
BERTOEIC: Solving TOEIC Problems Using Simple and Efficient Data Augmentation Techniques with Pretrained Transformer Encoders

 , , ,
, , ,
Abstract
:1. Introduction
- Through the POS-tagging based data augmentation methodology, when solving semantic problems comprising options with similar parts-of-speech but with words that have different meanings, the intention of the problem can be better understood by comparing the options focusing on the meanings;
- Through the lemmatizing-based data augmentation methodology, when solving grammar problems where various forms of words with a similar meaning are presented, the problem can be better understood by comparing the options focusing on the grammatical relationship;
- The effectiveness of the methodologies proposed in this study was verified through experiments for each methodology and experiments according to the amount of data, and we confirmed that the data scarcity problem could be solved through this methodology.
2. Related Work
3. Proposed Method
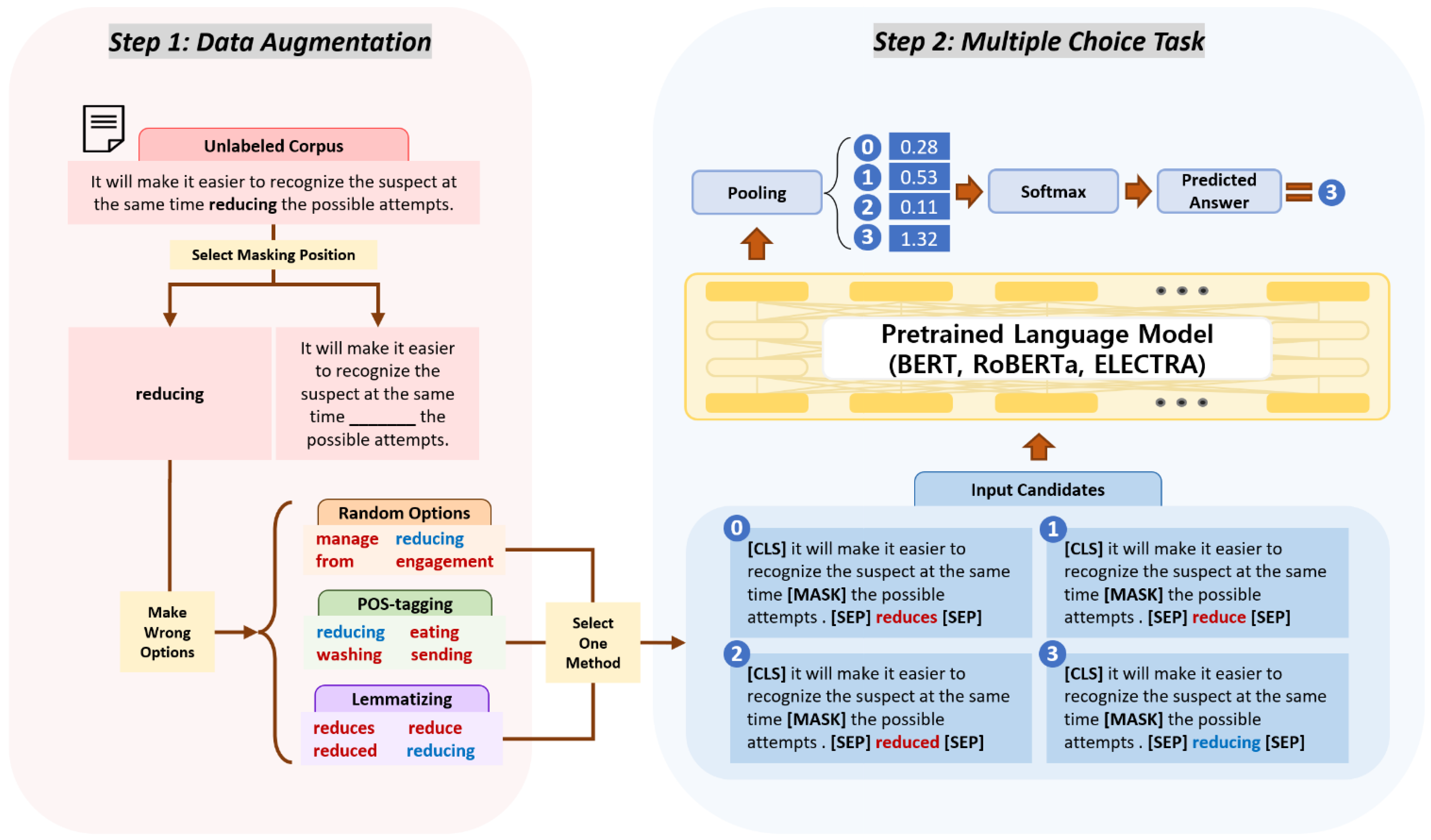
3.1. Simple and Efficient Data Augmentation
3.1.1. Random and Brute Data Augmentation
3.1.2. POS-Tagging Based Data Augmentation
3.1.3. Lemmatizing Based Data Augmentation
3.2. Model
4. Experiments
4.1. Dataset Details
4.2. Implementation Details
- BERT-large was trained using bert-large-uncased. BERT-large uses 24 layers with a hidden size of 1024 and has approximately 336M trainable parameters. In addition, the learning rate was set to 3 × 10;
- RoBERTa-large was trained using roberta-large. RoBERTa-large uses 24 layers with a hidden size of 1024 and has approximately 355M trainable parameters. Further, the learning rate was set to 1 × 10;
- ELECTRA-large was learned using google/electra-large-discriminator. ELECTRA-large uses 24 layers with a hidden size of 1024 and has approximately 335M trainable parameters. In addition, the learning rate was set to 1 × 10.
4.3. Evaluation Details
4.4. Main Results
4.5. Performance Comparison Experiment According to the Amount of Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Tag | Description | Example |
|---|---|---|
| $ | dollar | $ |
| “ | opening quotation mark | ‘ “ |
| ” | closing quotation mark | ’ ” |
| CC | conjunction, coordinating | and |
| CD | numeral, cardinal | 1987, one-tenth |
| DT | determiner | the |
| EX | existential there | there |
| FW | foreign word | ich |
| IN | preposition or conjunction, subordinating | among, into |
| JJ | adjective or numeral, ordinal | cheap |
| JJR | adjective, comparative | cheaper |
| JJS | adjective, superlative | cheapest |
| LS | list item marker | SP-44001 |
| MD | modal auxiliary | could, will |
| NN | noun, common, singular or mass | table |
| NNP | noun, proper, singular | Venneboerger |
| NNPS | noun, proper, plural | Americans |
| NNS | noun, common, plural | tables |
| PDT | pre-determiner | both |
| POS | genitive marker | ’s |
| PRP | pronoun, personal | me, myself, themselves |
| PRP$ | pronoun, possessive | my, their |
| RB | adverb | fast |
| RBR | adverb, comparative | faster |
| RBS | adverb, superlative | fastest |
| RP | particle | up |
| SYM | symbol | =, * |
| TO | “to” as preposition or infinitive marker | to |
| UH | interjection | Gosh |
| VB | verb, base form | ask, avoid |
| VBD | verb, past tense | dipped, exacted |
| VBG | verb, present participle or gerund | telegraphing, focusing |
| VBN | verb, past participle | multihulled, experimented |
| VBP | verb, present tense, not 3rd person singular | predominate, wrap |
| VBZ | verb, present tense, 3rd person singular | reconstructs, marks |
| WDT | WH-determiner | whichever |
| WP | WH-pronoun | who, whom, whosoever |
| WP$ | WH-pronoun, possessive | whose |
| WRB | Wh-adverb | whenever |
References
- Taylor, W.L. “Cloze procedure”: A new tool for measuring readability. J. Q. 1953, 30, 415–433. [Google Scholar] [CrossRef]
- Fotos, S.S. The cloze test as an integrative measure of EFL proficiency: A substitute for essays on college entrance examinations? Lang. Learn. 1991, 41, 313–336. [Google Scholar] [CrossRef]
- Jonz, J. Cloze item types and second language comprehension. Lang. Test. 1991, 8, 1–22. [Google Scholar] [CrossRef]
- Tremblay, A. Proficiency assessment standards in second language acquisition research:“Clozing” the gap. Stud. Second. Lang. Acquis. 2011, 33, 339–372. [Google Scholar] [CrossRef]
- Hu, Z.; Chanumolu, R.; Lin, X.; Ayaz, N.; Chi, V. Evaluating NLP Systems On a Novel Cloze Task: Judging the Plausibility of Possible Fillers in Instructional Texts. arXiv 2021, arXiv:2112.01867. [Google Scholar]
- Loper, E.; Bird, S. Nltk: The natural language toolkit. arXiv 2002, arXiv:cs/0205028. [Google Scholar]
- Bilal, M.; Almazroi, A.A. Effectiveness of Fine-Tuned BERT Model in Classification of Helpful and Unhelpful Online Customer Reviews. Electron. Commer. Res. 2022, 1–21. [Google Scholar] [CrossRef]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. Adv. Neural Inf. Process. Syst. 2015, 28, 1693–1701. [Google Scholar]
- Hill, F.; Bordes, A.; Chopra, S.; Weston, J. The goldilocks principle: Reading children’s books with explicit memory representations. arXiv 2015, arXiv:1511.02301. [Google Scholar]
- Bajgar, O.; Kadlec, R.; Kleindienst, J. Embracing data abundance: Booktest dataset for reading comprehension. arXiv 2016, arXiv:1610.00956. [Google Scholar]
- Onishi, T.; Wang, H.; Bansal, M.; Gimpel, K.; McAllester, D. Who did what: A large-scale person-centered cloze dataset. arXiv 2016, arXiv:1608.05457. [Google Scholar]
- Lu, S.; Guo, D.; Ren, S.; Huang, J.; Svyatkovskiy, A.; Blanco, A.; Clement, C.; Drain, D.; Jiang, D.; Tang, D.; et al. Codexglue: A machine learning benchmark dataset for code understanding and generation. arXiv 2021, arXiv:2102.04664. [Google Scholar]
- Lai, G.; Xie, Q.; Liu, H.; Yang, Y.; Hovy, E. Race: Large-scale reading comprehension dataset from examinations. arXiv 2017, arXiv:1704.04683. [Google Scholar]
- Premtoon, V.; Koppel, J.; Solar-Lezama, A. Semantic code search via equational reasoning. In Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation, London, UK, 15–20 June 2020; pp. 1066–1082. [Google Scholar]
- Wang, W.; Zhang, Y.; Zeng, Z.; Xu, G. Trans^3: A transformer-based framework for unifying code summarization and code search. arXiv 2020, arXiv:2003.03238. [Google Scholar]
- Svyatkovskiy, A.; Deng, S.K.; Fu, S.; Sundaresan, N. Intellicode compose: Code generation using transformer. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event, 8–13 November 2020; pp. 1433–1443. [Google Scholar]
- Svyatkovskiy, A.; Zhao, Y.; Fu, S.; Sundaresan, N. Pythia: AI-assisted code completion system. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2727–2735. [Google Scholar]
- Moon, H.; Park, C.; Eo, S.; Seo, J.; Lee, S.; Lim, H. A Self-Supervised Automatic Post-Editing Data Generation Tool. arXiv 2021, arXiv:2111.12284. [Google Scholar]
- Moon, H.; Park, C.; Seo, J.; Eo, S.; Lim, H. An Automatic Post Editing With Efficient and Simple Data Generation Method. IEEE Access 2022, 10, 21032–21040. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Xie, Q.; Lai, G.; Dai, Z.; Hovy, E. Large-scale cloze test dataset created by teachers. arXiv 2017, arXiv:1711.03225. [Google Scholar]
- Zellers, R.; Bisk, Y.; Schwartz, R.; Choi, Y. Swag: A large-scale adversarial dataset for grounded commonsense inference. arXiv 2018, arXiv:1808.05326. [Google Scholar]
- Sakaguchi, K.; Le Bras, R.; Bhagavatula, C.; Choi, Y. Winogrande: An adversarial winograd schema challenge at scale. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8732–8740. [Google Scholar]
- Bisk, Y.; Zellers, R.; Gao, J.; Choi, Y. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7432–7439. [Google Scholar]
- Park, C.; Lim, H. A study on the performance improvement of machine translation using public korean-english parallel corpus. J. Digit. Converg. 2020, 18, 271–277. [Google Scholar]
- Park, C.; Shim, M.; Eo, S.; Lee, S.; Seo, J.; Moon, H.; Lim, H. Empirical Analysis of Korean Public AI Hub Parallel Corpora and in-depth Analysis using LIWC. arXiv 2021, arXiv:2110.15023. [Google Scholar]
- Park, C.; Seo, J.; Lee, S.; Lee, C.; Moon, H.; Eo, S.; Lim, H.S. BTS: Back TranScription for speech-to-text post-processor using text-to-speech-to-text. In Proceedings of the 8th Workshop on Asian Translation (WAT2021), Bangkok, Thailand, 6 August 2021; pp. 106–116. [Google Scholar]
- Park, C.; Go, W.Y.; Eo, S.; Moon, H.; Lee, S.; Lim, H. Mimicking Infants’ Bilingual Language Acquisition for Domain Specialized Neural Machine Translation. IEEE Access 2022, 10, 38684–38693. [Google Scholar] [CrossRef]



| Model | BERT-Base-Uncased | BERT-Base-Cased | BERT-Large-Uncased | BERT-Large-Cased |
| Accuracy | 73.46% | 76.38% | 75.29% | 72.84% |
| Type | Questions | Options |
|---|---|---|
| Semantic | Even experienced clerks are encouraged to attend training ______ to keep them updated on new ideas in the world of banking. | (A) materials (B) sessions (C) experiences (D) positions |
| Grammar | The assets of Marble Faun Publishing Company ______ last quarter when one of their main local distributors went out of business. | (A) suffer (B) suffers (C) suffering (D) suffered |
| POS-Tagging Based Data | Lemmatizing Based Data | ||
|---|---|---|---|
| Question | Options | Question | Options |
| I think the ______ discovery is that of fire. | (A) sweetest (B) driest (C) youngest (D) greatest | I was told that the initial ______ could be possible before going to the processing plant. | (A) purchase (B) purchases (C) purchasing (D) purchased |
| A litigation agent in a criminal case shall faithfully perform the following ______ until the close of the relevant case. | (A) beanies (B) observatories (C) laundries (D) duties | Weighing only a third of the existing products the flat lash is so light that users might forget that they are ______ artificial eyelashes. | (A) wears (B) wore (C) wear (D) wearing |
| So A is an eco-friendly product, and it’s a highly portable container which can be used by ______ it. | (A) folding (B) windsurfing (C) caching (D) downsizing | It will make it easier to recognize the suspect at the same time ______ the possible attempts. | (A) reduces (B) reduce (C) reduced (D) reducing |
| Train | Valid | Test | |
|---|---|---|---|
| # questions | 2899 | 363 | 363 |
| Min length | 5 | 12 | 10 |
| Max length | 57 | 34 | 50 |
| Avg length | 20.45 | 22.25 | 21.28 |
| Data | BERT | RoBERTa | ELECTRA | |||
|---|---|---|---|---|---|---|
| Only Aug | With FT | Only Aug | With FT | Only Aug | With FT | |
| Kaggle TOEIC | 86.22% | 96.14% | 90.63% | |||
| Random & Brute | 84.02% | 92.01% | 93.11% | 96.41% | 94.21% | 97.24% |
| POS-tagging | 90.08% | 94.21% | 95.59% | 96.96% | 96.14% | 97.52% |
| Lemmatizing | 90.63% | 94.21% | 95.04% | 97.24% | 96.96% | 98.07% |
| Mixed | 91.46% | 95.04% | 96.41% | 97.52% | 97.24% | 98.07% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Moon, H.; Park, C.; Seo, J.; Eo, S.; Lim, H. BERTOEIC: Solving TOEIC Problems Using Simple and Efficient Data Augmentation Techniques with Pretrained Transformer Encoders. Appl. Sci. 2022, 12, 6686. https://doi.org/10.3390/app12136686
Lee J, Moon H, Park C, Seo J, Eo S, Lim H. BERTOEIC: Solving TOEIC Problems Using Simple and Efficient Data Augmentation Techniques with Pretrained Transformer Encoders. Applied Sciences. 2022; 12(13):6686. https://doi.org/10.3390/app12136686
Chicago/Turabian StyleLee, Jeongwoo, Hyeonseok Moon, Chanjun Park, Jaehyung Seo, Sugyeong Eo, and Heuiseok Lim. 2022. "BERTOEIC: Solving TOEIC Problems Using Simple and Efficient Data Augmentation Techniques with Pretrained Transformer Encoders" Applied Sciences 12, no. 13: 6686. https://doi.org/10.3390/app12136686