
Infrared Bird Target Detection Based on Temporal Variation Filtering and a Gaussian Heat-Map Perception Network


Abstract
:1. Introduction
- (1)
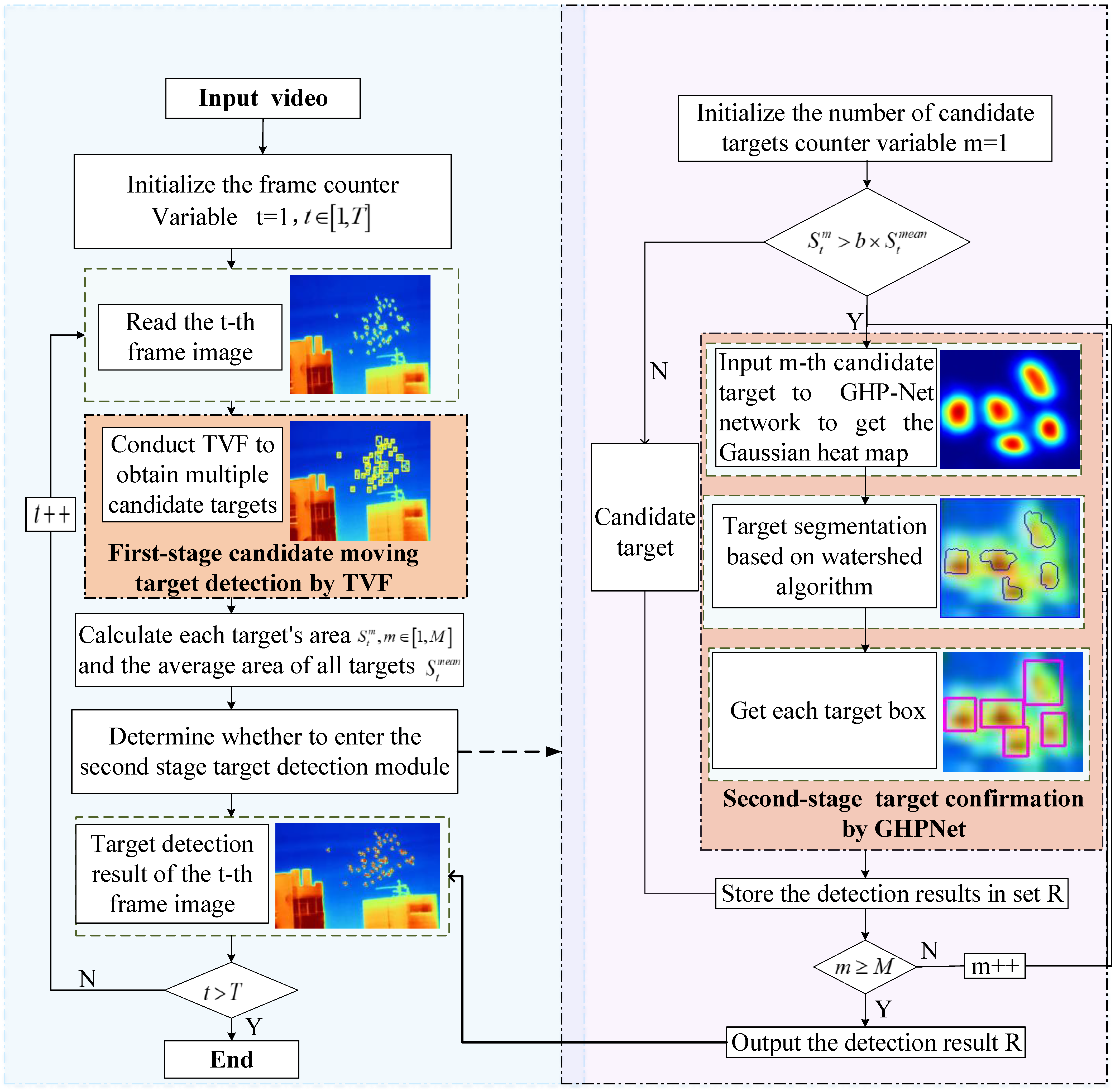
- We propose a two-stage flying bird detection method in infrared video, which consists of the pre-processing and deep learning method. The former is used for background separation, and the latter is used for re-detection of overlapping targets;
- (2)
- We propose a method for generating ground truth of bird targets, which can be automatically generated by using a size-adaptive Gaussian kernel;
- (3)
- We propose a novel Gaussian heatmap perception network (GHPNet) to predict individual birds in highly crowded and occluded scenes;
- (4)
- We replace the traditional maxpooling filter with maximum-no-pooling filtering to maintain small target features in deeper network layers, thus avoiding the loss of small objects;
- (5)
- The experimental results show that our method is not only superior to state-of-the-art methods in several infrared bird videos but also has near real-time performance.
2. The Proposed Method
2.1. TVF and Screening Candidate Targets
2.2. Gaussian Heat Map Sample Production
2.3. GHPNet Network Architecture
3. Experiments and Analysis
3.1. Datasets, Experiment Setup and Performance Evaluation
3.2. Comparisons with the Baseline Methods
3.3. Speed Analysis
3.4. Comparison and Analysis of Ablation Experiments
4. Challenges and Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dolbeer, R.; Wright, S.; Weller, J.; Begier, M. Wildlife Strikes to Civil Aircraft in the United States 1990–2013; Department of Transportation, Federal Aviation Administration and U.S. Department of Agriculture Animal and Plant Health Inspection Services: Washington, DC, USA, 2014.
- Bhusal, S.; Khanal, K.; Goel, S.; Karkee, M.; Taylor, M. Bird deterrence in a vineyard using an unmannes aerial system (UAS). Trans. ASABE 2019, 62, 561–569. [Google Scholar] [CrossRef]
- Boudaoud, L.; Maussang, F.; Garello, R.; Chevallier, A. Marine bird detection based on deep learning using high-resolution aerial images. In Proceedings of the OCEANS 2019-Marseille, Marseille, France, 17–20 June 2019. [Google Scholar]
- Hong, S.; Han, Y.; Kim, S.; Lee, A.; Kim, G. Application of deep-learning methods to bird detection using unmanned aerial vehicle imagery. Sensors 2019, 19, 1651. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, C.; Li, H.; Wei, Y.; Xia, T.; Tang, Y. A Local Contrast Method for Small Infrared Target Detection. IEEE Trans. Geosci. Remote Sens. 2013, 52, 574–581. [Google Scholar] [CrossRef]
- Han, J.; Liang, K.; Zhou, B.; Zhu, X.; Zhao, J.; Zhao, L. Infrared small target detection utilizing the multiscale relative local contrast measure. IEEE Geosci. Remote Sens. Lett. 2018, 15, 612–616. [Google Scholar] [CrossRef]
- Wu, L.; Ma, Y.; Fan, F.; Wu, M.; Huang, J. A double-neighborhood gradient method for infrared small target detection. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1476–1480. [Google Scholar] [CrossRef]
- He, Y.; Zhang, C.; Mu, Y.; Yan, T.; Chen, Z. Multiscale Local Gray Dynamic Range Method for Infrared Small-Target Detection. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1846–1850. [Google Scholar] [CrossRef]
- Wan, M.; Kan, R.; Gu, G.; Zhang, X.; Qian, W.; Chen, Q.; Yu, S. Infrared Small Moving Target Detection via Saliency Histogram and Geometrical Invariability. Appl. Sci. 2017, 7, 569. [Google Scholar] [CrossRef] [Green Version]
- Ren, X.; Wang, J.; Ma, T.; Bai, K.; Ge, M.; Wang, Y. Infrared dim and small target detection based on three-dimensional collaborative filtering and spatial inversion modeling. Infrared Phys. Technol. 2019, 101, 13–24. [Google Scholar] [CrossRef]
- Han, J.; Moradi, S.; Faramarzi, I.; Liu, C.; Zhang, H.; Zhao, Q. A Local Contrast Method for Infrared Small-Target Detection Utilizing a Tri-Layer Window. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1822–1826. [Google Scholar] [CrossRef]
- Sun, S.; Kim, K.; Kim, S. Highly effificient supersonic small infrared target detection using temporal contrast fifilter. Electron. Lett. 2014, 50, 81–83. [Google Scholar]
- Deng, L.; Zhu, H.; Tao, C. Infrared moving point target detection based on spatial-temporal local contrast filter. Infrared Phys. Technol. 2016, 76, 168–173. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. NIPS 2012, 60, 1097–1105. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchiesfor accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 June 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, realtime object detection. In Proceedings of the IEEE Computer Vision Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO 9000: Better, faster, stronger. In Proceedings of the IEEE Computer Vision Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Shi, W.; Bao, S.; Tan, D. FFESSD: An Accurate and Efficient Single-Shot Detector for Target Detection. Appl. Sci. 2019, 9, 4276. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Jiang, J.; Bao, S.; Tan, D. CISPNet: Automatic Detection of Remote Sensing Images from Google Earth in Complex Scenes Based on Context Information Scene Perception. Appl. Sci. 2019, 9, 4836. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Zhao, M.; Cheng, L.; Yang, X.; Feng, P.; Liu, L.; Wu, N. TBC-Net: A real-time detector for infrared small target detection using semantic constraint. arXiv 2019, arXiv:2001.05852. [Google Scholar]
- Fang, H.; Xia, M.; Zhou, G.; Chang, Y.; Yan, L. Infrared Small UAV Target Detection Based on Residual Image Prediction via Global and Local Dilated Residual Networks. IEEE Geosci. Remote Sens. Lett. 2021, 9, 1–5. [Google Scholar] [CrossRef]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense Nested Attention Network for Infrared Small Target Detection. arXiv 2021, arXiv:2106.00487. [Google Scholar]
- Thanasutives, P.; Fukui, K.; Numao, M.; Kijsirikul, B. Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting. arXiv 2020, arXiv:2003.05586. [Google Scholar]
- Liu, W.; Salzmann, M.; Fua, P. Context-Aware Crowd Counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wu, Z.; Fuller, N.; Theriault, D.; Betke, M. A Thermal Infrared Video Benchmark for Visual Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Nayef, N.; Yin, F.; Bizid, I.; Choi, H.; Ogier, J. ICDAR2017 Robust Reading Challenge on Multi-Lingual Scene Text Detection and Script Identification-RRC-MLT. In Proceedings of the IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 1454–1459. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Layer | Parameter Setting | Output Dimension | Network Layer | Parameter Setting | Output Dimension |
|---|---|---|---|---|---|
| FE module | Conv7_x | ||||
| Conv1_x | Conv8_x | ||||
| Conv2_x | Conv9_x | ||||
| Conv3_x | Conv10_x | ||||
| Conv4_x | GHE module | ||||
| Conv5_x | Conv11_x | ||||
| MF module | |||||
| Conv6_x | |||||
| Methods | Year | Backbone | Detection (%) | ||
|---|---|---|---|---|---|
| P | R | F1 | |||
| U-Net [29] | 2015 | U-Net | 82.6 | 79.7 | 81.1 |
| Faster R-CNN [17] | 2017 | VGG16 | 80.3 | 73.4 | 76.7 |
| Mask R-CNN [18] | 2017 | ResNet-101-FPN | 83.3 | 77.9 | 80.5 |
| YOLOv4 [24] | 2020 | CSPDarknet-53 | 89.4 | 86.6 | 88.0 |
| DRU-Net [31] | 2021 | U-Net | 87.0 | 86.1 | 86.5 |
| DNA-Net [32] | 2021 | U-Net | 89.0 | 87.4 | 88.2 |
| Our method | 2022 | VGG16+U-Net | 91.2 | 89.8 | 90.5 |
| Methods | Year | Backbone | Detection(%) | ||
|---|---|---|---|---|---|
| P | R | F1 | |||
| U-Net [29] | 2015 | U-Net | 78.5 | 76.3 | 77.3 |
| Faster R-CNN [17] | 2017 | VGG16 | 75.8 | 71.0 | 73.3 |
| Mask R-CNN [18] | 2017 | ResNet-101-FPN | 80.4 | 77.6 | 79.0 |
| YOLOv4 [24] | 2020 | CSPDarknet-53 | 87.7 | 85.5 | 86.2 |
| DRU-Net [31] | 2021 | U-Net | 86.8 | 83.6 | 85.2 |
| DNA-Net [32] | 2021 | U-Net | 84.4 | 78.4 | 81.2 |
| Our method | 2022 | VGG16+U-Net | 88.3 | 87.4 | 87.8 |
| Methods | Year | F1 (%) | FPS |
|---|---|---|---|
| U-Net [29] | 2015 | 77.3 | 9 |
| Faster R-CNN [17] | 2017 | 76.7 | 7 |
| Mask R-CNN [18] | 2017 | 80.5 | 5 |
| YOLOv4 [24] | 2020 | 88.0 | 31 |
| DRU-Net [31] | 2021 | 86.5 | 5.2 |
| DNA-Net [32] | 2021 | 88.2 | 4.4 |
| Our method without convolution | 2022 | 90.5 | 18.9 |
| Our method with convolution | 2022 | 90.5 | 21.1 |
| TVF | P (%) | R (%) | F1 (%) | FPS | |
|---|---|---|---|---|---|
| Mode | |||||
| Median | 69.2 | 63.4 | 66.2 | 10 | |
| Mean | 78.0 | 72.7 | 75.3 | 71 | |
| Dataset | TVF | GHPNet without Maximum- No-Pooling | GHPNet with Maximum-No-Pooling | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|---|
| Bird | ✓ | ✕ | ✕ | 78.0 | 72.7 | 75.3 |
| ✓ | ✓ | ✕ | 90.2 | 89.0 | 89.6 | |
| ✓ | ✕ | ✓ | 91.2 | 89.8 | 90.5 | |
| TIV | ✓ | ✕ | ✕ | 77.6 | 75.4 | 76.5 |
| ✓ | ✓ | ✕ | 86.4 | 82.5 | 84.4 | |
| ✓ | ✕ | ✓ | 88.3 | 87.4 | 87.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, F.; Wei, R.; Chao, Y.; Shao, S.; Jing, C. Infrared Bird Target Detection Based on Temporal Variation Filtering and a Gaussian Heat-Map Perception Network. Appl. Sci. 2022, 12, 5679. https://doi.org/10.3390/app12115679
Zhao F, Wei R, Chao Y, Shao S, Jing C. Infrared Bird Target Detection Based on Temporal Variation Filtering and a Gaussian Heat-Map Perception Network. Applied Sciences. 2022; 12(11):5679. https://doi.org/10.3390/app12115679
Chicago/Turabian StyleZhao, Fan, Renjie Wei, Yu Chao, Sidi Shao, and Cuining Jing. 2022. "Infrared Bird Target Detection Based on Temporal Variation Filtering and a Gaussian Heat-Map Perception Network" Applied Sciences 12, no. 11: 5679. https://doi.org/10.3390/app12115679