1. Introduction
Groundwater quality might be affected by many natural and industrial processes. There are many sources of groundwater contamination, for instance, polluted precipitation, runoff from roadways, leaking barrels of waste chemicals, etc. [
1] (p. 500). High concentrations of dissolved substances can result in water being unfit for drinking or irrigation. Our research focuses on observing groundwater processes in the vicinity of a deep geological repository (DGR) of radioactive waste. Despite all the protective layers, radioactive material will be exposed to the geosphere in the distant future. As a result, groundwater may become contaminated. Since it is not feasible to measure these processes directly, we model and simulate them numerically. Taking the uncertainties into account, we consider bedrock properties as random variables, specifically, spatially correlated random fields (SRF). Consequently, a quantity of interest (QoI) is also a random variable. We investigate statistical moments of a QoI in the first place and a probability density function (PDF) afterward.
Models can be process-based or data-driven [
2] (p. 4). Our research takes advantage of both approaches. First, we run a stochastic process-based contaminant transport model. A physical process is numerically solved by the finite element method on an unstructured mesh with prescribed SRF. To estimate the expectation of QoI, the model run (=simulation) is performed multiple times in accordance with the Monte Carlo method (MC); for some applications, see [
3,
4,
5]. However, MC suffers from high computational costs. Many highly accurate simulations must be performed to obtain statistical estimates with reasonably low variance, see [
6] (p. 2). To save the cost, it is beneficial to construct a hierarchical system of less accurate but cheaper models that approximate the same QoI; for details, see [
7] (p. 552). In the field of numerical modeling, the accuracy of a model is given by the number of mesh elements. Thus, we consider the hierarchy of models with gradually coarsened computational meshes, see [
7] (p. 555). For this purpose, we adopt the multilevel Monte Carlo method (MLMC) [
6] described in more detail in
Section 4. For some MLMC applications, see [
8,
9,
10,
11].
A meta-modeling approach is another option for decreasing the total computational cost of MC. A function of inputs and parameters of a complex and expensive model is approximated by a simpler and faster meta-model, also called a surrogate model. Meta-modeling techniques are widely used across scientific fields (see [
12]), and groundwater modeling is no exception [
13,
14,
15,
16]. In terms of the classification of meta-models by Robinson [
17] and Asher et al. [
13], we concentrate our effort on data-driven meta-models. In our case, the input of the model is a 2D SRF, and the output is some scalar QoI. Asher et al. [
13] (p. 5958) also provides a list of popular data-driven meta-modeling techniques, such as radial basis functions, Gaussian processes, support vector regression (SVR), and neural networks (NN). For their brief description, see [
18,
19]. We have focused on meta-models based on neural networks, the applicability of which to hydrological processes was discussed in [
20,
21]. The latter article also provides the basics of deep learning and briefly introduces some popular DNN architectures. Neural networks and deep learning have already been utilized in groundwater modeling to predict its: level [
22], quality [
23,
24], flow [
25,
26], or contaminant transport [
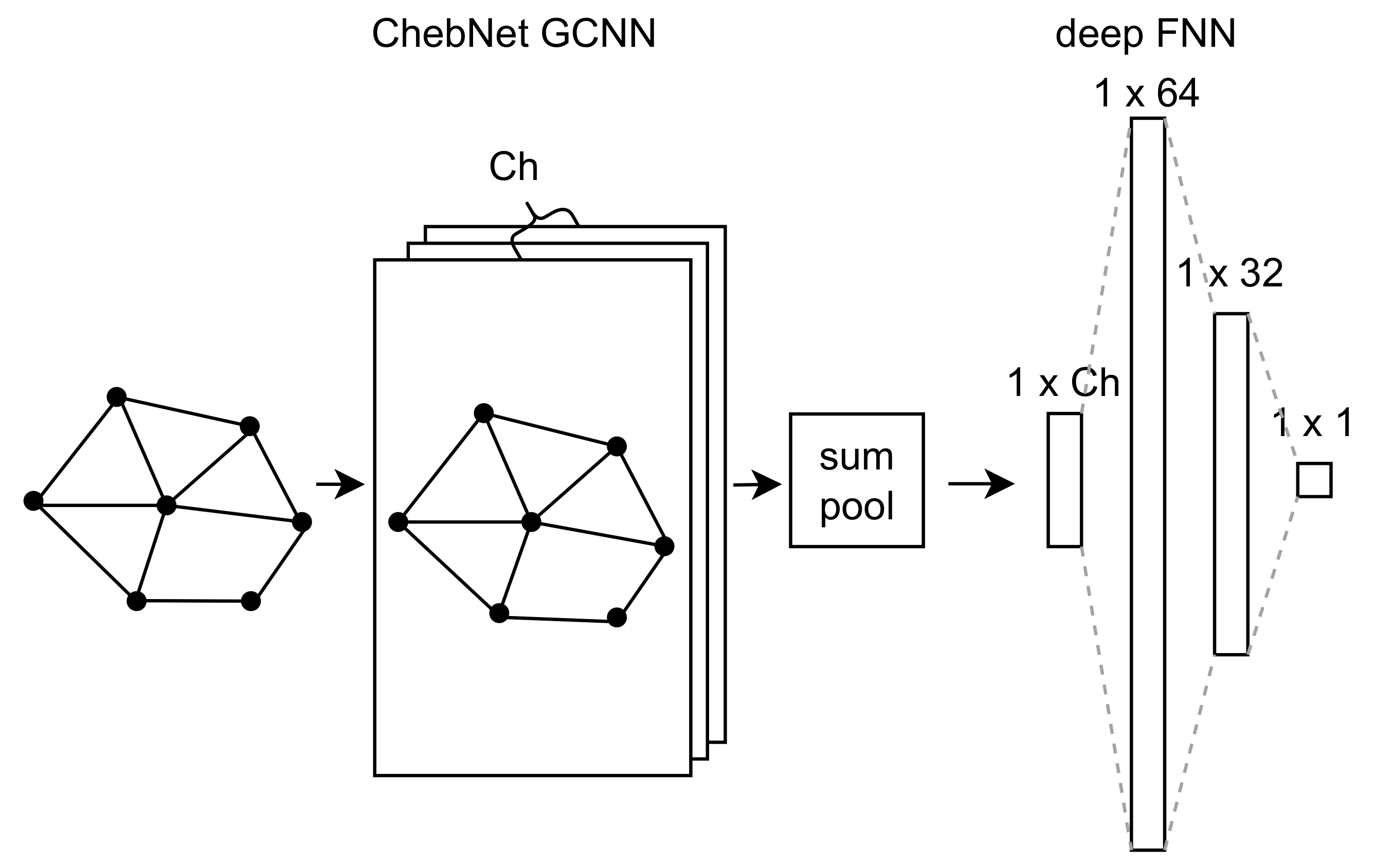
27]. With regard to the nature of input data of our model, it would be felicitous to use a convolutional neural network (CNN) as a meta-model. CNNs excel in learning spatial relationships within data on a regular grid such as an image. Since we use unstructured meshes, we cannot adopt a CNN directly (see [
28]). We briefly discussed some ways to overcome this difficulty in [
29]. Representing the structure of SRF as a graph (for graph theory, see [
30]) and then using a graph convolutional neural network (GCNN) [
31] is the option we selected.
The general objective of the presented article is to reduce the computational cost of Monte Carlo methods by incorporating a meta-model. In this regard, we build on the findings of our initial article [
29], which addressed the same objective with a GCNN meta-model of a groundwater flow problem. In this article, we specifically focus on improving the accuracy of the meta-model and its applicability for groundwater contaminant transport problems. To the best of our knowledge, no previous research in groundwater modeling has investigated the computational cost reduction in Monte Carlo methods using a meta-model.
The article is organized as follows. First, the contaminant transport model is described. Next, its deep learning meta-model is presented in
Section 3. The multilevel Monte Carlo method is briefly introduced, and the proposed incorporation of the meta-model is delineated in
Section 4 and
Section 5.
Section 6 is devoted to numerical experiments, meta-models are assessed, and their usage is put into the context of MC and MLMC. The article is concluded with a summary and discussion of the important findings.
2. Groundwater Contaminant Transport Model
We consider a conceptual 2D model of the transport of contaminants from DGR, see
Figure 1. The Darcy flux of groundwater
q [ms
] is described by the equations:
where
p is the pressure head [m], and
is the hydraulic conductivity considered to be smaller at a stripe near the surface. The Darcy flow is driven by the seepage face condition:
on the top boundary, with
denoting a precipitation flux. No flow is prescribed on the remaining boundaries. The surface geometry is intentionally overscaled to pronounce its impact on the groundwater flow.
The advection equation is used as the contaminant transport model:
where
is the porosity and
c is the concentration [kg m
] of a contaminant in terms of mass in the unit volume of water. The equation is solved for the unknown concentration with the initial condition
in the repository and 0 elsewhere. Zero concentration is prescribed at the inflow part of the boundary.
The
is given as a correlated random field. Then, the random field of hydraulic conductivity
is determined from
using the Kozeny–Carman equation and slight random scaling given by an independent random field.
Figure 1 displays the geometry of the model, the random conductivity field (conductivity in the figure), and the concentration field (X_conc in the figure) at the time
of the total simulation time
. The simulation is performed using the Flow123d software [
32].
4. Multilevel Monte Carlo Method
The multilevel Monte Carlo method [
6] (MLMC) is based on the variance reduction principle [
6] (p. 3). Many simulation samples are collected at low levels, with less accurate but inexpensive approximations of the model available. While much fewer samples are collected at high levels, there are differences between approximations of the model that are more accurate but computationally expensive. If these differences have a significantly smaller variance, we obtain estimates with the same accuracy but at a fraction of the cost compared to the standard Monte Carlo method.
Let
P be a random variable and
, …,
be a sequence of its approximations, where
. The approximations are becoming more accurate from
to
. Then, the expected value of
satisfies the identity:
The MLMC estimates an individual expectation as follows:
where
L is the total number of levels,
stands for the number of simulation samples on level
l,
denotes the average over
samples. Pairs of random inputs
are both discrete evaluations of a single realization of a random field
, while the random states
are independent and come from a given probability space
.
When using estimator (
7), we are particularly interested in its total computational cost
C and estimated variance
:
where
denote the cost and the estimated variance of
. Meanwhile, for
,
represent the cost and the estimated variance of differences
. For a comprehensive MLMC theory, see [
6].
In the presented way, it is feasible to estimate the expectations of quantities derived from the original QoI. In particular, we utilize the so-called generalized statistical moments of QoI. In our study, the moments’ functions
are Legendre polynomials, as they are suitable for the PDF approximation (see [
36]).
4.1. Optimal Number of Samples
As previously mentioned, the principal motivation of our research is to reduce
C. However, it is also essential to keep the variance of the estimator sufficiently low. To achieve this, we prescribe the target variance
of the estimator. Then, the optimal
is found by minimizing function (
8) under the constraint
After some calculus:
where
is an estimated variance of
for
moment function on level
l,
. Finally,
. This procedure is crucial in our study and determines the results presented.
The Python library MLMC [
37], developed by the authors of this article, is used to schedule simulation samples and post-process the results. The software also implements the maximal entropy method (MEM) to determine the PDF from moments estimated by MLMC. The description of MEM is beyond the scope of this article. The interested reader is advised to read [
36,
38] for a comprehensive study or [
29] for a brief introduction.
6. Results
6.1. Analysis of Meta-Models
In order to evaluate the meta-model in accordance with our assessment procedure described in
Section 3.4, the contaminant transport model was run on meshes of different sizes, and obtained data are used as
. From the Monte Carlo method’s point of view, we generally set
to obtain sufficiently accurate estimates of moments to decently approximate PDF by MEM. Consequently, we have at least 2000 samples at the lowest Monte Carlo level. Thus, from now on, we undertake all meta-model learnings with
, and 400 samples out of
account for validation samples,
50,000,
.
Table 1 shows the accuracy of meta-model approximations of models on different mesh sizes. Two architectures of meta-models are compared. The Deep meta-model is the one proposed in this article, whereas the Shallow meta-model was propounded in our previous study [
29]. The accuracy is characterized by NRMSE (see
Section 3.4). Apparently, the Deep meta-model outperforms the Shallow meta-model in all observed cases. Since
stays almost steady and
, our approach can be used regardless of the mesh size, at least up to the ca. 20,000 elements, larger meshes were not tested. Considering
is just slightly below
, we believe there is still some room for improvement in future research.
All meta-models were trained on GeForce GTX 1660 Ti Mobile graphics card with 16 Gb RAM. The time of meta-model learning ranges from around 400 s for a model on 53 mesh elements to about 3000 s for a model on 18,397 mesh elements.
6.2. Comparison of MC-M and MLMC-M
Once we have a promising meta-model, it can be utilized by Monte Carlo methods. Based on the approach proposed in
Section 5, we provide MC-M and two-level MLMC-M in comparison with the standard MC. Both are compared in terms of computational cost and the quality of estimations of moments. The number of samples
were calculated by formulas presented in
Section 4.1 with
,
. The efficiency of Monte Carlo methods with a meta-model compared to Monte Carlo methods without a meta-model is expressed as computational cost savings
calculated as
.
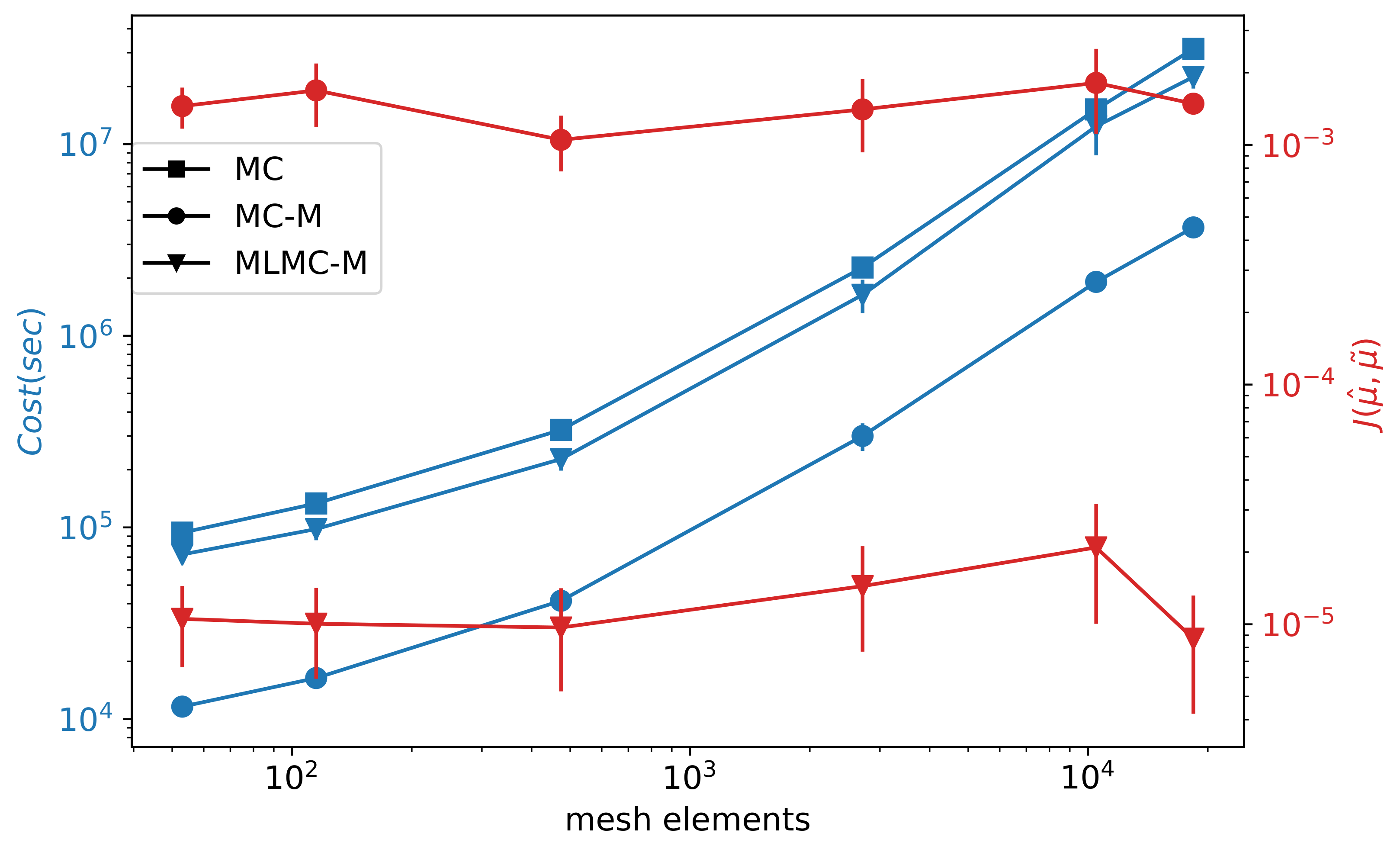
Figure 4 shows the computational cost (
) and moments error (
). The cost is measured as the CPU time of simulations, including auxiliary processing and time needed for meta-model learning. The moments error has the form of MSE:
where
represents the moments estimated by the standard MC, whereas
are moments calculated by either MC-M or MLMC-M. As expected, the computational cost increases with the precision of a model expressed as a number of mesh elements. As you can see, the cost can be greatly reduced (
) by using MC-M instead of MC. However, the meta-model error causes poor estimates of moments:
. On the contrary, MLMC-M suppresses the effect of the meta-model error, and estimates of moments are obtained with
. The cost savings are not so substantial but still significant:
. Generally, using MC-M can be reasonable if we have an exceptionally accurate meta-model or we intend to obtain just a basic idea of the moments and PDF in a short time. Otherwise, using the MLMC-M is recommended.
6.3. Multilevel Case
In this section, we investigate an MLMC-M with more than two levels. In order to demonstrate some properties and limitations of our approach, we introduce the following three pairs of Monte Carlo methods:
1LMC and 1LMC-M: standard MC of models on 18,397 mesh elements and its extension by meta-level;
2LMC and 2LMC-M: 2-level MLMC on models with 18,397 and 2714 mesh elements, and its extension by meta-level trained on the model of 2714 mesh elements;
3LMC and 3LMC-M: 3 level MLMC with models on 18,397, 2714, and 474 mesh elements and its extension by meta-level trained on the model of 474 mesh elements
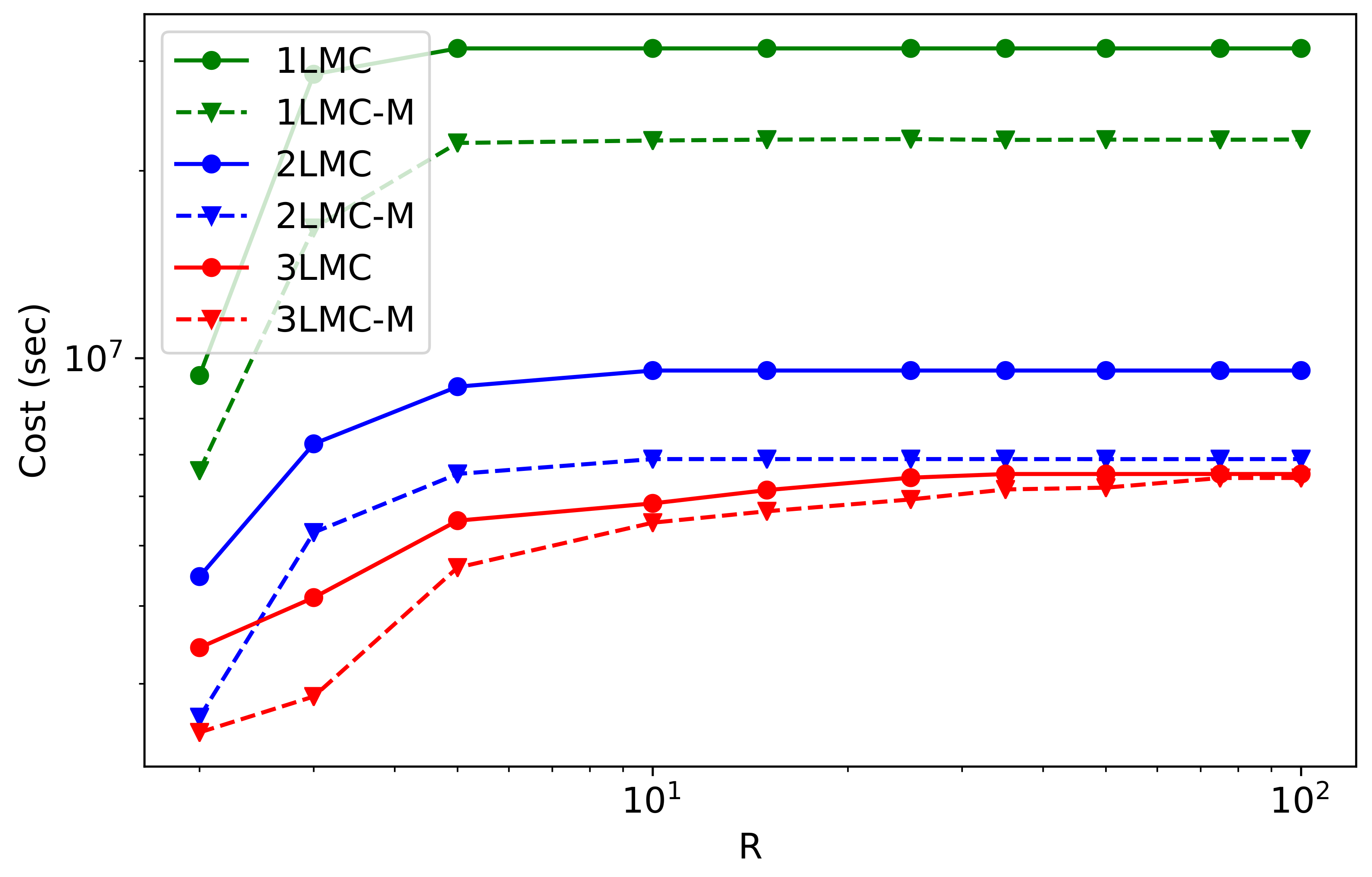
Figure 5 shows the computational costs of these Monte Carlo methods for a different number of estimated moments
R. We see that 1LMC and 1LMC-M have a much higher cost than methods with more levels. This is the crucial observation that demonstrates the limitations of the standard MC.
Let us focus on the course of the costs depending on R. In all the cases, the lowest cost was obtained for . However, as R increases, the behaviors of the methods differ. For 1LMC, 1LMC-M, 2LMC, and 2LMC-M, we observe a similar course that is steady for . It means we can add more moments without affecting computational cost. On the other hand, for 3LMC and 3LMC-M, we observe a gradual increase in cost up to and , respectively.
Regarding computational cost savings, in cases of 1LMC and 2LMC, there is
utilizing 1LMC-M and 2LMC-M, whereas 3LMC provides us with savings, from around
for
to just
for
. As mentioned in
Section 5.2, the computational cost distribution across levels can be described using
and
variables. Since for 1LMC and 2LMC,
, the dominant computational cost is on the lowest-accuracy levels. Therefore, adding the meta-level results in a much higher
(for
) than for
, which is the case with 3LMC. Thus, the behavior of our experiments corresponds to the theoretical properties of the MLMC.
A closer look at the variances of moments across levels
(
Figure 6) provides a rationale for the claims already presented. For clarity, we display only the first five moments (
), which capture the behavior observed also in cases with more moments. To recall, we employ Legendre polynomials as
; therefore,
. The total computational cost (see Formula (
8)) depends on the number of simulation samples
that are determined by
(see
Section 4.1) and
, which is also displayed in the figure. To meet
, the pictured variances are calculated based on the following numbers of samples:
for 3LMC and [
] for 3LMC-M.
We can see that increases with increasing r for some l, leading to the observed growth of C and with R to the point where is stable. When it comes to different , we need to focus on the course of across levels. We observe increasing of 3LMC-M, whereas the corresponding of 3LMC remains constant. This trend is accentuated for and causes a decrease in . The distinguishable increase in for 3LMC-M has just a slight impact on due to the minor compared to , for . A more accurate meta-model could prevent from increasing for 3LMC-M.
We faced a similar behavior for the groundwater flow problem investigated in our previous research [
29]. It is good to be aware of this behavior, although the distribution of variances of moments across MLMC levels would deserve a much more detailed explanation, which is beyond the scope of this article.
6.4. Approximation of Probability Density Function
Finally, we use moments estimated by the cheapest Monte Carlo methods presented (3LMC and 3LMC-M) to approximate the PDF of the contaminant concentration c[kgm] on the surface, , . Let , , be the PDFs approximated based on the moments estimated by 3LMC, 3LMC-M, and reference MC. We run model samples on a mesh with 18,397 elements to obtain the reference MC.
Figure 7 depicts the approximated PDFs, as well as the Kullback–Leibler (KL) divergence (for details, see [
39]) used for the accuracy assessment of PDFs:
and
. Considering the values of
and
R, we have decent PDF approximations. Both 3LMC and 3LMC-M provide almost the same results in terms of KL divergence. It means
are sufficiently accurate, in particular
. Moreover,
are obtained with
. If we are interested just in the expected value and the variance, which is very common, we have
. Importantly, we can decrease
to obtain a better PDF approximation; in this case, the computational cost naturally increases, but
does not change.
7. Discussion and Conclusions
This study presented the deep learning meta-model to reduce the computational costs of Monte Carlo methods. We followed up on our previous research [
29] and improved the meta-model, which now consists of a graph convolutional neural network connected to the feed-forward neural network. This meta-model can better approximate models such as the tested groundwater contaminant transport problem. We showed that our meta-model could be trained with comparable accuracy for models solved on unstructured meshes from 53 to 18,397 mesh elements.
We adopted Monte Carlo methods to obtain generalized statistical moments that are utilized to approximate the probability density function of the contaminant concentration on the surface above a future deep geological repository of radioactive waste. In order to reduce the computational cost of MC, two approaches were propounded. MC-M, a meta-model instead of a model within the standard Monte Carlo method, brings substantial cost savings (). However, the accuracy of moments J was severely affected by the meta-model error and was just around . Under the described experiment setting, it is tough to obtain minor meta-model errors for such a complex model such as the one we have. Thus, this procedure has limited usability. What is favorable, though, is the second approach. A meta-level is employed as the lowest-accuracy level of MLMC, denoted MLMC-M. Generally, this approach reduces the computational cost and keeps the error of moments low, , which is sufficient for PDF approximations. We presented three pairs of MLMCs and MLMC-Ms to demonstrate the impact of a different distribution of computational cost across levels. In accordance with theory, the most significant cost savings () was achieved when the dominant computational cost was on the lowest-accuracy level. On the contrary, if the prevailing computational cost is on the highest-accuracy level, we have in the worst case. Importantly, the computational cost and savings are affected by the number of moments R we estimate. In many applications, we are interested in the first few moments, such as the expected value or the variance. For that, we have in all the cases. Intending to approximate PDF, we need at least around , then in the worst-case scenario.
In our future research, we shall try to improve the accuracy of the current meta-model further and investigate the applicability of standard convolutional neural networks as a meta-model. We shall also rigorously describe the causes of the different course of variances of moments across MLMC levels. We shall deal with other applications in groundwater modeling, especially in connection with fractured porous media.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}