning, and all tasks are trained to minimize the loss value. According to the characteristics of the multi-task learning model, error propagation in the shared layer is performed by applying the average of all errors per task.
4. Environment and Evaluation
This Section describes the experimental environments and performance evaluation of the proposed model.
4.1. Environment Setup
Among the verdicts published between 2010 and 2019, eight types of accidents with a frequency of more than 30 were selected: collision, stranding, contact, fire, sinking, engine damage, human casualty, and marine pollution. The selection criteria were based on the following factors: (1) Accident data occurring less than 30 times in 10 years can cause an imbalance problem between the training data. (2) It is an accident type that rarely occurs in reality. (3) It is easy to retrieve them because of their rarity. Consequently, a total of 11,638 ship accidents of the eight types were selected as training and evaluation data.
Table 2 shows the statistics of the data according to the accident types. The average number of sentences is relatively low for collisions, stranding, and contact types, where the cause of the accident is simply between two ships or a ship and a crew member. However, the average number of sentences is high in cases of fire, where the cause of ignition and ignition point must be investigated. It is also high for the case of engine damage, where it is necessary to reveal how the damaged engine affected the accident and why it broke down.
AIIMA has a total of 90 articles. However, more than half of the articles (50) are excluded because they are not the basis article that affects the judgment or provides the handling process or the department in charge of marine accidents. Therefore, 40 applied articles as labels were manually selected for the second multiple tasks.
Article 6 of AIIMA stipulates that ‘Discipline is divided into the following three types, and the judge determines the type of disciplinary action according to the severity of the act’. The three disciplines named in the article were revocation of license, suspension of work, and reprimand. Furthermore, the article also stated that ‘the period shall be from one month to one year.’ If the period is divided by months, the number of labels in the sentence prediction is 36 (three disciplines multiplied by 12 months). Therefore, the length of sentences that appeared in the verdicts published between 2010 and 2019 was investigated. We found that most of the disciplinary sentences lasted for three months. In addition, if the accident caused serious damage, the punishment was permanent instead of lasting one year. Therefore, the label was produced by dividing the disciplinary period into three sections. For each type of punishment, the label of the sentence was defined as less than three months, between three months but less than nine months, and at least nine months. Hence, a total of nine sentence labels were selected.
The factual information and predicted labels of the verdict were morphologically analyzed using Utagger [
20] and were subsequently produced as embedding data through the KorBERT. In addition, for each type of accident, the ratio of training data to test data was 7:3 for the evaluation.
4.2. Evaluation of Attention Mechanism
In this study, as described in
Section 3.3, the attention mechanism not only improves performance in machine translation but also in multi-class classification tasks. The goal is to allow the neural network model to be better trained by focusing on additional features related to the training data. The effectiveness of the method was verified by comparing the accuracy of the proposed multi-task learning model based on the attention mechanism and [
1].
Table 3 shows the prediction accuracy according to whether the attention mechanism was used for each task or not. Task 1 is an accident type prediction, Task 2 is an applied article prediction, and Task 3 is a sentence prediction.
For all the tasks, when the attention mechanism was used, the accuracy was relatively high. In particular, unlike the first and third tasks, which increased by 0.53% and 0.06%, respectively, the second task of predicting the applied article showed a high accuracy improvement of 4.55%. This seems to be reflected more in the context vector than in other tasks because the sentence length of the article is much longer than that of the accident type or sentence. However, as with the results in [
1], the second task still has the lowest accuracy. This could be caused by the number of prediction labels, which is approximately four times greater than those of the other tasks.
This shows that the attention mechanism is very helpful for predicting the sentencing on ship accidents; however, additional supplementation is needed to aid the relevant personnel.
4.3. Evaluation of Multi-Task Learning Model
Table 1 shows the accuracy of Task 1, and the classes are encoded in order as follows: collision, stranding, contact, fire, sinking, engine damage, human casualty, and marine pollution. As shown in
Table 1, the number of collisions and human casualties (class 1 and class 7) account for about 65% of the total data. We use two accuracy metrics, micro-average and macro-average since the imbalance between these types can be caused. As a result, the micro-average and the macro-average of accuracy are 96.53 and 94.96, respectively. As you can see, the micro-average, which is calculated from the individual classes, is greater than the macro-average.
Table 4 and
Table 5 show the prediction performance for Task 2 and Task 3. The classes are the same as that of
Table 6.
A characteristic common to all prediction tasks is data imbalance by class. The difference between micro-accuracy and macro-accuracy is 1.67% in the first task, 1.14% in the second task, and 2.21% in the third task. This difference is caused by the difference in data distribution between the classes. This difference is even more pronounced when comparing accuracies by class. In the first task, class 1, with the most data, was predicted with an accuracy of 97.48%, while the accuracy of class 8, with the least data, was 89.32%, showing a difference of 8.16%. The second task and the third task also showed a difference of 7.27% and 8.69%, respectively.
To solve this problem, it is not appropriate to additionally collect a relatively small number of class data. Owing to the fact that the data used for training and testing are the verdicts issued from 2010 to 2019, a small number of class data means that fewer accidents related to the class occur in reality. Thus, to overcome this issue, imbalance learning is necessary.
Analogous to the evaluation in
Section 4.2, the performance of the model improved when the attention mechanism was employed. However, to further improve the accuracy, other neural network models that can extract more appropriate features than LSTM from factual information, or a method of adding new features that can be used for prediction, should be applied.
In addition, for in-depth analysis of the proposed model, a confusion matrix as shown in
Table 7 was conducted using Task 1, which showed the best performance among the three tasks.
Unlike the accuracy shown in
Table 4,
Table 5 and
Table 6,
Table 8 shows five additional measures using the values in
Table 7. Since it is a multiclass classification task, not a binary, the calculated measure was obtained as the average of all classes.
Precision is a measure of the accuracy of the accident type prediction. The precision of the model is 94.46%, which means that the prediction results are mostly accurate. Recall is a measure of how accurately each type of accident is predicted. The recall of the model is 94.98%, which confuses about 5% of the type of accident by the model, leaving room for improvement. The F1 score is the harmonic mean of precision and recall, and the F1 score of the model is 94.70%. False alarm rate refers to the rate of being incorrectly classified as a specific accident type. The false alarm rate of the model is very low at 0.5%. Additionally, specificity, as opposed to false alarm rate, is the rate at which the model is certain of a specific accident type. The specificity of the model is 99.48%. In conclusion, the false alarm rate and specificity show very high reliability of the proposed model. However, in terms of precision and recall, it seems that classification performance improvement work is needed.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}