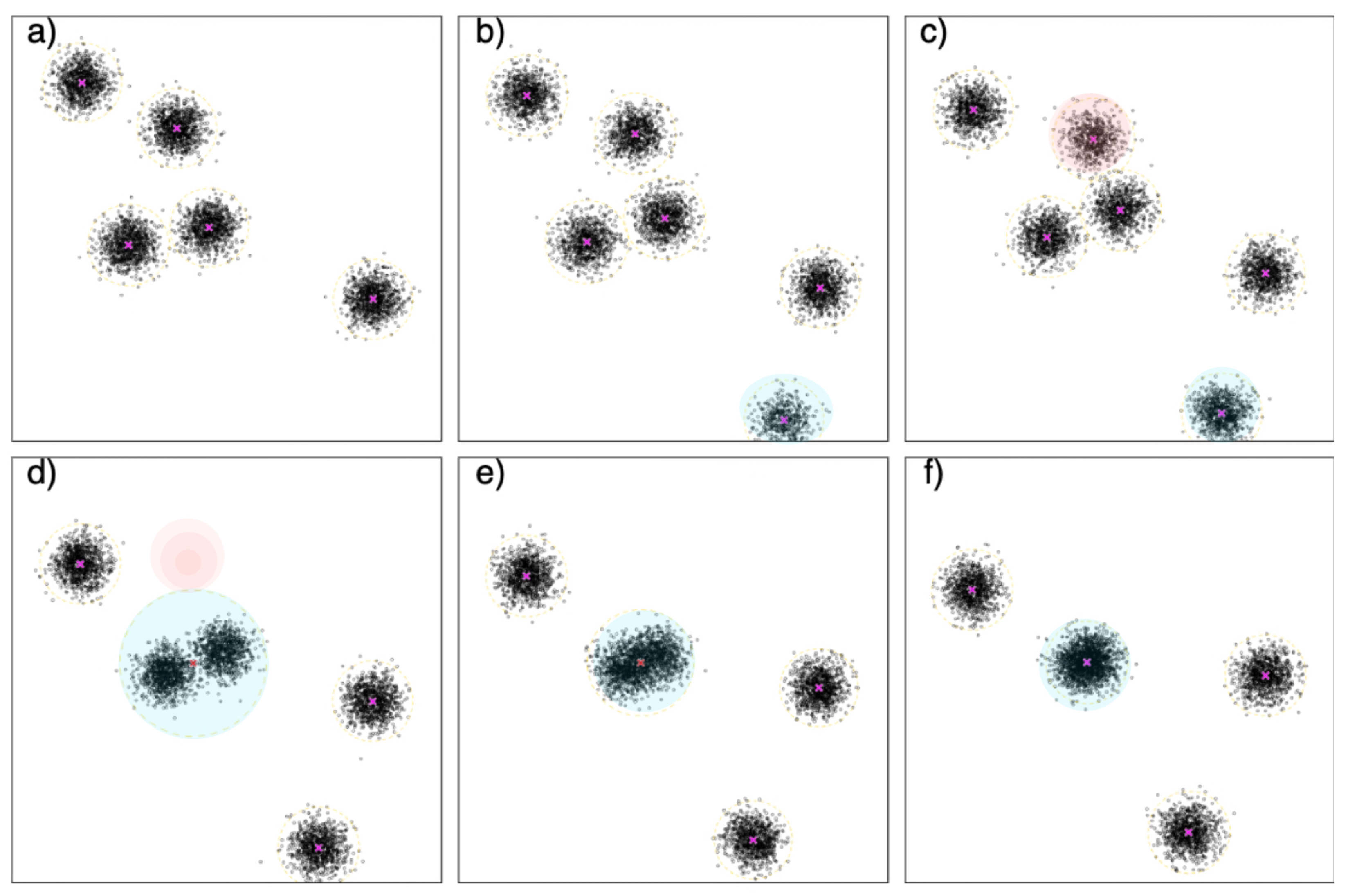
The stream clustering algorithms should handle the dynamic nature of streaming data, in which there is no control over the data arrival order, and the underlying data distribution can change over time. Such changes can be reflected in data clusters [
23]. To illustrate such changes in Gaussian data distribution over time, assume that we look at the data stream in six moments represented in
Figure 2a–f. Initially,
Figure 2a illustrates five data distributions. After this, a new data distribution appears (which can be gradual or abrupt), shown in
Figure 2b,c. Moreover, some data distributions can disappear, highlighted in red in
Figure 2c,d, or merge with existing ones.
Figure 2d,e illustrate two data distributions that are becoming closer over time, and then they merge, forming one dense data distribution, as in
Figure 2f.
Initially introduced in [
13], this section presents three evolutionary algorithms developed and compared in the present study, designed to cluster scalable batch streams and dynamically estimate the number of clusters. In [
12], the algorithms use sequential and parallel approaches to process data objects one-by-one, respecting the data points’ sequence, such as traditional data stream clustering algorithms. However, the analysis of single objects sequentially shows a severe computational bottleneck towards the distributed processing. In advance of the present work, all the compared algorithms used the Discretized-Stream (DS) [
11] approach to properly handle the data streams in the MapReduce model, taking full advantage of the distributed computation and scalability of the framework. In the DS model, the t-th micro-batch
consists of an unsorted set of data points
, where
p is the offset of the micro-batch and
q is the size of the micro-batch. A micro-batch
can be interpreted as one of six scenarios illustrated in
Figure 2 from a to f. When the micro-batch arrives, it is distributed through the nodes of the system so that
, where
m is the size of the distributed system, and
represents a subset of
stored in a node. Note that MapReduce implementation replicates all the data in a few nodes to ensure reliability and fault tolerance. Moreover, the time window established by the DS model is the union set of the last micro-batches
, where
is the window size. Note that the time window is not a computational resource limitation but a forgetting mechanism related to the data evolution [
1].
3.1. SESC
Scalable Evolutionary Stream Clustering (SESC) [
13] is an evolutionary algorithm able to cluster batch streams by using the largely widespread data summarization [
3]. The algorithm has two main steps, the data summarization (abstraction phase), done over distributed data, and the data clustering (clustering phase), performed by applying F-EAC over the summarized data.
The data are summarized as micro-clusters [
22], which have four components:
n (the number of data points),
(the linear sum of the data points),
(the sum of squared data points), and
(the timestamp of the most recent data point of the micro-cluster). Given a micro-cluster
M formed by a set of data points
, where
n is the number of data points belonging to it, the linear sum of
M is given by a vector
and its sum of square
. The representative of a micro-cluster
M is given by its centroid (mean vector from data points of
M)
. Micro-clusters have two relevant capabilities: the incrementality, which allows adding a single point
i to a micro-cluster
j (by summing up
with the components of
,
and
), and the additivity, which allows combining two micro-clusters, simply adding their three first components (
n,
, and
) and taking the maximum
. An outdated
(related to the time window) means that the micro-cluster is no longer updated.
Figure 3 shows an overview of the algorithm. When the
t-th micro-batch is received, the objects are distributed through the nodes by the DS framework. When the accumulated objects (micro-batch) are delivered to SESC, each node works in a parallel and independent way to maintain a set of
q micro-clusters. After the initial micro-clusters are obtained by applying
k-means in the first portion of data, the received objects (by the node) are inserted into the micro-cluster model according to the CluStream update method [
22]: a data point
is inserted into a micro-cluster
if the Euclidean distance between
and the centroid
,
, is less than the
boundary; otherwise, a new micro-cluster is created considering the
,
, and
. There is a threshold for the number of micro-clusters (
q); thus, an extra action is necessary to fix the model when the limit is exceeded. They are removed if there are outdated micro-clusters (
is outside of the time window). Otherwise, the closest pair is merged into a single micro-cluster.
When all the nodes finish the micro-cluster model update, which is executed in parallel, a set composed of the union of all the micro-clusters (from all the nodes) is used as weighted data points by the centralized F-EAC algorithm in order to estimate the number of clusters and build a (macro-)clustering model. It is expected that the number of micro-clusters is higher than the number of macro-clusters () and much smaller than the data stream size (). Thus, it is expected that the centralized system can handle the summarized data.
3.2. ISESC
Differently from SESC, the
Incremental Scalable Evolutionary Stream Clustering (ISESC) [
13] was designed to cluster raw data directly instead of summarizing them into micro-clusters. Storing the data requires more resources such as memory and processing time than micro-clusters but provides more information and higher accuracy. Distributed and scalable frameworks (such as MapReduce) were designed to provide such resources. SF-EAC provides the first macro-clustering model over an initial data portion, using distributed and parallel computation. These macro-clusters use a data structure extended from the micro-cluster concept, providing incrementality and additivity capabilities. Besides the components
n,
,
, and
, the macro-cluster structure also keeps the lowest simplified silhouette index (SS) value (
) among its data points. The SS index considers the compactness and the separation of the data point
belonging to a micro-cluster
, which are represented by two terms,
and
, respectively. Specifically, the
term is given by
and
, where
is the closest neighbor micro-cluster centroid to
. Then, the SS index is calculated as
. The average SS index for all data points gives an estimate of full clustering quality, which ranges from 0 to 1 (under
k-means assumption). The cluster radius (
) can be calculated according to Equation (
1), which results in the standard deviation, and
defines how many standard deviations compose the radius (
).
Figure 4 presents an overview of ISESC. After SF-EAC clusters the first micro-batch, the incremental update component of the algorithm updates the model with new data from the following micro-batches. If the component detects a change (concept drift) during the update, the full-clustering component (SF-EAC) is executed to estimate the number of clusters and build a new model.
Inspired by FEAC-Stream [
23], the incremental update component searches for evidence of a significant change (e.g., the emergence of a new cluster) and, if there is none, updates the clusters incrementally. For each data point, the component calculates the shortest Euclidean distance between the point and the centroids (
d), and its SS value (
) [
21] associated with the closest cluster. Evidence of a significant change is a data point for which
d is higher than the radius of the closest cluster (
) or has an SS value inferior to the lowest SS value of the points of the associated cluster (
). If any data point of the micro-batch matches this evidence criterion, the full-clustering component is executed; otherwise, the associated cluster is updated, and the incremental update component continues. All distances, SS, and tests of evidence are made in a distributed fashion through map jobs of MapReduce.
The evidence criterion is represented and visualized as two boundaries for each cluster.
Figure 5 is a partial representation of a bi-dimensional clustering model, where
and
are cluster centroids and
are data points. The dotted lines represent the clusters’ radius (
) boundaries, and the dashed lines represent the irregular and convex lowest simplified silhouette (
) boundaries given by the SS function. In this illustrative scenario,
is within the
boundary of
but not within that of
. The
boundary can assume such irregular and wide areas that may even encompass new clusters, and then this object will be treated as evidence of a significant change. In turn,
is within overlapping
boundaries but is not within any
area. Inserting
in either
or
may not be considered correct, as it does not truly merge these two clusters. Thus,
will also be treated as evidence of a significant change (cluster merging). Note that
areas will never overlap since they grow towards the Voronoi diagram, and
k-means always consider the minimum distance. The data point
is outside both boundaries and will be treated as evidence of a significant change. The last data point,
, lies within both boundaries of
and does not represent evidence of a significant change.
If evidence of change is detected, the model is incrementally updated. A reduce job assigns the data points to their closest clusters, aggregating their summaries and incrementally updating their information. Then, clusters not updated in the most recent time window, i.e., with values older than the time window limit, are removed from the model. The remaining updated clusters compose the new model.
Otherwise, if evidence of change is detected, the full-clustering component is executed over the data of the present time window. It consists of running SF-EAC over an initial population of pre-defined solutions built from the current model and derivatives. The current model reflects the known structure along the data stream. Based on this model, two methods are used to derive it: the first aims at increasing iteratively the number of clusters
k until a limit
is reached, selecting prototype candidates among the farthest objects from the existent centroids (inspired by [
18]); the second method aims at decreasing
k by merging the closest pairs of clusters repeatedly until a
cluster is reached. The closest pair of clusters is estimated by their boundaries, i.e., the distance between centroids minus the sum of their radii values (
). If necessary, both methods may use other arbitrary stopping criteria (the maximum population size, for example). Besides guided initialization, SF-EAC provides different strategies to diversify the population during the evolutionary search, estimating a new data-adjusted model.
ISESC incrementally updates the model with a low computational cost when no significant change is detected. However, it runs the full-clustering component at any evidence of change, which is the most accurate (but costly) way to learn the current clustering model. Thus, ISESC prioritizes quality and is suitable for data sets with low concept drift, i.e., the clusters do not or rarely change abruptly. Otherwise, the full-clustering component may be triggered repeatedly, requiring computational resources.
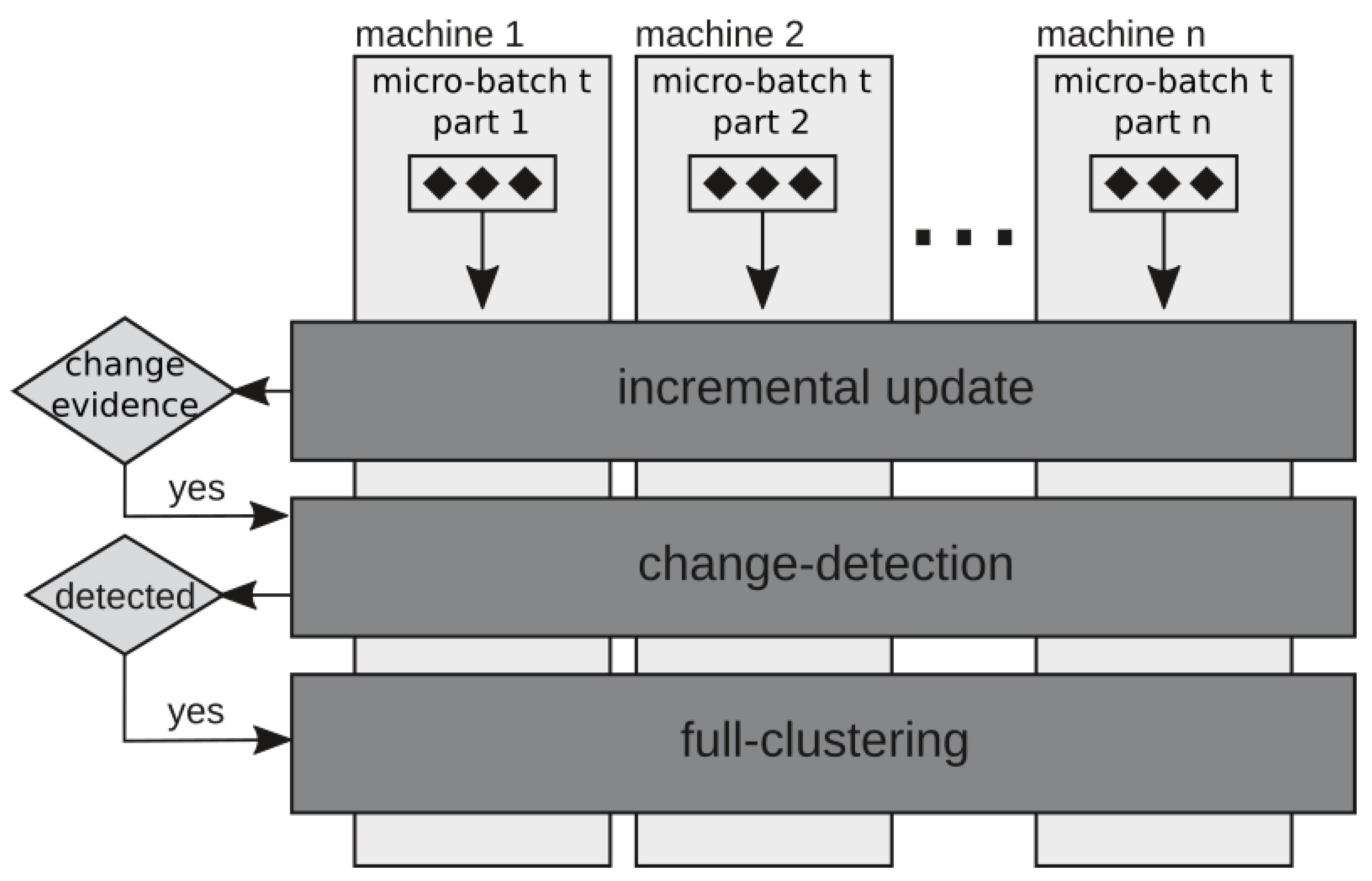
3.3. ISESC-CD
Incremental Scalable Evolutionary Stream Clustering with Change Detection (ISESC-CD) [
13] is an extension of ISESC with one additional heuristic component, an attempt to avoid unnecessary executions of full clustering. The change-detection component (CD) resides between the incremental update and full-clustering components, as shown in
Figure 6. This component addresses five types of data stream changes detected by the incremental update component: (i) the displacement of an existing cluster in space; (ii) the emergence of a new cluster; (iii) the split of an existing cluster caused by the arrival of objects that leads two or more parts of the cluster in different directions; (iv) the disappearance or expiration of an existing cluster according to its
and the time window; (v) the merging of two existing clusters, as they incrementally overlap each other. The role of CD is to distinguish the displacement of the clusters (case i) from the others, as cases ii and iii increase the number of clusters
k, while cases iv and v decrease it. Applying
k-means is enough to deal with cluster displacements, while the full-clustering component is required to estimate models with variations of
k.
The model’s change is detected by comparing the current model with two derivations of it. The first derivation results from adding the farthest object from the centroids of the model as a new centroid, increasing k by one. The second results from merging the closest pair of clusters according to its boundaries (the distance between the centroids minus the sum of their radii), decreasing k by one. Both derivations and the current model are fine-tuned by distributed k-means, and then compared among themselves in terms of SS index values. If the current model is the best evaluated, it is preserved. Otherwise, significant evidence of change is detected, and the full-clustering component builds a new model.
Although the full-clustering component is essentially SF-EAC, other clustering algorithms may be considered since the incremental update and change-detection components work regardless of the full-clustering and vice versa. This structure, named Incremental Scalable Stream Clustering with Change-Detection (ISSC-CD), allows the exploration of new batch stream clustering algorithms from non-stream ones.
3.4. Computational Complexity Analysis
For the worst-case scenario, the asymptotic computational complexity of the evolutionary algorithms presented in this work for single micro-batch processing is shown in
Table 1. The size of the micro-batch is given by
,
d is the dimensionality of the data,
is the number of micro-clusters,
m is the number of worker nodes of a distributed system,
is the size of the landmark window,
is the maximum number of clusters found during the process,
i is the maximum iterations of
k-means,
g is the maximum generations of F-EAC-based algorithms, and
is the population size.
Although the three algorithms have linear complexity in relation to the stream/micro-batch size, for most scenarios, , which gives SESC a lower boundary than ISESC and ISESC-CD.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}