
Deep Learning-Based Context-Aware Recommender System Considering Contextual Features



Abstract
:1. Introduction
2. Related Works
3. Proposed Model
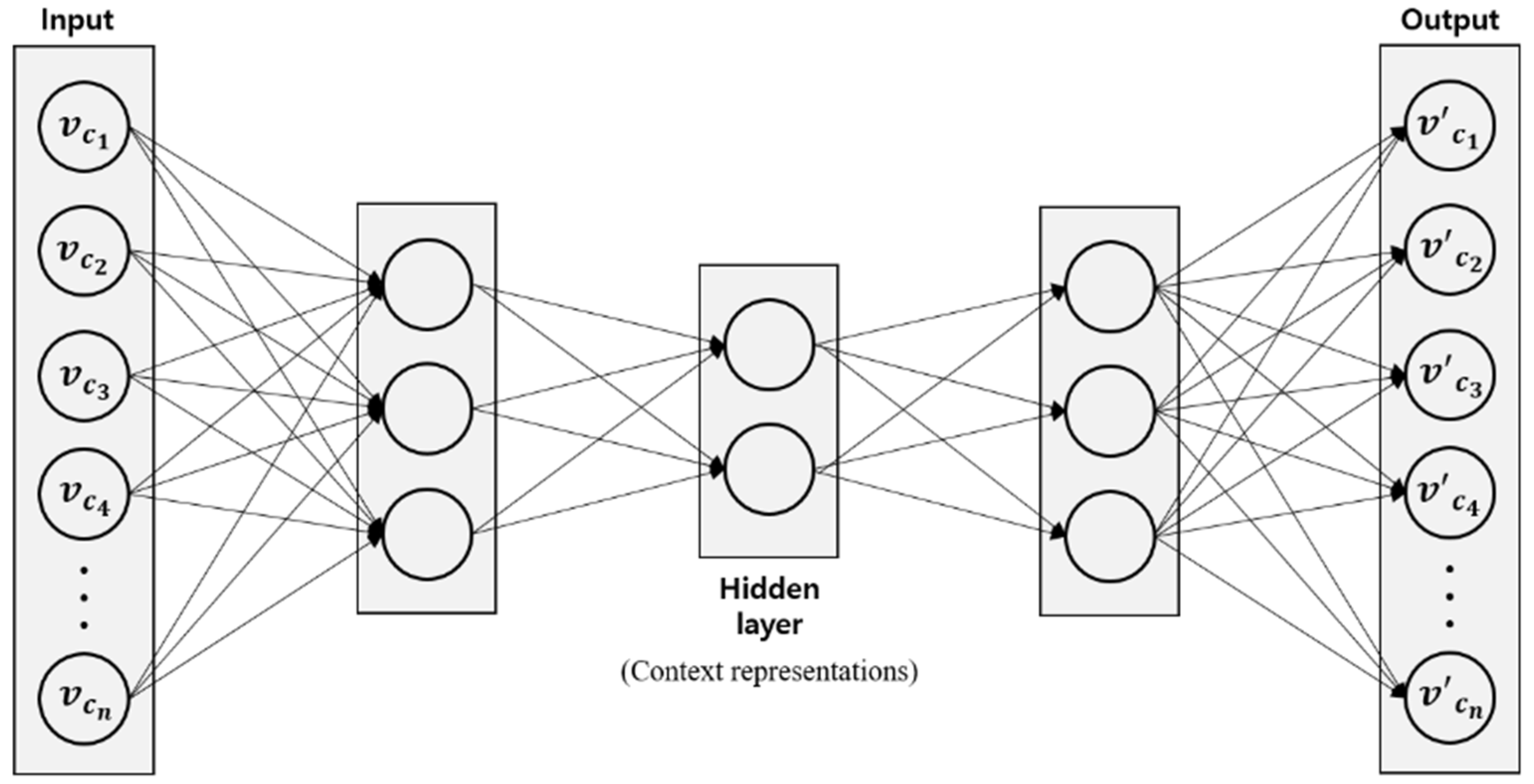
3.1. Learning Context Using Autoencoder
3.2. Deep Learning
| Algorithm 1 Algorithm of Proposed Model |
| Input: User vector U, Item vector I, Context vector Learning rate N, number of iterations k |
| Output: parameter , Rating vector Y |
| Randomly initialize parameters |
| for to k do |
| for do |
| Update using |
| Update using |
| end for |
| end for |
4. Experiments
4.1. Datasets
- DePaulMovie dataset has a total of 3 contextual dimensions—Time, Location and Companion. Time has a total of 2 contextual conditions—Weekend and Weekday. Location has a total of 2 contextual conditions—Home and Cinema. Companion has a total of 3 contextual conditions—Alone, Family and Partner. DePaulMovie has the smallest set of context features.
- InCarMusic dataset has a total of 8 contextual dimensions—Driving Style, Road type, Landscape, Sleepiness, Traffic conditions, Mood, Weather and Natural Phenomena. In total, there exist a total of 26 contextual conditions.
- Restaurant (Tijuana) dataset is formed by combining time (Weekday, Weekend) and location(School, Home, Work).
4.2. Evaluation Measures
4.3. Compared Methods
4.4. Results of the Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Covington, P.; Adams, J.; Sargin, E. Deep Neural Networks for YouTube Recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 191–198. [Google Scholar] [CrossRef] [Green Version]
- Esmaeili, L.; Mardani, S.; Golpayegani, S.A.H.; Madar, Z.Z. A novel tourism recommender system in the context of social commerce. Expert Syst. Appl. 2020, 149, 113301. [Google Scholar] [CrossRef]
- Jiang, P.; Zhu, Y.; Zhang, Y.; Yuan, Q. Life-stage prediction for product recommendation in e-commerce. In Proceedings of the Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1879–1888. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Context-aware recommender systems. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 217–253. [Google Scholar]
- Li, J.; Sun, C.; Lv, J. TCMF: Trust-Based Context-Aware Matrix Factorization for Collaborative Filtering. In Proceedings of the 2014 IEEE 26th International Conference on Tools with Artificial Intelligence, Limassol, Cyprus, 10–12 November 2014; pp. 815–821. [Google Scholar] [CrossRef]
- Verbert, K.; Manouselis, N.; Ochoa, X.; Wolpers, M.; Drachsler, H.; Bosnic, I.; Duval, E. Context-aware recommender systems for learning: A survey and future challenges. IEEE Trans. Learn. Technol. 2012, 5, 318–335. [Google Scholar] [CrossRef]
- Zheng, Y.; Mobasher, B.; Burke, R.D. Incorporating Context Correlation into Context-aware Matrix Factorization. In Proceedings of the 2015 International Conference on Constraints and Preferences for Configuration and Recommendation and Intelligent Techniques for Web Personalization, Buenos Aires, Argentina, 25–27 July 2015; Volume 1440. [Google Scholar]
- Akhmatnurov, M.; Ignatov, D.I. Context-Aware Recommender System Based on Boolean Matrix Factorization. CEUR Workshop Proc. 2015, 1466, 99–110. [Google Scholar]
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative filtering for implicit feedback datasets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 263–272. [Google Scholar] [CrossRef]
- Liu, Q.; Wu, S.; Wang, L. Cot: Contextual operating tensor for context-aware recommender systems. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 203–209. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Bokde, D.; Girase, S.; Mukhopadhyay, D. Matrix factorization model in collaborative filtering algorithms: A survey. Procedia Comput. Sci. 2015, 49, 136–146. [Google Scholar] [CrossRef] [Green Version]
- Xue, H.J.; Dai, X.; Zhang, J.; Huang, S.; Chen, J. Deep Matrix Factorization Models for Recommender Systems. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; Volume 17, pp. 3203–3209. [Google Scholar] [CrossRef] [Green Version]
- Mu, R.; Zeng, X.; Han, L. A survey of recommender systems based on deep learning. IEEE Access 2018, 6, 69009–69022. [Google Scholar] [CrossRef]
- Tay, Y.; Luu, A.T.; Hui, S.C. Multi-Pointer Co-Attention Networks for Recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2309–2318. [Google Scholar] [CrossRef] [Green Version]
- Frank, M.; Drikakis, D.; Charissis, V. Machine-learning methods for computational science and engineering. Computation 2020, 8, 15. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep learning based recommender system: A survey and new perspectives. ACM Comput. Surv. (CSUR) 2019, 52, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional matrix factorization for document context-aware recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 233–240. [Google Scholar] [CrossRef]
- Bobadilla, J.; Alonso, S.; Hernando, A. Deep Learning Architecture for Collaborative Filtering Recommender Systems. Appl. Sci. 2020, 10, 2441. [Google Scholar] [CrossRef] [Green Version]
- Shoja, B.M.; Tabrizi, N. Customer reviews analysis with deep neural networks for e-commerce recommender systems. IEEE Access 2019, 7, 119121–119130. [Google Scholar] [CrossRef]
- Tuinhof, H.; Pirker, C.; Haltmeier, M. Image-based fashion product recommendation with deep learning. In Proceedings of the International Conference on Machine Learning, Optimization, and Data Science, Volterra, Italy, 13–16 September 2018; Springer: Cham, Swizerland, 2018; pp. 472–481. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Wang, N.; Yeung, D.Y. Collaborative deep learning for recommender systems. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1235–1244. [Google Scholar]
- Baltrunas, L.; Ludwig, B.; Ricci, F. Matrix factorization techniques for context aware recommendation. In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 301–304. [Google Scholar] [CrossRef] [Green Version]
- Rendle, S.; Schmidt-Thieme, L. Pairwise interaction tensor factorization for personalized tag recommendation. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, New York, NY, USA, 3–6 February 2010; pp. 81–90. [Google Scholar] [CrossRef] [Green Version]
- Karatzoglou, A.; Amatriain, X.; Baltrunas, L.; Oliver, N. Multiverse recommendation: N-dimensional tensor factorization for context-aware collaborative filtering. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 79–86. [Google Scholar] [CrossRef]
- Baltrunas, L.; Ricci, F. Experimental evaluation of context-dependent collaborative filtering using item splitting. User Modeling User-Adapt. Interact. 2014, 24, 7–34. [Google Scholar] [CrossRef]
- Phuong, T.M.; Phuong, N.D. Graph-based context-aware collaborative filtering. Expert Syst. Appl. 2019, 126, 9–19. [Google Scholar] [CrossRef]
- Rendle, S.; Gantner, Z.; Freudenthaler, C.; Schmidt-Thieme, L. Fast context-aware recommendations with factorization machines. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 24–28 July 2011; pp. 635–644. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L. Autorec: Autoencoders meet collaborative filtering. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 111–112. [Google Scholar] [CrossRef]
- Zhong, S.-T.; Huang, L.; Wang, C.-D.; Lai, J.-H.; Yu, P.S. An autoencoder framework with attention mechanism for cross-domain recommendation. IEEE Trans. Cybern. 2020, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Pan, Y.; He, F.; Yu, H. Learning social representations with deep autoencoder for recommender system. World Wide Web 2020, 23, 2259–2279. [Google Scholar] [CrossRef]
- Zheng, Y.; Mobasher, B.; Burke, R. Carskit: A java-based context-aware recommendation engine. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 1668–1671. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Movie | Music | Restaurant | |
|---|---|---|---|
| #of users | 123 | 42 | 50 |
| #of items | 79 | 139 | 41 |
| #of ratings | 5043 | 4013 | 896 |
| Dimension | 3 | 8 | 1 |
| Rating Scale | 1–5 | 0–5 | 1–5 |
| Data sparsity | 94.5 | 99.9 | 93.4 |
| Precision@10 | Music | Restaurant | Movie |
|---|---|---|---|
| UserKNN | 0.010082 | 0.062889 | 0.063732 |
| SVD++ | 0.045452 | 0.062174 | 0.059719 |
| CAMF_CI | 0.024234 | 0.050423 | 0.058384 |
| ItemSplitting-BiasedMF | 0.045365 | 0.06249 | 0.054859 |
| CSLIM_CI | 0.003996 | 0.012763 | 0.004598 |
| PMF | 0.048151 | 0.068362 | 0.06807 |
| FM | 0.010663 | 0.047136 | 0.027956 |
| NN based model | 0.050387 | 0.059913 | 0.076811 |
| Proposed model | 0.056760 | 0.072748 | 0.102263 |
| MAP@10 | Music | Restaurant | Movie |
|---|---|---|---|
| UserKNN | 0.036538 | 0.110237 | 0.107568 |
| SVD++ | 0.171105 | 0.17123 | 0.070776 |
| CAMF_CI | 0.070767 | 0.121712 | 0.087723 |
| ItemSplitting-BiasedMF | 0.188662 | 0.175772 | 0.07685 |
| CSLIM_CI | 0.006741 | 0.066281 | 0.011318 |
| PMF | 0.179647 | 0.203266 | 0.095294 |
| FM | 0.037309 | 0.086927 | 0.073874 |
| NN based model | 0.147583 | 0.175486 | 0.224978 |
| Proposed model | 0.196248 | 0.190286 | 0.268133 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, S.-Y.; Kim, Y.-K. Deep Learning-Based Context-Aware Recommender System Considering Contextual Features. Appl. Sci. 2022, 12, 45. https://doi.org/10.3390/app12010045
Jeong S-Y, Kim Y-K. Deep Learning-Based Context-Aware Recommender System Considering Contextual Features. Applied Sciences. 2022; 12(1):45. https://doi.org/10.3390/app12010045
Chicago/Turabian StyleJeong, Soo-Yeon, and Young-Kuk Kim. 2022. "Deep Learning-Based Context-Aware Recommender System Considering Contextual Features" Applied Sciences 12, no. 1: 45. https://doi.org/10.3390/app12010045
APA StyleJeong, S.-Y., & Kim, Y.-K. (2022). Deep Learning-Based Context-Aware Recommender System Considering Contextual Features. Applied Sciences, 12(1), 45. https://doi.org/10.3390/app12010045