1. Introduction
Human beings are able to recognize known voices in a very short time [
1]. The voice of an individual is unique, which is due mainly to their developed and physical features. There are physical variations amongst human beings, due to the unique voice-producing organs and the sizes and shapes of their articulators. The larynx (most importantly the vocal folds) is voice-producing, and the rest, including the nose, are mostly responsible for resonances, i.e., articulation [
2]. In addition to anatomical features, speech rate, vocabulary, accent, and other personal behaviors taking shape over time are also responsible for the different speech patterns found in individuals These features are exploited by state-of-the-art speaker recognition systems in a way that makes it possible to attain significant recognition accuracy [
3]. There are two broad categories of speaker recognition (SR): speaker identification (SI), and speaker verification (SV) [
4]. The process of speaker identification involves automatic detection of the speaking person from a set of specific speakers. Conversely, speaker verification involves automatic detection of whether the speaker is a specific person or not. Speaker identification can be used for various purposes. For instance, applications such as credit card security, confidential data safety, client identity and verification are some examples of broad speaker recognition applications. The functioning of speaker identification is either text-dependent [
5,
6,
7] or text-independent [
8,
9,
10,
11,
12].
Many circumstances can cause stress, including noisy backgrounds, emergencies such as aircraft pilot communications, high workloads, physical environmental factors, and multitasking [
13]. There are several applications of speech recognition under stressful conditions in real life. This includes emergency call centers, telephone banking and military voice communications applications.
An emotional talking environment occurs when the speaker speaks his or her language under the influence of emotional conditions such as anger, happiness, and sadness. Emotion recognition applications are found in telecommunications, human–robot interfaces, and intelligent call centers. Emotion recognition can be used in intelligent language education systems to sense and adapt to student emotions when they reach a state of boredom during a tutoring session [
14,
15].
Speaker identification in emotional and stressful conditions is challenging because of the mismatch between training and testing. In the training stage, the models are trained using neutral conditions; however, in the testing phase, models are tested using neutral, as well as emotional and stressful, conditions. This why models perform better when they are tested under neutral conditions.
Speaker identification also has various applications in civil cases and the media. This includes applications in recorded discussions and phone calls made to radio stations or other state and local departments and insurance companies [
16]. It is important that the speaker be identified in such cases, since some people tend to disguise their voices to imitate famous people in the media, which may affect their reputation.
The main aim of this research was to further enhance speaker identification performance in stressful talking environments using a novel RBFNN-CNN model. In this research, we evaluated our approach with two distinct speech databases: a local Arabic Emirati-accent dataset and a global English Speech Under Simulated and Actual Stress (SUSAS) corpus. Our speech identification models selected the finest speech signal representation by feature extraction such as Mel-frequency cepstral coefficients (MFCCs), after having been processed. We evaluated our proposed model against different classical classifiers such as support vector machine (SVM), multilayer perceptron (MLP), k-nearest neighbors algorithm (KNN), and different deep learning models such as convolutional neural network (CNN) and recurrent neural network (RNN). Results show that the proposed model outperforms all other models.
The remaining sections are organized as follows:
Section 2 presents related work.
Section 3 describes the datasets used in this research, while the model architecture and methodology are explained in
Section 4. The results of the models are presented in
Section 5.
Section 6 concludes the paper.
2. Related Work
The performance of speaker identification is exceptionally high in a neutral talking environment compared to other talking environments such as emotional and stressful [
16,
17,
18]. Conversely, its performance is lower in the case of a stressful talking environment [
19,
20,
21]. A neutral talking environment is the kind of talking environment whereby the speaker utters the speech without any stressful or emotional talking condition. On the other hand, a stressful talking environment is different from neutral talking conditions in the sense that the speakers deliver their speech under stressful talking conditions, such as shouting or speaking loudly, and quickly.
The authors in [
19] investigated “talker-stress-induced intra-word variability”, and the algorithm meant to counter these systematic changes, based on “hidden Markov models (HMMs)” as classifiers that had been trained with the help of speech indications under different types of talking conditions. By using the hypothesis-driven compensation technique, the error rate was reduced from 13.9% to 6.2%.
Raja and Dandapat [
20] focused on studying speaker recognition in stressed conditions with the aim of improving the decline in performance usually observed in these conditions. They made use of four types of stressed conditions of the SUSAS database [
22,
23], including neutral, angry, Lombard, and question conditions. The study revealed that speech uttered by speakers under angry conditions exhibited the lowest speaker identification performance [
20]. The average speaker identification rate using the SUSAS database (stressed condition) was about 57%.
Zhang and Hansen [
24] examined five different vocal modes, including whispered, soft, neutral, loud, and shouted, with the aim of studying various aspects of speech. They intended to identify distinguishing features of speech modes. The average accuracy rate was about 96%. Chatzis [
25] tried to learn through the use of data with sequential dynamics and put forward infinite-order HMM models that were based on the assumption that first-order Markovian dependencies existed among the successive label values denoted by
y. The models that were designed were better than other techniques, for a couple of reasons. First, extended and complex temporal dependencies can be captured by these models. Second, margin maximization paradigms are employed for performing model training in these models, ultimately leading to a convex optimization design [
25]. The highest average accuracy obtained was 71.68% for the iMMS model.
In another work, Prasetio et al. (2020) [
26] proposed a method using the deep time-delay Markov network (DTMN) to predict emotions by studying earlier emotional states. The novel approach has been evaluated on the English SUSAS database. They concluded in that study that the proposed DTMN outperformed the baseline systems. TDNN-4 was the optimal temporal context for predicting the emotional state of 8.31% PER.
There are very few research studies that focus on the spoken Arabic language as speech [
27,
28]. This is mainly because Arabic speech databases are quite limited with reference to the speaker recognition area. There are four main regional dialects of the Arabic language. They include “Egyptian, Levantine (e.g., Jordan), North African (e.g., Tunisian), and Gulf Arabic (e.g., Emirati)” [
29].
There is currently no published work dealing with speaker identification in stressful talking environments using the RBFNN-CNN model. In this paper, a significant contribution has been made for enhancing speaker identification within stressful talking environments. For this purpose, two speech databases were applied for model testing of speaker identification within stressful talking environments. “Speech Under Simulated and Actual Stress (SUSAS)” is the first database that has been recorded using stressful and neutral talking [
22]. The “Emirati speech database” [
30] is the second database, in which 30 Emirati speakers (15 males and 15 females) were used as respondents and subjected to neutral, shouted, slow, loud, soft and fast talking conditions.
Results based on different classifiers and compensators as reported in our previous results, Refs. [
31,
32,
33] reported speaker identification performance under shouted/stressful talking conditions using the Emirati accent dataset. Their reported speaker identification performance in shouted/stressful talking conditions was 58.6%, 61.1%, 65.0%, 68%, 74.6%, 75%, 78.4%, 81.7%, 78.7%, 83.4%, and 85.8% based, respectively, on “First-Order Hidden Markov Models (HMM1s), Second-Order Hidden Markov Models (HMM2s), Third-Order Hidden Markov Models (HMM3s), Second-Order Circular Hidden Markov Models (CHMM2s), First-Order Left-to-Right Suprasegmental Hidden Markov Models (LTRSPHMM1s), Suprasegmental Hidden Markov Models (SPHMMs), Second-Order Left-to-Right Suprasegmental Hidden Markov Models (LTRSPHMM2s), Third-Order Left-to-Right Suprasegmental Hidden Markov Models (LTRSPHMM3s), First-Order Circular Suprasegmental Hidden Markov Models (CSPHMM1s), Second-Order Circular Suprasegmental Hidden Markov Models (CSPHMM2s), and third-order circular suprasegmental hidden Markov models (CSPHMM3s)”.
Table 1 shows more comparison with previous studies.
The main contributions of this study are as follows:
To the best of our knowledge, this is the first work that uses and evaluates an RBFNN-CNN model for speaker identification under stressful/emotional conditions.
We conduct extensive comparisons between traditional classifiers and deep learning models to predict the model that yields the highest performance.
We showed that the proposed RBFNN-CNN model outperforms other models.
4. Model Architecture
Generally, the speaker identification process may be categorized into two crucial parts: feature extraction and classification.
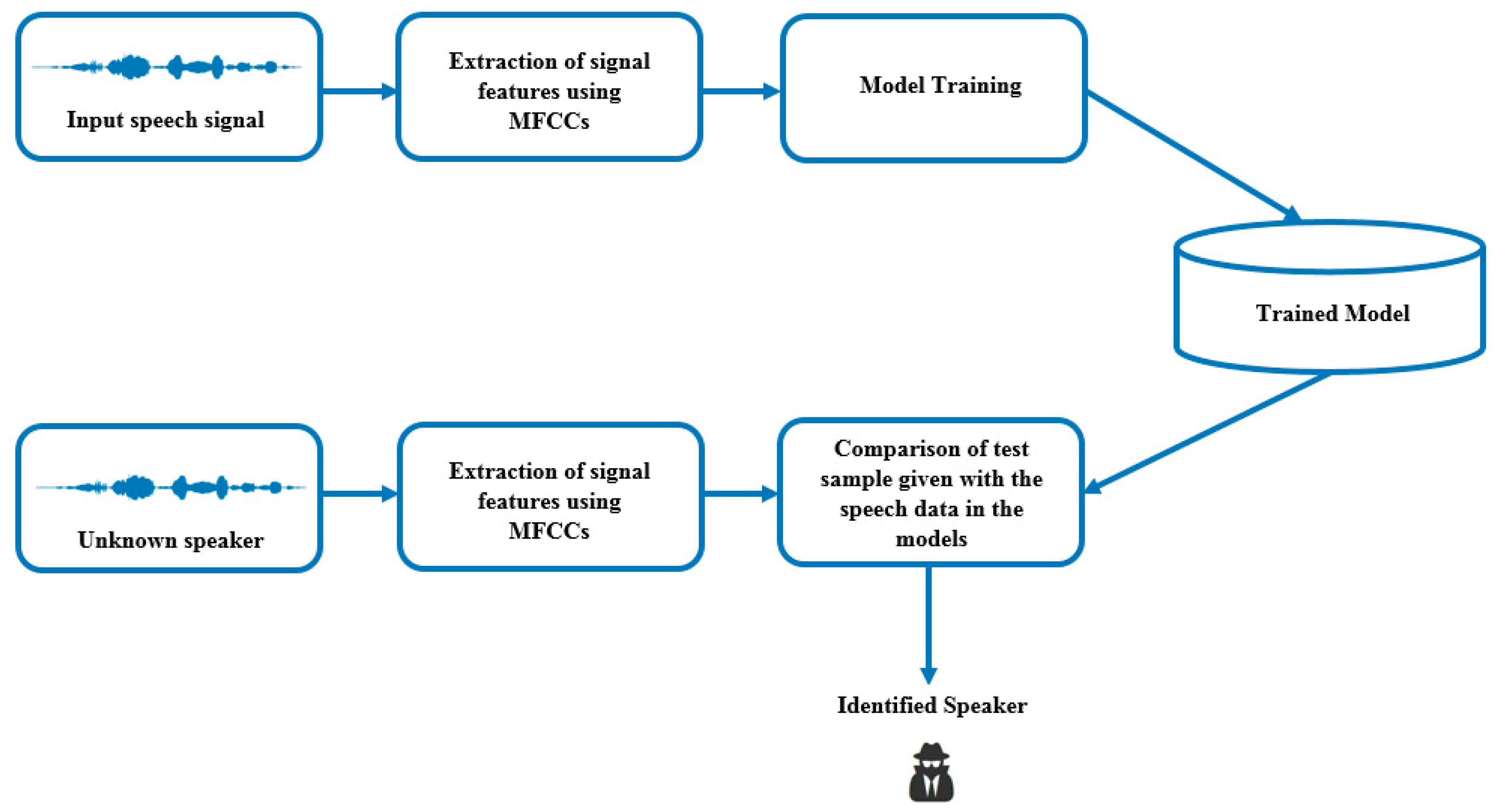
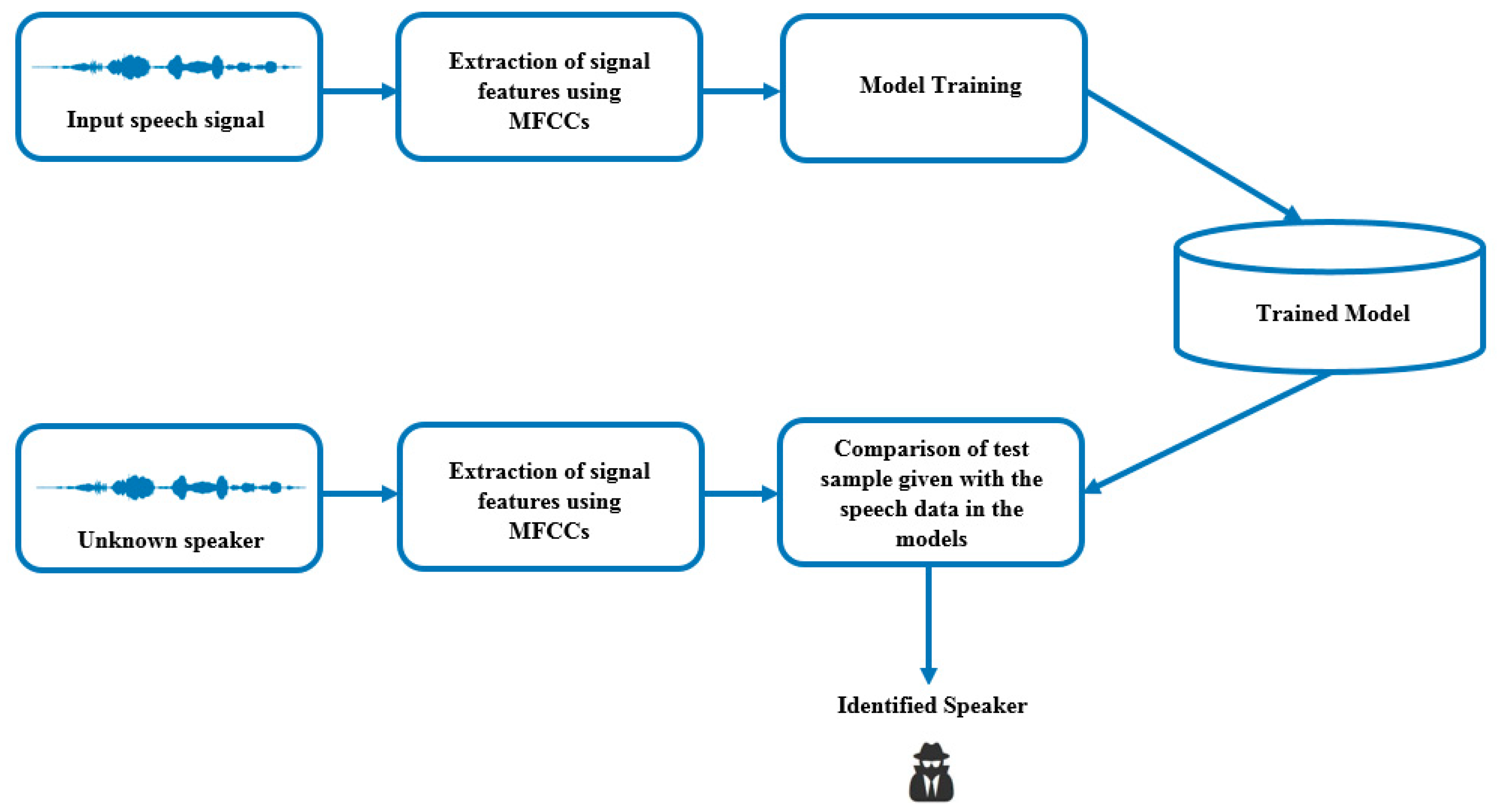
Figure 1 shows the speaker identification process. Speakers may be distinguished on the basis of some exceptional characteristics that are typical to a particular speaker by using the extracted features. Feature extraction is an important part of speaker identification; hence, features call for additional fine-tuning and use of appropriate approaches to come up with the ultimate identity of a speaker. Individual speaker models are formulated for each and every speaker by making use of these feature sets. All of the developed speaker models are stored. The features of the speech uttered by the unidentified speaker are extracted and compared with the developed speaker models using a speaker identification classifier, which checks if the features of the unknown speaker match with those in the developed speaker models. This leads to the identification of the unknown speaker. The speaker identification process explained in the current study uses a machine learning approach, whereby speakers are identified by considering the features extracted from the speaker’s recorded speech. The features out of Mel-frequency cepstrum coefficients (MFCC) were used for classifier training. A 96-dimension feature of MFCCs was used to determine the observation vectors in all deep learning and classical techniques. A “continuous mixture observation density” was selected in each classifier with six states. MFCC determines the change in the straight cosine in the range of log control related to the direct Mel recurrence size. The human voice can be represented with high precision in Mel recurrence, due to uniform or similar dispersion of recurrence groups therein. The models are fed by an array of MFCCs of each time frame. Closed-set speaker identification is presented as follows: The words spoken by the given speaker are recorded, and the recording is compared with the developed speaker models (a finite set). The developed model that shows the most resemblance with the recording is considered. The recorded speech signals of the given speaker are used for extraction of MFCC. Overall, the MFCC technique will generate features from the inserted audio signal samples that are used as input for the speech recognition model. This is followed by classifier training with these features. The feature extraction process is also followed for the new speech signals we want to classify. The speaker with the closest resemblance is predicted by the trained classifiers.
Figure 1 depicts the speaker identification approach employed in the current study.
4.1. RBFNN-CNN Model
RBFNN is a feedforward neural network model that is relatively fast in comparison with other machine learning models such as multilayer perceptron [
38].
Figure 2 shows how the RBFNN layers are comprised [
39], where the input vector is represented by the first layer. The second layer, which is also called the hidden layer, is where the RBFs of all input data are stored. For example, the node RBF1 is the vector with the length of n where the RBF of X ([x
1, x
2, …, x
n]) and C1 (first centroid vector) is described. The RBF1 vector is a measure of how the distance between the first centroid and data X is related to other vectors. Eventually, through utilizing the theory described above, the resulting prediction of the unknown point’s class can be made by calculating the RBF of an unidentified data point x in terms of all centroids. Additionally, we calculate the dot product of RBF and W (the weight) and choose the index with the highest value. RBFNN models use a Gaussian function as an activation function in the hidden layer. In this article, the implementation of SUSAS and Arabic Emirati-accent dataset classifications are described.
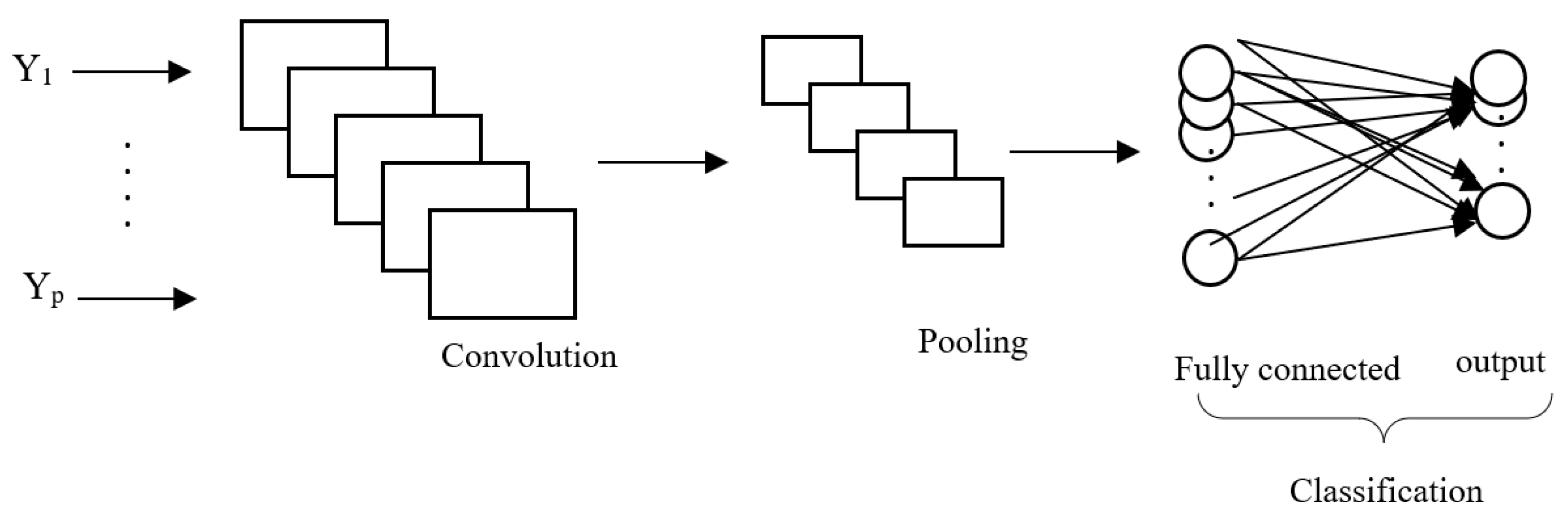
The RBFNN is followed by CNN, in which the final model is the result of cascading RBFNN with CNN (RBFNN-CNN). In the CNN model design, five hidden layers have been used due to the significant outcome in accuracy. The number of input neurons is 957, which represent the features, while the number of output neurons is 50, which represent the classes after categorizing the testing labels, knowing that the output layer is known since the dataset is labeled.
Figure 3 illustrates the block diagram of the CNN model that is cascaded with RBFNN, where the output of RBFNN is the input for the CNN model. The block diagram of the RBFNN-CNN model is shown in
Figure 4. The activation function that has been applied in this work is “Softmax”. The standard (unit) Softmax function
{\displaystyle \sigma:\mathbb {R} ^{K}\to \mathbb {R} ^{K}} is characterized by the following equation [
40].
The exponential function is applied to all input vector features and then normalizes the values. At first, audio signals are inserted into the model with zero manipulations. The inserted audios are the input for the next step, named “preprocessing step”, that is applied to each audio. In addition, this step involves the labeling process for each audio file. The labeling process is where the naming of each sound file is accomplished, e.g., the first sound corresponds to speaker X, etc.
The output of the preprocessing step includes all of the files along with their labels. This output is the input to the feature extraction process, where each audio file contains special characteristics recognized by the presented MFCC feature extraction method. The output of the feature extraction method entails the essential features as a matrix having feature vectors for each audio. The output encounters all of the matrices that should be used in the classification. Before applying the classification method, we first split the data into training and testing datasets. The next step was to start classifying our data using the proposed model, RBFNN-CNN. RBFNN addresses the theoretical gap in the original RBF and solves the ambiguity regarding the class of the data. Inside the RBFNN, in the hidden layers, each node represents a vector that is stored with its centroid vector. Each node vector represents the distance between first centroid and data X, which are associated with one another. The output of RBFNN is an array of features that contain weights that best estimate the linear relationship among RBFs and the output. This is considered as the input to CNN, where the “Softmax” activation layer was used to normalize it into a probability distribution containing K probabilities, ending up with the identified speaker.
RBFNN is an unconventional machine learning method that is also incredibly fast, effective, and straightforward. RBFNN models the data using smooth transitioning circular shapes rather than harsh cut-off circles, creating a pattern that best approximates the position of the clusters (features of speaker x). It also provides information on the prediction confidence rate, which is the core use of RBFNN as a deep feature match/robust for stressed conditions. The color intensity gradually lowers as you move away from the cluster centroids. An exponential function with a negative power of distance can be utilized to achieve such a smooth transition. We can regulate how fast the function decays by multiplying the distance with a scalar coefficient “Beta.” As a result, a larger Beta indicates a more rapid drop. RBFNN is, in general, one of the most powerful models for classification and regression applications. Using a large number of RBF curves, RBF nets can learn to approximate the underlying patterns. In comparison to MLP structured networks, the use of a statistical equation for the optimization process makes the method more conducive and faster.
4.2. Traditional Classifier Experiments
In this section, we discuss the traditional machine learning algorithms that were evaluated for speaker identification using the Emirati speech database and the global English SUSAS database in stressful talking environments. In this study, we used the KNN, SVM and MLP classifiers. Within each model, there is one classifier, where 80% of utterance for the individual speaker has been used for training. Testing and evaluation include 20% of utterances.
4.2.1. Support Vector Machines (SVM)
A multi-class support vector machine (SVM) classifier was trained by applying the linear function. As the SVM is considered to be simple as well as competent for machine learning algorithm computation, it was applied for pattern recognition and classification issues. Since the training data were limited, the classification performance was quite efficient when compared to other classifiers. Hence, in the current research, the speech data were classified using the support vector machine, and the following parameters were used.
4.2.2. Multilayer Perceptron (MLP)
With the help of the MLP, it was possible to minimize the system’s expected and real output differences. For the current model, the MLP topology design included the following parameters:
activation = ‘tanh’
hidden_layer_sizes = 100
activation = ‘relu’, solver = ‘adam’
validation_fraction = 0.1
learning_rate_init = 0.001
max_iter = 200
The hyperbolic tangent activation function was applied for all hidden layer neurons. For the output layer neurons, the linear ones were applied.
4.2.3. The K-Nearest Neighbors Algorithm (KNN)
KNN is the simplest classification algorithm, as it assumes that instances that are close to the instance space will have similar class values. Currently, the KNN classifier is usually adopted by researchers, since it is simple, refined, and direct. If new sample data x arrive, KNN will search for the k neighbors nearest to the unlabeled data initiating from the training space with reference to some distance measure. In the current research, the following parameters were applied:
KNN: n_neighbors = 25
weights = ‘uniform’
algorithm = ‘auto’
max_iter = 200
4.3. Deep Learning Experiments
In this research, we implemented CNN and RNN models. There are many researchers [
41,
42] who have experimented using a combination of RNN and CNN. They have clearly indicated that as compared to the machine learning models, this mixture is much more effective.
4.3.1. Convolutional Neural Network (CNN)
In this paper, the CNN model was developed through the integration of five convolutional layers, each followed by a max-pooling layer and a dropout layer. The input of the neural network was a vector of 96 MFCC features. Each of these five CNN layers had 64 filters, with a kernel size of 3 × 3, that were applied at a stride setting of three pixels. We used the RELU activation function instead of the typical sigmoid functions, which improved the efficiency of the training process. The max-pooling layer generates a lower resolution version of the convolution layer; we applied a pool size of 2 × 2. Later, we added a dropout layer, which helped in avoiding overfitting; we set the dropout ratio at 20%. Finally, we added a fully connected layer and a dense layer that had 30 neurons; each represented one speaker in the dataset.
4.3.2. Recurrent Neural Networks (LSTM)
Due to the effectiveness of deep learning techniques, we also adopted an RNN model consisting of three LSTM layers. The input of the neural network was a vector of 96 MFCC features. Each of these three LSTM layers had 64 filters. We added a fully connected layer and a dense layer of 16 nodes that had an activation function, Softmax.
4.3.3. Bidirectional LSTM (BILSTM)
There are three LSTM layers present within the proposed BILSTM model. The neural network input contained a vector of 96 MFCC features. There were 64 filters present within each of the three LSTM layers. A fully connected layer and dense layer were included, which attained an activation function Softmax with 16 nodes.
4.3.4. CNN-BiLSTM
There are four convolutional layers present within the proposed CNN-BILSTM model. The max-pooling layer and a dropout layer follow each of these layers. The neural network input is a vector of 96 MFCC features. There are 64 filters present within the four CNN layers along with a kernel size of 3 × 3 that are included in a 3-pixel stride setting. For the convolution layer, a lower resolution version was generated by the max-pooling layer, and 2 × 2 pool size was applied. A dropout layer, of ratio 20%, was also included later, helping to avoid overfitting. Lastly, an entirely connected layer was included, along with a dense layer that maintained an activation function, Softmax.
4.3.5. Gated Recurrent Units (GRU)
The proposed GRU model consists of three GRU layers. Each of these three GRU layers has 32 filters. We added a fully connected layer and a dense layer that has activation function Softmax with 16 nodes. Finally, we added a dropout layer, which helps in avoiding overfitting; we set the dropout ratio at 20%.
4.3.6. BI-GRU
There are three GRU layers present within the proposed BI-GRU model. Each of these three GRU layers has 32 filters. We added two dropout layers, which help in avoiding overfitting; we set a dropout ratio of 20%. Finally, we added a fully connected layer and two dense layers that have activation functions Softmax and RELU, respectively, with 16 nodes.
4.3.7. Attention-BILSTM BI-GRU
The proposed Attention-BILSTM model consists of three BI-GRU layers. Each of these three GRU layers has 32 filters. We added a dropout layer, which helps in avoiding overfitting; we set a dropout ratio of 30%. Finally, we added a fully connected layer and a dense layer that has activation function Softmax with 16 nodes.
5. Results and Discussion
Experimental Results and Evaluation
The measurement of classifiers in terms of quality involves the use of accuracy, precision, recall, and F1-measure.
One of the most crucial performance measures is accuracy. It is defined as the ratio of observation predicted accurately to all of the observations predicted. It is usually believed that the model with the highest accuracy is best. While the significance of accuracy as an important measure cannot be denied, measuring performance also calls for the availability of symmetric datasets having close or similar values for false positives and false negatives. Hence, a model’s performance evaluation must involve additional parameters. The ratio of the predicted positive observations that are accurate to the overall predicted positive observations is referred to as the precision. High precision is associated with a low false positive rate.
Recall (sensitivity)—Recall refers to the ratio of predicted positive observations that are accurate to the overall observations with respect to actual class-yes. Any value exceeding 0.5 is considered as appropriate. F1 score—Computation of the weighted average of precision and recall yields the F1 score. This implies the inclusion of false positives as well as false negatives in the F1 score. This concept involves more complexity as compared to accuracy; however, F1 outshines accuracy when it comes to usefulness, particularly in the case of irregular class distribution. The higher the similarity of costs of false positives and false negatives, the higher the accuracy will be. We must consider precision as well as recall in the case of high diversity in the cost of false positives and false negatives.
This research employed a novel RBFNN-CNN that was evaluated against multiple machine learning algorithms using the Emirati speech database and global English SUSAS database in stressful talking environments. The stressful talking environments included “neutral, shouted, slow, loud, soft, and fast-talking conditions”.
Table 2 and
Table 3 demonstrate average speaker identification performance in stressful talking conditions using the Emirati and SUSAS datasets, respectively. In
Table 2, the standard deviation is added as one of the measurements. A large standard deviation indicates that the data are dispersed, which is unreliable. However, a low standard deviation indicates that the data are tightly grouped around the mean, which is more reliable. The conducted results show that the standard deviation outcomes were relatively small; thus, the data were reliable.
Results in the above tables show that the proposed RBFNN-CNN outperformed all classical and deep learning models in both Emirati and SUSAS datasets. To prove that the proposed model is significantly better than other models, we conducted a statistical test between the proposed model and other models. We chose the non-parametric Wilcoxon test [
43] because data were not normally distributed. The reported
p-values were less than 0.05, which indicated that the proposed model was statistically significant. On the other hand, based on classical classifiers only, SVM surpassed other classifiers using the Emirati dataset; while MLP was the winning model with the SUSAS dataset. Furthermore, the CNN_BILSTM model proved to be the winning model in both datasets after the proposed RBFNN-CNN model. Based on these results, MLP had better performance as compared to the other classifiers using the SUSAS speech corpus. However, the results attained based on SVM were better than those achieved based on each of the MLP and KNN classifiers using the Emirati-accent dataset. Therefore, we can conclude that there is no rule that states the superiority of a specific classifier over another in any classification problem. Furthermore, the neutral talking environment was noted for the best accuracy followed by slow, soft, fast, loud, and shout, respectively. Based on
Table 1,
Table 2 and
Table 3, it is evident that our proposed model outperformed the models in previous studies.
6. Conclusions
In this paper, we focused on improving speaker identification performance in stressful talking environments by introducing a novel RBFNN-CNN model. The proposed model was compared against shallow and deep learning models using a local Arabic Emirati-accent dataset and a global English Speech Under Simulated and Actual Stress (SUSAS) corpus. MFCCs were used as the extracted features of the database based on classical machine learning algorithms SVM, MLP, and KNN as classifiers, as well as deep learning techniques, such as RBFNN-CNN, CNN, and RNN in stressful talking conditions. Some conclusions can be presented. First, the proposed RBFNN-CNN model outperformed all other models based on both datasets. Second, the results attained based on SVM were better than those achieved based on each of the MLP and KNN classifiers using the Emirati-accent dataset. Third, the MLP had better performance as compared to the other classifiers using the SUSAS speech corpus. Fourth, the CNN_BILSTM classifier came second in terms of performance after the proposed model using both datasets. Furthermore, the proposed model surpassed the models used in studies in related work based on the same datasets.
The main limitation in our study is that we used two different datasets for model evaluation. In the future, we plan to extend the Emirati-accent speech dataset to include more speakers from different emirates and genders.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}