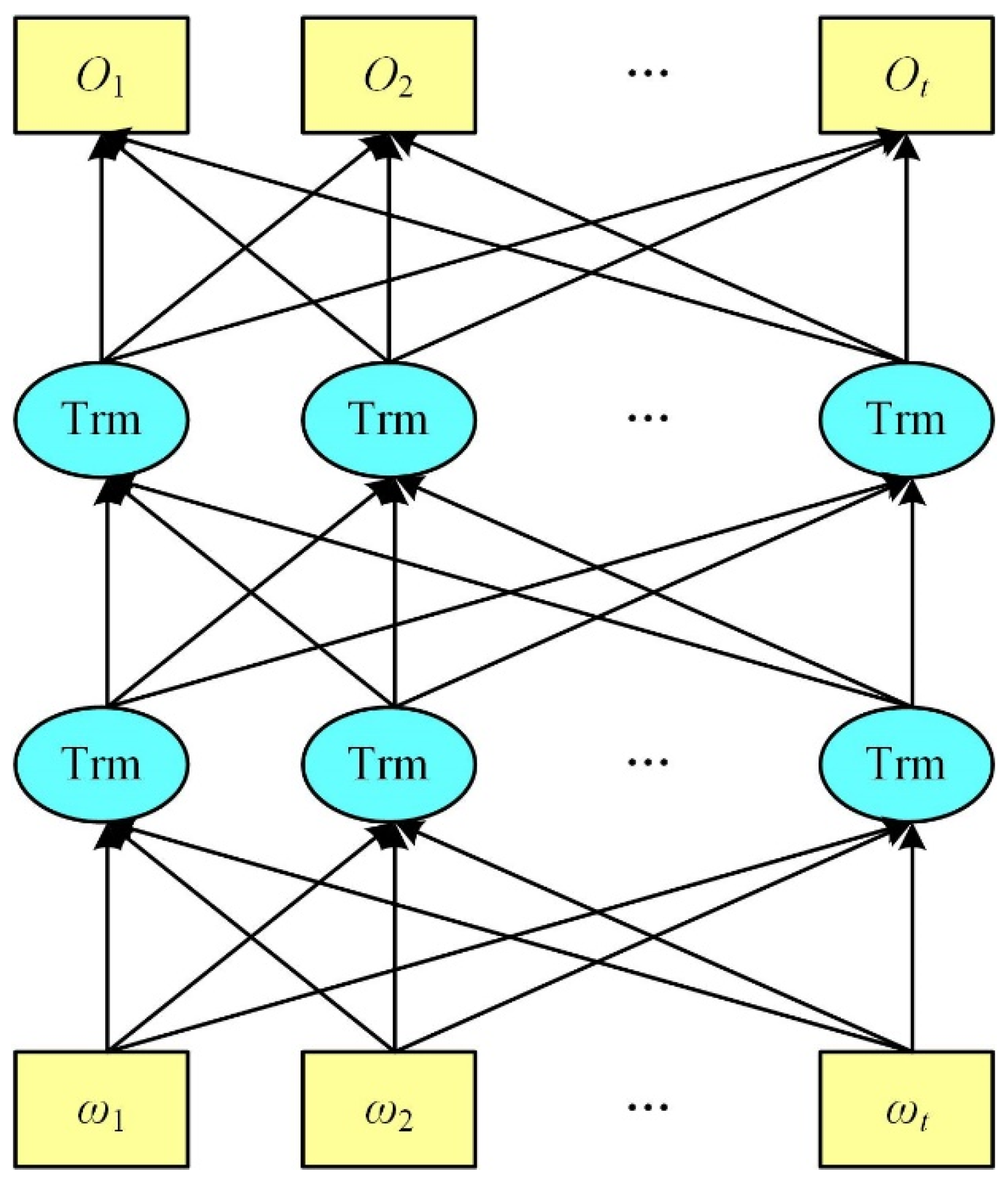
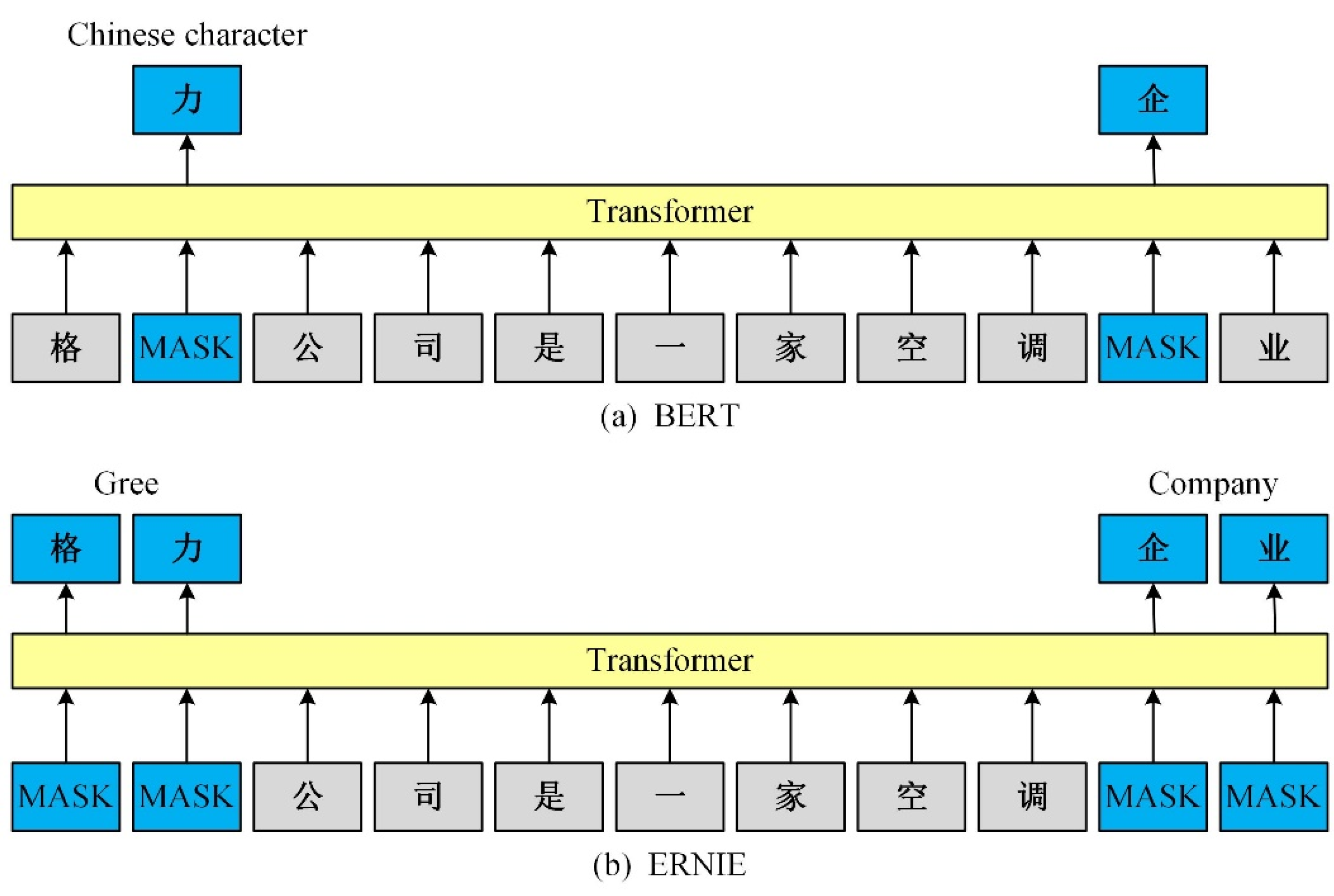
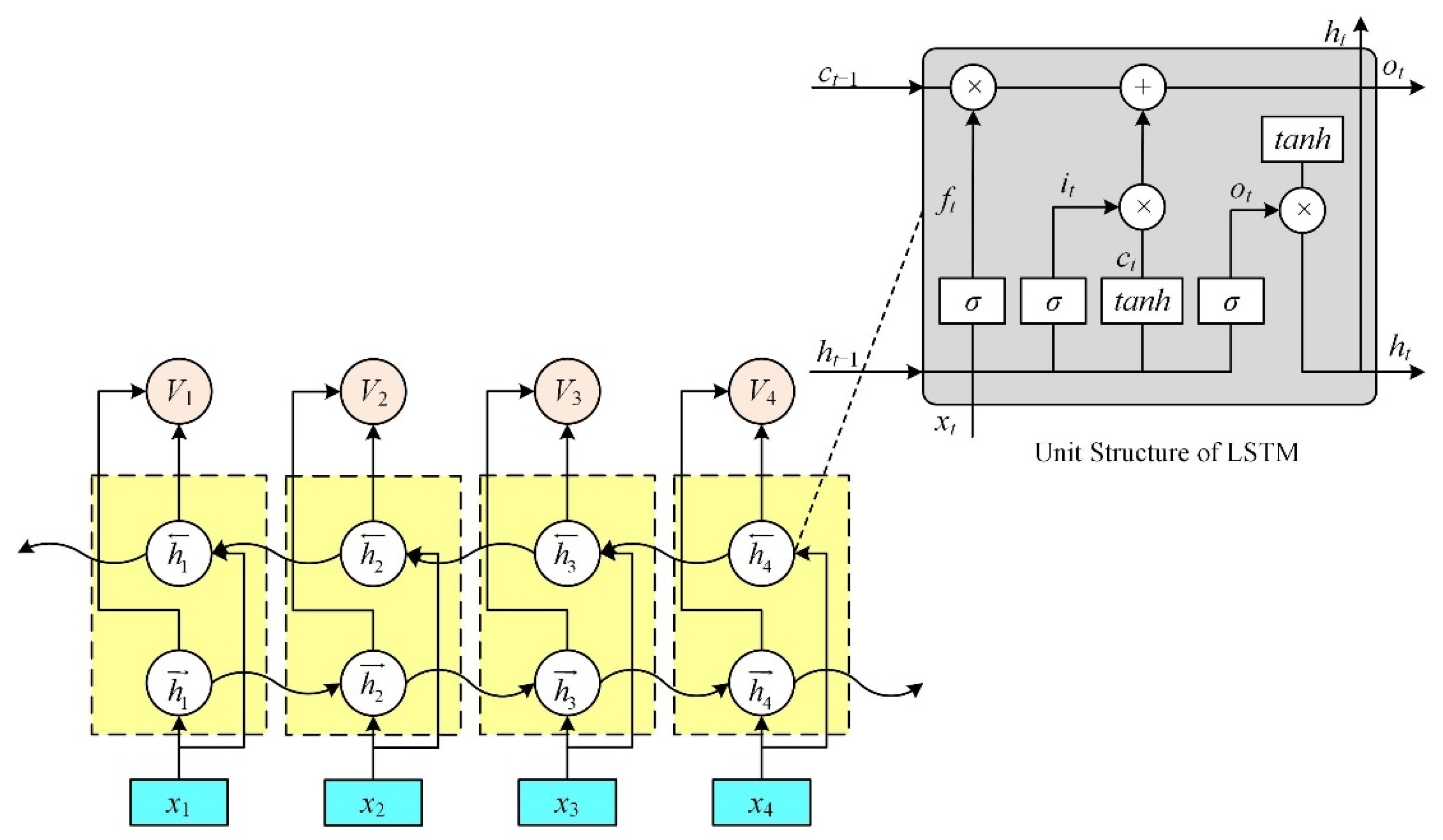
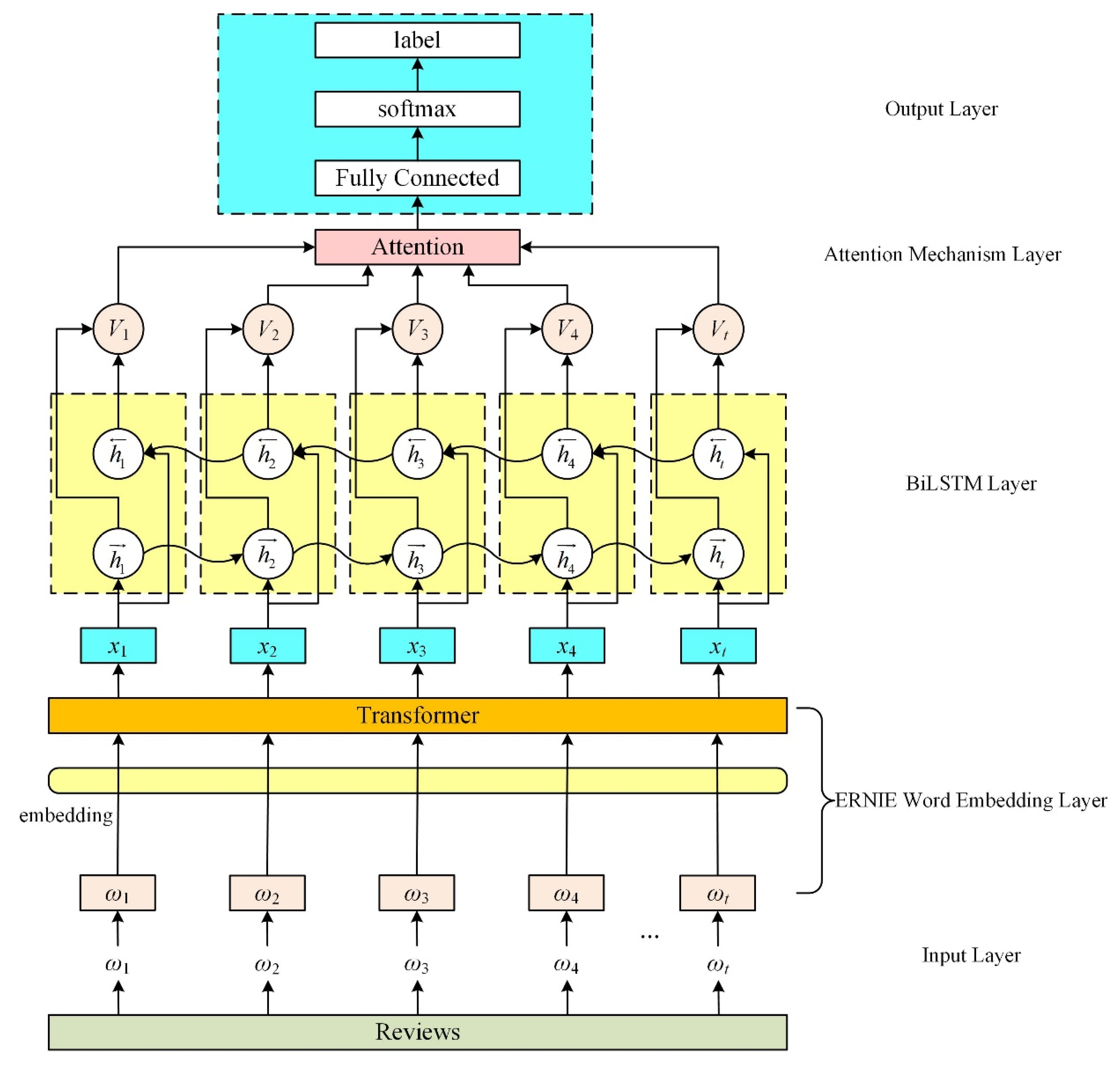
4.4. Performance Indicators
The performance indicators of precision (
P), recall (
R), and
F1 value are used to evaluate the sentiment analysis model; these performance indicators range from 0 to 1, and the closer to 1, the better the performance of the model. Precision (
P) represents the ratio of true correct samples in all the data predicted as correct samples; recall ® represents the ratio of predicted correct samples in actual correct samples.
F1 value trades off precision versus recall [
23], which can comprehensively reflect the performance of the model. However, the
F1 value is only applicable to the scenario with binary classification task, Macro
F1, Micro
F1, and Weighted
F1 are often used as performance indicators for multi-classification tasks. In this experiment, the
F1 value is calculated by weighted method, the Weighted
F1 value solves the problem that Macro
F1 does not consider the imbalance of samples, and the calculation formula is shown in Equation (18):
Here:
TP is True positive;
FP is False positive;
TN is True negative;
FN is False negative;
is the precision (P) of the i-th classification;
is the recall(R) of the i-th classification;
is the F1 value of the i-th classification;
is the proportion of the i-th classification sample to the total sample;
is the total number of classifications. In this experiment, = 3.
4.5. Results and Discussion
To evaluate the effectiveness of the EBLA model for sentiment analysis of e-commerce product reviews, we conducted two control experiments. The first group compares the sentiment analysis performance of models using different word embeddings, and the second group compares the sentiment analysis performance of different deep learning models.
- (1)
Comparative Experiment for Different Word Embedding Models
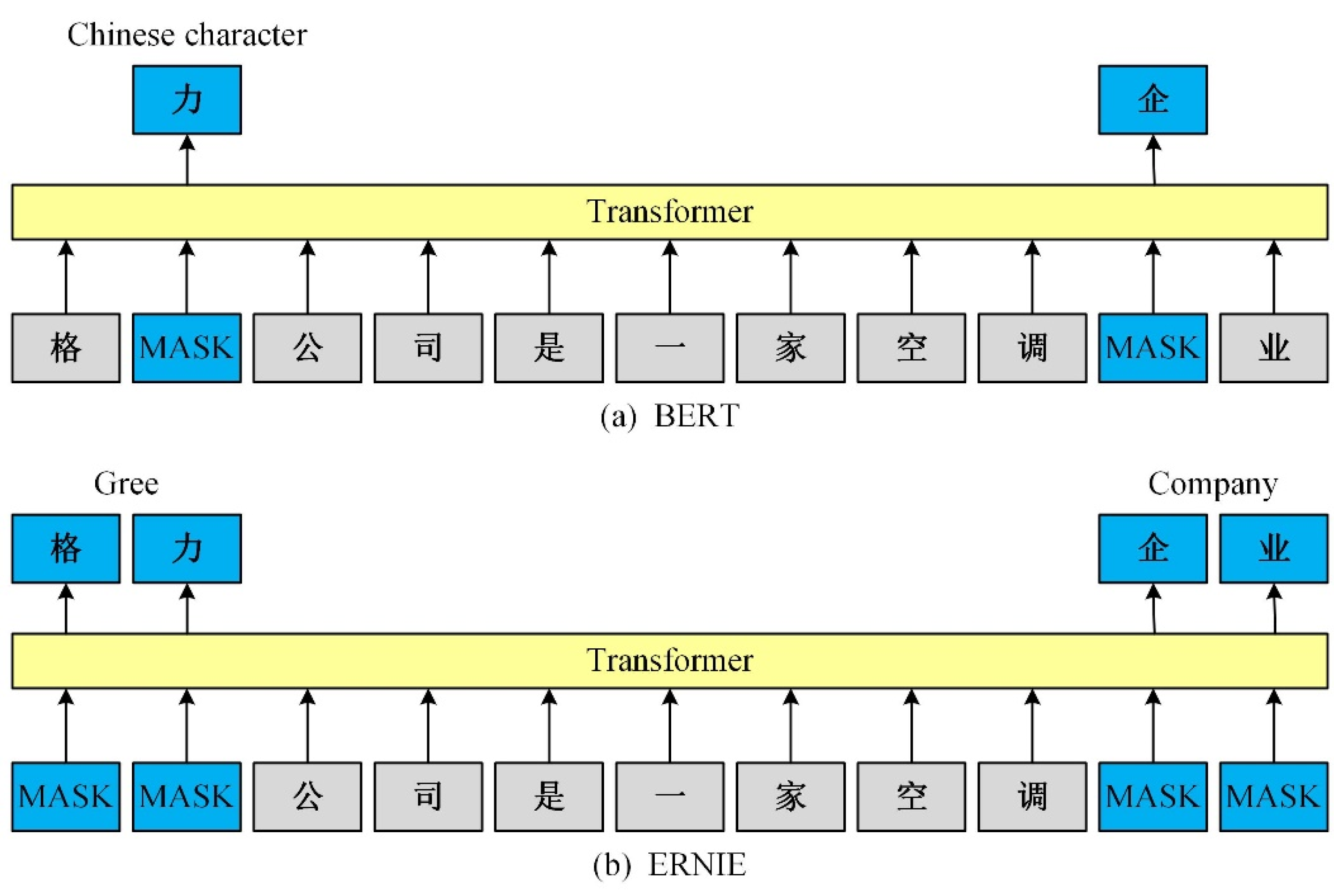
To verify that the ERNIE word embedding model has better semantic representation ability, we compared its performance with that of Word2Vec and BERT word embedding models. ERNIE used the ERNIE1.0 Chinese pre-training model published by Baidu with the word vector dimension of 768. BERT used the BERT-base network structure launched by Google with the word vector dimension of 768. Word2Vec used the Chinese word vector “Chinese Word Vector” constructed by Li [
24] with the word vector dimension of 300. In this experiment, we divided the word embedding model into two combined deep learning models: TextCNN and BiLSTM-Att. The experimental results are shown in
Table 4.
The experimental results show that compared with the traditional static word embedding model Word2Vec, dynamic word embedding models, such as BERT and ERNIE, can dynamically adjust the different semantic representations of a word using the text context information, thereby effectively solving the polysemy problem of the static word vector.
- (2)
Comparative Experiment of Different Sentiment Analysis Model
To verify the effectiveness of this model in sentiment analysis of e-commerce product reviews, the sentiment classification performance of different models was compared in the same experimental environment. ERNIE adopted the ERNIE1.0 Chinese pre-training model released by Baidu, and other traditional deep learning models adopted Word2Vec constructs word vectors.
Table 5 shows the experimental results of the experiment.
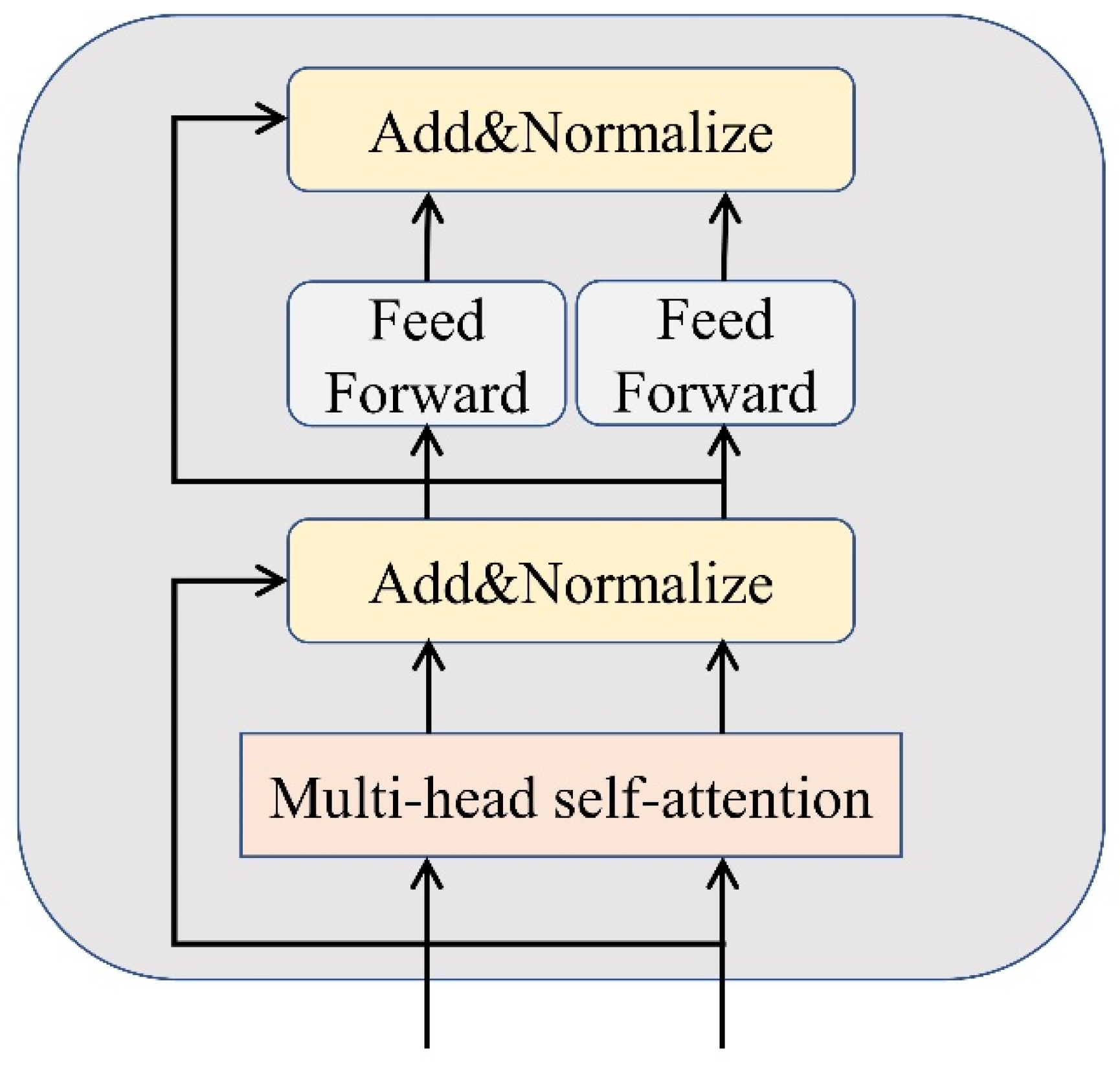
BiLSTM: Bidirectional long short-term memory network, the forward hidden layer vector, and the backward hidden layer vector sum were obtained using the forward LSTM and backward LSTM modules, respectively, then both were spliced to obtain the hidden layer vector. Finally, the output is connected to the softmax function for sentiment classification.
TextCNN: This is a convolutional neural network for text classification, including convolutional and maximum pooling layers, and finally, the output is connected to a softmax function for sentiment classification.
RCNN: Here, the convolution layer in the general convolutional neural network is replaced with a BiLSTM network, and finally, the maximum pooling layer is taken and the output is connected to the softmax function for sentiment classification.
BiLSTM-Att: The attention mechanism is introduced using the BiLSTM network to obtain features highly relevant to the training task, and finally, the output is connected to an external softmax function for sentiment classification.
ERNIE: The ERNIE pre-training model adds [CLS] symbols and uses the corresponding output as the semantic representation of the text. Finally, the output is connected to a softmax function for sentiment classification.
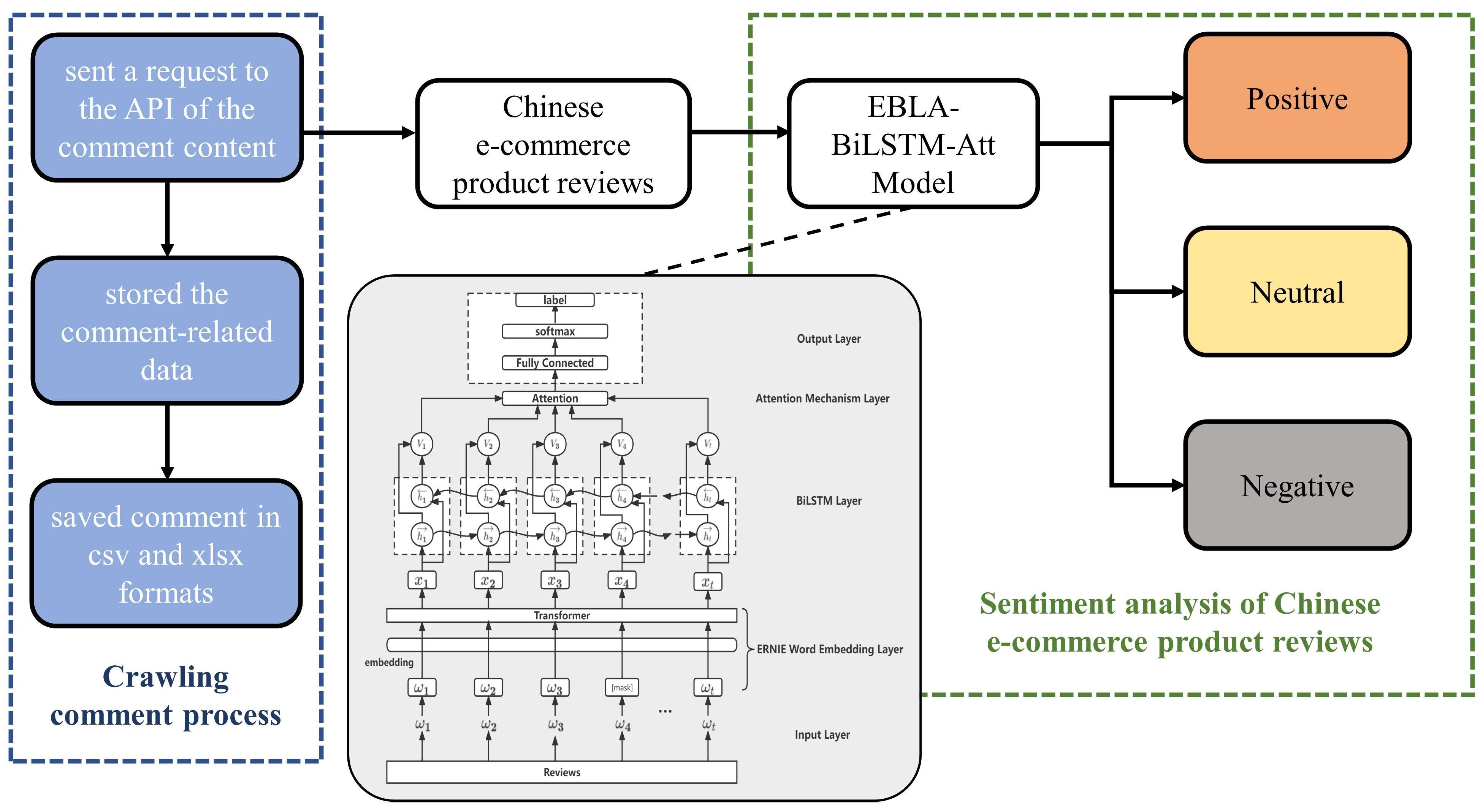
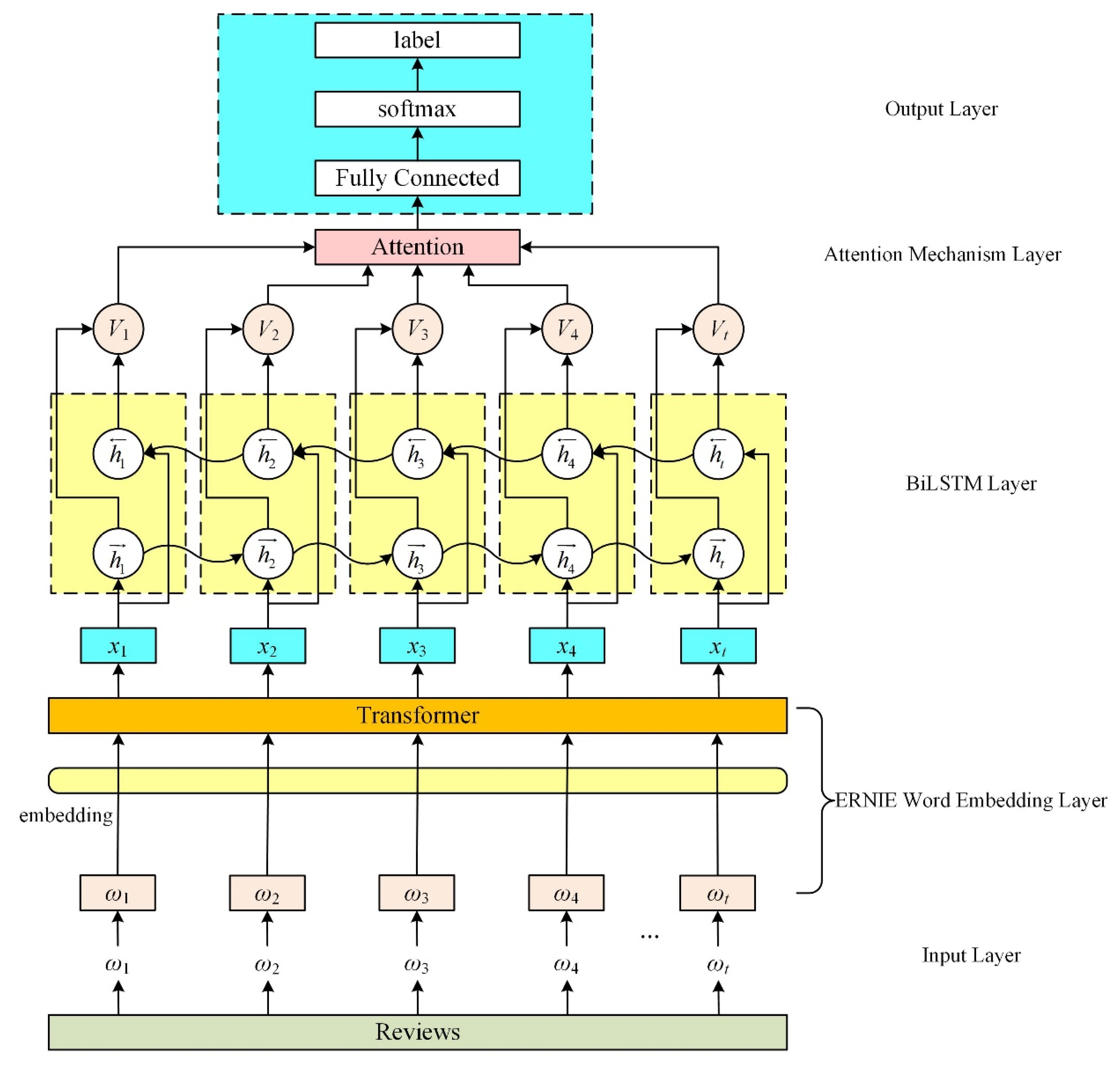
ERNIE-BiLSTM: After the input text is vectorized and represented by the word embedding model ERNIE, it is input to the BiLSTM model to extract features, and finally, the output is externally connected to the softmax function for sentiment classification.
ERNIE-RCNN: After the input text is vectorized and represented by the ERNIE word embedding model, it is input to the RCNN model to extract features, and finally, the output is externally connected to the softmax function for sentiment classification.
ERNIE-CNN: After the input text is vectorized and represented by the ERNIE word embedding model, it is input to the TextCNN model to extract features, and finally, the output is externally connected to the softmax function for sentiment classification.
EBLA: After the input text is vectorized and represented by the ERNIE word embedding model, it is input to the BiLSTM-Att model to extract features, and finally, the output is externally connected to the softmax function for sentiment classification.
From the experimental results, all the metrics of TextCNN are optimal for the neural network using traditional static word embedding. This is attributed to the TextCNN model having a simple structure, which only contains a convolution layer and a maximum pooling layer. Therefore, it has a good classification effect on the small corpus. The introduction of the maximum pooling layer of TextCNN reduces the risk of overfitting, reduces parameters, speeds up the calculation speed, and obtains better experimental results. The worst effect is the BiLSTM model, which can be explained by analyzing the principle of its model structure. Its structure contains two LSTM layers with several model parameters, and the corresponding amount of data required is relatively large. The amount of data collected in this paper is small, so the effect is poor. However, after adding the attention mechanism (BiLSTM-Att), the classification effect significantly improved, indicating that the attention mechanism enables the model to learn more important features, thereby improving the performance of the neural network. Additionally, compared with the neural network using the traditional static word embedding, the neural network built with the ERNIE word embedding model greatly improved its classification effect, with an average increase of 6.7% in precision, 5.82% in recall, and 6.17% in F1 value. Furthermore, it shows that the ERNIE word embedding model has a strong semantic representation ability, and achieved good results in dealing with the dimension mapping and polysemy problems in the Chinese e-commerce product review. The combination of ERNIE and BiLSTM-Att effectively improved the performance of model sentiment classification.
The EBLA model used in this paper achieved the best results in the sentiment analysis experiment of the Chinese e-commerce product reviews. Compared with the BiLSTM, TextCNN, RCNN, BiLSTM-Att, ERNIE, ERNIE-BiLSTM, ERNIE-CNN, and ERNIE-RCNN models, the F1 value of the EBLA model increased by 13.04%, 4.15%, 6.13%, 5.9%, 0.97%, 0.96%, 1.12%, and 2.47%, respectively. The EBLA model, too, achieves more than 0.87 in precision, recall, and F1 values, and it can be seen that this model has an excellent performance on the sentiment analysis task of the Chinese e-commerce product reviews.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}