1. Introduction
Trained convolutional neural networks (CNNs) are among the dominant and most accurate tools for automatic image classification [
1]. Nevertheless, they can be fooled by attacks [
2] following particular scenarios, which can lead to classification errors in adversarial images. In the present work, we mainly consider the target scenario. Given a trained CNN
and an ancestor image
classified by
as belonging to category
, it first consists of choosing a target category
. Then, the attack perturbs
to create an adversarial image
, which not only is classified by
as belonging to category
but also is humanly indistinguishable from
.
Attacks are classified into three groups depending on the amount of information that the attackers have at their disposal. Gradient-based attacks (see e.g., [
3,
4,
5,
6,
7]) have complete knowledge of
, its explicit architecture, its layers, and their respective weights. The insider knowledge of the CNN is much more limited for transfer-based attacks (see e.g., [
8,
9,
10]). They create a model mirroring
, which they attack with gradient-based methods, leading to adversarial images that also fool
. Score-based attacks (see [
11,
12]) are the least demanding of all. The training data, model architecture, and parameters of the CNN are unknown to them. They only require
’s predicted output label values for either all or a subset of object categories.
This study aims to gain insights into the functioning of adversarial attacks by analyzing the adversarial images, on the one hand, and the reactions of CNNs when exposed to adversarial images, on the other hand. These analyses and comparisons are performed from different perspectives: the behavior while looking at smaller regions, the noise frequency, the transferability, the changes in image texture, and the penultimate layer activations. The reasons for considering these perspectives are as follows. The first question we attempt to answer is whether adversarial attacks make use of texture change to fool CNNs. This texture issue is related to the frequency of the noise in the sense that changes in the image texture are reflected by the input of high-frequency noise [
13]. This issue is also related to what occurs at smaller image regions, as texture modifications should also be noticed at these levels. The transferability issue measures the extent to which the adversarial noise is specific to the attacked CNN or to the training data. Finally, studying the behavior of the penultimate layers of the addressed CNNs provides a close look at the direction of the adversarial noise with respect to each object category.
This insight is addressed through a thorough experimental study. We selected 10 CNNs that are very diverse in terms of architecture, number of layers, etc. These CNNs are trained on the ImageNet dataset to sort images with sizes of
into 1000 categories. We then intentionally chose two attacks that are on opposing edges of the attacks’ classification. More precisely, here, we consider the gradient-based BIM [
3] and the score-based
[
14,
15,
16,
17], with both having high success rates against CNNs trained on ImageNet [
14,
18].
We run these two algorithms to fool the 10 CNNs, with the additional very-demanding requirement that, for an image to be considered adversarial, its -label value should exceed . We start with 10 random pairs of ancestor and target categories and 10 random ancestor images in each , hence 100 ancestor images altogether. Out of the 1000 performed runs per attack, the two attacks succeeded for 84 common ancestors, leading to 2 distinct groups (one for each attack) of 437 adversarial images coming from these 84 convenient ancestors. The adversarial images and the 10 CNNs are then analyzed and compared from the abovementioned perspectives. Each of these perspectives is addressed in a dedicated section containing the specific obtained outcomes.
We first analyze whether the adversarial noise introduced by the EA and BIM has an adversarial impact at regions of smaller sizes. We also explore whether this local noise alone is sufficient to mislead the CNN, either individually or globally, but in a shuffled manner. To the best of our knowledge, we are the first to study the image level at which the attacks’ noise becomes adversarial.
Additionally, we provide a visualization of the noise that the EA and BIM add to an ancestor image to produce an adversarial image. In particular, we identify the frequencies of the noise introduced by the EA and BIM and, among them, those that are key to the adversarial nature of the images created by each of the two attacks. In contrast, in [
19], the authors studied the noise introduced by several attacks and found that it is in the high-frequency range; their study was limited to attacks on CNNs trained on Cifar-10. Since Cifar-10 contains images of considerably smaller sizes than the images of ImageNet, the results of that noise frequency study differed considerably. Another study [
20], performed on both abovementioned datasets, found that adversarial attacks are not necessarily a high-frequency phenomenon. Here, we further prove that the EA attack introduces white noise, while the BIM attack actually introduces predominantly low-frequency noise. Moreover, with both attacks, we find that, irrespective of the types of noise they introduce, the lower part of the spectrum is responsible for carrying adversarial information.
We next explore the texture changes introduced by the attacks in relation to the transferability of the adversarial images from one CNN to another. The issue is to clarify whether adversarial images are specific to their targeted CNN or whether they contain rather general features that are perceivable by others. It has been proven that ImageNet-trained CNNs are biased towards texture [
21], while CNNs that have been adversarially trained to become robust against attacks have a bias towards shape [
22]. However, here, we attempt to find whether texture change is an underlying mechanism of attacks, to evaluate the degree to which it participates in fooling a CNN, and to check whether CNNs with differing amounts of texture bias agree on which image modifications have the largest adversarial impact. We find that texture change takes place in the attacks’ perturbation of the images, but that this texture change is not necessarily responsible for fooling the CNNs. However, our results show that adversarial images are more likely to transfer to CNNs that have higher texture biases.
Previous work on the transferability of a gradient-based FGSM [
4] attack has proven that, while untargeted attacks transfer easily, targeted attacks have a very low transferability rate [
9]. Here, we provide the first study of the transferability of a targeted gradient-based BIM as well as of a targeted black-box EA. We find that, in both cases, transferability is extremely low.
In another direction related to transferability, the authors of [
23] specifically perturbed certain features of intermediate CNN layers and compared the transferability of the adversarial images targeting different intermediate features. They proved that perturbing features in early CNN layers result in more transferability than perturbing features in later CNN layers. It is also known that early CNN layers capture more textural information found in smaller image regions, whereas later CNN layers capture more shape-related information found in larger image regions [
24]. Considering the two statements above, we create the EA and BIM adversarial images that target the last CNN layers and explore whether the adversarial noise at smaller image regions is less CNN-specific, hence more transferable, than the noise at the full-image scale. This issue is addressed in two ways. First, we check whether and how a modification of the adversarial noise intensity affects the
and the
-label values predicted by a CNN when fed with a different CNN’s adversarial image, and the influence of shuffling in this process. Second, we keep the adversarial noise as it is (meaning without changing its intensity), and we check whether adversarial images are more likely to transfer when they are shuffled.
Finally, we delve inside the CNNs and study the changes that adversarial images produce in the activation of the CNNs’ penultimate layers. A somewhat similar study was performed in [
25], where the activations at all layers were visualized for one CNN trained on Cifar-10. Here, rather than performing a visualization of the intermediate activations, we attempt to quantify the precise nature of the changes made on the path to reaching a high probability for the target class in the final layer. We find that both attacks introduce noise that increases the activation of the positively related
units and (perhaps simultaneously) increases the activation of negatively related
units.
The paper is organized as follows:
Section 2 defines the concept of a
-strong adversarial image and briefly describes the two attacks used here, namely the EA and BIM. We explain the criteria leading to the selection of the 10 CNNs, the ancestor and target categories, as well as the choice of the ancestor images in each category. In
Section 3, we study the impact of the two attacks’ adversarial noise at smaller image regions. In
Section 4, we perform the study of the noise frequency.
Section 5 explores the texture changes introduced by the two attacks, while the transferability of their generated adversarial images is pursued in
Section 6. Moreover, the activation of the CNNs’ penultimate layers is analyzed in
Section 7. The concluding
Section 8 summarizes our results and describes some future research directions. This study is completed by two appendices.
Appendix A displays all considered ancestors, the convenient ancestors, and some
-strong adversarial images obtained by the EA and BIM.
Appendix B contains a series of tables and graphs supporting our findings.
3. Local Effect of the Adversarial Noise on the Target CNN
Here, we analyze whether the adversarial noise introduced by the EA and by BIM also has an adversarial effect at regions of smaller sizes and whether this local effect alone would be sufficient to mislead the CNNs, either individually (
Section 3.1) or globally but in a “patchwork” way (
Section 3.2).
3.1. Is Each Individual Patch Adversarial?
To examine the adversarial effect of local image areas, we replace non-overlapping
,
,
, and
patches of the ancestors with patches taken from the same location in their adversarial versions (this process is performed for BIM and for the EA separately), one patch at a time, starting from the top-left corner. Said otherwise, each step leads to a new hybrid image
I that coincides with the ancestor image
everywhere except for one patch taken at the same emplacement from the adversarial
. At each step, the hybrid image
I is sent to
to extract the
and
-label values:
and
.
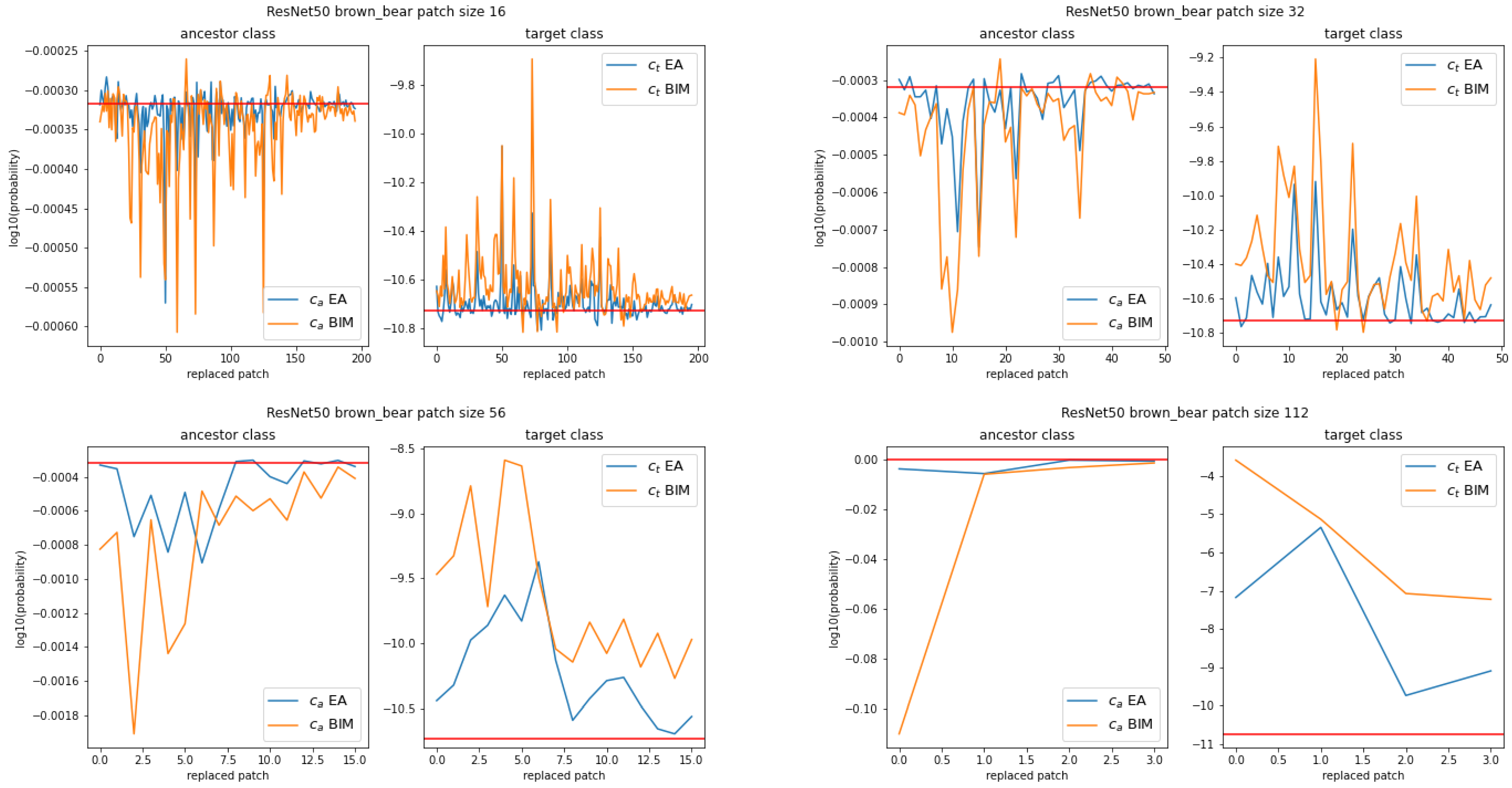
Figure 1 shows an example of the plots of these successive
and
-label values, step-by-step, for the ancestor image
, the CNN
, and the adversarial images obtained by the EA and BIM. The behavior illustrated in this example is representative of what happens for all ancestors and CNNs.
For all values of s and both attacks, almost all patches individually increase the -label value and decrease the -label value. The fact that the peaks often coincide between the EA and BIM proves that modifying the ancestor in some image areas rather than others can make a large difference. However, BIM’s effect is usually larger than the EA’s. Note also that no single patch is sufficient to fool the CNNs in the sense that it would create a hybrid image with a dominating -label value.
3.2. Is the Global Random Aggregation of Local Adversarial Effect Sufficient to Fool the CNNs?
First, replacing all patches simultaneously and at the correct location is, by definition, enough for a targeted misclassification, since its completion leads to the adversarial image. Second, most of the patches taken individually have a local adversarial impact, but none are sufficient to individually achieve a targeted attack.
The issue addressed here is whether the global aggregation of the local adversarial effect is strong enough, independent of the location of the patches, to create the global adversarial effect that we are aiming at.
We proceed as follows. Given an image I and an integer s such that patches of size create a partition of I, is a shuffled image deduced from I by randomly swapping all its patches. With these notations, (with or ) is sent to CNN. One obtains the and -label values as well as the dominant category (which may differ from ). The values of s used in our tests are 16, 32, 56, and 112, leading to partitions of the images into 196, 49, 16, and 4 patches, respectively.
Table 2 gives the outcome of these tests. For each value
s, each cell is composed of a triplet of numbers. The left one corresponds to the tests with the ancestor images, the middle one corresponds to the tests with images obtained by the EA, and the right one corresponds to the tests with images obtained by BIM. Each number is the percentage of images
or of images
taken for all ancestor images
, all (ancestor and target) category pairs, and all
, which are classified in category
c, where
c is the ancestor category
, the target category
, or any other class. To allow for comparisons, the randomly selected swapping order of the patches is performed only once per value of
s. For each
s, this uniquely defined sequence is applied in the same manner to create the
,
, and
shuffled images.
Contrary to what occurs with and 112, the proportion of shuffled ancestors classified as is negligible for . Therefore, seems to lead to patches that are too small for a image to allow for a meaningful comparison between the ancestor and adversarials and is consequently disregarded in the remainder of this subsection. At all other values of s, the classification of the shuffled adversarial image as a class different from ( or other) is more common with BIM than with the EA. With , it is noticeable that as many as 41.8% of BIM shuffled adversarials still produce targeted misclassifications. Enlarging s from 56 to 112 dramatically increases the proportion of shuffled adversarials classified as with BIM (with a modest increase with the EA) and as with the EA (with a modest increase with BIM). Moreover, the shuffled EA adversarials behave similarly to the shuffled ancestors, the probability of which increases considerably as the size of the patches grows larger and the original object becomes clearer (despite its shuffled aspect).
3.3. Summary of the Outcomes
Both the EA and BIM attacks have an adversarial local effect, even at patch sizes as small as , but they generally require the image to be at full scale in order to be adversarial in the targeted sense. However, the difference between the attacks is that as the patch size increases (without reaching full scale and while being subject to a shuffling process) and the shape consequently becomes more obvious (even despite shuffling), the EA’s noise has a lower adversarial effect, while BIM’s -meaningful noise actually accumulates and has a higher global adversarial effect.
4. Adversarial Noise Visualization and Frequency Analysis
This section first attempts to provide a visualization of the noise that the EA and BIM add to an ancestor image to produce an adversarial image (
Section 4.1). We then look more thoroughly at the frequencies of the noise introduced by the EA and BIM (
Section 4.2). Finally, we look for the frequencies that are key to the adversarial nature of an image created by the
and by BIM (
Section 4.3).
4.1. Adversarial Noise Visualization
The visualization of the noise that
and BIM add to
to create the
-strong adversarial images
and
is performed in two steps. First, the difference
between each adversarial image and its ancestor is computed for each RGB channel. Second, a histogram of the adversarial noise is displayed. This leads to the measurement of the magnitude of each pixel modification. An example, typical of the general behavior regardless of the channel, is illustrated in
Figure 2, showing the noise (the fact that the dominating colors of the noise representation displayed in
Figure 2 are green, yellow, and purple stems from the ’viridis’ setting in Python’s matplotlib library, which could be changed at will, but still, the scale gives the amplitude of the noise per pixel in the range
and hence justifies the position of the observed colors) and histogram of the perturbations added to the red channel of
to fool
with the EA and BIM.
Recall that both attacks perform pixel perturbations with a maximum perturbation magnitude of
(see
Section 2.4). However, with BIM, the smaller magnitudes dominate the histogram and the adversarial noise is closer to a uniform distribution with the EA. Another difference is that, whereas with BIM, all pixels are modified, a considerable number of pixels (9.3% on average) are not modified at all with the EA. Overall, there is a larger variety of noise magnitudes with the EA than with BIM, which can also be observed visually in the image display of the noise.
4.2. Assessment of the Frequencies Present in the Adversarial Noise
With the adversarial perturbations
having been assessed (
Section 4.1) for each RGB channel, we proceed to an analysis of the frequencies present in the adversarial noise per channel. Specifically, the Discrete Fourier Transform (DFT) is used to obtain the 2D magnitude spectra of the adversarial perturbations. We compute two quantities: magn (diff)
, and diff (magn)
.
Figure 3 displays a typical example of the general outcome regarding the adversarial noise in the red channel added by the EA or by BIM. For each image, the low frequencies are represented in the center, the high frequencies are represented in the corners, and the vertical bar (on the right) maps the frequency magnitudes to the colors shown in the image.
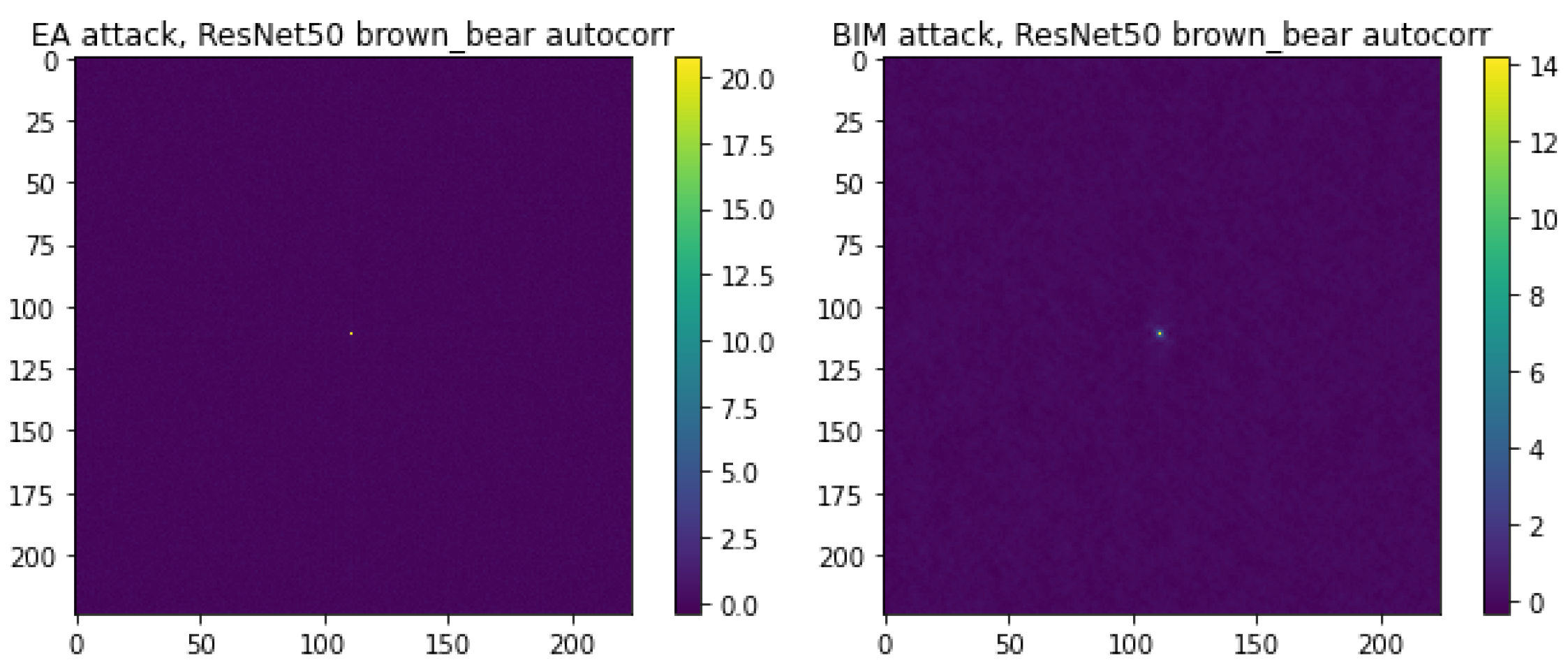
A clear difference between the EA and BIM is visible from the magn (diff) visualizations. With the EA, the high magnitudes do not appear to be concentrated in any part of the spectrum (with the exception of occasional high magnitudes in the center), indicating the white noise nature of the added perturbations. Supporting evidence for the white noise nature of the EA comes from the
autocorrelation of the noise.
Figure 4 shows that the
autocorrelation for both attacks have a peak at lag 0, which is expected. It turns out that this is the only peak when one considers the EA, which is no longer the case when considering BIM. Unfortunately, this is difficult to see in
Figure 4, since the central peak takes very high values; hence, the other peaks fade away in comparison. With BIM, the magn (diff) visualizations display considerably higher magnitudes for the low frequencies, indicating that BIM primarily uses low-frequency noise to create adversarial images.
In the case of diff (magn), both the EA and BIM exhibit larger magnitudes at high frequencies than at low frequencies. This can be interpreted as a larger effect of the adversarial noise on the high frequencies than on the low frequencies. Natural images from ImageNet have significantly more low-frequency than high-frequency information [
20]. Therefore, even a quasi-uniform noise (such as the EA’s) has a proportionally larger effect on the components that are numerically less present than on the more numerous ones.
4.3. Band-Stop Filtering Shuffled and Unshuffled Images: Which Frequencies Make an Image Adversarial?
Thus far, the results of this study have revealed the quantity of all frequency components present in the adversarial perturbations, but their relevance to the attack effectiveness is still unknown. To address this issue, we band-stop filter the adversarial images to eliminate various frequency ranges and check the effect produced on the CNN predictions. To evaluate the proportion of low vs. high frequencies of the noise introduced by the two attacks, the process is repeated with the shuffled adversarials for and 112.
We first obtain the DFT of all shuffled or unshuffled ancestor and adversarial images, followed by filtering with band-stop filters of 10 different frequency ranges
, where the range center
goes from 15 to 115 units per pixel, with steps of 10, and the bandwidth
is fixed to 30 units per pixel. For example, the last band-stop filter
removes frequencies in the range of
units per pixel. The band-stopped images are passed through the Inverse DFT (IDFT) and sent to the CNN, which results in 10 pairs of
-label values for each image, be it an ancestor or an adversarial.
Figure 5 presents some results that are typical of the general behavior.
For both the EA and BIM, the
probability tends to increase as
increases. This means that lower frequencies have a larger impact on the adversarial classification than higher frequencies. As shown in the left column of each pair of graphs, it is the low frequencies that matter for the correct classification of the ancestor, as well. Although with both attacks, the
probability tends to increase at higher values of
, with BIM, it is dominant at considerably smaller values of
, whereas the EA adversarials are usually still classified as
. Hence, the EA adversarials require almost the full spectrum of perturbations to fool the CNNs, whereas the lower part of the spectrum is sufficient for BIM adversarials. This result matches those of magn (diff) in
Figure 3, where the EA and BIM were found to introduce white and predominantly low-frequency noise, respectively.
As for the shuffled images, it is clear that their low-frequency features are affected by the shuffling process, and as a result, the probability cannot increase to the extent it does in the unshuffled images. With BIM and , at high rcs, the band-stop graphs show a slower increase in the probability than when the images are not shuffled. This implies that a large part of the BIM adversarial image’s low-frequency noise is meaningful only for the unshuffled image. When this low-frequency noise changes location through the shuffling process, one needs to gather noise across a broader bandwidth to significantly increase the probability of the shuffled adversarial.
Even if the BIM adversarials require a larger bandwidth to be adversarial when shuffled, they still reach this goal. In contrast, the shuffled EA adversarials have band-stop graphs that closely resemble the shuffled ancestors’ graph. Only BIM’s remaining low and middle frequencies are meaningful enough to and still manage to increase the probability.
4.4. Summary of the Outcomes
The histogram of the adversarial noise introduced by BIM follows a bell shape (hence smaller magnitudes dominate), while it is closer to a uniform distribution with the EA (hence with a larger variety of noise magnitudes in this case). In addition, BIM modifies all pixels, while the EA leaves many (approximately 14,000 out of , hence 9.3% on average) unchanged.
In terms of the frequency of the adversarial noise, the EA introduces white noise (meaning that all possible frequencies occur with equal magnitude), while BIM introduces predominantly low-frequency noise. Although for both attacks, the lower frequencies have the highest adversarial impact, the low and middle frequencies are considerably more effective with BIM than with the EA.
5. Transferability and Texture Bias
This section examines whether adversarial images are specific to their targeted CNN or whether they contain rather general features that are perceivable by other CNNs (
Section 5.1). Since ImageNet-trained CNNs are biased towards texture [
21], it is natural to ask whether adversarial attacks take advantage of this property. More precisely, we examine whether texture is changed by the EA and BIM and whether this could be the common “feature” perceived by all CNNs (
Section 5.2). Using heatmaps, we evaluate whether CNNs with differing amounts of texture bias agree on which image modifications have the largest adversarial impact and whether texture bias plays any role in transferability (
Section 5.3).
5.1. Transferability of Adversarial Images between the 10 CNNs
For each attack , we check the transferability of the adversarial images as follows. Starting from an ancestor image , we input the image, which is adversarial against , to a different (hence, ). We then extract the probability of the dominant category, the probability, and the probability given by for that image.
Then, we check whether the predicted class is precisely (targeted transferability) or if it is any other class different from both and . Out of all possible CNN pairs, our experiments showed that none of the adversarial images created by the EA for one CNN are classified by another as , while this phenomenon occurs for 5.4% of the adversarial images created by BIM. As for classification in a category , the percentages are 5.5% and 3.2% for the EA and BIM, respectively.
5.2. How Does CNNs’ Texture Bias Influence Transferability?
Knowing that CNNs trained on ImageNet are biased towards texture, we assume that a high probability for a particular class given by such a CNN expresses the fact that the input image contains more of that class’s texture. Our goal is to check whether this occurs for adversarial images as well.
We restrict our study to adversarial images obtained by the EA and BIM for the following three CNNs, which have a similar architecture and have been proven [
24] to gradually have less texture bias and less reliance on their texture-encoding neurons:
BagNet-17 [
33],
ResNet-50, and
ResNet-50-SIN [
21]. The experiments amount to checking the transferability of the adversarial images between these three CNNs. The fact that the statement about the graduation is fully proven only for these three justifies that we limit our study to them, since no such hierarchy is known for other CNNs in general.
Even in this case of three CNNs with similar architectures, the experiments show that targeted transferability between the three CNNs is 0%, regardless of the attack. Consequently, checking whether
becomes dominant for another CNN is unnecessary. Instead, we calculate the difference produced in a CNN’s predictions of the
and
probabilities between the ancestor and another CNN’s adversarial image. The average results over all images are presented in
Table 3.
When transferring from ResNet-50 to BagNet-17, the experiments show that the -label value decreases while the -label value increases, with the former being larger in magnitude than the latter. If the assumption formulated in the first paragraph holds, this phenomenon implies that the attacks change image texture. However, the similarly low transferability from BagNet-17 to ResNet-50 proves that texture change is not sufficient to generate adversarial images. The texture change observed in ResNet-50 adversarials might simply be a side effect of the perturbations created by the EA and BIM.
Nevertheless,
Table 3 reveals that texture bias seems to play a role in transferability. It shows that the more texture-biased the CNN that the adversarial images are transferred to, the larger the decrease in its
-label values. Indeed, this
decrease is larger when transferring from
ResNet-50-SIN to
ResNet-50 and from
ResNet-50 to
BagNet-17 than vice-versa.
5.3. How Does Texture Change Relate to Adversarial Impact on the CNNs?
In this subsection, BagNet-17 is used to visualize, thanks to heatmaps, whether texture change correlates with the adversarial impact of the obtained images for the 10 CNNs .
Although we have seen that both attacks affect BagNet-17’s probability on average, here, we attempt to find the image areas in which these changes are most prominent and to compare the locations in the adversarials that have the largest impact on BagNet-17 and on .
To achieve this, we proceed in a similar manner as in
Section 3.1, with the difference that we allow overlaps. We replace all overlapping
patches of the ancestor
with patches from the same location in
, a single patch at a time, and we extract and store the
and
probabilities given by
of the obtained hybrid image
I at each step. Contrary to the situation in
Section 3.1, note that there are as many patches as pixels in this case. Simultaneously, these patches are also fed to BagNet-17 (leading to 50,176 predictions for each adversarial image) to extract the
and
-label values of these patches. The stored
and
label values (and combinations of them) can be displayed in a square box of size
(hence of sizes equal to the size of the handled images), resulting in a heatmap.
More precisely, given an ancestor image , all hybrid adversarial images obtained as above via the EA lead to 5 heatmaps, and all those obtained by BIM lead to 5 heatmaps as well. For both attacks, the first four heatmaps are obtained using BagNet-17, and the fifth is obtained using for comparison purposes. Each heatmap assesses the 10% largest variations in the following sense.
We have the first sequence of -label values obtained from the evaluation by BagNet-17 of the patches of the adversarial images and a second similar sequence of -label values coming from the patches of the ancestor images. Both sequences are naturally indexed by the same successive patch locations P. We then consider that the sequence, also indexed by the patches, was made up of the differences . The selection of locations of the smallest 10% out of this sequence of differences leads to the first heatmap. One proceeds similarly for the second heatmap by selecting the location of the largest 10% of the values of (with obvious notations). The process is similar for the third and fourth heatmaps, where one considers the location of the largest 10% of the values of for the third heatmap and of the values of for the fourth heatmap.
Finally, the fifth heatmap is obtained by considering the largest 10% of the values , where the two members of the difference are the -label values given by the CNN for a full image: the right one for the ancestor image and the left one for the hybrid image, obtained as explained above.
Figure 6 shows the outcome of this process for
= ResNet-50 and ancestor
(see
Figure A5 in
Appendix B.1 for other examples).
Figure 6a shows the adversarial images
(top) and
(bottom).
Figure 6b–e are the four heatmaps obtained thanks to BagNet-17 (in the order stated above), and
Figure 6f is the heatmap obtained thanks to
(the top row corresponds to the EA, and the bottom row corresponds to BIM). The 10% largest variations are represented by yellow points in each heatmap.
With both attacks, actually stronger with BIM than with the EA, modifying the images in and around the object locations is the most effective at increasing
’s
probability, as shown in
Figure 6f.
For both attacks, the locations where the
texture decreases coincide with the locations of most adversarial impact for
(
Figure 6b,f), while the
texture increase is slightly more disorganized, being distributed across more image areas (
Figure 6c). However, even though the
texture decreases, it remains dominant in the areas where the
shape is also present (
Figure 6d), without being replaced by the
texture, which only dominates in other, less
object-related areas (
Figure 6e). The
texture and shape coupling encourages the classification of the image into
, which may explain why the adversarial images are not transferable.
5.4. Summary of the Outcomes
Both attacks’ adversarial images are generally not transferable in the targeted sense. Although some texture is distorted by the attacks, the texture is not significantly increased (while the opposite is true for the targeted CNNs’ and probabilities), and this increase is nevertheless not correlated with an adversarial impact on the CNNs. However, we find that the EA’s and BIM’s adversarial images transfer more to CNNs, which have higher texture bias.
6. Transferability of the Adversarial Noise at Smaller Image Regions
On the one hand, the very low transferability rate observed in
Section 5 shows that most obtained adversarial images are specific to the CNNs they fool. On the other hand, the size of the covered region increases linearly with successive CNN layers [
36]. Moreover, the similarity between the features captured by different CNNs is higher in earlier layers than in later layers [
37,
38]. Roughly speaking, the earlier layers tend to capture information of a general nature, common to all CNNs, whereas the features captured by the later layers diverge from one CNN to another.
The question addressed in this section goes in the direction of a potential stratification of the adversarial noise’s impact according to the successive layers of the CNNs. In other words, this amounts to clarifying whether it is possible to sieve the adversarial noise, so that one would identify the part of the noise (if any) that has an adversarial impact for all CNNs up to some layers, and the part of the noise in which adversarial impact becomes CNN-specific from some layer on. This is a difficult challenge since the adversarial noise is modified continuously until a convenient adversarial image is created. In particular, the “initial” noise, created at some early point of the process and potentially adversarial for the first layers of different CNNs, is likely to be modified as well during this process, and to lose its initial “quasi-universal” adversarial characteristic, potentially to the benefit of a new adversarial noise. Note en passant that a careful study in this direction may contribute to “reverse engineer” a CNN, namely to reconstruct its architecture (up to a point). This direction is only indicated here and is not explored in full details at this stage.
More modestly and more specifically, in this section, we ask whether the adversarial noise for regions of smaller sizes is less CNN-specific and, hence, more transferable than at full scale, namely in the present case, where we know that, in general, it is not transferable.
This issue is addressed in two ways. First, we check whether and how a modification of the adversarial noise intensity affects the
and the
-label values of an image, adversarial for a given CNN, when exposed to a different CNN, and the influence of shuffling in this process (
Section 6.1). Second, we keep the adversarial noise as it is, and we check whether adversarial images are more likely to transfer when they are shuffled (
Section 6.2).
6.1. Generic versus Specific Direction of the Adversarial Noise
One is given a convenient ancestor image , a CNN , and the adversarial images and obtained by both attacks.
We perform the first series of experiments, which consists of changing the adversarial noise magnitude of these adversarial images by a factor f in the 0–300% range and of submitting the corresponding modified f-boosted adversarial images to different s to check whether they fool them.
Figure 7a shows what happens for the particular case of
,
, and to the
s equal to
, and
(the
f-boosted adversarial image is sent back to
as well), representative of the general behavior. In particular, it shows that the direction of the noise created for the EA adversarials is highly specific to the targeted CNN since the images cannot be made transferable by any change in magnitude.
A contrario, the noise of BIM’s adversarials has a more general direction, since amplifying its magnitude eventually leads to untargeted misclassifications by other CNNs.
A second series of experiments is performed in a similar manner as above, with the difference that, this time, it is on the shuffled adversarial images and for , 56, or 112.
Figure 7b–d show the typical outcome of this experiment. It reveals another difference between the adversarial noise obtained by the two attacks, namely, when
s is increased from 32 to 56 and 112, BIM images have a higher adversarial effect on other CNNs, whereas the EA images only have a higher adversarial effect when
s is increased from 32 to 56. As the size of the shuffled boxes increases to
and reveals the ancestor object more clearly, the EA adversarials actually have a lower fooling effect on other CNNs.
Moreover, in contrast to
Figure 7a, where the considered region is at full scale, i.e., coincides with the full image size,
Figure 7b–d show that the noise direction is more general at the local level and that an amplification of the noise magnitude is able to lead the adversarial images outside of other CNNs’
bounds, even with the EA.
To ensure that the observed effects were not simply due to shuffling but were also due to the adversarial noise, we repeated the experiment shown in
Figure 7 with random normal noise. As expected, it turned out that, with random noise, the
-label value always remained dominant and the
-label value barely increased as
f varied from 0% to 300% (see
Figure A6 in
Appendix B.2). The close-to-zero impact of random noise on unshuffled images was already known [
39]. These experiments confirm that this also holds true for shuffled images. Therefore, the observed effects were indeed due to the adversarial noise’s transferability at the local level. Nevertheless, although the adversarial noise is general enough to affect other CNNs’
-label values, its effect on
-label values is never as strong as for the targeted CNN.
6.2. Effects of Shuffling on Adversarial Images’ Transferability
Here, we do not change the intensity of the noise. That is, . The point is no longer to visualize the graph of the evolution of the -label values of shuffled adversarials but to focus on their actual values for the “real” noise (at ). The issue is to check whether the adversarial images are more likely to transfer when they are shuffled.
We proceed as follows. We input the unshuffled ancestor
and the unshuffled adversarial
to all
’s for
(hence, all CNNs except the targeted one). We extract the
and
-label values for each
i, namely
,
,
, and
. We compute the difference in the
-label values between the two images for each
i and, similarly, the difference in the
-label values to obtain
For
and 112, this process is repeated with the shuffled ancestor
and the shuffled adversarial
, yielding the following differences:
and
These
assess the impact of the adversarial noise both when unshuffled and shuffled.
Regarding the
-label values, both differences are ≤0 (the
-label value of the ancestor dominates the
-label value of the adversarial, shuffled or not). We consider the absolute value of both quantities (
k and
i are fixed). Finally, we compute the percentage over all
k, all
, of all convenient ancestors
for which
Regarding the
-label values, both differences are
(this is obvious for the unshuffled images and turns out to be the case for the shuffled one). In this case, there is therefore no need to take the absolute values. We compute the percentage over all
k, all
, of all convenient ancestors
for which
Table 4 presents the outcome of these computations for each value of
s and for the adversarials obtained by both attacks.
Note that we do not simply present the -label values of shuffled adversarial images because, then, the measured impact could have two sources: either the adversarial noise or the fact that the shape is distorted by shuffling, leaving room for the -label value to increase. Since our goal is to only measure the former source, we compare the -label values of shuffled adversarials with those of shuffled ancestors.
When the percentage is larger than 50%, the adversarial images have, on average, a stronger adversarial effect (for the untargeted scenario if one considers and for the target scenario if one considers ) when shuffled than when they are not. The adversarial effect is then perceived more by other CNNs for regions of the corresponding same size than at full scale.
For all values of s, the first percentage is larger than the second one. This means that distorting the shape of the ancestor object (done by shuffling) helps the EA more than BIM in fooling other CNNs than the targeted . This occurs although computation shows that shuffled BIM adversarials are typically classified with a larger -label value than the shuffled EA adversarials.
The percentages achieved with not only are the largest compared with those with or 112 but also exceed 50% by far. Said otherwise, a region size of achieves some optimum here. An interpretation could be that a region of that size is small enough to distort the -related information more while also being large enough to enable the adversarial pixel perturbations to join forces and to create adversarial features with a larger impact on different CNNs than the targeted one.
6.3. Summary of the Outcomes
The direction of the created adversarial noise for the EA adversarials is very specific to the targeted CNN. No change in magnitude of the adversarial noise makes them more transferable. The situation differs to some extent from the noise of BIM’s adversarials. This latter noise has a more general direction, since its amplification leads to untargeted misclassifications by other CNNs. When images are shuffled and the noise is intensified, BIM’s adversarials have a higher adversarial effect on other CNNs as s grows. This is also the case with the EA’s adversarials as s grows from 32 to 56, but no longer when s increases from 56 to 112.
The second outcome is that the EA and BIM adversarial images become closer to being transferable in a targeted sense when shuffled with than when unshuffled (at their full scale) and that is optimal in this regard compared with or 112. In the untargeted sense, this happens at regions with sizes of and (for both attacks, the corresponding percentages exceed 50%).
7. Penultimate Layer Activations with Adversarial Images
In this section, we closely examine (in
Section 7.2) the changes that adversarial images produce in the activation of the CNNs’ penultimate layers (for reasons explained in
Section 7.1). In the work that led to this study, we performed a similar study on the activation changes of the CNNs’ convolutional layers. However, different from what happens with the penultimate layers, the results obtained with adversarial noise were identical to those obtained with random noise. Hence, visualizing the intermediate layer activations requires a more in-depth method than the one employed here and we restrict the current paper to the study of the penultimate classification layers.
It is important to note that we do not pay attention to the black-box or white-box nature of the attack. We use the adversarial images independently on how they are obtained. Indeed, we assume full access to the architectures of the CNNs. This full access to the CNNs’ architectures goes without saying when one considers BIM, since it is a prerequisite for this attack. However, it is worthwhile to explicitly state for the EA, since the EA attack excludes any a priori knowledge of the CNNs’ architectures.
Still, the study of the way layers are activated by the adversarial images may reveal differences in their behaviors according to the methods used to construct them. It is not excluded that the patterns of layer activations differ according to the white-box or black-box nature of the attack that created the adversarial images sent to the CNNs. Should this be the case, this difference in patterns according to the nature of the attack may lead to attack detection or even protection measures. The issue is not addressed in this study.
7.1. Relevance of Analyzing the Activation of - and of -Related Units
The features extracted by the convolutional CNN layers pass through the next group of CNN layers, namely the classification layers. We focus on the penultimate classification layer, i.e., the layer just before the last one that gives the output classification vector.
When a CNN is exposed to an adversarial image , the perturbation of the features propagates and modifies the activation of the classification layers, which in turn leads to an output vector (drastically different from the output vector for the ancestor) in which the probability corresponding to the target class is dominant. To achieve this result, it is certain that previous classification layers are modified in a meaningful manner, with higher activations of the units that are relevant to .
However, it is not clear how the changes in these classification layers occur. Since the penultimate layer has a direct connection with the final layer and the impact of changes in activation are thus traceable, we delve into the activations of the CNNs’ penultimate layers to answer two questions essentially: Do all -relevant units have increased activation? Do -related units have decreased activations?
The connection between the penultimate and final layers is made through a weight vector W, which, for each class in the output vector, provides the weights by which to multiply the penultimate layer’s activation values. Whenever a weight that connects one penultimate layer unit with one class is positive, that particular unit of the penultimate layer is indicative of that class’ presence in the image, and vice-versa for negative weights. We can thus determine which penultimate layer units are - or -related.
7.2. How Are the CNNs’ Classification Layers Affected by Adversarial Images?
For each CNN
, we obtain the following. The aforementioned weights are extracted, and for both
and
, they are separated into positive and negative weights. Then, we compute the difference in activation values in the penultimate layer between each adversarial
and its ancestor
. Since our intention is to measure the proportion of units, relevant to a class, that are increased or decreased by the adversarial noise, we compute the average percentage of both positively and negatively related units—
Table 5 for
and
Table 6 for
(see
Table A2 and
Table A3 in
Appendix B.3 for an individual outcome)—in which the activation increased, stagnated, or decreased. For
and
,
Table 7 presents the average change in penultimate layer activation for both the positively and negatively related units.
Note that and have different behaviors than the other CNNs as far as the values of and are concerned. The EA and BIM change the activations of and much less frequently than with the other CNNs. Indeed, between 50.28% and 74.85% of the activations of these two CNNs are left unchanged, and this is valid for , for , and for both attacks. Observe that the group of units that contribute to the values taken by and by for coincides with the group of units that contribute to the values taken by and for .
Overall,
Table 5 and
Table 6 show that neither the EA nor BIM increase the activation of all positively
-related penultimate layer units; the percentages where such an increase happens is similar between the two attacks and varies between 31.40% and 77.68% throughout the different CNNs. However, in all cases, more positively
-related units are increased rather than decreased in activation. Meanwhile, for
, this preference for increasing rather than decreasing the activation is present for the negatively
-related units.
These observations are consistent with the results of
Table 7, which show that the average activation changes are large and positive for (
,
) and (
,
) for both attacks. Additionally, the averages and standard deviations corresponding to
are higher than those corresponding to
, with both attacks. However, both the averages and standard deviations are larger for BIM than for the EA.
To verify how the penultimate layer activations of a CNN are changed by adversarial images that are designed for other CNNs, we perform the experiments that led to
Table 5 and
Table 6 with the change that all CNNs are fed the adversarial images of
(DenseNet-121). The results (see
Table A2 and
Table A3 in
Appendix B.3) show that, with both attacks, the percentages of positive and negative activation changes are approximately equal. Therefore, the pixel perturbations are not necessarily meaningful towards decreasing the
-label value or increasing the
-label value of other CNNs.
Therefore, it appears that the attacks do not significantly impact the existing positively
-related features. Rather, they create some features that relate negatively to
and some that increase the confidence for
. Additionally, although both attacks usually (except against
and
, where the proportion is only around one third) increase the activation of approximately two thirds of the positively
-related and negatively
-related units, BIM increases this activation with a larger magnitude than the EA. The latter change is the most striking difference between the attacks. It could explain why the band-stop graphs in
Figure 5 show a much larger decrease in the
-label value with BIM than with the EA and why BIM adversarial images are more likely to transfer than those coming from the EA.
7.3. Summary of the Outcomes
In terms of the penultimate layer, the most prominent changes in both attacks are the increase in the activation value of the units that are positively related to and of those that are negatively related to . However, BIM performs the latter activation changes with a larger magnitude than the EA.
8. Conclusions
Through the lenses of frequency, transferability, texture change, smaller image regions, and penultimate layer activations, this study investigates the properties that make an image adversarial against a CNN. For this purpose, we consider a white-box, gradient-based attack and a black-box, evolutionary algorithm-based attack that create adversarial images fooling 10 ImageNet-trained CNNs. This study, which is performed using 84 original images and two groups of 437 adversarial images (one group per attack), provides an insight into the internal functioning of the considered attacks.
The main outcomes are that the aggregation of features in smaller regions is generally insufficient for a targeted misclassification. We also find that image texture change is likely to be a side effect of the attacks rather than to play a crucial role, even though the EA and BIM adversarials are more likely to transfer to more texture-biased CNNs. While the lower part of the noise has the highest adversarial effect for both attacks, in contrast to the EA’s white noise, BIM’s mostly low-frequency noise impacts the local features considerably more than the EA. This effect intensifies at larger image regions.
In the penultimate CNN layers, neither the EA nor BIM affect the features that are positively related to . However, BIM’s gradient-based nature allows it to find noise directions that are more general across different CNNs, introducing more features that are negatively related to and that are perceivable by other CNNs as well. Nevertheless, with both attacks, the -related adversarial noise that targets the final CNN layers is specific to the targeted CNN when the adversarial images are at full scale. On the other hand, its adversarial impact on other CNNs increases when the considered region is reduced from full scale to .
This study can be pursued in many ways, with the most natural one being its expansion to other attacks such as the gradient-based PGD attack [
7] and the score-based square attack [
12]. Furthermore, the study of the CNN penultimate layer activations could be expanded to the intermediate layers, to visualize how the activation paths differ between clean and adversarial images. Another idea towards an improved CNN explainability would be to design methods for a small-dimensional visualization of the CNNs’ decision boundaries to better assess how adversarial images cross these boundaries. Another research direction is to use the shuffling process described in this study to detect the existence of an attack and to separate adversarial images from clean images.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










