1. Introduction
Employee attrition is expressed as the normal process by which the employees leave the organization due to some reasons, such as the resignation of employees. There are many factors that can cause employee attrition [
1]. The employees leave the organization faster than they are hired. When the employee leaves the organization, the vacancies remain unfilled, resulting in a loss for the organization. The employee attrition rate helps to understand the progress level of an organization. The high attrition rate shows that the employees are frequently leaving. The results of the high attrition rate are the loss of organizational benefits [
2]. In order to keep the organization in progress, the attrition rate must be controlled.
Many types of employee attrition help us to understand the attrition process. The attrition type is whether an employee chooses to leave the company voluntarily. The involuntary attrition type is when the organization ends the employment process. The external attrition type is referred to when an employee leaves an organization to work for another organization. Internal attrition occurs when an employee is given another position within the same organization as a promotion. The employee attrition rate is the measure of people who leaves the organization. By measuring the attrition rate, we can identify the causes and factors that need to be solved to eliminate employee attrition. The attrition rate is calculated by dividing the number of employees who have left the company by the average number of employees over some time. The attrition rate helps us find the company’s progress over a specific period.
The employee attrition states [
1] demonstrate that after six months of job duration, 1/3 of new employees leave the organization. The 3 to 4.5 million employees leave their job every month in the United States, according to the Job Openings and Labor Turnover Survey (JOLTS) [
2]. The employee attrition rate is 57.3% in 2021 to the report of the Bureau of Labor Statistics [
3]. The report also suggests that in many industries, the employee attrition rate is close to 19% [
2]. The cost per hire of new employees is USD 4129 by SHRM [
4]. Ninety percent of employee retention rate is considered suitable for a company, and the attrition rate must be less than 10%.
Machine learning [
5] in the field of Artificial Intelligence (AI) gives the ability to machines to learn from historical data and make future predictions. Currently, machine learning is a crucial component of the data science field. The goal of machine learning techniques is to achieve higher accuracy results than humans. The machine learning models are utilized for decision-making. The learning process of machines is automated. The refined data are fed to machines to train and obtain decisions from them for new data. The primary aim of machine learning models is to find the patterns in data and learn from them.
The applications of machine learning for today’s technology are growing daily. The key applications of machine learning cover a broader area of real-world domains. The typical real word problems such as image recognition [
6], traffic prediction [
7], speech recognition, text classification [
8], social analysis, stock market trading, health care [
9], e-commerce, agriculture, healthcare, and many more are solved by using machine learning techniques. The machine learning models are utilized for the prediction of employee attrition [
10]. The followings are the main contributions of our proposed research study in the context of employee attrition prediction:
The four advanced machine learning-based techniques Extra Trees Classifier (ETC), Support vector machine (SVM), Logistic Regression (LR), and Decision Tree Classifier (DTC), were applied for predicting employee attrition;
The comparative analysis among the four employed machine learning models in terms of accuracy score value was conducted to find the best performance fit evaluation technique;
We optimized the proposed ETC technique as an innovation to achieve the highest accuracy scores in comparison with machine learning techniques and also with the state-of-the-art studies;
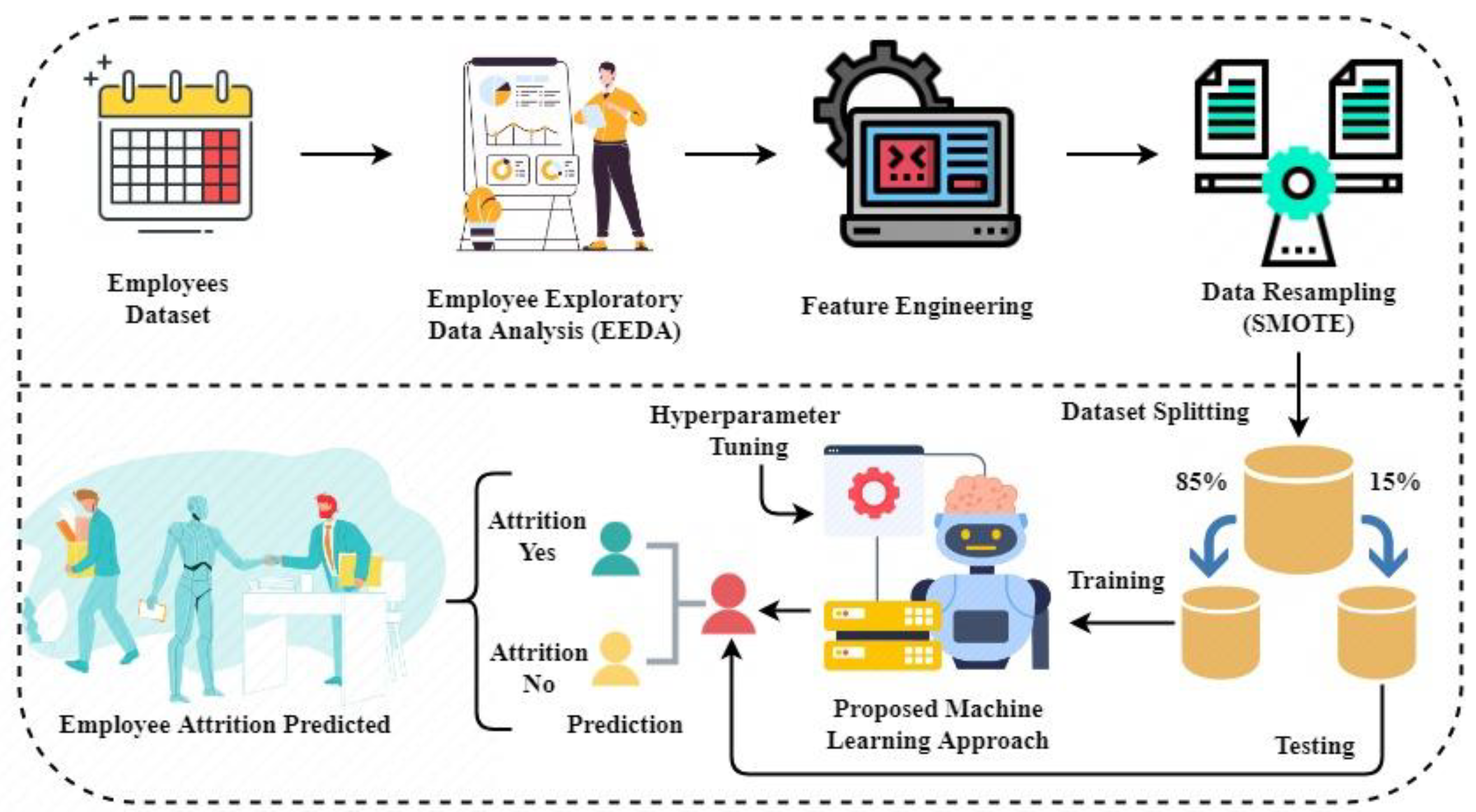
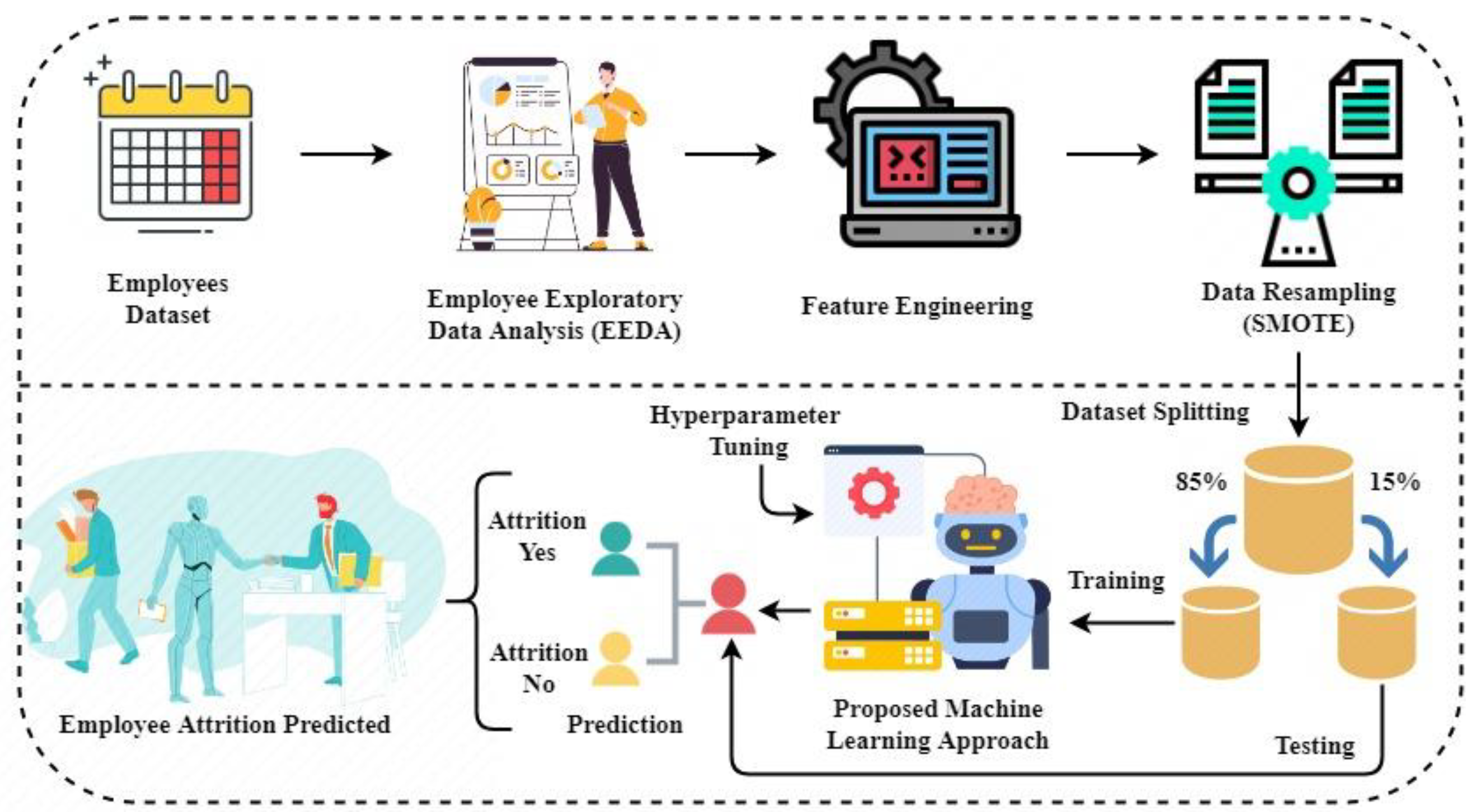
The Employee Exploratory Data Analysis (EEDA) was applied to obtain valuable insights from the dataset. The factors that affect employee attrition were examined.
The SOMTE (Synthetic Minority Oversampling Technique) dataset resampling was applied to make the dataset balanced. The data balancing reduces the model prediction complexity due to the equal number of target distributions and increased model accuracy scores;
The K-Fold cross-validation comparative analysis among the four employed approaches in terms of performance evaluation accuracy score;
The confusion matrix and ROC curve analysis of our proposed approach were conducted to examine the performance validation through different evaluation techniques.
The next sections of our research study are organized as follows: The related literature to our research is examined in
Section 2. The methodology analysis of our research is reviewed in
Section 3. The proposed approaches in the context of employee attrition are discussed in
Section 4. The results and evaluations of our proposed research study are examined in
Section 5.
Section 6 is based on the conclusion of our research study.
2. Related Work
The related literature to our research study is examined in this section. The related literature is based on the summary of past applied approaches and research outcomes for predicting employee attrition. The most recent applied state-of-the-art approaches were selected for the literature review.
In the classification task, the Performance Assessment of Data Balancing Techniques was proposed [
11]. The imbalanced dataset causes a major issue in numerous classification problems such as intrusion detection, fraud detection, anomaly detection, and many more. The data balancing was applied to obtain the high accuracy results from prediction models. The research study addresses the performance issues empirically using an imbalanced dataset. Hybrid Sampling (HS), Synthetic Minority Over Sampling (SMOTE), Under Sampling (US), Random Over Sampling Examples (ROSE), Over Sampling (OS), and Clustering-Based Under Sampling (CBUS) balancing techniques were examined. The imbalance ratio (IR) was used as the performance factor. The research experimental results show that data balancing proves helpful in improving the applied classifiers’ performance. The results also indicate that no significant performance difference was found in US, SMOTE, HS, OS, and CBUS balancing techniques.
The introduction and real-world applications of neural network techniques were analyzed [
12]. Neural networks are a subtype of the machine learning area. The advantages of neural network techniques are high-speed processing and parallelism with big data. Neural networks are useful and novel techniques for solving learning problems. The working of neural networks is similar to the biological nervous systems of the human brain. The major brain element is the information processing unique design. This is based on the numerous complex neurons that are interconnected. The neural networks contain layers of nodes that are independent of one another. The study analyzed the neural network techniques, performance comparison, and challenges. The research study presented that the feedforward and feedback propagation neural networks techniques were performing better with the huge dataset to solve real-world problems. The analyzed factors were fault tolerance, processing speed, accuracy, latency, scalability, volume, and performance.
The prediction of employee attrition rate using machine learning-based classification algorithms was proposed [
13]. The HR employee data collected from Kaggle were utilized for the model-building process. The K-Nearest neighbors, extreme gradient boosting, Ada Boosting, Decision Tree, neural networks, and Random Forest applied machine learning techniques [
14] for the classification task. The regularization techniques were applied to find the best-fit parameters for predicting the employee attrition rate. The different steps were applied to obtain an accuracy score of 88%.
The automated prediction of employee attrition based on several machine learning models was proposed in this study [
15]. The IBM HR employee dataset was utilized for learning model building and model evaluation process. The Ad boost Model, Random Forest Regressor, Decision Tree, Logistic Regressor, and Gradient Boosting Classifiers were utilized for the prediction task. The Decision Tree and Logistic Regressor achieved an 86% accuracy score. The goal was the accurate detection of employee attrition to help the organizations to boost their employee satisfaction [
16].
The three-stage system based on preprocessing, processing, and post-processing techniques was proposed to predict employee attrition [
17]. The IBM HR employee dataset was utilized for framework training and testing. The max-out feature selection technique was utilized for the dimension reduction stage. The logistic regression technique was utilized for employee attrition prediction. The model results achieved an 81% of accuracy score. The framework parameters were validated.
The comparison of state-of-the-art machine learning methods was applied to predict employee attrition using the IBM HR employee dataset [
18]. The results of the study were utilized to warn managers to update their business strategies [
19]. The six machine learning models were utilized. The Random Forest was the proposed approach. The accuracy of the proposed approach was 85% for the prediction of employee attrition. The study findings are based on the factors social, financial, cultural, relational, and professional that caused employee attrition. The prediction of employee attrition using the IBM HR employee dataset was proposed [
20]. The seven-machine learning techniques were applied and evaluated. The factors that cause attrition were determined by the gain ratio approach. The dataset balancing was applied using bootstrapping technique. The proposed model achieved an 80% of accuracy score. The factors that cause attrition were ranked according to their gain ratio scores.
The employee attrition prediction using a machine learning pipeline [
21] was proposed in this study [
22]. The study findings analyze the factors such as the number of years of work experience, educational qualifications, gender, and department were that caused employee attrition. The pipeline was based on gradient boosting and ensemble learning techniques. The hyperparameter tuning was applied to models using a randomized grid search technique. The pipeline algorithm achieved state-of-the-art performance. The k-fold cross-validation was applied for model evaluations.
The emotional assessment and prediction of employee attrition rate of the employee were proposed [
23]. The dataset was collected through a survey based on attrition-related questions. The Decision Tree, Random Forest, and Support Vector Machine classifiers were applied for the prediction task. The proposed approach achieved an 86% of accuracy score in predicting attrition rate.
The systematic flow for predicting employee attrition using machine learning techniques was proposed in this research study [
24]. The machine learning models Naive Bayes, Random Forest, Decision Tree, Support Vector Machine, and K-Nearest Neighbor were applied using the python tool. The Random Forest was the proposed approach with an accuracy score of 83%. The key causes of employee attrition were found and minimized using data analysis.
The rise of a sudden pandemic in 2020 brought significant losses in employment to the global economy [
25]. In China, a governmental force contributed to 50% of tax revenue, 80% of jobs, 60% of GDP, and 70% of innovation. The limited capability results in a higher employee attrition rate. The higher employee attrition rate causes unemployment stress. The studies show that job stress cause problems of job dissatisfaction and burnout, resulting in a higher turnover rate.
The related literature was examined in comparison with our proposed study. The analysis demonstrates that our proposed model outperformed in comparison with machine learning techniques and state-of-the-art studies. We applied hyperparameter optimization and data balancing techniques to achieve the highest accuracy scores for the prediction of employee attrition. The literature analysis concluded that these applied techniques were not performed by past applied techniques in the related literature.
4. Proposed Machine Learning Approaches
The four advanced machine learning-based techniques, Support Vector Machine (SVM), Logistic Regression (LR), Decision Tree Classifier (DTC), and Extra Trees Classifier (ETC), were applied in this research study. The ETC is our proposed approach for predicting employee attrition.
The SVM technique [
29] is a family of supervised learning models that are based on support vectors used for classification. The SVM model [
30] creates a best-fit decision boundary that divides input n-dimensional feature space data into target classes. The decision boundary is called a hyperplane. A hyperplane is an n-dimensional Euclidean space that divides the space into two disconnected subsets. The iterative manner was used by SVM to create the best fit hyperplane to minimize the error. The SVM selects the extreme vectors that are useful for creating the hyperplane. These extreme vectors are called support vectors. The separating hyperplane is expressed in Equation (1). Where
w is the weight matrix,
x is the input feature, and b is the biased values.
The LR is a statistical supervised machine learning method used for classification problems. The LR technique [
31] was used to describe the relationship between dependent and independent variables. The LR uses the concept of the sigmoid function. The probabilistic values of the sigmoid function lie between zero and one. The S-shaped logistic function is fit for prediction. The LR model is expressed in Equation (2). where the predicted class output is
y, the bias term is
b0, and the coefficient for input
x is
b1.
The DTC is a supervised machine learning technique utilized for classification problems. The DTC [
32] is a tree structure representation where the target class labels represent on the leaf node, decision rules represent by branches, and the attributes are represented on the internal nodes. The motive of DTC [
33] is to predict the target class by learning decision rules inferred from training data. The DTC is good to utilize because the decision-making rule is mimicked by human thinking ability. The best attributes are selected by Information Gain and Gini Index in DTC. The Gini Index is calculated as expressed in Equation (3).
The ETC is an extension of the ensemble learning method based on the construction of bagged decision trees [
34]. The ETC concept is similar to the Random Forest; however, the difference in forest construction. The ETC aggregates the outcome of multiple de-correlated decision trees to predict the target class for the classification task. The ETC technique works by generating a large number of bagged decision tree samples from the training data. The decision rule is selected randomly. The majority voting is used for predictions from decision trees. The majority voting predictions are aggregated to yield the final prediction. The entropy calculated for ETC is expressed in Equation (4).
Hyperparameter Tuning
The hyperparameter tuning was applied to find the best-fit parameters of applied machine learning models [
35]. The hyperparameter configuration parameters were examined in
Table 2. The hyperparameters were achieved by checking the model’s outcome accuracy results iteratively on the dataset. The parameters on which model performance score are efficiently selected as their hyperparameters. The tuning proved very fruitful in our research study. Our applied machine learning models achieved good accuracy scores.
5. Results and Discussions
The results and evaluations of our proposed research study are examined in this section. All the experiments were run on a machine with specifications of Intel (R) Xeon (R) CPU, 13 GB RAM, 2249.998 MHz CPU, 512KB cache size, and the CPU model name is AMD EPYC 7B12. The results in terms of predicting employee attrition were carefully examined. The evaluation metrics of our machine learning-based research study include the training accuracy, testing accuracy, precision score, recall score, f1 measure score, and ROC curve score. The followings are the important factors of evaluation metrics:
True Positive: when both the predicted values and actual values are positive;
True Negative: when both the predicted values and actual values are negative;
False Positive: when the approach predicts a value as positive but the actual value is negative;
False Negative: when the approach predicts a value as negative, but the actual value is positive.
During the training and testing process of our proposed ETC model, the accuracy score results were measured. In order to demonstrate how much our machine learning model is accurate on training and testing data, we found that our model achieved a 93% of accuracy score on unseen data. Then we made our model generalize. In order to calculate the accuracy score, the formula equation is expressed in Equation (5).
The precision is the measure of the model that correctly identifies values as positive out of all values. The recall of the model is the measure of correctly identifying true positive values. The recall and precision scores of our proposed model are 93%. The mathematical notations to calculate the precision and recall are expressed in Equations (6) and (7), respectively.
The f1 score was utilized to summarize the performance of our predictive model. The f1 score combines the recall and precision score values. The f1 score value of our model was 93%. The log loss is a Logarithmic cost function used to find the loss of the model in classification. The log loss value of our model was 2.3337248795797283. The f1 score was calculated as expressed in Equation (8).
The ROC curve accuracy metric was utilized to measure the accuracy of the predictive model in terms of the area under the curve at the different thresholds of the target class. The ROC accuracy of our model was 93%. In order to calculate the ROC accuracy, Equation (9) is expressed.
The comparative performance analysis among the applied machine learning techniques is examined in
Table 3. The analysis demonstrates that the LR technique has a low accuracy score of 72% results among all. The proposed ETC technique achieved the highest accuracy of 93%. Our proposed ETC approach outperformed.
The classification report analysis of all applied machine learning approaches is examined in
Table 4. The analysis is based on the performance metrics of precision, recall, f1 score, and support score category-wise. The performance metrics were also analyzed in the average case. The analysis shows that the classification report of proposed ETC techniques achieved higher score results in comparison with other employed machine learning models.
The 10-fold cross-validation was applied to all employed machine learning models. The k-fold cross-validation comparative analysis among the employed approaches is analyzed in
Table 5 and
Figure 8. The machine learning model increases the accuracy scores by utilizing the k-fold validation. The k-fold technique proves useful as by applying it, the model’s performance accuracy results are increased.
The performance accuracy comparative analysis of our proposed ETC approach with the past applied state of art approaches are examined in
Table 6 and
Table 7. The recently applied approaches were examined for comparison analysis. The analysis shows that our proposed approach achieved the highest accuracy results. Our proposed model achieved the best result for predicting employee attrition.
The ROC curve analysis of our proposed technique is examined in
Figure 9. The higher the area under the curve, the higher the model validation performance in classification. The ROC analysis demonstrated that our proposed model achieved a 93% of accuracy score. This analysis validates our approaches in the prediction performance for employee attrition.
The confusion matrix analysis of our proposed approach is examined in
Figure 10. The analysis shows that the 182 samples were identified as the true positive values, and 163 samples were identified as the true negative values out of the test dataset. The 11 samples were identified as false positives, and 14 samples were identified as false negatives. The confusion matrix validated our accuracy score of 93%.
6. Conclusions
The employee attrition prediction by using the four advanced machine learning techniques ETC, SVM, LR, and DTC, were applied in comparison in this study. The applied machine learning techniques achieved accuracy scores of 87% by SVM technique, 72% by LR technique, and 83% by DTC technique. The proposed Extra Trees Classifier (ETC) achieved 93% accuracy, precision, recall, f1 score, and ROC accuracy scores. The data resampling was applied to balance the dataset. The approaches were validated with k-fold validation and with the past applied state-of-the-art studies. By using dataset 10-folds, the SVM technique achieved an 88% of accuracy score, the LR technique achieved a 74% of accuracy score, the DTC technique achieved an 84% of accuracy score, and the proposed achieved a 93% of accuracy score. The EEDA application revealed the key factors that cause employee attrition is the monthly income, hourly rate, job level, and age. Our research findings help organizations overcome employee attrition. The study limitations and in future direction, we will apply the deep learning techniques to predict the employee attrition. Moreover, we will enhance the dataset feature space to obtain more accurate results by using deep learning techniques.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}