
New Hybrid Techniques for Business Recommender Systems



Abstract
:1. Introduction
- Requirement-driven: A consultancy recommender needs to consider business requirements not personal preferences;
- Interdependent items: The recommended items are not simple, atomic and independent products (such as books, movies etc.) but interdependent and sometimes complex components of a larger solution;
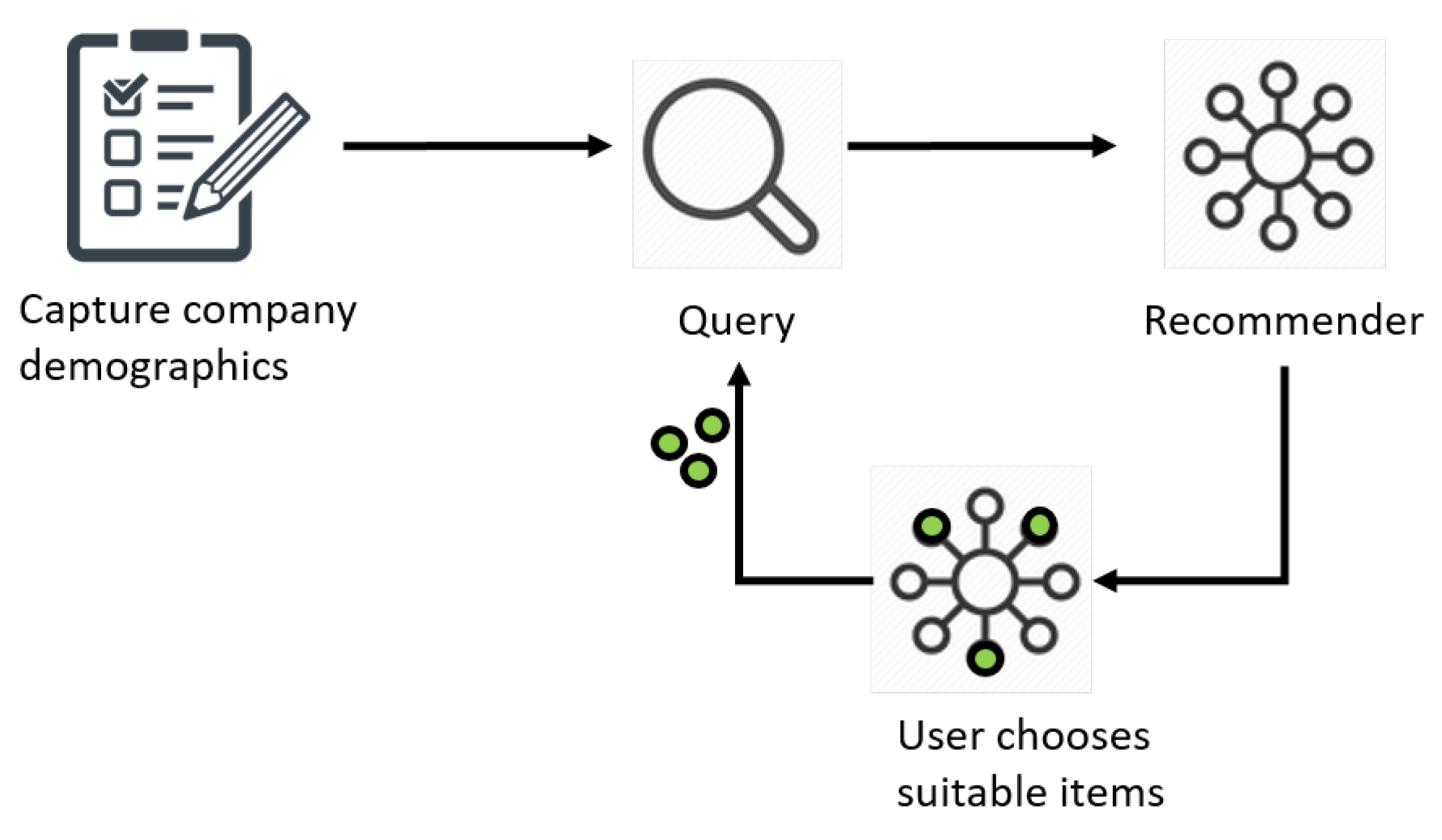
- No profiles: While typical B2C recommenders are used repeatedly by the same person, a digital consultancy service has no chance to build up customer profiles through repeated interactions; companies will usually access the service only once. Thus, a profile of the company needs to be acquired within a single session by the recommender; one can regard it as forming a query that describes the situation of the company seeking advice.
- Many companies share the same requirements, just like many persons share preferences. The similarity of requirements often depends on the companies’ demographics (e.g., size, industry etc.). Thus, a first step in the digital consultancy process may be to capture company demographics and regard them as an initial company profile or initial query. This allows establishing a certain similarity between companies from the beginning.
- Later, the similarity of context and requirements manifests itself in accepting similar suggestions from the recommender. Since solutions will be complex, one may construct a repeated interaction with the recommender in the form of iterations: after entering the company demographics (step 1), the business user receives a first set of recommendations and selects from those some first elements of a solution. These elements are added to the initial company profile to form an extended query, and the recommender is invoked again. This process is repeated, each time with a more verbose query. (We will later use the term “query verbosity” to refer to the growing amount of information that the query contains.)
1.1. Application Scenario
- Suitable key performance indicators (KPIs) that can be used to monitor and measure the company’s success in achieving its goals, e.g., “sales revenue”;
- Adequate dimensions to describe the values of KPIs, e.g., to characterise sales by product that was sold, channel through which it was sold and/or date when it was sold;
- Suitable representations, e.g., charts or tables that help to analyse KPI values along dimensions (e.g., a chart showing temporal evolution of sales revenue for different products).
1.2. Contribution
- Despite the existence of some previous work, we do not yet have reliable knowledge about which type of recommender is best suited for the task;
- We do know that different recommenders have different strengths and weaknesses in general that affect their ability to represent and accommodate certain types of knowledge and/or inputs and their ability to deal with a lack of such knowledge (“cold-start problems”).
2. Related Work
2.1. Digitalisation of Consultancy Services
2.2. Business-Oriented Recommendations
- Augmentations of content-based filtering:Approaches in this category model both the input and output complexities and establish the degree to which both of them match. For instance, constraint-based recommenders [4,16] help model product features and constraints to be expressed about them and then ensure constraint satisfaction. Other approaches use tree-like structures to model items and user preferences [17] or use multiple levels on which queries and items are matched (such as recommending first providers and then actual services in a service recommender [18]).In content-based filtering, additional knowledge can be incorporated, e.g., into the function that determines the similarity between an item and the user profile. Often, this is knowledge about user context, item features and/or domain-specific constraints. For instance, refs. [19,20] use ontologies to represent and reason about item features and to apply this knowledge in a sophisticated similarity measure that takes into account “hidden relationships” [20]. Middleton et al. [21] use an ontology to represent user profiles and engage users in correcting the profiles before assessing profile–item similarities. The complexity of business contexts has also been highlighted in [22], where the authors focus on identifying the criteria for recommendations in business processes that will serve as inputs to knowledge-based recommenders.
- Augmentations of collaborative filtering:Case-based recommenders [6,23] can be seen as a special form of collaborative filtering since they recommend items used in solutions of companies that are similar to the current company. However, instead of only considering already chosen items, case-based recommenders’ similarity measures take into account context variables that describe, e.g., company demographics and other relevant aspects of the company’s problem and/or initial situation.Since case-based reasoning is an approach based on problem-solving from past experience, case-based recommenders have been implemented in domains that most benefit from contextual information coming from past experience. For example, [24] explored case-based recommenders to recommend personalized financial products to the customers of a banking organisation. The authors of [25] argue that case-based recommenders are much more suitable for a complex domain of smart-city intiatives as they can utilize a rich range of domain-specific attributes.
- Graph-based recommenders:Recommender algorithms based on graph structures [7,26,27] have been put forward because of their ability to accommodate a wide variety of forms of contexts in a flexible way without much effort. Random walks [28,29,30] are a predominant type of algorithm to provide recommendations based on graph structures. Because of their simplicity, graphs also have limitations, e.g., in modeling and matching simple string-valued attributes of input cases or in modeling certain forms of complex solution structures. The possibility of using graph-based recommenders to “mimick” traditional recommender approaches, such as collaborative or content-based filtering, has been explored by Lee et al. [31]. For this, one needs to assign different weight to different types of graph relations.A comprehensive study by [32] has identified the potential of knowledge graphs to improve the explanability of recommendations as well as to provide dynamic recommendations. Wang et al. [33] have combined knowledge graphs with content-based filtering to support the recruitment of consultants with suitable skills for clients by calculating semantic similarity between the graph nodes.
2.3. Evaluation of Business-Oriented Recommenders
2.4. Hybrid Recommenders
3. Methodology
3.1. Awareness of Current Consultancy Practice
3.2. Recommender Selection
3.3. Experiments
4. Interview Findings: Case Structure and Similarity Measure
- Customers often come to the meetings with some important KPIs and dimensions (i.e., solution elements) already in mind. However, the degree to which customers have initial ideas can vary greatly. We have reflected this variance by creating queries at different verbosity levels.
- In terms of company demographics, consultants consider the industry of a customer as the main criterion for finding similar past cases. Further relevant variables that we elicited were the target group of the solution (e.g., only management or all employees) and the goal of the BI project (expressed in natural language). Finally, consultants use all known customer preferences from initial meetings (see above), i.e., any already known solution elements to remember past cases with similar elements.The business process was also mentioned by consultants as an important variable. Because of its importance, we chose not to use it simply as a ranking criterion for the retrieval of similar cases, but as a filter. For a given company, we created separate cases for each business process the company wanted to analyse and retrieved only cases with the same business process. (Analogously, we built separate case base graphs for the graph recommender, see below.)
- In the second round of interviews, we asked the consultants to quantify the relative importance of these types of attributes in terms of percentage weight. This task can be difficult as the weights identified by different consultants can vary. However, since the relative importance of the attributes is based on domain-knowledge and not on personal preferences of the consultants, we were quickly able to arrive at a consensus about the weights. Although quantifying something as abstract as a variable’s contribution to a similarity score is a hard task, we were able to verify in some preliminary experiments that the chosen weights gave quite good results compared to other potential weight configurations. The resulting weights are shown in Table 1.
- When talking to a customer from an unknown industry, consultants tried to remember cases of customers from similar industries. Since our attempts to use an industry taxonomy for improved similarity assessment in a graph-based recommender were not particularly successful, we did not consider this kind of reasoning in this work. However, we did use the industry taxonomy to define a local similarity measure for industries within a CBR recommender (see Section 5.3).
5. Recommender Configurations
5.1. Collaborative Filtering
5.2. Random Walk Recommender
5.3. CBR Recommender
- Similarity measures depending on attribute type: Based on the taxonomy-tree approach proposed by [54], the industry attribute uses the industry taxonomy derived by [3] that categorizes the customers of the consultancy based on their similarities (e.g., customers that are likely to share KPIs and dimensions). For the attributes goal (free text) and KPI, we could apply the TF-IDF [55] similarity measure by creating a corpus of goals and KPIs, respectively, from the case base for the computation of inverse document frequencies (IDFs). Although KPIs are not free text, applying TF-IDF is appropriate to disregard repeated terms such as “Number of” or “Amount” since they do not add significant value to the recommendations. Lastly, for the attribute target group, we calculated the Jaccard coefficient [55] as a case may have more than one target audience from the possible values “employees”/“middle management”/“top management”.
- The number n of the most relevant (top) cases retrieved: The number of the retrieved cases played a significant role in calculating the scores of the recommended elements, which in turn determine the ranking. For an element appearing in any of the retrieved cases for a query , the score of that element is the sum of the scores of all the retrieved cases in which the element occurs:Obviously, the larger the case base, the larger we can choose n, i.e., the maximum size of . For a rather small case base like ours, we expect that smaller values of n will work better since larger values will likely imply a “topic drift” by including rather dissimilar cases. The score of the case was generated by the CBR recommender using the global similarity function, which is the weighted average of the local similarity measures [56]: .
- For that weighted average, we used the weights assigned to the local similarity measures shown in Table 1.
6. Experiment 1: Strengths and Weaknesses of Recommenders
7. A New Hybrid Recommender Design
8. Experiment 2: Performance of Hybrid Recommender
9. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nissen, V. Digital transformation of the consulting industry—Introduction and overview. In Digital Transformation of the Consulting Industry; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1–58. [Google Scholar]
- Werth, D.; Zimmermann, P.; Greff, T. Self-service consulting: Conceiving customer-operated digital IT consulting services. In Proceedings of the AMCIS 2016, San Diego, CA, USA, 11–14 August 2016. [Google Scholar]
- Witschel, H.; Martin, A. Random Walks on Human Knowledge: Incorporating Human Knowledge into Data-Driven Recommender. In Proceedings of the 10th International Conference on Knowledge Management and Information Sharing (KMIS), Seville, Spain, 18–20 September 2018. [Google Scholar]
- Felfernig, A.; Burke, R. Constraint-based recommender systems: Technologies and research issues. In Proceedings of the 10th International Conference on Electronic Commerce, Innsbruck, Austria, 19–22 August 2008; p. 3. [Google Scholar]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl.-Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Bridge, D.; Göker, M.H.; McGinty, L.; Smyth, B. Case-based recommender systems. Knowl. Eng. Rev. 2005, 20, 315–320. [Google Scholar] [CrossRef] [Green Version]
- Minkov, E.; Kahanov, K.; Kuflik, T. Graph-based recommendation integrating rating history and domain knowledge: Application to on-site guidance of museum visitors. J. Assoc. Inf. Sci. Technol. 2017, 68, 1911–1924. [Google Scholar] [CrossRef]
- Witschel, H.F.; Peter, M.; Seiler, L.; Parlar, S.; Grivas, S.G. Case Model for the RoboInnoCase Recommender System for Cases of Digital Business Transformation: Structuring Information for a Case of Digital Change. In Proceedings of the 11th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2019), Vienna, Austria, 17–19 September 2019; SciTePress: Setubal, Portugal, 2019; pp. 62–73. [Google Scholar]
- Burke, R.; Ramezani, M. Matching recommendation technologies and domains. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 367–386. [Google Scholar]
- Deelmann, T. Does digitization matter? Reflections on a possible transformation of the consulting business. In Digital Transformation of the Consulting Industry; Springer: Cham, Switzeland, 2018; pp. 75–99. [Google Scholar]
- Witschel, H.F.; Galie, E.; Riesen, K. A Graph-Based Recommender for Enhancing the Assortment of Web Shops. In Proceedings of the Workshop on Data Mining in Marketing DMM’2015, Hamburg, Germany, 11–14 July 2015. [Google Scholar]
- Zhang, M.; Ranjan, R.; Nepal, S.; Menzel, M.; Haller, A. A declarative recommender system for cloud infrastructure services selection. In International Conference on Grid Economics and Business Models; Springer: Berlin/Heidelberg, Germany, 2012; pp. 102–113. [Google Scholar]
- Kritikos, K.; Laurenzi, E.; Hinkelmann, K. Towards business-to-IT alignment in the cloud. In Advances in Service-Oriented and Cloud Computing. ESOCC 2017; Springer: Cham, Switzerland, 2017; pp. 35–52. [Google Scholar]
- Yao, L.; Sheng, Q.Z.; Ngu, A.H.; Yu, J.; Segev, A. Unified collaborative and content-based web service recommendation. IEEE Trans. Serv. Comput. 2015, 8, 453–466. [Google Scholar] [CrossRef]
- Laliwala, Z.; Sorathia, V.; Chaudhary, S. Semantic and rule based event-driven services-oriented agricultural recommendation system. In Proceedings of the 26th IEEE International Conference on Distributed Computing Systems Workshops (ICDCSW’06), Lisboa, Portugal, 4–7 July 2006; p. 24. [Google Scholar]
- Felfernig, A.; Friedrich, G.; Jannach, D.; Zanker, M. Constraint-based recommender systems. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2015; pp. 161–190. [Google Scholar]
- Wu, D.; Zhang, G.; Lu, J. A fuzzy preference tree-based recommender system for personalized business-to-business e-services. IEEE Trans. Fuzzy Syst. 2015, 23, 29–43. [Google Scholar] [CrossRef]
- Mohamed, B.; Abdelkader, B.; M’hamed, B.F. A multi-level approach for mobile recommendation of services. In Proceedings of the International Conference on Internet of things and Cloud Computing, Cambridge, UK, 22–23 March 2016; p. 40. [Google Scholar]
- Carrer-Neto, W.; Hernández-Alcaraz, M.L.; Valencia-García, R.; García-Sánchez, F. Social knowledge-based recommender system. Application to the movies domain. Expert Syst. Appl. 2012, 39, 10990–11000. [Google Scholar] [CrossRef] [Green Version]
- Blanco-Fernández, Y.; Pazos-Arias, J.J.; Gil-Solla, A.; Ramos-Cabrer, M.; López-Nores, M.; García-Duque, J.; Fernández-Vilas, A.; Díaz-Redondo, R.P.; Bermejo-Muñoz, J. A flexible semantic inference methodology to reason about user preferences in knowledge-based recommender systems. Knowl.-Based Syst. 2008, 21, 305–320. [Google Scholar] [CrossRef]
- Middleton, S.E.; Shadbolt, N.R.; De Roure, D.C. Ontological user profiling in recommender systems. ACM Trans. Inf. Syst. (TOIS) 2004, 22, 54–88. [Google Scholar] [CrossRef]
- Revina, A.; Rizun, N. Multi-Criteria Knowledge-Based Recommender System for Decision Support in Complex Business Processes. In Proceedings of the Workshop on Recommendation in Complex Scenarios co-located with 13th ACM Conference on Recommender Systems (RecSys 2019), Copenhagen, Denmark, 20 September 2019; pp. 16–22. [Google Scholar]
- Bousbahi, F.; Chorfi, H. MOOC-Rec: A case based recommender system for MOOCs. Procedia-Soc. Behav. Sci. 2015, 195, 1813–1822. [Google Scholar] [CrossRef] [Green Version]
- Hernandez-Nieves, E.; Hernández, G.; Gil-González, A.B.; Rodríguez-González, S.; Corchado, J.M. CEBRA: A CasE-Based Reasoning Application to recommend banking products. Eng. Appl. Artif. Intell. 2021, 104, 104327. [Google Scholar] [CrossRef]
- Anthony Jnr, B. A case-based reasoning recommender system for sustainable smart city development. AI Soc. 2021, 36, 159–183. [Google Scholar] [CrossRef]
- Bogers, T. Movie recommendation using random walks over the contextual graph. In Proceedings of the 2nd International Workshop on Context-Aware Recommender Systems, Barcelona, Spain, 26 September 2010. [Google Scholar]
- Zhang, Z.; Zeng, D.D.; Abbasi, A.; Peng, J.; Zheng, X. A random walk model for item recommendation in social tagging systems. ACM Trans. Manag. Inf. Syst. (TMIS) 2013, 4, 8. [Google Scholar] [CrossRef] [Green Version]
- Fouss, F.; Pirotte, A.; Renders, J.M.; Saerens, M. Random-Walk Computation of Similarities Between Nodes of a Graph with Application to Collaborative Recommendation. IEEE Trans. Knowl. Data Eng. 2007, 19, 355–369. [Google Scholar] [CrossRef]
- Huang, Z.; Chung, W.; Ong, T.H.; Chen, H. A Graph-based Recommender System for Digital Library. In Proceedings of the 2nd ACM/IEEE-CS Joint Conference on Digital Libraries, Portland, OR, USA, 14–18 July 2002; pp. 65–73. [Google Scholar]
- Liu, Y.; Ma, H.; Jiang, Y.; Li, Z. Learning to recommend via random walk with profile of loan and lender in P2P lending. Expert Syst. Appl. 2021, 174, 114763. [Google Scholar] [CrossRef]
- Lee, S.; Park, S.; Kahng, M.; Lee, S.G. PathRank: Ranking nodes on a heterogeneous graph for flexible hybrid recommender systems. Expert Syst. Appl. 2013, 40, 684–697. [Google Scholar] [CrossRef]
- Chicaiza, J.; Valdiviezo-Diaz, P. A comprehensive survey of knowledge graph-based recommender systems: Technologies, development, and contributions. Information 2021, 12, 232. [Google Scholar] [CrossRef]
- Wang, Y.; Allouache, Y.; Joubert, C. A Staffing Recommender System based on Domain-Specific Knowledge Graph. In Proceedings of the 2021 Eighth International Conference on Social Network Analysis, Management and Security (SNAMS), Gandia, Spain, 6–9 December 2021; pp. 1–6. [Google Scholar]
- Nia, A.G.; Lu, J.; Zhang, Q.; Ribeiro, M. A Framework for a Large-Scale B2B Recommender System. In Proceedings of the 2019 IEEE 14th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Dalian, China, 14–16 November 2019; pp. 337–343. [Google Scholar]
- Tarus, J.K.; Niu, Z.; Mustafa, G. Knowledge-based recommendation: A review of ontology-based recommender systems for e-learning. Artif. Intell. Rev. 2018, 50, 21–48. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. (TOIS) 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Silveira, T.; Zhang, M.; Lin, X.; Liu, Y.; Ma, S. How good your recommender system is? A survey on evaluations in recommendation. Int. J. Mach. Learn. Cybern. 2019, 10, 813–831. [Google Scholar] [CrossRef] [Green Version]
- Ge, M.; Delgado-Battenfeld, C.; Jannach, D. Beyond accuracy: Evaluating recommender systems by coverage and serendipity. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 257–260. [Google Scholar]
- Voorhees, E.M.; Harman, D.K. TREC—Experiment and Evaluation in Information Retrieval; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Burke, R. Hybrid recommender systems: Survey and experiments. User Model. User-Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Burke, R. Hybrid web recommender systems. In The Adaptive Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 377–408. [Google Scholar]
- Burke, R. A case-based reasoning approach to collaborative filtering. In European Workshop on Advances in Case-Based Reasoning, Trento, Italy, 6–9 September 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 370–379. [Google Scholar]
- Rivas, A.; Chamoso, P.; González-Briones, A.; Casado-Vara, R.; Corchado, J.M. Hybrid job offer recommender system in a social network. Expert Syst. 2019, 36, e12416. [Google Scholar] [CrossRef]
- Burke, R. Knowledge-based recommender systems. Encycl. Libr. Inf. Syst. 2000, 69, 175–186. [Google Scholar]
- Rebelo, M.Â.; Coelho, D.; Pereira, I.; Fernandes, F. A New Cascade-Hybrid Recommender System Approach for the Retail Market. In International Conference on Innovations in Bio-Inspired Computing and Applications; Springer: Cham, Switzerland, 2021; pp. 371–380. [Google Scholar]
- Alshammari, G.; Jorro-Aragoneses, J.L.; Polatidis, N.; Kapetanakis, S.; Pimenidis, E.; Petridis, M. A switching multi-level method for the long tail recommendation problem. J. Intell. Fuzzy Syst. 2019, 37, 7189–7198. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Liu, L.; Zhang, C.; He, J.; Hu, C. Hybrid recommendation algorithm based on latent factor model and PersonalRank. J. Internet Technol. 2018, 19, 919–926. [Google Scholar]
- Gatzioura, A.; Vinagre, J.; Jorge, A.M.; Sanchez-Marre, M. A hybrid recommender system for improving automatic playlist continuation. IEEE Trans. Knowl. Data Eng. 2019, 33, 1819–1830. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, J.; Sun, Z.; Yorke-Smith, N. LibRec: A Java Library for Recommender Systems. In Proceedings of the UMAP Workshops, Dublin, Ireland, 29 June–3 July 2015; Volume 1388. [Google Scholar]
- Bello-Tomás, J.J.; González-Calero, P.A.; Díaz-Agudo, B. Jcolibri: An object-oriented framework for building cbr systems. In Proceedings of the European Conference on Case-Based Reasoning, Madrid, Spain, 30 August–2 September 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 32–46. [Google Scholar]
- Pande, C. Benchmarking Recommender Algorithms for Business Intelligence Consultancy. Master’s Thesis, FHNW University of Applied Sciences and Arts Northwestern Switzerland, Olten, Switzerland, 2019. [Google Scholar]
- Zhang, Y.; Zuo, W.; Shi, Z.; Yue, L.; Liang, S. Social Bayesian Personal Ranking for Missing Data in Implicit Feedback Recommendation. In Proceedings of the International Conference on Knowledge Science, Engineering and Management, Changchun, China, 17–19 August 2018; Springer: Cham, Switzerland, 2018; pp. 299–310. [Google Scholar]
- White, S.; Smyth, P. Algorithms for Estimating Relative Importance in Networks. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; pp. 266–275. [Google Scholar]
- Bergmann, R. On the Use of Taxonomies for Representing Case Features and Local Similarity Measures. In Proceedings of the 6th German Workshop on CBR, Berlin, Germany, 6–8 March 1998; Gierl, L., Lenz, M., Eds.; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Huang, A. Similarity measures for text document clustering. In Proceedings of the Sixth New Zealand Computer Science Research Student Conference (NZCSRSC2008), Christchurch, New Zealand, 14–18 April 2008; Volume 4, pp. 9–56. [Google Scholar]
- Richter, M.M. Introduction. In Case-Based Reasoning Technology SE-1; Lecture Notes in Computer Science; Lenz, M., Burkhard, H.D., Bartsch-Spörl, B., Wess, S., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; Volume 1400, pp. 1–15. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Case Attribute | Local Similarity Measure | Weight |
|---|---|---|
| Industry | Taxonomy | 0.24 |
| Goal | TF-IDF | 0.06 |
| Target Group | Jaccard | 0.1 |
| KPIs and dimensions | TF-IDF | 0.6 |
| Query Verbosity | User-Knn | Item-Knn | Graph-Based | CBR | |||
|---|---|---|---|---|---|---|---|
| Top 1 | Top 2 | Top 3 | Top 5 | ||||
| 0 | - | - | 0.408 | 0.773 | 0.783 | 0.773 | 0.747 |
| 5 | 0.487 | 0.420 | 0.566 | 0.777 | 0.805 | 0.774 | 0.714 |
| 10 | 0.497 | 0.416 | 0.646 | 0.785 | 0.805 | 0.772 | 0.719 |
| 15 | 0.498 | 0.413 | 0.689 | 0.787 | 0.807 | 0.766 | 0.709 |
| 20 | 0.501 | 0.411 | 0.713 | 0.787 | 0.807 | 0.776 | 0.713 |
| 30 | 0.498 | 0.411 | 0.733 | 0.787 | 0.812 | 0.780 | 0.716 |
| 40 | 0.499 | 0.411 | 0.742 | 0.787 | 0.812 | 0.783 | 0.719 |
| 100 | 0.499 | 0.409 | 0.746 | 0.787 | 0.812 | 0.781 | 0.718 |
| Query Size | Graph- | CBR | Hybrid | Hybrid | Hybrid | Hybrid |
|---|---|---|---|---|---|---|
| (Verbosity) | Based | Top-2 Cases | = 0.1 | = 0.3 | = 0.5 | = 0.9 |
| 0 | 0.408 | 0.783 | 0.801 | 0.801 | 0.801 | 0.801 |
| 5 | 0.566 | 0.805 | 0.836 | 0.835 | 0.836 | 0.835 |
| 10 | 0.646 | 0.805 | 0.843 | 0.845 | 0.839 | 0.840 |
| 15 | 0.689 | 0.807 | 0.804 | 0.856 | 0.849 | 0.849 |
| 20 | 0.713 | 0.807 | 0.817 | 0.862 | 0.853 | 0.851 |
| 30 | 0.733 | 0.812 | 0.821 | 0.864 | 0.856 | 0.852 |
| 40 | 0.742 | 0.812 | 0.825 | 0.866 | 0.858 | 0.854 |
| 100 | 0.746 | 0.812 | 0.827 | 0.866 | 0.858 | 0.854 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pande, C.; Witschel, H.F.; Martin, A. New Hybrid Techniques for Business Recommender Systems. Appl. Sci. 2022, 12, 4804. https://doi.org/10.3390/app12104804
Pande C, Witschel HF, Martin A. New Hybrid Techniques for Business Recommender Systems. Applied Sciences. 2022; 12(10):4804. https://doi.org/10.3390/app12104804
Chicago/Turabian StylePande, Charuta, Hans Friedrich Witschel, and Andreas Martin. 2022. "New Hybrid Techniques for Business Recommender Systems" Applied Sciences 12, no. 10: 4804. https://doi.org/10.3390/app12104804
APA StylePande, C., Witschel, H. F., & Martin, A. (2022). New Hybrid Techniques for Business Recommender Systems. Applied Sciences, 12(10), 4804. https://doi.org/10.3390/app12104804