
Boosting the Transformer with the BERT Supervision in Low-Resource Machine Translation


Abstract
:1. Introduction
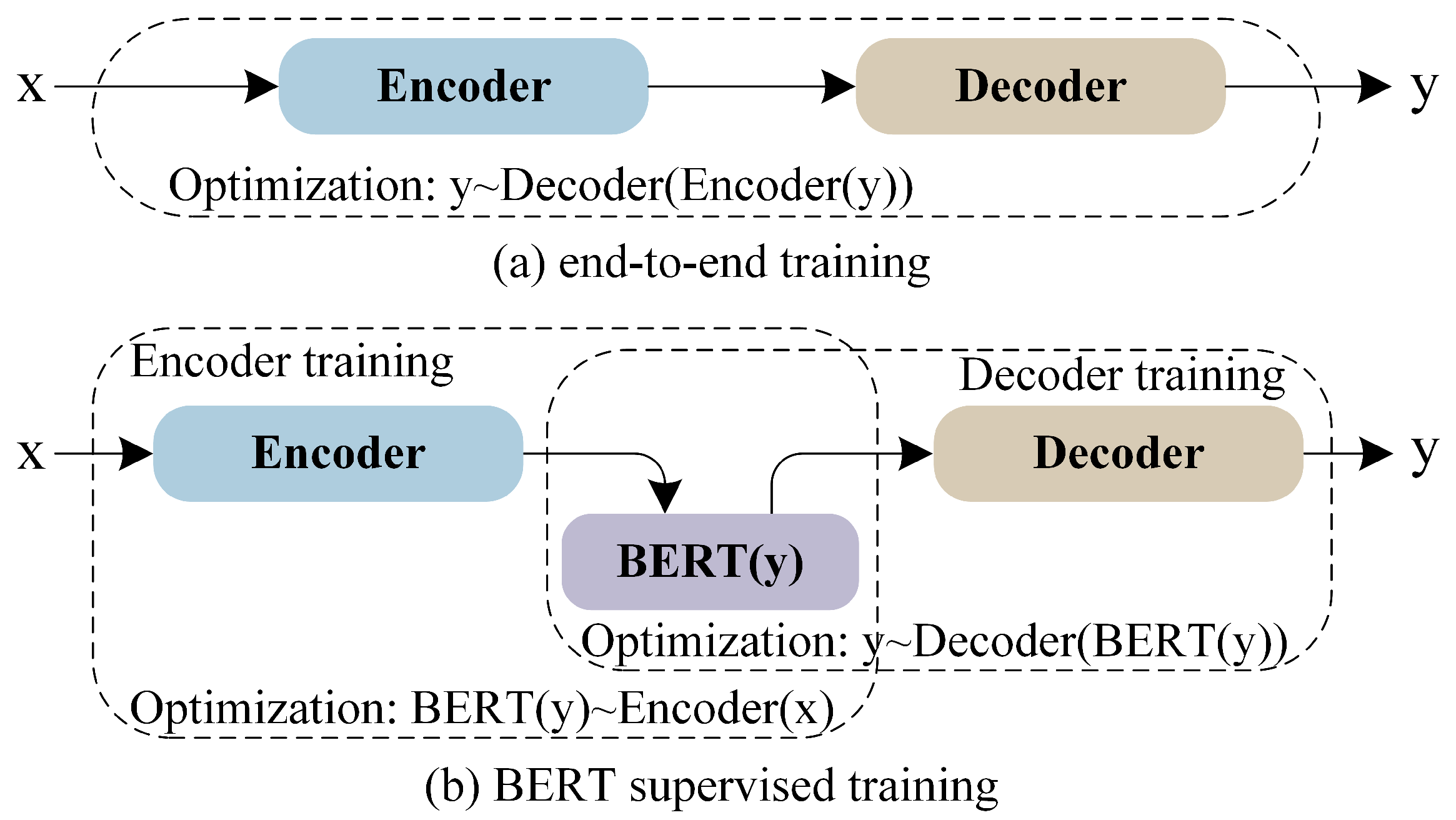
- We boost the Transformer by adding the BERT constraint on the latent representation in low-resource machine translation. As such, we design a training algorithm to optimize the Transformer in a multi-step way, including encoder training, decoder training, and joint optimization. It alleviates the mismatch problem between the capacity of the Transformer and the training data size in low-resource machine translation.
- We provide a new way to incorporate the pre-trained language models in machine translation. Compared to the BERT-fused methods, a significant advantage of our approach is that it improves the performance of the Transformer in low-resource translation tasks without changing its structure and increasing the number of parameters.
- Adding BERT supervision enables us to further improve the Transformer with a large-scale monolingual target language dataset in the sense of a low parallel corpus but a high monolingual target language corpus.
2. Related Work
2.1. Transformer and Its Variants
2.2. MT Methods with Pre-Training Language Models
2.3. Low-Resource Machine Translation Models
3. Approach
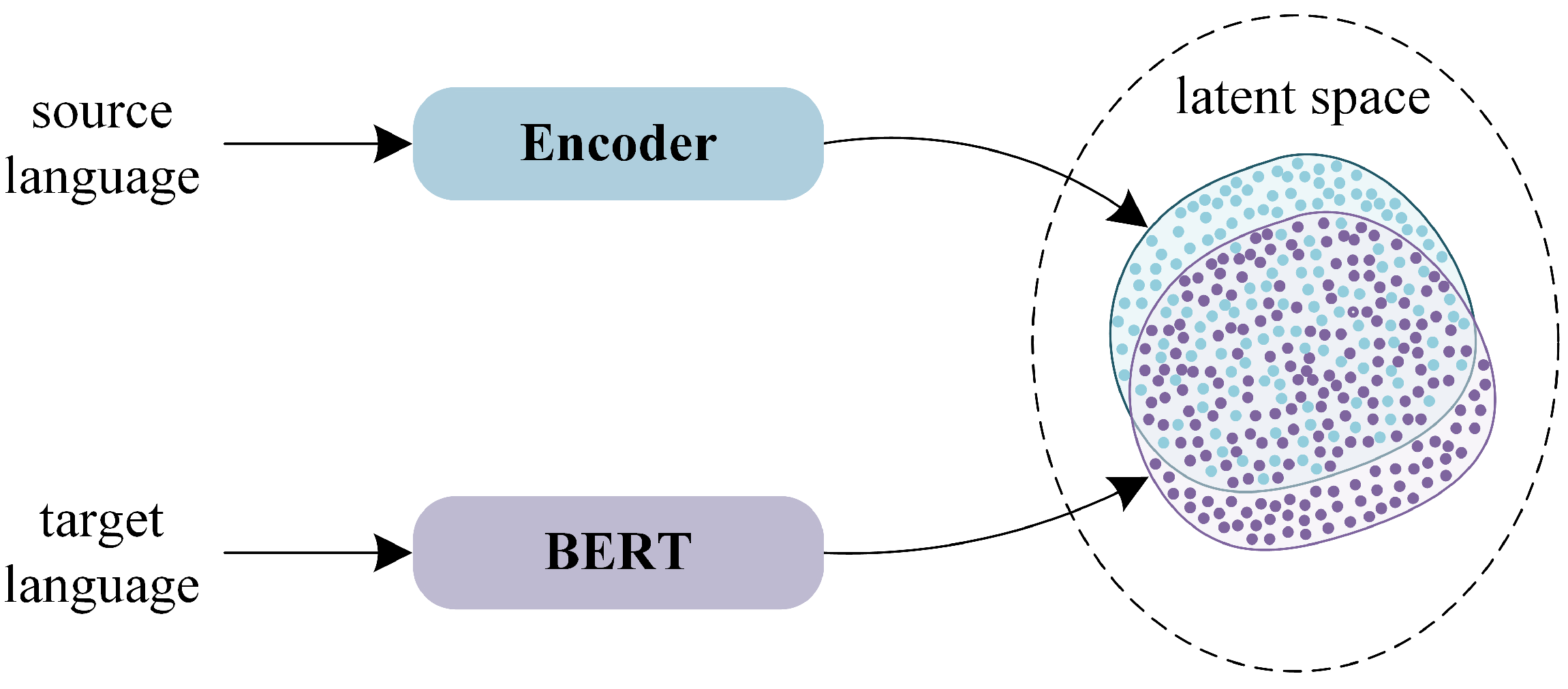
3.1. Latent Representation Using the BERT
3.2. Training Algorithm
| Algorithm 1 The Training Algorithm |
| Data set construction: |
|
|
| using data set A |
3.2.1. Encoder Training
3.2.2. Decoder Training
3.2.3. Joint Optimization
4. Experimental Setting
4.1. Data and Metric
4.2. Implementation Details
4.3. Baselines
5. Results and Discussion
5.1. Comparison with Baselines
5.2. Effectiveness of Joint Optimization
5.3. Effectiveness of the BERT Fine-Tuning
5.4. Effectiveness of the Large-Scale Monolingual Corpus of the Target Language
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1724–1734. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 1412–1421. [Google Scholar]
- Sun, H.; Wang, R.; Chen, K.; Utiyama, M.; Sumita, E.; Zhao, T. Unsupervised Bilingual Word Embedding Agreement for Unsupervised Neural Machine Translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 1235–1245. [Google Scholar]
- Britz, D.; Goldie, A.; Luong, M.T.; Le, Q. Massive Exploration of Neural Machine Translation Architectures. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 1442–1451. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1243–1252. [Google Scholar]
- Ramesh, S.H.; Sankaranarayanan, K.P. Neural Machine Translation for Low Resource Languages using Bilingual Lexicon Induced from Comparable Corpora. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Student Research Workshop, New Orleans, LA, USA, 2–4 June 2018; Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 112–119. [Google Scholar]
- Lignos, C.; Cohen, D.; Lien, Y.C.; Mehta, P.; Croft, W.B.; Miller, S. The Challenges of Optimizing Machine Translation for Low Resource Cross-Language Information Retrieval. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 3497–3502. [Google Scholar]
- Nguyen, T.Q.; Chiang, D. Transfer Learning across Low-Resource, Related Languages for Neural Machine Translation. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Taipei, Taiwan, 27 November–1 December 2017; Asian Federation of Natural Language Processing: Taipei, Taiwan, 2017; pp. 296–301. [Google Scholar]
- Kim, Y.; Gao, Y.; Ney, H. Effective Cross-lingual Transfer of Neural Machine Translation Models without Shared Vocabularies. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1246–1257. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Pan, X.; Wang, M.; Wu, L.; Li, L. Contrastive Learning for Many-to-many Multilingual Neural Machine Translation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual Event, 1–6 August 2021; pp. 244–258. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Improving Neural Machine Translation Models with Monolingual Data. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 86–96. [Google Scholar] [CrossRef]
- Baldi, P.; Vershynin, R. The capacity of feedforward neural networks. Neural Netw. 2019, 116, 288–311. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, J.; Xia, Y.; Wu, L.; He, D.; Qin, T.; Zhou, W.; Li, H.; Liu, T. Incorporating BERT into Neural Machine Translation. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Song, K.; Tan, X.; Qin, T.; Lu, J.; Liu, T.Y. MASS: Masked Sequence to Sequence Pre-training for Language Generation. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 5926–5936. [Google Scholar]
- Conneau, A.; Lample, G. Cross-lingual language model pretraining. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Clinchant, S.; Jung, K.W.; Nikoulina, V. On the use of BERT for Neural Machine Translation. In Proceedings of the 3rd Workshop on Neural Generation and Translation, Hong Kong, China, 4 November 2019; pp. 108–117. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Weng, R.; Wei, H.; Huang, S.; Yu, H.; Bing, L.; Luo, W.; Chen, J. Gret: Global representation enhanced transformer. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9258–9265. [Google Scholar]
- Bapna, A.; Chen, M.; Firat, O.; Cao, Y.; Wu, Y. Training Deeper Neural Machine Translation Models with Transparent Attention. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 3028–3033. [Google Scholar]
- Wang, Q.; Li, B.; Xiao, T.; Zhu, J.; Li, C.; Wong, D.F.; Chao, L.S. Learning Deep Transformer Models for Machine Translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 1810–1822. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the NAACL-HLT, New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5753–5763. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Yang, J.; Wang, M.; Zhou, H.; Zhao, C.; Zhang, W.; Yu, Y.; Li, L. Towards making the most of bert in neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9378–9385. [Google Scholar]
- Zoph, B.; Yuret, D.; May, J.; Knight, K. Transfer Learning for Low-Resource Neural Machine Translation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1568–1575. [Google Scholar]
- Ahmadnia, B.; Serrano, J.; Haffari, G. Persian-Spanish Low-Resource Statistical Machine Translation Through English as Pivot Language. In Proceedings of the International Conference Recent Advances in Natural Language Processing, RANLP, Varna, Bulgaria, 2–8 September 2017; INCOMA Ltd.: Varna, Bulgaria, 2017; pp. 24–30. [Google Scholar]
- He, D.; Xia, Y.; Qin, T.; Wang, L.; Yu, N.; Liu, T.Y.; Ma, W.Y. Dual learning for machine translation. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Ahmadnia, B.; Dorr, B.J. Augmenting neural machine translation through round-trip training approach. Open Comput. Sci. 2019, 9, 268–278. [Google Scholar] [CrossRef]
- Xu, T.; Ozbek, O.I.; Marks, S.; Korrapati, S.; Ahmadnia, B. Spanish-Turkish Low-Resource Machine Translation: Unsupervised Learning vs Round-Tripping. Am. J. Artif. Intell. 2020, 4, 42–49. [Google Scholar] [CrossRef]
- Chronopoulou, A.; Stojanovski, D.; Fraser, A. Improving the lexical ability of pretrained language models for unsupervised neural machine translation. arXiv 2021, arXiv:2103.10531. [Google Scholar]
- Atrio, À.R.; Popescu-Belis, A. On the Interaction of Regularization Factors in Low-resource Neural Machine Translation. In Proceedings of the 23rd Annual Conference of the European Association for Machine Translation, Ghent, Belgium, 1–3 June 2022; European Association for Machine Translation: Ghent, Belgium, 2022; pp. 111–120. [Google Scholar]
- Qi, Y.; Sachan, D.; Felix, M.; Padmanabhan, S.; Neubig, G. When and Why Are Pre-Trained Word Embeddings Useful for Neural Machine Translation? In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 529–535. [Google Scholar]
- Wang, Y.; Zhai, C.; Awadalla, H.H. Multi-task Learning for Multilingual Neural Machine Translation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1022–1034. [Google Scholar]
- Tang, Y.; Tran, C.; Li, X.; Chen, P.J.; Goyal, N.; Chaudhary, V.; Gu, J.; Fan, A. Multilingual translation from denoising pre-training. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 3450–3466. [Google Scholar]
- Chi, Z.; Dong, L.; Ma, S.; Huang, S.; Singhal, S.; Mao, X.L.; Huang, H.Y.; Song, X.; Wei, F. mT6: Multilingual Pretrained Text-to-Text Transformer with Translation Pairs. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 7–11 November 2021; pp. 1671–1683. [Google Scholar]
- Rothe, S.; Narayan, S.; Severyn, A. Leveraging pre-trained checkpoints for sequence generation tasks. Trans. Assoc. Comput. Linguist. 2020, 8, 264–280. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2019, arXiv:abs/1910.03771. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. Comput. Sci. 2015. [Google Scholar] [CrossRef]
- Dou, Z.Y.; Tu, Z.; Wang, X.; Shi, S.; Zhang, T. Exploiting Deep Representations for Neural Machine Translation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 4253–4262. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-Attention with Relative Position Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 464–468. [Google Scholar]

{kind=link}
{kind=link}
| Category | Models | Key Idea |
|---|---|---|
| Transformer and its variants | NMT-JL [20], Seq2Seq [1] | Advancing the translation quality via neural networks and attention mechanisms. |
| Attention is all you need [3] | It relies entirely on an attention mechanism to draw global dependencies between sources. | |
| GRET [21] | A novel global representation enhanced the Transformer to model the global representation explicitly in the Transformer. | |
| Transparent [22] | The encoder layers were combined just after the encoding is completed but not during the encoding process. | |
| DLCL [23] | An approach based on a dynamic linear combination of layers to memorizing the features extracted from all preceding layers. | |
| MT Methods with Pre-training Language Models | Elmo [24], Xlnet [25], Roberta [26], GPT [27] | The pre-training language models are effective for the machine learning. |
| BERT [12] | Designing the BERT to pre-train deep bidirectional encoder representations from unlabeled text to produce contextualized embedding. | |
| MASS [17] | Adopting the encoder–decoder framework to reconstruct a sentence fragment with the remaining part of the sentence. | |
| [28] | Integrating the pre-trained LMs to neural machine translation. | |
| NMT-BERT [19] | The pre-trained models should be exploited for supervised neural machine translation. | |
| BERT-fused [16] | Using BERT to extract representations for input sequences. Then the representations are fused with each layer of the NMT model through attention mechanisms. | |
|
Low-resource Machine Translation Models | NMT-TL [29] | Proposing transfer learning for NMT. |
| NMT-EPL [30] | Utilizing English as a bridging language. | |
| DLMT [31] | Dual-learning mechanism for machine translation. | |
| NMT-RT [32] | A new round-tripping approach. | |
| NMT-Attention [33] | An unsupervised method based on an attentional NMT system. | |
| NMT-lexically aligned [34] | Optimizing the cross-lingual alignment of word embeddings on unsupervised Macedonian–English and Albanian–English. | |
| NMT-regularization factors [35] | Exploring the roles and interactions of the hyperparameters governing regularization. |
| Approaches | De→En | Ro→En | Vi→En | De→Zh | Ko→Zh | Ru→Zh | |
|---|---|---|---|---|---|---|---|
| Transformer- based Methods | Transformer (base) | 34.98 | 32.06 | 27.87 | 27.88 | 30.24 | 25.43 |
| Transformer (big) | 34.85 | 31.98 | 27.82 | 27.79 | 30.28 | 25.35 | |
| Transformer-based transfer learning | 35.01 | 32.10 | 27.75 | 27.72 | 30.13 | 25.15 | |
| RelPos | 35.12 | 32.15 | 28.57 | 28.12 | 30.51 | 25.69 | |
| DeepRepre | 35.41 | 32.27 | 28.48 | 28.35 | 30.59 | 26.14 | |
| Incorporating Bert Methods | Bert-fused NMT | 36.34 | 32.35 | 29.04 | 28.82 | 30.79 | 26.29 |
| Ours | 36.45 | 32.86 | 29.65 | 29.17 | 31.24 | 26.57 | |
| Approaches | Parameters | Avg. Time |
|---|---|---|
| Transformer (base) | 87 M | 1.0× |
| Transformer (big) | 124 M | 1.29× |
| Transformer-based transfer learning | 87 M | 1.0× |
| DeepRepre | 111 M | 1.25× |
| RelPos | 87 M | 1.0× |
| BERT-fused NMT | 197 M | 1.41× |
| Ours | 87 M | 1.0× |
| De→ En | |
|---|---|
| Source | Und warum? Weil sie Dreiecke verstehen und sich-selbst-ver stärkende geometrische Muster sind der Schlüssel um stabile Strukturen zu bauen. |
| Target | And why? Because they understand triangles and self-reinforcing geometric patterns are the key to building stable structures. |
| Transformer(base) | And why? Because they understand triangles and self-reinforcing geometric patterns, they are crucial to building stable structures. |
| Ours | And why? Because they understand triangles and self-reinforcing geometric patterns are key to building stable structures. |
| Ro→En | |
| Source | Ban și-a exprimat regretul c divizrile în consiliu și între poporul sirian și puterile regionale “au fcut aceast situație de nerezolvat”. |
| Target | He expressed regret that divisions in the council and among the Syrian people and regional powers “made this situation unsolvable”. |
| Transformer(base) | Ban expressed regret that the divisions in the council and between the Syrian people and the regional powers “have made this situation unresolved”. |
| Ours | Ban expressed regret that divisions in the council and between the Syrian people and regional powers “have made this situation intractable”. |
| Vi→En | |
| Source |  |
| Target | All the dollars were allocated and extra tuition in English and mathematics was budgeted for regardless of what missed out, which was usually new clothes; they were always secondhand. |
| Transformer(base) | Every dollar is considered and English and math tutoring is set separately no matter what is deducted, usually new clothes; our clothes are always second-hand. |
| Ours | All the money was allocated, extra English and math tuition was budgeted, whatever was missed, usually new clothes; they were always second-hand. |
| Models | De→En | Ro→En | Vi→En | De→Zh | Ko→Zh | Ru→Zh | |
|---|---|---|---|---|---|---|---|
| Transformer (base) | 34.84 | 32.06 | 27.87 | 27.88 | 30.24 | 25.43 | |
| Ours | EncT + DecT | 30.88 | 26.51 | 22.11 | 22.82 | 25.33 | 18.95 |
| EncT + DecT + JO (40 epoch) | 33.77 | 31.19 | 28.12 | 27.58 | 28.71 | 23.23 | |
| EncT + DecT + JO (80 epoch) | 35.28 | 31.67 | 28.38 | 28.03 | 29.59 | 25.87 | |
| EncT + DecT + JO (full training) | 36.38 | 32.86 | 29.65 | 29.17 | 31.24 | 26.57 | |
| Strategy | De→En | Ro→En | Vi→En | De→Zh | Ko→Zh | Ru→Zh |
|---|---|---|---|---|---|---|
| BERT frozen | 35.86 | 32.46 | 29.08 | 28.76 | 30.81 | 26.29 |
| BERT fine-tuning | 36.38 | 32.86 | 29.65 | 29.17 | 31.24 | 26.57 |
| Approaches | De→En |
|---|---|
| EncT + DecT | 30.88 |
| EncT + DecT(+TED) | 31.33 |
| EncT + DecT(+WMT) | 31.27 |
| EncT + DecT(+TED) + JO | 35.87 |
| EncT + DecT(+WMT) + JO | 35.35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, R.; Li, J.; Su, X.; Wang, X.; Gao, G. Boosting the Transformer with the BERT Supervision in Low-Resource Machine Translation. Appl. Sci. 2022, 12, 7195. https://doi.org/10.3390/app12147195
Yan R, Li J, Su X, Wang X, Gao G. Boosting the Transformer with the BERT Supervision in Low-Resource Machine Translation. Applied Sciences. 2022; 12(14):7195. https://doi.org/10.3390/app12147195
Chicago/Turabian StyleYan, Rong, Jiang Li, Xiangdong Su, Xiaoming Wang, and Guanglai Gao. 2022. "Boosting the Transformer with the BERT Supervision in Low-Resource Machine Translation" Applied Sciences 12, no. 14: 7195. https://doi.org/10.3390/app12147195
APA StyleYan, R., Li, J., Su, X., Wang, X., & Gao, G. (2022). Boosting the Transformer with the BERT Supervision in Low-Resource Machine Translation. Applied Sciences, 12(14), 7195. https://doi.org/10.3390/app12147195