1. Introduction
Currently, many internet users can impart information and work together inside online social networks (OSNs). However, Twitter is viewed as the most well-known informal community which offers free blogging services for clients to publish their news and thoughts inside 280 characters. Clients can follow others through various platforms [
1]. Consistently, a huge number of Twitter clients share their status and news about their disclosures [
2]. Moreover, the Twitter platform additionally attracts criminal records (spammers) that can tweet spam substances, which may incorporate destructive URLs. This could divert clients to malevolent or phishing sites for bringing in cash misguidedly [
3,
4] by assaulting the client’s profile. As Twitter set caps for the length of the characters of tweets, this makes spammer swindle clients by putting cheat content or malicious URL to divert them for the outside site [
5]. In an investigation studying the correlation between both email and social spam, the click-through rate of Twitter spam was found to reach 0.13%, in spite of the fact that email spam arrives at 0.0003–0.0006% [
6]. Moreover, social spam is viewed as increasingly perilous and cheats a lot of clients [
7].
To tackle this problem, many researchers are focusing on detecting spammers by discovering the statistical features of spammers on both messaging and account levels. These messaging detection approaches focus on checking tweet content to find keyword patterns, hashtags, and URLs. These approaches are shown to be effective, but real-time detection is needed to solve the huge number of messages which are posted per hour. The account level approaches focus on extracting statistics and info about the behavior of each account to classify whether they are spam accounts or legitimate users. However, an experimental study was conducted to examine whether the statistical features changed over time. The experimental results proved that the statistical features are changed over time. Most of the researchers are focusing on collecting these features and trying to experience spammers priorities, ignoring that these features drift over time. However, spammers will try to tackle all these features. In this paper, an effective technique has been proposed to tackle the aforementioned limitations. Our proposed technique focuses on the content of each tweet in addition to the statistical features. Moreover, it has an auto-learning capability to find the features which make it able to classify each tweet as spam or not with high accuracy in a reasonable time.
Accordingly, these challenges inspire us to investigate this problem to contribute to spam detection approaches. To cope with this problem, we maintain a framework that contains three stages to detect spammers:
Fast filter mode classifier to determine whether each input tweet is spam or not.
Every filtered spam tweet is paraphrased to generate a new spam sentence with different definition with the same meaning.
Ensemble deep learning methods are collected in addition to the statistical features to decide the output of the classifier.
The rest of this manuscript is organized as follows.
Section 2 briefly discusses the literature review on Twitter spam detection.
Section 3 clarifies the problem statement of spam drift in detail.
Section 4 explains our proposed detection framework.
Section 5 discusses our experiments and results. Finally, conclusions are represented in
Section 6.
2. Literature Review
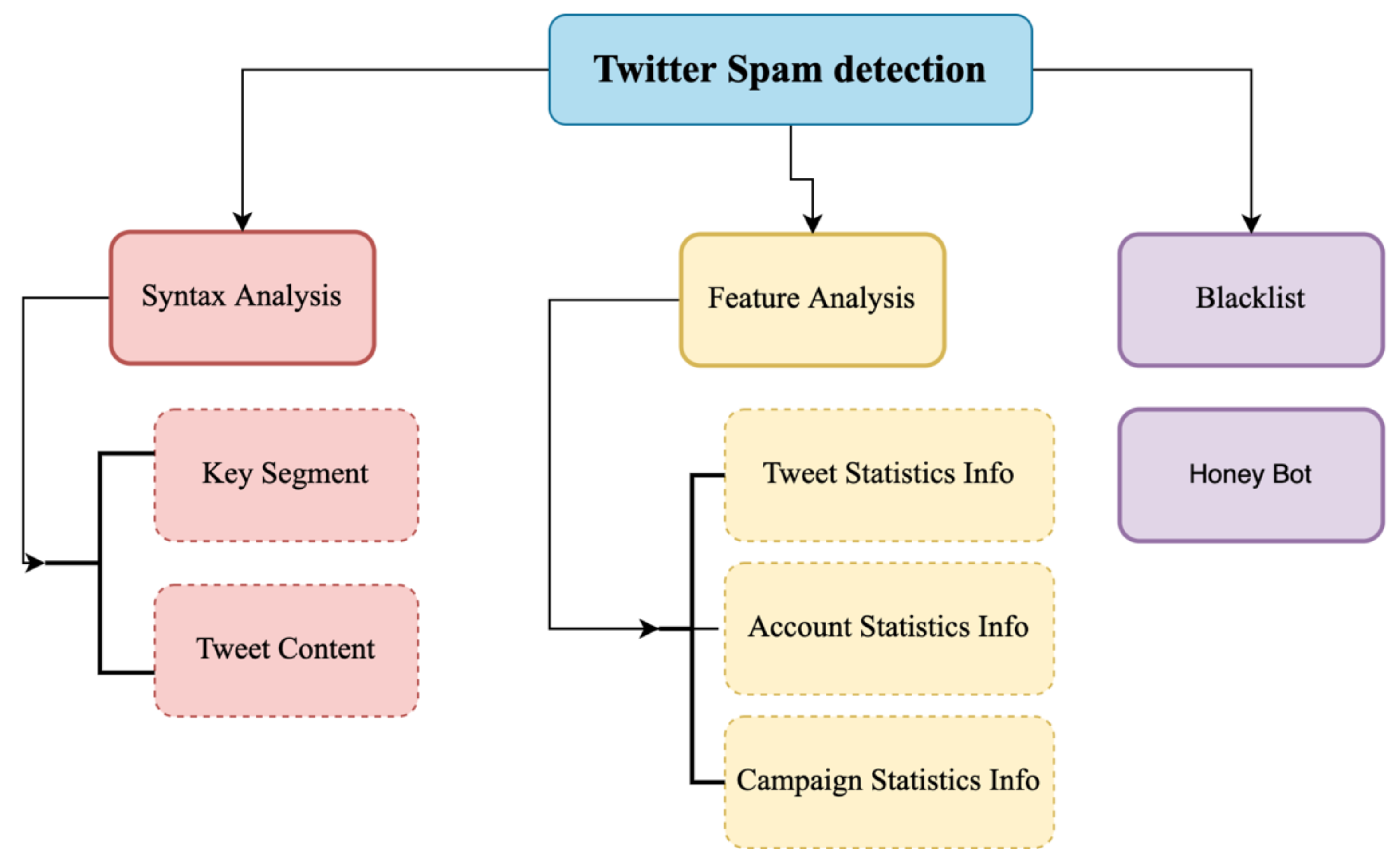
Many studies have been performed to improve spam detection challenges. These studies can be organized into three categories [
8], syntax analysis, feature analysis, and blacklist techniques, as shown in
Figure 1.
Most of the research applied blacklisting techniques based on URLs in the tweets using any third-party tools, such as Trend Micro or Google safe browsing. However, S. Savage [
9] creates a lightweight technique for spam detection, while [
10] filtered tweets based on checking URLs in tweets, username patterns, and hashtags.
Consequently, a lot of researchers have applied machine learning (ML) techniques in their works [
11,
12,
13,
14] and extracted some features of users, such as number of followings, username pattern, and account creation in addition to features of content, such as length of tweets, number of hashtags, and hashtags pattern. Authors in [
11] employed honey pots to collect spammers’ profiles to extract statistical features using different ML algorithms, such as Decorate and Random some space. However, Benevento et al. attempted to detect spammers by using a support vector machine (SVM) algorithm [
12]. These features can be easily fabricated as spammers can buy fake spammers’ followers and followings. Thus, some studies [
15] depend on a social graph to tackle the problem of fabrication by calculating distance and connectivity of each tweet between sender and receiver to examine whether it is spam. Yang et al. [
16] built a more robust feature using a bidirectional link ratio between centrality and local cluster coefficient with performance 99% true positive, while [
17] provides a new solution that can detect most campaigns and classify each of them into spam or not spam using deep learning techniques and semantic similarity methods.
Most of the described methods focus on detecting spam tweets based on some statistical features. Some studies employ syntax analysis, while a spam dataset based on hashtags was created by [
18], in which authors collected 14 million tweets and classified them using five different techniques. Sedhi and son [
19] utilized a package of four lightweight techniques to detect spam at tweet level using part of speech tag, content-based, sentiment, and user-based features, using a word vector as the universal feature of their task. Le and Mikulov [
20] have deployed a deep learning method by constructing a tweet vector by combining the word vector with the document vector to classify the neural network.
In [
21], the authors employ the horse herd optimization algorithm (HOA), inspired by nature optimization algorithms. This algorithm emulates the social exhibitions of horses at various ages. The idea behind this study has a great performance result on complex problems, specifically with high dimensions, solving many dimension problems with low cost based on time, performance, and complexity (up to 10,000 dimensions). The researcher attempts to find the best solution by employing the multiobjective opposition-based binary which gave good results compared with similar approaches. However, it still depends on statistical functions which can deviate over time as explained.
The study by Abayomi-Alli [
22] used the ensemble approach to detect SMS spam. This approach depends on two pipeline the BI-LSTM (Bidirectional Long-Short Term Memory) network which produce accurate results in text classification tasks and the classical machine learning methods. However, this approach does not employ any attention mechanism in the BI-LSTM network, which causes this approach to suffer in long sentences of more than 8 words.
Many different extraction methods have been used for representing tweets, such as [
23]. In this reference, authors analyzed people’s sentiments collected through tweets. They employed three different feature extraction methods, domain-agnostic, fastText-based, and domain-specific, for tweet representation. Then, an ensemble approach was proposed for sentiment analysis by employing three CNN models and traditional ML models, such as random forest (RF), and SVM using the Nepali Twitter sentiment dataset, called NepCOV19Tweets. Their models achieve 72.1% accuracy by employing a smaller feature size (300-D). However, these models have two limitations. First, they are complex and need high computational resources for implementation. Second, their methods are based on only semantic features.
In addition, authors in [
24] analyzed people’s sentiments using three feature extrac-tions, term frequency-inverse document f(TF-IDF), fastText, and a combination of these two methods as hybrid features for representing COVID-19 tweets. Then, they validated their methods against different ML techniques. Their SVM model obtained the highest accuracy on both TF-IDF (65.1%) and hybrid features (72.1%). The major limitation of this model is its high computational complexity.
TF-IDF [
25] may be used to vectorize text into a format that is more suitable for machine learning and natural language processing approaches. It is a statistical measure that we can apply to terms in a text and then use to generate a vector, whereas other methods, such as word2vec [
26], will provide a vector for a term and then extra effort may be required to transform that group of vectors into a single vector or other format. Another approach is Bidirectional Encoder Representations from Transformers (BERT), which converts phrases, words, and other objects into vectors using a transformer-based ML model [
27]. However, BERT’s design also includes deep neural networks, which means it can be significantly more computationally expensive than TF-IDF.
Because our proposed framework will be used with highly intensive data applications, we had to choose a high-performance and quick feature extraction method. TF-IDF produces high accuracy relative to our framework, so we decided to build our model with it.
Most of the mentioned studies focus on extracting the features that can help them find the spammers, but they ignore a very important problem, which is “spam drift”, meaning that these features are changed over time. Egele et al. [
28] build a historical-based model, which does not suffer from this problem. Authors in [
29] have built a model using a fuzzy model that attempts to adapt the features over time, but the accuracy is decreased. So, we will focus on this problem and then try to build a robust framework to cope with most of the challenges to detect Twitter spam.
3. Problem Statement
The problem revealed in this paper is detecting and classifying each tweet whether it is spam or not. So, we have the problem of “spam drift”, which happened because most of the researchers focus on determining the spam tweets based on the statistical features. Most of them focus on selection of features as shown in
Table 1. In the real world, these features are changing in an unpredictable way over time. Therefore, we attempted to build a framework that is robust against these changes.
At the beginning, we will try to prove this problem as in [
29]. So, we have crawled data of tweets from Twitter Stream API for 10 consecutive days. We have to check a lot of tweets to determine which are spam. In this stage, we found that most of the spam tweets contain a URL, which most spammers use to spread their malicious content by sending the victim to mine or farm sites. Therefore, we use Trend Micro’s Web Reputation Technology (WRT) to detect the tweet as spam or not based on the URL [
22]. This WRT system helps users to identify the malicious sites in real-time with high reliability with an accuracy rate of 100% as reported in [
30]. Moreover, we have made hundreds of manual inspections to ensure the reliability of this system.
As described previously, we found that the statistical features are changing from day to day with impressive effect as shown in
Table 1. For example, we found that the average number of account followings changes from the 1st day (500–900) to the 9th day (950–1350). This means that the spammers try to collect the followings, but the average number of followings is confused whether this account is spam or not.
Therefore, to justify the problem of changing the statistical features, the distribution of the data should be modeled. There are two types of data: parametric and non-parametric. The parametric approaches are always used when the distribution of data is known as normal distribution, but the statistical features of Twitter are unknown [
31,
32]. So, we used the non-parametric approaches. One of the most common non-parametric approaches is the statistical test. The calculation of the statistical test is based on computing the distance between the two distributions to calculate the change between them. Distance is calculated using Kullback-Leibler (KL) divergence [
31], which is also known as relative entropy, shown in Equation (1):
This formula is used to measure the two probability distributions as reported in [
33]. Let
=
be a multi-set from a finite set
containing numerical feature values, and
is the number of appearances of
∈
. Thus, the relative proportion of each
is shown Equation (2)
The ratio of the two variables
is undefined, if we assume
. Therefore, the estimation of
is changed to Equation (3)
when variable
is defined as the number of elements in the finite set
. The distance between two day’s tweets,
and
, is defined as shown in Equation (4)
We calculate the KL Divergence of spam and legitimate tweets of each feature in two adjacent days as shown in
Table 1. The larger the distance, the more dissimilarity between the two distributions. So, according to the results in
Table 1, the distance is large in most features in case of spam data. However, in non-spam data, the distance is very small in most of the features. According to this study, by examining the Number_of_tweet (f-6) feature from
Table 1, we notice that the KL Divergence metric of spam tweets for Day 1 and Day 2 is 0.99. However, in non-spam tweets, it is 0.36, which means that the distribution of this feature is changed from Day 1 to Day 2 compared to non-spam tweets. As shown in
Table 1, most features are changing unpredictably from one day to another, although the training data is fixed and is not affected by any changes. Therefore, the performance of the classifiers will become inaccurate if the decision boundary is not updated.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}