1. Introduction
The expectation of a convenient daily life, an aging society, child care in two-job families, and the shortage of nursing staff and other issues have created a large demand for intelligent service robots. Due to the need to directly provide corresponding services for users, the human–computer interaction of intelligent service robots needs to be comprehensive and natural. Service robots need to recognize users’ emotions and respond in many application scenarios which are defined as emotional interaction.
Facial expression is an important way for humans to express emotions and accounts for 55% of the information in communication [
1]. Facial expression recognition is widely used in medical [
2], business, teaching [
3], criminal investigation, and other fields to analyze people’s emotional states by capturing facial expressions.Therefore, the emotional interaction intelligent robot based on expression recognition has become a research hotspot.
Expression recognition has been gradually studied by many subjects such as computer science, psychology, cognitive science, neural computing, and so on since the 1990s. Two core steps of expression recognition are feature extraction and expression classification. Feature recognition is particularly important in traditional methods. Global feature extraction methods and local feature extraction methods represented by geometric and texture feature extraction have been proposed. Machine learning is first applied to the expression classification after traditional expression feature extraction when developed, including SVM [
4], KNN [
5], and so on. However, the usage of complex algorithms and artificial feature extraction has the disadvantages of incomplete feature definition, inaccurate feature extraction, and being too cumbersome and time-consuming.
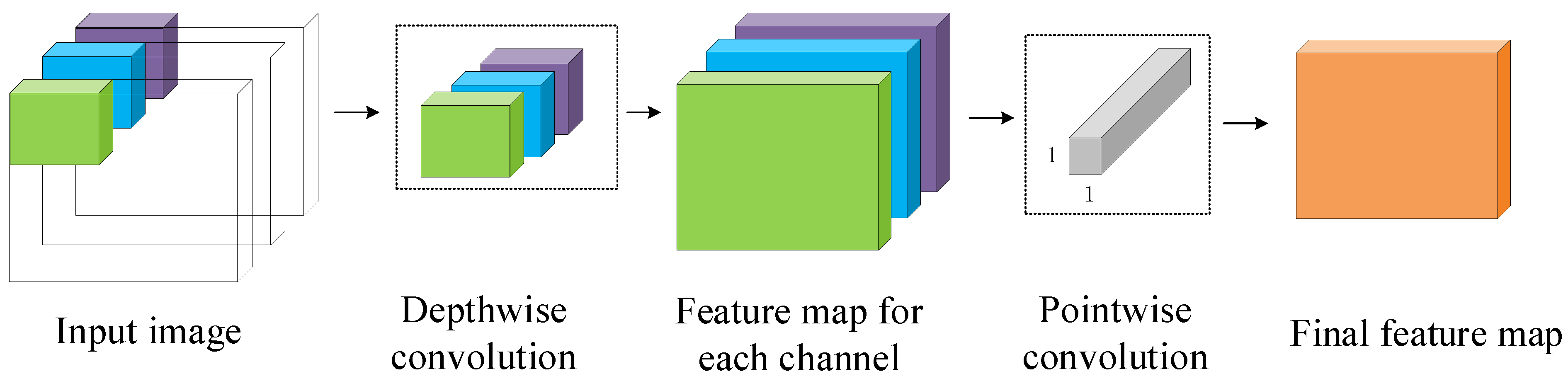
Many recognition tasks have made revolutionary leaps with the development of deep learning. The approach to feature extraction becomes extremely different with a deep artificial neural network. Instead of using complex algorithms or even manual feature extraction for pattern recognition, a large amount of data is “fed” into the black box of the convolutional neural network, and feature extraction and expression classification are carried out at the same time. The extracted features include color, texture, edge, and other features that human beings can understand, as well as a large number of features that human beings cannot even understand and explain directly. The weights of extracted features are updated iteratively through the back-propagation algorithm and optimizer, and an excellent effect is achieved.
A type of deep artificial neural network named convolutional neural network (CNN) originated from Hubel and Wiesel [
6], who put forward the concept of “receptive field” in the study of cat visual structure and functional mechanism. CNN has been proved to have great advantages in image recognition and classification and has gradually become the mainstream method of expression recognition. In the study, most researchers improve the emotion recognition accuracy by increasing the size and depth when designing convolution network such as AlexNet [
7], VGG [
8], GoogLeNet [
9], ResNet [
10], and DenseNet [
11]. However, this strategy of increasing the model complexity greatly increases the amount of calculation and puts forward higher requirements for hardware in the application so that the algorithms have poor portability for platform equipment with limited computing power, which is not conducive to real-time emotional interaction. Some current methods to make the neural network lightweight, including quantization, pruning, low-rank decomposition, teacher–student network, and lightweight network, design are used by researchers to solve the above problems. Some lightweight models for the domain of image recognition have been proposed through the study of efficient networks and lightweight methods at present [
12]. A lightweight facial expression recognition system is characterized by small memory consumption and strong portability. It is generally constructed by a small-scale convolutional neural network model generated from the simplified deep CNN using lightweight methods. However, the lightweight model structure will lose part of the learning ability. The recognition model trained on specific datasets has a gap in performance from that on the verification dataset in the face of complex and diverse real environment samples, thus the generalization performance is difficult to guarantee. Such systems have poor performance in real interactive applications.
The seven recognized categories of expressions include happiness, surprise, sadness, fear, disgust, and anger [
13]. Facial expression recognition has strong data-driven properties as a kind of fine-grained classification and the dataset samples at the input of the network also have an important influence on the performance, especially the generalization performance of the model in addition to the network structure and training algorithm as a consequence. The approach to improving the generalization performance is to increase the sample size, but the cost is high. In addition, it is liable to produce many incorrectly labeled samples that are difficult to identify and evaluate, namely, noise samples in the process of labeling. In this regard, a Self-Cure Network (SCN) is proposed to suppress the uncertainty in expression datasets because of the belief that noise samples may lead to insufficient learning of effective features [
14], whereas SCN is aimed at large-scale expression recognition. On the one hand, it increases the weight module fully connected with the samples, changes the training process, and greatly increases the amount of calculation. On the other hand, it depends on the self-learning of the model. To optimize through the noise adjustment of datasets is a feasible solution, and there is less relevant research at present. A Confidence Learning (CL) algorithm [
15] for the problem of noise samples is proposed, and certain noise detection effects on datasets such as ImageNet are achieved. A Confidence Learning (CL) algorithm for the problem of noise samples is proposed in Reference [
15], which achieved certain noise detection effects on datasets such as ImageNet. Therefore, the confidence learning algorithm for noise sample recognition and cleaning of datasets can be feasible and effective.
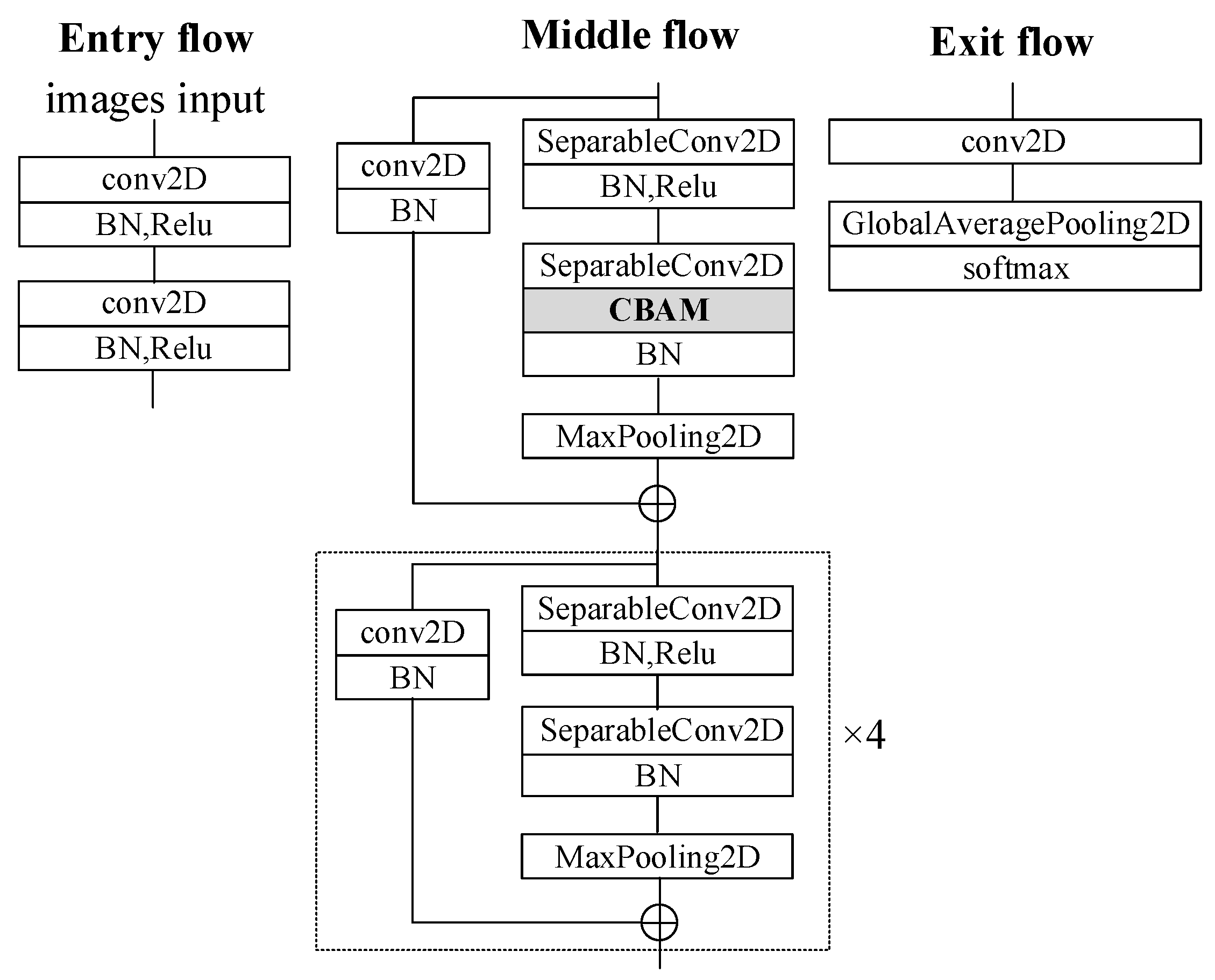
This paper builds a lightweight facial expression recognition system based on a network structure combining deep separation convolution and attention mechanism, and a confidence learning application method is proposed to detect and adjust the noise sample of the training dataset, in which appropriate noise samples are reserved and the robustness of the model is improved. The purpose of this approach is to generalize the suitable model chosen on specific training datasets to the real environment and improve the performance of robot emotional interaction in engineering applications. Specifically, this paper’s main contributions lie in the following:
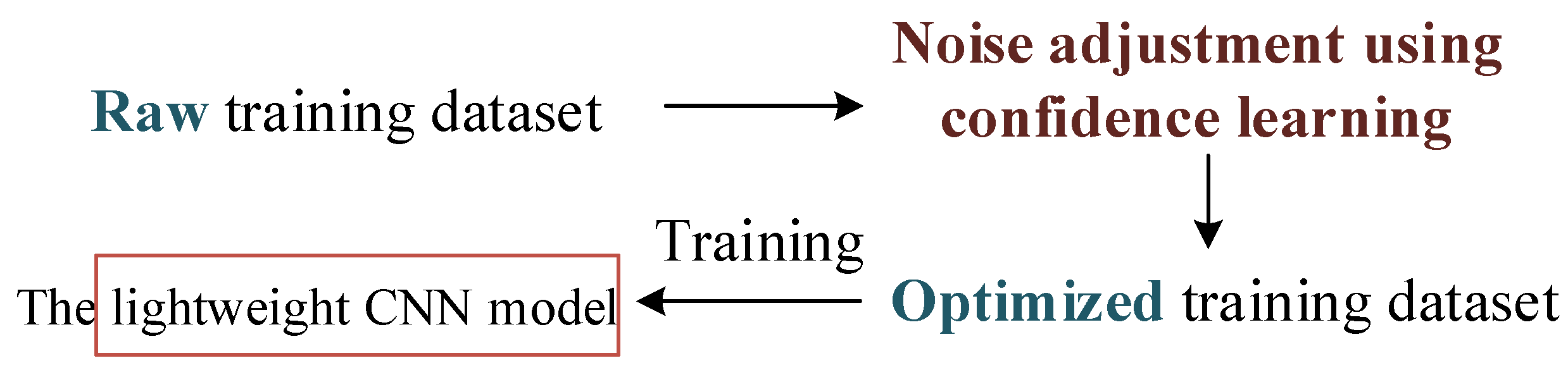
In the expression recognition of human–computer natural emotional interactions, we find that the actual lightweight recognition system has poor recognition effect on the real environment, insufficient recognition rate, and interaction stability no matter how excellent the network recognizing accuracy is on a certain dataset in the theoretical simulation. We use a confidence learning algorithm to adjust the dataset to improve the generalization ability in the recognition environment in reality.
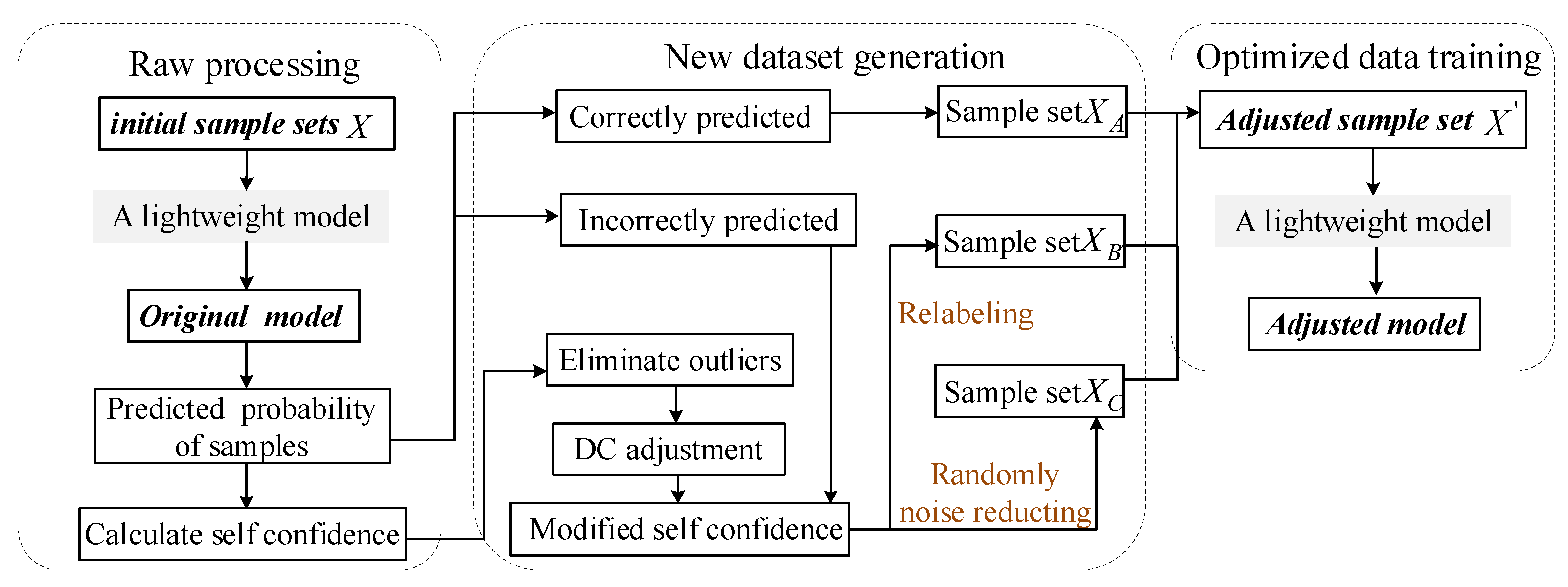
In the confidence learning algorithm, we improve the reliability of noise detection by modifying the self-confidence.
In the application of confidence learning, we propose to transfer the concept of hyper-parameters in machine learning to confidence learning and set the hyper-parameters according to the related problems affecting the noise adjustment effect. By manually adjusting the learning effect, the portability and flexibility of this method are improved.
A lightweight expression recognition system suitable for human–computer emotional interaction is established, and the recognition effect is significantly improved through application optimization.
This study provides an optimization idea for other lightweight human–computer interaction systems based on deep neural networks.
This paper introduces this strategy in five parts.
Section 2 reviews the works related to the research background, algorithms, and engineering applications of this paper.
Section 3 introduces the algorithm, application ideas, and methods of confidence learning, and briefly describes the model construction and training of the lightweight expression recognition system.
Section 4 verifies the constructed system and the proposed scheme by three designed experiments. The experiments are carried out, and the results are analyzed and discussed.
Section 5 succinctly summarizes the work of this paper and analyzes the shortcomings and further research improvement. The proposed method in this paper can play an important role in improving the emotional interaction experience of intelligent robots.
5. Conclusions
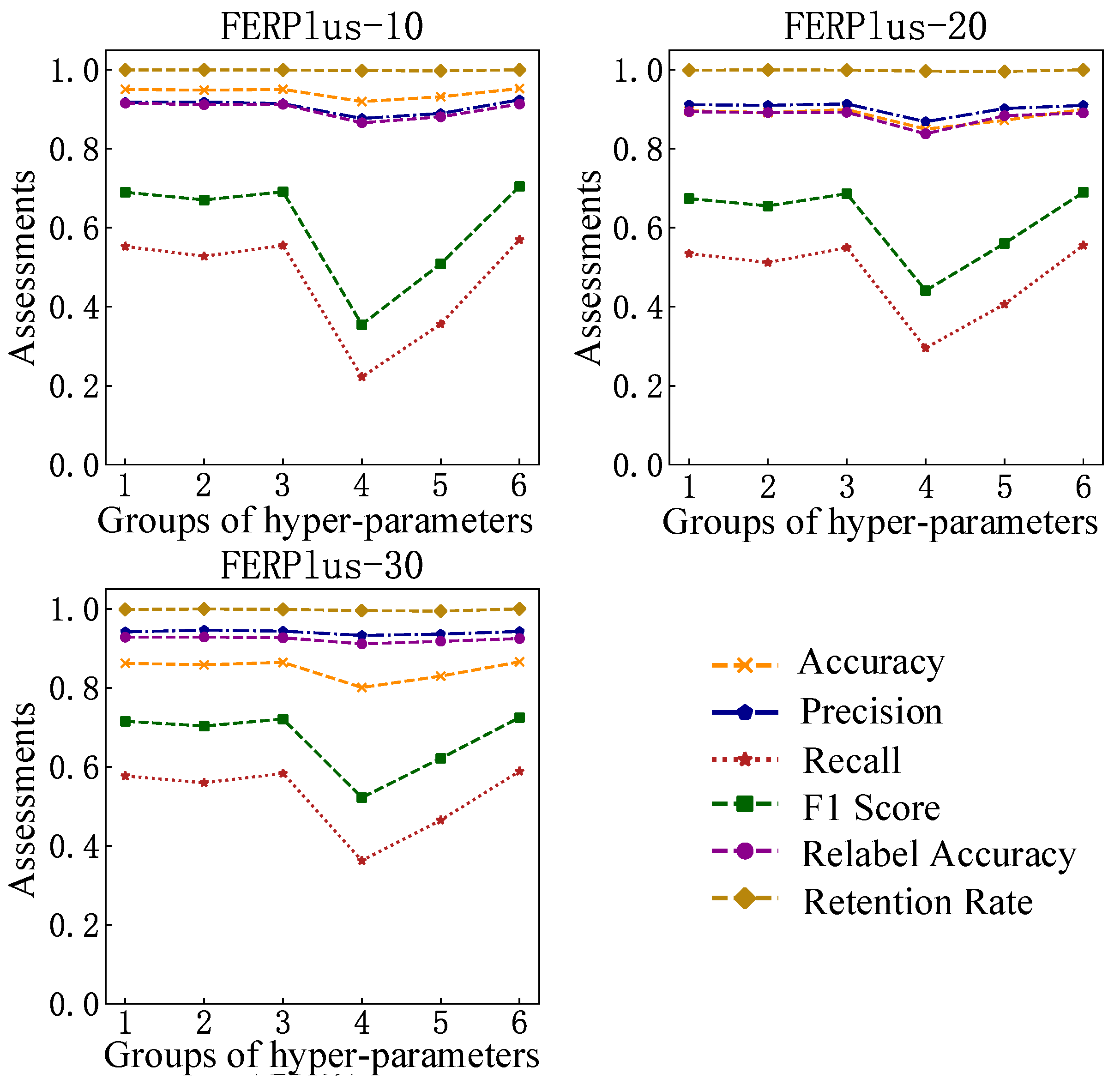
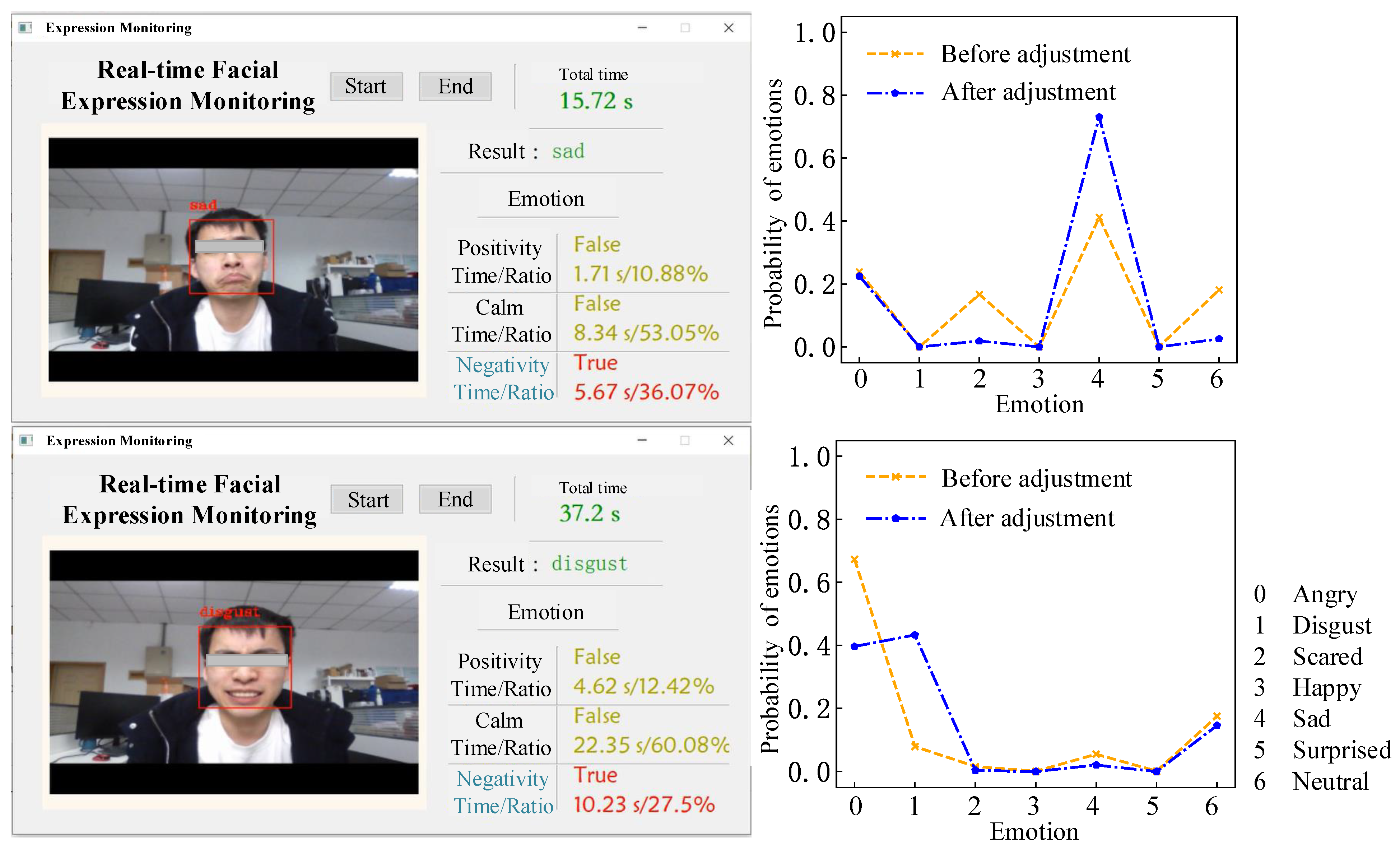
This paper puts forward the problems of low recognition accuracy and poor generalization performance in the actual interaction and improves it from the perspective of a training dataset aiming at a lightweight expression recognition system in the emotional interaction scene of an intelligent robot. In order to reduce the dependence of the lightweight model on the specific training set, the application of a confidence learning algorithm is proposed to optimize the training set by noise sample detection. The relabeling method is applied at the same time. The hyper-parameters are innovatively introduced to manually adjust the noise detection range to match the application requirements and obtain better system robustness.
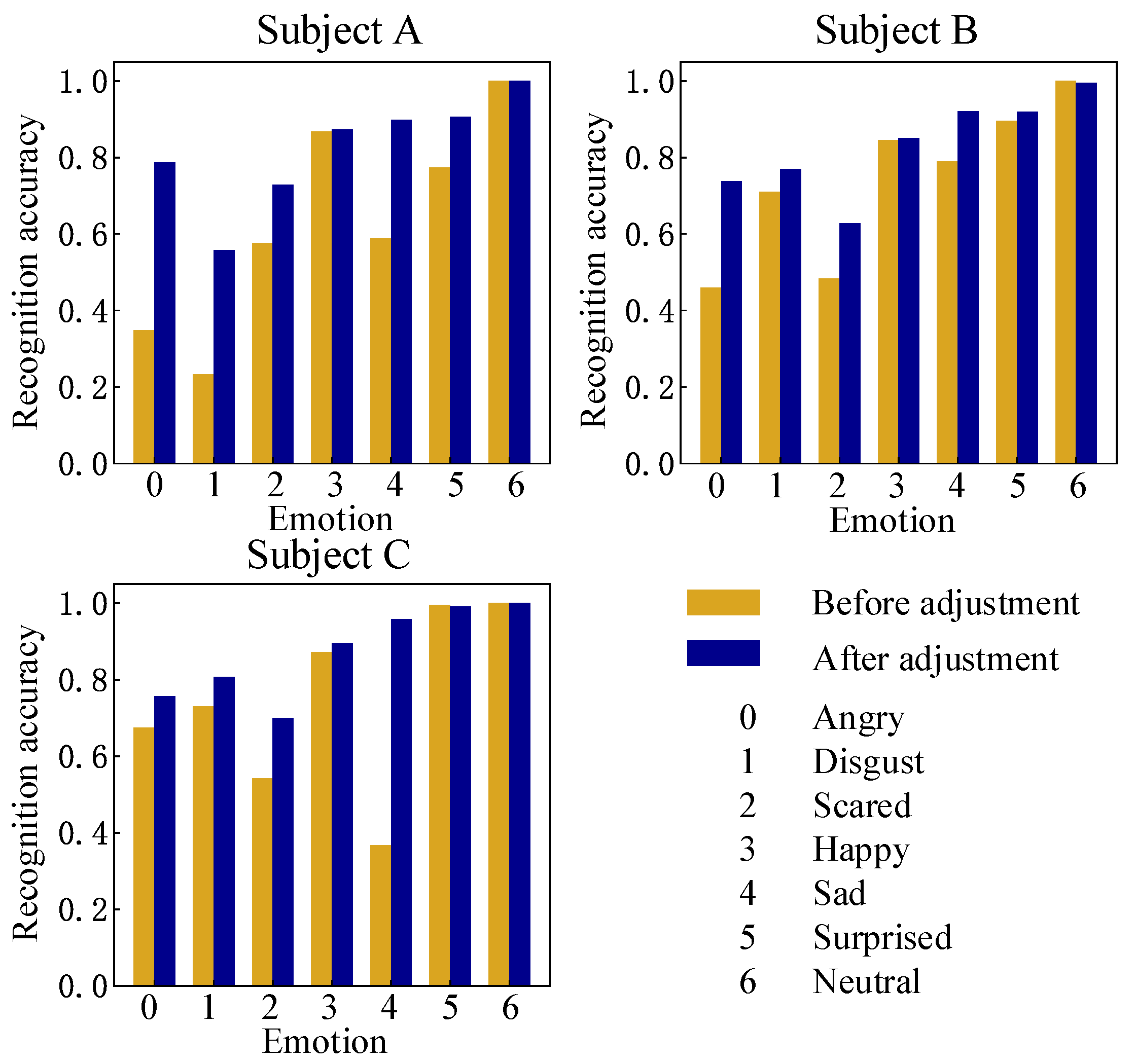
On the theoretical side, we add uncertainty to the confidence learning algorithm so that its learning effect can be adjusted by some preset hyper-parameters as the mode of machine learning, which increases flexibility and creates more possibilities for its better and wider application. However, the algorithm has not been accurately verified for other machine learning algorithms or deep learning networks and will be further studied in the future. On the practical side, a lightweight expression recognition system is established. We analyzed and found the insufficient recognition generalization performance caused by dataset dependence, and introduced confidence learning in an innovative way for noise detection and adjustment so that we realized a great improvement in the recognition effect in the actual system recognition, which is of great significance in the engineering application of human–computer emotional interaction. However, the generalizability of the application effect, such as the effect on special groups such as the elderly, children, and patients with facial diseases, needs to be further studied. In addition, frame-by-frame static expression recognition is proven to be effective after optimization in real-time recognition, but the recognition stability of the system is insufficient. More dynamic recognition methods will be further discussed in the future.
This paper further makes full use of the specific training set to optimize the model parameters without increasing the complexity of the model, changing the training method, and expanding the new dataset in other publications. It achieves good results in an actual lightweight expression recognition system. In the follow-up, the improvement of the lightweight model structure and the selection and optimization method of hyper-parameters will be further studied, and based on this, a robot emotional interaction system with a better experience will be built.



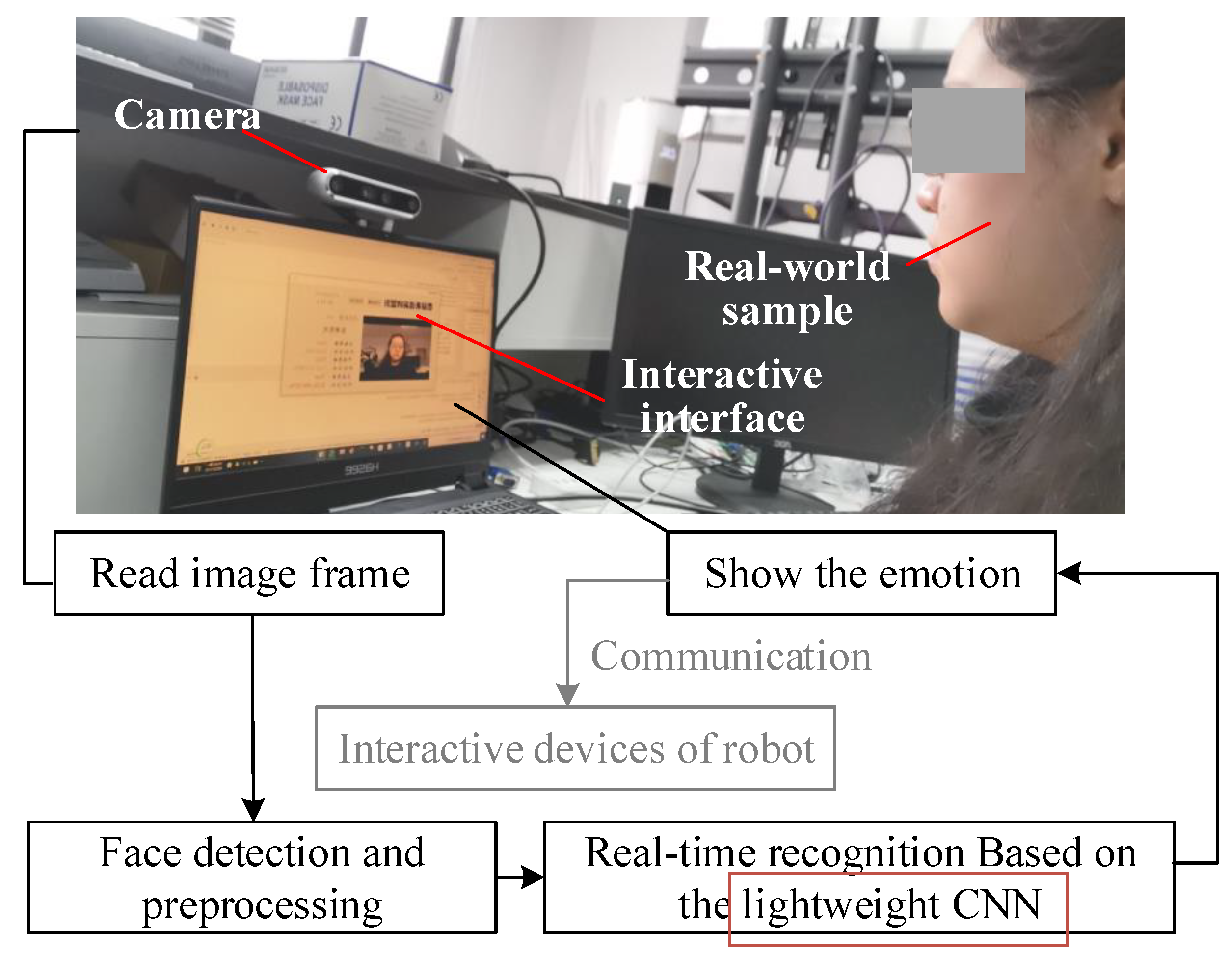








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}