
IMNets: Deep Learning Using an Incremental Modular Network Synthesis Approach for Medical Imaging Applications



Abstract
:1. Introduction
1.1. Background
1.2. Applications
1.3. Related Works
1.4. Contributions
1.5. Paper Organization
2. Materials
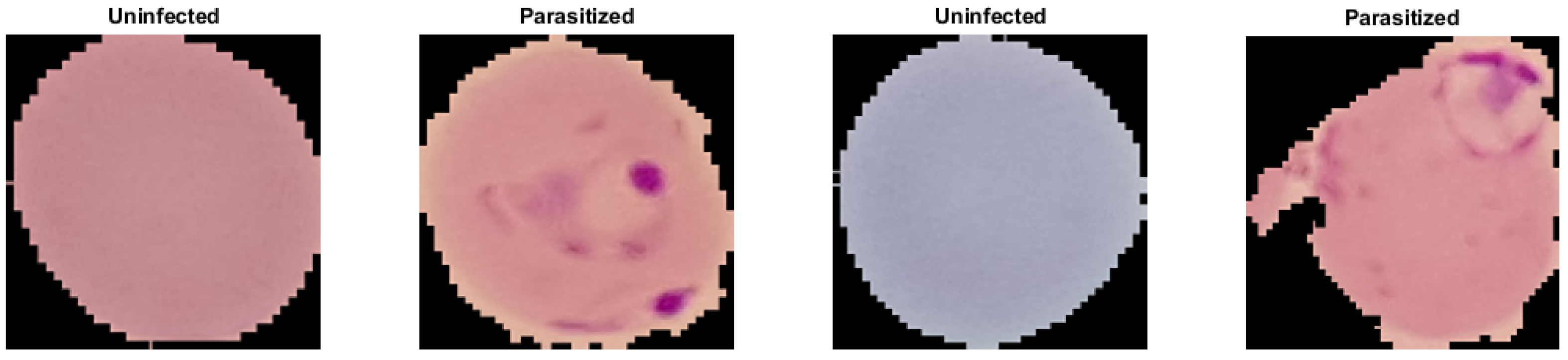
2.1. Malaria Dataset
2.2. Diabetic Retinopathy Dataset
- We find the mask of the orange portion of the eye and separate it from the black background.
- We locate the optic nerve that appears as a bright disk in the images. This is achieved by applying a Gaussian low-pass filter with a spatial standard deviation approximately equal to the radius of the optic nerve disk. The brightest pixel after the blurring operation generally is located near the center of the optic nerve.
- We compare the location of the optic nerve center to the center of the eye mask to determine the orientation of the eye. We then rotate the image so that optic nerve is consistently on the right of center in the resulting image.
- Finally, we crop, zero pad, and interpolate to obtain the same size images. We do so in such a way as to not change the aspect ratio of image, as this would contaminate the geometric integrity of the data.
2.3. Tuberculosis Dataset
3. Methods
3.1. Overview
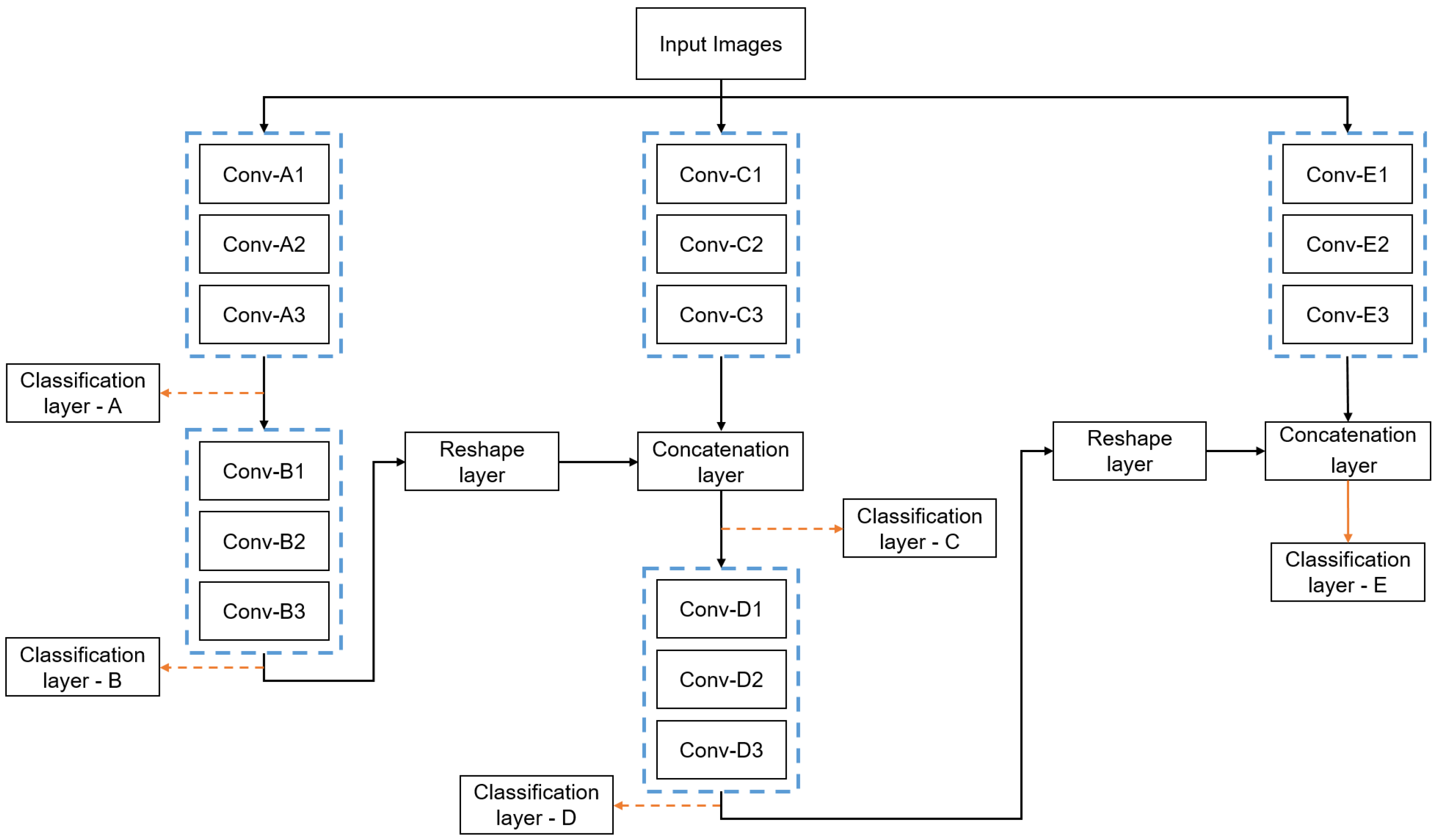
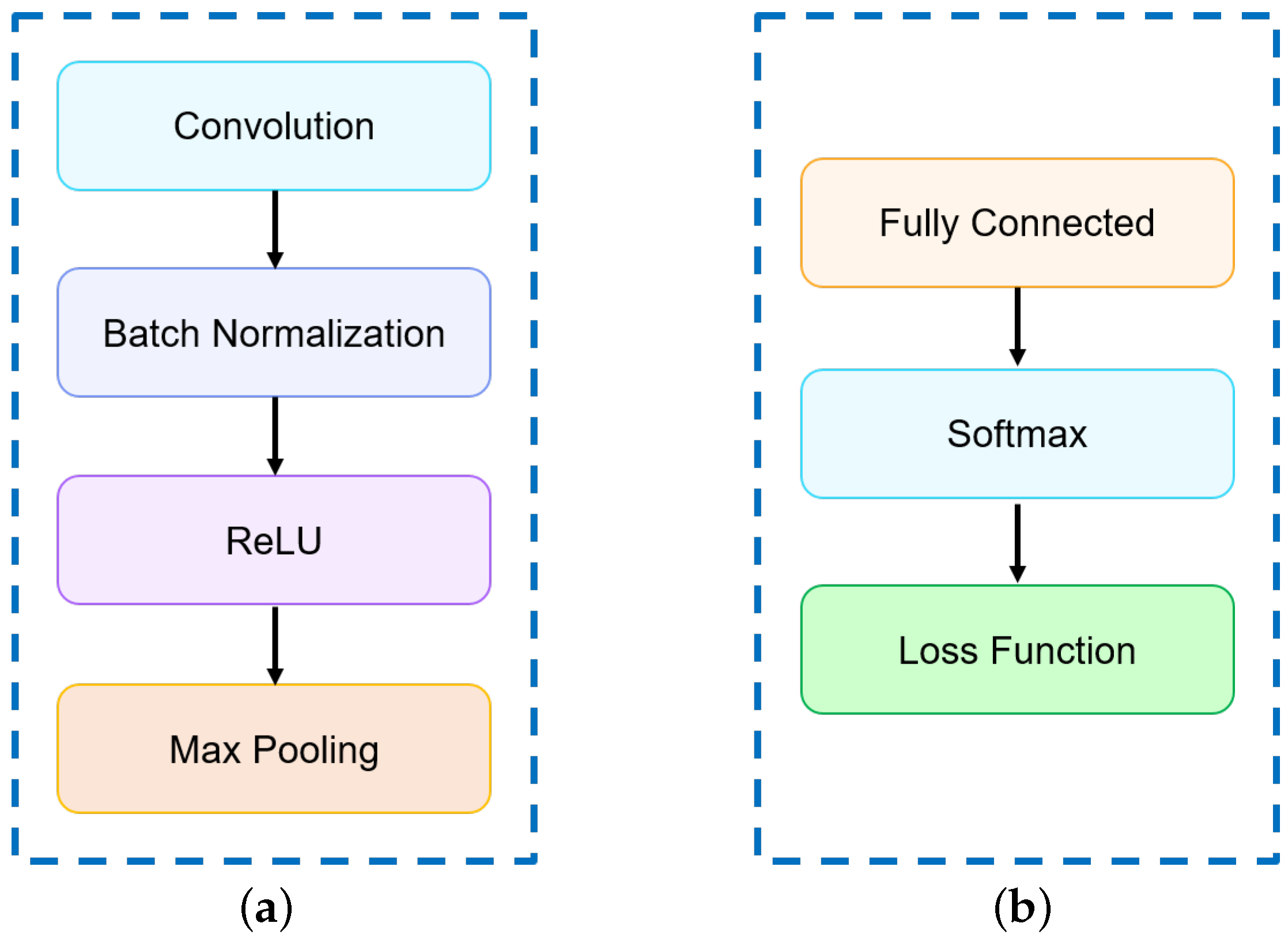
3.2. SubNet Architecture
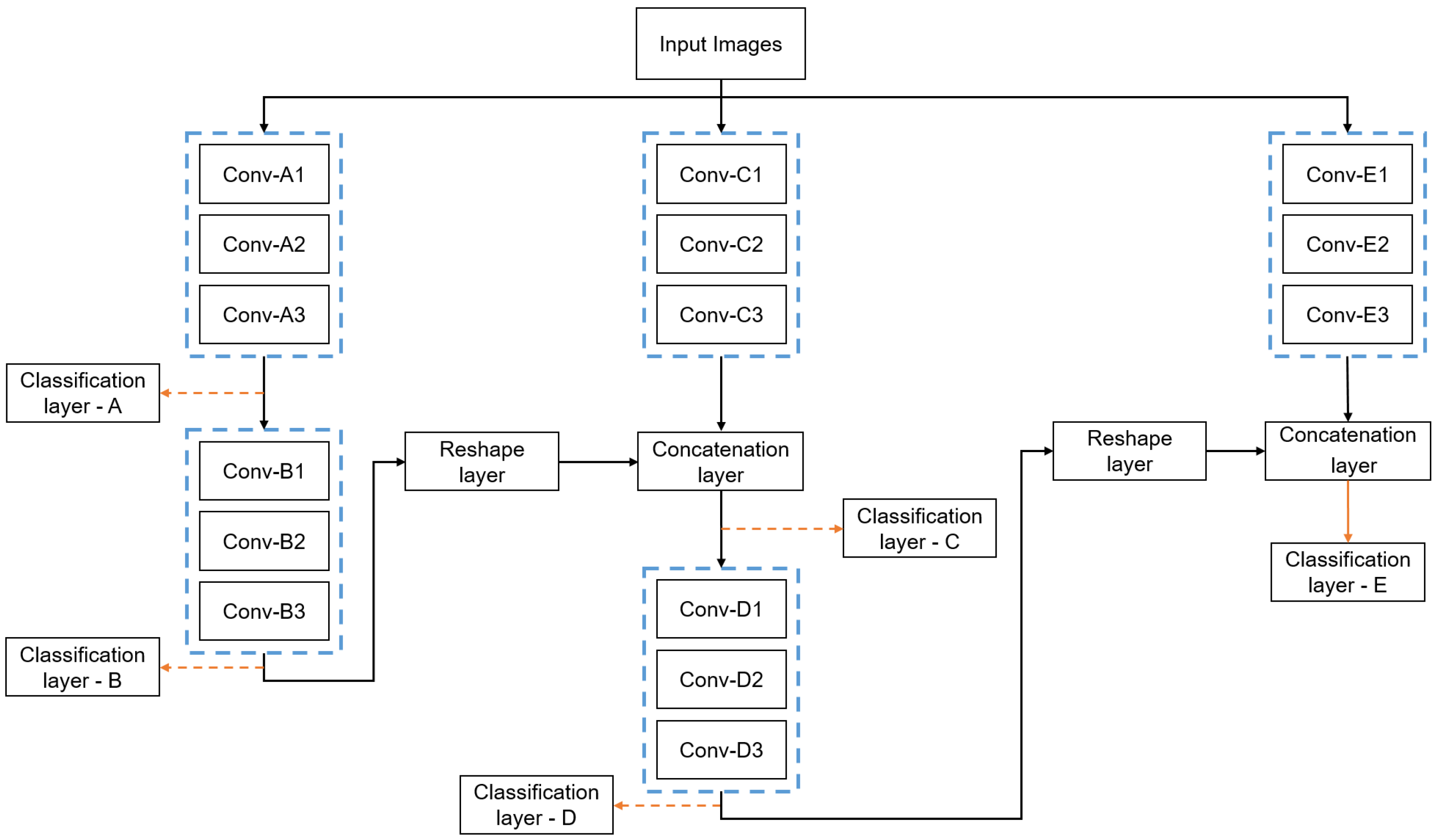
3.3. Series and Parallel Combinations
3.4. Proposed IMNet Architecture
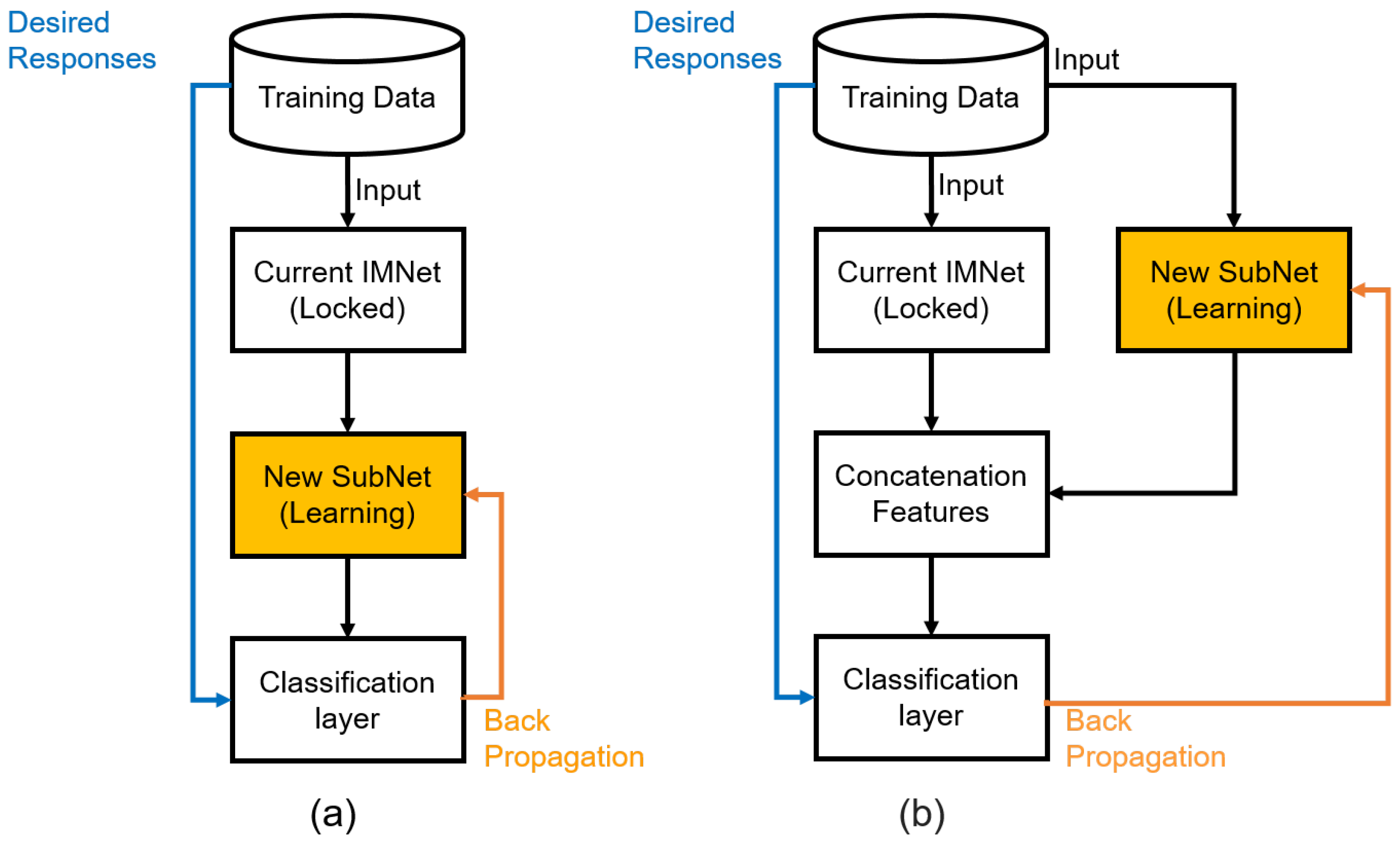
3.5. Network Training
3.6. Statistical Analysis
4. Experiment Results
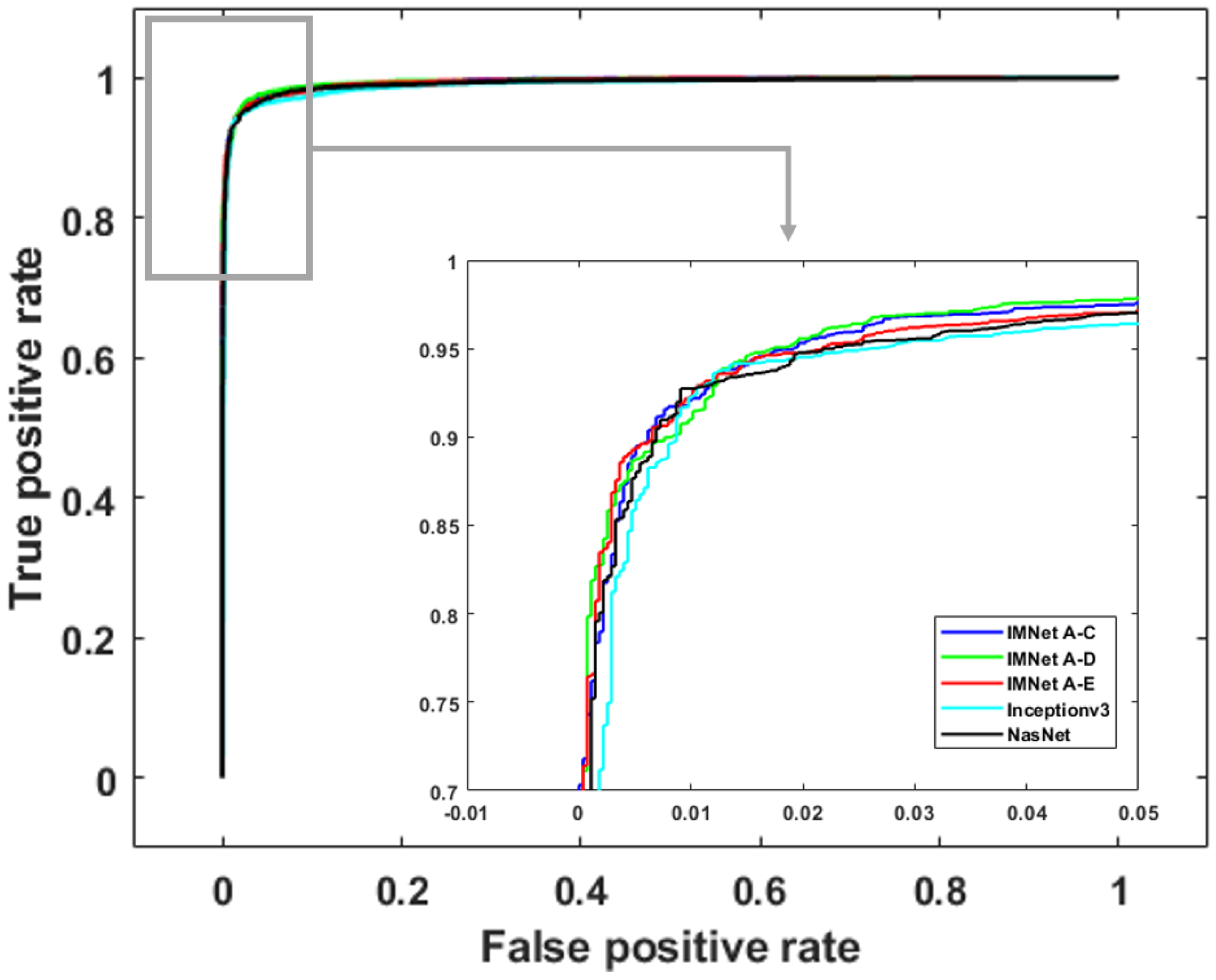
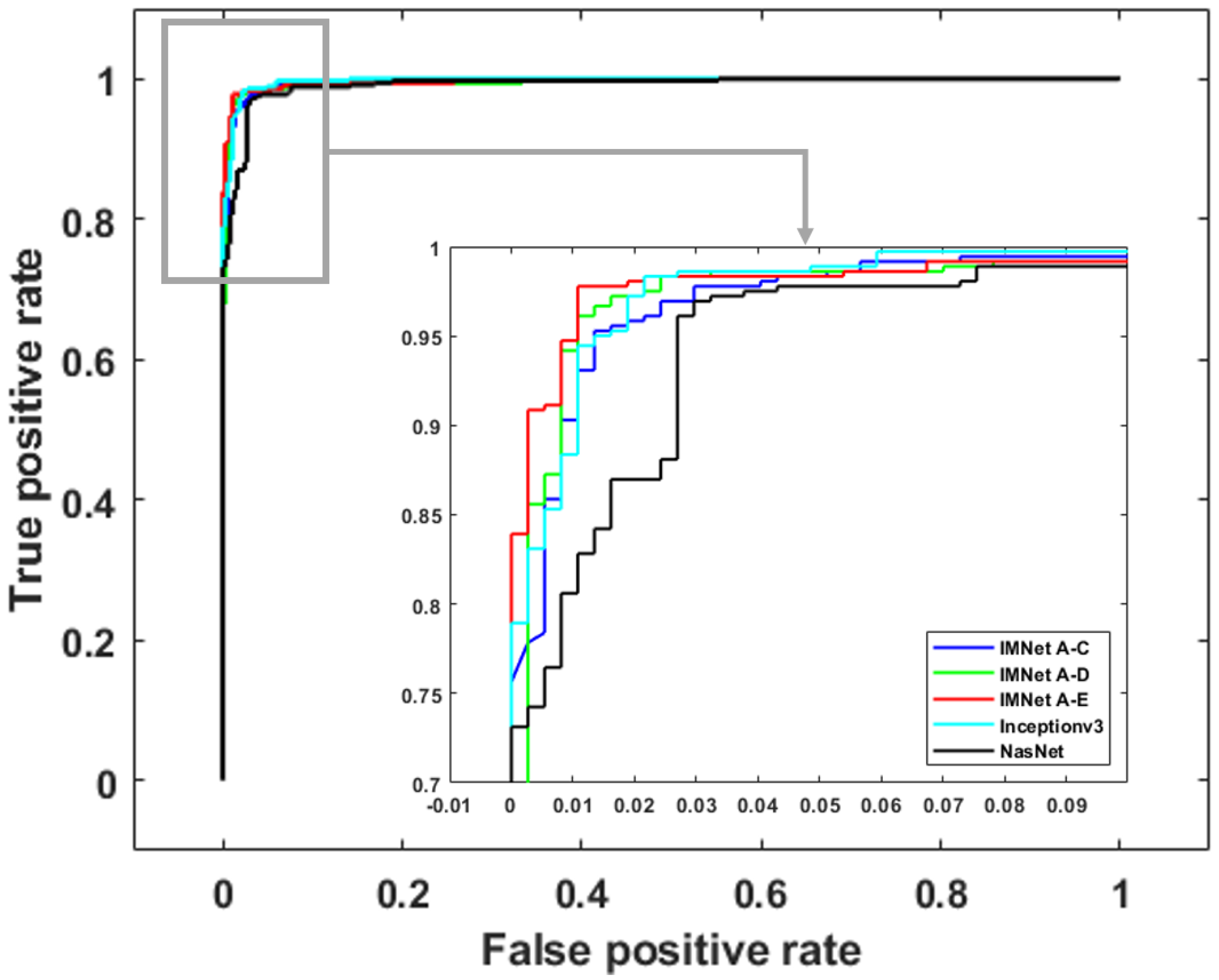
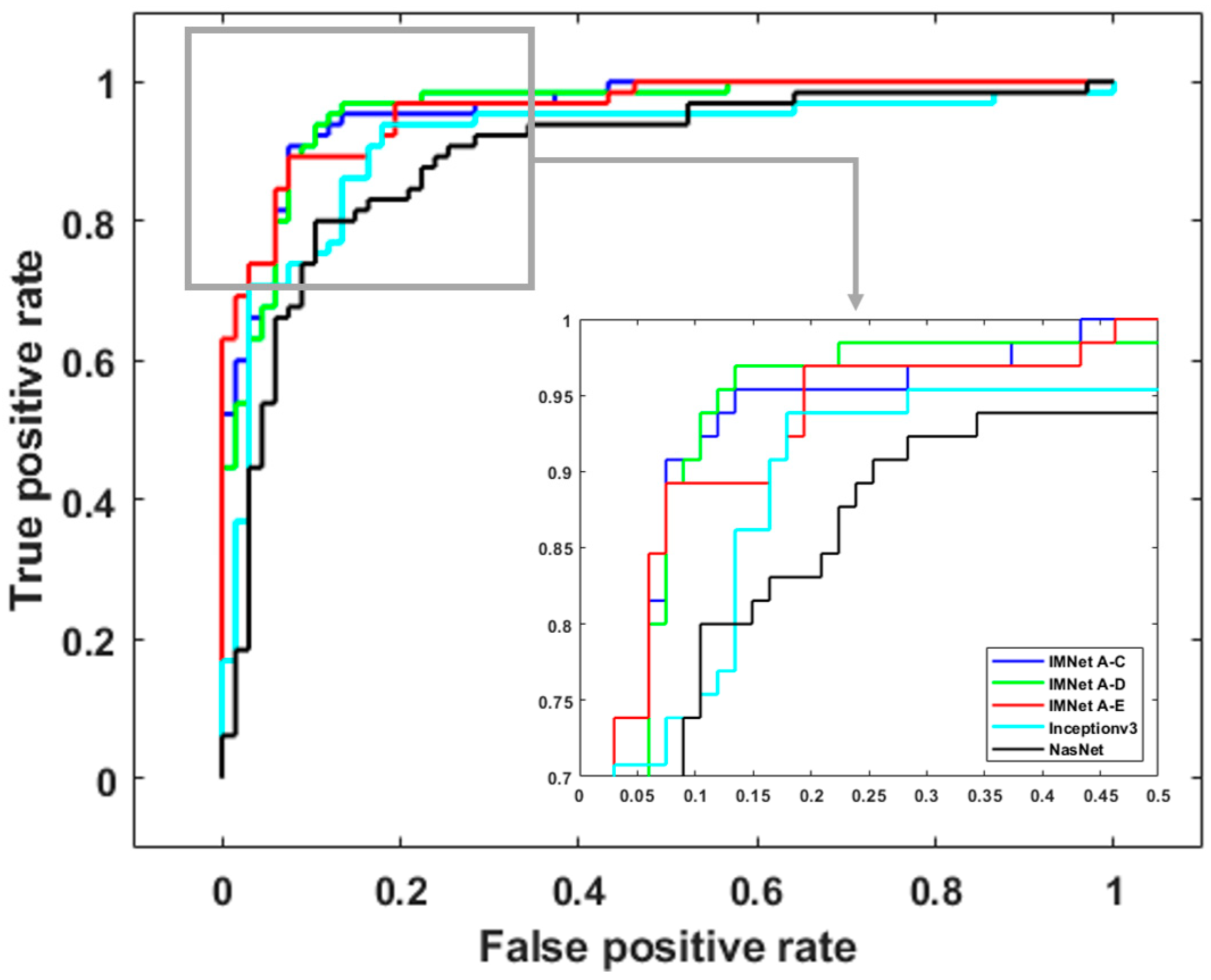
4.1. Quantitative Results Summary
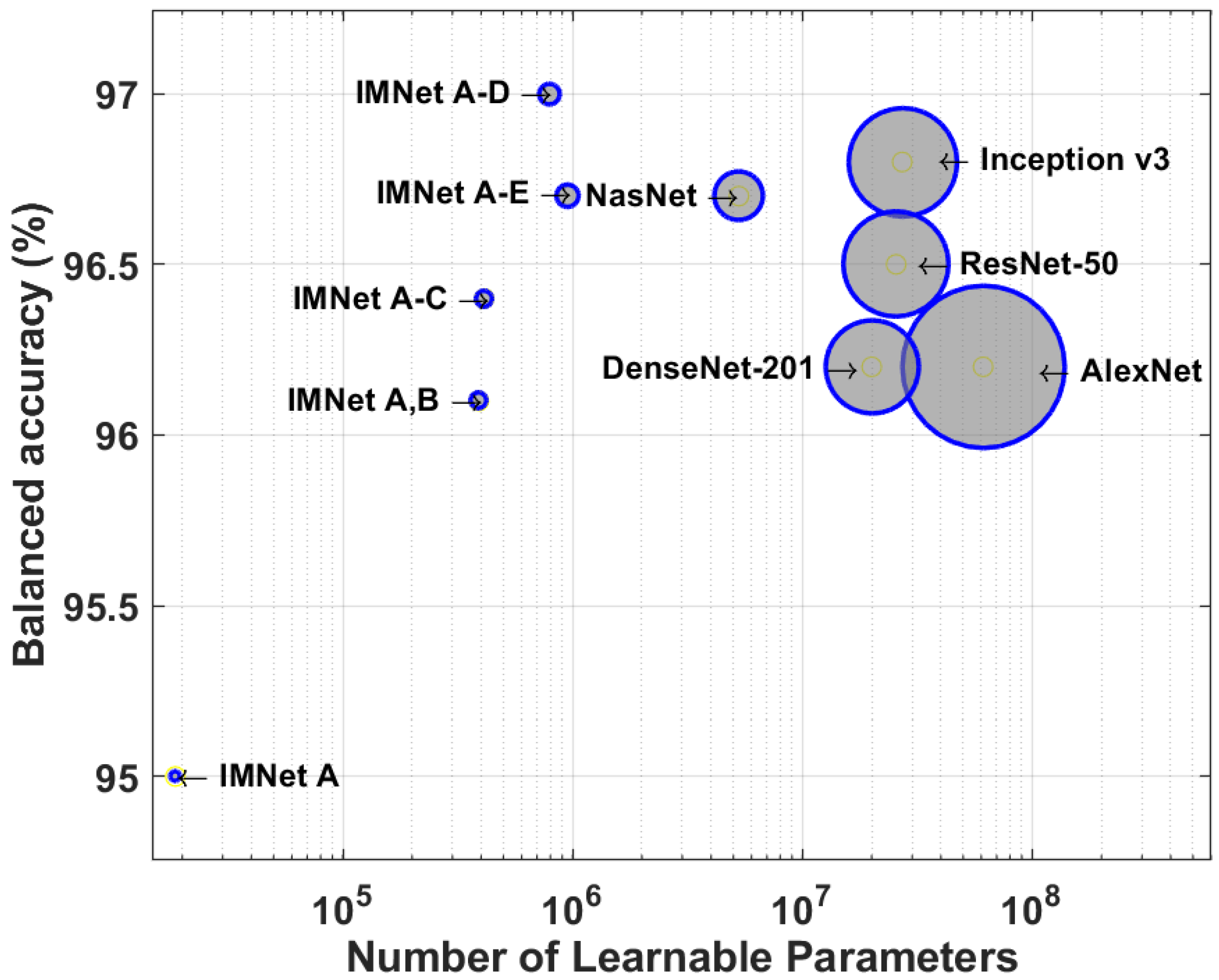
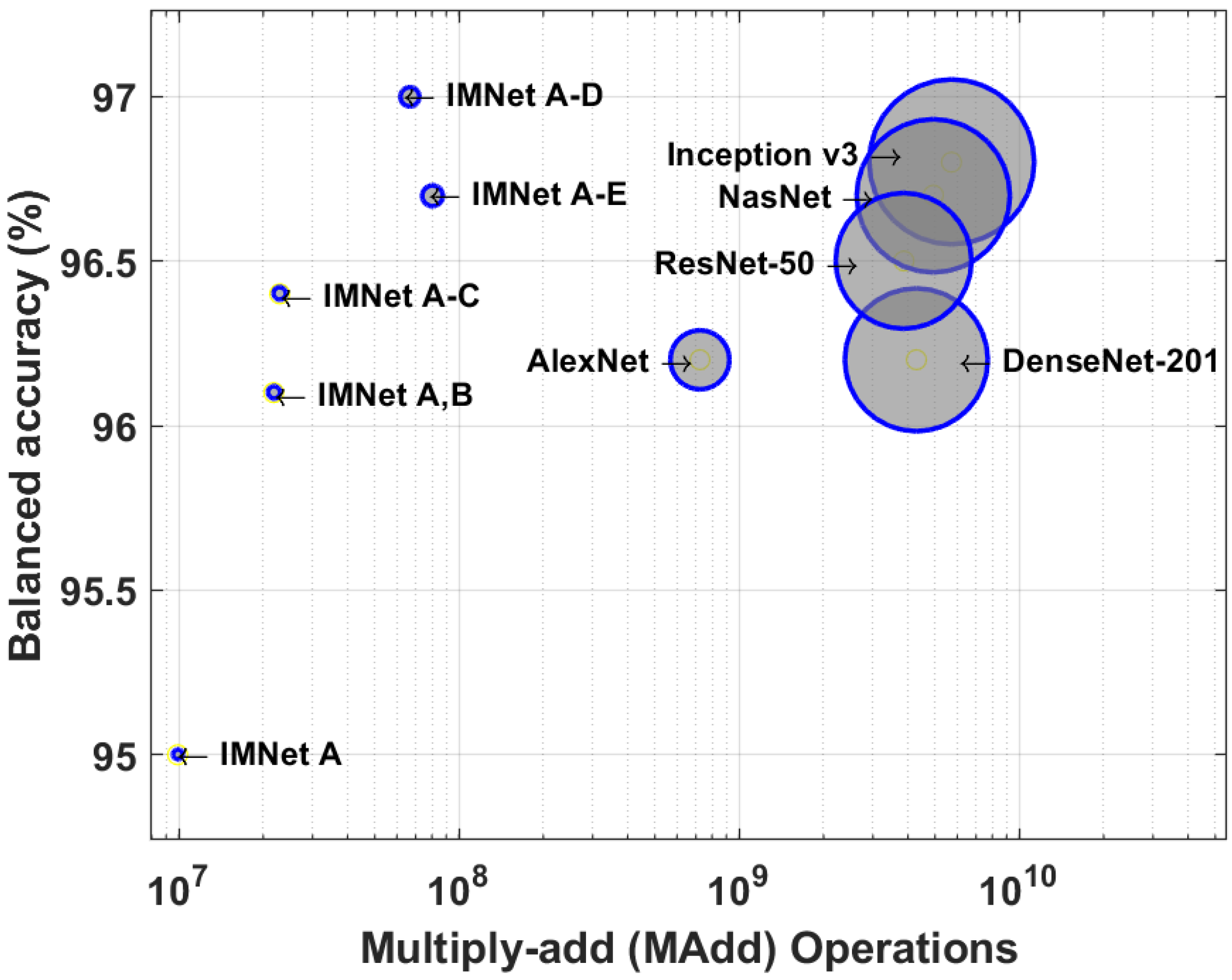
4.2. Computational Complexity Comparison
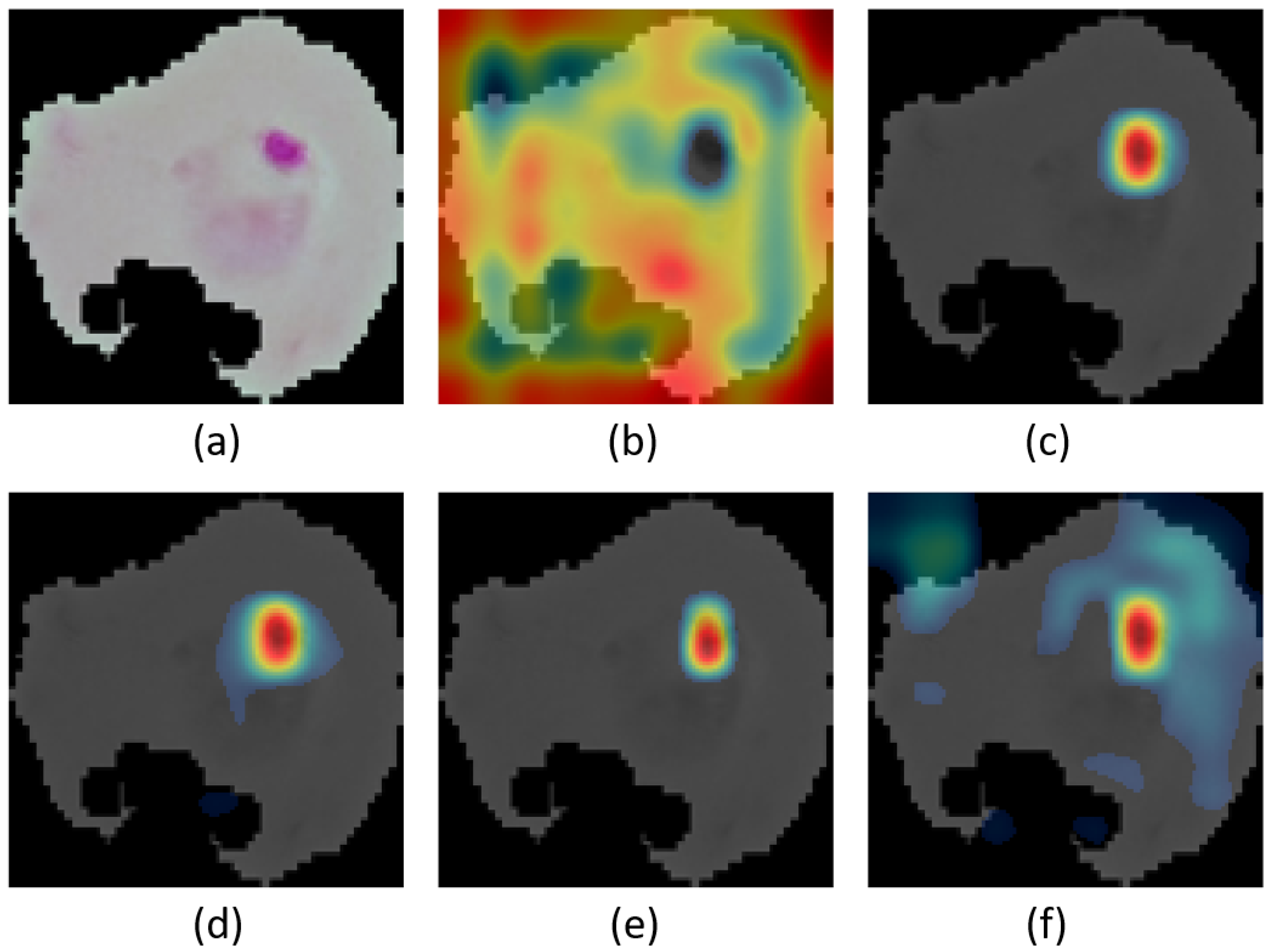
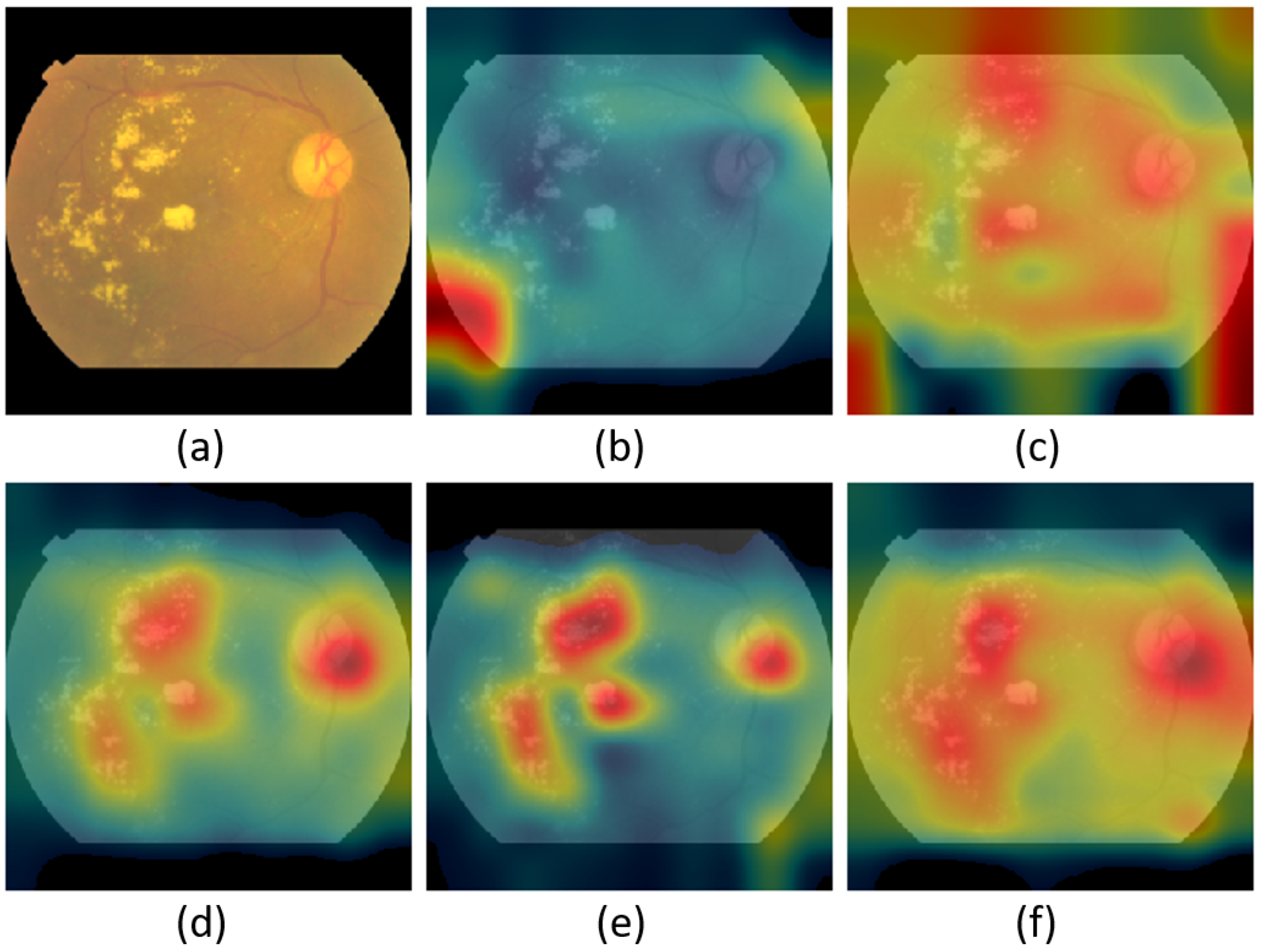
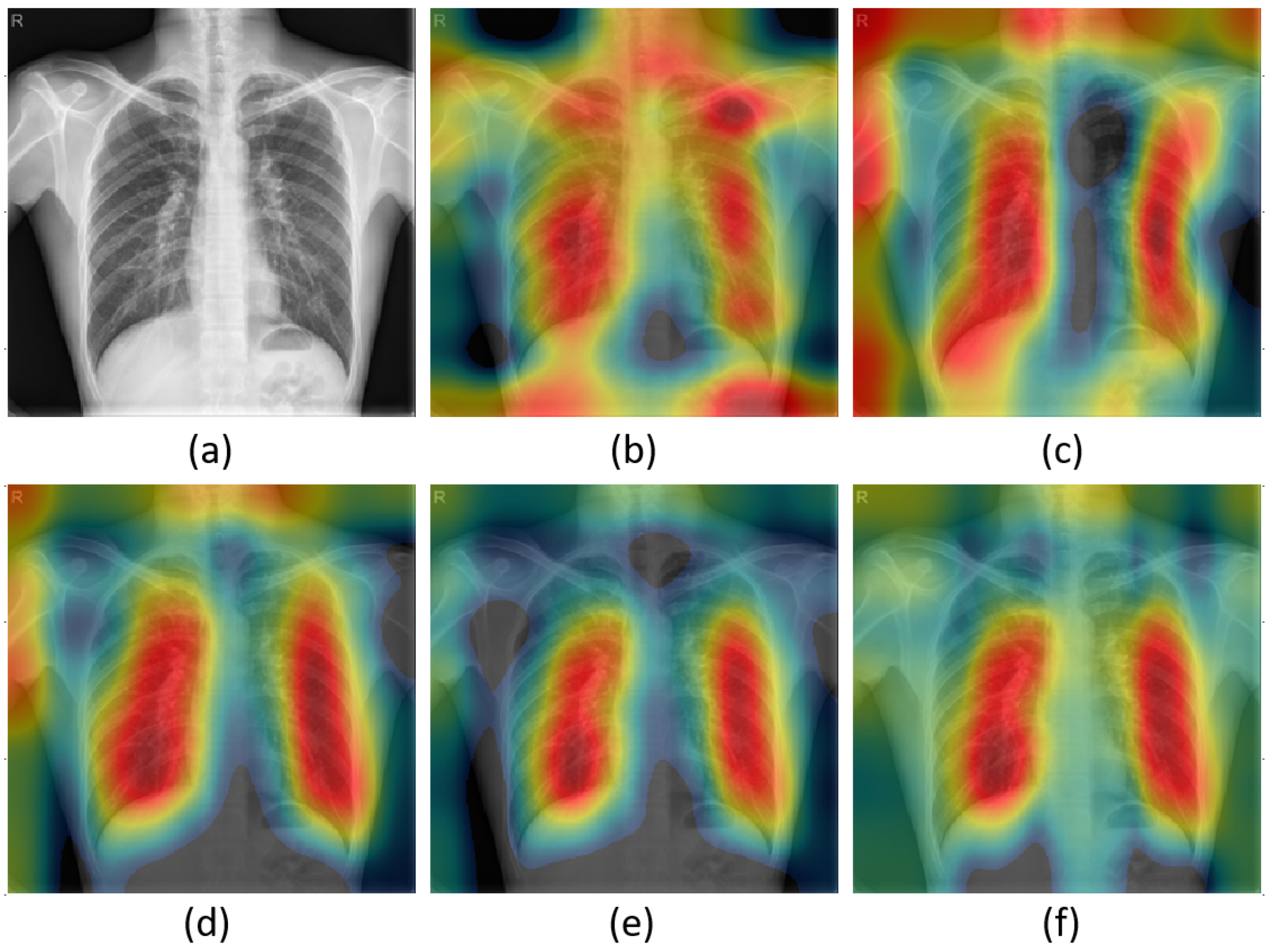
4.3. Visual Explanations
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhai, X.; Kolesnikov, A.; Houlsby, N.; Beyer, L. Scaling vision transformers. arXiv 2021, arXiv:2106.04560. [Google Scholar]
- Riquelme, C.; Puigcerver, J.; Mustafa, B.; Neumann, M.; Jenatton, R.; Pinto, A.S.; Keysers, D.; Houlsby, N. Scaling Vision with Sparse Mixture of Experts. arXiv 2021, arXiv:2106.05974. [Google Scholar]
- Image Classification on ImageNe. Available online: https://paperswithcode.com/sota/image-classification-on-imagenet (accessed on 6 July 2021).
- D’souza, R.N.; Huang, P.Y.; Yeh, F.C. Structural analysis and optimization of convolutional neural networks with a small sample size. Sci. Rep. 2020, 10, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Arsenovic, M.; Karanovic, M.; Sladojevic, S.; Anderla, A.; Stefanovic, D. Solving current limitations of deep learning based approaches for plant disease detection. Symmetry 2019, 11, 939. [Google Scholar] [CrossRef] [Green Version]
- Cremer, C.Z. Deep limitations? Examining expert disagreement over deep learning. Prog. Artif. Intell. 2021, 26, 1–16. [Google Scholar] [CrossRef]
- Lv, X.; Zhang, X. Generating chinese classical landscape paintings based on cycle-consistent adversarial networks. In Proceedings of the 2019 6th International Conference on systems and Informatics (ICSAI), Shanghai, China, 2–4 November 2019; pp. 1265–1269. [Google Scholar]
- Chen, K. Deep and Modular Neural Networks. In Handbook of Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Albright, T.D.; Jessell, T.M.; Kandel, E.R.; Posner, M.I. Neural science: A century of progress and the mysteries that remain. Neuron 2000, 25, S1–S55. [Google Scholar] [CrossRef] [Green Version]
- Fodor, J.A. The Modularity of Mind; MIT Press: Cambridge, MA, USA, 1983. [Google Scholar]
- Edelman, G.M. Neural Darwinism: The Theory of Neural Group Selection; Basic Books: New York, NY, USA, 1987. [Google Scholar]
- O’Connell, K.A.; Gatakaa, H.; Poyer, S.; Njogu, J.; Evance, I.; Munroe, E.; Solomon, T.; Goodman, C.; Hanson, K.; Zinsou, C.; et al. Got ACTs? Availability, price, market share and provider knowledge of anti-malarial medicines in public and private sector outlets in six malaria-endemic countries. Malar. J. 2011, 10, 326. [Google Scholar] [CrossRef] [Green Version]
- WHO. World Malaria Report 2020: 20 Years of Global Progress and Challenges; WHO: Geneva, Switzerland, 2020.
- Mace, K.E.; Arguin, P.M.; Tan, K.R. Malaria surveillance—United States, 2015. MMWR Surveill. Summ. 2018, 67, 1. [Google Scholar] [CrossRef]
- Posfai, D.; Sylvester, K.; Reddy, A.; Ganley, J.G.; Wirth, J.; Cullen, Q.E.; Dave, T.; Kato, N.; Dave, S.S.; Derbyshire, E.R. Plasmodium parasite exploits host aquaporin-3 during liver stage malaria infection. PLoS Pathog. 2018, 14, e1007057. [Google Scholar] [CrossRef]
- Dey, N.; Ashour, A.S.; Borra, S. Classification in BioApps: Automation of Decision Making; Springer: Berlin/Heidelberg, Germany, 2017; Volume 26. [Google Scholar]
- WHO. Malaria Microscopy: Quality Assurance Manual, Version 2; WHO: Geneva, Switzerland, 2016.
- Yang, F.; Poostchi, M.; Yu, H.; Zhou, Z.; Silamut, K.; Yu, J.; Maude, R.J.; Jaeger, S.; Antani, S. Deep learning for smartphone-based malaria parasite detection in thick blood smears. IEEE J. Biomed. Health Inform. 2019, 24, 1427–1438. [Google Scholar] [CrossRef]
- Dong, Y.; Jiang, Z.; Shen, H.; Pan, W.D.; Williams, L.A.; Reddy, V.V.; Benjamin, W.H.; Bryan, A.W. Evaluations of deep convolutional neural networks for automatic identification of malaria infected cells. In Proceedings of the 2017 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), Chicago, IL, USA, 16–19 February 2017; pp. 101–104. [Google Scholar]
- Zheng, Y.; He, M.; Congdon, N. The worldwide epidemic of diabetic retinopathy. Indian J. Ophthalmol. 2012, 60, 428. [Google Scholar] [PubMed]
- Zhang, X.; Wang, H.; Du, C.; Fan, X.; Cui, L.; Chen, H.; Deng, F.; Tong, Q.; He, M.; Yang, M.; et al. Custom-Molded Offloading Footwear Effectively Prevents Recurrence and Amputation, and Lowers Mortality Rates in High-Risk Diabetic Foot Patients: A Multicenter, Prospective Observational Study. Diabetes Metab. Syndr. Obes. Targets Ther. 2022, 15, 103. [Google Scholar] [CrossRef] [PubMed]
- Flaxman, S.R.; Bourne, R.R.; Resnikoff, S.; Ackland, P.; Braithwaite, T.; Cicinelli, M.V.; Das, A.; Jonas, J.B.; Keeffe, J.; Kempen, J.H.; et al. Global causes of blindness and distance vision impairment 1990–2020: A systematic review and meta-analysis. Lancet Glob. Health 2017, 5, e1221–e1234. [Google Scholar] [CrossRef] [Green Version]
- Salz, D.A.; Witkin, A.J. Imaging in diabetic retinopathy. Middle East Afr. J. Ophthalmol. 2015, 22, 145. [Google Scholar] [PubMed]
- Harding, E. WHO global progress report on tuberculosis elimination. Lancet Respir. Med. 2020, 8, 19. [Google Scholar] [CrossRef]
- Narayanan, B.N.; Hardie, R.C.; Krishnaraja, V.; Karam, C.; Davuluru, V.S.P. Transfer-to-transfer learning approach for computer aided detection of COVID-19 in chest radiographs. AI 2020, 1, 539–557. [Google Scholar] [CrossRef]
- World Health Organization. World Malaria Report 2015; World Health Organization: Geneva, Switzerland, 2016.
- Ali, R.; Hardie, R.C.; Ragb, H.K. Ensemble lung segmentation system using deep neural networks. In Proceedings of the 2020 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 13–15 October 2020; pp. 1–5. [Google Scholar]
- Rahman, A.; Zunair, H.; Rahman, M.S.; Yuki, J.Q.; Biswas, S.; Alam, M.A.; Alam, N.B.; Mahdy, M. Improving malaria parasite detection from red blood cell using deep convolutional neural networks. arXiv 2019, arXiv:1907.10418. [Google Scholar]
- Pattanaik, P.; Mittal, M.; Khan, M.Z.; Panda, S. Malaria detection using deep residual networks with mobile microscopy. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 1700–1705. [Google Scholar] [CrossRef]
- Zhao, O.S.; Kolluri, N.; Anand, A.; Chu, N.; Bhavaraju, R.; Ojha, A.; Tiku, S.; Nguyen, D.; Chen, R.; Morales, A.; et al. Convolutional neural networks to automate the screening of malaria in low-resource countries. PeerJ 2020, 8, e9674. [Google Scholar] [CrossRef]
- Poostchi, M.; Silamut, K.; Maude, R.J.; Jaeger, S.; Thoma, G. Image analysis and machine learning for detecting malaria. Transl. Res. 2018, 194, 36–55. [Google Scholar] [CrossRef] [Green Version]
- Lee, Y.W.; Choi, J.W.; Shin, E.H. Machine learning model for predicting malaria using clinical information. Comput. Biol. Med. 2020, 129, 104151. [Google Scholar] [CrossRef] [PubMed]
- Narayanan, B.N.; Ali, R.; Hardie, R.C. Performance analysis of machine learning and deep learning architectures for malaria detection on cell images. In Applications of Machine Learning; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 11139, p. 111390W. [Google Scholar]
- Qummar, S.; Khan, F.G.; Shah, S.; Khan, A.; Shamshirband, S.; Rehman, Z.U.; Khan, I.A.; Jadoon, W. A deep learning ensemble approach for diabetic retinopathy detection. IEEE Access 2019, 7, 150530–150539. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, H.; Murthy, V.; Wang, X.; Cao, L.; Schwartz, J.; Hernandez, J.; Rodriguez, G.; Liu, B.J. The application of deep learning for diabetic retinopathy prescreening in research eye-PACS. In Medical Imaging 2018: Imaging Informatics for Healthcare, Research, and Applications; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10579, p. 1057913. [Google Scholar]
- Majumder, S.; Elloumi, Y.; Akil, M.; Kachouri, R.; Kehtarnavaz, N. A deep learning-based smartphone app for real-time detection of five stages of diabetic retinopathy. In Real-Time Image Processing and Deep Learning 2020; International Society for Optics and Photonics: Bellingham, WA, USA, 2020; Volume 11401, p. 1140106. [Google Scholar]
- Narayanan, B.N.; Hardie, R.C.; De Silva, M.S.; Kueterman, N.K. Hybrid machine learning architecture for automated detection and grading of retinal images for diabetic retinopathy. J. Med Imaging 2020, 7, 034501. [Google Scholar] [CrossRef] [PubMed]
- Chetoui, M.; Akhloufi, M.A. Explainable end-to-end deep learning for diabetic retinopathy detection across multiple datasets. J. Med. Imaging 2020, 7, 044503. [Google Scholar] [CrossRef]
- Niazi, M.K.K.; Beamer, G.; Gurcan, M.N. An application of transfer learning to neutrophil cluster detection for tuberculosis: Efficient implementation with nonmetric multidimensional scaling and sampling. In Medical Imaging 2018: Digital Pathology; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10581, p. 1058108. [Google Scholar]
- Hwang, S.; Kim, H.E.; Jeong, J.; Kim, H.J. A novel approach for tuberculosis screening based on deep convolutional neural networks. In Medical imaging 2016: Computer-Aided Diagnosis; SPIE: Bellingham, WA, USA, 2016; Volume 9785, pp. 750–757. [Google Scholar]
- Wu, E.Q.; Zhou, M.; Hu, D.; Zhu, L.; Tang, Z.; Qiu, X.Y.; Deng, P.Y.; Zhu, L.M.; Ren, H. Self-Paced Dynamic Infinite Mixture Model for Fatigue Evaluation of Pilots’ Brains. IEEE Trans. Cybern. 2020. [Google Scholar] [CrossRef]
- Panicker, R.O.; Kalmady, K.S.; Rajan, J.; Sabu, M. Automatic detection of tuberculosis bacilli from microscopic sputum smear images using deep learning methods. Biocybern. Biomed. Eng. 2018, 38, 691–699. [Google Scholar] [CrossRef]
- Li, X.; Zhou, Y.; Du, P.; Lang, G.; Xu, M.; Wu, W. A deep learning system that generates quantitative CT reports for diagnosing pulmonary tuberculosis. Appl. Intell. 2021, 51, 4082–4093. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Deng, W.; Zhang, X.; Zhou, Y.; Liu, Y.; Zhou, X.; Chen, H.; Zhao, H. An enhanced fast non-dominated solution sorting genetic algorithm for multi-objective problems. Inf. Sci. 2022, 585, 441–453. [Google Scholar] [CrossRef]
- Chen, T.; Goodfellow, I.; Shlens, J. Net2Net: Accelerating Learning via Knowledge Transfer. arXiv 2016, arXiv:1511.05641. [Google Scholar]
- Anderson, A.; Shaffer, K.; Yankov, A.; Corley, C.D.; Hodas, N.O. Beyond Fine Tuning: A Modular Approach to Learning on Small Data. arXiv 2016, arXiv:1611.01714. [Google Scholar]
- Rajaraman, S.; Antani, S.K.; Poostchi, M.; Silamut, K.; Hossain, M.A.; Maude, R.J.; Jaeger, S.; Thoma, G.R. Pre-trained convolutional neural networks as feature extractors toward improved malaria parasite detection in thin blood smear images. PeerJ 2018, 6, e4568. [Google Scholar] [CrossRef] [PubMed]
- APTOS 2019 Blindness Detection. Available online: https://www.kaggle.com/c/aptos2019-blindness-detection/overview (accessed on 14 December 2020).
- Jaeger, S.; Candemir, S.; Antani, S.; Wáng, Y.X.J.; Lu, P.X.; Thoma, G. Two public chest X-ray datasets for computer-aided screening of pulmonary diseases. Quant. Imaging Med. Surg. 2014, 4, 475. [Google Scholar] [PubMed]
- Finlayson, G.D.; Trezzi, E. Shades of gray and colour constancy. In Proceedings of the Color and Imaging Conference. Society for Imaging Science and Technology, Scottsdale, AZ, USA, 9–12 November 2004; Volume 2004, pp. 37–41. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Kim, P. Matlab deep learning. In With Machine Learning, Neural Networks and Artificial Intelligence; Springer: Berkeley, CA, USA, 2017; Volume 130. [Google Scholar]
- Ng, A.Y. Feature selection, L 1 vs. L 2 regularization, and rotational invariance. In Proceedings of the 21st International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; p. 78. [Google Scholar]
- Brinker, T.J.; Hekler, A.; Utikal, J.S.; Grabe, N.; Schadendorf, D.; Klode, J.; Berking, C.; Steeb, T.; Enk, A.H.; Von Kalle, C. Skin cancer classification using convolutional neural networks: Systematic review. J. Med. Internet Res. 2018, 20, e11936. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2016; pp. 2818–2826. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- MATLAB Deep Learning Toolbox Documentation. Available online: https://www.mathworks.com/help/deeplearning/ (accessed on 6 July 2021).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Rajaraman, S.; Jaeger, S.; Antani, S.K. Performance evaluation of deep neural ensembles toward malaria parasite detection in thin-blood smear images. PeerJ 2019, 7, e6977. [Google Scholar] [CrossRef] [Green Version]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef]
- Sahlsten, J.; Jaskari, J.; Kivinen, J.; Turunen, L.; Jaanio, E.; Hietala, K.; Kaski, K. Deep learning fundus image analysis for diabetic retinopathy and macular edema grading. Sci. Rep. 2019, 9, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Meraj, S.S.; Yaakob, R.; Azman, A.; Rum, S.; Shahrel, A.; Nazri, A.; Zakaria, N.F. Detection of pulmonary tuberculosis manifestation in chest X-rays using different convolutional neural network (CNN) models. Int. J. Eng. Adv. Technol. (IJEAT) 2019, 9, 2270–2275. [Google Scholar] [CrossRef]
- Sathitratanacheewin, S.; Sunanta, P.; Pongpirul, K. Deep learning for automated classification of tuberculosis-related chest X-Ray: Dataset distribution shift limits diagnostic performance generalizability. Heliyon 2020, 6, e04614. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Prasad, K.; Winter, J.; Bhat, U.M.; Acharya, R.V.; Prabhu, G.K. Image analysis approach for development of a decision support system for detection of malaria parasites in thin blood smear images. J. Digit. Imaging 2012, 25, 542–549. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Borsos, B.; Nagy, L.; Iclanzan, D.; Szilágyi, L. Automatic detection of hard and soft exudates from retinal fundus images. Acta Unitiversitatis-Sapientiae-Inform. 2019, 11, 65–79. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Applications | Malaria | Diabetic Retinopathy | Tuberculosis | |
|---|---|---|---|---|
| Datasets | ||||
| Images size | ||||
| No. of training set | 19842 | 2637 | 477 | |
| No. of validation set | 2204 | 293 | 53 | |
| No. of testing set | 5512 | 732 | 132 | |
| Model | Layers | Filter Size | Total Parameters | MAdd |
|---|---|---|---|---|
| SubNet A | Conv-A2 | 0.018M | 9.94M | |
| Conv-A2 | ||||
| Conv-A3 | ||||
| SubNet B | Conv-B1 | 0.390M | 11.94M | |
| Conv-B2 | ||||
| Conv-B3 | ||||
| SubNet C | Conv-C1 | 0.021M | 1.10M | |
| Conv-C2 | ||||
| Conv-C3 | ||||
| SubNet D | Conv-D1 | 0.390M | 43.65M | |
| Conv-D2 | ||||
| Conv-D3 | ||||
| SubNet E | Conv-E1 | 0.165M | 13.82M | |
| Conv-E2 | ||||
| Conv-E3 |
| Model | BACC (%) | SPEC (%) | SENS (%) | AUC | Testing Time (s) |
|---|---|---|---|---|---|
| AlexNet | |||||
| ResNet | |||||
| DenseNet | |||||
| Inception v3 | |||||
| NasNet | |||||
| IMNet A | |||||
| IMNet | |||||
| IMNet | |||||
| IMNet | |||||
| IMNet |
| Model | BACC (%) | SPEC (%) | SENS (%) | AUC | Testing Time (s) |
|---|---|---|---|---|---|
| AlexNet | |||||
| ResNet | |||||
| DenseNet | |||||
| Inception v3 | |||||
| NasNet | |||||
| IMNet A | |||||
| IMNet | |||||
| IMNet | |||||
| IMNet | |||||
| IMNet |
| Model | BACC (%) | SPEC (%) | SENS (%) | AUC | Testing Time (s) |
|---|---|---|---|---|---|
| AlexNet | |||||
| ResNet | |||||
| DenseNet | |||||
| Inception v3 | |||||
| NasNet | |||||
| IMNet A | |||||
| IMNet | |||||
| IMNet | |||||
| IMNet | |||||
| IMNet |
| Model | Total Parameters | MAdd |
|---|---|---|
| AlexNet | 61.10M | 0.72G |
| ResNet | 25.56M | 3.87G |
| Inception v3 | 27.16M | 5.72G |
| DenseNet | 20.01M | 4.29G |
| NasNet | 5.290M | 4.93G |
| IMNet A | 0.018M | 0.0099G |
| IMNet | 0.390M | 0.0218G |
| IMNet | 0.412M | 0.0229G |
| IMNet | 0.790M | 0.0666G |
| IMNet | 0.955M | 0.0804G |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, R.; Hardie, R.C.; Narayanan, B.N.; Kebede, T.M. IMNets: Deep Learning Using an Incremental Modular Network Synthesis Approach for Medical Imaging Applications. Appl. Sci. 2022, 12, 5500. https://doi.org/10.3390/app12115500
Ali R, Hardie RC, Narayanan BN, Kebede TM. IMNets: Deep Learning Using an Incremental Modular Network Synthesis Approach for Medical Imaging Applications. Applied Sciences. 2022; 12(11):5500. https://doi.org/10.3390/app12115500
Chicago/Turabian StyleAli, Redha, Russell C. Hardie, Barath Narayanan Narayanan, and Temesguen M. Kebede. 2022. "IMNets: Deep Learning Using an Incremental Modular Network Synthesis Approach for Medical Imaging Applications" Applied Sciences 12, no. 11: 5500. https://doi.org/10.3390/app12115500
APA StyleAli, R., Hardie, R. C., Narayanan, B. N., & Kebede, T. M. (2022). IMNets: Deep Learning Using an Incremental Modular Network Synthesis Approach for Medical Imaging Applications. Applied Sciences, 12(11), 5500. https://doi.org/10.3390/app12115500