1. Introduction
Over recent decades, neural networks trained by the backpropagation method made huge progress in supervised tasks, such as image classification, object detection, and natural language processing [
1]. The combination of neural networks and reinforcement learning yields a new research field, i.e., Deep Reinforcement Learning (DRL) [
2]. DRL has made impressive achievements over recent decades, such as AlphaGo, OpenAI Five, and Hide-and-Seek [
3,
4,
5]. Researchers realized that DRL provides a potential approach to achieving artificial general intelligence and tried to use DRL to complete more real-world tasks. However, most of the real-world tasks such as traffic signal control and web service composition require two or more agents to cooperate to complete and, currently, the math model that single-agent reinforcement learning uses is not able to model the cooperation among agents [
6,
7]. Therefore, decentralized partially observable Markov decision processes (Dec-POMDPs) emerge as a general framework for modeling cooperative multi-agent tasks. Meanwhile, lots of multi-agent reinforcement learning (MARL) algorithms are proposed to address Dec-POMDPs problems.
Dec-POMDPs provide a framework to model the cooperation among multi-agents but how to encourage agents to cooperate with others still remains a challenging issue. In this setting, each agent obtains partial observation and cannot communicate with others, which explains the difficulties in addressing Dec-POMDPs problems. The partial observable setting requires the agent to execute their actions in a decentralized manner. A straightforward way is to learn a decentralized policy for each agent directly by using Q-learning and treating others as part of the environment, which yields the algorithms independent Q-learning [
8]. Ardi Tampuu extends this method by replacing the tabular policy (that is a hash table) with neural networks [
9]. After that, Independent Q-Learning (IQL) refers to the one using neural networks.
Though IQL still serves as the popular MARL algorithm because of its simplicity, agents trained by IQL stuck to suboptimal policies sometimes. For example, there is a team of agents in a soccer game and they want to beat the other team which is controlled by scrips. Agent A in this team learns to score and others learn to pass the ball to agent A even when they are in far better positions than agent A to score, which is not a smart policy. This phenomenon is called the “lazy-agent” problem, i.e., learned inefficient policies with only one agent active and the others being “lazy” [
10]. An approach to avoid this problem can be the fully centralized MARL algorithms, which cast the Dec-POMDPs problem into the MDP problem by using the joint state and joint action. Though it obtains the guarantee to converge to the optimal policies, it is hard to scale to large real-world applications.
To encourage the cooperation of agents and address wired phenomenons such as the “lazy-agent” problem, the multi-agent credit assignment becomes a crucial topic to study. The multi-agent credit assignment refers to the fact that in cooperative settings, joint actions typically generate only global rewards, making it difficult for each agent to deduce its own contribution to the team’s success [
11]. Sometimes each agent’s reward can probably be handcrafted based on the global rewards in very simple tasks. However, this is not always true and often leads to the situation where each agent only considers itself and ignores the cooperation, which leads to suboptimal policies. Lots of work has been conducted to learn to decompose the global reward into each agent’s reward but a good credit assignment method is still missing.
In this paper, we investigate the credit assignment problem from the perspective of multiple levels, i.e., different resolutions of time. We propose a novel hierarchical MARL method, coined MLCA, that can efficiently utilize different hierarchical information to reason and achieves credit assignment across multiple hierarchies. We set the number of hierarchies of MLCA to two in the paper, but it can be extended to more than two easily. The key contributions of this paper are: (1) to the best of our knowledge, MLCA is the first one that achieves credit assignment across multiple hierarchies; (2) MLCA uses plans as high-level options and primitive actions as the low-level options to achieve different hierarchies and the lower hierarchy is guided by the higher hierarchy; (3) the temporal abstraction mechanism is applied to enable different hierarchies to obtain different resolutions of time, thereby a different credit assignment mechanism is learned across multiple levels; (4) detailed experiments are provided to support our claims.
2. Background
2.1. Dec-POMDPs Formulation
Dec-POMDPs serve as a general framework for cooperative multi-agent tasks and we also adopt this formulation in the paper. Dec-POMDPs can defined as
:
S is a finite set of hidden states;
A is a finite set of joint actions;
P is the transition model and represents the probability of next state when all agents select joint action at state ;
R is the reward function which returns one total credit for all agents when they choose at state , i.e ;
O is the observation function where agent i obtains its own observation ;
n is the number of agents, is the discount factor;
is the discount factor;
T is the decision-making timestep set.
Following this setting, each agent receives its current observation s, selects its action a based on s and executes. Then, the environment reacts to all agents’ actions and returns the next observation and a global reward for each agent according to the transition model P and reward function R. It is worth noticing that each agent can neither see the actual state of the world nor explicitly communicate with each other, which explains the difficulty of finding optimal policies for agents. Thus, each agent aims to learn unilaterally to cooperate with others and maximize the cumulative global reward, which can be defined as the total Q-value, i.e., .
2.2. Independent Q-Learning
To address Dec-POMDPs problems, the straightforward approach can be Independent Q-learning (IQL) which was proposed by Ming Tan in 1993 [
12]. IQL extends the single-agent reinforcement learning algorithm, Q-learning, to the multi-agent tasks by treating each agent as an individual learner and others as part of the environment in the perspective of this agent. Thus, in IQL, each agent treats the global reward as its reward and maximizes its cumulative reward. While Ming Tan demonstrated that sharing information such as current observations among agents could encourage cooperation, it is not allowed in this setting since the communication cost can be expensive and prohibitive in most multi-agent tasks.
Ardi Tampuu extended the IQL to a more complex environment by replacing the Q table (where the Q-value stores) with neural networks [
9]. It is worth noticing that the introduction of neural networks also makes the converge guarantee for IQL no longer valid. After that, IQL refers to the one that uses neural networks to store Q-values but IQL often fails to address tasks that require high-level cooperation [
10].
2.3. Value Decomposition Network
Since the individual learner treats other agents as part of the environment in the fully decentralized methods, the transition dynamics for each agent become highly stochastic. The fully decentralized approach, such as IQL, faces the instability problem. In order to ease this instability, a centralized training and decentralized execution (CTDE) diagram is proposed. As its name reflects, CTDE allows the agents to communicate and share information in the training phase and stay isolated in the execution phase. CTDE eases the learning processes for MARL algorithms greatly and is the dominating framework currently. In addition, CTDE provides a possible way to achieve reasonable multi-agent credit assignments in the training phase.
To encourage the cooperation among agents in the multi-agent systems, Value Decomposition Network (VDN) that follows the CTDE diagram is proposed. VDN aims to use a value decomposition network to learn a linear decomposition scheme and divide the global reward into each agent’s individual reward based on its contribution to success. In VDN, each agent obtains its own value network and its output are added to obtain the total Q-value, which can be defined as
where
s is the global state,
denotes the n-th agent’s observation, and
denotes the n-th agent’s action and the gradient is backpropagated to update all agents’ value networks. VDN manages to avoid the spurious reward signals that emerge in a fully centralized approach and ameliorates the coordination problem.
2.4. COMA
Jakob N. Foerster proposes a classical policy-based MARL algorithm, COMA, to address the credit assignment issue [
11]. COMA follows the actor-critic approach and actors, i.e., policies, are independent and trained by backpropagating the gradient estimated by a critic. One of COMA’s contributions is that the critics are not independent, but centralized, which means all agents share the same critic. The critic only appears in the training phase, which satisfies the CTDE digram and the critic can use all available information in the training phase and each agent’s policy stays independent in the execution phase.
Another contribution is the introduction of the counterfactual baseline that is inspired by difference rewards [
11,
13,
14]. Difference rewards are a powerful way to perform multi-agent credit assignments but it requires a default action to compare with the reward obtained by the current action, which also requires access to the simulator. COMA avoids this requirement by introducing an advantage function
where
is the centralized critic,
denotes other agents’ actions,
denotes the probability of chosing action
condition on the history of observations
. Hence, COMA uses this advantage function as the object to optimize and learn directly from agents’ experiences instead of relying on extra simulations, a reward model, or a user-designed default action.
3. Related Work
Credit assignment has been a long-standing problem in the field of multi-agent reinforcement learning [
13,
15]. A good credit assignment scheme can divide the only global reward from the environment into individual rewards for agents based on their contribution. Thus, it can encourage high-level cooperation among agents and avoid suboptimal policies, such as the “lazy-agent” problem that exists in the trained policies by IQL. Because of the call for high-level coordination policies trained by MARL algorithms, credit assignment attracts lots of researchers’ attention. Lots of MARL algorithms have been proposed to tackle it and these methods can be divided into two groups.
The first group is the value-based methods, which start from the VDN. VDN proposed an addictive decomposition scheme to divide the global reward into each agent’s reward. It is worth noticing that the IGM (Individual-Global-Max) principle is required in this kind of method. The IGM principle requires the consistency of the optimal joint action selection with optimal individual action selections. This linear factorization does have better performance in encouraging cooperation among agents than IQL [
10]. However, it also limits the application scenarios of VDN because the linear relation between global reward and individual agents’ rewards is not always valid. To overcome the limitations of this linear representation, QMIX proposes a monotonic value function factorization scheme by introducing a hyper network [
16]. The hyper network takes the global information as input and outputs the weights of the mixing network. The weight of the mixing network is forced to be non-negative to obtain this monotonic value function factorization scheme. However, the representation ability of QMIX is limited due to the introduction of the non-negative mixing network [
17,
18]. QPLEX improves the representation ability of the mixing network by adopting the dueling network architecture, which can transform the IGM principle to easily realized constraints on advantage functions [
18].
Another group is the policy-based MARL methods. Unlike the value-based methods that learn the Q-values first and select actions based on Q-values, the policy-based MARL methods learn policy directly. Lowe et al. proposed a multi-agent policy-gradient algorithm using centralized critics named MADDPG, but it does not address the credit assignment [
19]. One of the most classical policy-based MARL methods is COMA. COMA performs the credit assignment by introducing a centralized critic and a counterfactual baseline that incorporates the difference reward technique. The difference reward technique replaces the original reward with a shaped reward that compares the reward received when that agent’s action is replaced with a default action [
13,
14]. It is worth noticing that the counterfactual baseline is proved to not influence the final optimization object. After that, a MARL algorithm named LICA tries to train a neural network to learn a credit assignment scheme directly [
20]. DOP introduces the idea of value function decomposition into the multi-agent actor-critic framework to address the credit assignment issue. It also supports off-policy learning to improve the sample efficiency and currently serves as the state-of-the-art MARL algorithm [
21].
4. Method
In this section, we provide a detailed description of the proposed method MLCA. First, we describe the hierarchical model that includes two levels. The hierarchical model not only serves as the foundation for multi-level credit assignment but also enables our method to utilize different resolutions of time. Then, in order to empower the higher level broader horizon over time and give high-level plans, the temporal abstraction is achieved by using the dilated LSTM. Finally, we present the two-level credit assignment method that can be easily extended to more levels.
It is worth noticing that unlike other hierarchical MARL methods, i.e., ROMA and RODE, MLCA proposes to use the temporal abstract technique to assign different time resolutions to different levels and achieves multi-level credit assignment based on that [
22,
23].
4.1. The Hierarchical Model
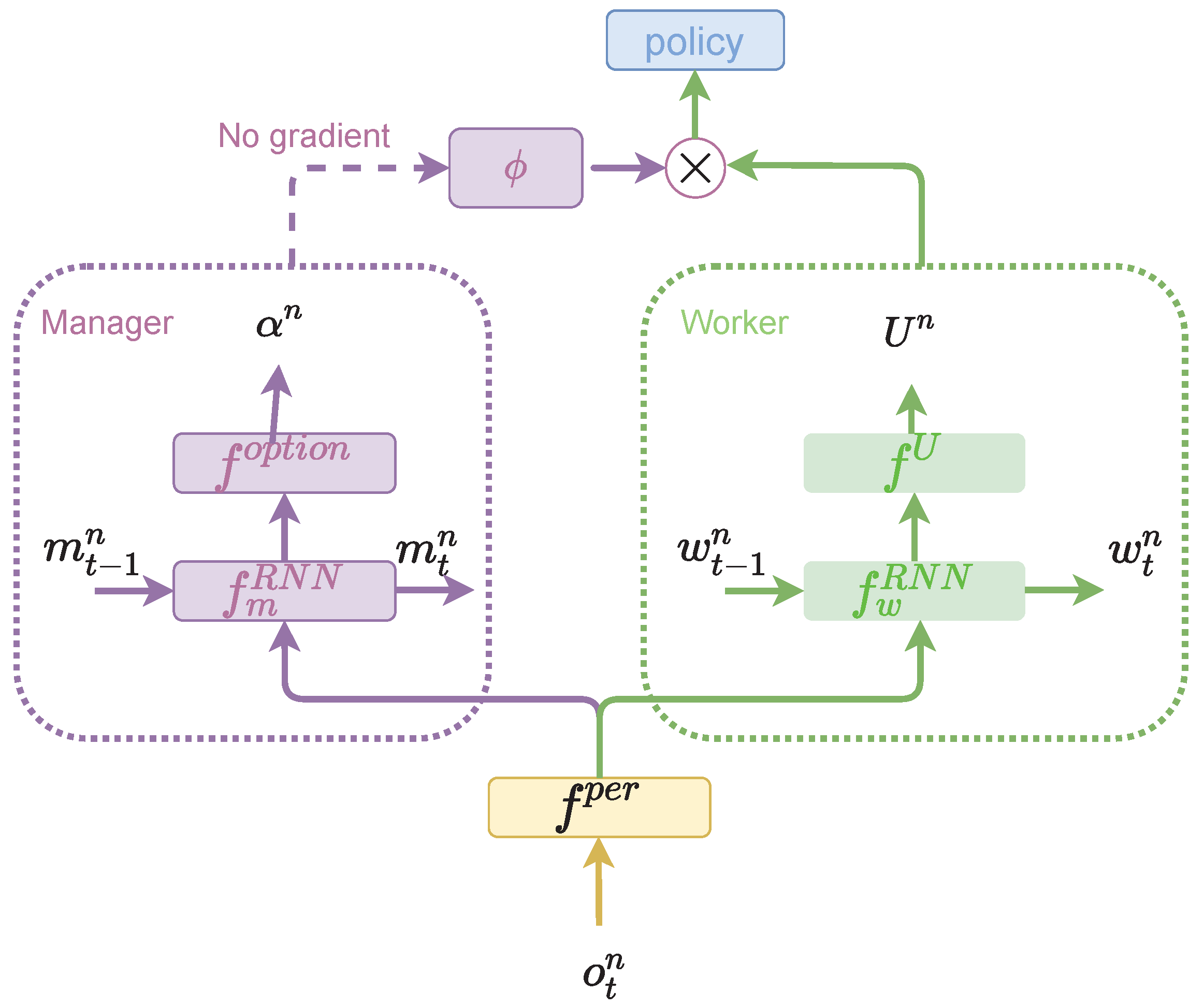
In order to achieve the multi-level credit assignment, we propose a two-level hierarchical model for each agent first. Inspired by the feudal network, the hierarchical model consists of the top level (the manager) and the lower level (the worker) and can be represented as
Figure 1 [
24]. The manager aims to learn high-level plans that are denoted as
. These high-level plans are used to guide the low-level worker to generate primitive actions based on
. Thus, the manager can focus on learning high-level decisions and the worker only needs to follow the guidance from the manager.
As
Figure 1 represented, the observation
is taken as the input of the hierarchical model. It first needs to be processed by the perception network
, which can be represented as
where
denotes the embedding results of the perception network. Then,
is sent to the manager and the worker, respectively. We first present the workflow of the manager.
is processed by the
RNN of the manager first, which can be denoted as
where
denotes the n-th agent’s hidden states in the manager. Then, the intermediate result
is sent to the option network
to produce the embedding results
of high-level policies, which can be represented as
To this end, high-level policies have been generated.
Then, we present the worker inside the worker and the mechanism that how the high-level plans guide the low-level actions.
is processed by the RNN of the worker first, which can be denoted as
where
denotes the n-th agent’s hidden states in the worker.
Then, intermediate result
is sent to the embedding network
to produce
, which can be represented as
In order to incorporate the high-level plans generated by the manager, the
is designed to combine with the
. To achieve this,
is processed by the
first. These two process can be denoted as
To this end, the policy
can be obtained by
It is worth noticing that the manager is supposed to generate high-level information. In this section, we introduce the hierarchical model but the details about the manager are not provided. Thus, we present the way we empower the manager with this ability, i.e., temporal abstraction.
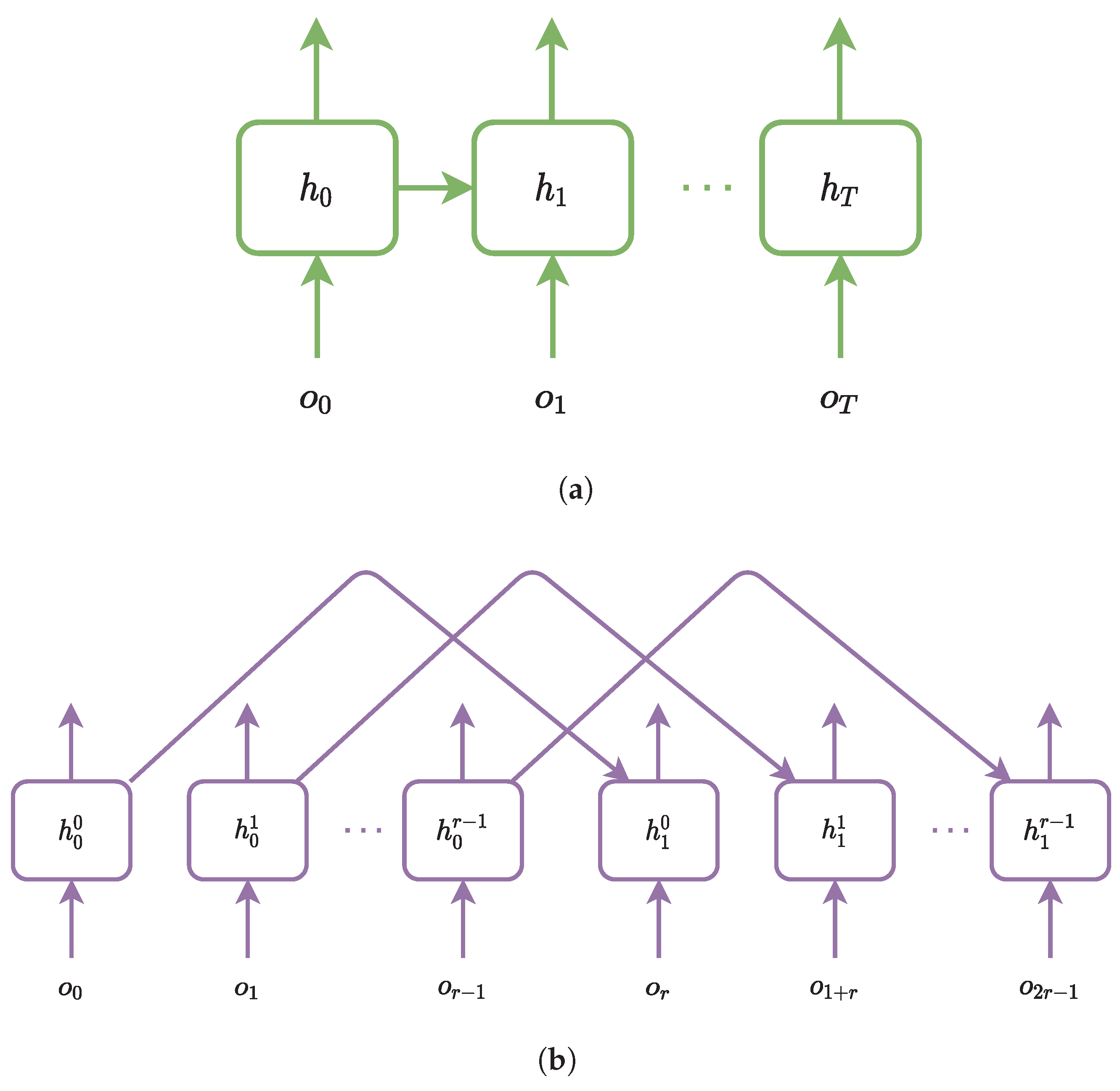
4.2. Temporal Abstraction
In order to make the manager able to focus on high-level decisions, the RNN structure of the manager is designed to work on a lower temporal resolution. Thus, the dilated GRU is applied, which is inspired by dilated convolution networks [
25]. The dilated convolution networks support the exponential expansion of the receptive field without loss of resolution or coverage and improve the performance in image classification greatly. The dilated GRU follows its dilated scheme by obtaining r (the dilated radius) sets of hidden states that are denoted as
. The comparison between the unrolling structure of dilated GRU and the traditional GRU is represented as
Figure 2.
At timestep t, the hidden state is chosen as the input of GRU. Each hidden state is used once every t timesteps. By doing so, the dilated GRU obtains the ability to have a much longer memory and larger receptive field than a normal GRU.
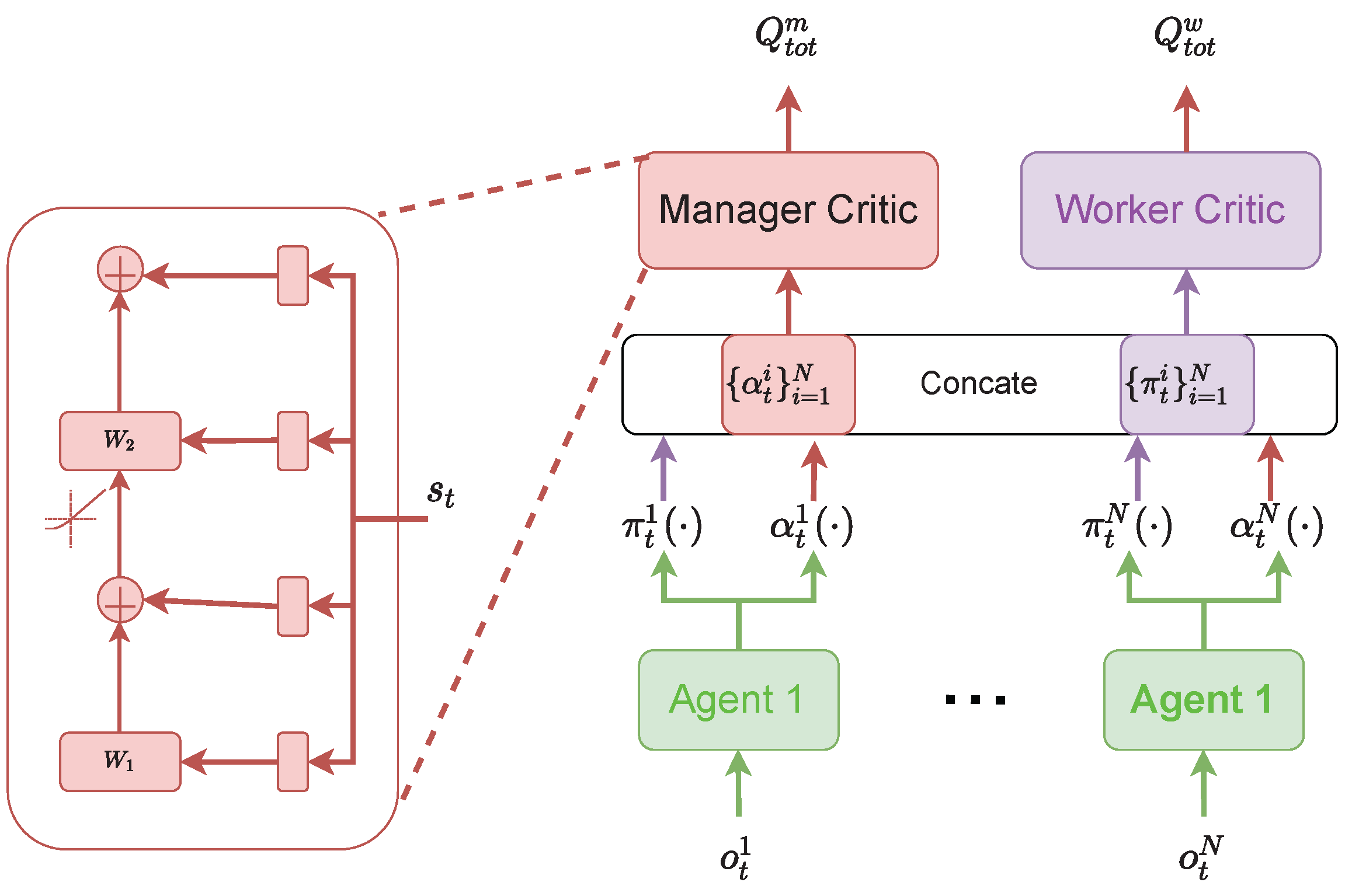
4.3. Multi-Level Credit Assignment
After the introduction of the hierarchical model and the dilated GRU, in
Figure 3 we present the multi-level credit assignment and the whole structure of the proposed method MLCA.
To achieve multi-level credit assignment for this two-hierarchical model, we propose to use one centralized critic network for each hierarchy. Then, there are two centralized critics, i.e., the manager critic for the high-level manager and the worker critic for the low-level worker. The manager critic takes all high-level plans
generated by the managers of all agents as input and outputs a total Q-value for the current joint plan. Thus, the total Q-value for the manager level can be denoted as
, which is what the method wants to maximize. Moreover, in order to obtain a good critic, the object function for the manager critic is
where
denotes the discounted accumulated rewards and can be defined as
Similarly, the worker critic takes all low-level primitive policies
as input and outputs a total Q-value for current joint policies. Thus, the total Q-value for the worker level can be denoted as
, which is what the method wants to maximize. The object function for the manager critic is
To this end, the whole learning process can be represented as Algorithm 1.
| Algorithm 1: Optimization Process for MLCA |
- 1:
Randomly initialize the neural networks (i.e., and ) for agents’ individual functions and all centralized critics - 2:
for number of training iterations do - 3:
Sample b trajectories by interacting with the environment - 4:
Calculate accumulated rewards for each trajectory - 5:
for k iterations do - 6:
Update both centralized critics by minimizing Equation ( 13)
- 7:
Update decentralized hierarchical model by maximizing Equation ( 14)
- 8:
end for - 9:
end for
|
5. Experiments
5.1. Environment Setting
MARL has gained great progress over recent decades but there exists a period the widely accepted benchmarks are missing. That is because the introduction of the neural networks improves the application scenarios of the MARL algorithms greatly and the toy cases used before are no longer good benchmarks for newly proposed algorithms. Thus, some challenging benchmarks are proposed to evaluate the performance of MARL algorithms. Among them, the StarCraft Multi-Agent Challenge (SMAC) provides the decentralized control of each agent and serves as the most popular, standard, and challenging benchmark [
26].
SMAC is developed based on the real-time strategy game, StarCraft II. Each agent in SMAC can observe its own states, i.e., health, shield, and others within its field of observation, it also observes other units’ statistics such as health, location, and unit type. Agents can only attack enemies within their shooting range. Agents in a team will receive a global reward for battle victory, as well as damaging or killing enemy units. Each battle will last for at most 250 steps and may end early because agents in a team all die.
SMAC provides a series of challenging tasks for MARL algorithms to learn and conquer. We select three classical tasks, 2s3z, 5m_vs_6m, and MMM2 to evaluate our proposed method. 2s3z is an easy task, 5m_vs_6m is a hard task and MMM2 is a super hard task. These three challenges with different levels of difficulties are able to demonstrate the performance of MLCA.
Three very effective algorithms, DOP, COMA, and QMIX serve as baseline methods [
11,
16,
21]. DOP is the most recent method and serves as the state-of-the-art method currently. DOP and COMA are policy-based and QMIX is value-based. We follow the setting in [
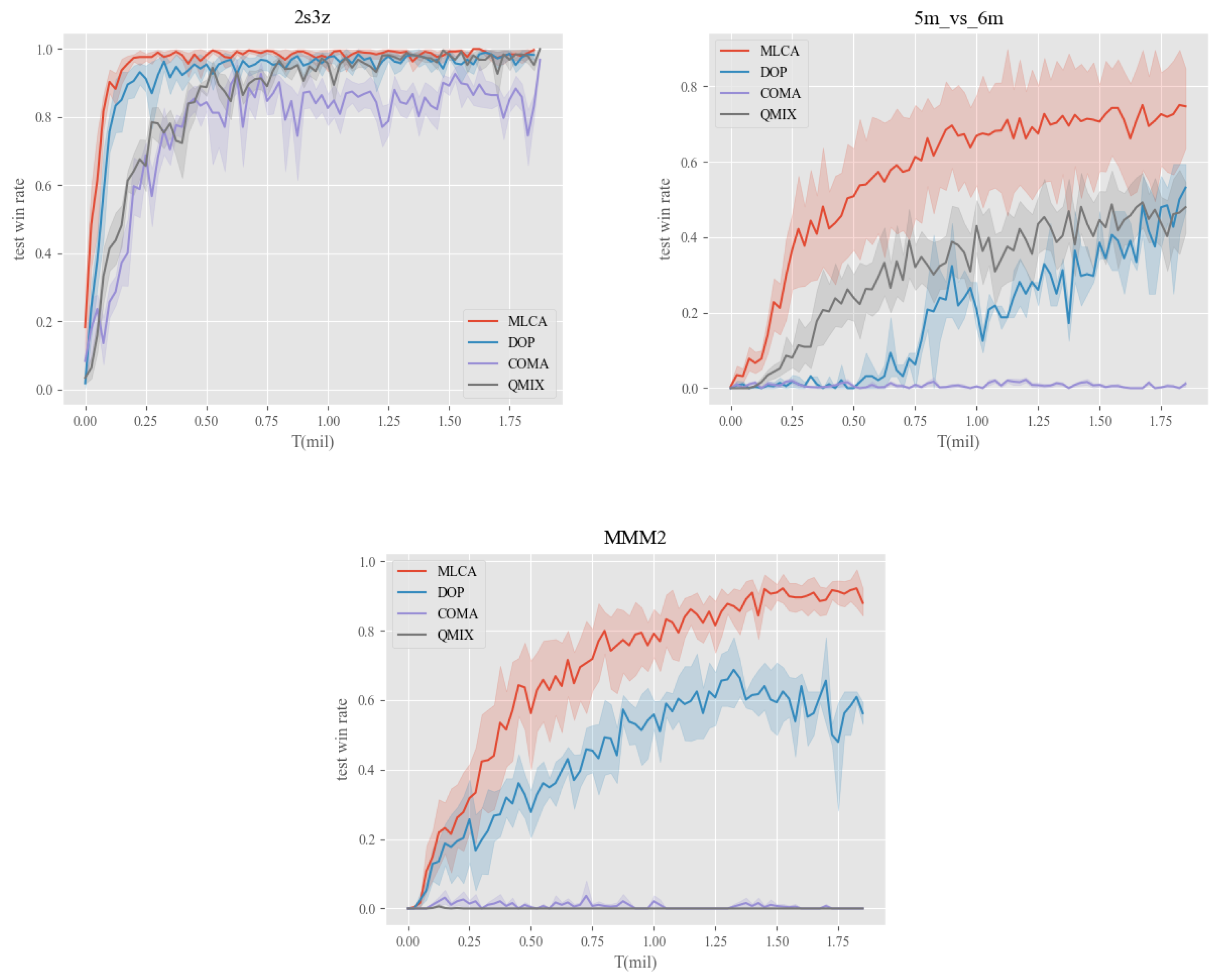
16] where all methods use the same batch size (i.e., 32 episodes) and the same number of training iterations which is 2 million. All methods’ performance is tested every 10,000 training iterations using 32 test episodes where agents act deterministically, All experiments are carried out with 3 different random seeds. The maximum and minimum values of the test win rate at different timesteps are plotted for every method in every challenge. Taking
Figure 4 as an example, the horizontal axis represents the number of timesteps experienced by the agent, denoted as
T.
represents
T in millions. The vertical axis represents the test win rate which ranges from 0 to 1. The MLCA is marked in red. The red line in the block denotes the mean test win rate, the upper and lower bound of the red area are the largest and smallest test win rate, respectively.
In order to reproduce results easily, hyperparameters are listed in
Table 1.
5.2. Results
Figure 4 presents the comparison results of the proposed method MLCA against DOP, COMA, and QMIX. We can observe that MLCA gains great performance improvement across all three challenges. Since 2s3z is an easy task that does not require high-level cooperation, all methods can learn to conquer easily, but MLCA obtains higher sample efficiency and stability. While in 5m_vs_6m and MMM2, our method learns faster and better. MMM2 is a super hard task and requires high-level cooperation among 10 agents and three different types of units. MLCA obtains the highest sample efficiency and can reach nearly 1.0 test win rate in 2 million steps, while other methods can not. The result in the MMM2 task demonstrates that the proposed method MLCA can learn better cooperation policy, which shows the effectiveness of the multi-level credit assignment scheme.
It is worth noticing 2s3z is a homogeneous task, which means the agent team and the enemy team share the same number of agents and the same type of agents. 5m_vs_6m and MMM2 are heterogeneous, which makes the learning process harder. While our method MLCA gains great performance improvement in both heterogeneous and homogeneous tasks because of the multi-level credit assignment scheme. The results demonstrate that MLCA can achieve a better credit assignment scheme and thus encourage high-level cooperation.








{kind=link}
{kind=link}
{kind=link}
{kind=link}