Abstract
Knowledge graph (KG) reasoning improves the perception ability of graph structure features, improving model accuracy and enhancing model learning and reasoning capabilities. This paper proposes a new GraphDIVA model based on the variational reasoning divergent autoencoder (DIVA) model. The network structures and calculation processes of the models are analyzed. The GraphSAGE algorithm is introduced into the path reasoning module to solve the inability of the original model to perceive the features of the graph structure, which leads to a decline in the accuracy rate. Hence, GraphDIVA can achieve a higher accuracy rate with fewer learning iterations. The experiments show the efficiency and effectiveness of our model and proves that our method has a better effect on the accuracy rate and training difficulty than the baseline model on the FB15k-237 and NELL-995 benchmark datasets.
1. Introduction
A knowledge graph (KG) [1], which can be applied to simple machine learning and statistics, adds reasoning to achieve results that traditional models struggle to attain. KGs have been applied in many fields, such as environmental monitoring [2], crisis management [3], and tourism [4], and have achieved excellent results. KG reasoning methods are mainstream, from traditional logic reasoning to machine learning reasoning [5]. Inference techniques can be divided into path-based, feature-based, and autoencoder-based methods. Based on path reasoning, by identifying and classifying connection paths, one can judge the relationship among entities and complete reasoning tasks. Feature-based reasoning models do not focus on obtaining connection paths between entities but directly classify the features of the entities or the features of a given path to obtain the reasoning results. Based on the structure of the variational autoencoder (VAE) [6], a path model based on identifying the connection paths between entities and a feature model based on the advantages of perfect path quality judgment were combined to avoid their respective defects and ultimately achieved performance improvements.
The research found that the DIVA model performed better than a single model based on path- and feature-based reasoning. In order to improve the stability of the existing KG reasoning model and deal with noisier environments, Chen et al. [7] divided the knowledge graph reasoning problem into two steps: pathfinding and path reasoning. By improving the interaction between the two steps, the problem is constructed as a potential variable graph model. The path is regarded as the potential variable; the relationship is regarded as the variable that can be observed after a given entity pair; the pathfinding module is regarded as an a priori distribution to infer the potential link; and the path reasoning module is regarded as a likelihood distribution to divide the potential link into multiple categories, so as to better summarize the unknown situation. However, when the graph structure is more complicated, DIVA experiences an accuracy decline. Therefore, the focus of this paper is on improving the DIVA model by realizing the perceived features of the adjacent graph structure and solving the performance bottleneck of the original model. The contributions of this paper are as follows:
- We propose a graph variational reasoning model framework (GraphDIVA), which combines a graph neural network and introduces a pretraining process to improve the reasoning performance of the knowledge graph.
- We introduce the GraphSAGE algorithm into the path reasoning module to generate the path feature matrix, enhance the model’s perception of the graph structure, and improve the accuracy of the model.
- We demonstrate that our method can scale up to large KGs and achieve better results on two popular datasets.
The rest of this article is arranged as follows. Section 2 reviews and discusses the work related to the knowledge inference algorithm. Section 3 describes the DIVA model, the GraphSAGE algorithm, and the GraphDIVA model structure and calculation process. Section 4 describes the dataset, training environment, path search module pretraining, and related parameter settings used in the experiments. Then, we verify the efficiency and effectiveness of our model through extensive experiments and analyze the experimental results. Section 5 concludes and discusses future work.
2. Related Work
The first path inference algorithm, the path ranking algorithm (PRA), was developed in 2010 by Lao et al. [8]. The PRA is based on a random walk strategy to complete a search process for the multihop connection paths between entities. Then, Xiong et al. [9] proposed DeepPath methods for KG reasoning. In the same year, Das et al. [10] proposed the MINERVA reasoning algorithm based on KGs and enhanced learning. The earliest feature-based model, TransE [11], was proposed in 2013, as well as knowledge graph entities and relationships in KGs to low-dimensional vector spaces. On the basis of TransE, other authors have proposed successive methods, such as TransH [12], TransD [13], TransR [14], and TransSparse [15], which indicates the effectiveness of this idea. Neelakantan et al. [16] proposed a KG inference model based on a compound vector space. Das et al. [17] proposed a chain-of-reasoning model. Zhang et al. [18] proposed a knowledge map question-and-answer model based on variational reasoning in 2017.
A few months after the DIVA model was proposed, Chen et al. [7] proposed a single-sample knowledge graph reasoning model for a single-hop relationship. Compared with the DIVA route that focuses on extracting paths and learning path features, the model directly compares the structural features of the knowledge graph spectrum subgraph with the target entity as the core to realizing the ability of single-sample learning. Although the structure is very simple, it has a greatly improved performance compared with the previous DIVA model structure diagram. CNNs were designed only for continuous data with regular sizes, such as image and voice data. The discrete and irregular characteristics of graph structure data are quite different. Therefore, the research community has been exploring how to apply CNN ideas to graph structure data [19]. In 2015, Duvenaud et al. [20] introduced a CNN to graph data to extract molecular structure features, but this method is used only for molecular structure graphs and lacks a systematic definition. In 2017, Kipf and Welling [21] systematically proposed a graph convolutional network (GCN) and, for the first time, defined the convolution operation on graph structure data utilizing single-sample learning methods. Wang et al. [22] proposed a knowledge graph reasoning model based on the attention mechanism GCN graph convolution network in 2019. The author used GCN to convolute the original graph structure directly, extract the topology information of the training sample in the knowledge graph, and finally generate the feature vector and predict it. In the experiment, the performance of the model using GCN for feature analysis was significantly improved compared with the traditional feature-based method. The model can only be trained on a fixed network structure and needs to be retrained after the network structure changes. It has poor adaptability to more dynamic graph data. In 2021, Peng et al. [23] proposed a new path-based reasoning method, with k-nearest neighbor and the position embedding method. This method can improve upon path reasoning methods that ignore both the overlapping phenomenon of paths between similar relations and the order information of relations in paths. Tiwari et al. [24] integrated a graph self-attention (GSA) mechanism to capture more comprehensive entity information from the neighboring entities and relations. They trained the agent in one pass to reduce the problem complexity. Wang et al. [25] proposed the Deep-IDA framework, which applies neural networks and reinforcement learning (RL) to empower the IDA algorithm to tackle the path discovery problem in KG reasoning. In 2022, Liu et al. [26] proposed a dynamic knowledge graph reasoning framework. They used the long short-term memory (LSTM) and the Markov decision process to efficiently model the path reasoning, which incorporates the embedding of actions and search history into the feed-forward neural network as the policy network. Moreover, this realized dynamic path reasoning. Zhang et al. [27] introduced a relational directed graph (r-digraph) composed of overlapped relational paths to capture the KG’s local evidence and proposed a variant of the graph neural network, i.e., RED-GNN. RED-GNN makes use of dynamic programming to recursively encode multiple r-digraphs with shared edges and utilizes a query-dependent attention mechanism to select the strongly correlated edges. It achieved significant performance gains in both inductive and transductive reasoning tasks over existing methods. Zhu et al. [28] applied the hierarchical reinforcement learning framework, which dismantles the task into a high-level process for relation detecting and a low-level process for entity reasoning. They introduced a dynamic prospect mechanism for low-level policy where the information can guide us to a refined and improved action space, assisted by an embedding-based method. The results demonstrated the interpretability of simultaneous reasoning processes.
3. Methods
This section introduces the DIVA model method, the GraphSAGE algorithm, and the GraphDIVA model structure and calculation process.
3.1. DIVA Model
Inspired by the VAE [6] (proposed in 2013), the DIVA model uses the VAE structure in its design to combine a path search and path reasoning. The encoder compresses the input image by encoding. It is converted to a low-dimensional implicit variable conforming to a priori distribution , and the process is expressed by (1). Next, the decoder decodes the hidden variable and upgrades it into a generated image with the exact dimensions of the original image. The process is expressed by (2). During training, the parameters of the encoder and the decoder are updated simultaneously to improve the encoding quality and enhance the generating ability of the decoder. For the sample , the loss function is shown in (3). DIVA is partially adjusted in the process of applying the VAE. Finally, the KG reasoning task can be described as finding the probability distribution of the potential relationships between entity pairs, as shown in (4). DIVA relates the posterior distribution in the VAE to the path search module , and the learning efficiency is improved by adding the feature vector of the annotated relationship in the search decision. After the learning of the posterior distribution is complete, the prior distribution approaches the posterior distribution by (5), and finally, the training process of the path search module is completed.
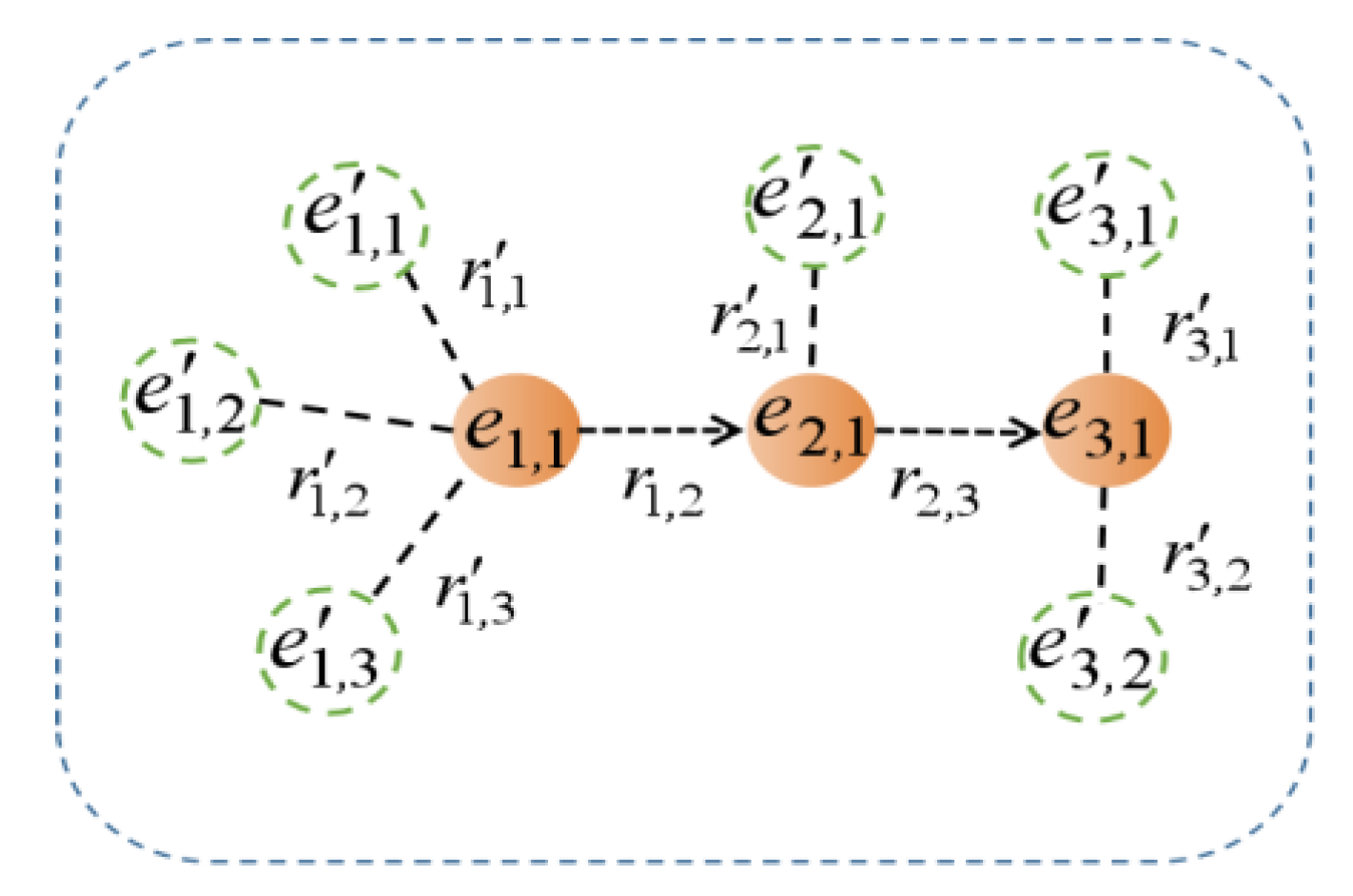
The process of the path reasoning module in generating the path characteristic matrix is shown in Figure 1, in which the solid circle represents the entity in the path, the arrow represents the relationship in the path, and the hollow circle and virtual connecting line represent the entity and relationship adjacent to the path entity. The path characteristic matrix is directly composed of the stacking of entities and relationship embedded vectors in the path.
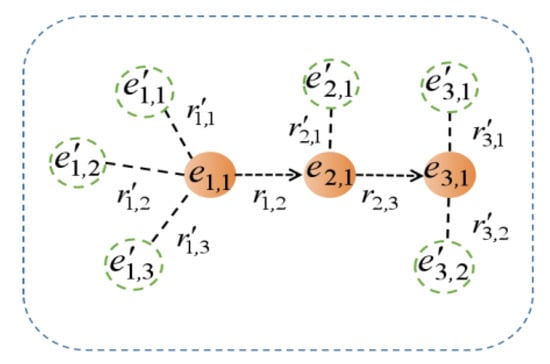
Figure 1.
DIVA path feature generation process diagram.
3.2. GraphSAGE Algorithm
The GraphSAGE algorithm was proposed by Hamilton et al. [29] in 2017 to perceive the characteristics of a graph structure, and it has very good adaptability to dynamic graph structures. Unlike the GCN [30], which requires a specific calculation structure, GraphSAGE applies a calculation strategy. The algorithm assumes that the characteristics of a node are determined by the surrounding nodes, and the final node characteristics can be obtained after multiple rounds of sampling and aggregation. Furthermore, the feature aggregation operation is defined as a recursive process that first diffuses sampling from the central node layer by layer and then aggregates layer by layer from the outermost layer. This method can solve the problem of insufficient GCN flexibility. The sampling process starts from the final node, spreads out along the adjacent nodes layer by layer, and sequentially adds nodes that require final aggregation features. When selecting neighbors, a fixed number can be randomly selected, or the types of edges and adjacent nodes can be screened, which has a very high degree of freedom. When all nodes are sampled, the features are aggregated layer by layer from the outermost layer. Through the aggregation process, the output feature of the adjacent nodes includes the topological features of the subgraph in which they are located, and the features of the final node also include the topological features of the subgraph within two hops.
3.3. Graph DIVA Model
In the path reasoning module of the DIVA model, the path feature matrix is directly composed of the stacking of entities and relationship embedded vectors in the path, which lacks the characteristics of the subgraph where the entities in the path are located. The three convolution windows in the path module can only extract the sequence characteristics of the path itself from the feature matrix and cannot perceive the subgraph structure of the path. When the structure of the knowledge map is complex, the path reasoning module cannot effectively distinguish the path features, resulting in the phenomenon of performance degradation. Therefore, the focus of this paper is on improving the path feature generation process of the original model and increasing the environmental perception ability of the path reasoning module for the path subgraph to solve the problem of declining accuracy.
3.3.1. Path Feature Generation Process
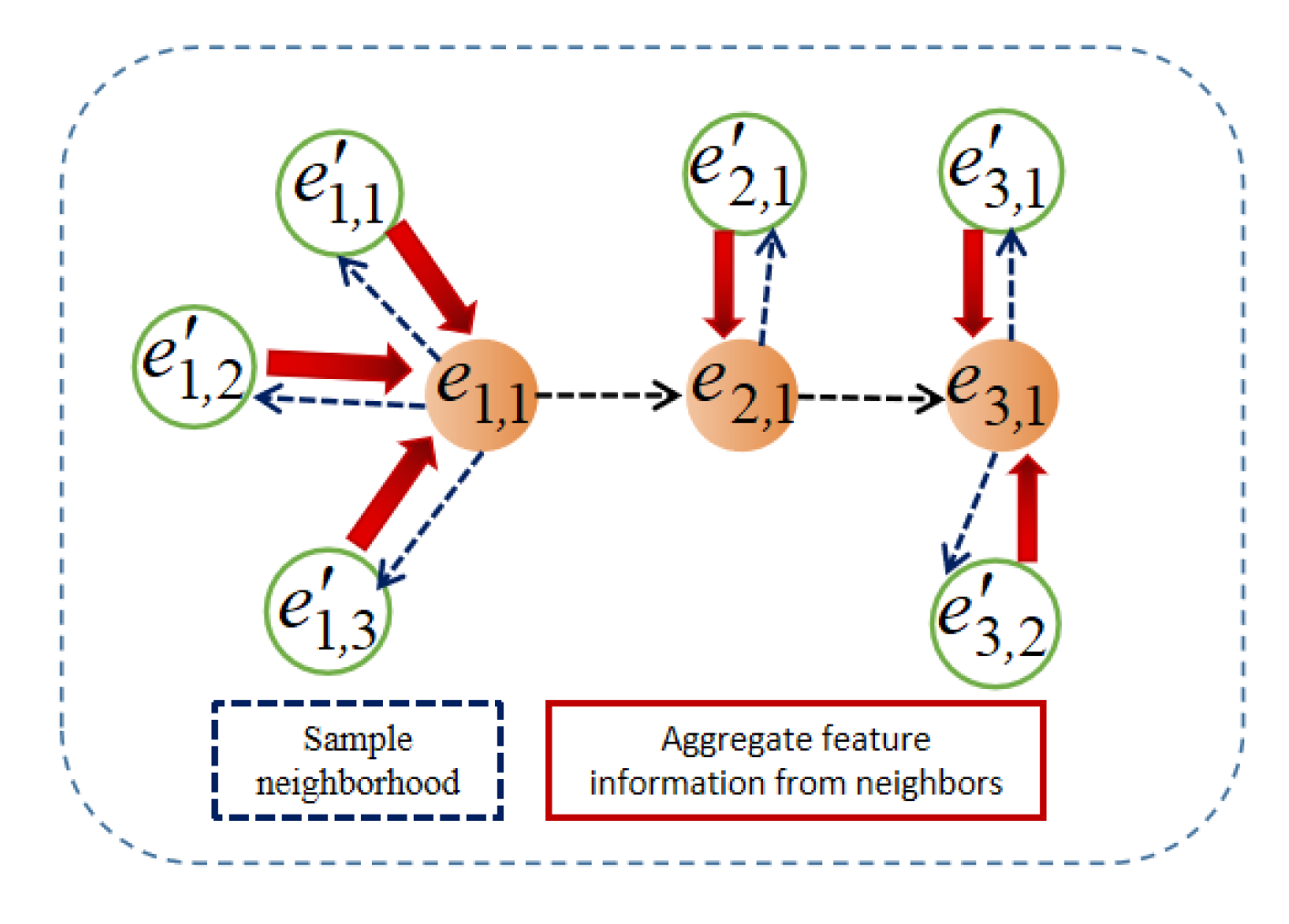
In order to improve the perception range of path features by the path reasoning module, when generating the path feature matrix, the GraphDIVA model introduces a GraphSAGE algorithm to sample and aggregate the subgraph structure where the path is located. The process is shown in Figure 2.
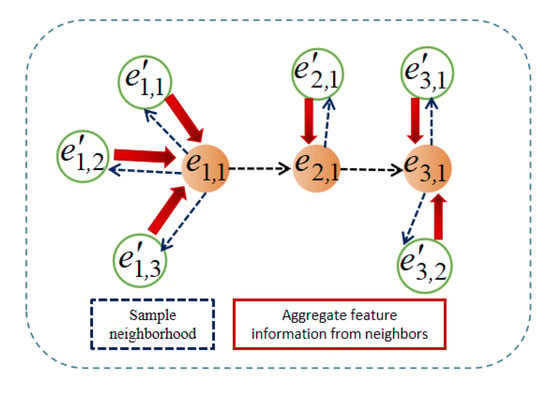
Figure 2.
GraphDIVA path feature generation process diagram.
At first, GraphSAGE is used to randomly sample several statical data and the connection relationship for each entity in the path, and then the MaxPooling strategy is used to aggregate the sampled embedding vectors to obtain the feature representation of the path entities and relationships. The detailed calculation process is shown in (6). In (7), indicates the relationship embedding vector and entity embedding vector at a certain step in the path, indicates that multiple adjacent entities are randomly selected from the path entity, indicates the entity and connection relationship embedding vector adjacent to the path entity, and is the final output for the path feature vector. The final generated path feature matrix comprises multistep feature vectors in the path.
3.3.2. Structure Diagram of Path Reasoning Module
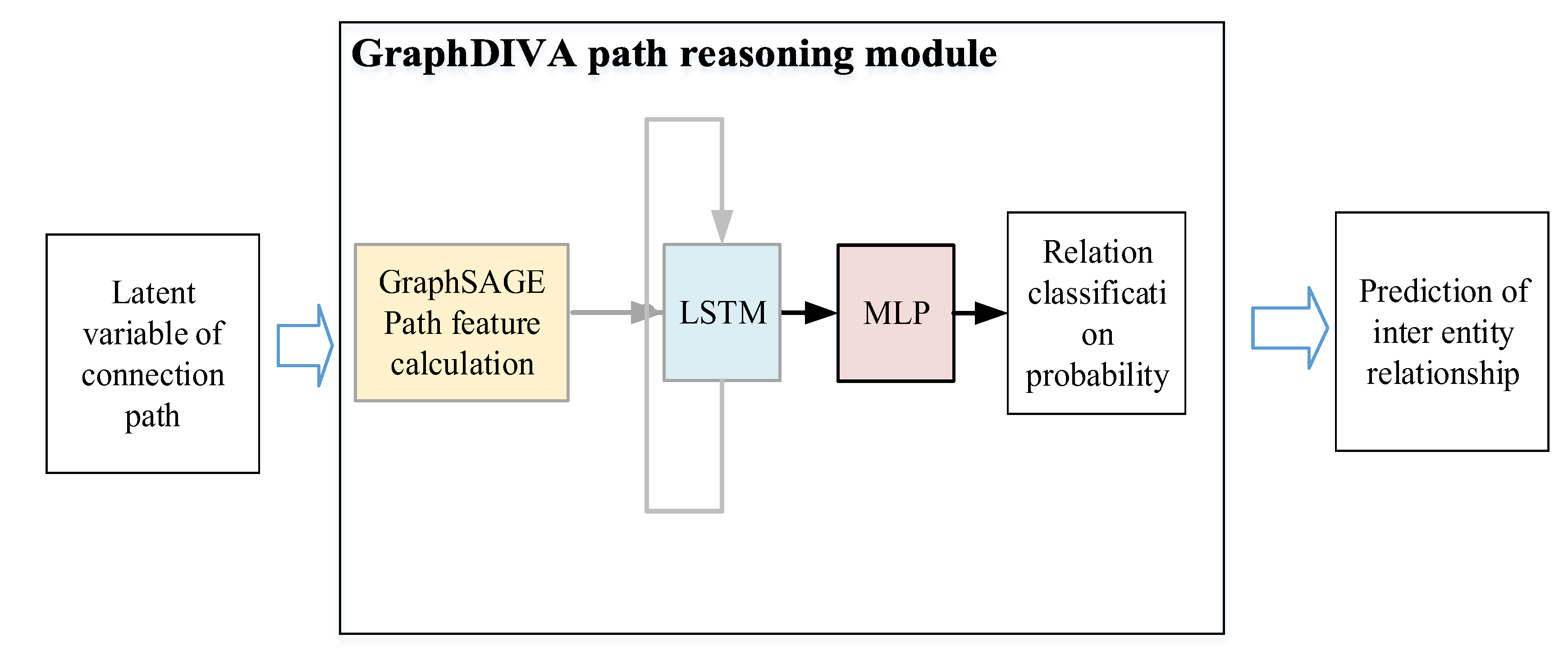
In order to improve the environment perception ability of the path reasoning module in relation to the subgraph, the GraphDIVA model first identifies the structural features of the subgraph where the entity in the path is located through GraphSAGE and then uses LSTM to extract the sequence features of the path. Finally, the vector connection is embedded and entered into the MLP fully connected network to calculate the current state characteristics, which significantly improves the perception range and ability of the model in relation to the graph. The GraphSAGE uses LSTM to calculate the ordered features of the path and finally uses the output vector of the LSTM as the feature vector of the path, as shown in (8) and (9). The adjusted GraphDIVA model is shown in Figure 3.
where is the characteristic of each time step of the LSTM calculation path and is a node in the graph.
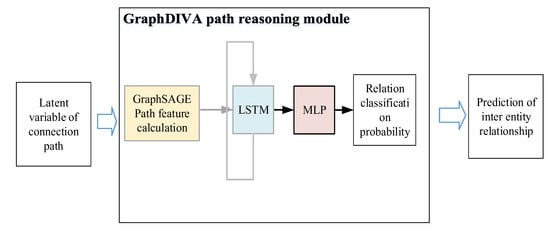
Figure 3.
GraphDIVA path reasoning module.
4. Experiments
This section describes the dataset, training environment, path search module pretraining, and related parameter settings used in the experiments. Then, we verify the efficiency and effectiveness of our model through extensive experiments and analyze the experimental results.
4.1. Datasets
In this paper, the experimental dataset was consistent with the deep path paper and DIVA paper and based on the published FB15k-237 [31] and NELL-995 [9] datasets. Fb15k-237 is a link prediction dataset created by the famous FreeBase, covering different fields such as sports, people, geography, film, and television. Nell-995 is derived from the famous never-ending language learning system [32], the data content generated after the 995th iteration. Parameters of the datasets included the number of entities, the number of relationships, the number of triples, and the types of tasks. Table 1 shows the size of the datasets.

Table 1.
Dataset information.
During the actual test, the tasks selected in this paper were as follows. FB15k-237 contained /film/director/film, /film/film/language, /film/film/written_by, /people/person/nationality, /tv/tv/program_languages, and so on. NELL-995 contained athletehomestadium, athleteplaysinleague, organizationheadquarteredincity, personborninlocation, worksfor, personleadsorganization, and so on.
Each task selected all the positive samples and the same number of negative samples. After random sorting, the first 200 samples were used as the training data for pretraining, and the first 100 samples were used as the training data for joint training. Next, an average of 320 samples were selected from the test set as the test data. Among them, the task data contained two different situations: low-quality labeled data with considerable noise, and high-quality labeled data to verify the effect of the model in terms of sensitivity and performance improvement.
Among them, the data annotation quality of/film/director/film, /film/film/language, worksfor, and personleadsorganization tasks was low and contained much noise. It was difficult to identify a significant performance gap between different model methods in previous tests. In the experiment, the above tasks were used to verify whether the GraphDIVA model was more sensitive to noise after enhancing the perception of the graph structure.
The data annotation quality of /film/film/written_by, /people/person/nationality, /tv/tv/program_languages, athletehomestadium, athleteplaysinleague, organizationheadquarteredincity, and personborninlocationtasks was high, and these are often used to indicate the performance differences between different models. In the experiment, the above tasks were used to verify whether the enhancement of the GraphDIVA model for graph structure perception could be translated into the final performance improvement.
While testing the final accuracy rate, the number of training sessions required for each of the two models to achieve the optimal performance in the experiment was investigated. In theory, after enhancing the perception of the graph structure, GraphDIVA can learn effective sample classification features more efficiently than the original model, so the number of training sessions required should also be significantly reduced.
4.2. Training Environment
The experiment used the TensorFlow 2.0.0 framework to train and execute the reasoning model. Based on the source code of the TensorFlow framework, the GraphDIVA model was implemented by inheriting and rewriting the layer and model classes. The hardware platform used a CPU to train and test the inference model. The experiment separately trained and tested the original DIVA and the improved GraphDIVA models. Table 2 shows the specific parameter values of the network.
Table 2.
Network parameters.
The main training parameters involved in the training process were the learning rate of the path search module during supervised pretraining, the maximum number of iterations, the maximum number of paths used by each sample, the number of iterations in joint training, the learning rate of the posterior distribution and path inference, and the learning rate of the module. The learning rate of the prior distribution and the number of paths generated from the posterior distribution for each sample in each round were also given. Details are shown in Table 3. Other than the posterior distribution during joint training, which used the stochastic gradient descent (SGD) optimizer, the other parts used the Adam optimizer.
Table 3.
Training parameters.
4.3. Path Search Module Training
In the experiment, to increase the training speed of the path search module, we pre-trained the path search module and used a bandwidth-based breadth-first search (BFS) algorithm to improve the search speed [33]. This method can provide more stable training samples and controllable time costs. Compared with direct joint training, the pre-trained path search module can reduce the probability of search failure to less than 5%.
4.4. Accuracy Rate Analysis
The original model and the improved model were trained and tested. In the experiment, the two models experienced overfitting in the later training stage, so the best checkpoints were recorded as the test results. The accuracy rates of the two models in the task are shown in Table 4 and Table 5.
Table 4.
FB15K-237 test results.
Table 5.
NELL-995 test results.
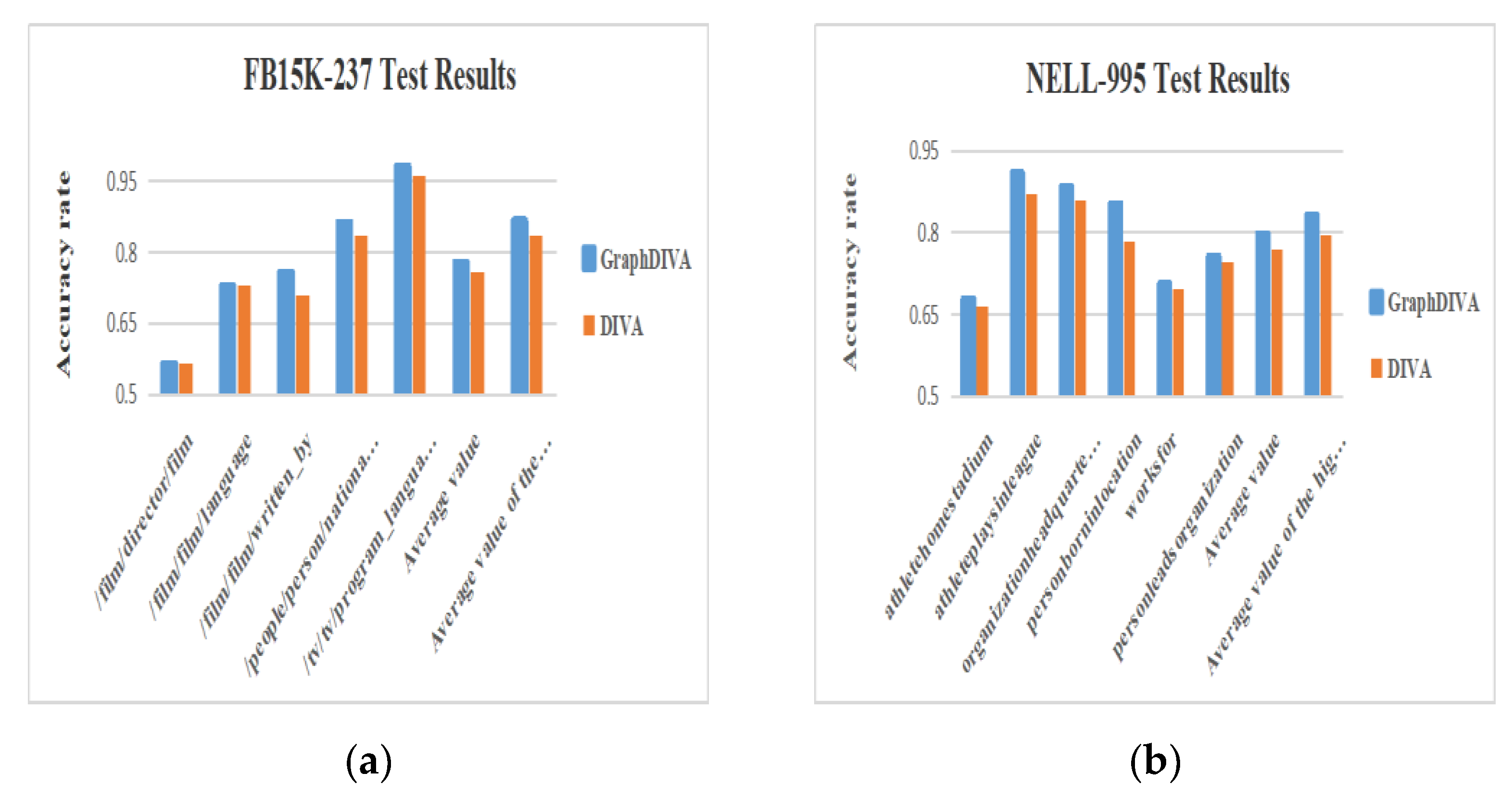
The experimental results indicated that the GraphDIVA model significantly improved the accuracy rate of the marked tasks compared with the original model. In the/film/film/written_by task, GraphDIVA increased the accuracy rate by 4.7% compared with the original model. In the/tv/tv/program_languages task, the original model had an extremely high accuracy of 96%, and GraphDIVA had an accuracy of 98%. The improvement in the personborninlocation task was the most obvious: the original model obtained an accuracy of 78.4%, and GraphDIVA obtained an accuracy of 85.3%, which is 6.9% greater. Finally, the average accuracy rates of GraphDIVA in the high-discrimination tasks were 3.2 and 3.7% higher than those of the original model; this showed a significant performance improvement and proved that graph structure features have a significant impact on inference tasks. Additionally, for noisy tasks, the accuracy rate of GraphDIVA was the same as that of the original model, and there was no excessive sensitivity to noise as a result of the addition of graph structure features, reflecting the practicality of the improvement. The test results are shown in Figure 4.
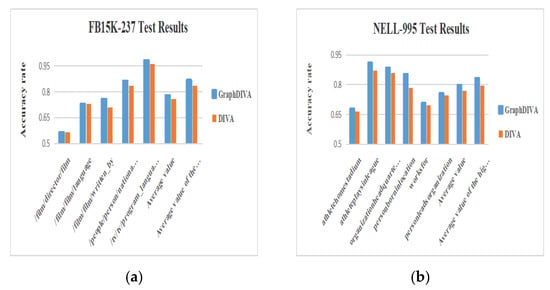
Figure 4.
(a) Description of FB15K-237 test results; (b) description of NELL-995 test results.
4.5. Number of Training Sessions
Training and testing were conducted on the dataset to verify the comparative effects of the original model and the improved model in terms of learning speed and training time. Table 6 and Table 7 show the training sessions required for the two models to achieve optimal results.
Table 6.
Number of training sessions required to obtain the best results on FB15K-237.
Table 7.
Number of training sessions required to obtain the best results on NELL-995.
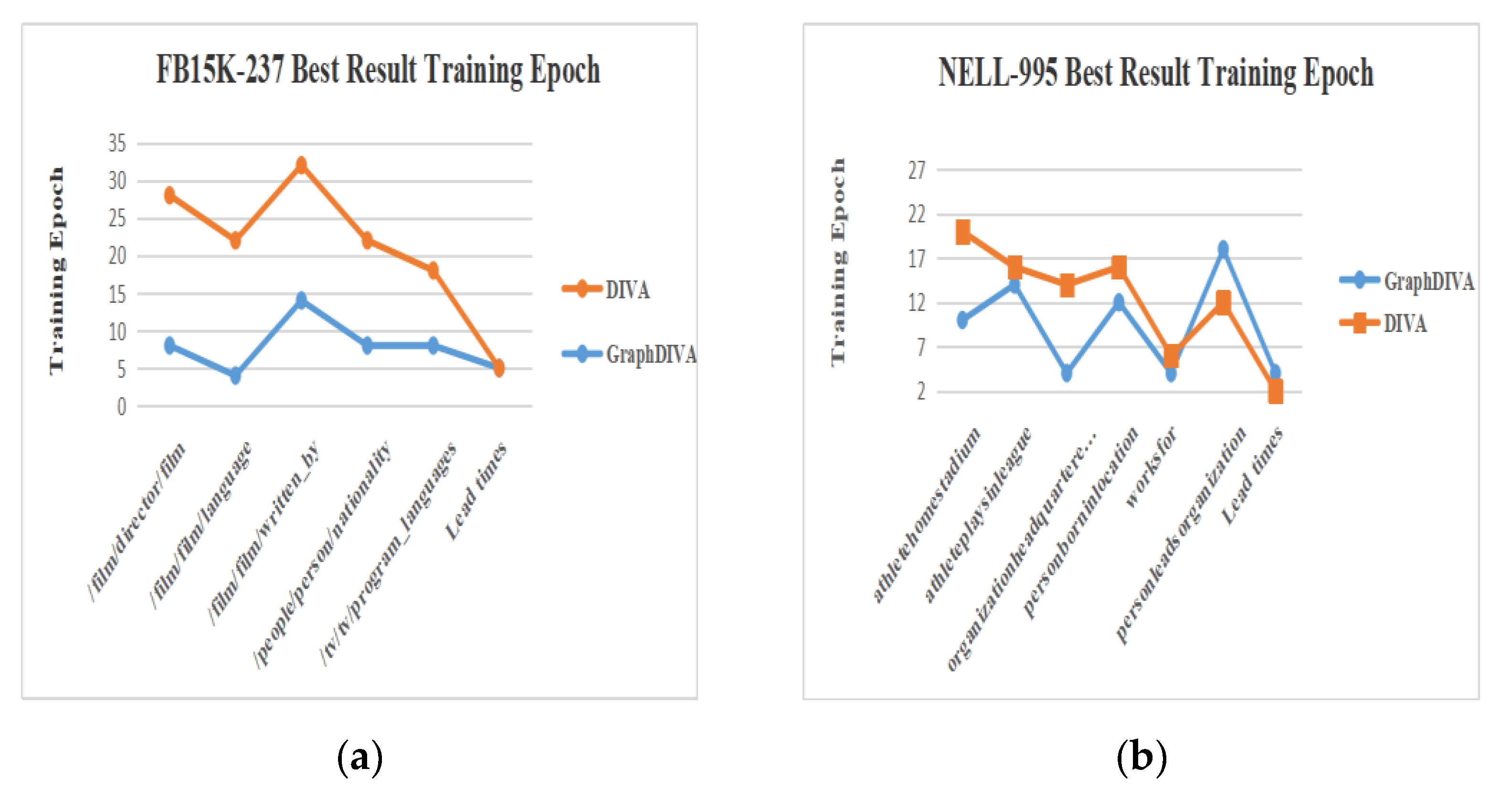
The above data show that the learning speed of GraphDIVA was significantly improved compared to the original model. For example, in the organizationalheadquarteredincity task, GraphDIVA only required four rounds of training to achieve the optimal effect. In comparison, DIVA required 14 rounds of training to achieve the optimal effect, and the final performance of DIVA was weaker than that of GraphDIVA. For noisy tasks, when /film/director/film and /film/film/language achieved comparable performances, the number of training sessions required by GraphDIVA was significantly reduced compared to that required by DIVA. Of the final 11 tasks, GraphDIVA was faster than the original model at 9 tasks, which proved that the graph structure perception improved the model. The best result training epochs are shown in Figure 5.
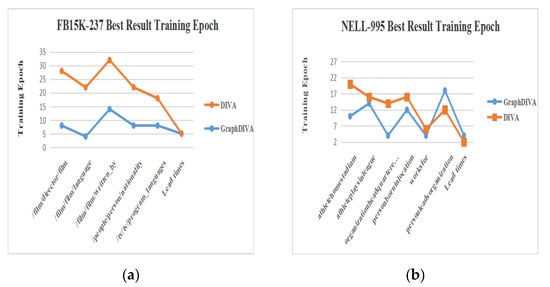
Figure 5.
(a) Depiction of FB15K-237 best result training epoch; (b) depiction of NELL-995 best result training epoch.
5. Conclusions and Future Work
In this paper, we proposed a new GraphDIVA model. This model was based on the variational reasoning DIVA model, which was analyzed from the two dimensions of the network model structure and calculation process. It introduced the GraphSAGE algorithm into the path reasoning module. It was used to solve the inability of the original model to perceive the features of the graph structure, which leads to a decline in the accuracy rate. The GraphDIVA model reduced the time required for model training while improving the accuracy rate, thereby realizing the feature perception of the adjacent graph structure and enhancing the learning and reasoning capabilities of the model. We trained the model on a public dataset. The experiments then established the efficiency and effectiveness of the model, which proved that our method had a better accuracy rate and training time than the baseline models using several benchmark datasets such as FB15k-237 and NELL-995.
By introducing the GraphSAGE algorithm into the path reasoning module, this paper solved the problem of the DIVA model’s inability to perceive the structural features of graphs. Although the performance of the new model was improved compared with the original model, the path search module became a new potential performance bottleneck. Because the path search can only realize a one-dimensional path representation, the vision of the path reasoning module is limited to only the narrow subnet centered on the path. Therefore, an essential future research direction will be further adjusting the architecture of the variational reasoning model to expand the range of graph features it can perceive.
Author Contributions
H.T.: literature research, data processing, methods, and writing; W.T.: funding acquisition, innovation analysis, and supervision; R.L.: literature research and experimental analysis; Y.W.: innovation analysis, project management, and supervision; S.W.: supervision and writing review; L.W.: innovation analysis, supervision, and writing review. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China, Grant No. 61901016.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hogan, A.; Blomqvist, E.; Cochez, M.; D’Amato, C.; de Melo, G.; Gutierrez, C.; Gayo, J.E.L.; Kirrane, S.; Neumaier, S.; Polleres, A.; et al. Knowledge graphs. arXiv 2020, arXiv:2003.02320v3. [Google Scholar]
- Caihua, Y.; Tonghui, K.; Jun, L. knowledge graph analysis of low carbon research in China. Resour. Sci. 2012, 10, 1959–1964. [Google Scholar]
- Xu, Z.; Zhang, H.; Hu, C.; Mei, L.; Xuan, J.; Choo, K.K.R.; Sugumaran, V.; Zhu, Y. Building knowledge base of urban emergency events based on crowdsourcing of social media. Concurr. Comput. Pract. Exp. 2016, 28, 4038–4052. [Google Scholar] [CrossRef]
- Tonghui, K.; Caihua, Y.; Qianjin, Z.; Qinjian, Y. Analysis of knowledge graph of tourism research from 2000 to 2010 based on CSSCI. J. Tour. 2013, 3, 114–119. [Google Scholar]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Chen, W.; Xiong, W.; Yan, X.; Wang, W. Variational knowledge graph reasoning. arXiv 2018, arXiv:1803.06581. [Google Scholar]
- Lao, N.; Mitchell, T.; Cohen, W. Random walk inference and learning in a large scale knowledge base. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; Association for Computational Linguistics: Edinburgh, UK, 2011; pp. 529–539. [Google Scholar]
- Xiong, W.; Hoang, T.; Wang, W.Y. Deeppath: A reinforcement learning method for knowledge graph reasoning. arXiv 2017, arXiv:1707.06690. [Google Scholar]
- Das, R.; Dhuliawala, S.; Zaheer, M.; Vilnis, L.; Durugkar, I.; Krishnamurthy, A.; Smola, A.; McCallum, A. Go for a walk and arrive at the answer: Reasoning over paths in knowledge bases using reinforcement learning. arXiv 2017, arXiv:1711.05851. [Google Scholar]
- Bordes, A.; Usunier, N.; García-Durán, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Curran Associates Inc.: Red Hook, NY, USA, 2013; pp. 2787–2795. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, AAAI, Québec City, QC, Canada, 27–31 July 2014; pp. 1112–1119. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Association for Computational Linguistics: Beijing, China, 2015; pp. 687–696. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; AAAI Press: Palo Alto, CA, USA, 2015; pp. 2181–2187. [Google Scholar]
- Ji, G.; Liu, K.; He, S.; Zhao, J. Knowledge graph completion with adaptive sparse transfer matrix. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, AAAI, Phoenix, AZ, USA, 12–17 February 2016; pp. 985–991. [Google Scholar]
- Neelakantan, A.; Roth, B.; McCallum, A. Compositional vector space models for knowledge base inference. In AAAI Spring Symposia 2015; AAAI: Palo Alto, CA, USA, 2015; pp. 1–4. [Google Scholar]
- Das, R.; Neelakantan, A.; Belanger, D.; McCallum, A. Chains of reasoning over entities, relations, and text using recurrent neural networks. arXiv 2016, arXiv:1607.01426. [Google Scholar]
- Zhang, Y.; Dai, H.; Kozareva, Z.; Smola, A.J.; Song, L. Variational reasoning for question answering with knowledge graph. In Thirty-Second AAAI Conference on Artificial Intelligence; AAAI Press: New Orleans, LA, USA, 2018; pp. 6069–6076. [Google Scholar]
- Geng, Q.; Zhou, Z.; Cao, X. Survey of recent progress in semantic image segmentation with CNNs. Sci. China Inf. Sci. 2018, 61, 051101. [Google Scholar] [CrossRef] [Green Version]
- Duvenaud, D.; Maclaurin, D.; Aguilera-Iparraguirre, J.; Gómez-Bombarelli, R.; Hirzel, T.; Aspuru-Guzik, A.; Adams, R.P. Convolutional networks on graphs for learning molecular fingerprints. arXiv 2015, arXiv:1509.09292. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Wang, H.; Lin, H.Z.; Lu, L.Y. Knowledge Map Inference Algorithm Based on AT_GCN Model[J/OL].Computer Engineering and Application:1-8[2019-08-15]. Available online: http://kns.cnki.net/kcms/detail/11.2127.TP.20190719.0943.005.html (accessed on 25 January 2021).
- Peng, Z.; Yu, H.; Jia, X. Path-based reasoning with K-nearest neighbor and position embedding for knowledge graph completion. J. Intell. Inf. Syst. 2021, 58, 513–533. [Google Scholar] [CrossRef]
- Tiwari, P.; Zhu, H.; Pandey, H.M. DAPath: Distance-aware knowledge graph reasoning based on deep reinforcement learning. Neural Netw. 2021, 135, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Hao, Y.; Chen, F. Deepening the IDA* algorithm for knowledge graph reasoning through neural network architecture. Neurocomputing 2021, 429, 101–109. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, S.; Chen, C.; Gao, T.; Xu, J.; Shu, M. Dynamic knowledge graph reasoning based on deep reinforcement learning. Knowl.-Based Syst. 2022, 241, 108235. [Google Scholar] [CrossRef]
- Zhang, Y.; Yao, Q. Knowledge graph reasoning with relational digraph. In Proceedings of the ACM Web Conference, Lyon, France, 25–29 April 2022; pp. 912–924. [Google Scholar]
- Zhu, A.; Ouyang, D.; Liang, S.; Shao, J. Step by step: A hierarchical framework for multi-hop knowledge graph reasoning with reinforcement learning. Knowl.-Based Syst. 2022, 248, 108843. [Google Scholar] [CrossRef]
- Hamilton, W.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Połap, D.; Woźniak, M.; Wei, W.; Damaševičius, R. Multi-threaded learning control mechanism for neural networks. Future Gener. Comput. Syst. 2018, 87, 16–34. [Google Scholar] [CrossRef]
- Toutanova, K.; Chen, D.; Pantel, P.; Poon, H.; Choudhury, P.; Gamon, M. Representing text for joint embedding of text and knowledge bases. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 1499–1509. [Google Scholar]
- Betteridge, J.; Carlson, A.; Hong, S.A.; Hruschka, E.R.; Law, E.L.M.; Tom, M.; Wang, S.H. Toward never ending language learning. In Proceedings of the AAAI Spring Symposium: Learning by Reading and Learning to Read, Stanford, CA, USA, 23–25 March 2009; pp. 1–2. [Google Scholar]
- Liu, S.; Xia, Z. A two-stage BFS local community detection algorithm based on node transfer similarity and local clustering coefficient. Phys. A Stat. Mech. Appl. 2020, 537, 122717. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).