
An End-to-End Classifier Based on CNN for In-Air Handwritten-Chinese-Character Recognition


Abstract
:1. Introduction
2. Related Works
3. Proposed Method
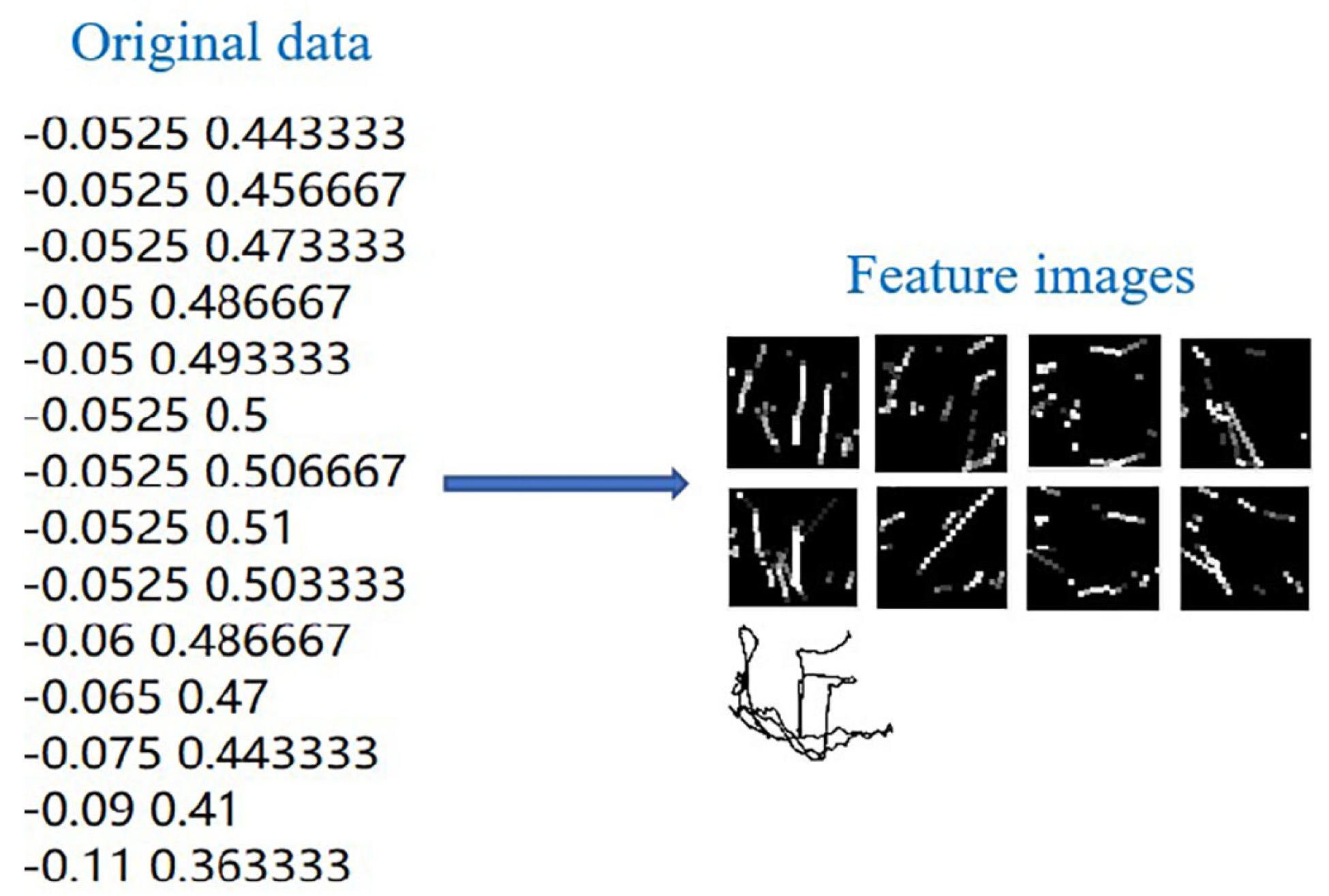
3.1. Preprocessing
3.1.1. Remove Redundant Points
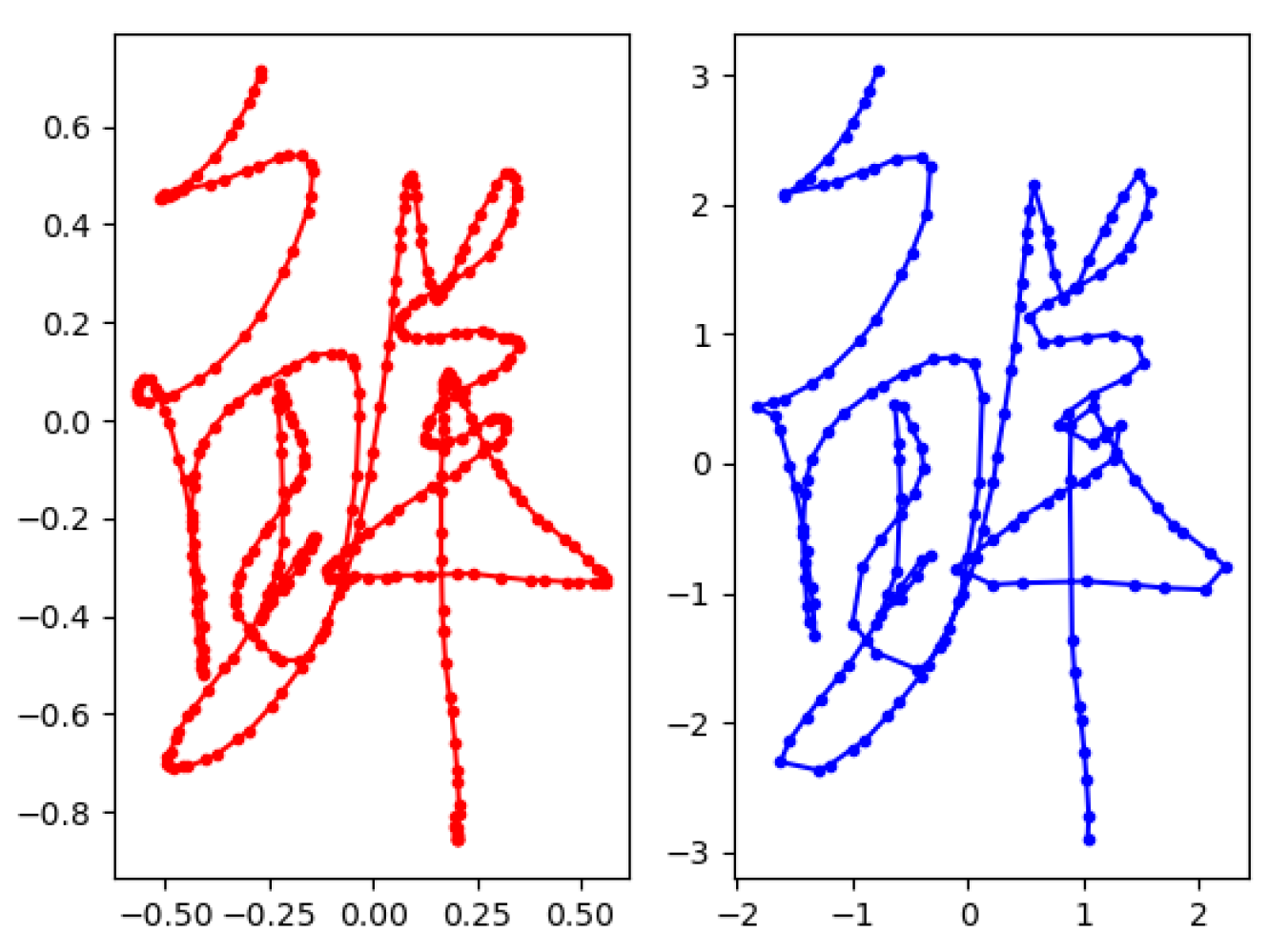
3.1.2. Normalize Coordinates
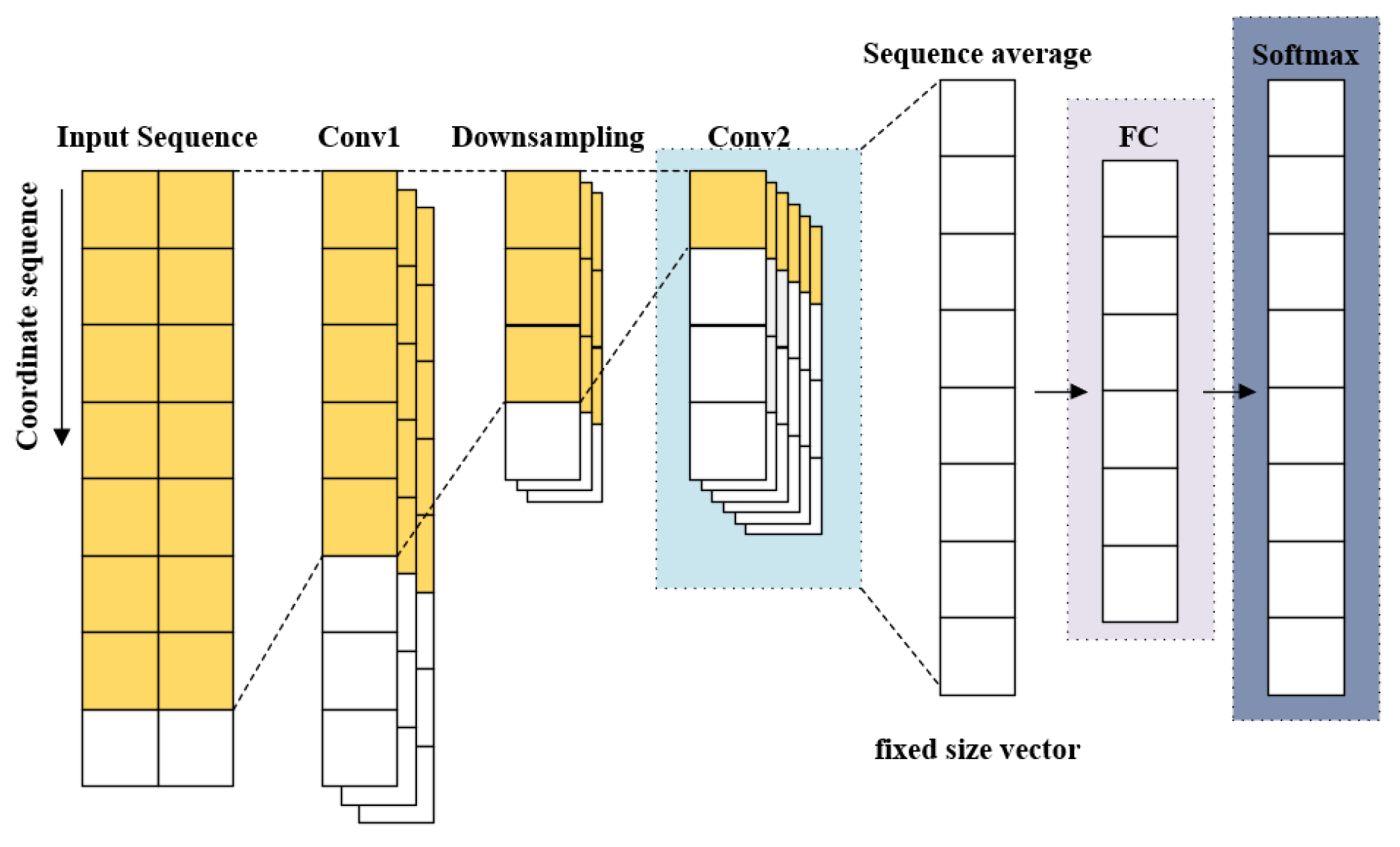
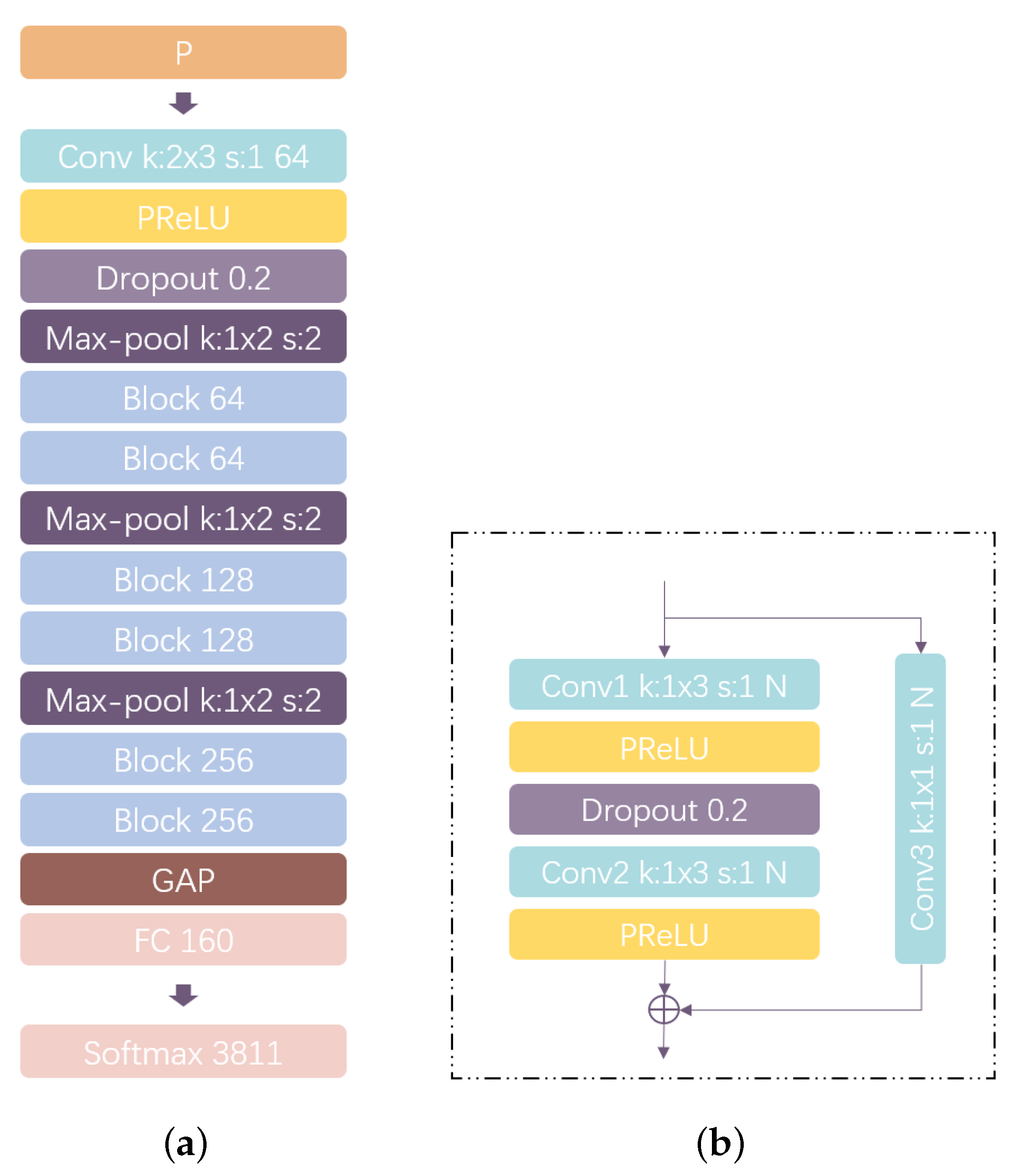
3.2. Designing End-to-End CNN Architecture
4. Experiments
4.1. Datasets
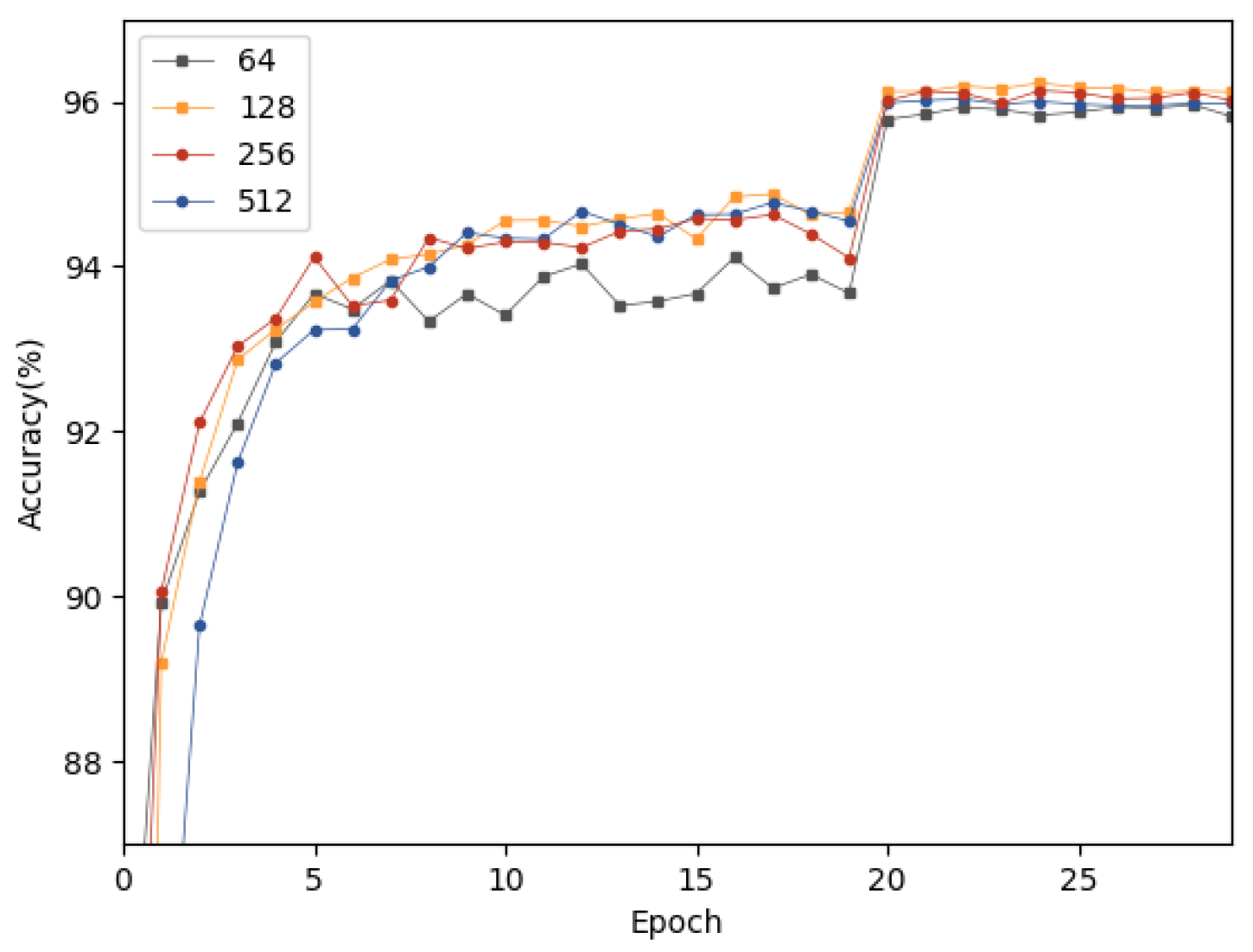
4.2. Model Training Strategy
4.3. Comparison Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, C.L.; Jaeger, S.; Nakagawa, M. Online recognition of chinese characters: The state-of-the-art. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 198–213. [Google Scholar]
- Yin, F.; Wang, Q.F.; Zhang, X.Y.; Liu, C.L. ICDAR 2013 Chinese handwriting recognition competition. In Proceedings of the 2013 International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1464–1470. [Google Scholar]
- Gan, J.; Wang, W.Q.; Lu, K. A new perspective: Recognizing online handwritten Chinese characters via 1-dimensional CNN. Inform. Sci. 2019, 378, 375–390. [Google Scholar] [CrossRef]
- Ren, H.Q.; Wang, W.Q.; Liu, C.L. Recognizing online handwritten Chinese characters using RNNs with new computing architectures. Pattern Recognit. 2019, 93, 179–192. [Google Scholar] [CrossRef]
- Li, Y.; Qian, Y.; Chen, Q.C.; Hu, B.T.; Wang, X.L.; Ding, Y.X.; Ma, L. Fast and Robust Online Handwritten Chinese Character Recognition with Deep Spatial & Contextual Information Fusion Network. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Xu, S.B.; XUE, Y.; CHEN, Y.Q. Quantitative Analyses on Effects from Constraints in Air-Writing. IEICE Trans. Inform. Syst. 2019, E120, 867–870. [Google Scholar] [CrossRef]
- Fu, Z.J.; Xu, J.S.; Zhu, Z.D.; Liu, A.X. Writing in the air with WiFi signals for virtual reality devices. IEEE Trans. Mobile Comput. 2019, 18, 473–484. [Google Scholar] [CrossRef]
- Gadekallu, T.R.; Srivastava, G.; Liyanage, M.; Iyapparaja, M.; Chowdhary, C.L.; Koppu, S.; Maddikunta, P.K.R. Hand gesture recognition based on a Harris Hawks optimized Convolution Neural Network. Comput. Electr. Eng. 2022, 100, 107836. [Google Scholar] [CrossRef]
- Bai, Z.L.; Huo, Q. A study of nonlinear shape normalization for online hand-written Chinese character recognition: Dot density vs. line density equalization. In Proceedings of the 2006 International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; pp. 921–924. [Google Scholar]
- Bai, Z.L.; Huo, Q. A study on the use of 8-directional features for online handwritten Chinese character recognition. In Proceedings of the 2005 International Conference on Document Analysis and Recognition, Seoul, Korea, 31 August–1 September 2005; pp. 262–266. [Google Scholar]
- Liu, C.L.; Marukawa, K. Pseudo two-dimensional shape normalization methods for handwritten Chinese character recognition Pattern Recognition. Inform. Sci. 2005, 38, 2242–2255. [Google Scholar]
- Liu, C.L.; Yin, F.; Wang, D.H.; Wang, Q.F. Online and offline handwritten Chinese character recognition: Benchmarking on new databases. Pattern Recognit. 2013, 46, 155–162. [Google Scholar] [CrossRef]
- Kimura, F.; Takashina, K.; Tsuruoka, S.; Miyake, Y. Modified quadratic discriminant functions and the application to Chinese character recognition. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 9, 149–153. [Google Scholar] [CrossRef]
- Lai, S.X.; Jin, L.W.; Yang, W.X. Toward high-performance online HCCR: A CNN approach with DropDistortion, path signature and spatial stochastic max-pooling. Pattern Recognit. Lett. 2017, 89, 60–66. [Google Scholar] [CrossRef] [Green Version]
- Hsieh, T.A.; Wang, H.M.; Lu, X.G.; Tsao, Y. WaveCRN: An Efficient Convolutional Recurrent Neural Network for End-to-end Speech Enhancement. IEEE Signal Proc. Let. 2020, 27, 2149–2153. [Google Scholar] [CrossRef]
- Oza, P.; Patel, V.-M. One-Class Convolutional Neural Network. IEEE Signal Proc. Let. 2019, 26, 277–281. [Google Scholar] [CrossRef] [Green Version]
- Yang, W.X.; Jin, L.W.; Tao, D.C.; Xie, Z.C.; Feng, Z.Y. Drop sample: A new training method to enhance deep convolutional neural networks for large-scale unconstrained handwritten chinese character recognition. Pattern Recognit. 2016, 58, 190–203. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.M.; Zhang, X.Y.; Yin, F.; Yang, Q.; Liu, C.L. Convolutional Prototype Network for Open Set Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2358–2370. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Bengio, Y.S.; Liu, C.L. Online and Offline Handwritten Chinese Character Recognition: A Comprehensive Study and New Benchmark. Pattern Recognit. 2017, 61, 348–360. [Google Scholar] [CrossRef] [Green Version]
- Ren, H.Q.; Wang, W.Q.; Lu, K.; Zhou, J.S.; Yuan, Q.C. An end-to-end recognizer for in-air handwritten Chinese characters based on a new recurrent neural networks. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo, Hong Kong, China, 11–14 July 2017; pp. 841–846. [Google Scholar]
- Liu, X.; Hu, B.; Chen, Q.; Wu, X.; You, J. Stroke Sequence-Dependent Deep Convolutional Neural Network for Online Handwritten Chinese Character Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4637–4648. [Google Scholar] [CrossRef] [Green Version]
- Parvizi, A.; Kazemifard, M.; Imani, Z. Fast Online Character Recognition Using a Novel Local-Global Feature Extraction Method. In Proceedings of the 2021 International Conference on Information and Knowledge Technology (IKT), Babol, Iran, 14–16 December 2021; pp. 183–187. [Google Scholar]
- Qu, X.W.; Wang, W.Q.; Lu, K.; Zhou, J.-S. Data augmentation and directional feature maps extraction for in-air handwritten Chinese character recognition based on convolutional neural network. Pattern Recognit. Lett. 2018, 111, 9–15. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Yin, F.; Zhang, Y.M.; Liu, C.L.; Bengio, Y. Drawing and recognizing Chinese characters with recurrent neural network. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 849–862. [Google Scholar] [CrossRef] [Green Version]
- Qu, X.W.; Wang, W.Q.; Lu, K.; Zhou, J.S. High-order directional features and sparse representation based classification for in-air handwritten chinese character recognition. In Proceedings of the IEEE International Conference on Multimedia and Expo, Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Liu, C.L.; Nakagawa, M. Evaluation of prototype learning algorithms for nearest-neighbor classifier in application to handwritten character recognition. Pattern Recognit. 2001, 34, 601–615. [Google Scholar] [CrossRef]
- Xu, N.; Wang, W.Q.; Qu, X.W. A discriminative classifier for in-air handwritten Chinese characters recognition. In Proceedings of the 2015 International Conference on Internet Multimedia Computing and Service, Quebec City, QC, Canada, 27–30 September 2015; pp. 16–19. [Google Scholar]
- Wei, C.P.; Chao, Y.W.; Yeh, Y.R.; Wang, Y.C.F. Locality-sensitive dictionary learning for sparse representation based classification. Pattern Recognit. 2013, 46, 1277–1287. [Google Scholar] [CrossRef]
- Qu, X.W.; Wang, W.Q.; Lu, K.; Zhou, J.S. In-air handwritten Chinese character recognition with locality-sensitive sparse representation toward optimized prototype classifier. Pattern Recognit. 2018, 78, 4783–4797. [Google Scholar] [CrossRef]
- XU, N.; WANG, W.Q.; QU, X.W. On-line sample generation for in-air written chinese character recognition based on leap motion controller. In Proceedings of the 2015 Pacific-Rim Conference on Multimedia, Gwangju, Korea, 16–18 September 2015; pp. 171–180. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- He, K.M.; Zhang, X.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S.C. Network in network. In Proceedings of the 2014 IEEE International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Jin, L.-W.; Gao, Y.; Liu, G.; Li, Y.-Y. SCUT-COUCH2009—A comprehensive online unconstrained Chinese handwriting database and benchmark evaluation. Int. J. Doc. Anal. Recog. 2011, 14, 53–64. [Google Scholar] [CrossRef] [Green Version]
- Jin, X.B.; Liu, C.L.; Hou, X. Regularized margin-based conditional loglikelihood loss for prototype learning. Pattern Recognit. 2010, 43, 2428–2438. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Types | Limitations |
|---|---|---|
| Linear normalization [11] | Preprocessing | Neglecting the density of handwritten character sequence coordinates can lead to severe shape distortion |
| Nonlinear normalization [9] | Preprocessing | Unable to correct skew, local width or height imbalances in handwritten characters |
| Pseudo-2D normalization and line density projection interpolation [11] | Preprocessing | Usually dealing with image features |
| Coordinate normalization [24] | Preprocessing | Usually dealing with sequence features |
| Eight-directional feature maps [10] | Feature extraction | Usually applied to OLHCCR |
| Higher-order directional features. [25] | Feature extraction | Usually applied to IAHCCR |
| Learning-vector-quantization-technique-based multi-level classifier [27] | Classifier | High computational cost and storage consumption |
| MQDF [25] | Classifier | Low recognition accuracy and high storage cost |
| LSRC [28] | Classifier | Difficulty obtaining discriminative features and low recognition accuracy |
| Locality-sensitive sparse representation toward optimized prototype classifier [29] | Classifier | Low recognition accuracy and high storage cost |
| Nine-layer convolutional neural network model combined with data-augmentation technology [23] | Classifier | Relying on manual feature extraction and large amounts of data |
| End-to-end recognizer based on recurrent neural networks [20] | Classifier | Less efficient computational structure |
| RNN system with two new computing architectures added [4] | Classifier | It has difficultly effectively learning the global spatial features of sequences |
| Methods | Accuracy (%) |
|---|---|
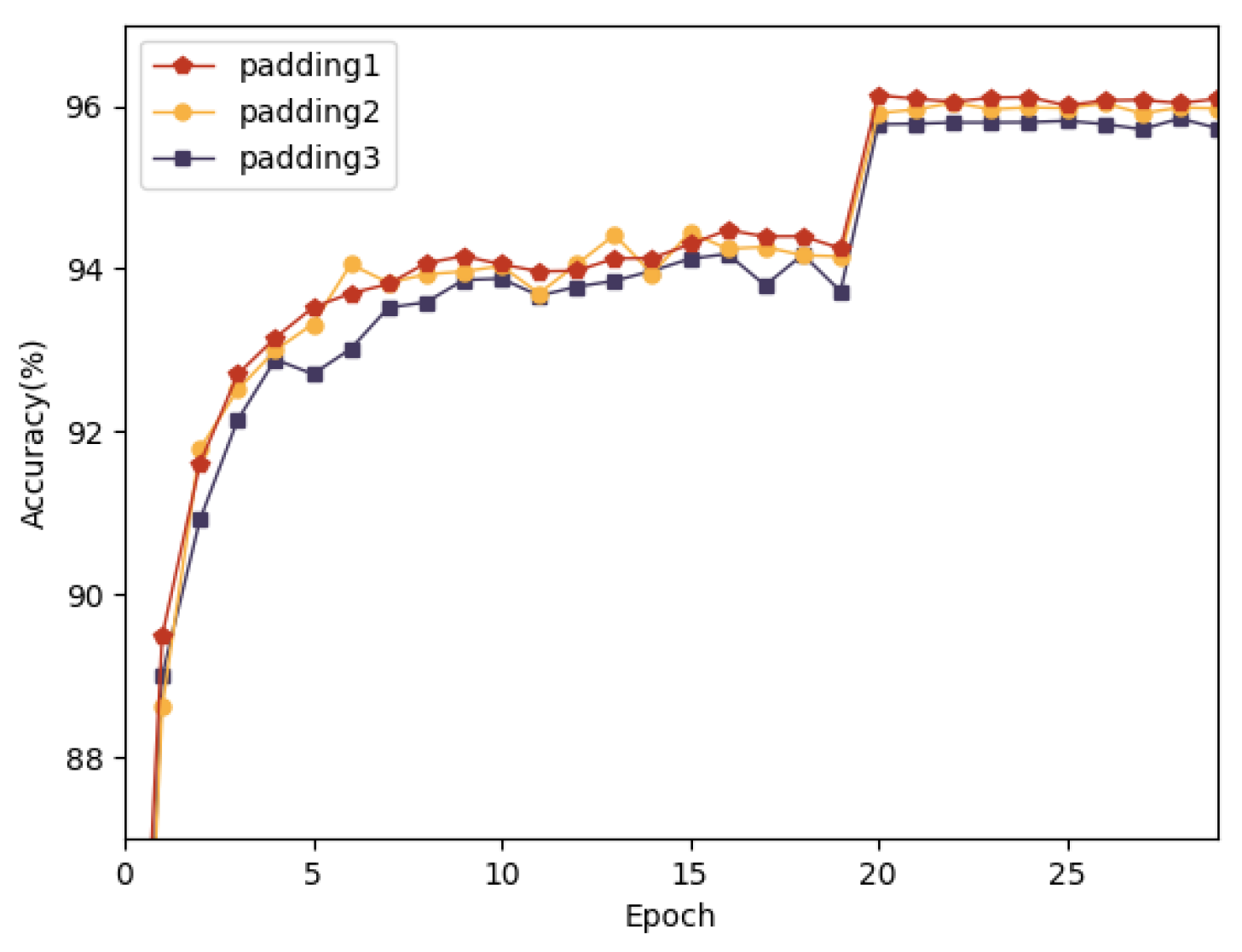
| padding1 | 96.07 |
| padding2 | 96.0 |
| padding3 | 95.79 |
| Methods | Accuracy (%) | Storage (MB) | DA | Ensemble |
|---|---|---|---|---|
| Cov8d [23] | 91.62 | 20.2 | No | No |
| CovCd1 [23] | 92.32 | 20.2 | Yes | No |
| CovCd2 [23] | 92.93 | 20.2 | Yes | No |
| RNN1 [20] | 92.50 | 7.03 | No | No |
| RNN1-Ensemble [20] | 93.40 | 61.59 | No | Yes |
| RNN2 [4] | 93.60 | 7.01 | No | No |
| RNN2-Ensemble [4] | 94.40 | 25.75 | No | Yes |
| Proposed method | 96.07 | 6.48 | No | No |
| Methods | Accuracy (%) | Storage (MB) | DA | Ensemble |
|---|---|---|---|---|
| Cov8d [23] | 96.10 | 19.4 | No | No |
| CovCd1 [23] | 97.15 | 19.4 | yes | No |
| CovCd2 [23] | 97.43 | 19.4 | yes | No |
| Proposed method | 98.02 | 6.44 | No | No |
| Methods | Accuracy (%) | Storage (MB) | DA | Ensemble |
|---|---|---|---|---|
| NPC [36] | 86.90 | 8.52 | No | No |
| NPC-MCE [28] | 88.93 | 8.52 | No | No |
| Multi1 [29] | 88.28 | 128.8 | No | No |
| Multi2 [26] | 88.90 | 128.8 | No | No |
| MQDF [25] | 89.96 | 191.11 | No | No |
| LSRC [27] | 88.93 | 31.78 | No | No |
| LSROPC [29] | 91.01 | 70.00 | No | No |
| Proposed method | 96.07 | 6.48 | No | No |
| Methods | Accuracy (%) | Storage (MB) | DA | Ensemble |
|---|---|---|---|---|
| NPC [36] | 91.30 | 4.76 | No | No |
| NPC-MCE [28] | 92.96 | 4.76 | No | No |
| Multi1 [29] | 92.36 | 124.5 | No | No |
| Multi2 [26] | 93.42 | 124.5 | No | No |
| MQDF [25] | 95.21 | 184.84 | No | No |
| LSRC [27] | 94.40 | 27.86 | No | No |
| LSROPC [29] | 95.50 | 65.53 | No | No |
| Proposed method | 98.02 | 6.44 | No | No |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, M.; Qu, X.; Huang, J.; Wu, X. An End-to-End Classifier Based on CNN for In-Air Handwritten-Chinese-Character Recognition. Appl. Sci. 2022, 12, 6862. https://doi.org/10.3390/app12146862
Hu M, Qu X, Huang J, Wu X. An End-to-End Classifier Based on CNN for In-Air Handwritten-Chinese-Character Recognition. Applied Sciences. 2022; 12(14):6862. https://doi.org/10.3390/app12146862
Chicago/Turabian StyleHu, Mianjun, Xiwen Qu, Jun Huang, and Xuangou Wu. 2022. "An End-to-End Classifier Based on CNN for In-Air Handwritten-Chinese-Character Recognition" Applied Sciences 12, no. 14: 6862. https://doi.org/10.3390/app12146862
APA StyleHu, M., Qu, X., Huang, J., & Wu, X. (2022). An End-to-End Classifier Based on CNN for In-Air Handwritten-Chinese-Character Recognition. Applied Sciences, 12(14), 6862. https://doi.org/10.3390/app12146862