
Solving Task Scheduling Problems in Dew Computing via Deep Reinforcement Learning


Abstract
:1. Introduction
2. Edge and Dew Computing
3. Related Work
3.1. Human-Designed Heuristic Methods in SCEs
3.2. RL Methods in Edge and Dew Computing
4. Reinforcement Learning (RL)
5. Reinforcement Learning for Dew Computing
5.1. Notation
5.2. Problem Definition: Task Scheduling in Dew Computing
5.3. Environment Definition: States, Actions, and Rewards
5.4. Implementation Details and Challenges
6. Experimentation
- 1
- Can a deep RL agent learn to distribute jobs better than heuristic methods in a fixed Dew environment?
- 2
- Can a deep RL agent learn a policy that generalizes well to unseen situations in a given Dew environment?
6.1. Baselines
- Enhanced Simple Energy-Aware Scheduler (E-SEAS) [32]: Before every allocation, the scheduler computes a score for each device which considers the node’s current battery level, computation capabilities, and the number of jobs currently in its queue. Then, the device with the lowest score is selected.
- Round Robin (RR) [8]: The traditional RR algorithm gives one task to each device in a circular order until all tasks have been assigned.
- Weighted Round Robin (W-RR) [7]: Each device is assigned a weight proportional to its computing power. Then, when giving tasks to the devices in circular order, those with higher weights will be assigned more jobs at once.
- Weighted Random (W-Rand) [7]: Similarly to W-RR, the weight of each device is proportional to its computing power. The scheduler will then sample a random device when assigning a job, but those with higher weights will have a higher chance of being selected.
- Batch Processing Algorithm (BPA) [7]: In the same way as E-SEAS, the scheduler computes a score considering the node’s current battery level, computation capabilities, and job load measured in how many operations are needed to finish each task. Then, the device with the lowest score is selected.
6.2. Fixed Job Experiments
6.2.1. Experimental Setup
6.2.2. The Agent Configuration
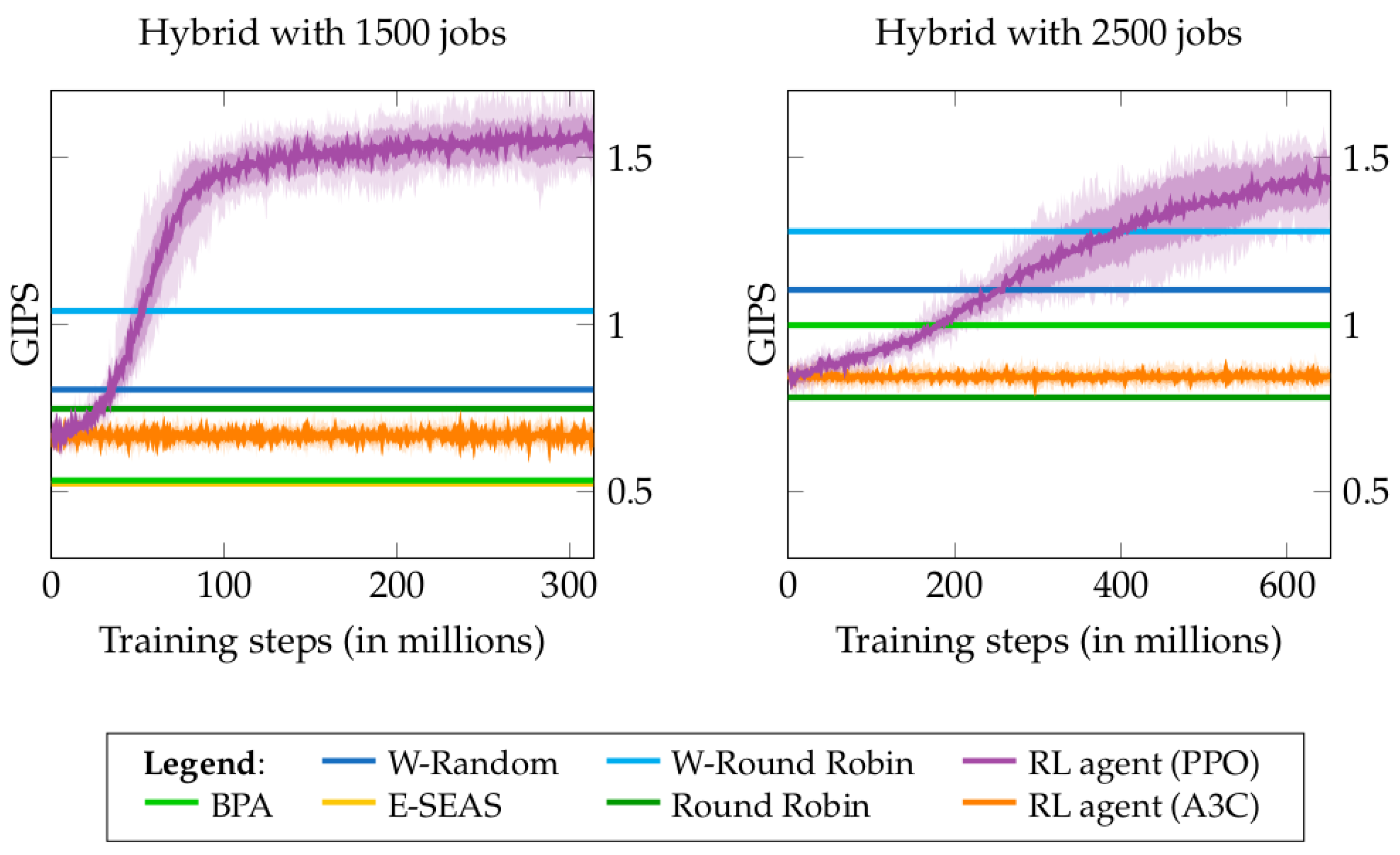
6.2.3. Results
6.3. Discussion on Generalization
6.4. Generalization Experiments
6.5. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Simulator Details

Appendix A.1. Scheduling Logic
Appendix A.2. Client/Server Mode

References
- Wang, Y. Definition and categorization of dew computing. Open J. Cloud Comput. 2016, 3, 1–7. [Google Scholar]
- Ray, P.P. An introduction to dew computing: Definition, concept and implications. IEEE Access 2017, 6, 723–737. [Google Scholar] [CrossRef]
- Hirsch, M.; Mateos, C.; Zunino, A. Augmenting computing capabilities at the edge by jointly exploiting mobile devices: A survey. Future Gener. Comput. Syst. 2018, 88, 644–662. [Google Scholar] [CrossRef]
- Khalid, M.N.B. Deep Learning-Based Dew Computing with Novel Offloading Strategy. In Proceedings of the International Conference on Security, Privacy and Anonymity in Computation, Communication and Storage, Nanjing, China, 18–20 December 2020; pp. 444–453. [Google Scholar]
- Nanakkal, A. A Brief Survey of Future Computing Technologies in Cloud Environment. Ir. Interdiscip. J. Sci. Res. 2021, 4, 63–70. [Google Scholar] [CrossRef]
- Rodriguez, J.M.; Zunino, A.; Campo, M. Mobile grid seas: Simple energy-aware scheduler. In Proceedings of the 3rd High-Performance Computing Symposium-39th JAIIO, Caba, Argentina, 31 August–3 September 2010; pp. 3341–3354. [Google Scholar]
- Sanabria, P.; Tapia, T.F.; Neyem, A.; Benedetto, J.I.; Hirsch, M.; Mateos, C.; Zunino, A. New Heuristics for Scheduling and Distributing Jobs under Hybrid Dew Computing Environments. Wirel. Commun. Mob. Comput. 2021, 2021, 8899660. [Google Scholar] [CrossRef]
- Samal, P.; Mishra, P. Analysis of variants in Round Robin Algorithms for load balancing in Cloud Computing. Int. J. Comput. Sci. Inf. Technol. 2013, 4, 416–419. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Akkaya, I.; Andrychowicz, M.; Chociej, M.; Litwin, M.; McGrew, B.; Petron, A.; Paino, A.; Plappert, M.; Powell, G.; Ribas, R.; et al. Solving rubik’s cube with a robot hand. arXiv 2019, arXiv:1910.07113v1. [Google Scholar]
- Li, J.; Monroe, W.; Ritter, A.; Galley, M.; Gao, J.; Jurafsky, D. Deep reinforcement learning for dialogue generation. arXiv 2016, arXiv:1606.01541v4. [Google Scholar]
- Popova, M.; Isayev, O.; Tropsha, A. Deep reinforcement learning for de novo drug design. Sci. Adv. 2018, 4, eaap7885. [Google Scholar] [CrossRef] [Green Version]
- Kaur, P. DRLCOA: Deep Reinforcement Learning Computation Offloading Algorithm in Mobile Cloud Computing. SSRN Electron. J. 2019. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of Deep Reinforcement Learning in Communications and Networking: A Survey. IEEE Commun. Surv. Tutorials 2019, 21, 3133–3174. [Google Scholar] [CrossRef] [Green Version]
- Alfakih, T.; Hassan, M.M.; Gumaei, A.; Savaglio, C.; Fortino, G. Task Offloading and Resource Allocation for Mobile Edge Computing by Deep Reinforcement Learning Based on SARSA. IEEE Access 2020, 8, 54074–54084. [Google Scholar] [CrossRef]
- Garí, Y.; Monge, D.A.; Pacini, E.; Mateos, C.; Garino, C.G. Reinforcement learning-based application Autoscaling in the Cloud: A survey. Eng. Appl. Artif. Intell. 2021, 102, 104288. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Rummery, G.A.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; University of Cambridge, Department of Engineering: Cambridge, UK, 1994; Volume 37. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Hirsch, M.; Mateos, C.; Rodriguez, J.M.; Zunino, A. DewSim: A trace-driven toolkit for simulating mobile device clusters in Dew computing environments. Softw. Pract. Exp. 2020, 50, 688–718. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef] [Green Version]
- Khan, W.Z.; Ahmed, E.; Hakak, S.; Yaqoob, I.; Ahmed, A. Edge computing: A survey. Future Gener. Comput. Syst. 2019, 97, 219–235. [Google Scholar] [CrossRef]
- Drolia, U.; Martins, R.; Tan, J.; Chheda, A.; Sanghavi, M.; Gandhi, R.; Narasimhan, P. The case for mobile edge-clouds. In Proceedings of the 2013 IEEE 10th International Conference on Ubiquitous Intelligence and Computing and 2013 IEEE 10th International Conference on Autonomic and Trusted Computing, Washington, DC, USA, 18–21 December 2013; pp. 209–215. [Google Scholar]
- Benedetto, J.I.; González, L.A.; Sanabria, P.; Neyem, A.; Navón, J. Towards a practical framework for code offloading in the Internet of Things. Future Gener. Comput. Syst. 2019, 92, 424–437. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Yu, W.; Liang, F.; He, X.; Hatcher, W.G.; Lu, C.; Lin, J.; Yang, X. A survey on the edge computing for the Internet of Things. IEEE Access 2017, 6, 6900–6919. [Google Scholar] [CrossRef]
- Olaniyan, R.; Fadahunsi, O.; Maheswaran, M.; Zhani, M.F. Opportunistic edge computing: Concepts, opportunities and research challenges. Future Gener. Comput. Syst. 2018, 89, 633–645. [Google Scholar] [CrossRef] [Green Version]
- Aslam, S.; Michaelides, M.P.; Herodotou, H. Internet of ships: A survey on architectures, emerging applications, and challenges. IEEE Internet Things J. 2020, 7, 9714–9727. [Google Scholar] [CrossRef]
- Hirsch, M.; Mateos, C.; Zunino, A. Practical criteria for scheduling CPU-bound jobs in mobile devices at the edge. In Proceedings of the 2018 IEEE International Conference on Cloud Engineering (IC2E), Orlando, FL, USA, 17–20 April 2018; pp. 340–345. [Google Scholar]
- Hirsch, M.; Rodriguez, J.M.; Zunino, A.; Mateos, C. Battery-aware centralized schedulers for CPU-bound jobs in mobile Grids. Perv. Mob. Comput. 2016, 29, 73–94. [Google Scholar] [CrossRef]
- Hirsch, M.; Mateos, C.; Rodriguez, J.M.; Zunino, A.; Garí, Y.; Monge, D.A. A performance comparison of data-aware heuristics for scheduling jobs in mobile grids. In Proceedings of the 2017 XLIII Latin American Computer Conference (CLEI), Cordoba, Argentina, 4–8 September 2017; pp. 1–8. [Google Scholar]
- Chen, X.; Pu, L.; Gao, L.; Wu, W.; Wu, D. Exploiting Massive D2D Collaboration for Energy-Efficient Mobile Edge Computing. IEEE Wirel. Commun. 2017, 24, 64–71. [Google Scholar] [CrossRef] [Green Version]
- Mtibaa, A.; Fahim, A.; Harras, K.A.; Ammar, M.H. Towards resource sharing in mobile device clouds. ACM SIGCOMM Comput. Commun. Rev. 2013, 43, 55–61. [Google Scholar] [CrossRef]
- Li, B.; Pei, Y.; Wu, H.; Shen, B. Heuristics to allocate high-performance cloudlets for computation offloading in mobile ad hoc clouds. J. Supercomput. 2015, 71, 3009–3036. [Google Scholar] [CrossRef]
- Chunlin, L.; Layuan, L. Exploiting composition of mobile devices for maximizing user QoS under energy constraints in mobile grid. Inf. Sci. 2014, 279, 654–670. [Google Scholar] [CrossRef]
- Birje, M.N.; Manvi, S.S.; Das, S.K. Reliable resources brokering scheme in wireless grids based on non-cooperative bargaining game. J. Netw. Comput. Appl. 2014, 39, 266–279. [Google Scholar] [CrossRef]
- Loke, S.W.; Napier, K.; Alali, A.; Fernando, N.; Rahayu, W. Mobile Computations with Surrounding Devices. ACM Trans. Embed. Comput. Syst. 2015, 14, 1–25. [Google Scholar] [CrossRef]
- Shah, S.C. Energy efficient and robust allocation of interdependent tasks on mobile ad hoc computational grid. Concurr. Comput. Pract. Exp. 2015, 27, 1226–1254. [Google Scholar] [CrossRef]
- Orhean, A.I.; Pop, F.; Raicu, I. New scheduling approach using reinforcement learning for heterogeneous distributed systems. J. Parallel Distrib. Comput. 2018, 117, 292–302. [Google Scholar] [CrossRef]
- Cheng, M.; Li, J.; Nazarian, S. DRL-cloud: Deep reinforcement learning-based resource provisioning and task scheduling for cloud service providers. In Proceedings of the 2018 23rd Asia and South Pacific Design Automation Conference (ASP-DAC), Jeju, Korea, 22–25 January 2018; pp. 129–134. [Google Scholar] [CrossRef]
- Huang, L.; Bi, S.; Zhang, Y.J.A. Deep Reinforcement Learning for Online Computation Offloading in Wireless Powered Mobile-Edge Computing Networks. IEEE Trans. Mob. Comput. 2020, 19, 2581–2593. [Google Scholar] [CrossRef] [Green Version]
- Zhao, R.; Wang, X.; Xia, J.; Fan, L. Deep reinforcement learning based mobile edge computing for intelligent Internet of Things. Phys. Commun. 2020, 43, 101184. [Google Scholar] [CrossRef]
- Tefera, G.; She, K.; Shelke, M.; Ahmed, A. Decentralized adaptive resource-aware computation offloading & caching for multi-access edge computing networks. Sustain. Comput. Inform. Syst. 2021, 30, 100555. [Google Scholar] [CrossRef]
- Baek, J.; Kaddoum, G. Heterogeneous task offloading and resource allocations via deep recurrent reinforcement learning in partial observable multifog networks. IEEE Internet Things J. 2020, 8, 1041–1056. [Google Scholar] [CrossRef]
- Lu, H.; Gu, C.; Luo, F.; Ding, W.; Liu, X. Optimization of lightweight task offloading strategy for mobile edge computing based on deep reinforcement learning. Future Gener. Comput. Syst. 2020, 102, 847–861. [Google Scholar] [CrossRef]
- Li, J.; Gao, H.; Lv, T.; Lu, Y. Deep reinforcement learning based computation offloading and resource allocation for MEC. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Ren, J.; Xu, S. DDPG Based Computation Offloading and Resource Allocation for MEC Systems with Energy Harvesting. In Proceedings of the 2021 IEEE 93rd Vehicular Technology Conference (VTC2021-Spring), Helsinki, Finland, 25–28 April 2021; pp. 1–5. [Google Scholar]
- Cobbe, K.; Klimov, O.; Hesse, C.; Kim, T.; Schulman, J. Quantifying generalization in reinforcement learning. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 1282–1289. [Google Scholar]
- Cobbe, K.; Hesse, C.; Hilton, J.; Schulman, J. Leveraging procedural generation to benchmark reinforcement learning. In Proceedings of the 37th International Conference on Machine Learning (ICML), Virtual, 13–18 July 2020; pp. 2048–2056. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Zhang, C.; Vinyals, O.; Munos, R.; Bengio, S. A study on overfitting in deep reinforcement learning. arXiv 2018, arXiv:1804.06893. [Google Scholar]
- Witty, S.; Lee, J.K.; Tosch, E.; Atrey, A.; Littman, M.; Jensen, D. Measuring and characterizing generalization in deep reinforcement learning. arXiv 2018, arXiv:1812.02868. [Google Scholar] [CrossRef]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust Region Policy Optimization. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Dhariwal, P.; Hesse, C.; Klimov, O.; Nichol, A.; Plappert, M.; Radford, A.; Schulman, J.; Sidor, S.; Wu, Y.; Zhokhov, P. OpenAI Baselines. 2017. Available online: https://github.com/openai/baselines (accessed on 1 November 2021).
- Machado, M.C.; Bellemare, M.G.; Talvitie, E.; Veness, J.; Hausknecht, M.; Bowling, M. Revisiting the arcade learning environment: Evaluation protocols and open problems for general agents. J. Artif. Intell. Res. 2018, 61, 523–562. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern recognition. In Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 128. [Google Scholar]
- Chen, L.; Lu, K.; Rajeswaran, A.; Lee, K.; Grover, A.; Laskin, M.; Abbeel, P.; Srinivas, A.; Mordatch, I. Decision transformer: Reinforcement learning via sequence modeling. Adv. Neural Inf. Process. Syst. 2021, 34, 15084–15097. [Google Scholar]
- Lazic, N.; Boutilier, C.; Lu, T.; Wong, E.; Roy, B.; Ryu, M.; Imwalle, G. Data center cooling using model-predictive control. In Proceedings of the 31st Conference on Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 3–8 December 2018; pp. 3814–3823. [Google Scholar]
- Pramanik, P.K.D.; Sinhababu, N.; Kwak, K.S.; Choudhury, P. Deep Learning Based Resource Availability Prediction for Local Mobile Crowd Computing. IEEE Access 2021, 9, 116647–116671. [Google Scholar] [CrossRef]
- Singh, P.; Kaur, A.; Aujla, G.S.; Batth, R.S.; Kanhere, S. Daas: Dew computing as a service for intelligent intrusion detection in edge-of-things ecosystem. IEEE Internet Things J. 2020, 8, 12569–12577. [Google Scholar] [CrossRef]
- Longo, M.; Hirsch, M.; Mateos, C.; Zunino, A. Towards integrating mobile devices into dew computing: A model for hour-wise prediction of energy availability. Information 2019, 10, 86. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | BPA | E-SEAS | RR | W-Rand | W-RR | PPO |
|---|---|---|---|---|---|---|
| 1500 jobs | 0.87 | 0.85 | 0.89 | 0.84 | 0.89 | 0.88 |
| 2500 jobs | 0.76 | 0.74 | 0.80 | 0.74 | 0.80 | 0.78 |
| Method | Train Set | Upward Generalization | ||||||
|---|---|---|---|---|---|---|---|---|
| Jobs: | 1500 j | 2500 j | 1500 j | 2500 j | 3500 j | 4500 j | 5500 j | 6500 j |
| BPA | 0.53 | 1.00 | 0.79 | 0.91 | 1.00 | 1.13 | 1.23 | 1.32 |
| E-SEAS | 0.52 | 0.85 | 0.74 | 0.82 | 0.86 | 0.94 | 1.02 | 1.09 |
| RR | 0.75 | 0.78 | 0.67 | 0.76 | 0.86 | 0.93 | 0.97 | 1.04 |
| W-Rand | 0.81 | 1.10 | 0.72 | 0.80 | 0.86 | 0.94 | 1.01 | 1.07 |
| W-RR | 1.04 | 1.28 | 0.68 | 0.77 | 0.84 | 0.90 | 0.97 | 1.01 |
| PPO-1500 | 1.73 | — | 1.35 | 1.46 | 1.35 | 1.25 | 1.18 | 1.14 |
| PPO-2500 | — | 1.60 | 1.06 | 1.23 | 1.23 | 1.21 | 1.19 | 1.17 |
| Method | Train Set | Upward Generalization | ||||
|---|---|---|---|---|---|---|
| Jobs: | 300–500 j | 300–500 j | 1000 j | 1500 j | 2000 j | 2500 j |
| BPA | — | 0.31 | 0.34 | 0.38 | 0.40 | 0.42 |
| E-SEAS | — | 0.31 | 0.30 | 0.33 | 0.35 | 0.37 |
| RR | — | 0.30 | 0.30 | 0.31 | 0.33 | 0.35 |
| W-Rand | — | 0.30 | 0.30 | 0.32 | 0.34 | 0.37 |
| W-RR | — | 0.30 | 0.29 | 0.31 | 0.33 | 0.34 |
| PPO | 0.54 | 0.55 | 0.52 | 0.47 | 0.44 | 0.43 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sanabria, P.; Tapia, T.F.; Toro Icarte, R.; Neyem, A. Solving Task Scheduling Problems in Dew Computing via Deep Reinforcement Learning. Appl. Sci. 2022, 12, 7137. https://doi.org/10.3390/app12147137
Sanabria P, Tapia TF, Toro Icarte R, Neyem A. Solving Task Scheduling Problems in Dew Computing via Deep Reinforcement Learning. Applied Sciences. 2022; 12(14):7137. https://doi.org/10.3390/app12147137
Chicago/Turabian StyleSanabria, Pablo, Tomás Felipe Tapia, Rodrigo Toro Icarte, and Andres Neyem. 2022. "Solving Task Scheduling Problems in Dew Computing via Deep Reinforcement Learning" Applied Sciences 12, no. 14: 7137. https://doi.org/10.3390/app12147137