
Novel Vision Transformer–Based Bi-LSTM Model for LU/LC Prediction—Javadi Hills, India


Abstract
:1. Introduction
2. Motivations and Contributions
- The novel Vision Transformer–based Bidirectional long-short term memory (Bi-LSTM) model is proposed for predicting the LU/LC changes of Javadi Hills, India.
- The use of the LST map with the Vision Transformer–based LU/LC classification map provides the main advantage in achieving good validation accuracy with less computational time during the process of LU/LC prediction analysis through the Bi-LSTM model.
- The impacts of the Multi-Satellite System (LISS-III multispectral with the Landsat TIRS, RED, and NIR bands) on the proposed LU/LC prediction model for Javadi Hills, India, are analyzed.
- Explainable Artificial Intelligence (XAI), an application-based explanation, is also introduced for validating the predicted results through the Google Earth Engine platform of Google Cloud so that the predicted results will be more informative and trustworthy to the urban planners and forest department to take appropriate measures in the protection of the environment.
3. Materials and Methods
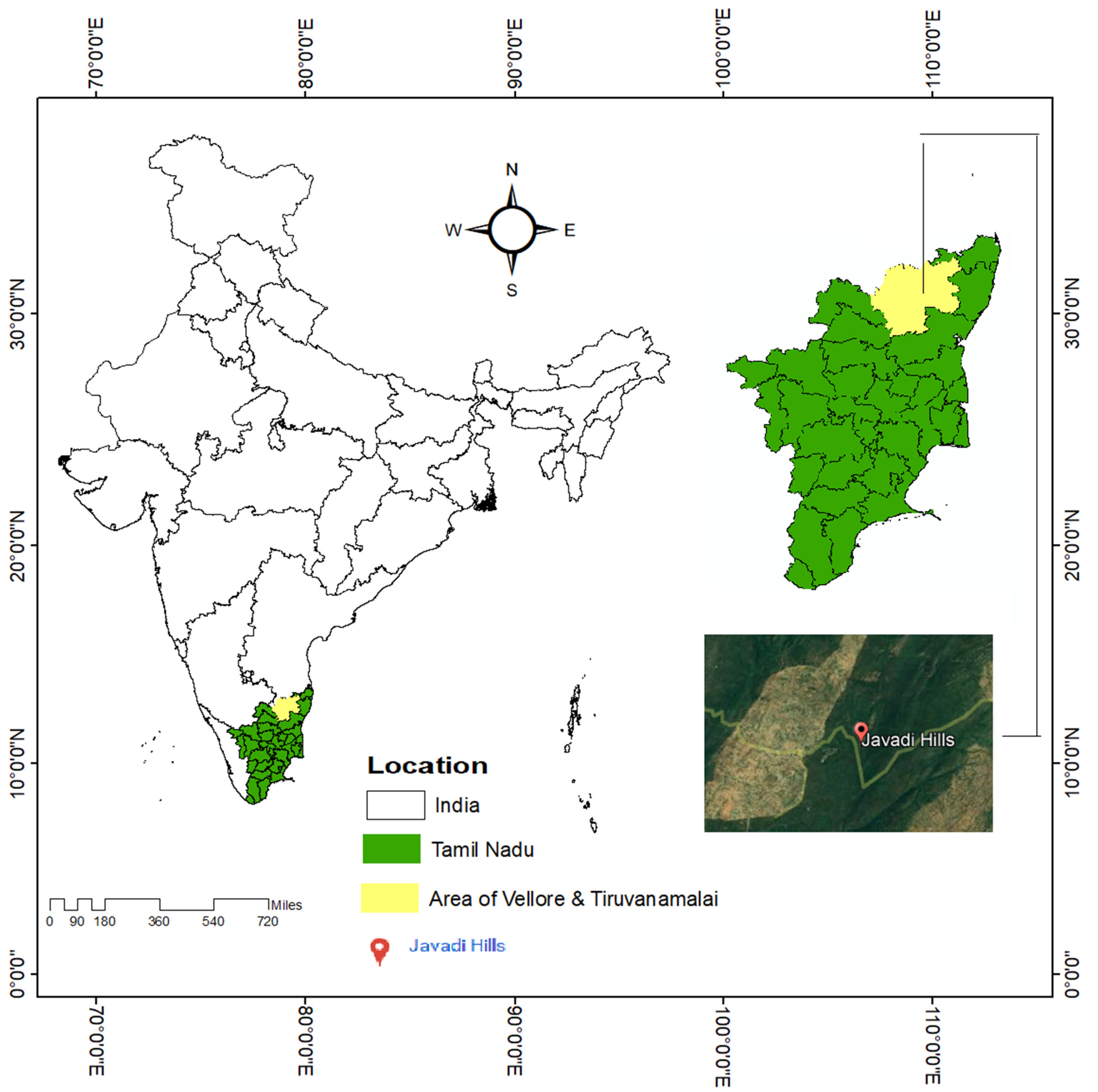
3.1. Study Area and Data Acquisition
3.2. Proposed Vision Transformer Model for LU/LC Classification
3.3. Land Surface Temperature
3.4. Bidirectional Long Short-Term Memory Model for LU/LC Prediction
3.5. Application-Based Explainable Artificial Intelligence and Its Importance
4. Proposed LU/LC Prediction Using Vision Transformer–Based Bi-LSTM Model
- The LISS III satellite images for the years 2012 and 2015 of Javadi Hills, India, were collected from Bhuvan-Thematic Services of the National Remote Sensing Centre (NRSC), Indian Space Research Organization (ISRO).
- The Landsat satellite images for the years 2012 and 2015 of Javadi Hills, India, were collected from the United States Geological Survey (USGS), United States.
- Atmospheric, geometric, and radiometric corrections were performed to provide better visibility in the acquired LISS-III and Landsat images.
- The proposed Vision Transformers for classifying LU/LC classes were successfully performed for the years 2012 and 2015 of the LISS-III image.
- An LST map was calculated for the years 2012 and 2015 from Landsat TIRS images for extracting the spatial features.
- The relationship between the spatial features of the LST map with the LU/LC classification map were used to provide good validation results during the prediction process.
- The Bi-LSTM model was successfully applied to forecast the future LU/LC changes of Javadi Hills for the years 2018, 2021, 2024, and 2027.
- The LU/LC changes that occurred in our study area will assist the urban planners and forest department to take proper actions in the protection of the environment through XAI.
Algorithm to Construct the Vision Transformer–Based Bi-LSTM Model for LU/LC Prediction
| Algorithm 1: To Construct the Vision Transformer–Based Bi-LSTM Prediction Model. |
| Inputs (): The LISS-III multispectral satellite images for the years 2012 and 2015 (I1, I2), and Landsat bands for the years 2012 and 2015 |
| Output (): Predicted LU/LC images 2018, 2021, 2024, and 2027 |
| Begin |
| 1 Input data (): |
| 2 Initialize the input data |
| 3 Extract LISS-III multispectral image () |
| 4 Extract Landsat bands |
| 5 Return input data () |
| 6 |
| 7 Preprocessed data : |
| 8 Initialize the input data for performing the preprocessing for the input data of M and T |
| 9 For each initialized input image of M and T |
| 10 Calculate the geometric coordinates of the study area (georeferencing) |
| 11 Reduce the atmospheric (haze) effects of the georeferenced image |
| 12 Correct the radiometric errors for the haze-reduced image |
| 13 End for |
| 14 Return preprocessed data |
| 15 |
| 16 LU/LC classification (): |
| 17 Perform the Vision Transformer–based LU/LC classification by using the preprocessed image |
| 18 For each input image of |
| 19 Load the training data and initialize the parameters |
| 20 Split an image into patches of fixed size |
| 21 Flatten the image patches |
| 22 Perform the linear projection from the flattened patches |
| 23 Include the positional embeddings |
| 24 Feed the sequences as an input to the transformer encoder |
| 25 Fine-tune the multi-head self-attention block in the encoder |
| 26 Concatenate all the outputs of attention heads and provide the MLP classifier for attaining the pixel value representation of the feature map. |
| 27 Generate the LU/LC classification map |
| 28 End for |
| 29 LU/LC classification () |
| 30 |
| 31 Accuracy assessment (): |
| 32 Perform the accuracy assessment for the feature extraction–based LU/LC classification map |
| 33 For each classified map of |
| 34 Compare the labels of each classified data with the Google Earth data |
| 35 Build the confusion matrix |
| 36 Calculate overall accuracy, precision, recall, and F1-Score |
| 37 Summarize the performance of the classified map |
| 38 End for |
| 39 Return accuracy assessment |
| 40 |
| 41 Change detection (): |
| 42 Perform the LU/LC change detection by using the time-series LU/LC change classification map () |
| 43 For each classified map of |
| 44 Calculate the percentage of change between the time-series classified map of |
| 45 End For |
| 46 Return change detection () |
| 47 |
| 48 Extracting LST map (LST) |
| 49 Initialize the of T |
| 50 For each preprocessed image of T |
| 51 Calculate Land Surface Temperature using the Landsat bands (TIRS, RED, and NIR) |
| 52 Extract the spatial features |
| 53 End for |
| 54 Return LST () |
| 55 |
| 56 LU/LC prediction (): |
| 57 Perform the Bi-LSTM prediction model by using the time-series LU/LC classification map of 2012 () and 2015 () and the spatial features of the LST map of 2012 () and 2015 () |
| 58 For each time-series, LU/LC classified map of : {} and LST map : |
| 59 Perform LU/LC prediction using Bi-LSTM model |
| 60 Initialize the inputs for LU/LC prediction |
| 61 Input |
| 62 Combine the information of the time-series LU/LC classified map with the LST map |
| 63 Load the 3D input vectors {samples, time steps, features} |
| 64 Initialize the Bi-LSTM parameters |
| 65 Apply tanh activation function for each Bi-LSTM layer |
| 66 The output layer is decided by using the Softmax activation function |
| 67 Update the parameters until the loss function is minimized |
| 68 The output of the predicted time-series data is obtained |
| 69 Validate the results |
| 70 End for |
| 71 Return LU/LC prediction map |
| 72 Analyze the growth patterns of the LU/LC prediction maps |
| 73 |
| 74 Explain predicted results to the urban planners, forest department, and government officials, using application-based XAI |
| End |
5. Results and Discussion
5.1. Training Data and Parameter Settings
5.2. Validation of Vision Transformer–Based Bi-LSTM Model
5.3. Growth Pattern of the LU/LC Area of Javadi Hills
6. Comparative Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Baig, M.F.; Mustafa, M.R.U.; Baig, I.; Takaijudin, H.B.; Zeshan, M.T. Assessment of land use land cover changes and future predictions using CA-ANN simulation for selangor, Malaysia. Water 2022, 14, 402. [Google Scholar] [CrossRef]
- Imran, M.; Aqsa, M. Analysis and mapping of present and future drivers of local urban climate using remote sensing: A case of Lahore, Pakistan. Arab. J. Geosci. 2020, 13, 1–14. [Google Scholar] [CrossRef]
- Heidarlou, H.B.; Shafiei, A.B.; Erfanian, M.; Tayyebi, A.; Alijanpour, A. Effects of preservation policy on land use changes in Iranian Northern Zagros forests. Land Use Policy 2019, 81, 76–90. [Google Scholar] [CrossRef]
- Chaves, M.E.D.; Michelle, C.A.P.; Ieda, D.S. Recent applications of Landsat 8/OLI and Sentinel-2/MSI for land use and land cover mapping: A systematic review. Remote Sens. 2020, 12, 3062. [Google Scholar] [CrossRef]
- Priyadarshini, K.N.; Kumar, M.; Rahaman, S.A.; Nitheshnirmal, S. A comparative study of advanced land use/land cover classification algorithms using Sentinel-2 data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 20–23. [Google Scholar] [CrossRef] [Green Version]
- Siddiqui, A.; Siddiqui, A.; Maithani, S.; Jha, A.K.; Kumar, P.; Srivastav, S.K. Urban growth dynamics of an Indian metropolitan using CA markov and logistic regression. Egypt. J. Remote Sens. Space Sci. 2018, 21, 229–236. [Google Scholar] [CrossRef]
- Mohan, R.; Sam, N.; Agilandeeswari, L. Modelling spatial drivers for LU/LC change prediction using hybrid machine learning methods in Javadi Hills, Tamil Nadu, India. J. Indian Soc. Remote Sens. 2021, 49, 913–934. [Google Scholar] [CrossRef]
- Sandamali, S.P.I.; Lakshmi, N.K.; Sundaramoorthy, S. Remote sensing data and SLEUTH urban growth model: As decision support tools for urban planning. Chin. Geogr. Sci. 2018, 28, 274–286. [Google Scholar] [CrossRef] [Green Version]
- Hegde, G.; Ahamed, J.M.; Hebbar, R.; Raj, U. Urban land cover classification using hyperspectral data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 8, 751–754. [Google Scholar] [CrossRef] [Green Version]
- Elmore, A.J.; John, F.M. Precision and accuracy of EO-1 Advanced Land Imager (ALI) data for semiarid vegetation studies. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1311–1320. [Google Scholar] [CrossRef]
- Elbeih, S.F.; El-Zeiny Ahmed, M. Qualitative assessment of groundwater quality based on land use spectral retrieved indices: Case study Sohag Governorate, Egypt. Remote Sens. Appl. Soc. Environ. 2018, 10, 82–92. [Google Scholar] [CrossRef]
- Nagy, A.; El-Zeiny, A.; Sowilem, M.; Atwa, W.; Elshaier, M. Mapping mosquito larval densities and assessing area vulnerable to diseases transmission in Nile valley of Giza, Egypt. Egypt. J. Remote Sens. Space Sci. 2022, 25, 63–71. [Google Scholar] [CrossRef]
- Etemadi, H.; Smoak, J.M.; Karami, J. Land use change assessment in coastal mangrove forests of Iran utilizing satellite imagery and CA–Markov algorithms to monitor and predict future change. Environ. Earth Sci. 2018, 77, 1–13. [Google Scholar] [CrossRef]
- Goodarzi Mehr, S.; Ahadnejad, V.; Abbaspour, R.A.; Hamzeh, M. Using the mixture-tuned matched filtering method for lithological mapping with Landsat TM5 images. Int. J. Remote Sens. 2013, 34, 8803–8816. [Google Scholar] [CrossRef]
- Vijayan, D.; Shankar, G.R.; Shankar, T.R. Hyperspectral data for land use/land cover classification. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 40, 991. [Google Scholar] [CrossRef] [Green Version]
- Myint, S.W.; Okin, G.S. Modelling land-cover types using multiple endmember spectral mixture analysis in a desert city. Int. J. Remote Sens. 2009, 30, 2237–2257. [Google Scholar] [CrossRef]
- Amigo, J.M.; Carolina, S. Preprocessing of hyperspectral and multispectral images. In Data Handling in Science and Technology; Elsevier: Amsterdam, The Netherlands, 2020; Volume 32, pp. 37–53. [Google Scholar] [CrossRef]
- HongLei, Y.; JunHuan, P.; BaiRu, X.; DingXuan, Z. Remote sensing classification using fuzzy C-means clustering with spatial constraints based on Markov random field. Eur. J. Remote Sens. 2013, 46, 305–316. [Google Scholar] [CrossRef] [Green Version]
- Navin, M.S.; Agilandeeswari, L. Comprehensive review on land use/land cover change classification in remote sensing. J. Spectr. Imaging 2020, 9, a8. [Google Scholar] [CrossRef]
- Ganasri, B.P.; Dwarakish, G.S. Study of land use/land cover dynamics through classification algorithms for Harangi catchment area, Karnataka State, India. Aquat. Procedia 2015, 4, 1413–1420. [Google Scholar] [CrossRef]
- Sharma, J.; Prasad, R.; Mishra, V.N.; Yadav, V.P.; Bala, R. Land use and land cover classification of multispectral LANDSAT-8 satellite imagery using discrete wavelet transform. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 703–706. [Google Scholar] [CrossRef] [Green Version]
- Kabisch, N.; Selsam, P.; Kirsten, T.; Lausch, A.; Bumberger, J. A multi-sensor and multi-temporal remote sensing approach to detect land cover change dynamics in heterogeneous urban landscapes. Ecol. Indic. 2019, 99, 273–282. [Google Scholar] [CrossRef]
- Xing, W.; Qian, Y.; Guan, X.; Yang, T.; Wu, H. A novel cellular automata model integrated with deep learning for dynamic spatio-temporal land use change simulation. Comput. Geosci. 2020, 137, 104430. [Google Scholar] [CrossRef]
- Ali, A.S.A.; Ebrahimi, S.; Ashiq, M.M.; Alasta, M.S.; Azari, B. CNN-Bi LSTM neural network for simulating groundwater level. Environ. Eng. 2022, 8, 1–7. [Google Scholar] [CrossRef]
- Floreano, I.X.; de Moraes, L.A.F. Land use/land cover (LULC) analysis (2009–2019) with google earth engine and 2030 prediction using Markov-CA in the Rondônia State, Brazil. Environ. Monit. Assess. 2021, 193, 1–17. [Google Scholar] [CrossRef]
- Xiao, B.; Liu, J.; Jiao, J.; Li, Y.; Liu, X.; Zhu, W. Modeling dynamic land use changes in the eastern portion of the hexi corridor, China by cnn-gru hybrid model. GIScience Remote Sens. 2022, 59, 501–519. [Google Scholar] [CrossRef]
- Gaetano, R.; Ienco, D.; Ose, K.; Cresson, R. A two-branch CNN architecture for land cover classification of PAN and MS imagery. Remote Sens. 2018, 10, 1746. [Google Scholar] [CrossRef] [Green Version]
- Mu, L.; Wang, L.; Wang, Y.; Chen, X.; Han, W. Urban land use and land cover change prediction via self-adaptive cellular based deep learning with multisourced data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5233–5247. [Google Scholar] [CrossRef]
- Al Kafy, A.; Dey, N.N.; Al Rakib, A.; Rahaman, Z.A.; Nasher, N.R.; Bhatt, A. Modeling the relationship between land use/land cover and land surface temperature in Dhaka, Bangladesh using CA-ANN algorithm. Environ. Chall. 2021, 4, 100190. [Google Scholar] [CrossRef]
- MohanRajan, S.N.; Loganathan, A.; Manoharan, P. Survey on land use/land cover (LU/LC) change analysis in remote sensing and GIS environment: Techniques and challenges. Environ. Sci. Pollut. Res. 2020, 27, 29900–29926. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Wen, Q.; Zhou, T.; Zhang, C.; Chen, W.; Ma, Z.; Yan, J.; Sun, L. Transformers in time series: A survey. arXiv 2022, arXiv:2202.07125. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2021, 1–38. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Xu, K.; Deng, P.; Huang, H. Vision transformer: An excellent teacher for guiding small networks in remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Sha, Z.; Li, J. MITformer: A multi-instance vision transformer for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Xu, F.; Uszkoreit, H.; Du, Y.; Fan, W.; Zhao, D.; Zhu, J. Explainable AI: A brief survey on history, research areas, approaches and challenges. In CCF International Conference on Natural Language Processing and Chinese Computing; Tang, J., Kan, M.Y., Zhao, D., Li, S., Zan, H., Eds.; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Schlegel, U.; Arnout, H.; El-Assady, M.; Oelke, D.; Keim, D.A. Towards a rigorous evaluation of XAI methods on time series. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; IEEE: Manhattan, NY, USA, 2020. [Google Scholar] [CrossRef] [Green Version]
- Saeed, W.; Christian, O. Explainable AI (XAI): A systematic meta-survey of current challenges and future opportunities. arXiv 2021, arXiv:2111.06420. [Google Scholar] [CrossRef]
- Ribeiro, J.; Silva, R.; Cardoso, L.; Alves, R. Does dataset complexity matters for model explainers? In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; IEEE: Manhattan, NY, USA, 2022. [Google Scholar] [CrossRef]
- Samek, W.; Montavon, G.; Lapuschkin, S.; Anders, C.J.; Müller, K.R. Explaining deep neural networks and beyond: A review of methods and applications. IEEE 2021, 109, 247–278. [Google Scholar] [CrossRef]
- LinarLinardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A review of machine learning interpretability methods. Entropy 2020, 23, 18. [Google Scholar] [CrossRef]
- Navin, M.S.; Agilandeeswari, L. Multispectral and hyperspectral images based land use/land cover change prediction analysis: An extensive review. Multimed. Tools Appl. 2020, 79, 29751–29774. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Thyagharajan, K.K.; Vignesh, T. Soft computing techniques for land use and land cover monitoring with multispectral remote sensing images: A review. Arch. Comput. Methods Eng. 2019, 26, 275–301. [Google Scholar] [CrossRef]
- Kaselimi, M.; Voulodimos, A.; Daskalopoulos, I.; Doulamis, N.; Doulamis, A. A Vision transformer model for convolution-free multilabel classification of satellite imagery in deforestation monitoring. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Wu, Y.; Liang, W.; Cao, Y.; Li, M. High resolution SAR image classification using global-local network structure based on vision transformer and CNN. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A.; Jmal, M.; Souidene Mseddi, W.; Attia, R. Wildfire segmentation using deep vision transformers. Remote Sensing 2021, 13, 3527. [Google Scholar] [CrossRef]
- Chen, X.; Qiu, C.; Guo, W.; Yu, A.; Tong, X.; Schmitt, M. Multiscale feature learning by transformer for building extraction from satellite images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Meng, X.; Wang, N.; Shao, F.; Li, S. Vision transformer for pansharpening. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Mukherjee, F.; Singh, D. Assessing land use–land cover change and its impact on land surface temperature using LANDSAT data: A comparison of two urban areas in India. Earth Syst. Environ. 2020, 4, 385–407. [Google Scholar] [CrossRef]
- Sekertekin, A.; Stefania, B. Land surface temperature retrieval from Landsat 5, 7, and 8 over rural areas: Assessment of different retrieval algorithms and emissivity models and toolbox implementation. Remote Sens. 2020, 12, 294. [Google Scholar] [CrossRef] [Green Version]
- Nasir, M.J.; Ahmad, W.; Iqbal, J.; Ahmad, B.; Abdo, H.G.; Hamdi, R.; Bateni, S.M. Effect of the urban land use dynamics on land surface temperature: A case study of kohat city in Pakistan for the period 1998–2018. Earth Syst. Environ. 2022, 6, 237–248. [Google Scholar] [CrossRef]
- Sefrin, O.; Riese, F.M.; Keller, S. Deep learning for land cover change detection. Remote Sens. 2020, 13, 78. [Google Scholar] [CrossRef]
- Cao, C.; Dragićević, S.; Li, S. Short-term forecasting of land use change using recurrent neural network models. Sustainability 2019, 11, 5376. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Zhao, X.; Zhang, X.; Wu, D.; Du, X. Long time series land cover classification in China from 1982 to 2015 based on Bi-LSTM deep learning. Remote Sens. 2019, 11, 1639. [Google Scholar] [CrossRef] [Green Version]
- Adadi, A.; Mohammed, B. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Fulton, L.B.; Lee, J.Y.; Wang, Q.; Yuan, Z.; Hammer, J.; Perer, A. Getting playful with explainable AI: Games with a purpose to improve human understanding of AI. In Proceedings of the Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Kute, D.V.; Pradhan, B.; Shukla, N.; Alamri, A. Deep learning and explainable artificial intelligence techniques applied for detecting money laundering–a critical review. IEEE Access 2021, 9, 82300–82317. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite | Path | Sensor | Year | Source |
|---|---|---|---|---|
| Resourcesat-1/2 | 101/064 | LISS-III | 18 February 2012 22 March 2015 | Bhuvan Indian Geo-Platform of ISRO (www.bhuvan.com (accessed on 9 December 2019)) |
| Landsat 8 OLI/TI and Landsat 7 (ETM+) | 143/51 | Operational Land Imager (OLI) and the Thermal Infrared (TI) Sensor | 27 March 2015 | United States Geological Survey (https://earthexplorer.usgs.gov (accessed on 16 December 2019)) |
| Enhanced Thematic Mapper Plus (ETM+) | 26 March 2012 |
| Hyperparameters | Value |
|---|---|
| Learning Rate | 0.001 |
| Weight Decay | 0.0001 |
| Batch Size | 10 |
| Number of epochs | 100 |
| Image size | 256 × 256 |
| Patch size | 64 |
| Patches per image | 16 |
| Number of heads | 4 |
| Transformer Layers | 8 |
| Activation Function | GeLU |
| Optimizer | Adam |
| Training Feature Value | Longitude | Latitude | Class Value | Class Label |
|---|---|---|---|---|
| 1 | 78.829746 | 12.581815 | 1 | High Vegetation |
| 241 | 78.81025 | 12.58796 | 2 | Less Vegetation |
| 1785 | 78.818244 | 12.580221 | 2 | Less Vegetation |
| 733 | 78.849159 | 12.576782 | 1 | High Vegetation |
| 6640 | 78.81107 | 12.57028 | 2 | Less Vegetation |
| 6277 | 78.83463 | 12.576789 | 1 | High Vegetation |
| 12,354 | 78.851079 | 12.59151 | 1 | High Vegetation |
| 12,179 | 78.80721 | 12.58024 | 2 | Less Vegetation |
| 20,163 | 78.81167 | 12.5669 | 2 | Less Vegetation |
| 30,759 | 78.841932 | 12.59148 | 1 | High Vegetation |
| 24,465 | 78.840458 | 12.591477 | 1 | High Vegetation |
| 28,861 | 78.805977 | 12.580232 | 2 | Less Vegetation |
| 35,655 | 78.836129 | 12.591499 | 1 | High Vegetation |
| 33,638 | 78.812464 | 12.580187 | 2 | Less Vegetation |
| 63 | 78.81674 | 12.60167 | 1 | Less Vegetation |
| 39,388 | 78.81276 | 12.58634 | 2 | Less Vegetation |
| Feature Value | Longitude | Latitude | Class Value | Temperature Value | Class Label |
|---|---|---|---|---|---|
| 1 | 78.82975 | 12.58182 | 1 | 32.183754 | High Vegetation |
| 241 | 78.81025 | 12.58796 | 2 | 37.755061 | Less Vegetation |
| 1785 | 78.81824 | 12.58022 | 2 | 37.755061 | Less Vegetation |
| 733 | 78.84916 | 12.57678 | 1 | 31.708773 | High Vegetation |
| 6640 | 78.81107 | 12.57028 | 2 | 34.998298 | Less Vegetation |
| 6277 | 78.83463 | 12.57679 | 1 | 31.708773 | High Vegetation |
| 12,354 | 78.85108 | 12.59151 | 1 | 30.273344 | High Vegetation |
| 12,179 | 78.80721 | 12.58024 | 2 | 38.20916 | Less Vegetation |
| 20,163 | 78.81167 | 12.5669 | 2 | 34.998298 | Less Vegetation |
| 30,759 | 78.84193 | 12.59148 | 1 | 32.607521 | High Vegetation |
| 24,465 | 78.84046 | 12.59148 | 1 | 32.183754 | High Vegetation |
| 28,861 | 78.80598 | 12.58023 | 2 | 38.20916 | Less Vegetation |
| 35,655 | 78.83613 | 12.5915 | 1 | 31.708773 | High Vegetation |
| 33,638 | 78.81246 | 12.58019 | 2 | 34.533323 | Less Vegetation |
| 63 | 78.81674 | 12.60167 | 2 | 36.842331 | Less Vegetation |
| 39,388 | 78.81276 | 12.58634 | 2 | 38.20916 | Less Vegetation |
| Parameter | Value |
|---|---|
| Input Image Format | Raster |
| Number of Training Samples | 51,200 |
| Activation Function | tanh, Softmax |
| Dropout | 0.1, 0.25 |
| Learning Rate | 0.001 |
| Optimizer | Adam |
| Loss Function | Categorical Cross Entropy |
| Hidden layers | 20 |
| Number of epochs | 100 |
| Batch Size | 32 |
| LU/LC Classification | Class | Reference Class | |||
|---|---|---|---|---|---|
| 2012 | 2015 | ||||
| High Vegetation | Less Vegetation | High Vegetation | Less Vegetation | ||
| Actual Class | High Vegetation | 694 | 4 | 689 | 6 |
| Less Vegetation | 7 | 303 | 8 | 305 | |
| LU/LC Classification | 2012 | 2015 |
|---|---|---|
| Overall Accuracy | 0.9891 | 0.9861 |
| Precision | 0.9901 | 0.9885 |
| Recall | 0.9942 | 0.9913 |
| F1-Score | 0.9921 | 0.9898 |
| Input Map (Year) | Training Feature Map (256 × 200 Pixels) | Train—Validation Split (8:2) Data | Test Data (Google Earth Image) | Predicted Map | Validation Accuracy | Testing Accuracy |
|---|---|---|---|---|---|---|
| LU/LC Classification—LST Map (2012, and 2015) | 51,200 | 40,960–10,240 | 51,200 | 2018 | 0.9865 | 0.9696 |
| 51,200 | 40,960–10,240 | 51,200 | 2021 | 0.9811 | 0.9673 |
| LU/LC Class | Area (ha) | |||||
|---|---|---|---|---|---|---|
| Year | ||||||
| 2012 | 2015 | 2018 | 2021 | 2024 | 2027 | |
| High Vegetation | 1651.04 | 1601.22 | 1621.18 | 1596.04 | 1568.23 | 1553.17 |
| Less Vegetation | 736.85 | 786.67 | 766.71 | 791.85 | 819.66 | 834.72 |
| Total (ha) | 2387.89 | 2387.89 | 2387.89 | 2387.89 | 2387.89 | 2387.89 |
| LU/LC Class | Area (%) | ||||
|---|---|---|---|---|---|
| Year | |||||
| 2012–2015 | 2015–2018 | 2018–2021 | 2021–2024 | 2024–2027 | |
| High Vegetation | −3.01 | 1.24 | −1.55 | −1.74 | −0.96 |
| Less Vegetation | 6.76 | −2.53 | 3.27 | 3.51 | 1.83 |
| Algorithms | Average Accuracy (%) |
|---|---|
| Ours | 98.76 |
| CNN [27] | 96.42 |
| DWT [22] | 94.21 |
| SVM [1] | 97.71 |
| MLC [2] | 94.4 |
| RFC [25] | 95.6 |
| Study Area | Algorithm | Prediction Accuracy (%) |
|---|---|---|
| Javadi Hills, India | Vision Transformer–based Bi-LSTM Model (ours) | 98.38% |
| RFC-based MC–ANN–CA Model [7] | 93.41% |
| Study Area | Input Data | Prediction Accuracy (%) |
|---|---|---|
| Javadi Hills, India | LU/LC Classification—LST Map | 98.38 |
| LU/LC Classification—Slope Map | 92.33 | |
| LU/LC Classification—Distance from Road Map | 91.64 | |
| LU/LC Classification—Slope, Distance from road map | 92.52 | |
| LU/LC Classification—Slope, LST map | 93.45 | |
| LU/LC Classification—Distance from Road, LST map | 93.17 | |
| LU/LC Classification—Slope, Distance from Road, LST map | 94.2 |
| Study Area | Algorithm | Prediction Accuracy (%) |
|---|---|---|
| Javadi Hills, India (our study) | Vision Transformer–Based Bi-LSTM Model | 98.38 |
| Wuhan, China [28] | Self-Adaptive Cellular-Based Deep-Learning LSTM Model | 93.1 |
| Guangdong province of South China [23] | Deep Learning (RNN–CNN) and CA–MC Model | 95.86 |
| Western Fansu Province, China [26] | CNN–GRU Model | 93.46 |
| Dhaka, Bangladesh [29] | CA–MC and ANN Model | 90.21 |
| University of Nebraska–Lincoln [24] | CNN–Bi-LSTM Model | 91.73 |
| City of Surrey, British Columbia [56] | RNN–ConvLSTM Model | 88.0 |
| Klingenberg, Germany [55] | Fully CNN–LSTM Model | 87.0 |
| Awadh, Lucknow [6] | CA–MC and LR model | 84.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohanrajan, S.N.; Loganathan, A. Novel Vision Transformer–Based Bi-LSTM Model for LU/LC Prediction—Javadi Hills, India. Appl. Sci. 2022, 12, 6387. https://doi.org/10.3390/app12136387
Mohanrajan SN, Loganathan A. Novel Vision Transformer–Based Bi-LSTM Model for LU/LC Prediction—Javadi Hills, India. Applied Sciences. 2022; 12(13):6387. https://doi.org/10.3390/app12136387
Chicago/Turabian StyleMohanrajan, Sam Navin, and Agilandeeswari Loganathan. 2022. "Novel Vision Transformer–Based Bi-LSTM Model for LU/LC Prediction—Javadi Hills, India" Applied Sciences 12, no. 13: 6387. https://doi.org/10.3390/app12136387
APA StyleMohanrajan, S. N., & Loganathan, A. (2022). Novel Vision Transformer–Based Bi-LSTM Model for LU/LC Prediction—Javadi Hills, India. Applied Sciences, 12(13), 6387. https://doi.org/10.3390/app12136387