
Mixed Machine Learning Approach for Efficient Prediction of Human Heart Disease by Identifying the Numerical and Categorical Features

 , ,
, ,  and
and
Abstract
:1. Introduction

1.1. Main Kind of Cardiovascular Ailments
1.2. Congestive Heart Failure
1.3. Abnormal Heart Rhythms, Irregular Heartbeat, Cardiac Arrhythmia, Abnormal Electrocardiography

2. Prediction of Heart Disease Using Machine Learning
2.1. Linear Discriminants Analysis (LDA)
2.2. Random Forest Classifier
2.3. Gradient Boosting Classifier
2.4. Decision Tree Classifier (DTC)
2.5. Support Vector Machine (SVM)
2.6. Nu-Support Vector Classifier (Nu-SVC)
2.7. Logistic Regression (LR)
2.8. K-Nearest Neighbors
- Select the number K of the neighbors
- Calculate the Euclidean distance of the K number of neighbors
- Take the K nearest neighbors as per the calculated Euclidean distance.
- Among these K neighbors, count the number of data points in each category.
- Assign new data points to that category for which the number of the neighbor is maximum.
2.9. Quadratic Discriminant Analysis (QDA)
2.10. AdaBoost Classifier
2.11. Neural Network (NN)
2.12. k-5 Fold Cross-Validation
2.13. Stacking CV Classifier
- Model building: A machine learning model is developed during this phase to detect cardiac illness. A risk assessment model is also developed to aid doctors in developing an early prediction with excellent predictive power. This is binary classification (has-disease or no-disease cases). The machine learning algorithms such as logistic regression, K-nearest neighbors, support vectors machine, Nu support vectors classifier, decision tree classifiers, random forest, adaboost, gradient boosting, naive bayes, linear discriminant analysis, quadratic discriminant analysis, neural network (12 classifiers to select the optimal base learners), and k-5 fold cross-validation. For avoiding the overfitting of the base learners, the random forest classifier is used as the Meta Learner. The stacking model is implemented for CVD prediction and is inspired by other ML models. The proposed technique is tested against 12 individual ML classifiers for accuracy, precision, recall, F1-score, and AUC values by using a combined heart disease dataset from multiple UCI machine learning resources and another publicly accessible heart disease dataset.
- The data are divided into training and testing sets in 3:1, optimizing the trained model 75% and the tested model 25%. As a result, the random forest and decision tree models are chosen as the top classifiers. However, the default settings were used to achieve this. With tweaked settings, we should be able to enhance our model even further. The working diagram of proposed model is shown in Figure 3 and application of proposed model is shown in Figure 4. The distribution of the target variable of heart disease is shown in Figure 5.
- Data insight: Heart disease detection using a dataset is presented, generating intriguing inferences to arrive at useful conclusions.
- EDA: Exploratory data analysis is carried out in order to obtain useful results.
- Feature development: It is needed to change the features when it acquires the insights from the data so that it can continue forward with the model development process.
3. Literature Review
4. Proposed Methodology
- (a)
- Choosing a dataset from the online machine learning repository is the initial step. The Cleveland, Switzerland, Hungarian, and Long Beach VA datasets are only a handful of the online repositories that provide 14 variables related to patients’ vital signs and cardiac disease. With 13 out of the 14 variables working as predictor variables, the last trait acts as the target. Sex, age, kind of chest pain, serum cholesterol, resting blood pressure, fasting blood sugar, resting maximum heart rate, electrocardiography, and ST-segment elevation are all factors to consider. Segment elevation is one of the study’s 13 predictor variables. Exercise-induced angina, depression, slope, and the outcome of a thallium test are all predicted, as are the number of vessels harmed by fluoroscopy and the diagnosis. The dataset has 1025 instances. Because there were no biases in the data, this strategy had no influence on the remaining data utilized in the experiment. Table 1 lists the datasets and their descriptions.
- (b)
- Establishing links between various heart disease risk factors. The reciprocal link between the heart disease features in this study is assessed using Pearson’s correlation. The results of the applied Pearson’s correlation coefficients amongst the heart disease risk a variable which is shown in Figure 8 and Figure 9 as a heatmap. The heatmap grid depicts the relationship among heart disease variables and their related coefficients. After completing the heatmap analysis, we noticed that independent characteristics are loosely associated with one another, which is a good indicator that the model’s performance may be improved. However, if the attributes in a dataset are tightly correlated, a change in one variable can cause a change in another, lowering the algorithm’s performance. The substantial association among qualities should be studied significantly because correlation does not imply causality. Because of some neglected elements, a link between qualities may appear causative through significant correlation.
- (c)
- The gathered data sets were improved and standardized in the second stage. These datasets were not collected in a controlled setting and contained incorrect information. As a result, data pre-processing is a necessary step in data analysis and machine learning. The various values of the dataset of risk factors are referred to as data normalization; for instance, Celsius and Fahrenheit are two different temperature measuring units. Data standardization requires scaling risk factors and producing values that indicate the difference between standard deviations (SD) from the mean value. The performance of machine learning classifiers can be improved by rescaling the risk factor value with SD as 1 and mean as 0. The standardizing formula is as follows:
- (d)
- Applying machine algorithms to the dataset produced in step 2 (logistic regression, k-nearest neighbors, support sectors machine, nu support vectors classifier, decision tree, random forest, adaboost, gradient boosting, naive bayes, linear discriminant analysis, quadratic discriminant analysis, neural net, k-fold cross validation and ensemble technique).
- (e)
- The prediction model’s accuracy, precision, recall, and F-measure are all assessed at this step. It is decided on the model with the greatest accuracy, precision, recall, and F-measures. The accuracy metric is used to assess the precision or exactness of the MLC or model’s predictions. In mathematics, it is supplied by an equation.


5. Data Collection
5.1. Checking the Distribution of the Data

5.2. Checking the Categorical and Numerical Features Pair Plots, Count Plots of the Data






6. Experimental Results and Discussion













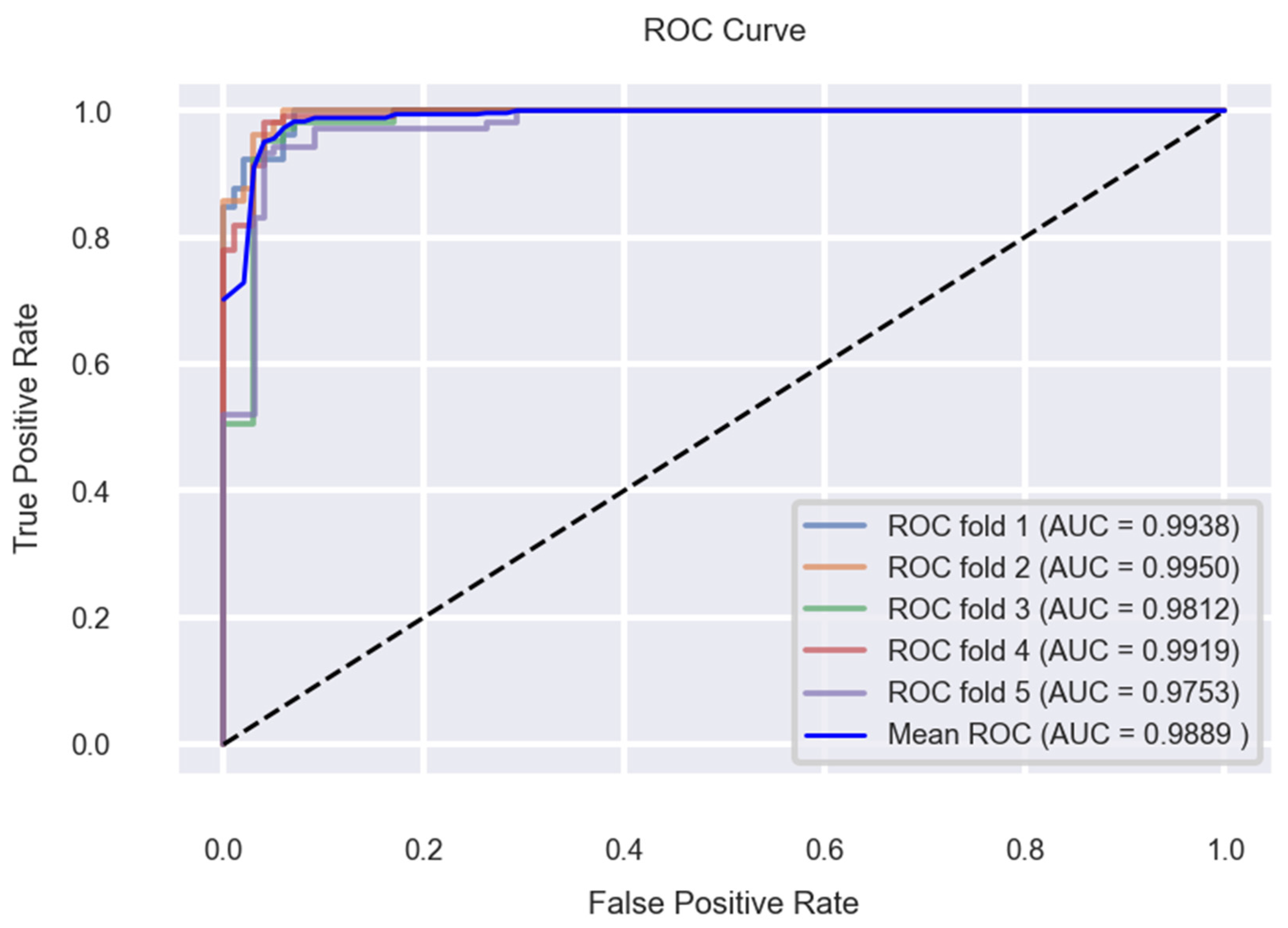





7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ornish, D. Can lifestyle changes reverse coronary heart disease? The Lifestyle Heart Trial. Lancet 1990, 336, 129–133. [Google Scholar] [CrossRef]
- Ambrosy, A.P.; Fonarow, G.C.; Butler, J. The global health and economic burden of hospitalizations for heart failure: Lessons learned from hospitalized heart failure registries. J. Am. Coll. Cardiol. 2014, 63, 1123–1133. [Google Scholar] [CrossRef] [PubMed]
- Bui, A.L.; Horwich, T.B.; Fonarow, G.C. Epidemiology and risk profifile of heart failure. Nat. Rev. Cardiol. 2011, 8, 30–41. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bathrellou, E.; Kontogianni, M.D.; Chrysanthopoulou, E. Adherence to a dash-style diet and cardiovascular disease risk: The 10-year follow-up of the Attica study. Nutr. Health 2019, 25, 225–230. [Google Scholar] [CrossRef] [PubMed]
- Das, R.; Turkoglu, I.; Sengur, A. Effffective diagnosis of heart disease through neural networks ensembles. Expert Syst. Appl. 2009, 36, 7675–7680. [Google Scholar] [CrossRef]
- Sinha, R.K.; Aggarwal, Y.; Das, B.N. Backpropagation artificial neural network classifier to detect changes in heart sound due to mitral valve regurgitation. J. Med. Syst. 2007, 31, 205–209. [Google Scholar] [CrossRef]
- Dangare, C.S.; Apte, S.S. Improved study of heart disease prediction system using data mining classification techniques. Int. J. Comput. Appl. 2012, 47, 44–48. [Google Scholar]
- Spencer, K.T.; Kimura, B.J.; Korcarz, C.E.; Pellikka, P.A.; Rahko, P.S.; Siegel, R.J. Focused cardiac ultrasound: Recommendations from the american society of echocardiography. J. Am. Soc. Echocardiogr. 2013, 26, 567–581. [Google Scholar] [CrossRef]
- Beymer, D.; Syeda-Mahmood, T. Cardiac disease recognition in echocardiograms using spatio-temporal statistical models. In Proceedings of the 2008 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Vancouver, BC, Canada, 20–25 August 2008; pp. 4784–4788. [Google Scholar]
- Wu, H.; Huynh, T.T.; Souvenir, R. Motion factorization for echocardiogram classification. In Proceedings of the 2014 IEEE 11th International Symposium on Biomedical Imaging (ISBI), Beijing, China, 29 April 2014–2 May 2014; pp. 445–448. [Google Scholar]
- Buman, M.P. Reallocating time to sleep, sedentary behaviors, or active behaviors: Associations with cardiovascular disease risk biomarkers, NHANES 2005–2006. Am. J. Epidemiol. 2014, 179, 323–334. [Google Scholar] [CrossRef]
- Javeed, A. Machine learning-based automated diagnostic systems developed for heart failure prediction using different types of data modalities: A systematic review and future directions. Comput. Math. Methods Med. 2022, 2022, 9288452. [Google Scholar] [CrossRef]
- Virani, S.S. Heart Disease and Stroke Statistics—2020 Update: A Report from the American Heart Association. Lippincott Williams Wilkins 2020, 141, e139–e596. [Google Scholar] [CrossRef]
- American Heart Association. Heart Disease and Stroke Statistics Update Fact Sheet American Heart Association Research Heart Disease, Stroke and Other Cardiovascular Diseases, Coronary Heart Disease (CHD); American Heart Association: Dallas, TX, USA, 2021. [Google Scholar]
- Sturgeo, K.M. A population-based study of cardiovascular disease mortality risk in US cancer patients. Eur. Heart J. 2019, 40, 3889–3897. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kaptoge, S.; Pennells, L.; De Bacquer, D.; Cooney, M.T.; Kavousi, M.; Stevens, G.; Di Angelantonio, E. World Health Organization cardiovascular disease risk charts: Revised models to estimate risk in 21 global regions. Lancet Glob. Health 2019, 7, e1332–e1345. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.A.; Algarni, F. A healthcare monitoring system for the diagnosis of heart disease in the IoMT cloud environment using MSSO-ANFIS. IEEE Access 2020, 8, 122259–122269. [Google Scholar] [CrossRef]
- Ferdousi, R.; Hossain, M.A.; Saddik, A.E. Early-stage risk prediction of non-communicable disease using ML in health CPS. IEEE Access 2021, 9, 96823–96837. [Google Scholar] [CrossRef]
- Shalev-Shwartz, S.; Ben-David, S. Understanding machine learning. In Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The elements of statistical learning. In Data Mining, Inference, and Prediction; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Marsland, S. Machine learning. In An Algorithmic Perspective; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Amin, M.S.; Chiam, Y.K.; Varathan, K.D. Identification of significant features and data mining techniques in predicting heart disease. Telemat. Inform. 2019, 36, 82–93. [Google Scholar] [CrossRef]
- Spencer, R.; Thabtah, F.; Abdelhamid, N. Exploring feature selection and classification methods for predicting heart disease. Digit. Health 2020, 6, 2055207620914777. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.A. An IoT framework for heart disease prediction based on MDCNN classifier. IEEE Access 2020, 8, 34717. [Google Scholar] [CrossRef]
- Mehmood, A.; Iqbal, M.; Mehmood, Z. Prediction of heart disease using deep convolutional neural networks. Arab. J. Sci. Eng. 2021, 46, 3409–3422. [Google Scholar] [CrossRef]
- Budholiya, K.; Shrivastava, S.K.; Sharma, V. An optimized XGBoost based diagnostic system for effective prediction of heart disease. J. King Saud Univ. Comput. Inf. Sci. 2020, 34, 4514–4523. [Google Scholar] [CrossRef]
- Martins, B.; Ferreira, D.; Neto, C.; Abelha, A.; Machado, J. Data mining for cardiovascular disease prediction. J. Med. Syst. 2021, 45, 6. [Google Scholar] [CrossRef]
- Miranda, E.; Irwansyah, E.; Amelga, A.Y.; Maribondang, M.M.; Salim, M. Detection of cardiovascular disease risk’s level for adults using naive bayes classifier. Healthc. Inform. Res. 2016, 22, 196–205. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pandey, A.; Pandey, P.; Jaiswal, K.L.; Sen, A.K. A Heart Disease Prediction Model Using Decision Tree. Available online: www.iosrjournals.orgwww.iosrjournals.org (accessed on 27 May 2021).
- Mienye, I.D.; Sun, Y.; Wang, Z. Improved sparse autoencoder based artificial neural network approach for prediction of heart disease. Inform. Med. Unlocked 2020, 18, 100307. [Google Scholar] [CrossRef]
- Siontis, K.C.; Noseworthy, P.A.; Attia, Z.I.; Paul, A. Artificial intelligence-enhanced electrocardiography in cardiovascular disease management. Nat. Rev. Cardiol. 2021, 18, 465–478. [Google Scholar] [CrossRef] [PubMed]
- Anitha, S.; Sridevi, N. Heart disease prediction using data mining techniques. J. Anal. Comput. 2019, 8, 48–55. [Google Scholar]
- Kumar, N.K.; Sindhu, G.S.; Prashanthi, D.K.; Sulthana, A.S. Analysis and prediction of cardio vascular disease using ML classififiers. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 15–21. [Google Scholar]
- Chowdhury, M.E.; Khandakar, A.; Alzoubi, K.; Mansoor, S.; Tahir, A.M.; Reaz, M.B.I.; Al-Emadi, N. Real-Time Smart-Digital Stethoscope System for Heart Diseases Monitoring. Sensors 2019, 19, 2781. [Google Scholar] [CrossRef] [Green Version]
- Negi, S.; Kumar, Y.; Mishra, V.M. Feature extraction and classification for EMG signals using linear discriminant analysis. In Proceedings of the 2016 2nd International Conference on Advances in Computing, Communication, & Automation (ICACCA), Bareilly, India, 30 September 2016–1 October 2016. [Google Scholar]
- Linda, P.S.; Yin, W.; Gregory, P.A.; Amanda, Z.; Margaux, G. Development of a novel clinical decision support system for exercise prescription among patients with multiple cardiovascular disease risk factors. Mayo Clin. Proc. Innov. Qual. Outcomes 2021, 5, 193–203. [Google Scholar]
- Ahmad, G.N.; Ullah, S.; Algethami, A.; Fatima, H.; Akhter, S.M.H. Comparative Study of Optimum Medical Diagnosis of Human Heart Disease Using ML Technique with and without Sequential Feature Selection. IEEE Access 2022, 10, 23808–23828. [Google Scholar] [CrossRef]
- Heart Disease Dataset. Available online: https://www.kaggle.com/johnsmith88/heart-disease-dataset (accessed on 20 July 2022).
- Heart Disease Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/Heart+Disease (accessed on 20 July 2022).
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Ramprakash, P.; Sarumathi, R.; Mowriya, R. Heart disease prediction using deep neural network. In Proceedings of the International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–28 February 2020; pp. 666–670. [Google Scholar]
- Gao, X.Y.; Ali, A.A.; Hassan, H.S.; Amwar, E.M. Improving the accuracy for analyzing heart diseases prediction based on the ensemble method. Complexity 2021, 2021, 6663455. [Google Scholar] [CrossRef]
- Ali, M.M.; Kumar, B.P.; Ahmad, K.; Francis, M.B.; Julian, M.W.Q.; Moni, M.A. Heart disease prediction using supervised ML algorithms: Performance analysis and comparison. Comput. Biol. Med. 2021, 136, 104672. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Chen, Y.; Chen, Y.; Ye, S.; Cai, W.; Jiang, J.; Chen, M. Heart Disease Prediction Based on the Embedded Feature Selection Method and Deep Neural Network. J. Healthc. Eng. 2021, 2021, 6260022. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No. | Attribute | Details |
|---|---|---|
| 1 | Age | Age in years |
| 2 | Sex | Male and female |
| 3 | Cp | Type of chest discomfort |
| 4 | Trestbps | Blood pressure at rest (in mm Hg on admission to the hospital) |
| 5 | Chol | Cholesterol levels in the blood in milligrams per decilitre |
| 6 | Fbs | After a fast, check your blood sugar levels. |
| 7 | Restecg | At rest, electrocardiography produces the following values. 0 indicates that the ST-T wave is normal; 1 indicates that the ST-T wave is aberrant; |
| 8 | Thalach | The highest heart rate was attained. |
| 9 | Exang | Angina due to exercise |
| 10 | Oldpeak | ST depression is a kind of depression that occurs when the J point is displaced below baseline |
| 11 | Slope | The slope of the ST half of the peak workout |
| 12 | Ca | A number of major vessels (0–3) have been colored using fluoroscopy. |
| 13 | Thal | The result of a thallium stress test |
| 14 | Target | 1 denotes heart illness, while 0 denotes the absence of heart disease. |
| S. No. | Classifier | Accuracy (%) | Recall (%) | Precision (%) | F1-Score (%) | ROC-AUC (%) |
|---|---|---|---|---|---|---|
| 1 | RF | 100 | 100 | 100 | 100 | 100 |
| 2 | DT | 98.80 | 99 | 98 | 100 | 99 |
| 3 | GB | 97.60 | 98 | 98 | 98 | 100 |
| 4 | KNN | 90.80 | 84 | 97 | 90 | 97 |
| 5 | AB | 88.00 | 91 | 86 | 89 | 94 |
| 6 | LR | 84.80 | 89 | 82 | 86 | 91 |
| 7 | NN | 84.80 | 92 | 81 | 86 | 91 |
| 8 | QDA | 83.60 | 85 | 83 | 84 | 91 |
| 9 | Nu SVC | 83.20 | 91 | 79 | 85 | 90 |
| 10 | LDA | 82.80 | 87 | 80 | 84 | 91 |
| 11 | NB | 82.40 | 86 | 81 | 83 | 88 |
| 12 | SVM | 68.80 | 69 | 69 | 69 | 73 |
| S. No. | Classifier | Accuracy (%) | Recall (%) | Precision (%) | F1-Score (%) | ROC-AUC (%) |
|---|---|---|---|---|---|---|
| 1 | RF | 99.41 | 100 | 98.89 | 99.40 | 99.97 |
| 2 | DT | 99.60 | 99.23 | 100 | 99.61 | 99.62 |
| 3 | GB | 99.41 | 99.50 | 99.45 | 99.53 | 100 |
| 4 | KNN | 86.06 | 86.19 | 86.25 | 86.04 | 94.86 |
| 5 | AB | 90.93 | 89.99 | 92.24 | 91.05 | 97.57 |
| 6 | LR | 84.59 | 89.98 | 82.31 | 85.59 | 91.88 |
| 7 | NN | 95.03 | 95.64 | 94.76 | 95.19 | 98.54 |
| 8 | QDA | 94.16 | 94.49 | 94.27 | 94.33 | 98.74 |
| 9 | Nu SVC | 94.83 | 95.45 | 94.60 | 94.97 | 98.54 |
| 10 | LDA | 93.56 | 93.54 | 93.93 | 93.71 | 98.60 |
| 11 | NB | 82.15 | 85.94 | 80.63 | 83.12 | 90.76 |
| 12 | SVM | 92.19 | 93.36 | 91.68 | 92.49 | 97.24 |
| S. No. | Classifier | Accuracy (%) | Recall (%) | Precision (%) | F1-Score (%) |
|---|---|---|---|---|---|
| 1 | RF | 100 | 100 | 100 | 100 |
| 2 | DT | 100 | 100 | 100 | 100 |
| 3 | GB | 89.26 | 89 | 89 | 89 |
| 4 | KNN | 86.34 | 86.19 | 86.25 | 86.04 |
| 5 | AB | 90.00 | 90.00 | 90.00 | 90.00 |
| 6 | LR | 86 | 87 | 86 | 86 |
| 7 | NN | 97 | 97 | 97 | 97 |
| 8 | QDA | 88 | 88 | 88 | 88 |
| 9 | Nu SVC | 93.17 | 93 | 93 | 93 |
| 10 | LDA | 86 | 87 | 86 | 86 |
| 11 | NB | 87 | 87 | 87 | 87 |
| 12 | SVM | 99 | 98 | 99 | 99 |
| 13 | RFC+NN+SVM | 100 | 100 | 100 | 100 |
| 14 | RFC+NN+QDA | 100 | 100 | 100 | 100 |
| 15 | RFC+NN | 100 | 100 | 100 | 100 |
| 16 | LDA+QDA | 89 | 89 | 89 | 89 |
| Authors | Methods | Accuracy (%) | Recall (%) | Precision (%) | F1-Measure (%) | ROC-AUC (%) |
|---|---|---|---|---|---|---|
| Ramprakash et al. [41] | χ2-DNN | 94 | 93 | - | - | - |
| Gao et al. [42] | Decision tree Plus PCA | 99.00 | 97.00 | 98.00 | - | - |
| Ali et al. [43] | MLP | 97.95 | 98.00 | 98.00 | - | - |
| D. Zhang et al. [44] | Linear SVC + DNN | 98.56 | 99.35 | 97.84 | - | - |
| Proposed Base model results | RF | 100 | 100 | 100 | 100 | 100 |
| DT | 98.80 | 99 | 98 | 100 | 99 | |
| GB | 97.60 | 98 | 98 | 98 | 100 | |
| KNN | 90.80 | 84 | 97 | 90 | 97 | |
| AB | 88.00 | 91 | 86 | 89 | 94 | |
| LR | 84.80 | 89 | 82 | 86 | 91 | |
| NN | 84.80 | 92 | 81 | 86 | 91 | |
| QDA | 83.60 | 85 | 83 | 84 | 91 | |
| Nu SVC | 83.20 | 91 | 79 | 85 | 90 | |
| LDA | 82.80 | 87 | 80 | 84 | 91 | |
| NB | 82.40 | 86 | 81 | 83 | 88 | |
| SVM | 68.80 | 69 | 69 | 69 | 73 | |
| Proposed Stratified (K = 5)-Fold Cross-validation Results | RF | 99.41 | 100 | 98.89 | 99.40 | 99.97 |
| DT | 99.60 | 99.23 | 100 | 99.61 | 99.62 | |
| GB | 99.41 | 99.50 | 99.45 | 99.53 | 100 | |
| KNN | 86.06 | 86.19 | 86.25 | 86.04 | 94.86 | |
| AB | 90.93 | 89.99 | 92.24 | 91.05 | 97.57 | |
| LR | 84.59 | 89.98 | 82.31 | 85.59 | 91.88 | |
| NN | 95.03 | 95.64 | 94.76 | 95.19 | 98.54 | |
| QDA | 94.16 | 94.49 | 94.27 | 94.33 | 98.74 | |
| Nu SVC | 94.83 | 95.45 | 94.60 | 94.97 | 98.54 | |
| LDA | 93.56 | 93.54 | 93.93 | 93.71 | 98.60 | |
| NB | 82.15 | 85.94 | 80.63 | 83.12 | 90.76 | |
| SVM | 92.19 | 93.36 | 91.68 | 92.49 | 97.24 | |
| Proposed stacking CV Classifier | RF | 100 | 100 | 100 | 100 | - |
| DT | 100 | 100 | 100 | 100 | - | |
| GB | 89.26 | 89 | 89 | 89 | - | |
| KNN | 86.34 | 86.19 | 86.25 | 86.04 | - | |
| AB | 90.00 | 90.00 | 90.00 | 90.00 | - | |
| LR | 86 | 87 | 86 | 86 | - | |
| NN | 97 | 97 | 97 | 97 | - | |
| QDA | 88 | 88 | 88 | 88 | - | |
| Nu SVC | 93.17 | 93 | 93 | 93 | - | |
| LDA | 86 | 87 | 86 | 86 | - | |
| NB | 87 | 87 | 87 | 87 | - | |
| SVM | 99 | 98 | 99 | 99 | - | |
| RFC+NN+SVM | 100 | 100 | 100 | 100 | - | |
| RFC+NN+QDA | 100 | 100 | 100 | 100 | - | |
| RFC+NN | 100 | 100 | 100 | 100 | - | |
| LDA+QDA | 89 | 89 | 89 | 89 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, G.N.; Shafiullah; Fatima, H.; Abbas, M.; Rahman, O.; Imdadullah; Alqahtani, M.S. Mixed Machine Learning Approach for Efficient Prediction of Human Heart Disease by Identifying the Numerical and Categorical Features. Appl. Sci. 2022, 12, 7449. https://doi.org/10.3390/app12157449
Ahmad GN, Shafiullah, Fatima H, Abbas M, Rahman O, Imdadullah, Alqahtani MS. Mixed Machine Learning Approach for Efficient Prediction of Human Heart Disease by Identifying the Numerical and Categorical Features. Applied Sciences. 2022; 12(15):7449. https://doi.org/10.3390/app12157449
Chicago/Turabian StyleAhmad, Ghulab Nabi, Shafiullah, Hira Fatima, Mohamed Abbas, Obaidur Rahman, Imdadullah, and Mohammed S. Alqahtani. 2022. "Mixed Machine Learning Approach for Efficient Prediction of Human Heart Disease by Identifying the Numerical and Categorical Features" Applied Sciences 12, no. 15: 7449. https://doi.org/10.3390/app12157449
APA StyleAhmad, G. N., Shafiullah, Fatima, H., Abbas, M., Rahman, O., Imdadullah, & Alqahtani, M. S. (2022). Mixed Machine Learning Approach for Efficient Prediction of Human Heart Disease by Identifying the Numerical and Categorical Features. Applied Sciences, 12(15), 7449. https://doi.org/10.3390/app12157449