
Effective Conversion of a Convolutional Neural Network into a Spiking Neural Network for Image Recognition Tasks


Abstract
:1. Introduction
2. Foundations of CNN–SNN Conversion and Related Works
| Algorithm 1: Basic CNN–SNN conversion procedure. |
Step1. CNN training: Train a CNN with designated constraints Step2. Weight transferring: Transfer weights from the trained CNN to an SNN with the same architecture Step3. Threshold balancing: Assign firing thresholds to spiking neurons of the SNN Step4. SNN inference preparation: Encode the input data into spike trains that are amenable to the SNN |
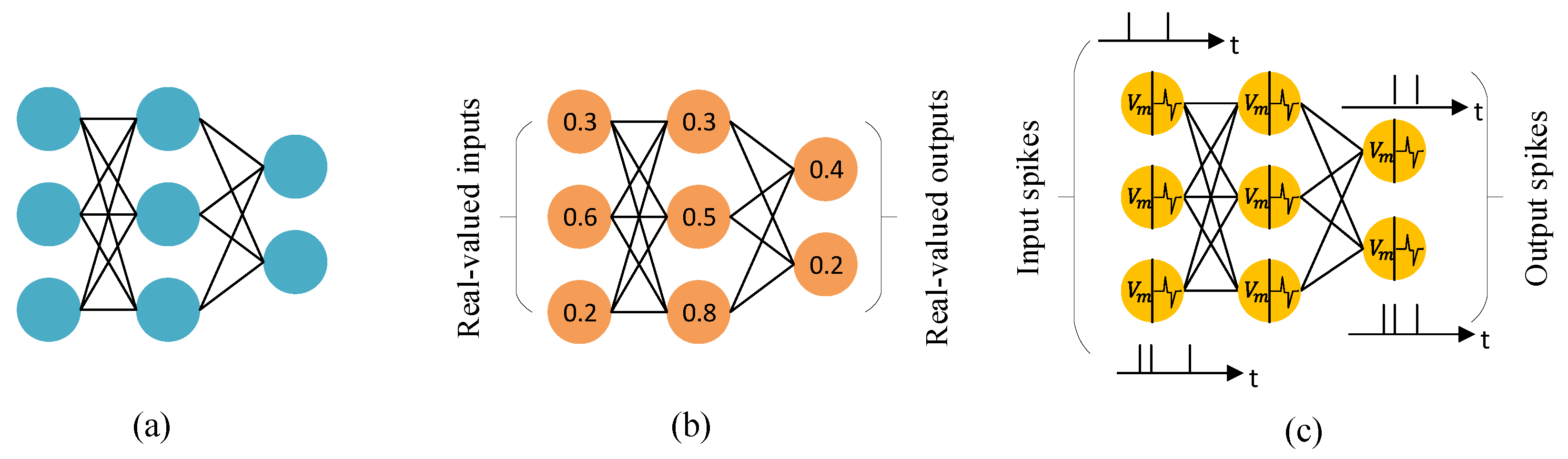
- The first factor stems from the difference in the input integration () between the CNN model and the SNN model. In the CNN, the input values x are floating-point values, while in the SNN model, the input values are represented by binary values {0,1} at each time step.
- The second factor comes from the difference in activation behavior between the neurons with the ReLU activation of the CNN model and the IF neurons of the SNN model.
- The last factor lies in the threshold balancing technique. A too-high firing threshold at each layer of the SNN yields a low firing rate for most neurons with low latency. This leads to neurons with a low firing rate, which cannot adequately contribute to the information transmission in the SNN model.
- The threshold at each layer may change in different trials due to the probabilistic nature of the input Poisson spike trains. The change of the firing threshold could affect the performance of the converted SNN model. That is, the accuracies of the converted SNN mode are different in different trials.
- The spike conversion of a very small input value can be a challenge to generate a spike train with low latency, which may cause information transmission loss in an SNN model.
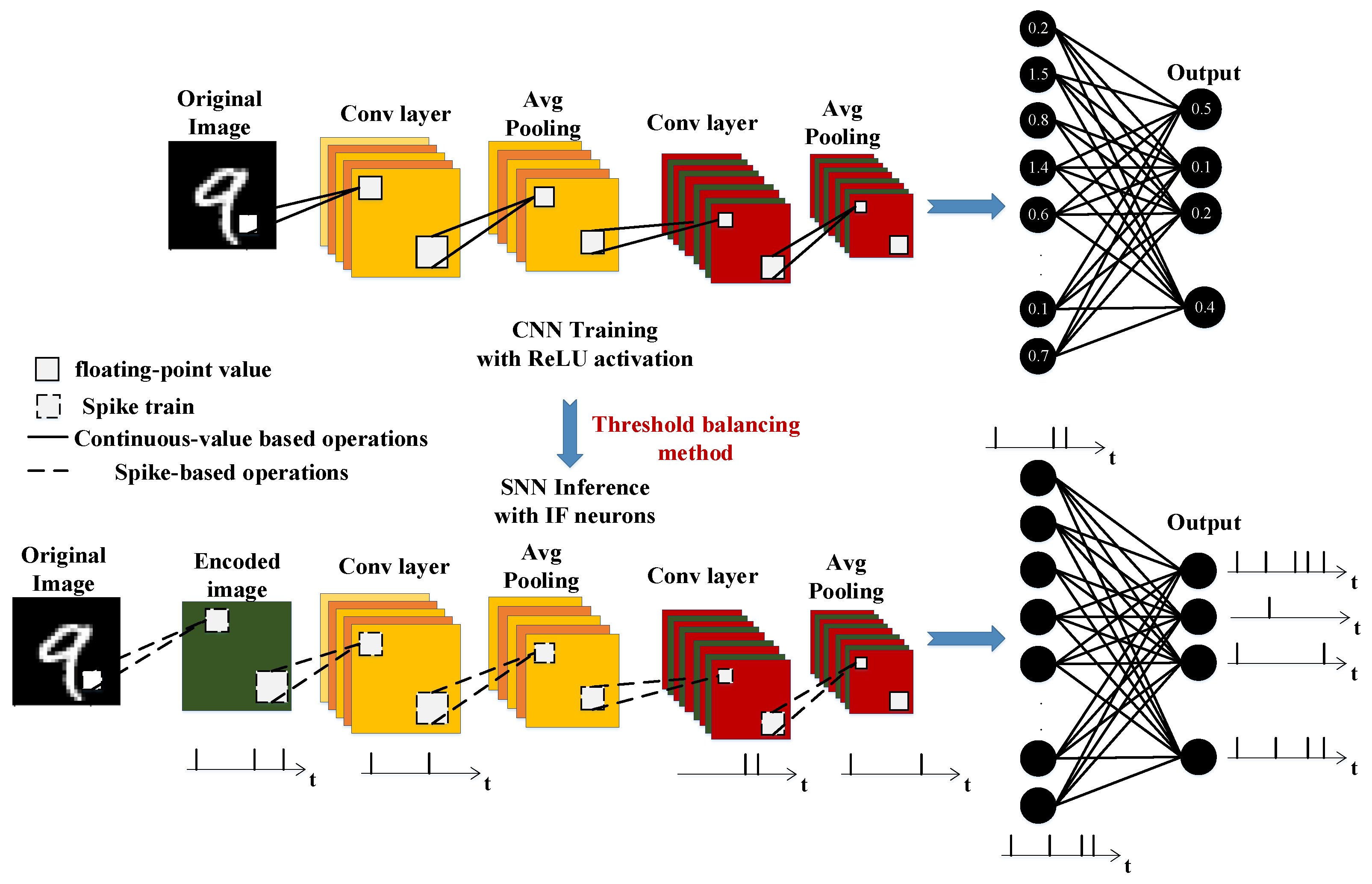
3. The Proposed CNN–SNN Conversion Method
3.1. CNN Training for SNN Conversion
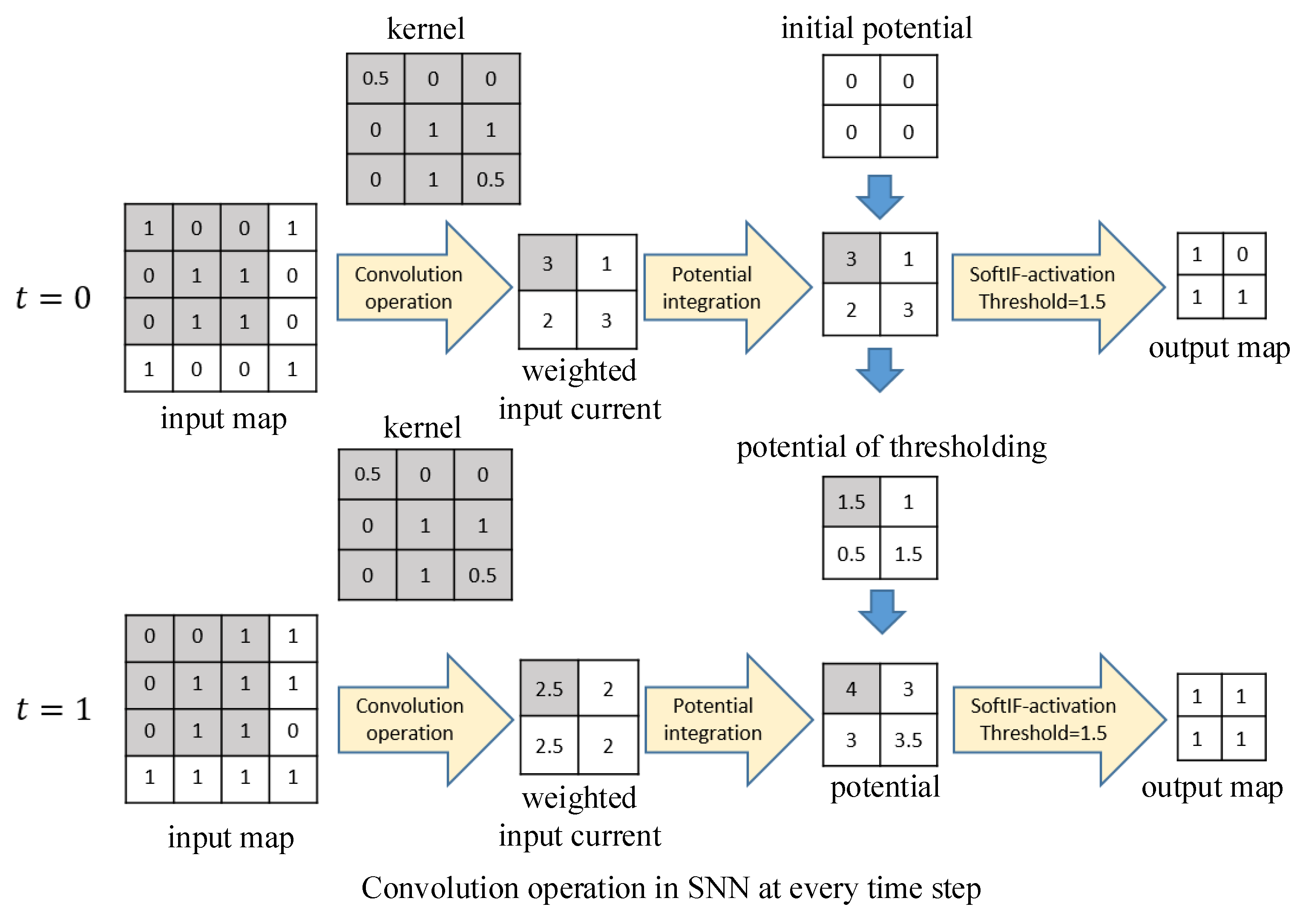
3.2. Construction of Converted SNN
| Algorithm 2: The proposed threshold balancing method. |
| Input: (): desired inference latency |
| Output: : firing threshold for neurons for the k-th channel at the l-th layer |
| Notations: (): number of layers; (l): layer index; (): number of channels at the (l)-th layer; (k): channel index in a layer; (): maximum input current over time steps at the (k)-th channel in the (l)-th layer; : the connection weight from the j-th connection from the preceding layer; : the input spike at the j-th presynaptic neuron from the preceding layer |
 |
3.3. Inference of the Converted SNN
| Algorithm 3: Inference of the converted SNN. |
| Input: : desire inference latency |
| Output: : Accuracy in % |
| Notations: : number of test samples; : number of correct predicted samples; : number of output neurons |
 |
4. Experiment Results and Discussion
4.1. Experiments on the MNIST and Fashion-MNIST Dataset
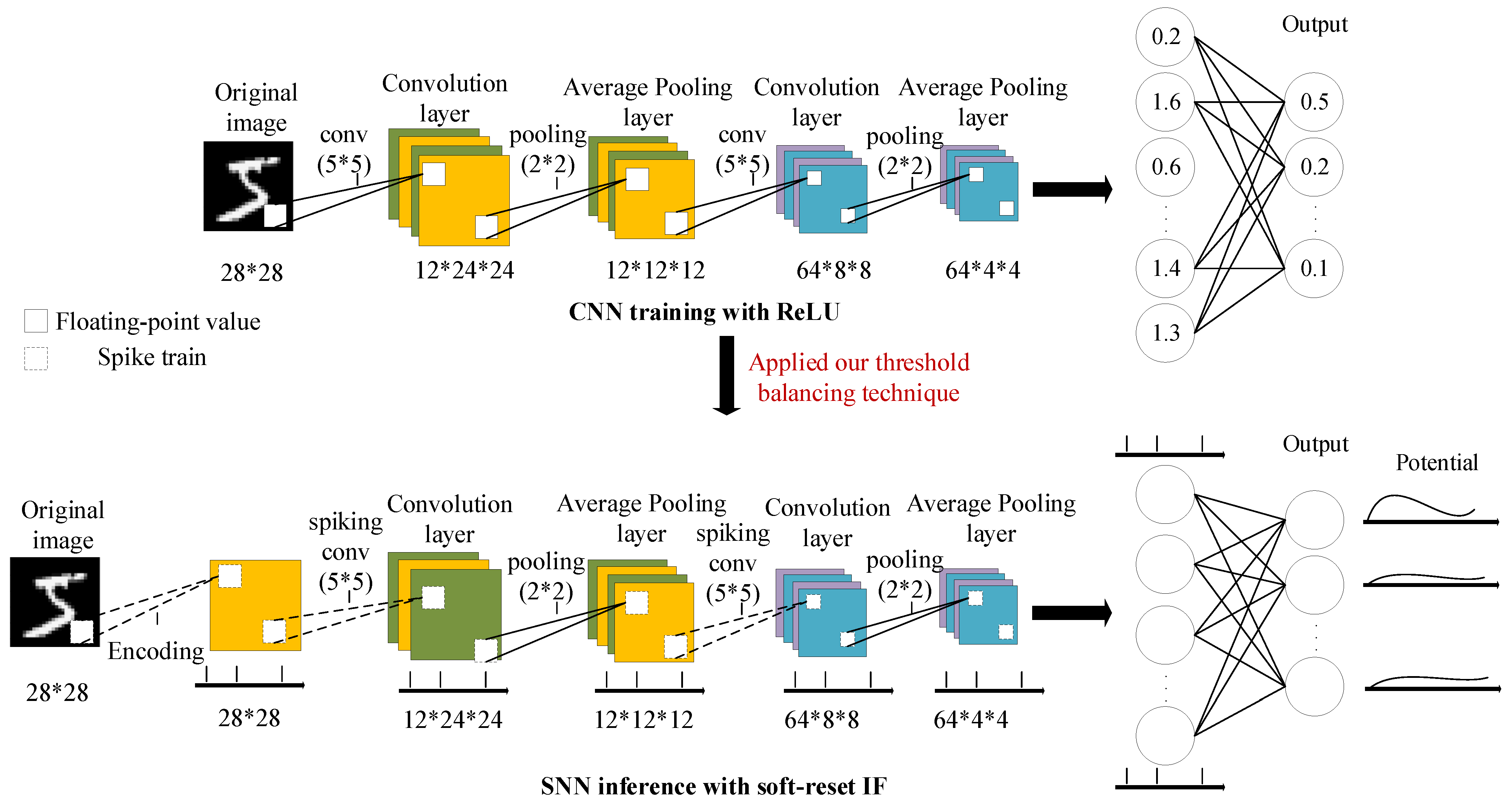
4.1.1. The Used CNN Architecture and Its Training Method
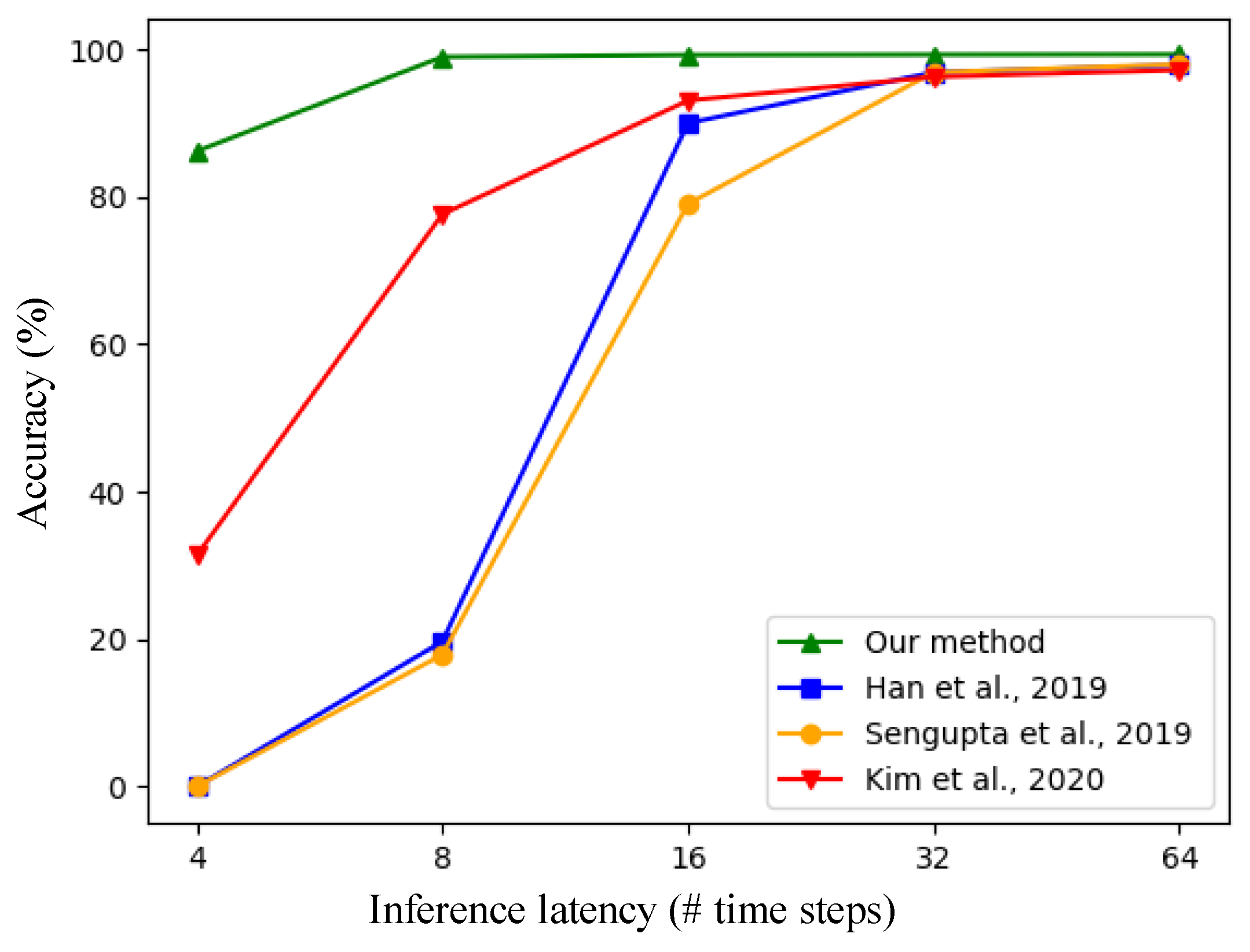
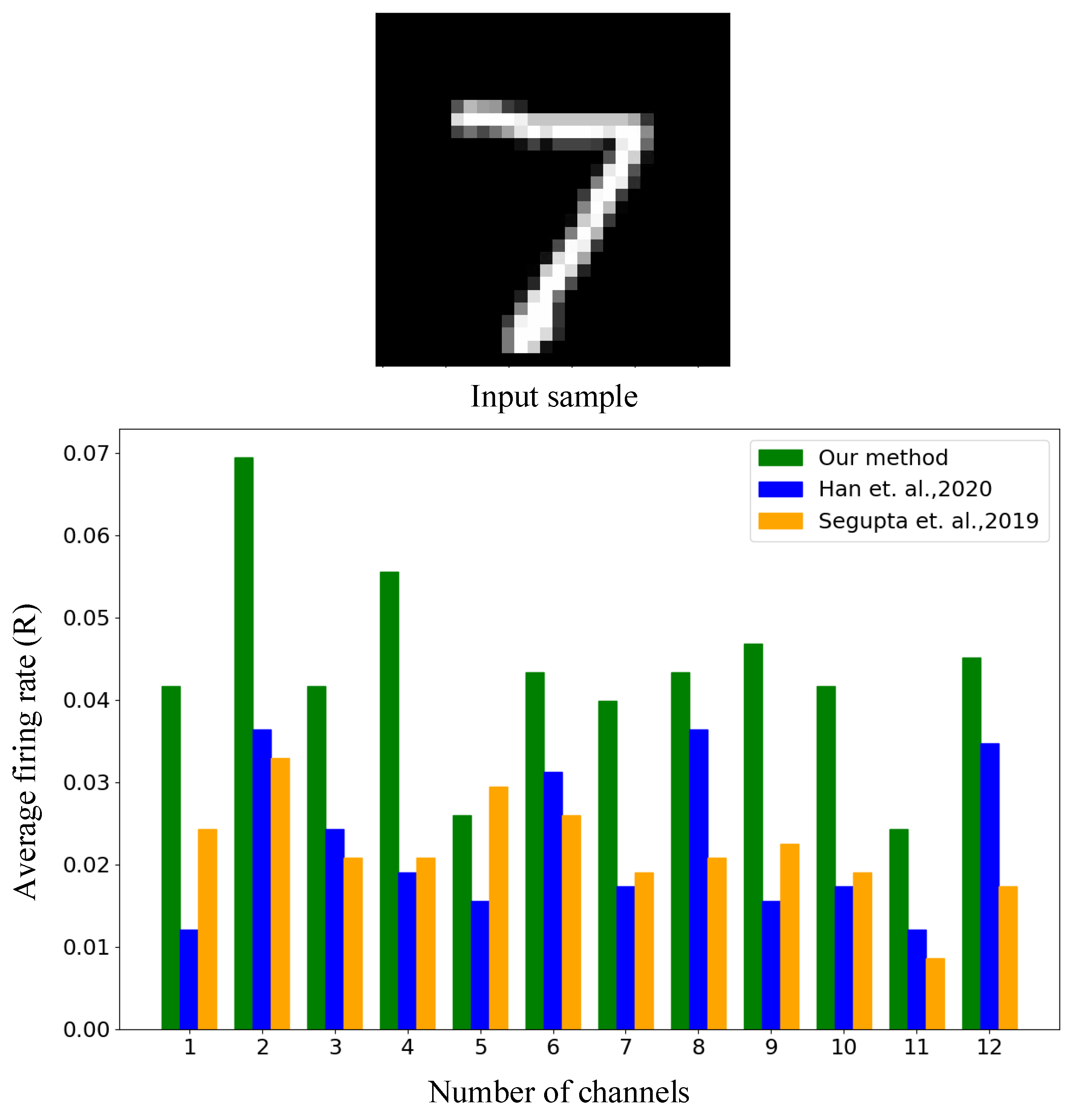
4.1.2. Conversion to SNN and Performance Evaluation
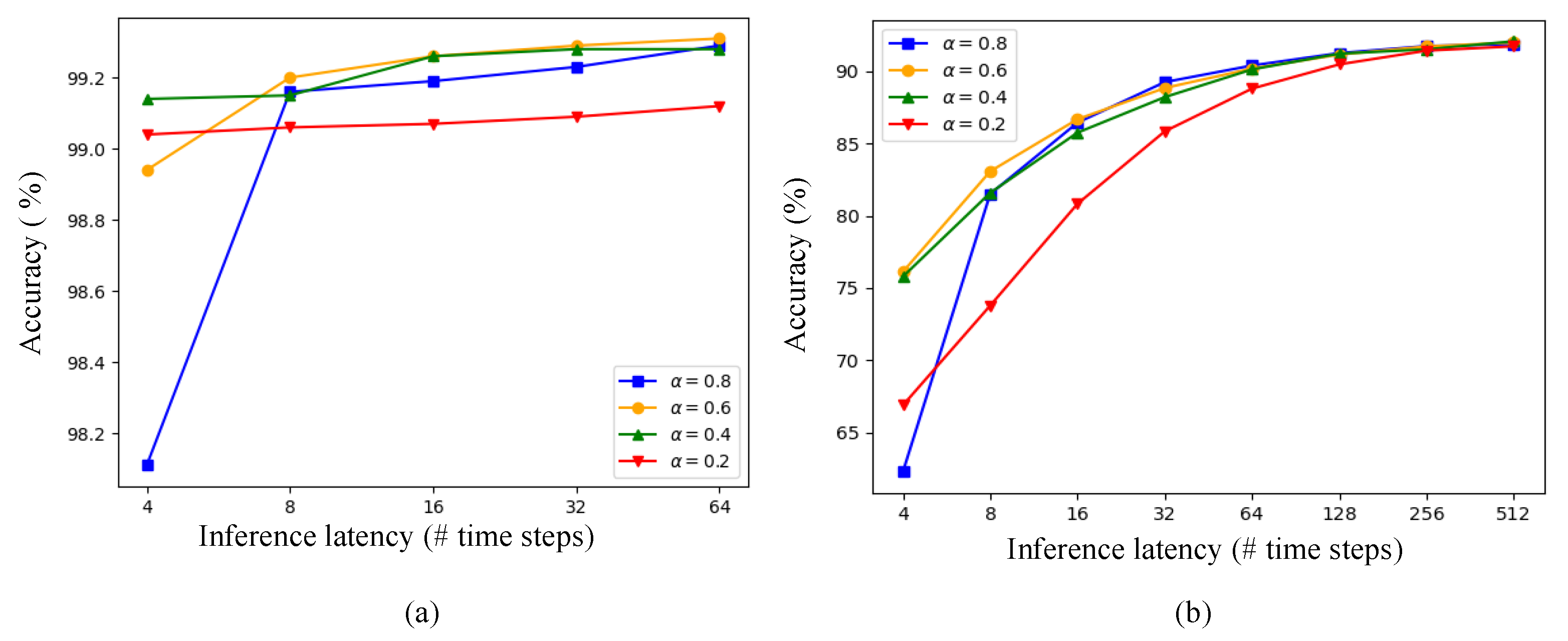
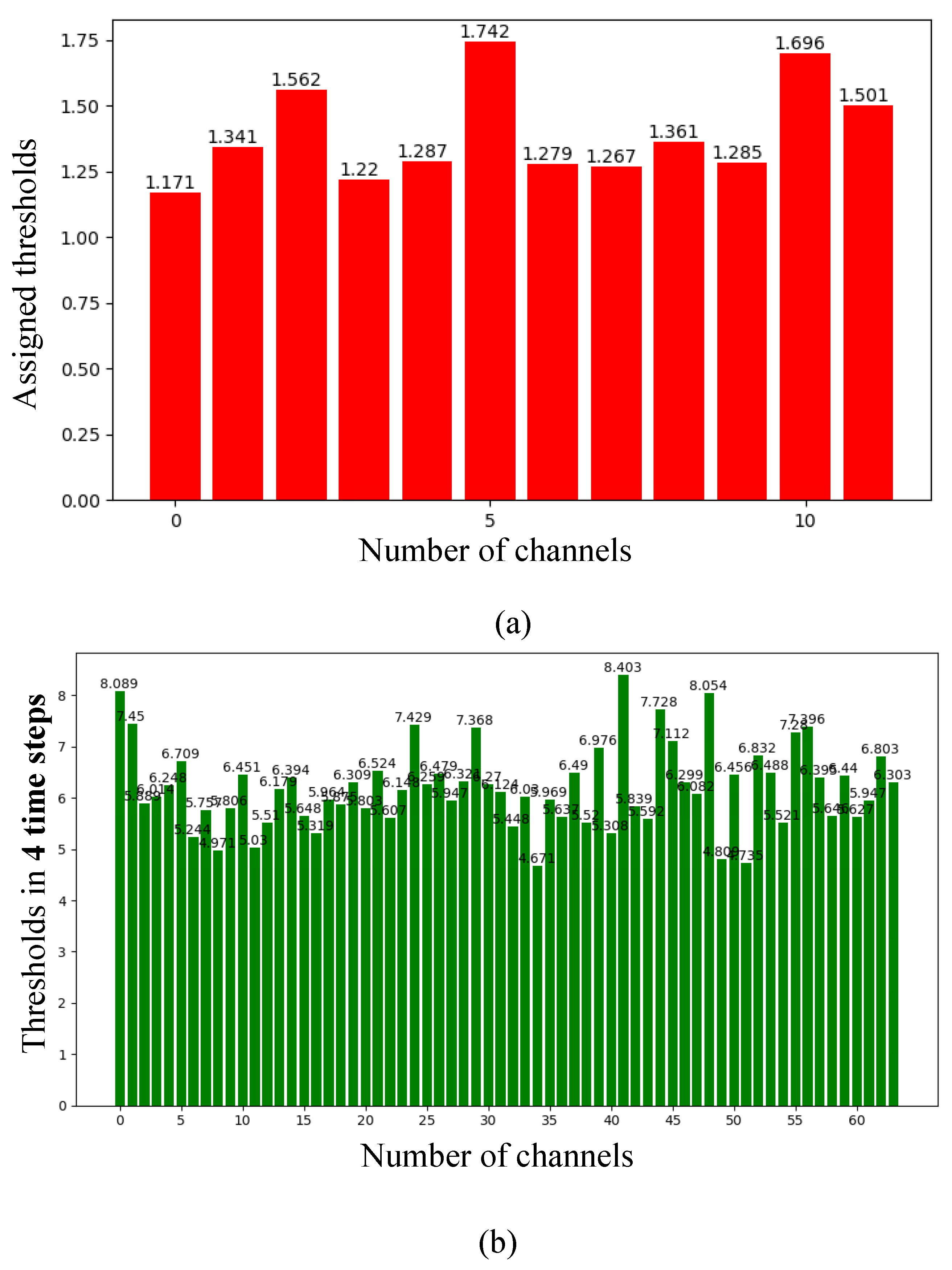
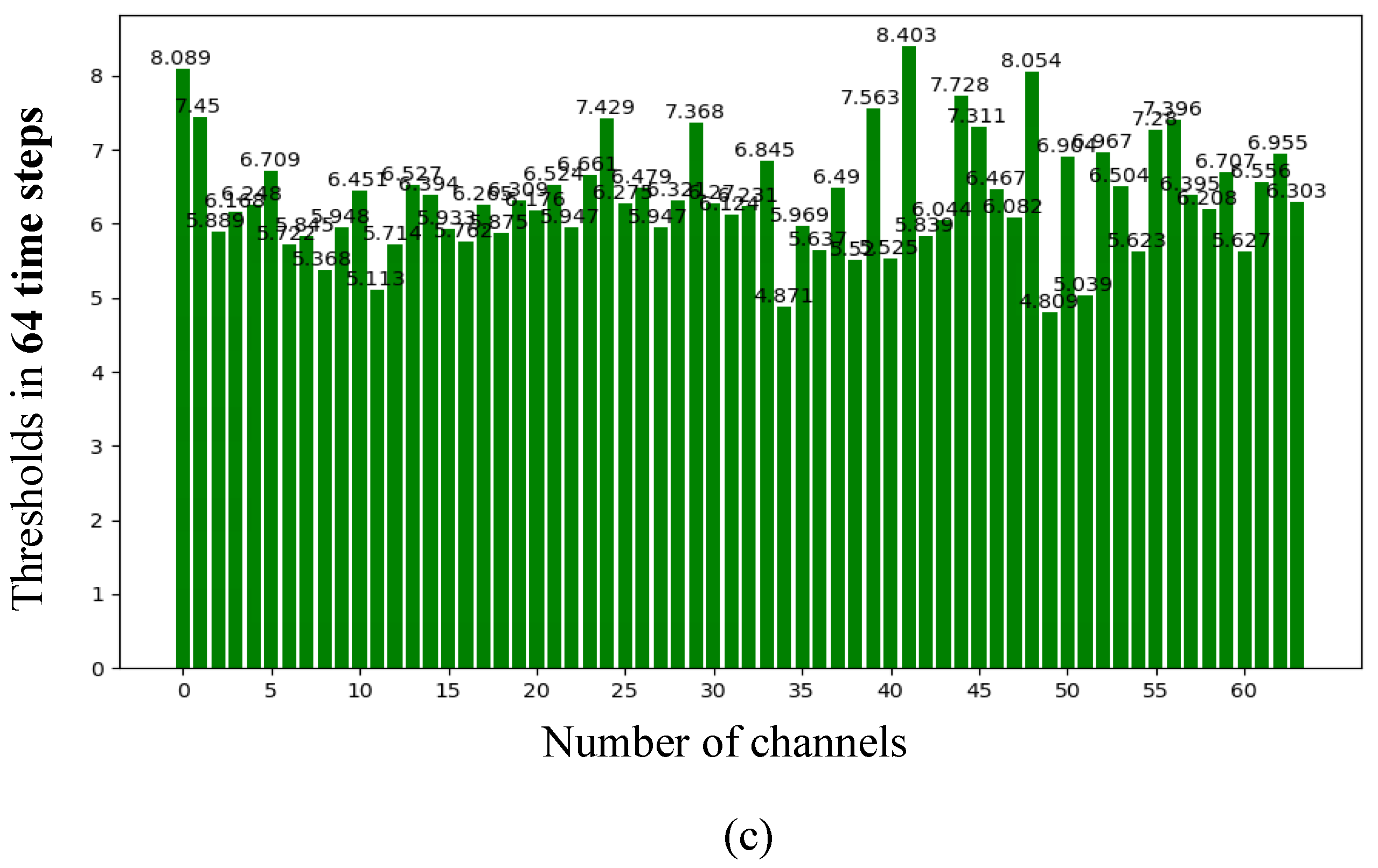
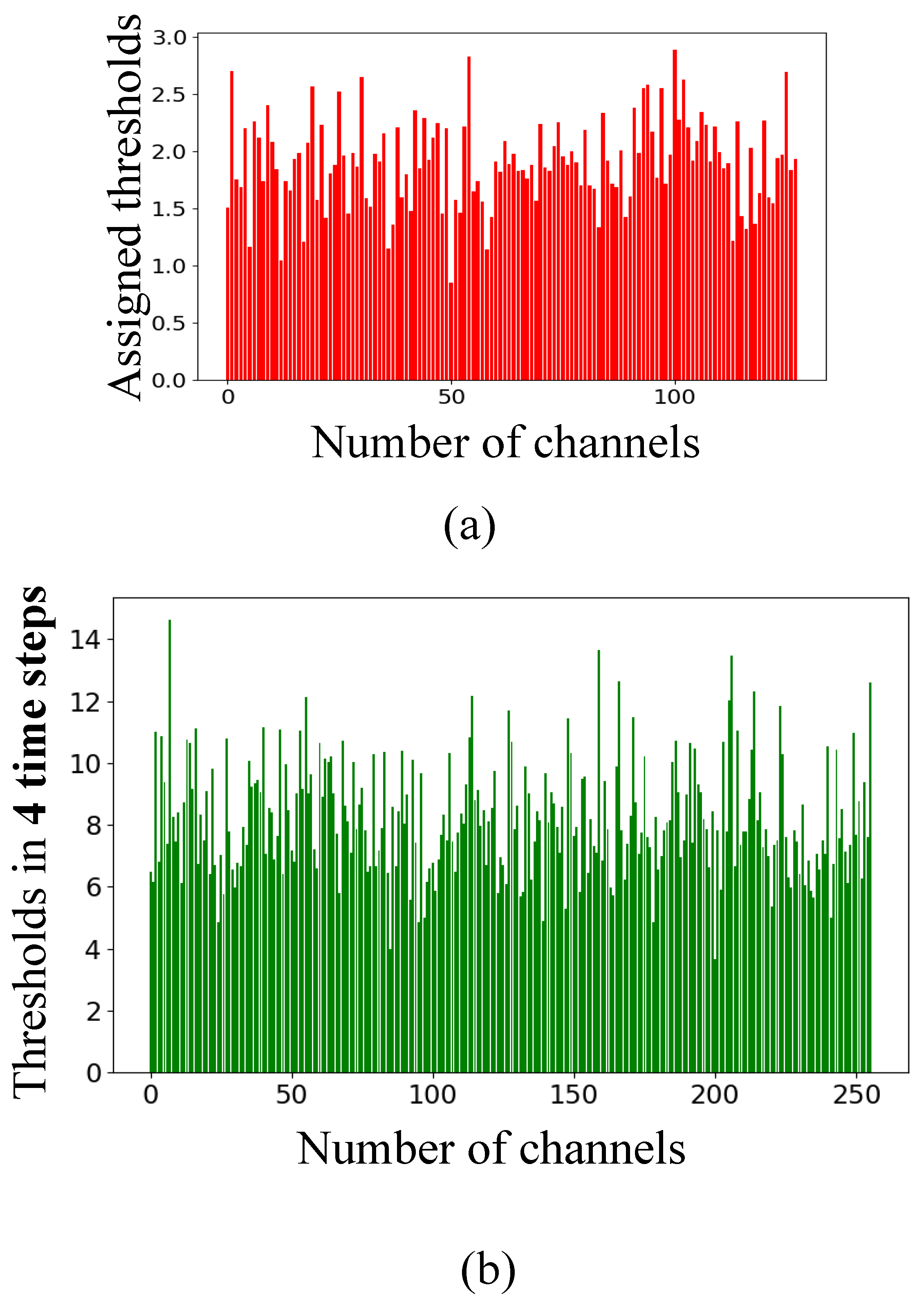
4.1.3. Ablation Study with the Scaled Thresholds
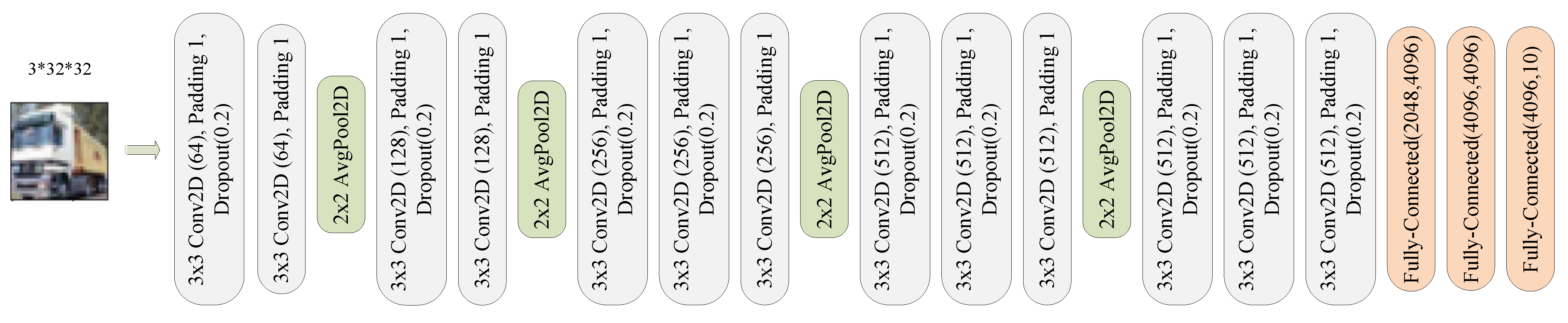
4.2. Experiments on the CIFAR-10 Dataset
4.2.1. CNN Architectures and Training Method
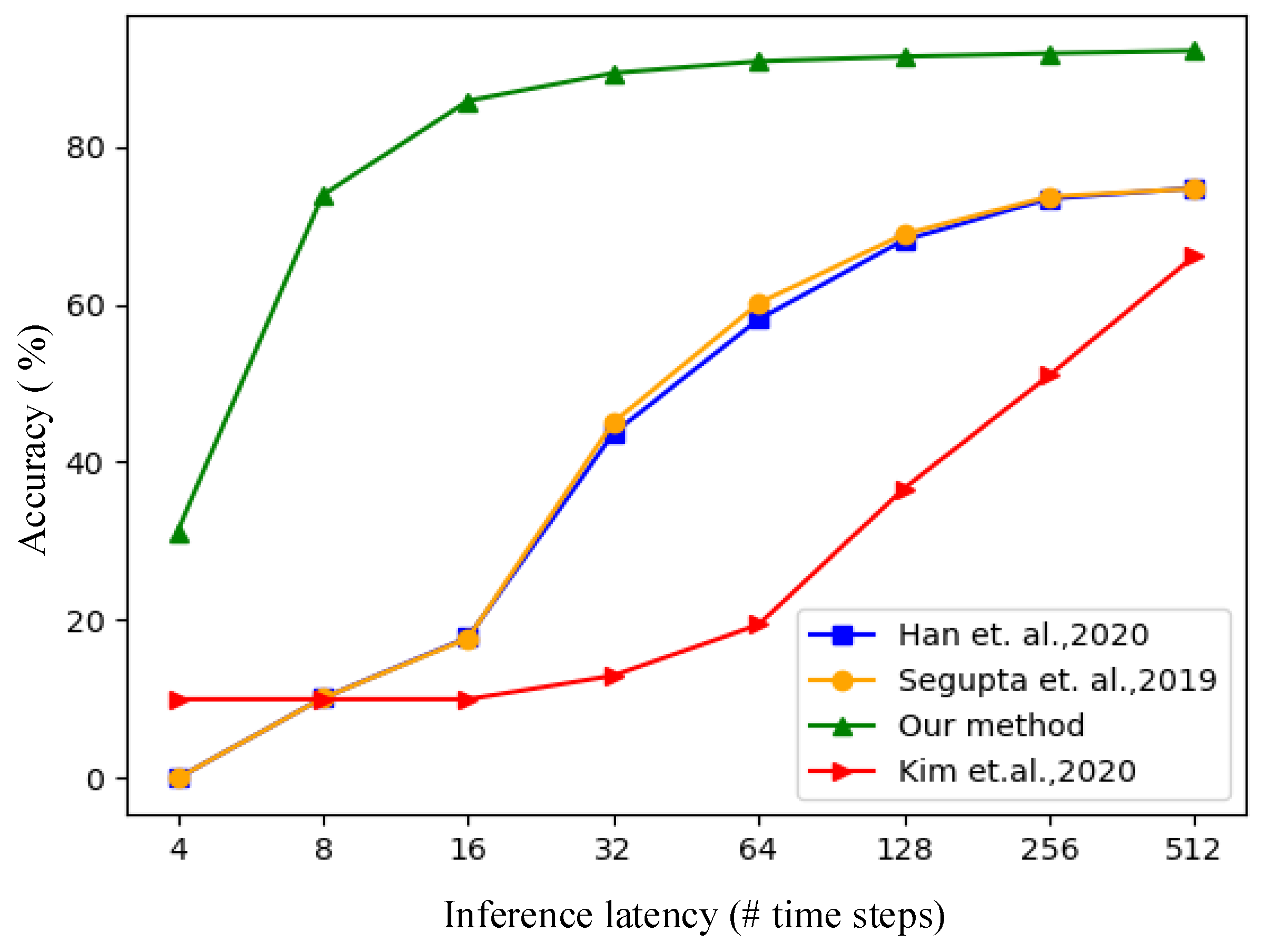
4.2.2. Conversion to SNN and Performance Evaluation
5. Further Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
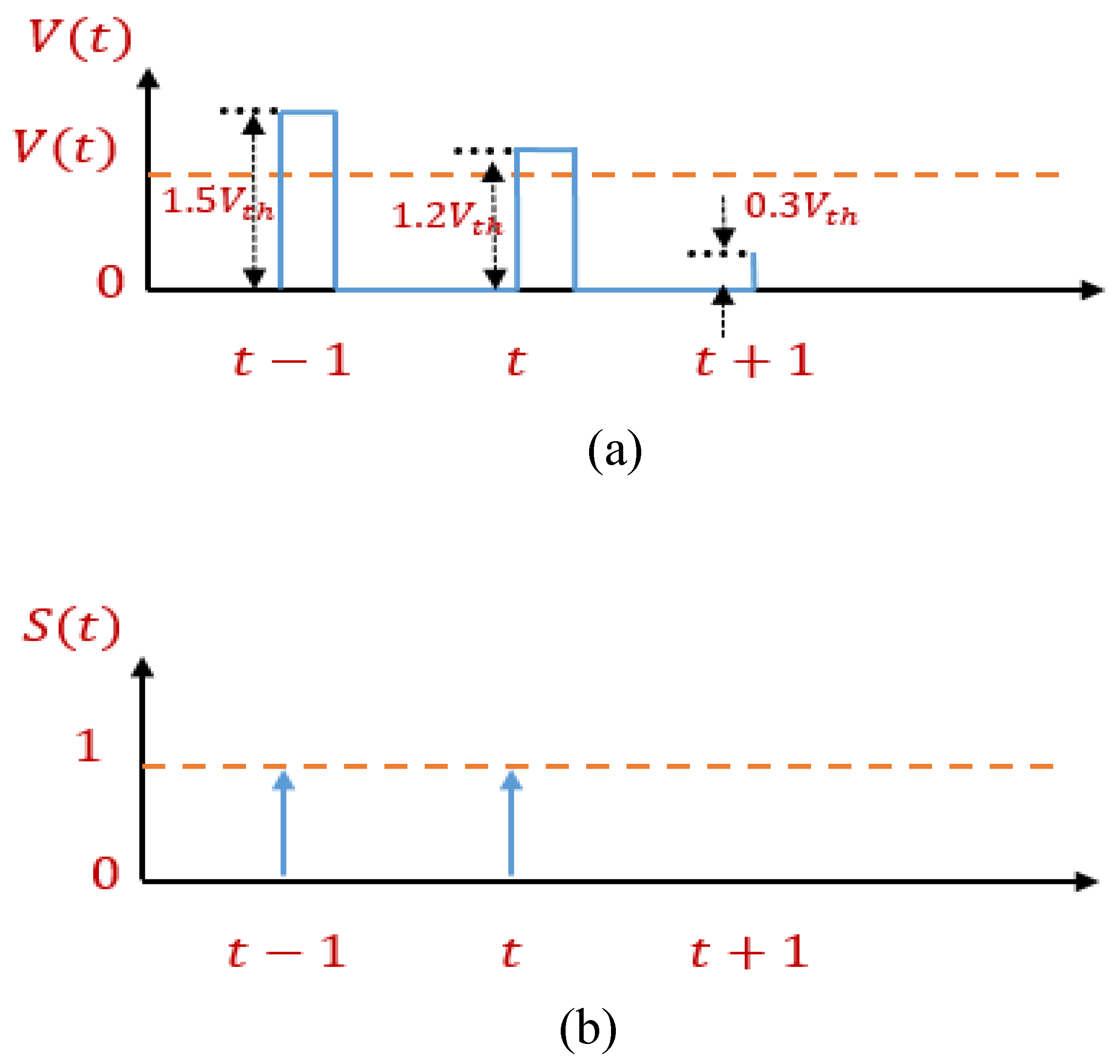
Appendix A. IF Neuron Model

| Algorithm A1: Behavior of the IF neuron model. |
 |
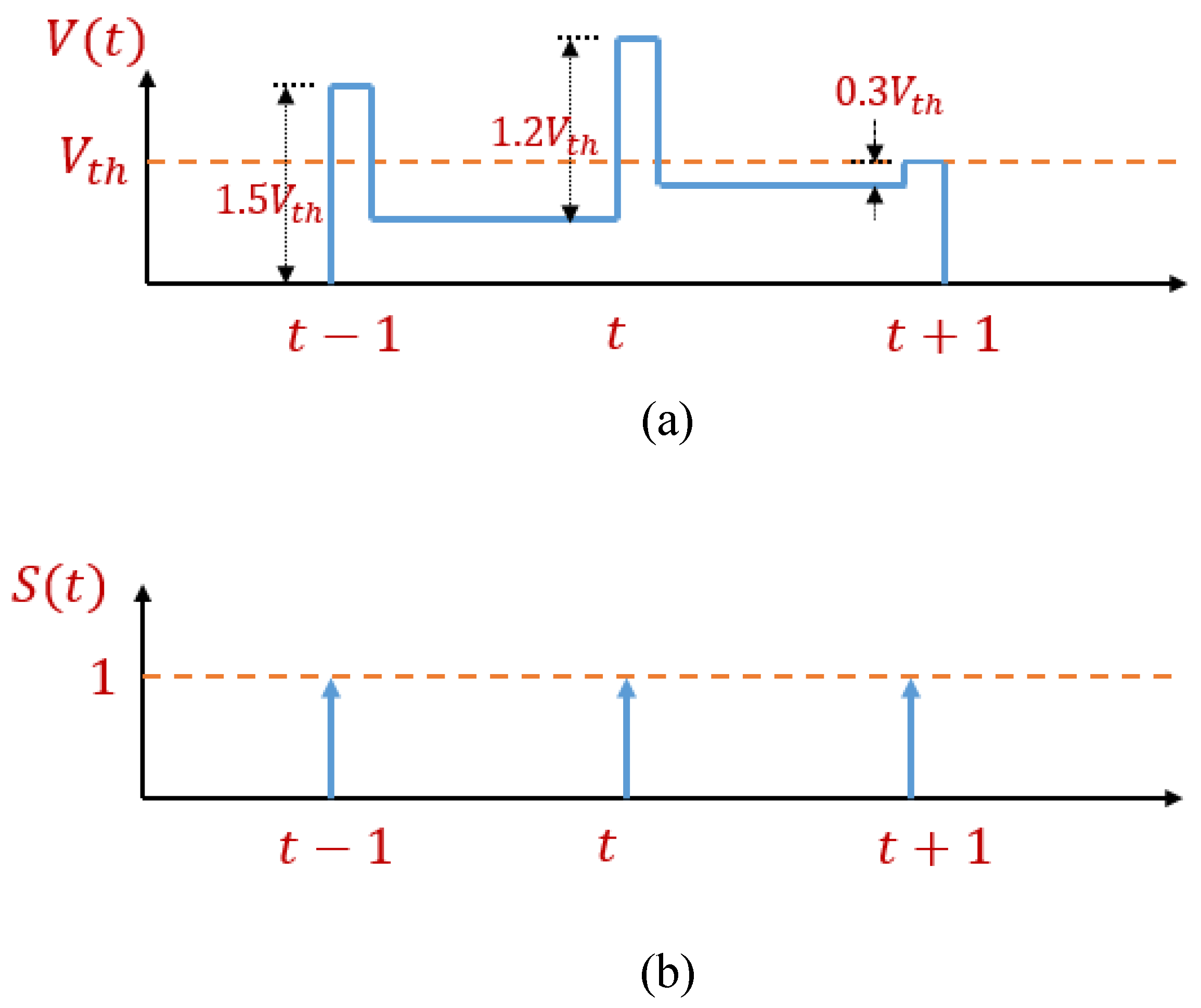
Appendix B. Soft-Reset IF Neuron Model
| Algorithm A2: Behavior of a soft-reset IF neuron model. |
 |

Appendix C. Some Modifications Made for Implementing the Conversion Method in Kim et al.’s Method

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | Original | Modified |
|---|---|---|
| Pre-train CNN unit | Leaky-ReLU | ReLU |
| SNN unit | Sign IF | IF |
Appendix D. Accuracy versus Latency Tinfer with Differently Scaled Thresholds on the MNIST and Fashion-MNIST Datasets (α Is the Scaling Factor)
| Values | |||||
|---|---|---|---|---|---|
| 64 | 99.29% | 99.31% | 99.28% | 99.12% | |
| 32 | 99.23% | 99.29% | 96.28% | 99.09% | |
| 16 | 99.19% | 99.26% | 99.26% | 99.07% | |
| 8 | 99.16% | 99.2% | 99.15% | 98.98% | |
| 4 | 98.11% | 98.94% | 99.14% | 99.04% | |
| Values | |||||
|---|---|---|---|---|---|
| 512 | 91.88% | 92.0% | 92.08% | 91.73% | |
| 256 | 91.75% | 91.72% | 91.52% | 91.43% | |
| 128 | 91.26% | 91.16% | 91.22% | 90.48% | |
| 64 | 90.4% | 90.19% | 90.13% | 88.8% | |
| 32 | 89.25% | 88.84% | 88.21% | 85.84% | |
| 16 | 86.44% | 86.68% | 85.75% | 80.82% | |
| 8 | 81.5% | 83.07% | 81.58% | 73.77% | |
| 4 | 62.26% | 76.11% | 75.78% | 66.87% | |
Appendix E. VGG-16 Model Architecture Used for the CIFAR-10 Dataset

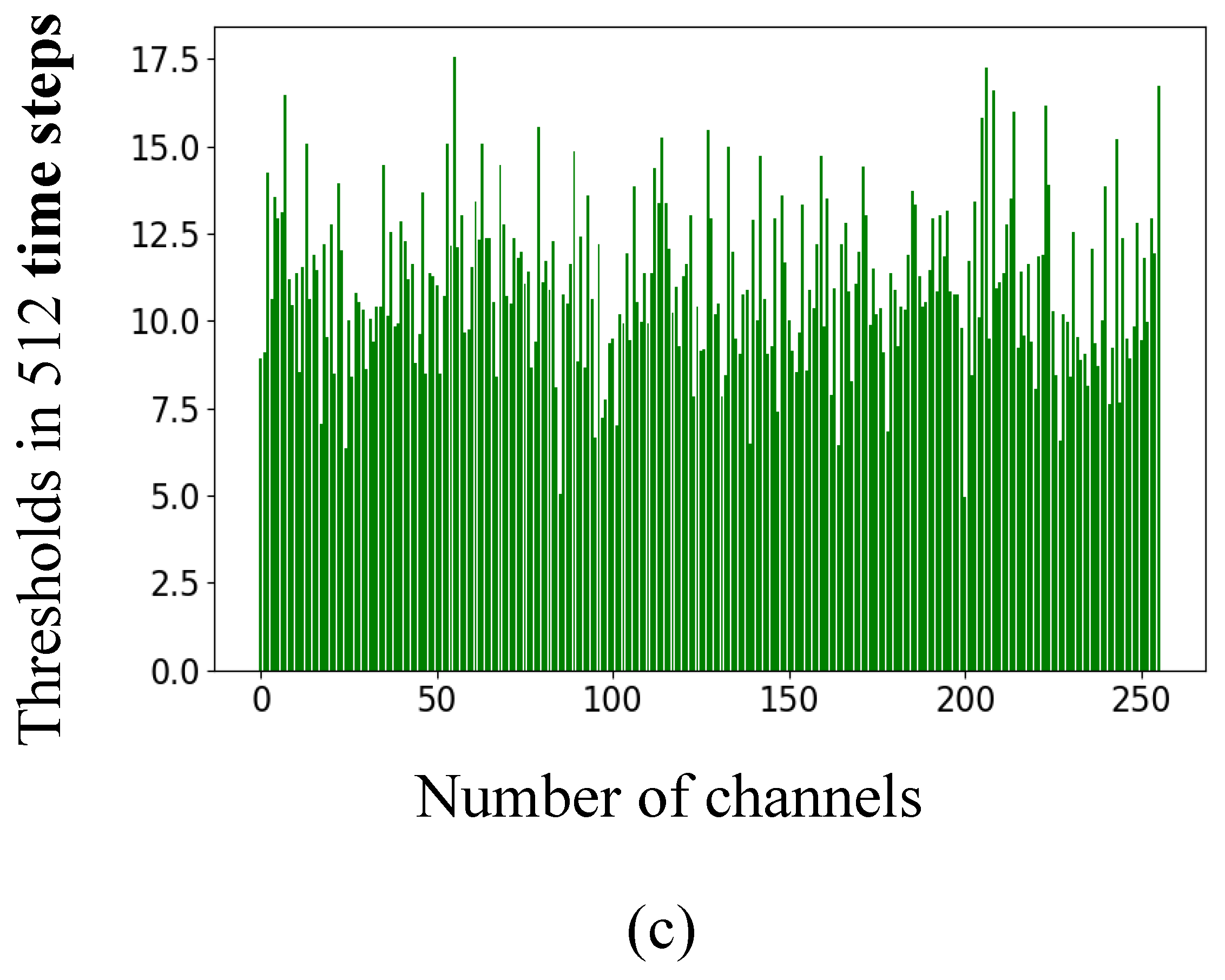
Appendix F. The Assigned Thresholds of Spiking Neurons in the Converted SNN on the MNIST and Fashion-MNIST Datasets



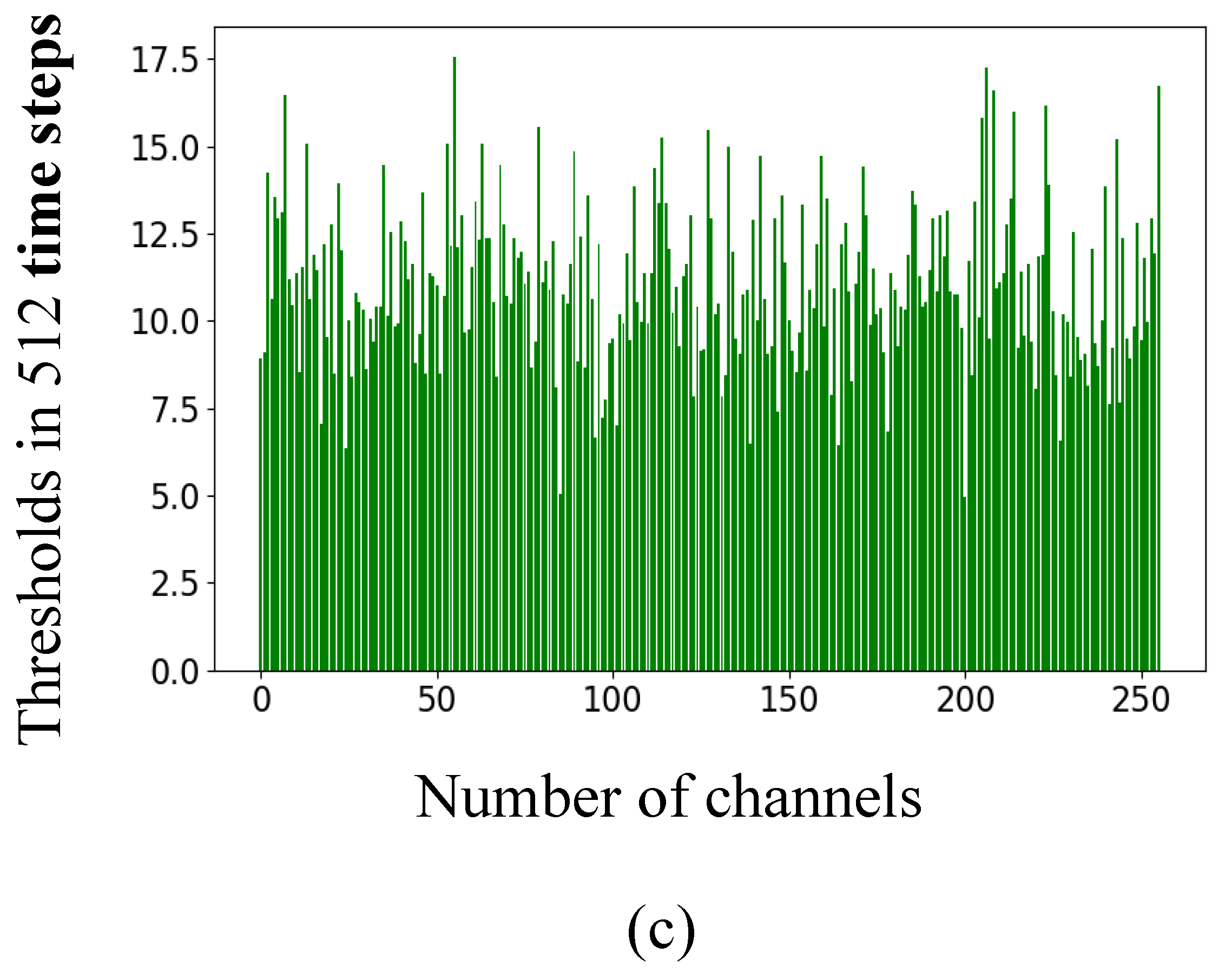
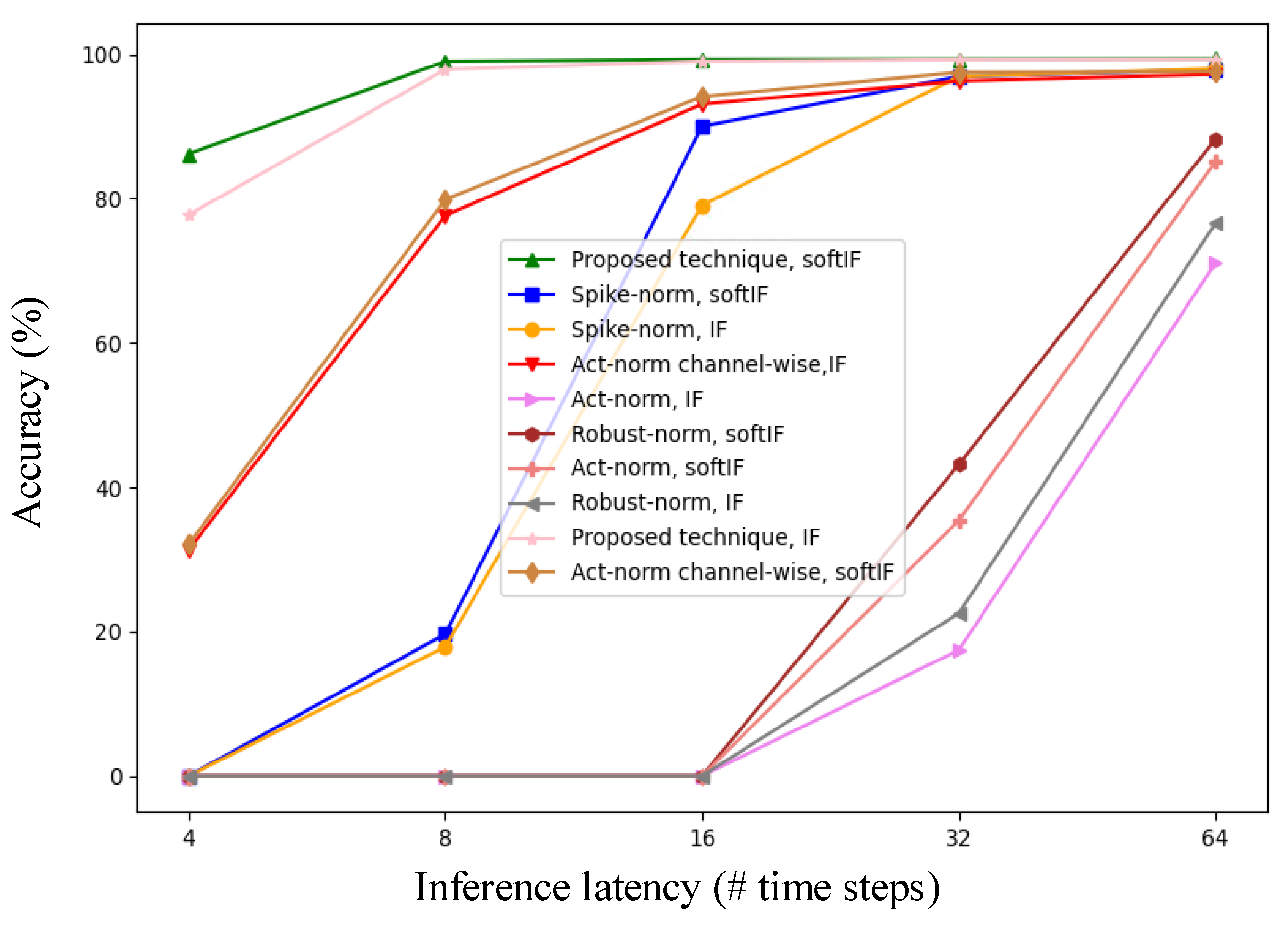
Appendix G. Comparison of “SNN Activation-Threshold Balancing Technique” Combinations on the MNIST Dataset
| Spiking Neuron Model | Balancing Technique | |||||
|---|---|---|---|---|---|---|
| IF | act-norm | - | - | - | 17.43% | 71.04% |
| IF | robust-norm | - | - | - | 22.53% | 76.56% |
| IF | spike-norm | - | 17.89% | 79.05% | 96.89% | 97.98% |
| IF | act-norm_CW | 31.31% | 77.64% | 93.06% | 96.27% | 97.20% |
| IF | Our technique | 77.73% | 97.89% | 98.99% | 99.24% | 99.25% |
| SoftIF | act-norm | - | - | - | 35.38% | 85.1% |
| SoftIF | Robust-Norm | - | - | - | 43.14% | 88.21% |
| SoftIF | spike-norm | - | 19.68% | 90.00% | 96.89% | 97.88% |
| SoftIF | act-norm_CW | 32.1% | 79.86% | 94.11% | 97.46% | 97.5% |
| SoftIF | Our technique | 86.18% | 98.98% | 99.25% | 99.30% | 99.33% |
References
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Kang, K.; Ouyang, W.; Li, H.; Wang, X. Object detection from video tubelets with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Zhan, K.; Shi, J.; Wang, H.; Xie, Y.; Li, Q. Computational mechanisms of pulse-coupled neural networks: A comprehensive review. Arch. Comput. Methods Eng. 2017, 24, 573–588. [Google Scholar] [CrossRef]
- Zhan, K.; Teng, J.; Shi, J.; Li, Q.; Wang, M. Feature-linking model for image enhancement. Neural Comput. 2016, 28, 1072–1100. [Google Scholar] [CrossRef] [PubMed]
- Han, C.S.; Lee, K.M. A Survey on Spiking Neural Networks. Int. J. Fuzzy Log. Intell. Syst. 2021, 21, 317–337. [Google Scholar] [CrossRef]
- Zhan, K.; Zhang, H.; Ma, Y. New spiking cortical model for invariant texture retrieval and image processing. IEEE Trans. Neural Netw. 2009, 20, 1980–1986. [Google Scholar] [CrossRef]
- Gerstner, W.; Kistler, W.M. Spiking Neuron Models: Single Neurons, Populations, Plasticity; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Blouw, P.; Choo, X.; Hunsberger, E.; Eliasmith, C. Benchmarking keyword spotting efficiency on neuromorphic hardware. In Proceedings of the 7th Annual Neuro-Inspired Computational Elements Workshop, Albany, NY, USA, 26–28 March 2019. [Google Scholar]
- Davies, M.; Srinivasa, N.; Lin, T.H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A neuromorphic many core processor with on-chip learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Cassidy, A.; Sawada, J.; Merolla, P.; Arthur, J.; Alvarez-lcaze, R.; Akopyan, F.; Jackson, B.; Modha, D. TrueNorth: A high-performance, low-power neurosynaptic processor for multi-sensory perception, action, and cognition. In Proceedings of the Government Microcircuits Applications & Critical Technology Conference, Orlando, FL, USA, 21–24 March 2011. [Google Scholar]
- Diehl, P.U.; Cook, M. Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Front. Comput. Neurosci. 2015, 9, 99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Masquelier, T.; Thorpe, S.J. Unsupervised learning of visual features through spike timing dependent plasticity. PLoS Comput. Biol. 2007, 3, e31. [Google Scholar] [CrossRef] [PubMed]
- Thiele, J.C.; Bichler, O.; Dupret, A. Event-based, timescale invariant unsupervised online deep learning with STDP. Front. Comput. Neurosci. 2018, 12, 46. [Google Scholar] [CrossRef] [PubMed]
- Kheradpisheh, S.R.; Ganjtabesh, M.; Thorpe, S.J.; Masquelier, T. STDP-based spiking deep convolutional neural networks for object recognition. Neural Netw. 2018, 99, 56–67. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.; Srinivasan, G.; Panda, P.; Roy, K. Deep spiking convolutional neural network trained with unsupervised spike-timing-dependent plasticity. IEEE Trans. Cogn. Dev. Syst. 2018, 11, 384–394. [Google Scholar]
- Mozafari, M.; Ganjtabesh, M.; Nowzari-Dalini, A.; Thorpe, S.J.; Masquelier, T. Bio-inspired digit recognition using reward-modulated spike-timing-dependent plasticity in deep convolutional networks. Pattern Recognit. 2019, 94, 87–95. [Google Scholar] [CrossRef] [Green Version]
- Tavanaei, A.; Kirby, Z.; Maida, A.S. Training spiking convnets by stdp and gradient descent. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Bellec, G.; Salaj, D.; Subramoney, A.; Legenstein, R.; Maass, W. Long short-term memory and learning-to-learn in networks of spiking neurons. arXiv 2018, arXiv:1803.09574. [Google Scholar]
- Jin, Y.; Zhang, W.; Li, P. Hybrid macro/micro level backpropagation for training deep spiking neural networks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Lee, C.; Sarwar, S.S.; Panda, P.; Srinivasan, G.; Roy, K. Enabling spike-based backpropagation for training deep neural network architectures. Front. Neurosci. 2020, 14, 119. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.H.; Delbruck, T.; Pfeiffer, M. Training deep spiking neural networks using backpropagation. Front. Neurosci. 2016, 10, 508. [Google Scholar] [CrossRef] [Green Version]
- Neftci, E.O.; Mostafa, H.; Zenke, F. Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Process. Mag. 2019, 36, 51–63. [Google Scholar] [CrossRef]
- Diehl, P.U.; Neil, D.; Binas, J.; Cook, M.; Liu, S.C.; Pfeiffer, M. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015. [Google Scholar]
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going deeper in spiking neural networks: VGG and residual architectures. Front. Neurosci. 2019, 13, 95. [Google Scholar] [CrossRef]
- Han, B.; Srinivasan, G.; Roy, K. Rmp-snn: Residual membrane potential neuron for enabling deeper high-accuracy and low-latency spiking neural network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Kim, S.; Park, S.; Na, B.; Yoon, S. Spiking-YOLO: Spiking neural network for energy-efficient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34. [Google Scholar]
- Rueckauer, B.; Lungu, I.A.; Hu, Y.; Pfeiffer, M.; Liu, S.C. Conversion of continuous-valued deep networks to efficient event-driven networks for image classification. Front. Neurosci. 2017, 11, 682. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, Canada, 2009; p. 7. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Burkitt, A.N. A review of the integrate-and-fire neuron model: I. Homogeneous synaptic input. Biol. Cybern. 2006, 95, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Baldi, P.; Sadowski, P. Understanding dropout. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 2. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Lee, C.; Panda, P.; Srinivasan, G.; Roy, K. Training deep spiking convolutional neural networks with stdp-based unsupervised pre-training followed by supervised fine-tuning. Front. Neurosci. 2018, 12, 435. [Google Scholar] [CrossRef]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Shi, L. Spatio-temporal backpropagation for training high-performance spiking neural networks. Front. Neurosci. 2018, 12, 331. [Google Scholar] [CrossRef]
- Tavanaei, A.; Maida, A. BP-STDP: Approximating backpropagation using spike timing dependent plasticity. Neurocomputing 2019, 330, 39–47. [Google Scholar] [CrossRef] [Green Version]












| Dataset | Training Configurations | Values |
|---|---|---|
| MNIST | Optimizer | Adam |
| Learning rate | 0.001 | |
| Number of channels in Conv layers | 12, 64 | |
| Number of epochs | 100 | |
| Dropout | 50% | |
| Fashion-MNIST | Optimizer | Adam |
| Learning rate | ||
| Number of channels in Conv layers | 128, 256 | |
| Number of epochs | 250 | |
| Dropout | 50% |
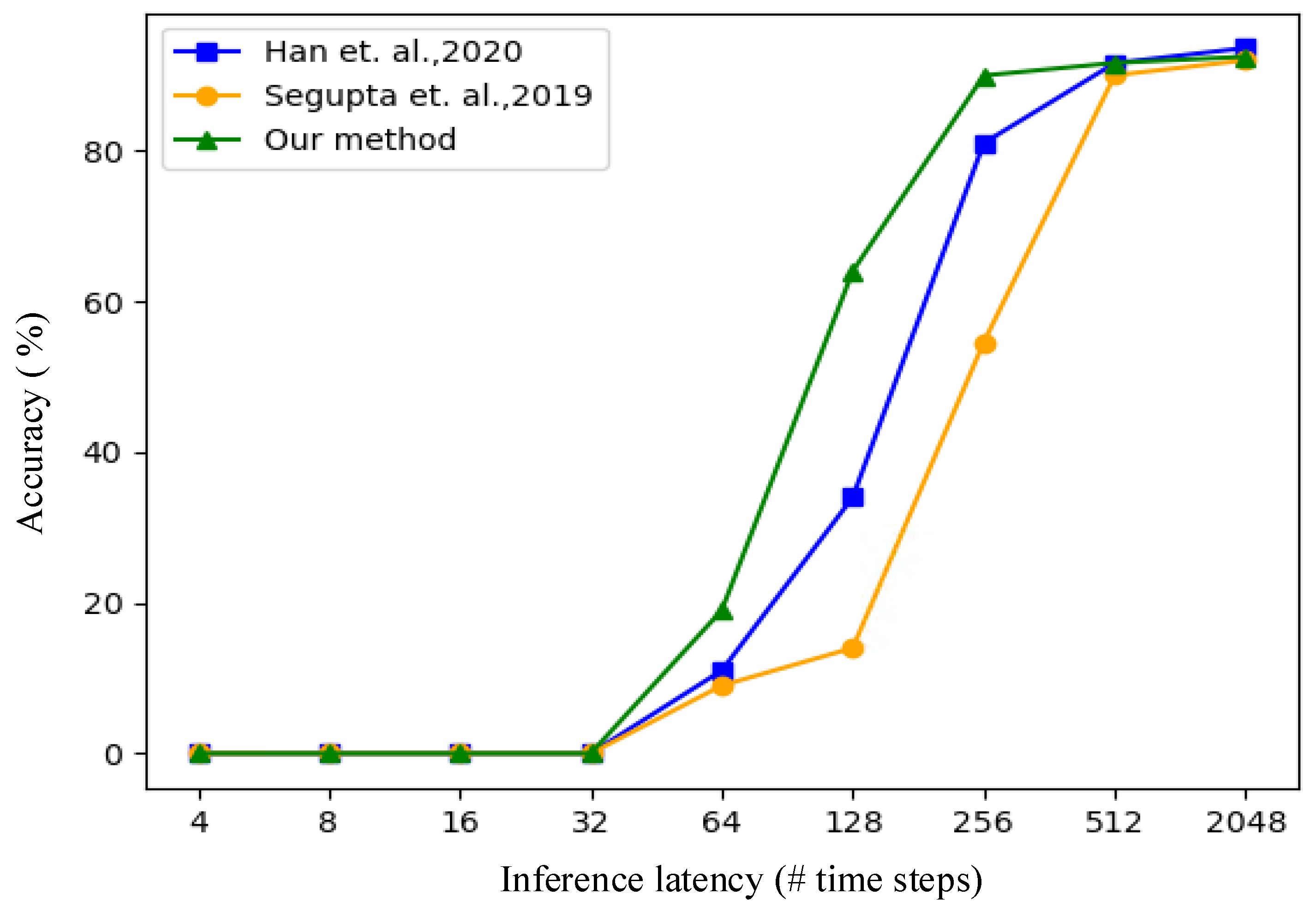
| Methods | [25] | [26] | [27] | Our Method | |
|---|---|---|---|---|---|
| Latency | |||||
| 64 | 97.98% | 97.87% | 97.20% | 99.33% | |
| 32 | 96.89% | 96.89% | 96.27% | 99.30% | |
| 16 | 79.05% | 90.00% | 93.06% | 99.25% | |
| 8 | 17.89% | 19.68% | 77.64% | 98.98% | |
| 4 | / | / | 31.31% | 86.18% | |
| Methods | [25] | [26] | [27] | Our Method | |
|---|---|---|---|---|---|
| Latency | |||||
| 512 | 74.65% | 74.73% | 66.15% | 92.11% | |
| 256 | 73.65% | 73.38% | 51.01% | 91.76% | |
| 128 | 68.89% | 68.14% | 36.69% | 91.36% | |
| 64 | 60.15% | 58.11% | 19.45% | 90.77% | |
| 32 | 45.07% | 43.66% | 13.1% | 89.29% | |
| 16 | 17.73% | 17.82% | 10.0% | 85.76% | |
| 8 | 10.14% | 10.15% | 10.0% | 73.84% | |
| 4 | / | / | 10.0% | 31.21% | |
| Training Configurations | Values |
|---|---|
| Optimizer | Adam |
| Learning rate | 0.01 |
| Number of epochs | 300 |
| Dropout | 50% |
| Cut_out technique [35] | 1 hole of size |
| Model | Neural Encoding | Training Approach | Learning Type | Accuracy (%) | Latency (Time Steps) |
|---|---|---|---|---|---|
| [21] | Rate-based | Gradient-based | Supervised | 99.59 | 100 |
| our work | Rate-based | Conversion | Supervised | 99.33 | 64 |
| [36] | Rate-based | Biological + gradient | Semi-supervised | 99.28 | 200 |
| [24] | Rate-based | Conversion | Supervised | 99.19 | >500 |
| our work | Rate-based | Conversion | Supervised | 99.14 | 4 |
| [37] | Rate-based | Gradient-based | Supervised | 98.89 | 30 |
| [15] | Temporal-based | Biologically based | Semi-supervised | 98.4 | 30 |
| [38] | Rate-based | Biological + gradient | Supervised | 97.20 | 9 |
| [12] | Rate-based | Biologically based | Unsupervised | 95 | 350 |
| [16] | Rate-based | Biologically based | Semi-supervised | 91.1 | 300 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ngu, H.C.V.; Lee, K.M. Effective Conversion of a Convolutional Neural Network into a Spiking Neural Network for Image Recognition Tasks. Appl. Sci. 2022, 12, 5749. https://doi.org/10.3390/app12115749
Ngu HCV, Lee KM. Effective Conversion of a Convolutional Neural Network into a Spiking Neural Network for Image Recognition Tasks. Applied Sciences. 2022; 12(11):5749. https://doi.org/10.3390/app12115749
Chicago/Turabian StyleNgu, Huynh Cong Viet, and Keon Myung Lee. 2022. "Effective Conversion of a Convolutional Neural Network into a Spiking Neural Network for Image Recognition Tasks" Applied Sciences 12, no. 11: 5749. https://doi.org/10.3390/app12115749
APA StyleNgu, H. C. V., & Lee, K. M. (2022). Effective Conversion of a Convolutional Neural Network into a Spiking Neural Network for Image Recognition Tasks. Applied Sciences, 12(11), 5749. https://doi.org/10.3390/app12115749