
Deep Vision Multimodal Learning: Methodology, Benchmark, and Trend


Abstract
:1. Introduction
- In terms of methodology, we propose a rational classification, including architectures, paradigms, and issues. We pay particular attention to recent works in this field.
- In terms of benchmarks, we collect larger scale multimodal tasks and benchmarks, as well as state-of-the-art models and metrics corresponding to each dataset.
- In terms of trends, we outline the trends according to the works in recent years and discuss the challenges that deserve attention in the future.
2. Learning Architectures
2.1. Feature Extraction
2.2. Modality Aggregation
2.3. Multimodal Loss Function
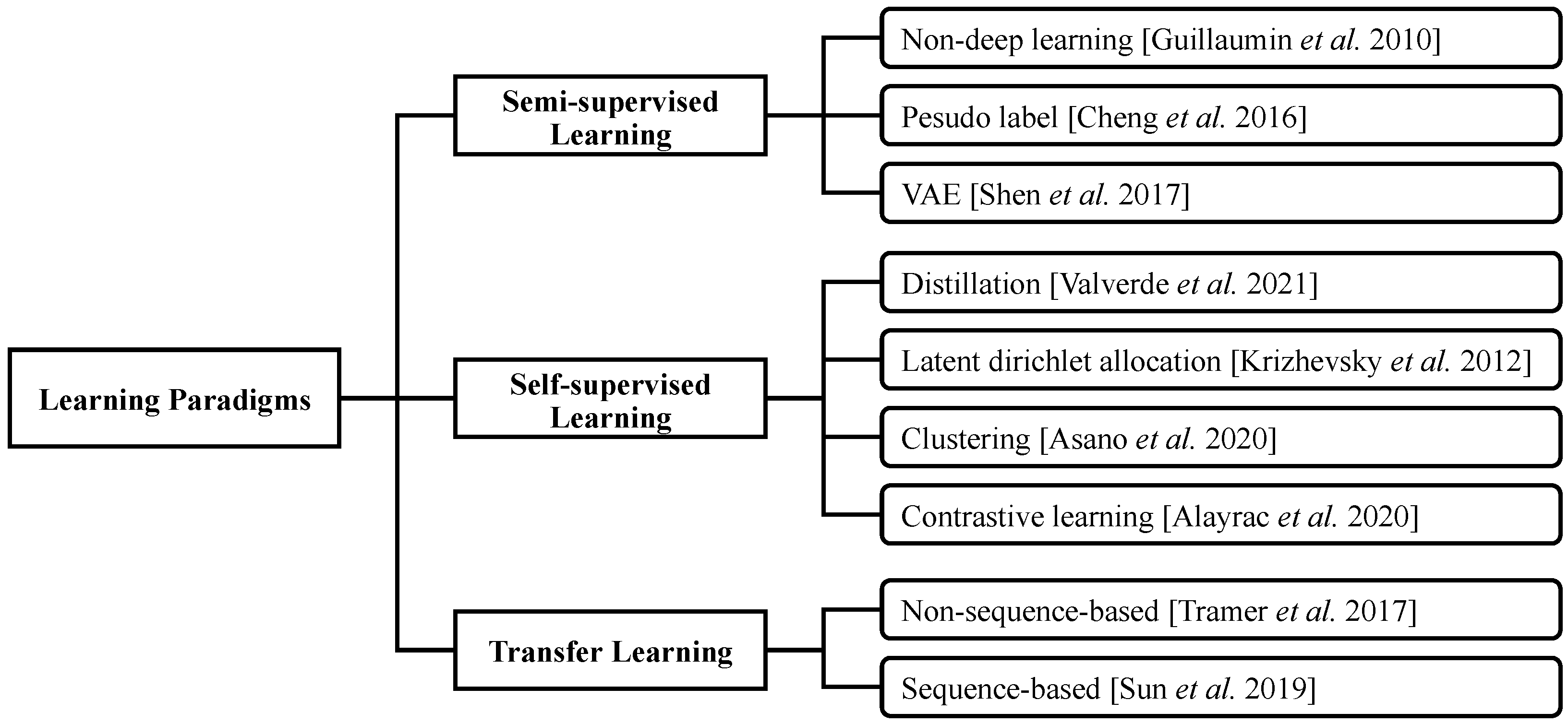
3. Learning Paradigms
3.1. Semi-Supervised Learning
3.2. Self-Supervised Learning
3.3. Transfer Learning
4. Multimodal Data Analysis
4.1. Missing Modalities
4.2. Noisy Modalities
5. Application
5.1. Media Captioning
5.2. Visual Question Answering
5.3. Multimodal Machine Translation
5.4. Text–Image Retrieval
5.5. Text-to-Image Generation
6. Multimodal Benchmark
6.1. Image Captioning
6.2. Visual Question Answering
6.3. Multimodal Machine Translation
6.4. Text-Image Retrieval
6.5. Text-to-Image Generation

{kind=link}
{kind=link}
{kind=link}
| Task and Dataset | Model | Year | Metric | |||
|---|---|---|---|---|---|---|
| Image Captioning | BLEU-4 [194] | METEOR [195] | CIDEr [196] | SPICE [197] | ||
| COCO Captions [189] | OFA [199] | 2022 | 43.5 | 31.9 | 149.6 | 26.1 |
| SimVL [201] | 2021 | 40.6 | 33.4 | 143.3 | 25.4 | |
| Oscar [200] | 2020 | 41.7 | 30.6 | 140.0 | 24.5 | |
| COCO [104] | M2 Transformer [213] | 2019 | 39.1 | 29.2 | 131.2 | 22.6 |
| Flickr30k [188] | Unified VLP [198] | 2019 | 30.1 | 23.0 | 67.4 | 17.0 |
| npcaps [193] | LEMON-large [214] | 2021 | 34.7 | 31.3 | 114.3 | 14.9 |
| SimVLM-huge [201] | 2021 | 32.2 | 30.6 | 110.3 | 14.5 | |
| TextCaps [191] | LSTM-R [215] | 2012 | 22.9 | 21.3 | 100.8 | 13.8 |
| VizWiz [192] | CASIA-IVA | 2020 | 28.3 | 22.1 | 79.1 | 17.9 |
| Local Narratives [190] | LoopCAG [216] | 2021 | 27.0 | 26.0 | 114.0 | - |
| SciCap [217] | CNN+LSTM [217] | 2021 | 21.9 | - | - | - |
| Visual Question Answering | Overall | Y/N | Number | Other | ||
| VQA v1 [119] | SAAA [203] | 2017 | 64.5 | 82.2 | 39.1 | 55.2 |
| DAN [202] | 2016 | 64.3 | 83.0 | 39.1 | 53.9 | |
| VQA v2 [125] | VLMo [218] | 2021 | 81.3 | 94.7 | 67.3 | 72.9 |
| OFA | 2022 | 80.5 | 92.9 | 67.0 | 72.7 | |
| VQA-CP [140] | CSS [219] | 2020 | 58.9 | 84.4 | 49.4 | 48.2 |
| VQA-CE [220] | RandImg [220] | 2021 | 63.3 | - | - | - |
| COCO | MCB 7 att. [135] | 2016 | 66.5 | - | - | - |
| VCR [221] | VL-BERT-Large [79] | 2019 | 75.5 | - | - | - |
| GQA [131] | NSM [222] | 2019 | 63.2 | 78.9 | - | - |
| CLEVR [127] | NS-VQA [136] | 2018 | 99.8 | - | - | - |
| IconQA [223] | Patch-TRM [223] | 2021 | 82.7 | - | - | - |
| MSRVTT-QA [224] | Just Ask [225] | 2020 | 41.5 | - | - | - |
| Multimodal Machine Translation | BLEU | METEOR | ||||
| Multi30k [152] | DCCN [205] | 2020 | 39.7 | 56.8 | ||
| Caglayan [226] | 2019 | 39.4 | 58.7 | |||
| MM Transformer [160] | 2020 | 38.7 | 55.7 | |||
| Text-Image Retrieval | Recall@1 | Recall@5 | Recall@10 | |||
| COCO Captions | VisualSparta [206] | 2020 | 68.2 | 91.8 | 96.3 | |
| COCO | Oscar | 2020 | 78.2 | 95.8 | 98.3 | |
| Flickr30k | VisualSparta | 2020 | 57.4 | 82.0 | 88.1 | |
| FooDI-ML [227] | ADAPT-12T [227] | 2021 | 19.0 | 30.0 | 45.0 | |
| WIT [228] | WIT-ALL [228] | 2021 | 34.6 | 64.2 | - | |
| Fashion IQ [229] | RTIC-GCN [230] | 2021 | - | - | 40.6 | |
| Text-to-Image Generation | FID [211] | IS [210] | ||||
| COCO | Lafite [212] | 2021 | 8.1 | 32.3 | ||
| CUB [207] | Lafite | 2021 | 10.5 | 6.0 | ||
| CelebA-HQ [209] | Lafite | 2021 | 12.5 | 2.9 | ||
| Oxford Flower [208] | StackGAN++ [187] | 2018 | 48.7 | 3.3 | ||
| Text Generation | BLEU-2 | BLEU-3 | BLEU-4 | BLEU-5 | ||
| COCO Captions | LeakGAN [231] | 2017 | 0.95 | 0.88 | 0.78 | 0.69 |
| RankGAN [232] | 2017 | 0.85 | 0.67 | 0.56 | 0.54 | |
7. Future Trends
7.1. Pretraining Paradigm
7.2. Unified Multitask Framework
7.3. Missing and Noisy Modality
7.4. Multimodal Task Diversity
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Huang, Y.; Du, C.; Xue, Z.; Chen, X.; Zhao, H.; Huang, L. What Makes Multi-modal Learning Better than Single (Provably). Adv. Neural Inf. Process. Syst. 2021, 34, 10944–10956. [Google Scholar]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th International Conference on Machine Learning, Washington, DC, USA, 28 June 28–2 July 2011. [Google Scholar]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Yang, Z.; He, X.; Deng, L. Multimodal intelligence: Representation learning, information fusion, and applications. IEEE J. Sel. Top. Signal Process. 2020, 14, 478–493. [Google Scholar] [CrossRef] [Green Version]
- Guo, W.; Wang, J.; Wang, S. Deep multimodal representation learning: A survey. IEEE Access 2019, 7, 63373–63394. [Google Scholar] [CrossRef]
- Mogadala, A.; Kalimuthu, M.; Klakow, D. Trends in integration of vision and language research: A survey of tasks, datasets, and methods. J. Artif. Intell. Res. 2021, 71, 1183–1317. [Google Scholar] [CrossRef]
- Zhang, P.; Li, X.; Hu, X.; Yang, J.; Zhang, L.; Wang, L.; Choi, Y.; Gao, J. Vinvl: Revisiting visual representations in vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5579–5588. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6836–6846. [Google Scholar]
- Gong, Y.; Chung, Y.A.; Glass, J. Ast: Audio spectrogram transformer. arXiv 2021, arXiv:2104.01778. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Singh, A.; Hu, R.; Goswami, V.; Couairon, G.; Galuba, W.; Rohrbach, M.; Kiela, D. FLAVA: A Foundational Language And Vision Alignment Model. arXiv 2021, arXiv:2112.04482. [Google Scholar]
- Likhosherstov, V.; Arnab, A.; Choromanski, K.; Lucic, M.; Tay, Y.; Weller, A.; Dehghani, M. PolyViT: Co-training Vision Transformers on Images, Videos and Audio. arXiv 2021, arXiv:2111.12993. [Google Scholar]
- Akbari, H.; Yuan, L.; Qian, R.; Chuang, W.H.; Chang, S.F.; Cui, Y.; Gong, B. Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text. Adv. Neural Inf. Process. Syst. 2021, 34, 1–16. [Google Scholar]
- Lee, S.; Yu, Y.; Kim, G.; Breuel, T.; Kautz, J.; Song, Y. Parameter efficient multimodal transformers for video representation learning. arXiv 2020, arXiv:2012.04124. [Google Scholar]
- Jason, W.; Sumit, C.; Antoine, B. Memory Networks. arXiv 2014, arXiv:1410.3916. [Google Scholar]
- Sukhbaatar, S.; Szlam, A.; Weston, J.; Fergus, R. End-to-end memory networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–26. [Google Scholar]
- Wang, J.; Wang, W.; Huang, Y.; Wang, L.; Tan, T. M3: Multimodal memory modelling for video captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7512–7520. [Google Scholar]
- Lin, C.; Jiang, Y.; Cai, J.; Qu, L.; Haffari, G.; Yuan, Z. Multimodal Transformer with Variable-length Memory for Vision-and-Language Navigation. arXiv 2021, arXiv:2111.05759. [Google Scholar]
- Chen, S.; Guhur, P.L.; Schmid, C.; Laptev, I. History aware multimodal transformer for vision-and-language navigation. Adv. Neural Inf. Process. Syst. 2021, 34, 1–14. [Google Scholar]
- Xiong, C.; Merity, S.; Socher, R. Dynamic memory networks for visual and textual question answering. In Proceedings of the International Conference on Machine Learning, New York, NY USA, 19–24 June 2016; pp. 2397–2406. [Google Scholar]
- Boulahia, S.Y.; Amamra, A.; Madi, M.R.; Daikh, S. Early, intermediate and late fusion strategies for robust deep learning-based multimodal action recognition. Mach. Vis. Appl. 2021, 32, 1–18. [Google Scholar]
- Khaleghi, B.; Khamis, A.; Karray, F.O.; Razavi, S.N. Multisensor data fusion: A review of the state-of-the-art. Inf. Fusion 2013, 14, 28–44. [Google Scholar] [CrossRef]
- Wu, D.; Pigou, L.; Kindermans, P.J.; Le, N.D.H.; Shao, L.; Dambre, J.; Odobez, J.M. Deep dynamic neural networks for multimodal gesture segmentation and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1583–1597. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kahou, S.E.; Pal, C.; Bouthillier, X.; Froumenty, P.; Gülçehre, Ç.; Memisevic, R.; Vincent, P.; Courville, A.; Bengio, Y.; Ferrari, R.C.; et al. Combining modality specific deep neural networks for emotion recognition in video. In Proceedings of the 15th ACM on International Conference on Multimodal Interaction, Sydney, Australia, 9–13 December 2013; pp. 543–550. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Neverova, N.; Wolf, C.; Taylor, G.; Nebout, F. Moddrop: Adaptive multi-modal gesture recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1692–1706. [Google Scholar] [CrossRef] [Green Version]
- Ma, M.; Ren, J.; Zhao, L.; Testuggine, D.; Peng, X. Are Multimodal Transformers Robust to Missing Modality? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Waikoloa, HI, USA, 3–8 January 2022; pp. 18177–18186. [Google Scholar]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.P. Tensor fusion network for multimodal sentiment analysis. arXiv 2017, arXiv:1707.07250. [Google Scholar]
- Hou, M.; Tang, J.; Zhang, J.; Kong, W.; Zhao, Q. Deep multimodal multilinear fusion with high-order polynomial pooling. Adv. Neural Inf. Process. Syst. 2019, 32, 1–10. [Google Scholar]
- Xu, R.; Xiong, C.; Chen, W.; Corso, J. Jointly modeling deep video and compositional text to bridge vision and language in a unified framework. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 19–25 January 2015; Volume 29. [Google Scholar]
- Sahu, G.; Vechtomova, O. Dynamic fusion for multimodal data. arXiv 2019, arXiv:1911.03821. [Google Scholar]
- Zadeh, A.; Liang, P.P.; Mazumder, N.; Poria, S.; Cambria, E.; Morency, L.P. Memory fusion network for multi-view sequential learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Xu, N.; Mao, W.; Chen, G. Multi-interactive memory network for aspect based multimodal sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 2019; Volume 33, pp. 371–378. [Google Scholar]
- Nagrani, A.; Yang, S.; Arnab, A.; Jansen, A.; Schmid, C.; Sun, C. Attention bottlenecks for multimodal fusion. Adv. Neural Inf. Process. Syst. 2021, 34, 1–14. [Google Scholar]
- Pérez-Rúa, J.M.; Vielzeuf, V.; Pateux, S.; Baccouche, M.; Jurie, F. Mfas: Multimodal fusion architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6966–6975. [Google Scholar]
- Liu, Z.; Shen, Y.; Lakshminarasimhan, V.B.; Liang, P.P.; Zadeh, A.; Morency, L.P. Efficient low-rank multimodal fusion with modality-specific factors. arXiv 2018, arXiv:1806.00064. [Google Scholar]
- Gat, I.; Schwartz, I.; Schwing, A.; Hazan, T. Removing bias in multi-modal classifiers: Regularization by maximizing functional entropies. Adv. Neural Inf. Process. Syst. 2020, 33, 3197–3208. [Google Scholar]
- George, A.; Marcel, S. Cross modal focal loss for rgbd face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7882–7891. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Jing, L.; Vahdani, E.; Tan, J.; Tian, Y. Cross-modal center loss. arXiv 2020, arXiv:2008.03561. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 499–515. [Google Scholar]
- Ging, S.; Zolfaghari, M.; Pirsiavash, H.; Brox, T. Coot: Cooperative hierarchical transformer for video-text representation learning. Adv. Neural Inf. Process. Syst. 2020, 33, 22605–22618. [Google Scholar]
- Tan, H.; Bansal, M. Lxmert: Learning cross-modality encoder representations from transformers. arXiv 2019, arXiv:1908.07490. [Google Scholar]
- Zhu, L.; Yang, Y. Actbert: Learning global-local video-text representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8746–8755. [Google Scholar]
- Kamath, A.; Singh, M.; LeCun, Y.; Synnaeve, G.; Misra, I.; Carion, N. MDETR-modulated detection for end-to-end multi-modal understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1780–1790. [Google Scholar]
- Van den Oord, A.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Chun, S.; Oh, S.J.; De Rezende, R.S.; Kalantidis, Y.; Larlus, D. Probabilistic embeddings for cross-modal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8415–8424. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Valverde, F.R.; Hurtado, J.V.; Valada, A. There is more than meets the eye: Self-supervised multi-object detection and tracking with sound by distilling multimodal knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11612–11621. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zhu, X.; Goldberg, A.B. Introduction to semi-supervised learning. Synth. Lect. Artif. Intell. Mach. Learn. 2009, 3, 1–130. [Google Scholar]
- Guillaumin, M.; Verbeek, J.; Schmid, C. Multimodal semi-supervised learning for image classification. In Proceedings of the 2010 IEEE Computer society conference on computer vision and pattern recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 902–909. [Google Scholar]
- Cheng, Y.; Zhao, X.; Cai, R.; Li, Z.; Huang, K.; Rui, Y. Semi-Supervised Multimodal Deep Learning for RGB-D Object Recognition. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 3345–3351. [Google Scholar]
- Cheng, Y.; Zhao, X.; Huang, K.; Tan, T. Semi-supervised learning for rgb-d object recognition. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 2377–2382. [Google Scholar]
- Tian, D.; Gong, M.; Zhou, D.; Shi, J.; Lei, Y. Semi-supervised multimodal hashing. arXiv 2017, arXiv:1712.03404. [Google Scholar]
- Shen, Y.; Zhang, L.; Shao, L. Semi-supervised vision-language mapping via variational learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1349–1354. [Google Scholar]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021, Early Access. [Google Scholar] [CrossRef]
- Taleb, A.; Lippert, C.; Klein, T.; Nabi, M. Multimodal self-supervised learning for medical image analysis. In International Conference on Information Processing in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2021; pp. 661–673. [Google Scholar]
- Tamkin, A.; Liu, V.; Lu, R.; Fein, D.; Schultz, C.; Goodman, N. DABS: A Domain-Agnostic Benchmark for Self-Supervised Learning. arXiv 2021, arXiv:2111.12062. [Google Scholar]
- Coen, M.H. Multimodal Dynamics: Self-Supervised Learning in Perceptual and Motor Systems. Ph.D. Thesis, Massachusetts Institute of Technology, Boston, MA, USA, 2006. [Google Scholar]
- Gomez, L.; Patel, Y.; Rusinol, M.; Karatzas, D.; Jawahar, C. Self-supervised learning of visual features through embedding images into text topic spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4230–4239. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Afouras, T.; Owens, A.; Chung, J.S.; Zisserman, A. Self-supervised learning of audio-visual objects from video. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 208–224. [Google Scholar]
- Asano, Y.; Patrick, M.; Rupprecht, C.; Vedaldi, A. Labelling unlabelled videos from scratch with multi-modal self-supervision. Adv. Neural Inf. Process. Syst. 2020, 33, 4660–4671. [Google Scholar]
- Alayrac, J.B.; Recasens, A.; Schneider, R.; Arandjelović, R.; Ramapuram, J.; De Fauw, J.; Smaira, L.; Dieleman, S.; Zisserman, A. Self-supervised multimodal versatile networks. Adv. Neural Inf. Process. Syst. 2020, 33, 25–37. [Google Scholar]
- Cheng, Y.; Wang, R.; Pan, Z.; Feng, R.; Zhang, Y. Look, listen, and attend: Co-attention network for self-supervised audio-visual representation learning. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 3884–3892. [Google Scholar]
- Alwassel, H.; Mahajan, D.; Korbar, B.; Torresani, L.; Ghanem, B.; Tran, D. Self-supervised learning by cross-modal audio-video clustering. Adv. Neural Inf. Process. Syst. 2020, 33, 9758–9770. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef] [Green Version]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://openai.com/blog/language-unsupervised/ (accessed on 1 June 2022).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. wav2vec: Unsupervised pre-training for speech recognition. arXiv 2019, arXiv:1904.05862. [Google Scholar]
- Yu, W.; Xu, H.; Yuan, Z.; Wu, J. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis. arXiv 2021, arXiv:2102.04830. [Google Scholar]
- Su, W.; Zhu, X.; Cao, Y.; Li, B.; Lu, L.; Wei, F.; Dai, J. Vl-bert: Pre-training of generic visual-linguistic representations. arXiv 2019, arXiv:1908.08530. [Google Scholar]
- Hu, R.; Singh, A. Unit: Multimodal multitask learning with a unified transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1439–1449. [Google Scholar]
- Chen, F.; Zhang, D.; Han, M.; Chen, X.; Shi, J.; Xu, S.; Xu, B. VLP: A Survey on Vision-Language Pre-training. arXiv 2022, arXiv:2202.09061. [Google Scholar]
- Li, G.; Duan, N.; Fang, Y.; Gong, M.; Jiang, D. Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7 February 2020; Volume 34, pp. 11336–11344. [Google Scholar]
- Zhou, M.; Zhou, L.; Wang, S.; Cheng, Y.; Li, L.; Yu, Z.; Liu, J. Uc2: Universal cross-lingual cross-modal vision-and-language pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 4155–4165. [Google Scholar]
- Rahman, W.; Hasan, M.K.; Lee, S.; Zadeh, A.; Mao, C.; Morency, L.P.; Hoque, E. Integrating multimodal information in large pretrained transformers. Integr. Multimodal Inf. Large Pretrained Transform. 2020, 2020, 2359. [Google Scholar]
- Wang, Y.; Shen, Y.; Liu, Z.; Liang, P.P.; Zadeh, A.; Morency, L.P. Words can shift: Dynamically adjusting word representations using nonverbal behaviors. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 2019; Volume 33, pp. 7216–7223. [Google Scholar]
- Gan, Z.; Chen, Y.C.; Li, L.; Zhu, C.; Cheng, Y.; Liu, J. Large-scale adversarial training for vision-and-language representation learning. Adv. Neural Inf. Process. Syst. 2020, 33, 6616–6628. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European conference on computer vision (ECCV), München, Germany, 8–14 September 2018; pp. 305–321. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Lei, J.; Li, L.; Zhou, L.; Gan, Z.; Berg, T.L.; Bansal, M.; Liu, J. Less is more: Clipbert for video-and-language learning via sparse sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7331–7341. [Google Scholar]
- Sun, C.; Myers, A.; Vondrick, C.; Murphy, K.; Schmid, C. Videobert: A joint model for video and language representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7464–7473. [Google Scholar]
- Tan, H.; Bansal, M. Vokenization: Improving language understanding with contextualized, visual-grounded supervision. arXiv 2020, arXiv:2010.06775. [Google Scholar]
- Ma, M.; Ren, J.; Zhao, L.; Tulyakov, S.; Wu, C.; Peng, X. Smil: Multimodal learning with severely missing modality. arXiv 2021, arXiv:2103.05677. [Google Scholar]
- Huang, Y.; Wang, W.; Wang, L. Unconstrained multimodal multi-label learning. IEEE Trans. Multimed. 2015, 17, 1923–1935. [Google Scholar] [CrossRef]
- Ding, Z.; Ming, S.; Fu, Y. Latent low-rank transfer subspace learning for missing modality recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Quebec City, QC, Canada, 27 July 2014; Volume 28. [Google Scholar]
- Ding, Z.; Shao, M.; Fu, Y. Missing modality transfer learning via latent low-rank constraint. IEEE Trans. Image Process. 2015, 24, 4322–4334. [Google Scholar] [CrossRef]
- Soleymani, M.; Garcia, D.; Jou, B.; Schuller, B.; Chang, S.F.; Pantic, M. A survey of multimodal sentiment analysis. Image Vis. Comput. 2017, 65, 3–14. [Google Scholar] [CrossRef]
- Pham, H.; Liang, P.P.; Manzini, T.; Morency, L.P.; Póczos, B. Found in translation: Learning robust joint representations by cyclic translations between modalities. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 2019; Volume 33, pp. 6892–6899. [Google Scholar]
- Moon, S.; Neves, L.; Carvalho, V. Multimodal named entity disambiguation for noisy social media posts. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2000–2008. [Google Scholar]
- Gupta, T.; Schwing, A.; Hoiem, D. Vico: Word embeddings from visual co-occurrences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7425–7434. [Google Scholar]
- Lee, J.; Chung, S.W.; Kim, S.; Kang, H.G.; Sohn, K. Looking into your speech: Learning cross-modal affinity for audio-visual speech separation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 10–17 October 2021; pp. 1336–1345. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Rohrbach, A.; Rohrbach, M.; Tandon, N.; Schiele, B. A dataset for movie description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3202–3212. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in homes: Crowdsourcing data collection for activity understanding. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 510–526. [Google Scholar]
- Sigurdsson, G.A.; Gupta, A.; Schmid, C.; Farhadi, A.; Alahari, K. Charades-ego: A large-scale dataset of paired third and first person videos. arXiv 2018, arXiv:1804.09626. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 652–663. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Yuan, Y.; Wu, Y.; Cohen, W.W.; Salakhutdinov, R.R. Review networks for caption generation. Adv. Neural Inf. Process. Syst. 2016, 29, 2369–2377. [Google Scholar]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Johnson, J.; Karpathy, A.; Fei-Fei, L. Densecap: Fully convolutional localization networks for dense captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4565–4574. [Google Scholar]
- Xu, H.; Li, B.; Ramanishka, V.; Sigal, L.; Saenko, K. Joint event detection and description in continuous video streams. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 396–405. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Laina, I.; Rupprecht, C.; Navab, N. Towards unsupervised image captioning with shared multimodal embeddings. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7414–7424. [Google Scholar]
- Rohrbach, A.; Rohrbach, M.; Tang, S.; Joon Oh, S.; Schiele, B. Generating descriptions with grounded and co-referenced people. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4979–4989. [Google Scholar]
- Wang, X.; Chen, W.; Wu, J.; Wang, Y.F.; Wang, W.Y. Video captioning via hierarchical reinforcement learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4213–4222. [Google Scholar]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Neural baby talk. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7219–7228. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Zhang, P.; Goyal, Y.; Summers-Stay, D.; Batra, D.; Parikh, D. Yin and yang: Balancing and answering binary visual questions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5014–5022. [Google Scholar]
- Yuan, X.; Côté, M.A.; Fu, J.; Lin, Z.; Pal, C.; Bengio, Y.; Trischler, A. Interactive language learning by question answering. arXiv 2019, arXiv:1908.10909. [Google Scholar]
- Fader, A.; Zettlemoyer, L.; Etzioni, O. Paraphrase-driven learning for open question answering. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Sofia, Bulgaria, 4–9 August 2013; pp. 1608–1618. [Google Scholar]
- Weston, J.; Bordes, A.; Chopra, S.; Rush, A.M.; Van Merriënboer, B.; Joulin, A.; Mikolov, T. Towards ai-complete question answering: A set of prerequisite toy tasks. arXiv 2015, arXiv:1502.05698. [Google Scholar]
- Kulkarni, G.; Premraj, V.; Ordonez, V.; Dhar, S.; Li, S.; Choi, Y.; Berg, A.C.; Berg, T.L. Babytalk: Understanding and generating simple image descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2891–2903. [Google Scholar] [CrossRef] [Green Version]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6904–6913. [Google Scholar]
- Tapaswi, M.; Zhu, Y.; Stiefelhagen, R.; Torralba, A.; Urtasun, R.; Fidler, S. Movieqa: Understanding stories in movies through question-answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4631–4640. [Google Scholar]
- Johnson, J.; Hariharan, B.; Van Der Maaten, L.; Fei-Fei, L.; Lawrence Zitnick, C.; Girshick, R. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2901–2910. [Google Scholar]
- Kembhavi, A.; Seo, M.; Schwenk, D.; Choi, J.; Farhadi, A.; Hajishirzi, H. Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4999–5007. [Google Scholar]
- Yagcioglu, S.; Erdem, A.; Erdem, E.; Ikizler-Cinbis, N. RecipeQA: A challenge dataset for multimodal comprehension of cooking recipes. arXiv 2018, arXiv:1809.00812. [Google Scholar]
- Zadeh, A.; Chan, M.; Liang, P.P.; Tong, E.; Morency, L.P. Social-iq: A question answering benchmark for artificial social intelligence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8807–8817. [Google Scholar]
- Hudson, D.A.; Manning, C.D. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6700–6709. [Google Scholar]
- Talmor, A.; Yoran, O.; Catav, A.; Lahav, D.; Wang, Y.; Asai, A.; Ilharco, G.; Hajishirzi, H.; Berant, J. Multimodalqa: Complex question answering over text, tables and images. arXiv 2021, arXiv:2104.06039. [Google Scholar]
- Xu, L.; Huang, H.; Liu, J. Sutd-trafficqa: A question answering benchmark and an efficient network for video reasoning over traffic events. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9878–9888. [Google Scholar]
- Wu, Q.; Teney, D.; Wang, P.; Shen, C.; Dick, A.; van den Hengel, A. Visual question answering: A survey of methods and datasets. Comput. Vis. Image Underst. 2017, 163, 21–40. [Google Scholar] [CrossRef] [Green Version]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal compact bilinear pooling for visual question answering and visual grounding. arXiv 2016, arXiv:1606.01847. [Google Scholar]
- Yi, K.; Wu, J.; Gan, C.; Torralba, A.; Kohli, P.; Tenenbaum, J. Neural-symbolic vqa: Disentangling reasoning from vision and language understanding. Adv. Neural Inf. Process. Syst. 2018, 31, 1–12. [Google Scholar]
- Vedantam, R.; Desai, K.; Lee, S.; Rohrbach, M.; Batra, D.; Parikh, D. Probabilistic neural symbolic models for interpretable visual question answering. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6428–6437. [Google Scholar]
- Cadene, R.; Dancette, C.; Cord, M.; Parikh, D. Rubi: Reducing unimodal biases for visual question answering. Adv. Neural Inf. Process. Syst. 2019, 32, 1–12. [Google Scholar]
- Fan, H.; Zhou, J. Stacked latent attention for multimodal reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1072–1080. [Google Scholar]
- Agrawal, A.; Batra, D.; Parikh, D.; Kembhavi, A. Don’t just assume; look and answer: Overcoming priors for visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4971–4980. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Zhang, Y.; Hare, J.; Prügel-Bennett, A. Learning to count objects in natural images for visual question answering. arXiv 2018, arXiv:1802.05766. [Google Scholar]
- Alberti, C.; Ling, J.; Collins, M.; Reitter, D. Fusion of detected objects in text for visual question answering. arXiv 2019, arXiv:1908.05054. [Google Scholar]
- Hu, R.; Singh, A.; Darrell, T.; Rohrbach, M. Iterative answer prediction with pointer-augmented multimodal transformers for textvqa. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9992–10002. [Google Scholar]
- Andreas, J.; Rohrbach, M.; Darrell, T.; Klein, D. Neural module networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 39–48. [Google Scholar]
- Hu, R.; Andreas, J.; Rohrbach, M.; Darrell, T.; Saenko, K. Learning to reason: End-to-end module networks for visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 804–813. [Google Scholar]
- Lei, J.; Yu, L.; Bansal, M.; Berg, T.L. Tvqa: Localized, compositional video question answering. arXiv 2018, arXiv:1809.01696. [Google Scholar]
- Cadene, R.; Ben-Younes, H.; Cord, M.; Thome, N. Murel: Multimodal relational reasoning for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1989–1998. [Google Scholar]
- Wu, Q.; Wang, P.; Shen, C.; Dick, A.; Van Den Hengel, A. Ask me anything: Free-form visual question answering based on knowledge from external sources. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4622–4630. [Google Scholar]
- Marino, K.; Rastegari, M.; Farhadi, A.; Mottaghi, R. Ok-vqa: A visual question answering benchmark requiring external knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3195–3204. [Google Scholar]
- Caglayan, O.; Aransa, W.; Wang, Y.; Masana, M.; García-Martínez, M.; Bougares, F.; Barrault, L.; Van de Weijer, J. Does multimodality help human and machine for translation and image captioning? arXiv 2016, arXiv:1605.09186. [Google Scholar]
- Elliott, D.; Frank, S.; Sima’an, K.; Specia, L. Multi30k: Multilingual english-german image descriptions. arXiv 2016, arXiv:1605.00459. [Google Scholar]
- Hewitt, J.; Ippolito, D.; Callahan, B.; Kriz, R.; Wijaya, D.T.; Callison-Burch, C. Learning translations via images with a massively multilingual image dataset. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2566–2576. [Google Scholar]
- Wang, X.; Wu, J.; Chen, J.; Li, L.; Wang, Y.F.; Wang, W.Y. Vatex: A large-scale, high-quality multilingual dataset for video-and-language research. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4581–4591. [Google Scholar]
- Hitschler, J.; Schamoni, S.; Riezler, S. Multimodal pivots for image caption translation. arXiv 2016, arXiv:1601.03916. [Google Scholar]
- Calixto, I.; Liu, Q.; Campbell, N. Incorporating global visual features into attention-based neural machine translation. arXiv 2017, arXiv:1701.06521. [Google Scholar]
- Delbrouck, J.B.; Dupont, S. An empirical study on the effectiveness of images in multimodal neural machine translation. arXiv 2017, arXiv:1707.00995. [Google Scholar]
- Calixto, I.; Liu, Q.; Campbell, N. Doubly-attentive decoder for multi-modal neural machine translation. arXiv 2017, arXiv:1702.01287. [Google Scholar]
- Zhou, M.; Cheng, R.; Lee, Y.J.; Yu, Z. A visual attention grounding neural model for multimodal machine translation. arXiv 2018, arXiv:1808.08266. [Google Scholar]
- Yao, S.; Wan, X. Multimodal transformer for multimodal machine translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Seattle, DC, USA, 5–10 July 2020; pp. 4346–4350. [Google Scholar]
- Lee, J.; Cho, K.; Weston, J.; Kiela, D. Emergent translation in multi-agent communication. arXiv 2017, arXiv:1710.06922. [Google Scholar]
- Chen, Y.; Liu, Y.; Li, V. Zero-resource neural machine translation with multi-agent communication game. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Elliott, D. Adversarial evaluation of multimodal machine translation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2018; pp. 2974–2978. [Google Scholar]
- Caglayan, O.; Madhyastha, P.; Specia, L.; Barrault, L. Probing the need for visual context in multimodal machine translation. arXiv 2019, arXiv:1903.08678. [Google Scholar]
- Ive, J.; Madhyastha, P.; Specia, L. Distilling translations with visual awareness. arXiv 2019, arXiv:1906.07701. [Google Scholar]
- Yang, P.; Chen, B.; Zhang, P.; Sun, X. Visual agreement regularized training for multi-modal machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7 February 2020; Volume 34, pp. 9418–9425. [Google Scholar]
- Zhang, Z.; Chen, K.; Wang, R.; Utiyama, M.; Sumita, E.; Li, Z.; Zhao, H. Neural machine translation with universal visual representation. In Proceedings of the International Conference on Learning Representations, Formerly Addis Ababa, Ethiopia, Virtual, 6–9 May 2019. [Google Scholar]
- Calixto, I.; Rios, M.; Aziz, W. Latent variable model for multi-modal translation. arXiv 2018, arXiv:1811.00357. [Google Scholar]
- Huang, P.Y.; Hu, J.; Chang, X.; Hauptmann, A. Unsupervised multimodal neural machine translation with pseudo visual pivoting. arXiv 2020, arXiv:2005.03119. [Google Scholar]
- Rui, Y.; Huang, T.S.; Ortega, M.; Mehrotra, S. Relevance feedback: A power tool for interactive content-based image retrieval. IEEE Trans. Circuits Syst. Video Technol. 1998, 8, 644–655. [Google Scholar]
- Kiros, R.; Salakhutdinov, R.; Zemel, R.S. Unifying visual-semantic embeddings with multimodal neural language models. arXiv 2014, arXiv:1411.2539. [Google Scholar]
- Vendrov, I.; Kiros, R.; Fidler, S.; Urtasun, R. Order-embeddings of images and language. arXiv 2015, arXiv:1511.06361. [Google Scholar]
- Wang, L.; Li, Y.; Lazebnik, S. Learning deep structure-preserving image-text embeddings. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5005–5013. [Google Scholar]
- Klein, B.; Lev, G.; Sadeh, G.; Wolf, L. Associating neural word embeddings with deep image representations using fisher vectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4437–4446. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 11. [Google Scholar]
- Huang, H.; Yu, P.S.; Wang, C. An introduction to image synthesis with generative adversarial nets. arXiv 2018, arXiv:1803.04469. [Google Scholar]
- Agnese, J.; Herrera, J.; Tao, H.; Zhu, X. A survey and taxonomy of adversarial neural networks for text-to-image synthesis. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1345. [Google Scholar] [CrossRef] [Green Version]
- Frolov, S.; Hinz, T.; Raue, F.; Hees, J.; Dengel, A. Adversarial text-to-image synthesis: A review. Neural Netw. 2021, 144, 187–209. [Google Scholar] [CrossRef]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1060–1069. [Google Scholar]
- Zhu, B.; Ngo, C.W. CookGAN: Causality based text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5519–5527. [Google Scholar]
- Li, B.; Qi, X.; Lukasiewicz, T.; Torr, P. Controllable text-to-image generation. arXiv 2019, arXiv:1909.07083. [Google Scholar]
- Yin, G.; Liu, B.; Sheng, L.; Yu, N.; Wang, X.; Shao, J. Semantics disentangling for text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2327–2336. [Google Scholar]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. Dm-gan: Dynamic memory generative adversarial networks for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5802–5810. [Google Scholar]
- Qiao, T.; Zhang, J.; Xu, D.; Tao, D. Mirrorgan: Learning text-to-image generation by redescription. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1505–1514. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1316–1324. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1947–1962. [Google Scholar] [CrossRef] [Green Version]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Chen, X.; Fang, H.; Lin, T.Y.; Vedantam, R.; Gupta, S.; Dollár, P.; Zitnick, C.L. Microsoft coco captions: Data collection and evaluation server. arXiv 2015, arXiv:1504.00325. [Google Scholar]
- Pont-Tuset, J.; Uijlings, J.; Changpinyo, S.; Soricut, R.; Ferrari, V. Connecting vision and language with localized narratives. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 647–664. [Google Scholar]
- Sidorov, O.; Hu, R.; Rohrbach, M.; Singh, A. Textcaps: A dataset for image captioning with reading comprehension. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 742–758. [Google Scholar]
- Gurari, D.; Li, Q.; Stangl, A.J.; Guo, A.; Lin, C.; Grauman, K.; Luo, J.; Bigham, J.P. Vizwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3608–3617. [Google Scholar]
- Agrawal, H.; Desai, K.; Wang, Y.; Chen, X.; Jain, R.; Johnson, M.; Batra, D.; Parikh, D.; Lee, S.; Anderson, P. Nocaps: Novel object captioning at scale. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October 2019–2 November 2019; pp. 8948–8957. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Spice: Semantic propositional image caption evaluation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 382–398. [Google Scholar]
- Zhou, L.; Palangi, H.; Zhang, L.; Hu, H.; Corso, J.; Gao, J. Unified vision-language pre-training for image captioning and vqa. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7 February 2020; Volume 34, pp. 13041–13049. [Google Scholar]
- Wang, P.; Yang, A.; Men, R.; Lin, J.; Bai, S.; Li, Z.; Ma, J.; Zhou, C.; Zhou, J.; Yang, H. Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. arXiv 2022, arXiv:2202.03052. [Google Scholar]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F.; et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 121–137. [Google Scholar]
- Wang, Z.; Yu, J.; Yu, A.W.; Dai, Z.; Tsvetkov, Y.; Cao, Y. Simvlm: Simple visual language model pretraining with weak supervision. arXiv 2021, arXiv:2108.10904. [Google Scholar]
- Nam, H.; Ha, J.W.; Kim, J. Dual attention networks for multimodal reasoning and matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 299–307. [Google Scholar]
- Kazemi, V.; Elqursh, A. Show, ask, attend, and answer: A strong baseline for visual question answering. arXiv 2017, arXiv:1704.03162. [Google Scholar]
- Elliott, D.; Kádár, A. Imagination improves multimodal translation. arXiv 2017, arXiv:1705.04350. [Google Scholar]
- Lin, H.; Meng, F.; Su, J.; Yin, Y.; Yang, Z.; Ge, Y.; Zhou, J.; Luo, J. Dynamic context-guided capsule network for multimodal machine translation. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1320–1329. [Google Scholar]
- Lu, X.; Zhao, T.; Lee, K. VisualSparta: An Embarrassingly Simple Approach to Large-scale Text-to-Image Search with Weighted Bag-of-words. arXiv 2021, arXiv:2101.00265. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-Ucsd Birds-200-2011 Dataset. 2011. Available online: https://authors.library.caltech.edu/27452/ (accessed on 1 June 2022).
- Nilsback, M.E.; Zisserman, A. Automated flower classification over a large number of classes. In Proceedings of the 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, Bhubaneswar, India, 16–19 December 2008; pp. 722–729. [Google Scholar]
- Xia, W.; Yang, Y.; Xue, J.H.; Wu, B. Tedigan: Text-guided diverse face image generation and manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2256–2265. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 1–12. [Google Scholar]
- Zhou, Y.; Zhang, R.; Chen, C.; Li, C.; Tensmeyer, C.; Yu, T.; Gu, J.; Xu, J.; Sun, T. LAFITE: Towards Language-Free Training for Text-to-Image Generation. arXiv 2021, arXiv:2111.13792. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-memory transformer for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10578–10587. [Google Scholar]
- Hu, X.; Gan, Z.; Wang, J.; Yang, Z.; Liu, Z.; Lu, Y.; Wang, L. Scaling up vision-language pre-training for image captioning. arXiv 2021, arXiv:2111.12233. [Google Scholar]
- Zhu, Q.; Gao, C.; Wang, P.; Wu, Q. Simple is not easy: A simple strong baseline for textvqa and textcaps. arXiv 2020, arXiv:2012.05153. [Google Scholar]
- Yan, K.; Ji, L.; Luo, H.; Zhou, M.; Duan, N.; Ma, S. Control Image Captioning Spatially and Temporally. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Bangkok, Thailand, 1–6 August 2021; pp. 2014–2025. [Google Scholar]
- Hsu, T.Y.; Giles, C.L.; Huang, T.H. SciCap: Generating Captions for Scientific Figures. arXiv 2021, arXiv:2110.11624. [Google Scholar]
- Wang, W.; Bao, H.; Dong, L.; Wei, F. VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts. arXiv 2021, arXiv:2111.02358. [Google Scholar]
- Chen, L.; Yan, X.; Xiao, J.; Zhang, H.; Pu, S.; Zhuang, Y. Counterfactual samples synthesizing for robust visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10800–10809. [Google Scholar]
- Dancette, C.; Cadene, R.; Teney, D.; Cord, M. Beyond question-based biases: Assessing multimodal shortcut learning in visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1574–1583. [Google Scholar]
- Zellers, R.; Bisk, Y.; Farhadi, A.; Choi, Y. From recognition to cognition: Visual commonsense reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6720–6731. [Google Scholar]
- Hudson, D.; Manning, C.D. Learning by abstraction: The neural state machine. Adv. Neural Inf. Process. Syst. 2019, 32, 1–19. [Google Scholar]
- Lu, P.; Qiu, L.; Chen, J.; Xia, T.; Zhao, Y.; Zhang, W.; Yu, Z.; Liang, X.; Zhu, S.C. IconQA: A New Benchmark for Abstract Diagram Understanding and Visual Language Reasoning. arXiv 2021, arXiv:2110.13214. [Google Scholar]
- Xu, J.; Mei, T.; Yao, T.; Rui, Y. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5288–5296. [Google Scholar]
- Yang, A.; Miech, A.; Sivic, J.; Laptev, I.; Schmid, C. Just ask: Learning to answer questions from millions of narrated videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1686–1697. [Google Scholar]
- Sulubacak, U.; Caglayan, O.; Grönroos, S.A.; Rouhe, A.; Elliott, D.; Specia, L.; Tiedemann, J. Multimodal machine translation through visuals and speech. Mach. Transl. 2020, 34, 97–147. [Google Scholar] [CrossRef]
- Olóndriz, D.A.; Puigdevall, P.P.; Palau, A.S. FooDI-ML: A large multi-language dataset of food, drinks and groceries images and descriptions. arXiv 2021, arXiv:2110.02035. [Google Scholar]
- Srinivasan, K.; Raman, K.; Chen, J.; Bendersky, M.; Najork, M. Wit: Wikipedia-based image text dataset for multimodal multilingual machine learning. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; pp. 2443–2449. [Google Scholar]
- Wu, H.; Gao, Y.; Guo, X.; Al-Halah, Z.; Rennie, S.; Grauman, K.; Feris, R. Fashion iq: A new dataset towards retrieving images by natural language feedback. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11307–11317. [Google Scholar]
- Shin, M.; Cho, Y.; Ko, B.; Gu, G. RTIC: Residual Learning for Text and Image Composition using Graph Convolutional Network. arXiv 2021, arXiv:2104.03015. [Google Scholar]
- Guo, J.; Lu, S.; Cai, H.; Zhang, W.; Yu, Y.; Wang, J. Long text generation via adversarial training with leaked information. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Lin, K.; Li, D.; He, X.; Zhang, Z.; Sun, M.T. Adversarial ranking for language generation. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Shi, B.; Ji, L.; Liang, Y.; Duan, N.; Chen, P.; Niu, Z.; Zhou, M. Dense procedure captioning in narrated instructional videos. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 6382–6391. [Google Scholar]
- Peng, X.; Wei, Y.; Deng, A.; Wang, D.; Hu, D. Balanced Multimodal Learning via On-the-fly Gradient Modulation. arXiv 2022, arXiv:2203.15332. [Google Scholar]
- Yu, W.; Liang, J.; Ji, L.; Li, L.; Fang, Y.; Xiao, N.; Duan, N. Hybrid reasoning network for video-based commonsense captioning. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 5213–5221. [Google Scholar]
- Bin, Y.; Shang, X.; Peng, B.; Ding, Y.; Chua, T.S. Multi-Perspective Video Captioning. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 5110–5118. [Google Scholar]
- Wang, J.; Xu, W.; Wang, Q.; Chan, A.B. Group-based distinctive image captioning with memory attention. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 5020–5028. [Google Scholar]
- Huang, Y.; Liu, B.; Fu, J.; Lu, Y. A Picture is Worth a Thousand Words: A Unified System for Diverse Captions and Rich Images Generation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 2792–2794. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chai, W.; Wang, G. Deep Vision Multimodal Learning: Methodology, Benchmark, and Trend. Appl. Sci. 2022, 12, 6588. https://doi.org/10.3390/app12136588
Chai W, Wang G. Deep Vision Multimodal Learning: Methodology, Benchmark, and Trend. Applied Sciences. 2022; 12(13):6588. https://doi.org/10.3390/app12136588
Chicago/Turabian StyleChai, Wenhao, and Gaoang Wang. 2022. "Deep Vision Multimodal Learning: Methodology, Benchmark, and Trend" Applied Sciences 12, no. 13: 6588. https://doi.org/10.3390/app12136588