5.1. Labeled Datasets
As we established in
Section 3.1, we use a machine-translation approach to take advantage of the English resources; thus, it is crucial to verify that the documents’ semantic orientation is not affected by the translation process [
51,
52]. In this regard, we perform an initial experiment aiming to evaluate the machine-translation impact for sentiment analysis. For such an experiment, we use the CorpusCine and PaperReviews that review dataset, each dataset since these corpora contain the actual labels. We build two sentiment analysis systems (based on machine learning algorithms) for each corpus. The first uses the documents in their original language (Spanish), while the second employs an English-translated version of such documents. Each document is parametrized by using unigram and bigram-based term frequency-inverse document frequency. We use a five-fold validation scheme, where the performance is assessed in terms of the overall accuracy.
Table 3 shows a comparison of a machine learning-based model for sentiment analysis trained by using both original and translated corpora. From
Table 3, we remark that there are no significant differences between the performance (in terms of overall accuracy) of sentiment analysis systems from Spanish and English-translated corpora. Consequently, we experimentally demonstrate that the sentiment polarity is preserved after the English translation in most cases.
Second, we perform a controlled experiment aiming to verify the capability of our proposal to compute the semantic orientation in the absence of labels. We use the CorpusCine and PaperReviews reviews dataset described previously. We remark that these datasets contain the true semantic orientations; nevertheless, such labels are only used to compute performance metrics.
As we pointed out in
Section 3.2 our approach uses a lexicon-based algorithm (LRSentiA) to generate pseudo-labels that are then used to train a machine learning model. Besides, LRSentiA computes the confidence score for each pseudo-label Equation (
2), where it has been established that there exists a relation between such confidence scores and the prediction accuracy [
14]. Accordingly, we perform a first experiment aiming to confirm previous affirmation experimentally.
Table 4 shows the prediction accuracy compared with the confidence groups defined in Equation (
3).
From
Table 4, it is possible to notice that, for both labeled datasets, there exists a significant relationship between the confidence scores and the prediction accuracy, the Very-high confidence group is related to the highest prediction accuracy. In contrast, the lowest accuracy corresponds to the Zero confidence group. We compute the Pearson coefficient between the prediction accuracy and the mean confidence score in each group to support our observations. Hence, we obtain a value of
for CorpusCine and
PaperReviews, which indicates a strong linear relationship between the analyzed variables confirming our initial qualitative analysis.
As a second experiment, we use lexicon-based algorithms for the CorpusCine dataset. We employ the well-known English dictionaries TextBlob and VADER, applied over an English version of the studied dataset. Further, we use the Spanish dictionary described in
Section 4.2. From
Table 5, we observe that CorpusCine, in terms of the F1 score, the dictionary TextBlob obtains the best performance. On the other hand, regarding PaperReview, we note that the VADER lexicon outperforms all its competitors. However, we observe that the lexicon-based methods exhibit a considerably low-performance in general terms. The above behavior is explained in the sense that dictionaries-based algorithms obtain their best yielding with highly polarity text; however, they are ineffective in assessing the sentiment orientation of cases with mixed opinions [
14].
Finally, we test our hybrid proposal over the labeled datasets.
Table 6 shows the performance of our approach compared with different methods (Unsupervised, supervised, and hybrid) to perform sentiment analysis in Spanish corpora. Analyzing the results for CorpusCine in
Table 6, we first evidence that our proposal reaches the best performance by using a logistic regression classifier, which is remarkable due to it can only deal with linear-separable data. The above suggests a linear structure may exist in the features extracted from the documents. On the other hand, we note that the approaches with the worst performance are those based on unsupervised learning algorithms, which is not surprising. As it was argued below, such types of methods cannot measure documents with mixed opinions. Now, concerning the supervised learning methods, we note that the F1 score considerably outperforms unsupervised algorithms. Such behavior is due to supervised models extracting relevant patterns related to the sentiment orientation. Then, we remark that the works based on hybrid approaches (i.e., combining supervised and unsupervised techniques) [
53,
54] achieve the best classification scores (F1 score, Accuracy). However, regarding our hybrid approach, we observe a significantly lower performance; in fact, it only outperforms the unsupervised models. To explain such an outcome, we highlight that unlike the approaches in [
53,
54], our proposal does not use any information about the gold standard. Conversely, it generates pseudo-labels using the lexicon-based method LRSentiA, which is then used to train a supervised classifier. Therefore, we argue that the performance of our approach can be increased by providing limited labeled data.
Conversely, regarding the results (
Table 6), we notice that, similar to previous outcomes, the best F1 scores come from supervised and hybrid approaches. However, we remark a considerable low yielding from our proposal and the deep learning approach introduced in [
58]; in fact, both methods are defeated by the lexicon-based algorithms (see
Table 5). Concerning the deep learning-based results, we argue that such low performance can be caused by a lack of generalization (overfitting). Now with respect to our hybrid proposal, we explain the undesired results in two regards. First, like the results for the CorpusCine dataset, the training step does not have access to the actual labels; therefore, the behavior of our approach can be enhanced by using partially labeled corpora. Second, we observe that the results from our method are skewed towards positive labels (the precision is greater than recall), which is caused for a discrepancy between the paper is evaluated and the way the review is written [
60].
Finally, aiming to evaluate the behavior of our hybrid proposal in scenarios with limited labeled data, we carry out an additional experiment where we vary the number of labels. Let be
the ratio of available labeled data. We split the CorpusCine review dataset into two groups. The first,
is conformed by
(being
N the number of documents in such corpus) samples with their corresponding true labels
; conversely, the second group
contains
unlabeled documents. Hence, we apply the LRSentiA algorithm over the unlabeled corpus
to generate pseudo-samples. LRSentiA classifies such labels into five groups (Very-high, High, Low, Very-low, and zero) according to their confidence. Then, we conform the sets
, and
by concatenating the samples and labels from the Very-high and High categories together with the labeled data (
).
and
is then used to feed a classification algorithm to predict the label for documents belonging to low, very-low, and zero confidence. For each value of
p, we use a five-fold validation scheme, where the sets
, and
are conformed randomly. The performance is measured in terms of the overall accuracy.
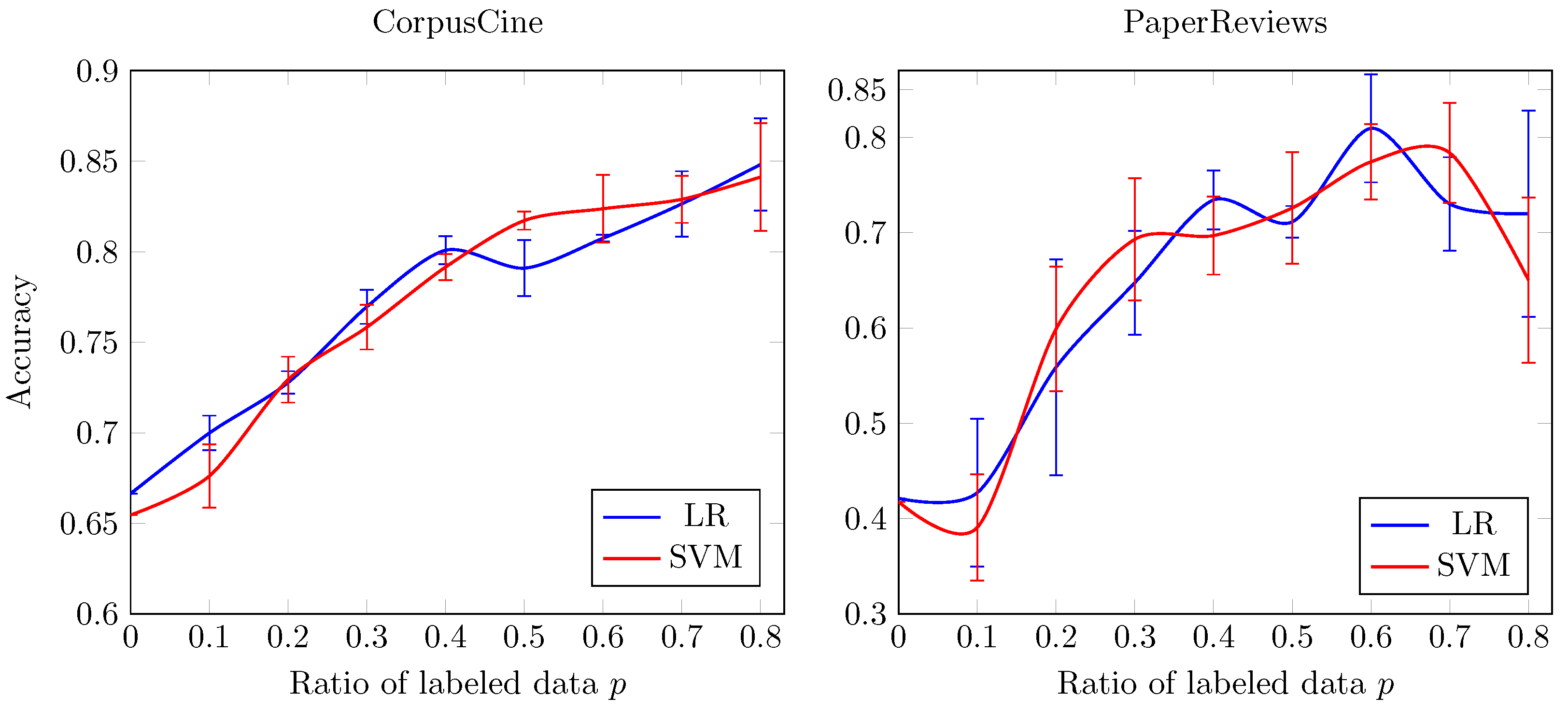
Figure 2 shows the mean and standard deviation for the accuracy of our proposal as a function of the ratio of labeled data. For specific testing, we compare a logistic regression classifier and a Support vector machine since they achieved the highest performances in previous experiments (see
Table 6). From
Figure 2, we remark that in most cases, the performance of our approach increases as there are more labeled data. Besides, we highlight that with the
of labeled data, our proposal achieves an accuracy near 0.8 for CorpusCine data and near 0.7 for PaperReview dataset, which remarkably is comparable with state-of-the-art results.
5.2. Colombian Conflict Dataset
As a final experiment, we apply our proposal to each document in the Colombian conflict dataset aiming to understand the narrative of the war from the journalism students’ perspective. Aiming to validate the obtained results, we use the qualitative labels explained in
Section 4.1.2. However, we note that such labels are not given for each document but for each media. Accordingly, to perform a fair comparison, we use the following procedure. Let
a set containing
documents corresponding to the
m-th media. We use our hybrid method to obtain the sentiment polarity
for each document in
. Accordingly, the polarity of
m-th media is computed as:
Table 7 shows a comparison between the semantic orientation obtained by using our approach under four configurations (employing four classification algorithms: LR, SVM, RF, and NB) and a set of qualitative labels, which are obtained using the identification of lexical worlds [
47] (see
Section 4.1.2).
From
Table 7, we first notice that according to the qualitative assessment, all of the considered media expresses positive aspects of the Colombian conflict and its stages. Now, regarding the result of our self-supervised approach, we note a similar tendency, given that most of the media are categorized as positives; such outcomes are consistent when we vary the classification scheme (RL, SVM, RF, and NB), obtaining an overall accuracy of 75%. Specifically, we remark that for media Universidad del Valle and Santiago de Cali the sentiment orientation predicted for our approach differs from the qualitative labels; hence, to explain such outcomes, we analyze each media individually. For the Universidad del Valle media, we observe it contains 60 documents, and only 26 were categorized as very-high or high confidence. The above indicates that the supervised learning approach was trained with 26 samples, which indicates that the overfitting causes the results obtained. Conversely, regarding the Santiago de Cali media, we notice that despite the predicted label being negative, the ratio of documents with a positive semantic orientation is close to
, which indicates the robustness of our approach to recognizing the polarity of documents related to the Colombian conflict.
On the other hand, the results are complemented by the lexicometric approach. College journalism narrated the conflict with a positive stance; this is reflected in the need to understand Colombia’s conflict and propose solutions and scenarios of agreement. From journalism, we could affirm that college journalism focused on presenting future actions and not falling into the traditional narrative that was merely informative.


 ,
, 



{kind=link}
{kind=link}