1. Introduction
In recent years, Japan has been the second largest trading partner of China, and China is the largest trading partner of Japan. As an important contributor to cultural exchange and industrial cooperation, China and Japan have been paying attention to each other. However, the language barrier problem has become a serious challenge that limits China and Japan from strengthening their communications. Both countries expect a high-quality Chinese-Japanese machine translation system. Therefore, the establishment of a high-quality Chinese-Japanese machine translation system is helpful for the language barrier arising from Chinese-Japanese exchange activities. It is of great significance to the development of both Japan and China in terms of technology and economy.
Machine translation is an important field of artificial intelligence research which translates source language into target language. It is one of the most effective methods for solving language barriers. After years of development, NMT is a new machine translation model with great potential that has exhibited superior translation results to the traditional frameworks for various language pairs. NMT is capable of training large-scale parallel corpora, although the amount of training data greatly affects the quality of translation results. NMT has a great potential for industrialization, as well as significant research value, making it the most advanced hotspot in machine translation research today.
In the field of machine translation, Chinese-Japanese machine translation is difficult due to the complex intertwining of the two languages. In order to obtain high-quality translations, a large amount of data in the Japanese-Chinese bilingual corpus is required. There are tens or hundreds of millions of sentence pairs, including English, and language pairs existing between European languages. It contain sentences from many different fields. However, there is a lack of Japanese-Chinese bilingual corpora that have been made public. For example, the Japanese Patent Office (JPO) Japanese-Chinese bilingual corpus has 130 million entries (about 26 GB) and 0.1 billion entries (about 1.4 GB), but research results using all of the data need to be submitted (
https://alaginrc.nict.go.jp/jpo-outline.html (accessed on 30 June 2017)), and the only type of content in this corpus is patented. The ASPEC-JC corpus contains approximately 670k sentences [
1]. This corpus contains only abstracts of scientific papers. The above two corpora are already have a very large number of sentences among the publicly available Japanese-Chinese corpora. However, there are still not many Japanese-Chinese bilingual corpora suitable for translating sentences from daily-use spoken language.
Currently, most of the research on NMT focuses on improving the translation quality of translation models. However, the lack of corpus with the basic properties remains an insurmountable problem. Although approaches such as back translation have been proposed to generate pseudo-data, they still cannot reach the essence of the problem. It is necessary to perform this basic research and lead the way by releasing the data. Professor Feifei Li of Stanford University had released the famous ImageNet dataset. This dataset led the field of computer vision and triggered the wave of AI that is sweeping the world today [
2]. Professor Feifei Li said “One thing ImageNet changed in the field of AI is suddenly people realized the thankless work of making a dataset was at the core of AI research”. This is exactly what our research was originally intended to do.
Most of the current research focuses on the translation of sentences that fall into the category of written language. On the other hand, research on spoken language is more ambiguous than written language, and it requires a greater understanding of context. For instance, the spoken language is usually shorter in length than written sentences. Even in spoken language, slang words and dialects may be overlooked by conventional translators. In addition, multi-modal translation is recognized as a future research trend, and a suitable bilingual corpus of spoken language is needed.
In this article, our research goal is to construct a Japanese-Chinese bilingual corpus by crawling data from websites. The corpus (WCC-JC) is constructed by crawling the data from movie, anime, and TV series subtitles. Then, the subtitles are mapped to Japanese and Chinese languages. The corpus also covers spoken language bilingualism, which has not been well researched in the existing Chinese-Japanese bilingual corpora. After the Japanese-Chinese bilingual corpus is completed, it is expected to attract researchers’ attention as a crucial resource for Japanese-Chinese NMT and to promote the progress of NMT research.
In the remainder of this article,
Section 2 presents the related works.
Section 3 describes the construction of WCC-JC.
Section 4 reports the experimental framework, the results obtained from Japanese-Chinese and Chinese-Japanese translation experiments, and the manual evaluations.
Section 5 discusses the legitimacy of WCC-JC. Finally,
Section 6 concludes with a discussion of the contributions of this article and the future works.
2. Related Works
The corpus was systematically introduced and analyzed in Stefanowitsch Anatol’s book
Corpus linguistics: A guide to the methodology [
3]. Several examples from corpus linguistics are surveyed to show how they fit into the outlined methodology.
The Japanese-Chinese bilingual corpus at Beijing Normal University contains about 80 full texts of novels, poems, essays, biographies, political commentaries, and legal treatises from the modern to the contemporary period [
4]. However, due to copyright restrictions, this corpus was only partially available for research, and could not be trained and used in NMT.
Zhang et al. constructed a Japanese-Chinese parallel corpus by human translation, which was part of the NICT multilingual corpus. The quality was high and annotated, but there were only about 40,000 sentence pairs [
5].
Koehn collected a corpus of parallel text in 11 languages from the proceedings of the European Parliament, which are published on the Web. This corpus had found widespread use in the NLP community [
6].
Lavecchia et al. proposed a method to automatically build a bilingual corpus from movie subtitle files, and also created a translation table by the method [
7].
Baroni et al. introduced ukWaC, deWaC, and itWaC, three very large corpora of English, German, and Italian built by Web crawling, and described the methodology and tools used in their construction. The corpora contained more than a billion words each, and were thus among the largest resources for the respective languages [
8].
Smith et al. used their open-source extension of the STRAND algorithm-mined 32 terabytes of the Common Crawl, a public Web crawl hosted on Amazon’s Elastic Cloud. Even with minimal cleaning and filtering, the resulting data boosted translation performance across the board for five different language pairs in the news domain [
9].
Chu et al. proposed a bilingual sentence extraction system to construct a Japanese-Chinese bilingual corpus from Wikipedia [
10]. Using the system, they constructed a Japanese-Chinese bilingual corpus containing more than 126k highly accurate bilingual sentences from Wikipedia.
Benko reported on the first phase of an ongoing project to create a Web corpus and summarized the problems encountered in the process [
11].
The United Nations Parallel Corpus v1.0 was composed of official records and other parliamentary documents of the United Nations that were in the public domain. These documents were mostly available in the six official languages of the United Nations. The current version of the corpus contained content that was produced and manually translated between 1990 and 2014, including sentence-level alignments [
12].
Pryzant et al. constructed a Japanese-English correspondence database of movie and TV program subtitles crawled from the Internet. The JESC was the largest freely available Japanese-English bilingual corpus (about 2.8 million sentences) [
13].
OpenSubtitles2018 was a multilingual parallel corpus of movie subtitle data [
14]. The Japanese-English bilingual corpus was a parallel corpus of two million sentences consisting of approximately 2000 movies, and will be considered for use in the field of machine translation and other tasks that take advantage of the characteristics of movie subtitles.
Park et al. proposed a simple, linguistically motivated solution to improve the performance of Korean–Chinese neural machine translation models by using a common vocabulary [
15].
Morishita et al. constructed JParaCrawl, a large-scale Web-based Japanese-English bilingual corpus, by crawling the Web on a large scale, automatically collecting Japanese-English bilingual sentences, and filtering out noisy bilingual pairs [
16].
Guokun et al. automatically built a corpus by crawling language resources from the Internet, but the data were not well filtered [
17].
Hasan et al. built a sentence segmentation method for Bengali, a sparse language, and constructed a non-English bilingual corpus [
18]. Thus, the construction of an open Japanese-Chinese bilingual corpus for NMT has significant implications on the resource scarcity problem.
Václav et al. compared two corpora of Czech. One was a traditional corpus and the other was a Web-crawled corpus, which had been extensively compared and analyzed for quality [
19].
The EuroparlTV Multimedia Parallel Corpus (EMPAC) was a collection of subtitles in English and Spanish for videos from the European Parliament’s Multimedia Centre. The corpus covered a time span from 2009 to 2017 and it was made up of 4000 texts amounting to two and half million tokens for every language, corresponding to approximately 280 h of video [
20].
Nakazawa et al. introduced the BSD corpus and the results of the BSD translation task in WAT2020. Additionally, they discussed the challenges of dialogue translation based on the analysis of the translation results [
21]. The BSD corpus was constructed using “dialogue” in “business” as the domain of the bilingual corpus.
Liu et al. conducted a parallel corpus in the field of biomedicine for English-Chinese translation [
22]. They compared the effectiveness of different algorithms/tools for sentence boundary detection and sentence alignment, and used the constructed corpus, fine-tuning the NMT models.
Dou et al. used pretrained language models, but by fine-tuning them on parallel texts with the aim of improving alignment quality, they proposed a method for efficiently extracting alignments from these fine-tuned models and demonstrated that their models can consistently outperform all previous state-of-the-art models of the species [
23].
Schwenk et al. presented an approach based on multilingual sentence embeddings to automatically extract parallel sentences from the content of Wikipedia articles in 96 languages, extracting 135M parallel sentences for 16,720 different language pairs, and achieving strong BLEU scores for many language pairs [
24].
For Japanese-Chinese translation, Zhang et al. proposed the following three data augmentation methods to improve the quality of Japanese-Chinese NMT: (1) radicals as an additional input feature [
25]; (2) the created Chinese character decomposition table [
26]; (3) a corpus augmentation approach [
27], considering the lack of resources in bilingual corpora.
The related works above are sorted by year. We also show the classification of these related works on five aspects: (1) Corpus linguistics; (2) Japanese-Chinese bilingual corpora; (3) Web-crawled corpora; (4) other corpora; (5) corpus augmentation through a summarized
Table 1.
The above related research showed that corpora play an important role in improving translation accuracy and in other directions of language processing. Thus, the construction of a Japanese-Chinese bilingual corpus for NMT has significant implications for the resource scarcity problem. In this research, we aim to develop Japanese-Chinese machine translation and construct a Japanese-Chinese bilingual corpus of a certain scale.
3. Construction of Japanese-Chinese Bilingual Corpus
The corpus to be constructed, WCC-JC, is a collection of Japanese-Chinese bilingual sentences from the Web. This method discovers websites that may contain Japanese-Chinese bilingual sentences, and attempts to extract bilingual sentences from the Web data.
3.1. Web Crawling
Considering a website that contains many Japanese-Chinese bilingual texts, we use Scrapy (
https://scrapy.org/ (accessed on 10 October 2021)) to retrieve subtitle files from the website (
http://assrt.net/ (accessed on 10 June 2020)) that contains subtitle files of movies, dramas, and TV series. In these subtitle files, there are bilingual translations of slang, spoken language, explanatory text, and story commentary. These are areas that have not been dealt with much in the existing corpora.
3.2. Extraction of Bilingual Sentences
Most of the acquired subtitle files are advanced SubStation Alpha (ASS) files.
Figure 1 shows an example of the contents of an ASS file (dummy contents). As shown in the figure, in the dialogue line of the ASS file, the information of display start time, end time, style, subtitle display content, and so on are described. The language information often appears in the layer field (the first “0” in the figure) and the style field (“DefaultJp” in the figure).
If there is a dialogue line containing one of “ja”, “jp”, “日 (Japan)” in the style name, the style is judged to be Japanese.
If there is a dialogue line containing one of “cn”, “ch”, “zh”, “中 (China)”, or “default” in the style name, the style is considered to be Chinese. If neither Japanese style nor Chinese style is found, it is judged that the subtitle file does not contain Japanese-Chinese bilingual subtitles.
After determining whether the dialogue lines are Japanese or Chinese, the dialogue lines with Japanese style and Chinese style are sorted in ascending order by start time (value of the start field in dialogue lines), respectively. The correspondence is stored by extracting the corresponding bilingual sentences in the timeline of start (value of the start field in dialogue lines) and end (value of the end field in dialogue lines). If the timelines do not correspond exactly, we also consider contextual one-to-many and many-to-many relationships to check whether the timelines between multiple sentence pairs correspond correctly. If the timelines of multiple sentence pairs correspond accurately, we treat the multiple sentence pairs as one bilingual pair. This allows corresponding to as many pairs of bilingual sentences as possible. Finally, we obtained the raw parallel corpus.
3.3. Text Processing
Before corpus segmentation, the text in the raw parallel corpus needs to be normalized. We perform text normalization by changing traditional Chinese characters to simplified Chinese characters and using zenhan (
https://pypi.org/project/zenhan/ (accessed on 10 October 2021)) to normalize Japanese katakana to full-width format, respectively. Finally, the text is sorted and duplicates are removed to obtain the filtered parallel corpus.
3.4. Corpus Segmentation
Since the generated corpus WCC-JC consists of subtitle data of many works, it is necessary to extract validation data (development data) and test data for NMT. Therefore, using other corpora as a reference, we decided that 2000 sentence pairs of ten characters or more were randomly extracted twice as the development data and the test data from the collected sentence pairs, and the remaining sentence pairs were used as training data.
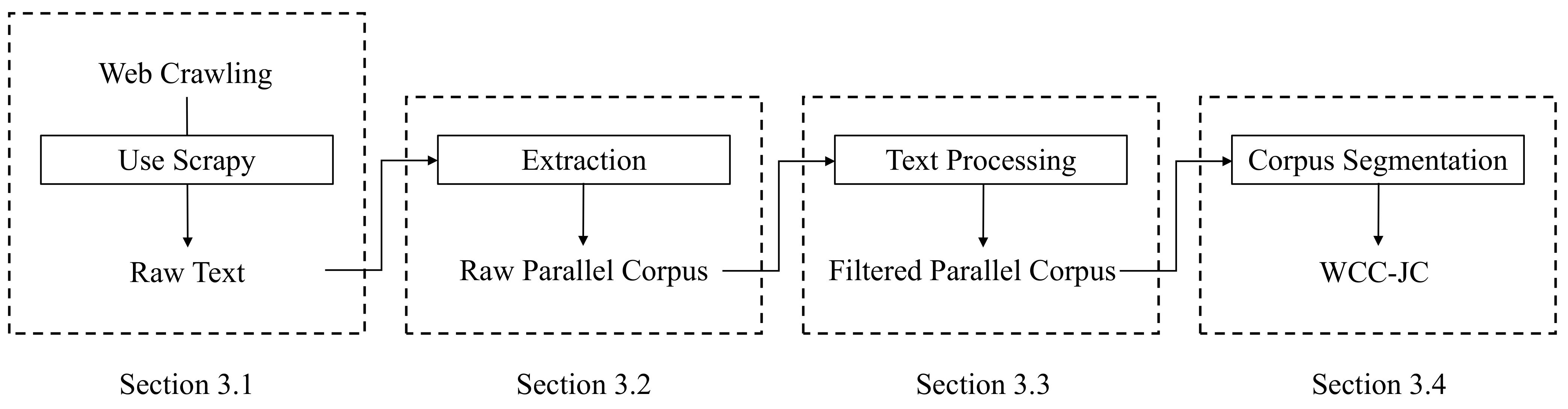
Figure 2 shows the whole workflow of the corpus construction. It is mainly divided into four steps: (1) Web crawling; (2) extraction; (3) text processing; (4) corpus segmentation. The above are also the contents of
Section 3.1,
Section 3.2,
Section 3.3 and
Section 3.4.
Table 2 shows the number of sentences in the ASPEC-JC, OpenSubtitles, and the constructed corpus. It can also be seen that, in terms of capacity, ASPEC-JC > OpenSubtitles > WCC-JC. This is mainly due to the length of the sentences in the corpus.
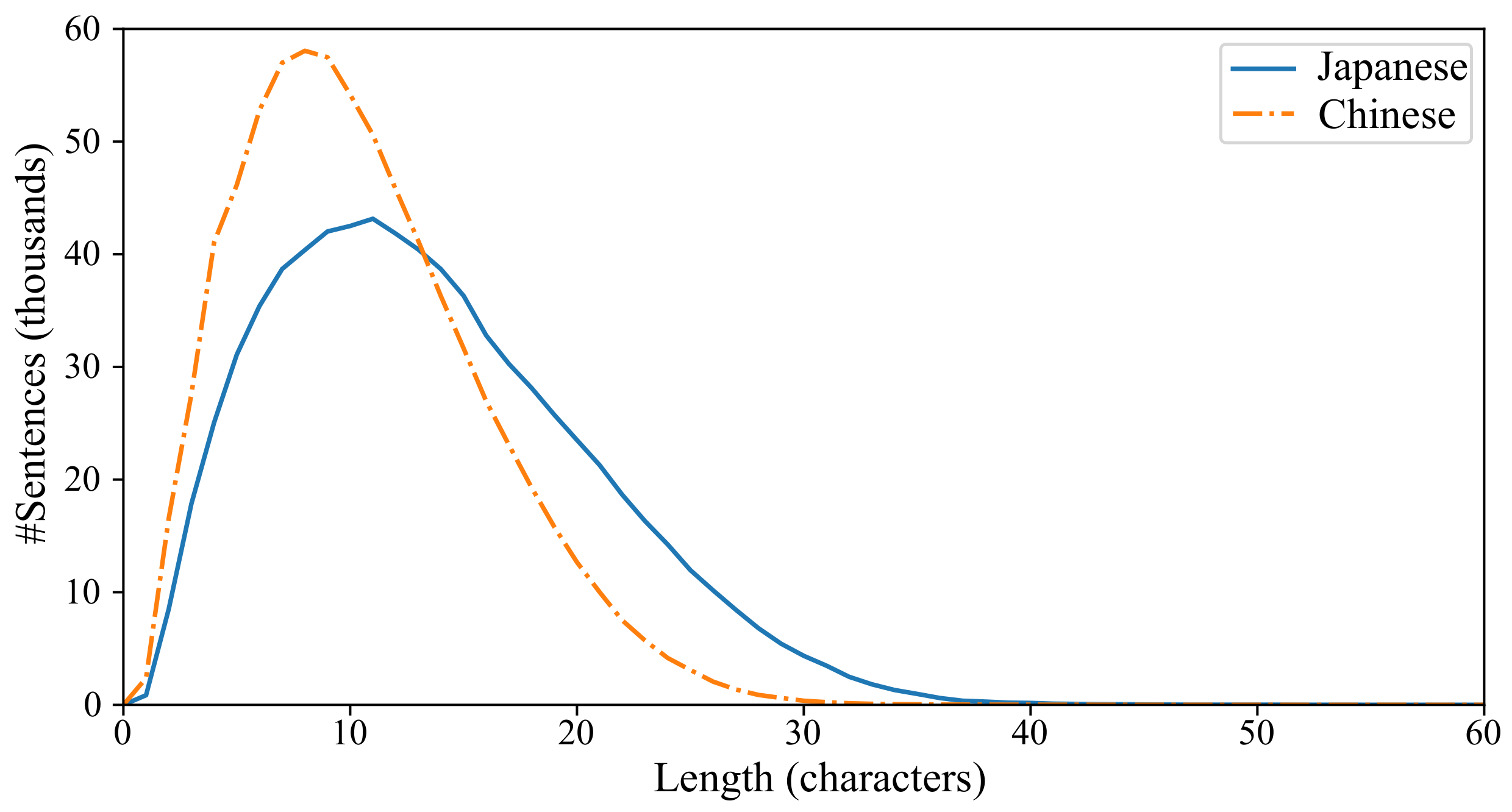
Figure 3 shows a right-skewed sentence length distribution. The average length of Chinese sentences and Japanese sentences are 10.6 and 13.7, respectively. The content of the WCC-JC is composed of spoken subtitles, and the sentences are generally shorter. Even though the number of sentences is higher than ASPEC-JC, it does not contain as much information as ASPEC-JC.
6. Conclusions
In this research, we introduced a Japanese-Chinese bilingual corpus: WCC-JC. This corpus was constructed by crawling the Web on a large scale and automatically collecting Japanese-Chinese bilingual sentences. In the end, about 753k sentence pairs of Japanese-Chinese bilingual data were obtained. The corpus is one of the largest Japanese-Chinese corpora available at present, and includes bilingual texts in spoken languages, which have not been widely treated in existing corpora.
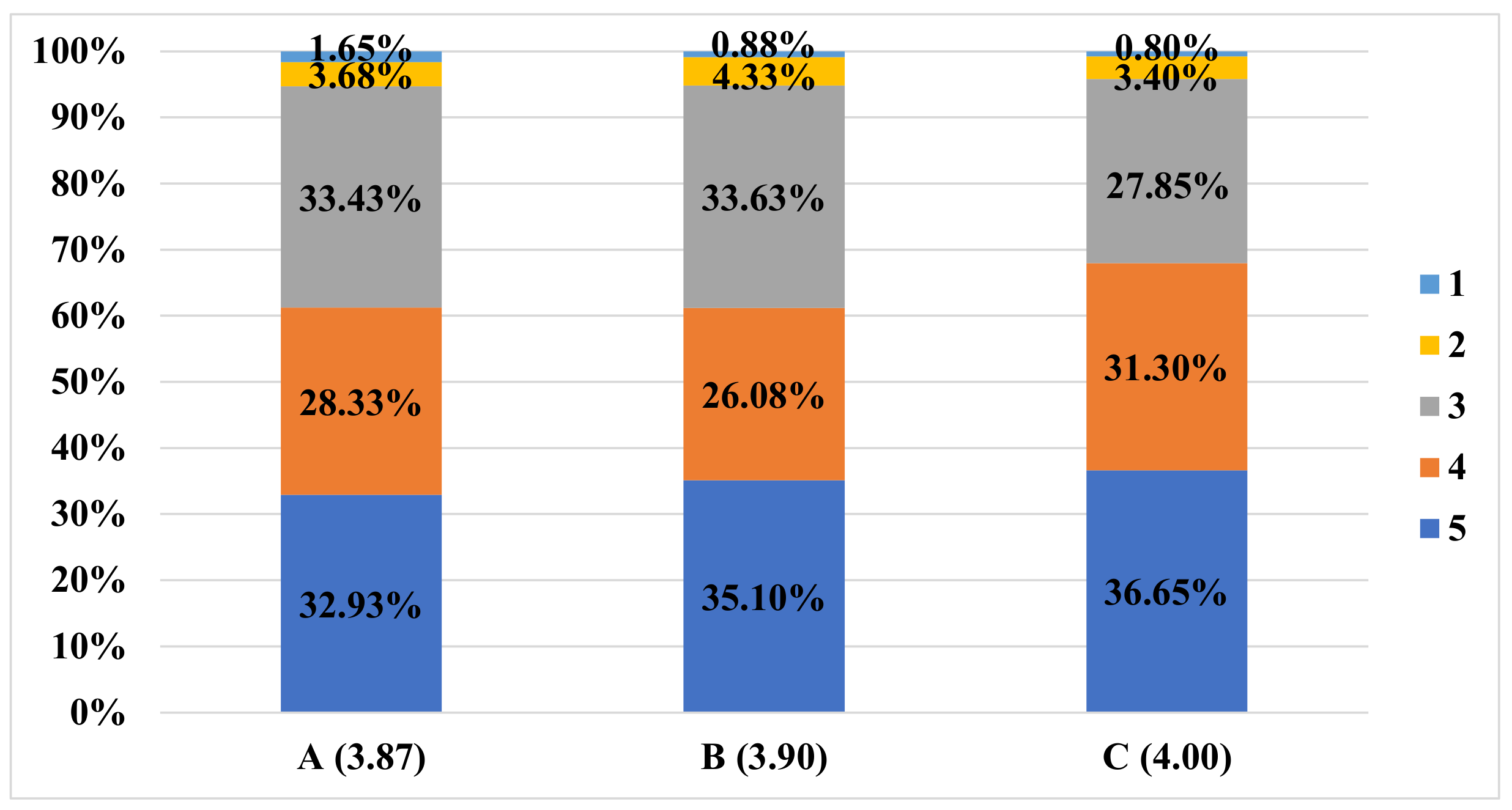
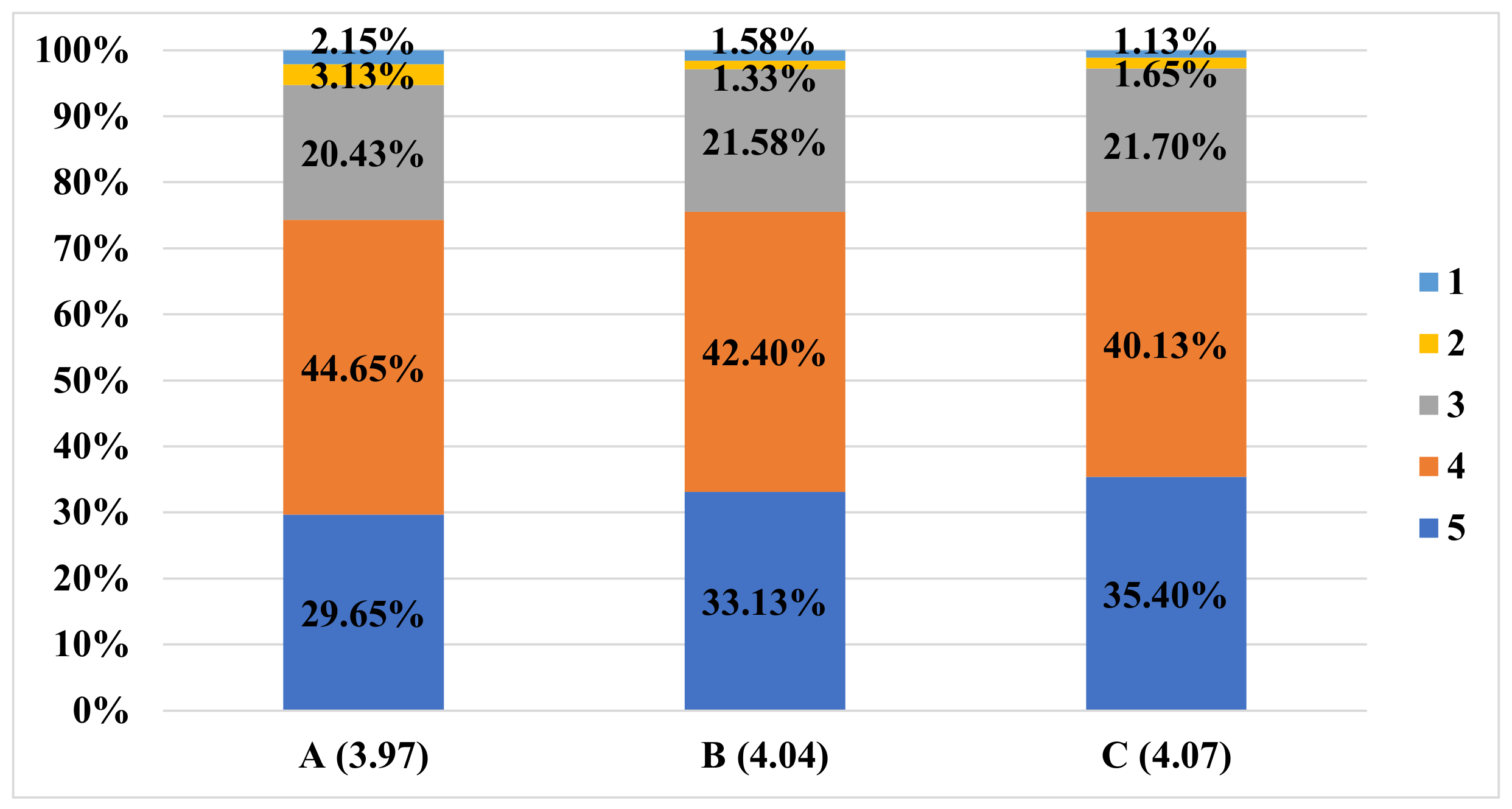
In the experiments using conversational sentences extracted from language course textbooks, we confirmed that although the BLEU values were low, the translation accuracy was the highest among the compared Japanese-Chinese corpora. We also obtained relatively high-level results from the manual evaluations.
Future works include constructing a larger-scale Web-crawled corpus. Another important issue is to improve the accuracy of the alignment of bilingual sentences by the subtitle display time. We are also considering adding more language pairs in the future.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}