
A Fast Identification Method of Gunshot Types Based on Knowledge Distillation




Abstract
:1. Introduction
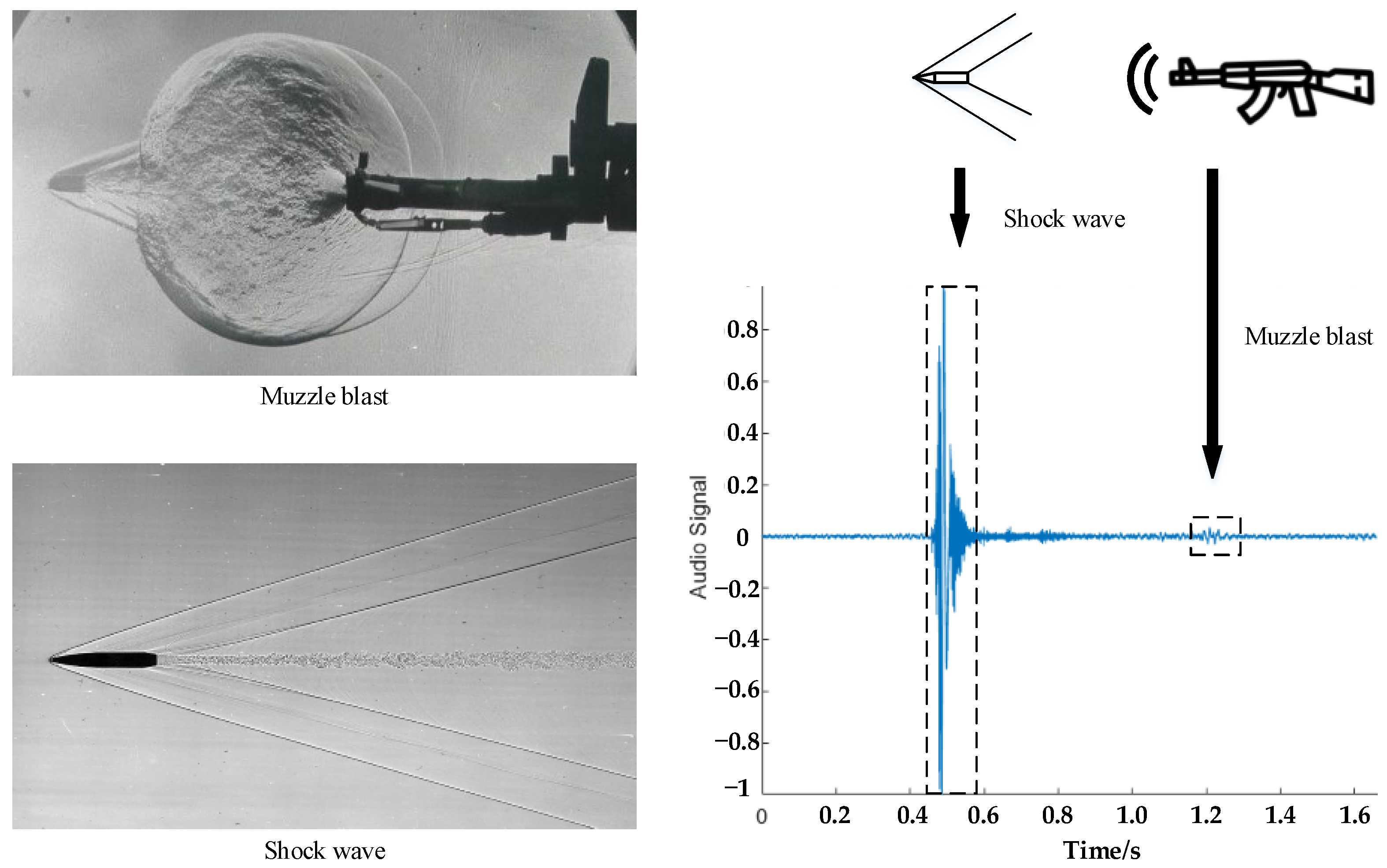
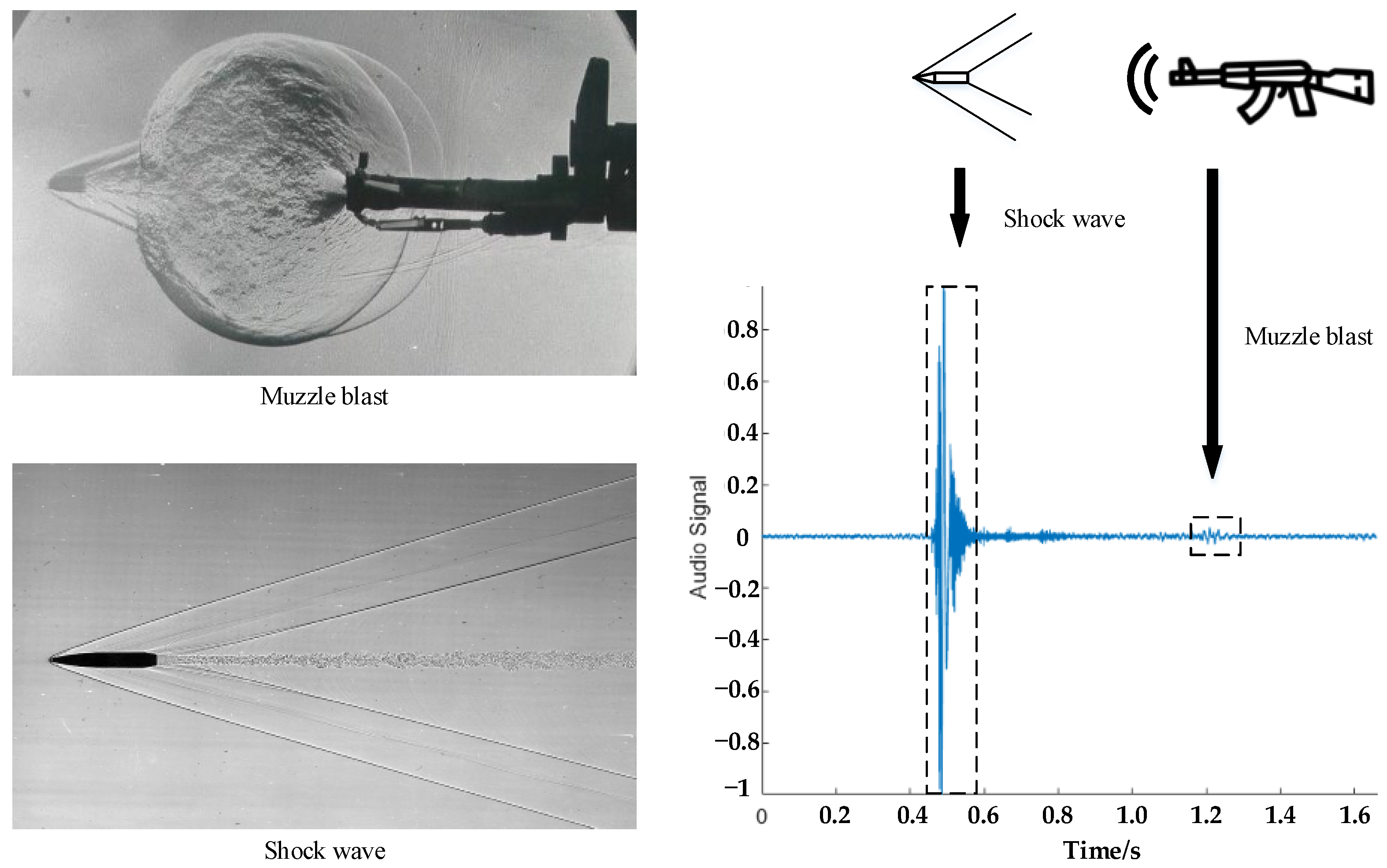
2. Principles Relating to Sniper Gunshot Recognition
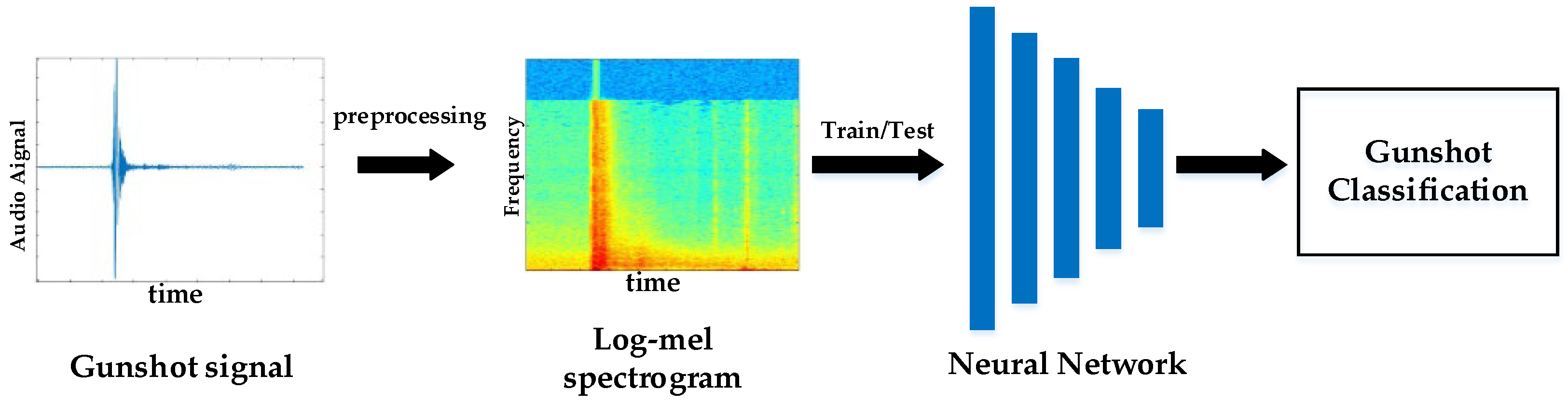
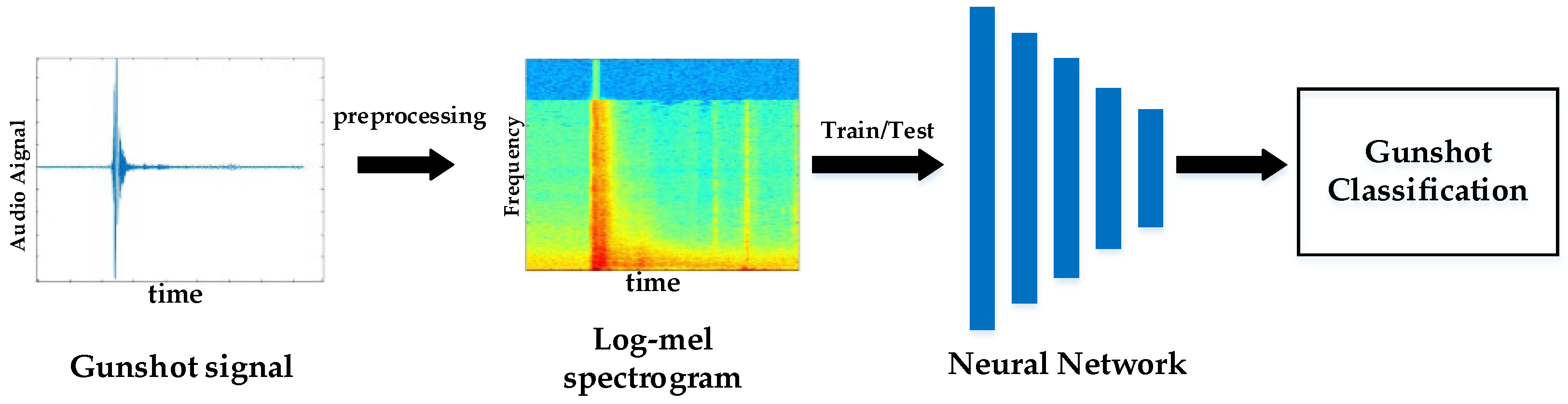
3. Design of the Gunshot Recognition Network
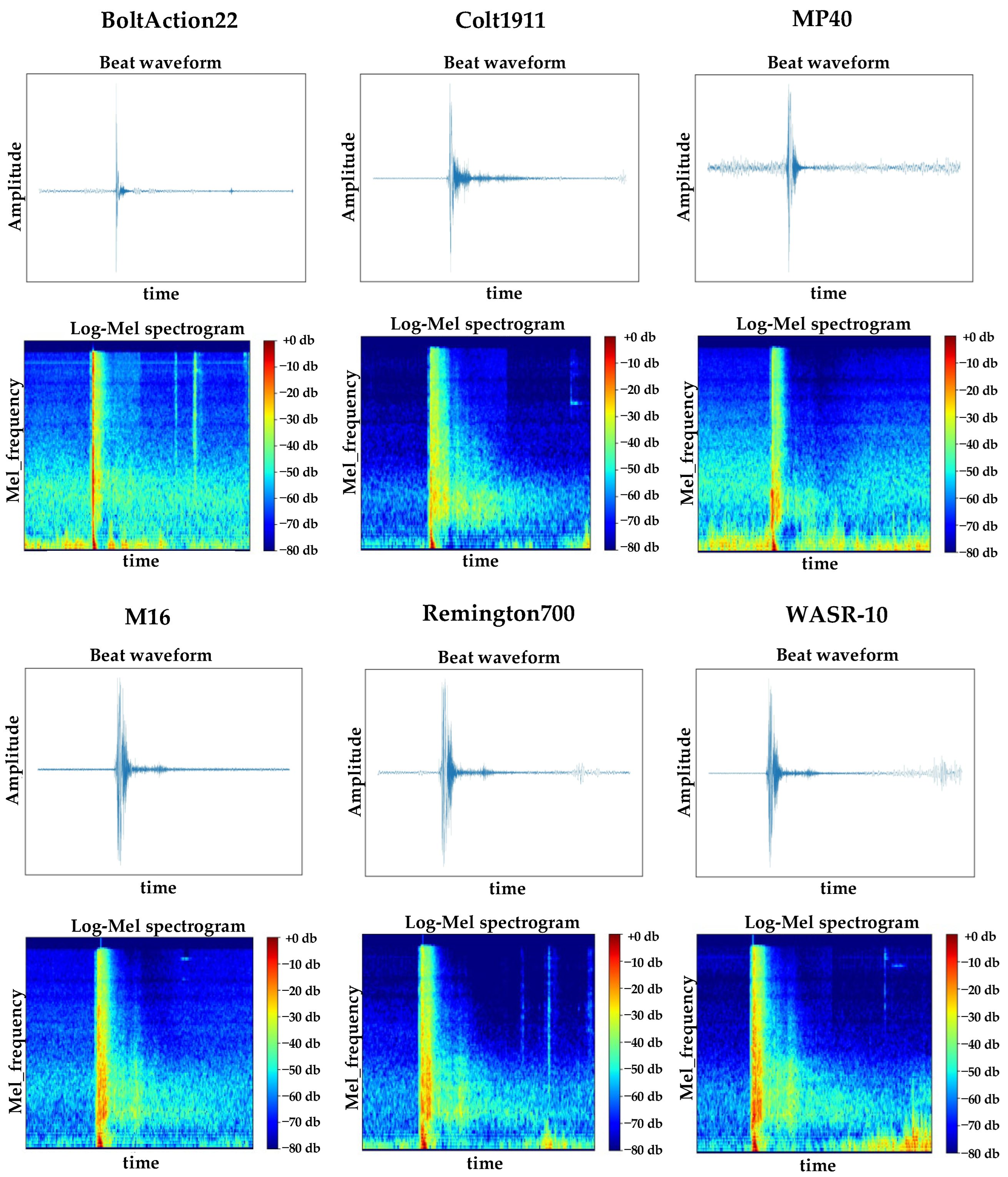
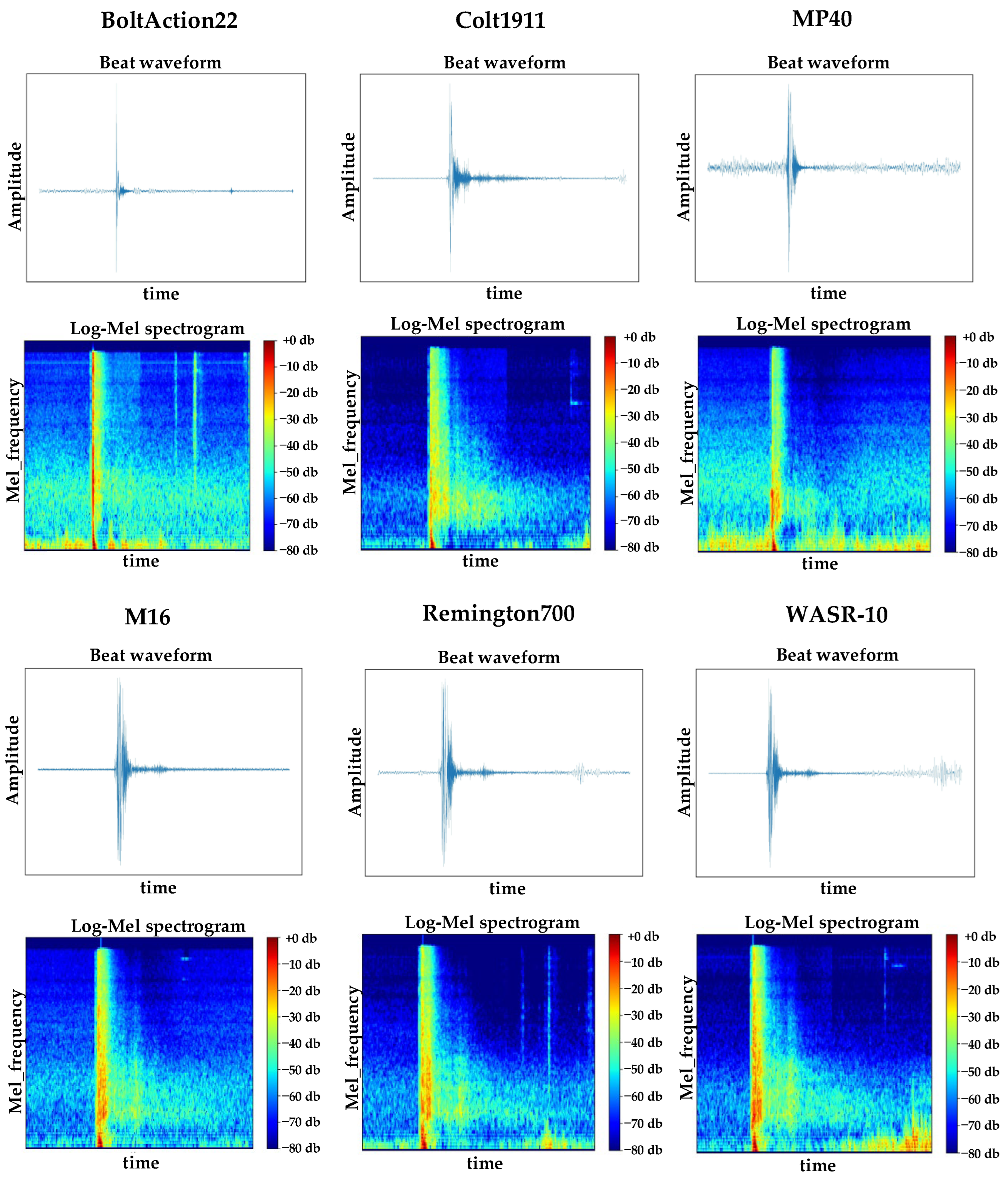
3.1. Gunshot Preprocessing
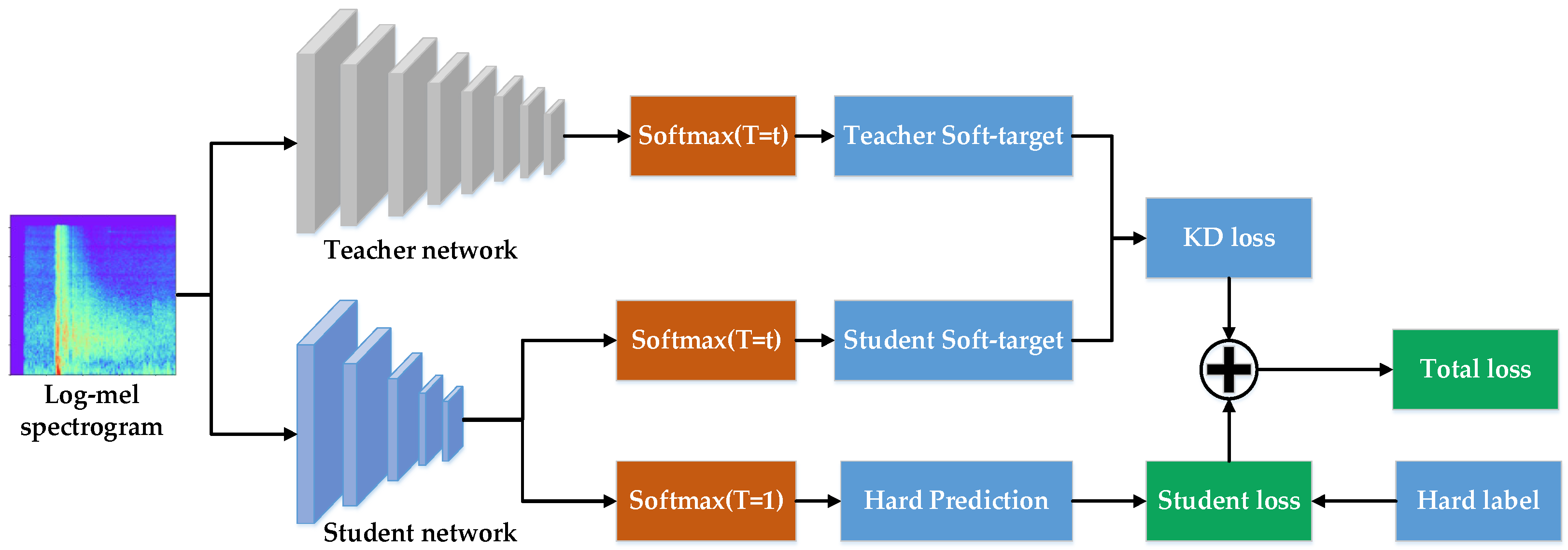
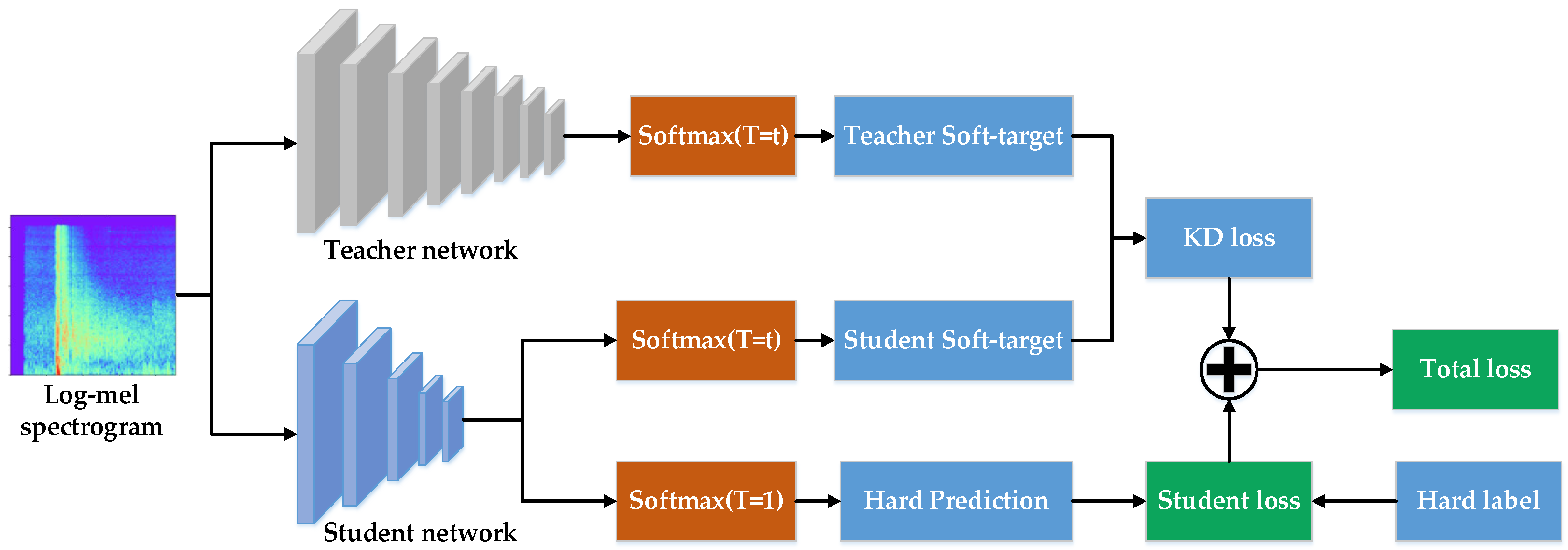
3.2. The Gunshot Recognition Network Based on Knowledge Distillation
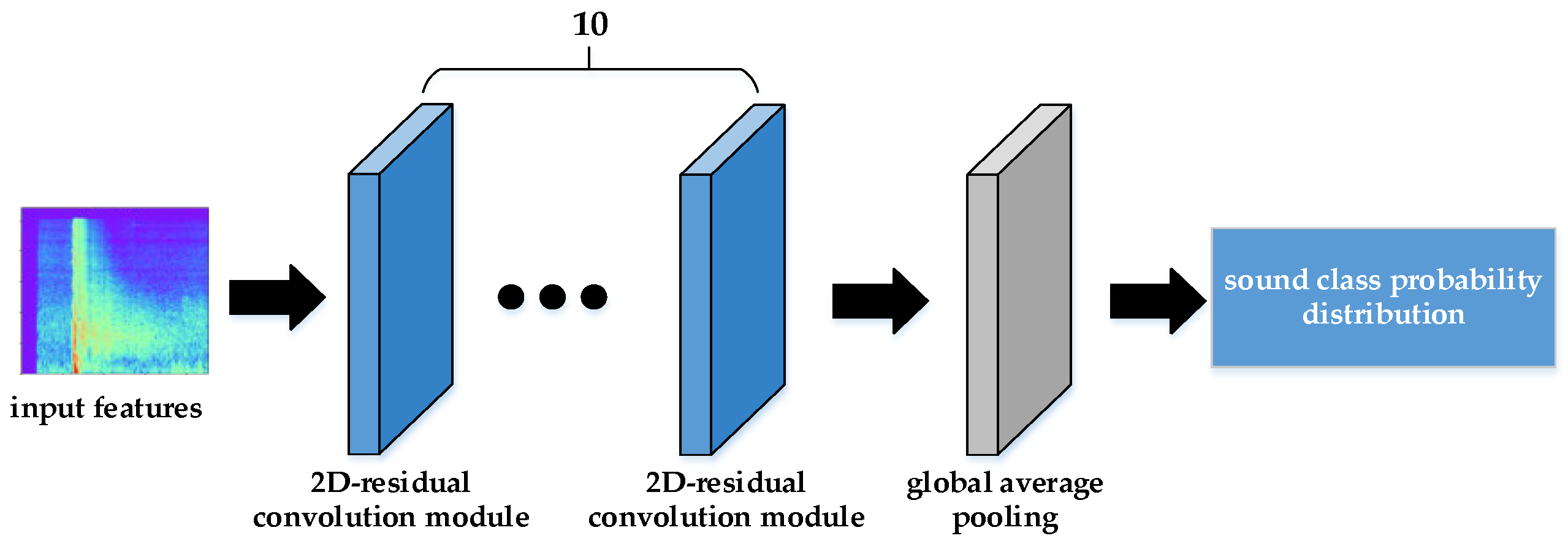
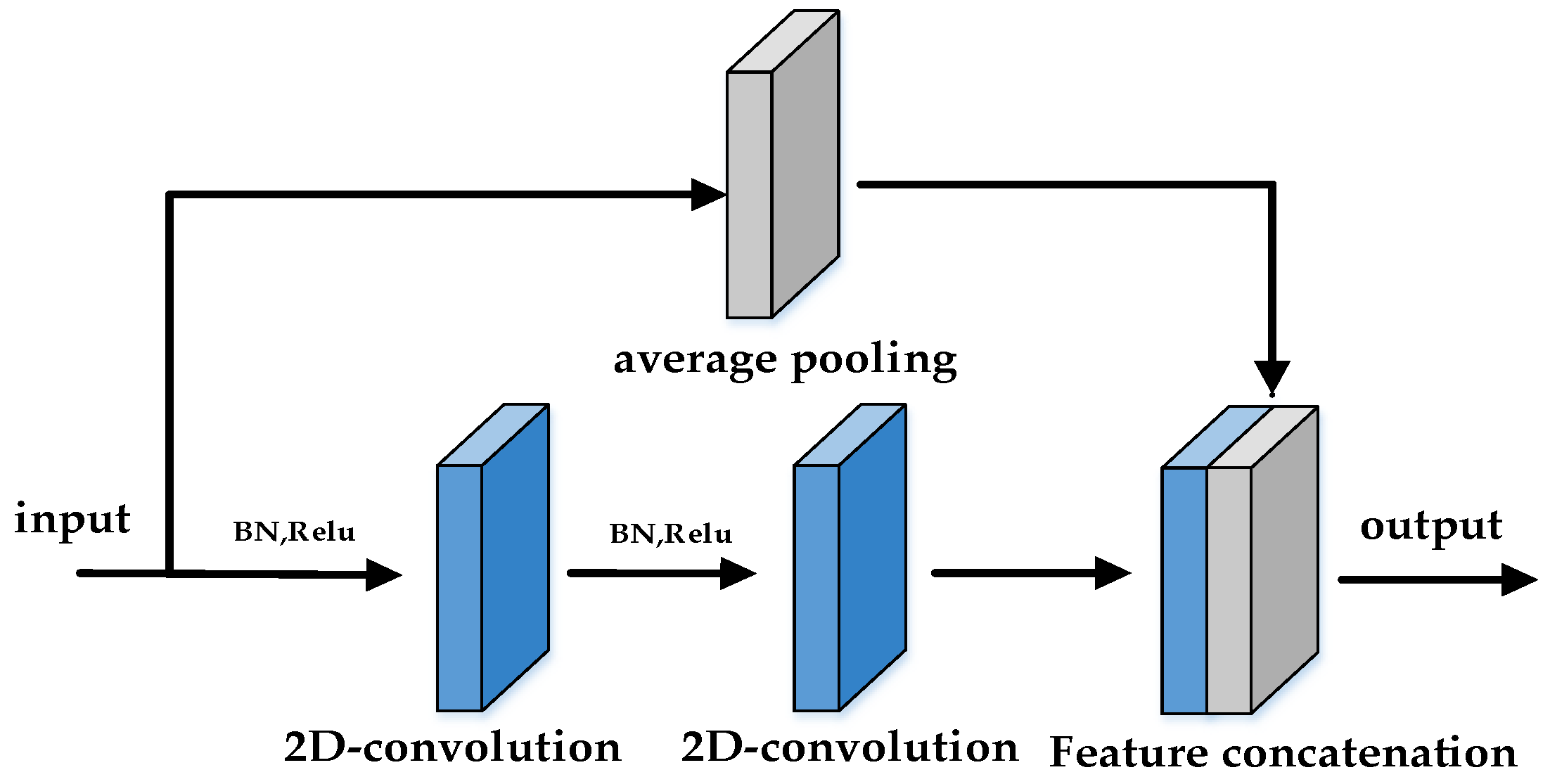
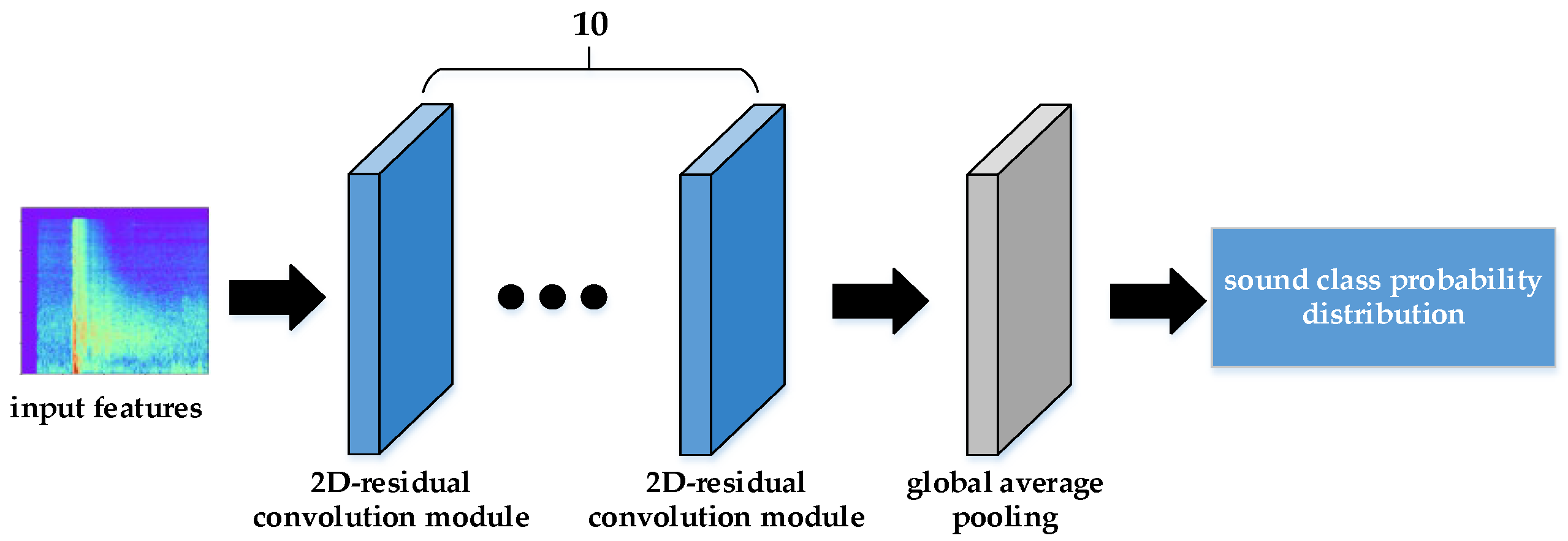
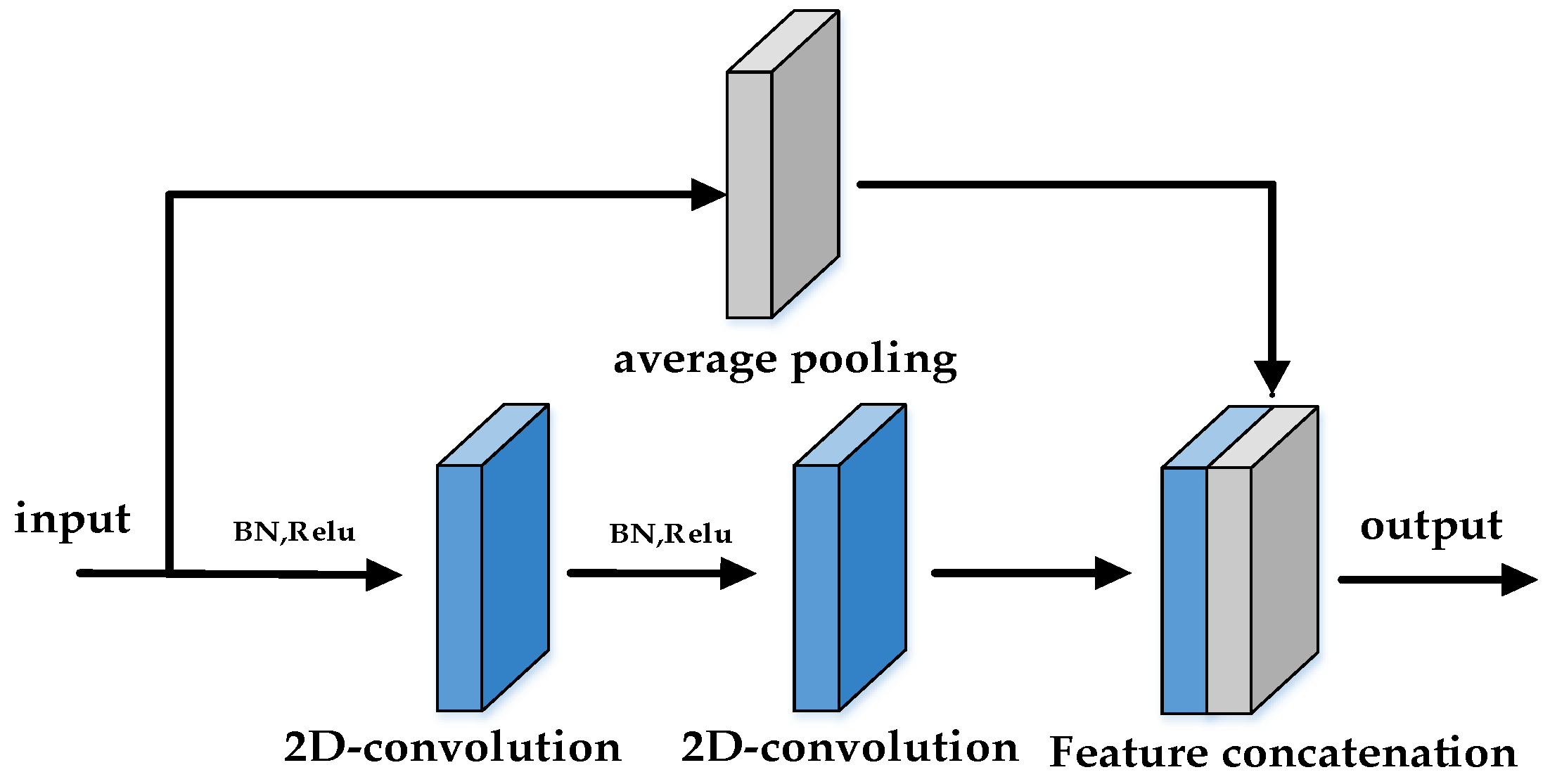
3.2.1. Teacher Network
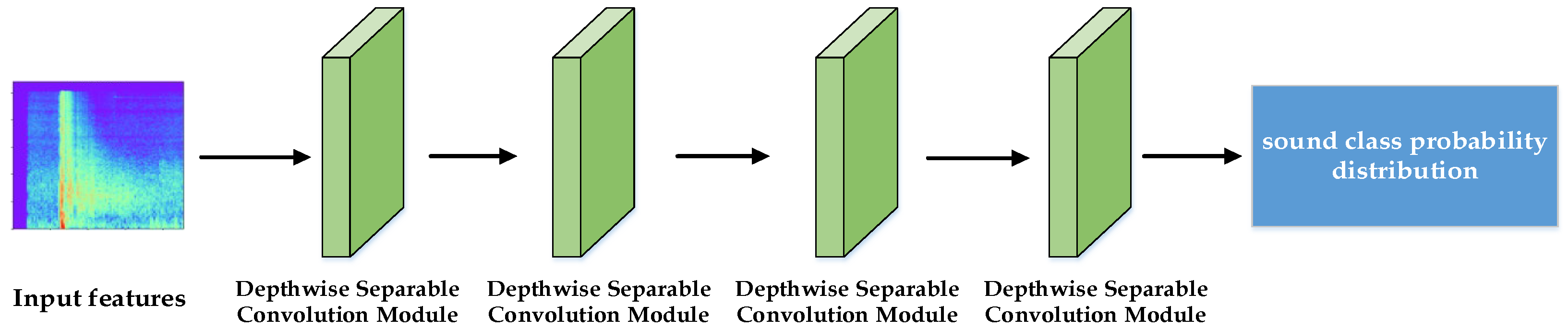
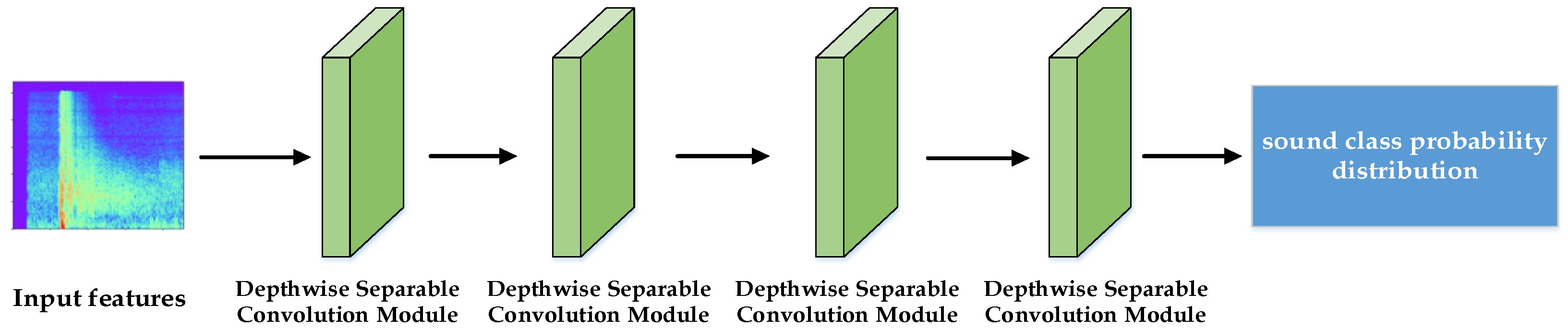
3.2.2. Student Network
3.2.3. Loss Function
3.2.4. Network Training Method
4. Experimental Verification
4.1. Dataset
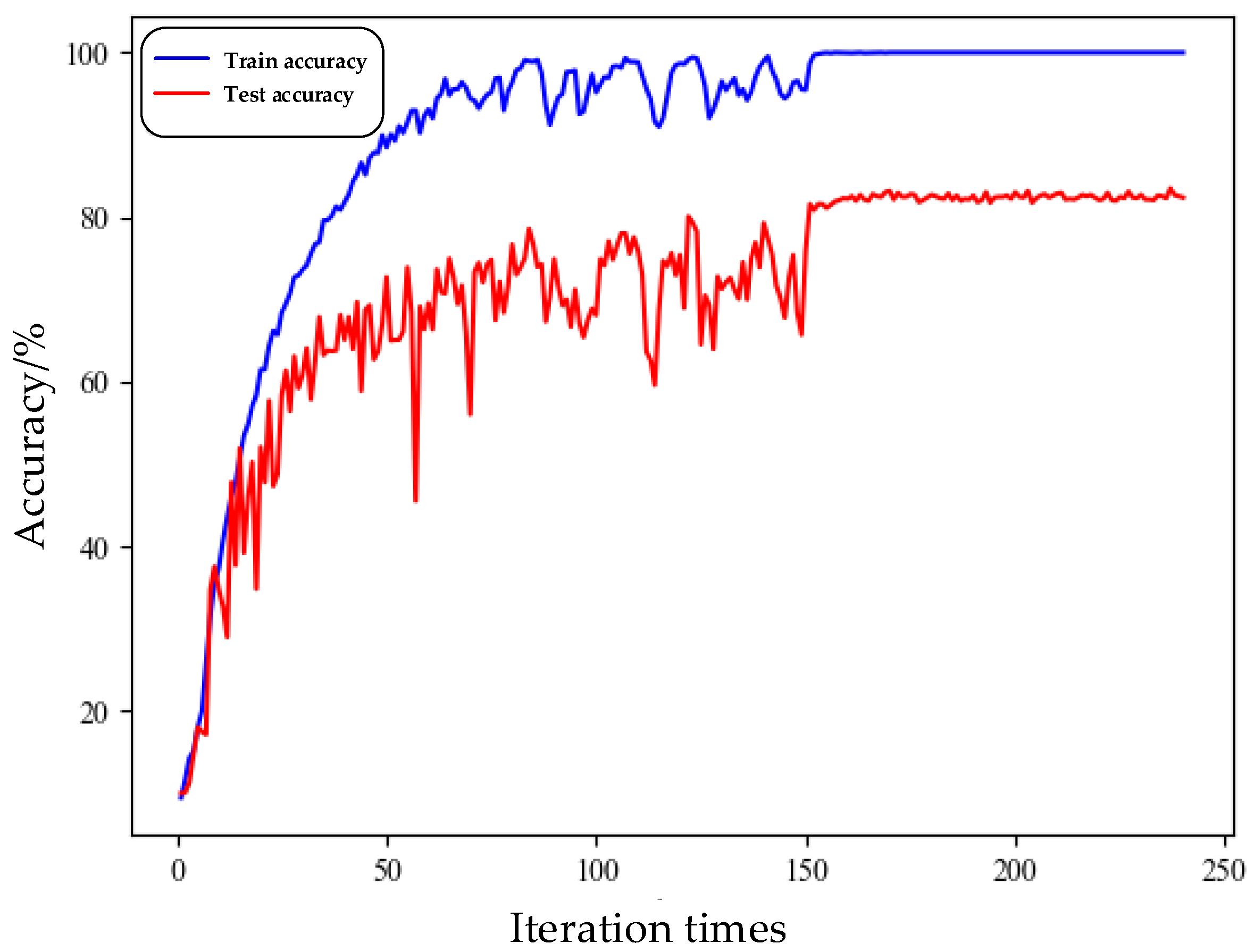
4.2. Network Training
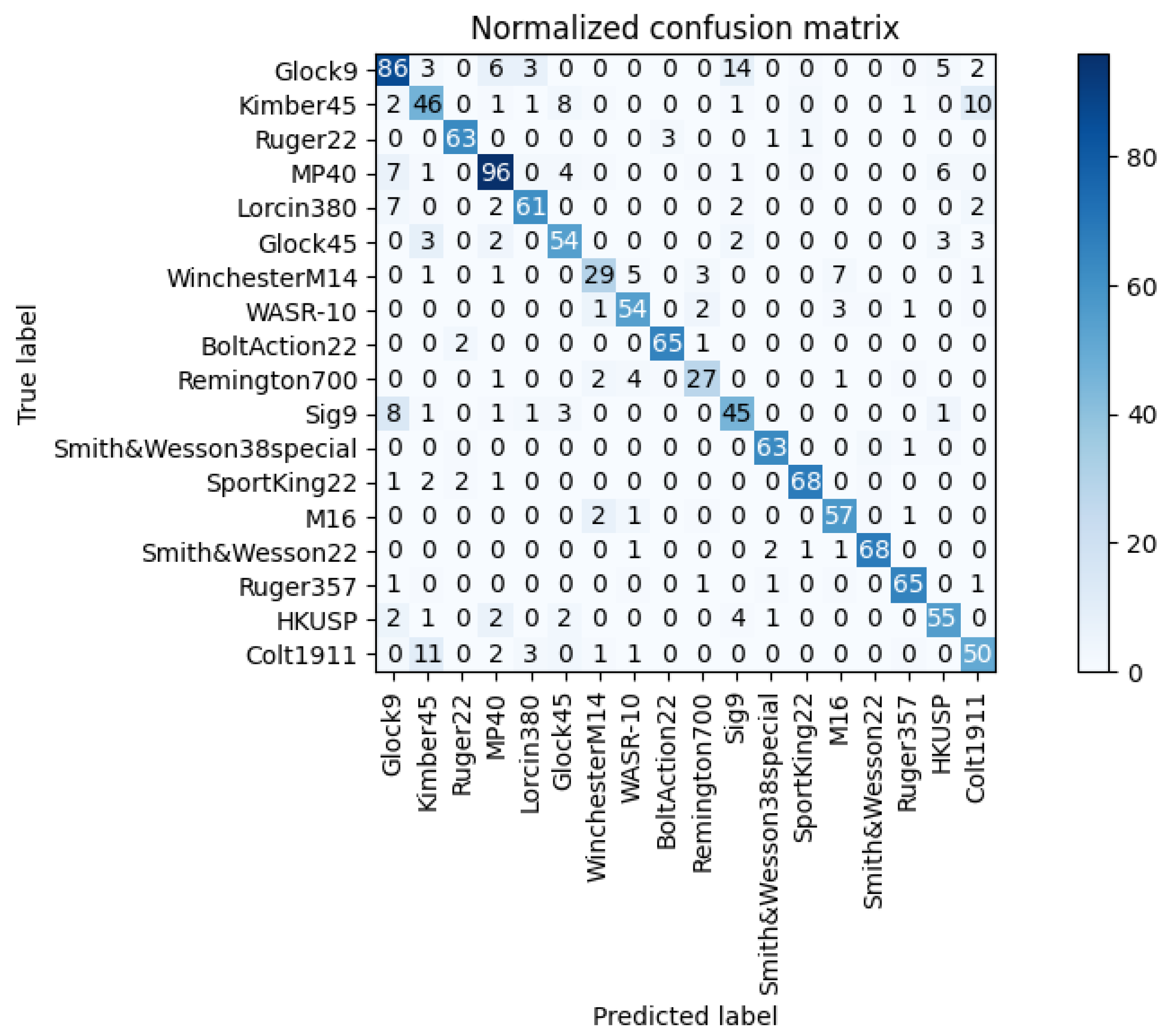
4.3. Experimental Results and Interpretation
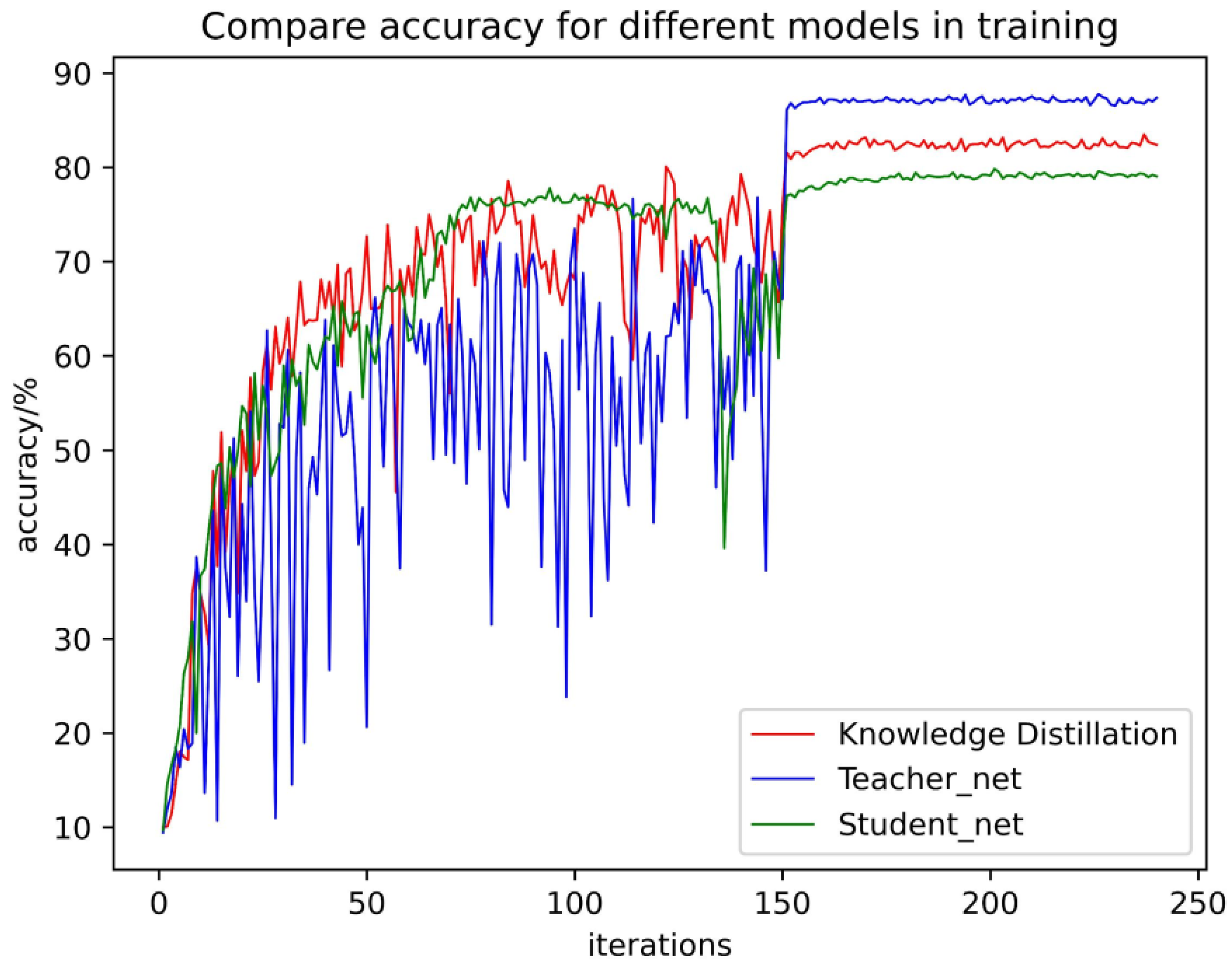
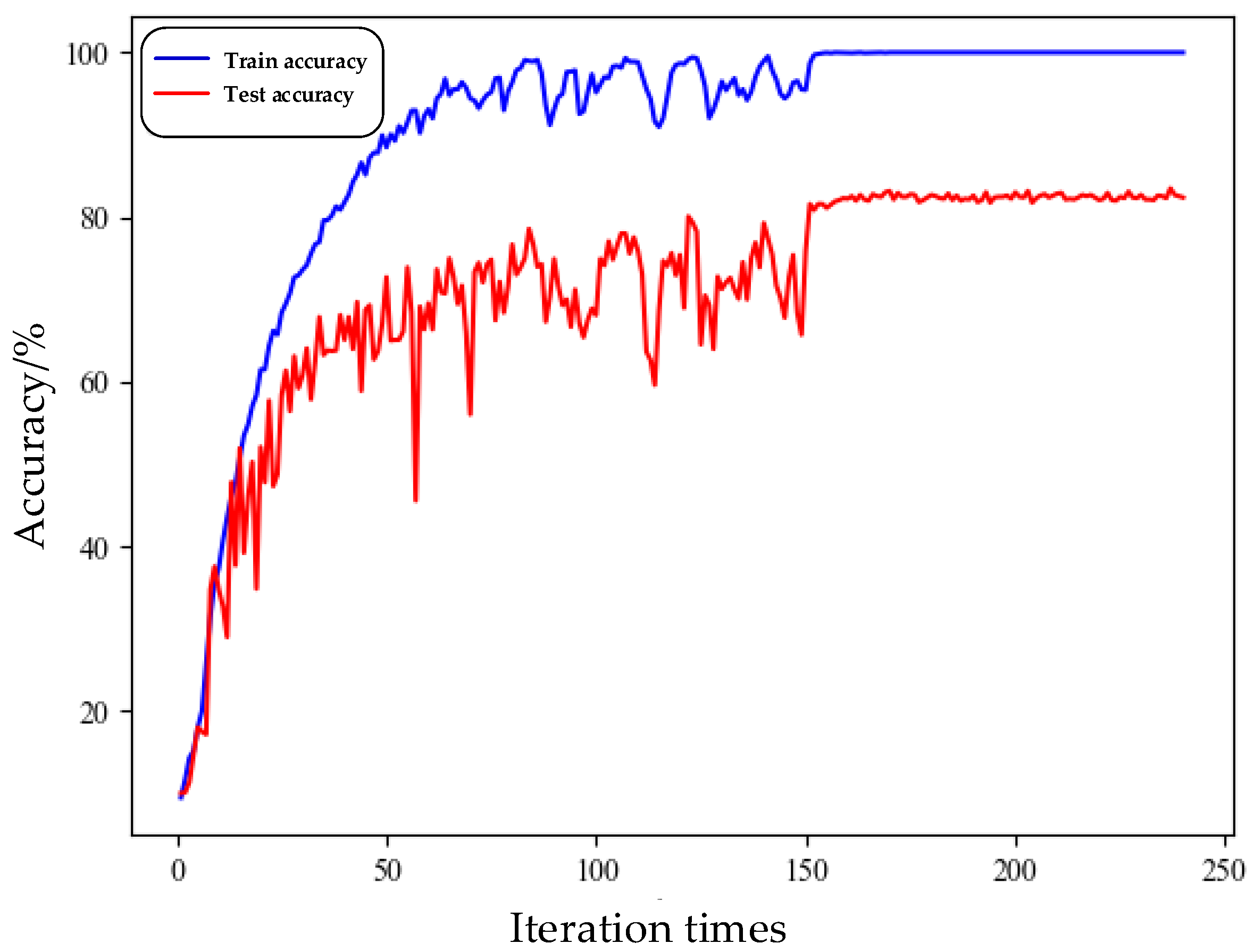
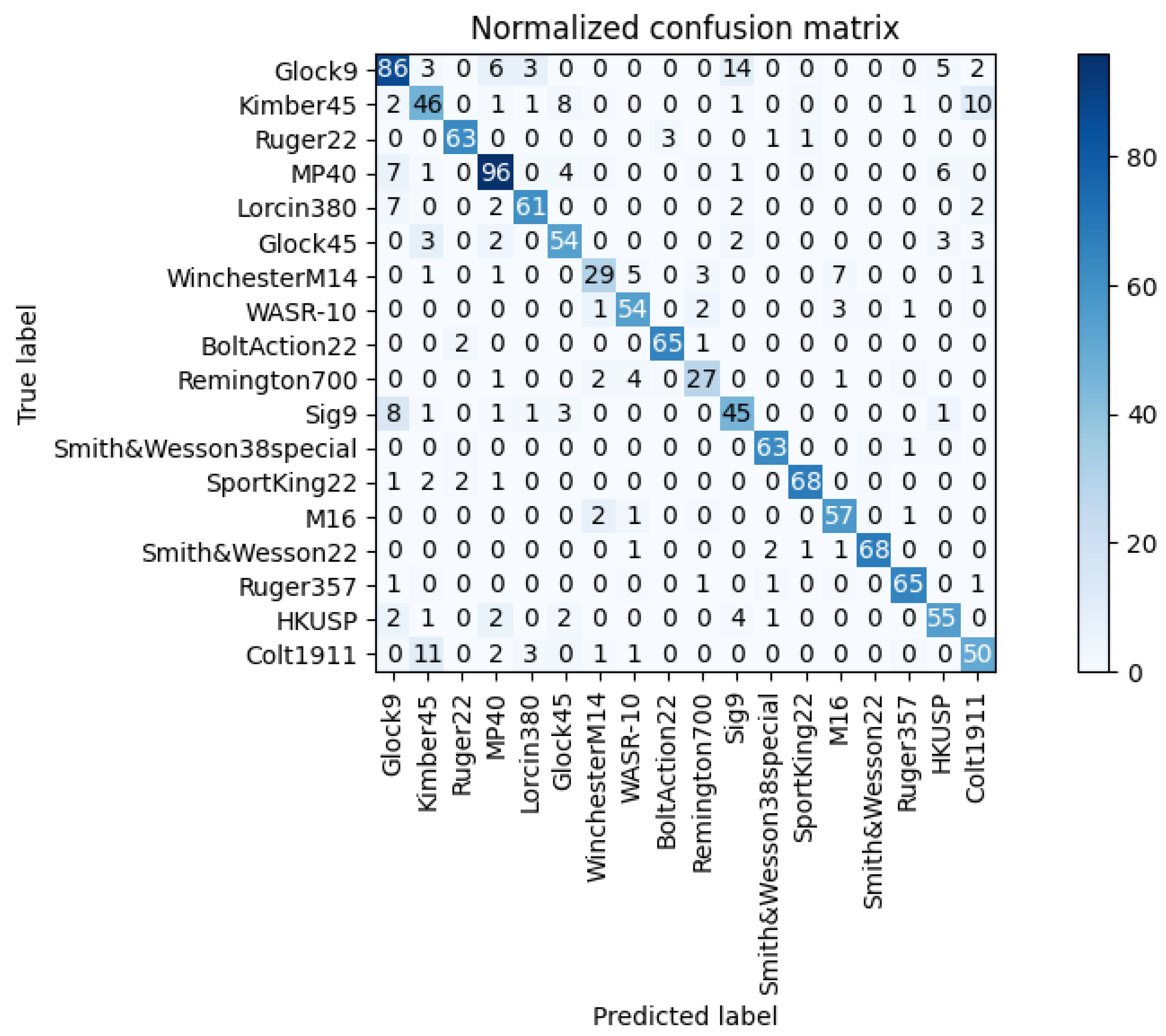
4.3.1. Performance Analysis of the Knowledge Distillation Network
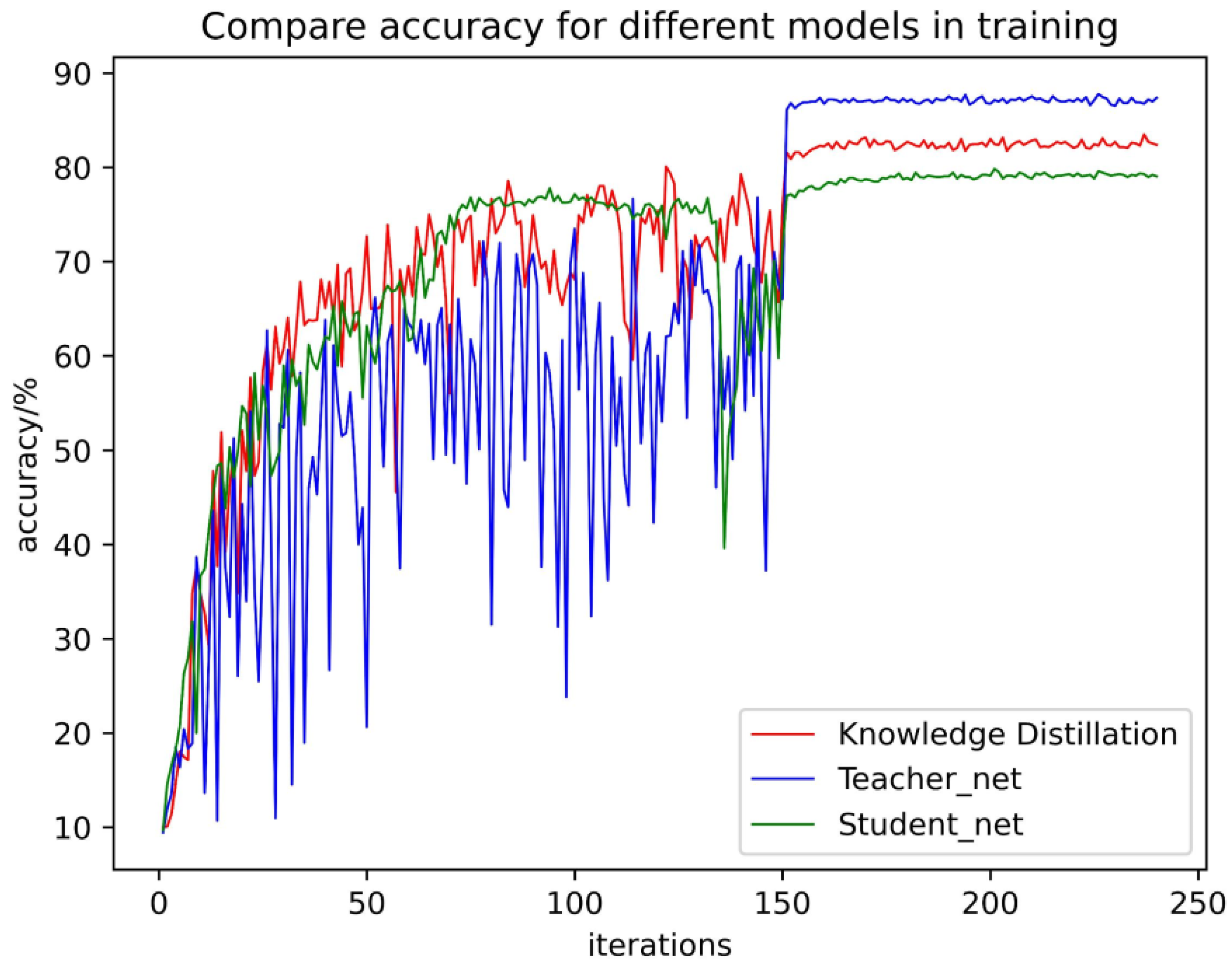
4.3.2. Comparison of the Combined Performance of the Teacher Network and the Student Network
4.3.3. Ablation Experiment
4.3.4. Performance Comparison with Other Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Begault, D.R.; Beck, S.D.; Maher, R.C. Overview of forensic audio gunshot analysis techniques. In Proceedings of the Audio Engineering Society Conference: 2019 AES International Conference on Audio Forensics, Porto, Portugal, 18–20 June 2019. [Google Scholar]
- Busse, C.; Krause, T.; Ostermann, J.; Bitzer, J. Improved Gunshot Classification by Using Artificial Data. In Proceedings of the Audio Engineering Society Conference: 2019 AES International Conference on Audio Forensics, Porto, Portugal, 18–20 June 2019. [Google Scholar]
- Ahmed, T.; Uppal, M.; Muhammad, A. Improving efficiency and reliability of gunshot detection systems. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Djeddou, M.; Touhami, T. Classification and modeling of acoustic gunshot signatures. Arab. J. Sci. Eng. 2013, 38, 3399–3406. [Google Scholar] [CrossRef]
- Khan, S.; Divakaran, A.; Sawhney, H.S. Weapon identification across varying acoustic conditions using an exemplar embedding approach. In Proceedings of the Sensors, and Command, Control, Communications, and Intelligence (C3I) Technologies for Homeland Security and Homeland Defense IX, Orlando, FL, USA, 5–9 April 2010. [Google Scholar]
- Kiktova, E.; Lojka, M.; Pleva, M.; Juhar, J.; Cizmar, A. Gun type recognition from gunshot audio recordings. In Proceedings of the 3rd International Workshop on Biometrics and Forensics (IWBF 2015), Gjovik, Norway, 3–4 March 2015. [Google Scholar]
- Lilien, R. Development of Computational Methods for the Audio Analysis of Gunshots; NCJRS; 2016-DN-BX-0183; National Institute of Justice: Washington, DC, USA, 2018.
- Raponi, S.; Ali, I.; Oligeri, G. Sound of Guns: Digital Forensics of Gun Audio Samples meets Artificial Intelligence. arXiv 2020, arXiv:2004.07948. [Google Scholar] [CrossRef]
- Arslan, Y. Impulsive Sound Detection by a Novel Energy Formula and Its Usage for Gunshot Recognition. arXiv 2017, arXiv:1706.08759. [Google Scholar]
- Hawthorne, D.L.; Horn, W.; Reinke, D.C. A system for acoustic detection, classification, and localization of terrestrial animals in remote locations. J. Acoust. Soc. Am. 2016, 140, 3182. [Google Scholar] [CrossRef]
- Austin, M.E. On the Frequency Spectrum of N-Waves. J. Acoust. Soc. Am. 1967, 41, 528. [Google Scholar] [CrossRef]
- Nimmy, P.; Rajesh, K.R.; Nimmy, M.; Vishnu, S. Shock Wave and Muzzle Blast Identification Techniques Utilizing Temporal and Spectral Aspects of Gunshot Signal. In Proceedings of the 2018 IEEE Recent Advances in Intelligent Computational Systems (RAICS), Thiruvananthapuram, India, 6–8 December 2018. [Google Scholar]
- Maher, R.C. Modeling and Signal Processing of Acoustic Gunshot Recordings. In Proceedings of the 2006 IEEE 12th Digital Signal Processing Workshop & 4th IEEE Signal Processing Education Workshop, Teton National Park, WY, USA, 24–27 September 2006; Volume 4, pp. 257–261. [Google Scholar]
- Libal, U.; Spyra, K. Wavelet based shock wave and muzzle blast classification for different supersonic projectiles. Expert Syst. Appl. 2014, 41, 5097–5104. [Google Scholar] [CrossRef]
- Aguilar, J. Gunshot Detection Systems in Civilian Law Enforcement. J. Audio Eng. Soc. 2015, 63, 280–291. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. Comput. Sci. 2015, 14, 38–39. [Google Scholar]
- Li, C.; Li, S.; Gao, Y.; Zhang, X.; Li, W. A Two-stream Neural Network for Pose-based Hand Gesture Recognition. IEEE Trans. Cogn. Dev. Syst. 2021, 1–10. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Gemmeke, J.F.; Ellis, D.P.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio Set: An ontology and humanlabeled dataset for audio events. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar]
- Sánchez-Hevia, H.A.; Ayllón, D.; Gil-Pita, R.; Rosa-Zurera, M. Maximum likelihood decision fusion for weapon classification in wireless acoustic sensor networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1172–1182. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2016, arXiv:1512.03385. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2018, arXiv:1801.04381. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Short-Time Fourier Transform | Mel Transform | |||
|---|---|---|---|---|
| Frame Length | Frame Shift | FFT Points | Window Type | Number of Mel Filters |
| 2048 | 1024 | 1024 | Hamming | 128 |
| Module | Operate | Kernel Size | Output Size |
|---|---|---|---|
| 2D Residual Module 1 | Conv_layer1 | 3 × 3 × 1 | 128 × 256 × 1 |
| Conv_layer2 | 3 × 3 × 1 | 128 × 256 × 1 | |
| 2D Residual Module 2 | Conv_layer3 | 3 × 3 × 2 | 64 × 128 × 2 |
| Conv_layer4 | 3 × 3 × 2 | 64 × 128 × 2 | |
| 2D Residual Module 3 | Conv_layer5 | 3 × 3 × 4 | 64 × 128 × 4 |
| Conv_layer6 | 3 × 3 × 4 | 64 × 128 × 4 | |
| 2D Residual Module 4 | Conv_layer7 | 3 × 3 × 8 | 32 × 64 × 8 |
| Conv_layer8 | 3 × 3 × 8 | 32 × 64 × 8 | |
| 2D Residual Module 5 | Conv_layer9 | 3 × 3 × 16 | 32 × 64 × 16 |
| Conv_layer10 | 3 × 3 × 16 | 32 × 64 × 16 | |
| 2D Residual Module 6 | Conv_layer11 | 3 × 3 × 32 | 16 × 32 × 32 |
| Conv_layer12 | 3 × 3 × 32 | 16 × 32 × 32 | |
| 2D Residual Module 7 | Conv_layer13 | 3 × 3 × 64 | 16 × 32 × 64 |
| Conv_layer14 | 3 × 3 × 64 | 16 × 32 × 64 | |
| 2D Residual Module 8 | Conv_layer15 | 3 × 3 × 128 | 8 × 16 × 128 |
| Conv_layer16 | 3 × 3 × 128 | 8 × 16 × 128 | |
| 2D Residual Module 9 | Conv_layer17 | 3 × 3 × 256 | 8 × 16 × 256 |
| Conv_layer18 | 3 × 3 × 256 | 8 × 16 × 256 | |
| 2D Residual Module 10 | Conv_layer19 | 3 × 3 × 512 | 4 × 8 × 512 |
| Conv_layer20 | 3 × 3 × 512 | 4 × 8 × 512 | |
| Global average pooling layer | Conv_layer21 | 3 × 3 × classes | 4 × 8 × classes |
| Global average pooling | - | classes |
| Dataset | Sample Size |
|---|---|
| AudioSet | 2.1 million audio samples, 527 sound categories |
| YouTube Gunshots Dataset | 840 gun sound samples, 14 gun models |
| NIJ Grant 2016-DN-BX-0183 Project Gunshots Dataset | 6000 gun samples, 18 gun models |
| Teacher Network | Student Network | Accuracy Rate (%) | Model Size |
|---|---|---|---|
| resnet32 × 4 | Resnet8 | 5.64 | 337.8 KB |
| Resnet8 × 4 | 80.44 | 4.9 MB | |
| WRN16 × 2 | 56.27 | 5.5 MB | |
| MobileNetV2 | 61.24 | 3.0 MB | |
| ShuffleV1 | 79.12 | 3.7 MB | |
| Ours | 68.16 | 2.5 MB | |
| wrn40 × 2 | Resnet8 | 6.18 | 264 KB |
| Resnet8 × 4 | 39.92 | 4.6 MB | |
| WRN16 × 2 | 71.03 | 5.5 MB | |
| MobileNetV2 | 79.52 | 4.0 MB | |
| ShuffleV1 | 82.16 | 3.5 MB | |
| Ours | 75.56 | 2.5 MB | |
| Ours | Resnet8 | 5.14 | 264 KB |
| Resnet8 × 4 | 41.21 | 4.6 MB | |
| WRN16 × 2 | 75.24 | 5.5 MB | |
| MobileNetV2 | 72.25 | 4.0 MB | |
| ShuffleV1 | 81.24 | 3.5 MB | |
| Ours | 83.49 | 2.5 MB |
| Method | YouTube Gunshot Dataset (Accuracy Rate%) | NIJ Grant Gunshot Dataset (Accuracy Rate%) | Model Size |
|---|---|---|---|
| Teacher network | 92.48 | 82.14 | 114 MB |
| Student network | 86.42 | 71.23 | 2.5 MB |
| Teacher network (Transfer Learning) | 98.4 | 87.78 | 114 MB |
| Student network (Transfer Learning) | 91.34 | 79.84 | 2.5 MB |
| Knowledge Distillation | 95.6 | 83.49 | 2.5 MB |
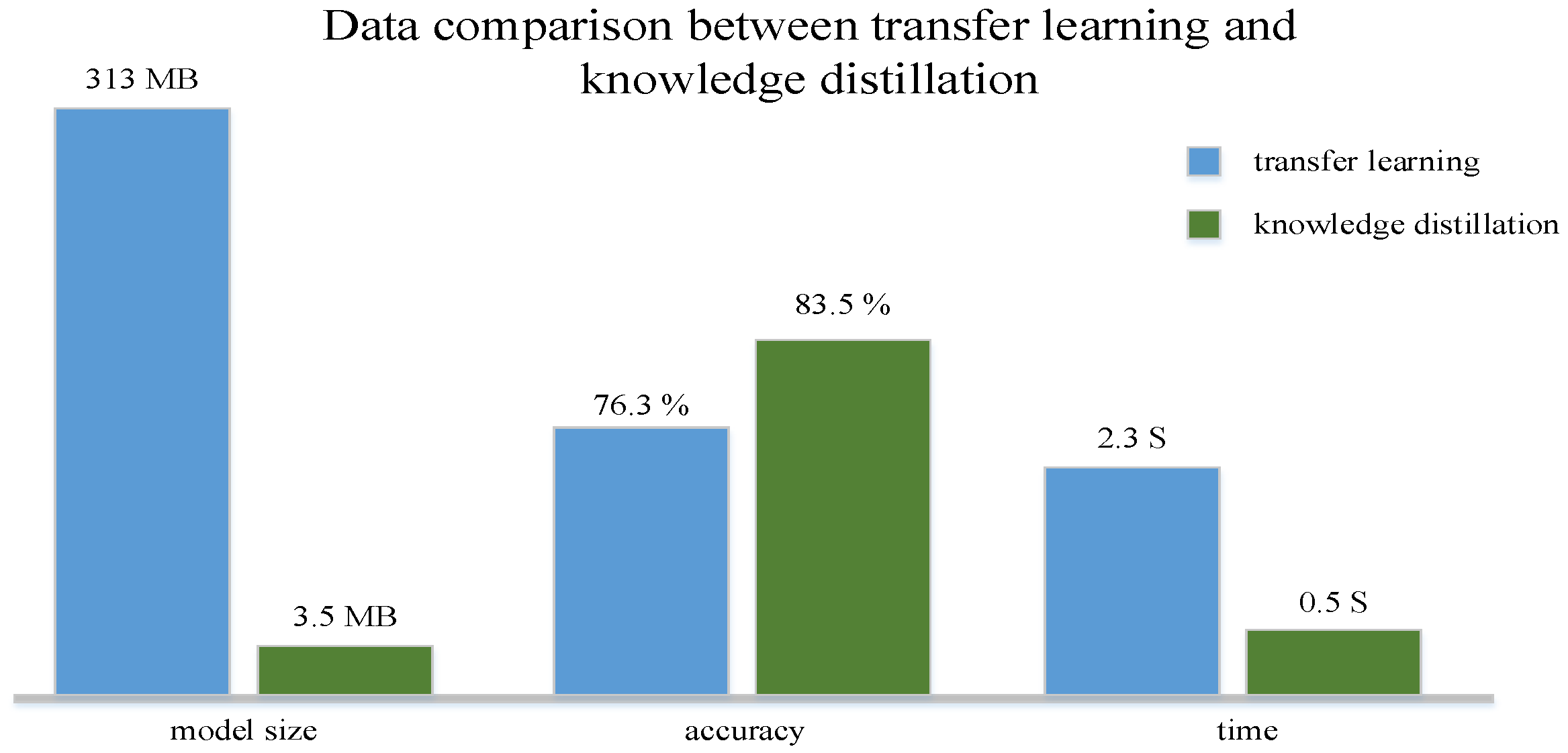
| Method | YouTube Gunshot Dataset (Accuracy Rate%) | NIJ Grant Gunshot Dataset (Accuracy Rate%) | Model Size | Speed |
|---|---|---|---|---|
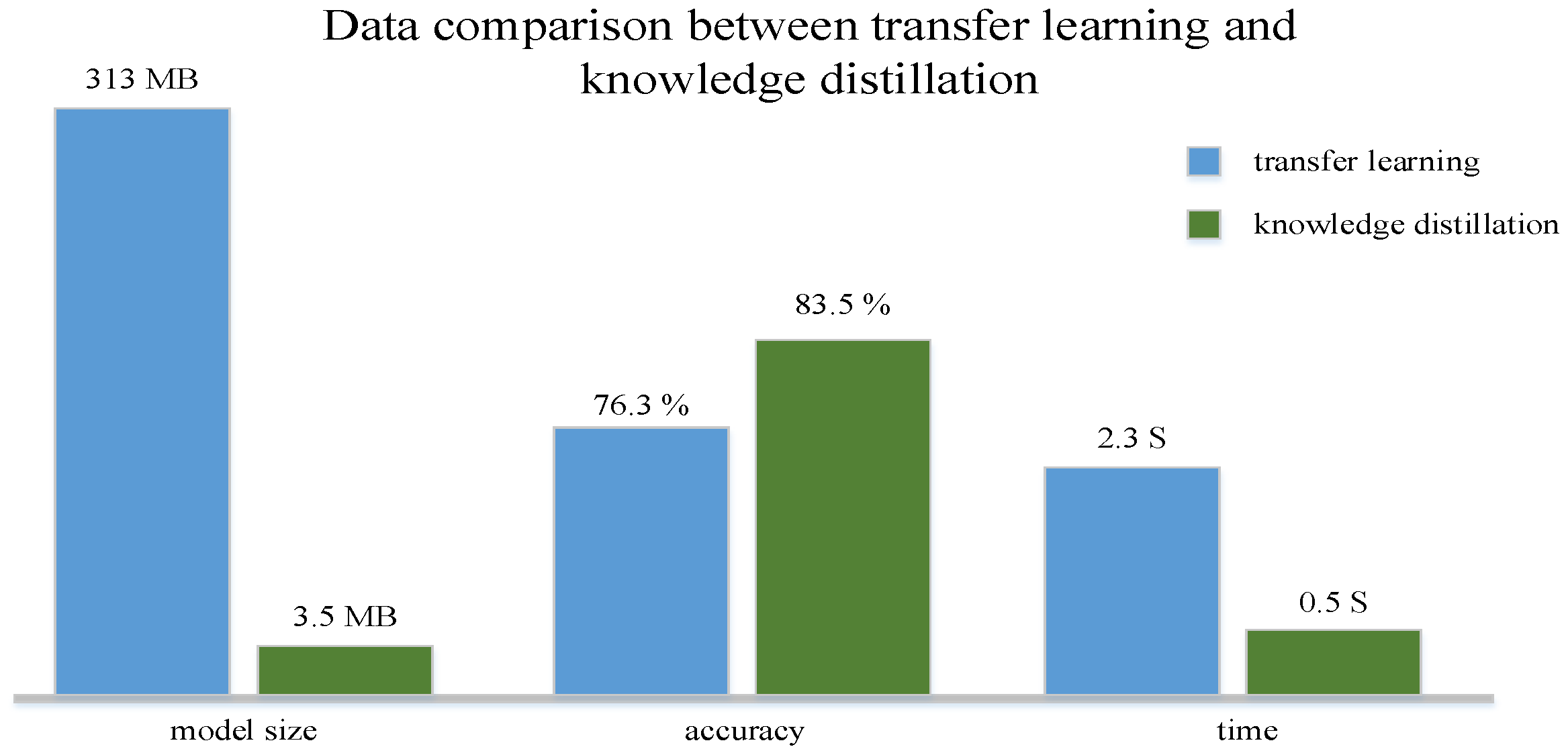
| Transfer Learning | 92.4 | 76.3 | 312 MB | 2.3 S |
| Knowledge Distillation | 95.6 | 83.5 | 2.5 MB | 0.5 S |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Guo, J.; Sun, X.; Li, C.; Meng, L. A Fast Identification Method of Gunshot Types Based on Knowledge Distillation. Appl. Sci. 2022, 12, 5526. https://doi.org/10.3390/app12115526
Li J, Guo J, Sun X, Li C, Meng L. A Fast Identification Method of Gunshot Types Based on Knowledge Distillation. Applied Sciences. 2022; 12(11):5526. https://doi.org/10.3390/app12115526
Chicago/Turabian StyleLi, Jian, Jinming Guo, Xiushan Sun, Chuankun Li, and Lingpeng Meng. 2022. "A Fast Identification Method of Gunshot Types Based on Knowledge Distillation" Applied Sciences 12, no. 11: 5526. https://doi.org/10.3390/app12115526
APA StyleLi, J., Guo, J., Sun, X., Li, C., & Meng, L. (2022). A Fast Identification Method of Gunshot Types Based on Knowledge Distillation. Applied Sciences, 12(11), 5526. https://doi.org/10.3390/app12115526