
Big Data ETL Process and Its Impact on Text Mining Analysis for Employees’ Reviews



Abstract
:1. Introduction
2. Background and Related Work
2.1. Web Scraping
2.2. Artificial Intelligence and Sentiment Analysis
3. Methods and Results
3.1. Business Understanding
3.2. Data Collection
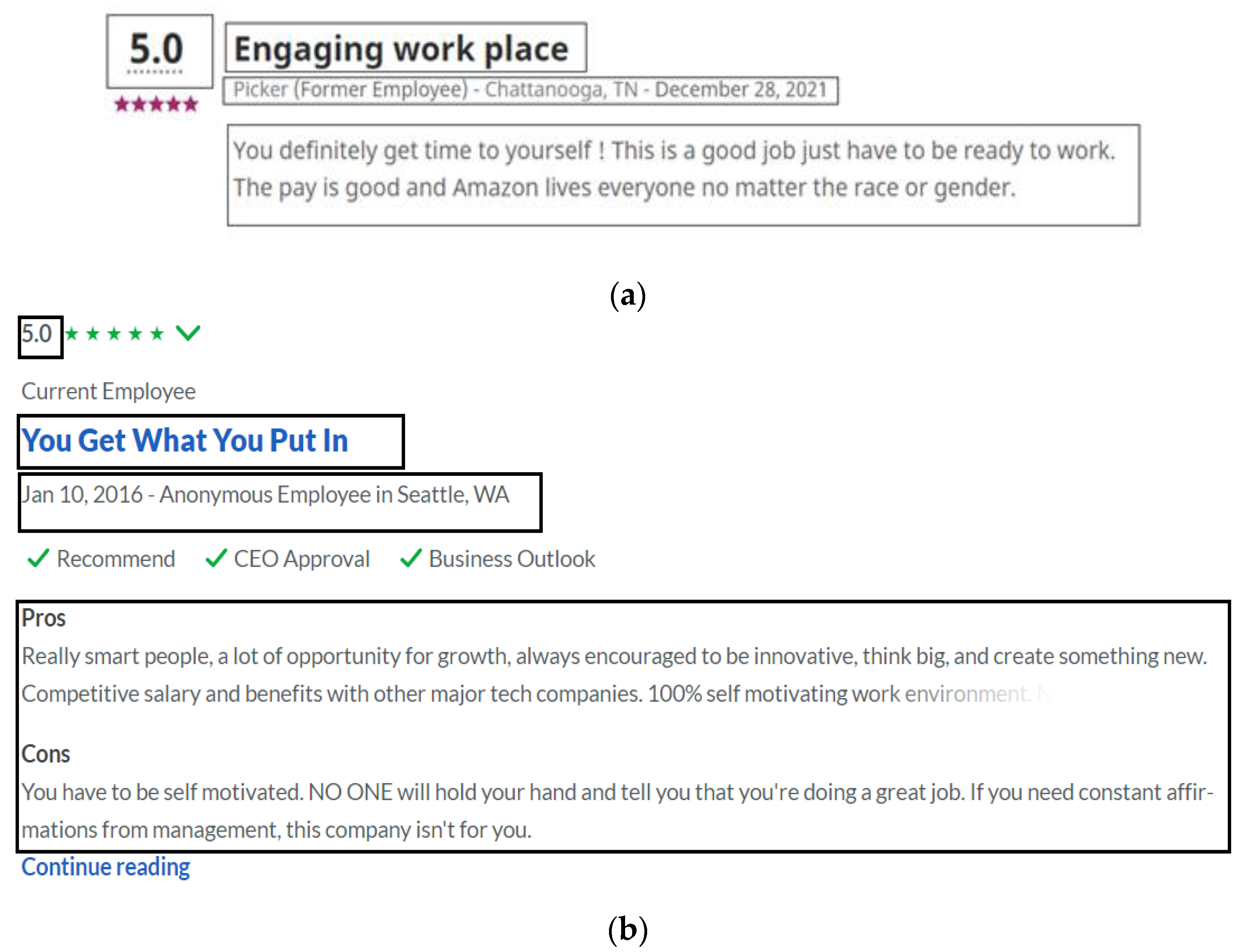
3.2.1. Web Scraping Process
3.2.2. Data Analysis and Distribution
3.3. Data Preparation
- Tokenization consists of breaking complex sentences into words, and it will understand the importance of each word as well with respect to the sentence.
- Stemming is the process of normalizing words into their base form or root form.
- Lemmatization will group together different inflected forms of the word. This is similar to stemming, because it will map several words having the same meaning of the root output in a proper word.
- Removing special characters.
- Removing extra new lines.
- Removing accented characters.
- Removing contractions will mean the contribution to text standardization and expand the words or combinations of words that were previously shortened by dropping letters and replacing them with an apostrophe.
- Removing stop words is the process that will remove the unnecessary words of the sentences, in order to reduce the size of the corpus.
3.4. Data Modeling
3.4.1. Lexicon-Based Approach for Labeling Initial Set of Data
3.4.2. Machine Learning Techniques and Data Processing for Sentiment Classification
- Naïve Bayes— Naïve Bayes classifiers are a collection of classification algorithms based on Bayes’ Theorem. It is not a single algorithm but a family of algorithms, where all of them share a common principle, i.e., every pair of features being classified is independent of each other. Bayes’ Theorem finds the probability of an event occurring given the probability of another event that has already occurred [34]. In addition, Naïve Bayes is mainly used for data pre-processing applications due to the fact that it does not require many resources. Bayesian reasoning and probability inference are all involved in predicting the target class, while attributes play an important role in the classification. Therefore, it might improve the overall performance of the assignment of different weight values to attributes [33].
- Logistic Regression—Logistic Regression is a type of linear regression that does not require linearity between the independent variables, while the dependent ones do not require a normal distribution. This method can be applied regardless of the types of variables: discrete, continuous or binary. This algorithm proved to perform for classification problems but had similar results to others that are easier to apply [35]. This algorithm, working in supervised learning, selects the best subjects to be labeled to achieve a good classification, a fact that represents an opportunity to reduce temporal costs. Moreover, active learning is engaged to find the best subject possible to label these machine learning models, a fact that represents a growing field of research in the area of text mining [33].
- KNN—K-Nearest Neighbor is a nonparametric classifier that learns from the similarities between classes. It uses a distance function for the relevant features and once a new record is added to the model, it analyzes its pattern and compares it with the nearest neighbors, adding it to the most similar class [36]. Even though this algorithm is robust for noisy data, deciding the exact value of k can be a complicated subject. Computation complexity further increases, with an increase that can be seen in dimensionality as well. Therefore, to reduce the cost of computing the k value, tree-based KNN is generally used [33].
- SVM—Support Vector Machine is a supervised machine learning algorithm used for both classification and regression. The objective of the SVM algorithm is to find a hyperplane in an N-dimensional space that distinctly classifies the data points. The dimension of the hyperplane depends upon the number of features. Compared to newer algorithms such as neural networks, they have two main advantages: higher speed and better performance with a limited number of samples (in the thousands) [34]. SVMs are particularly suitable for high-dimensional data, while the complexity associated with the classifiers depends on the number of the support vectors instead of data dimensions, a fact that produces the same hyper plane for repeated training sets [33].
3.5. Evaluation
3.6. Deployment
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sagiroglu, S.; Sinanc, D. Big data: A review. In Proceedings of the 2013 International Conference on Collaboration Technologies and Systems (CTS), San Diego, CA, USA, 20–24 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 42–47. [Google Scholar]
- Zhang, Y.; Xu, S.; Zhang, L.; Yang, M. Big data and human resource management research: An integrative review and new directions for future research. J. Bus. Res. 2021, 133, 34–50. [Google Scholar] [CrossRef]
- Popovič, A.; Hackney, R.; Tassabehji, R.; Castelli, M. The impact of big data analytics on firms’ high value business performance. Inf. Syst. Front. 2018, 20, 209–222. [Google Scholar] [CrossRef] [Green Version]
- Şerban, R.A. The impact of big data, sustainability, and digitalization on company performance. Stud. Bus. Econ. 2017, 12, 181–189. [Google Scholar] [CrossRef] [Green Version]
- Mikalefa, P.; Bourab, M.; Lakekosb, G.; Krogstie, J. Big data analytics and firm performance: Findings from a mixed-method approach. J. Bus. Res. 2019, 98, 261–276. [Google Scholar] [CrossRef]
- Tambe, P.; Cappelli, P.; Yakubovich, V. Artificial intelligence in human resources management: Challenges and a path forward. Calif. Manag. Rev. 2019, 61, 15–42. [Google Scholar] [CrossRef]
- Kitchin, R.; McArdle, G. What makes Big Data, Big Data? Exploring the ontological characteristics of 26 datasets. Big Data Soc. 2016, 3, 2053951716631130. [Google Scholar] [CrossRef]
- Vargiu, E.; Urru, M. Exploiting web scraping in a collaborative filtering-based approach to web advertising. Artif. Intell. Res. 2013, 2, 44–54. [Google Scholar] [CrossRef] [Green Version]
- Neves, P.; Mata, J.N.M.; Rita, J.X.; Correia, I.B. Sentiment Analysis—A literature review. Acad. Entrep. 2021, 27, 2S. [Google Scholar]
- Glez-Peña, D.; Lourenço, A.; López-Fernández, H.; Reboiro-Jato, M.; Fdez-Riverola, F. Web scaping technologies in an API world. Brienfings Bioinform. 2014, 15, 788–794. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saurkar, A.V.; Pathare, K.G.; Gode, S.A. An overview on web scraping techniques and tools. Int. J. Future Revolut. Comput. Sci. Commun. Eng. 2018, 4, 363–367. [Google Scholar]
- Hillen, J. Web scraping for food price research. Br. Food J. 2019, 121, 3350–3361. [Google Scholar] [CrossRef]
- Thota, P.; Ramez, E. Web Scraping of COVID-19 News Stories to Create Datasets for Sentiment and Emotion Analysis. In Proceedings of the 14th PErvasive Technologies Related to Assistive Environments Conference, Corfu, Greece, 29 June–2 July 2021; pp. 306–314. [Google Scholar]
- Dallmeier, E.C. Computer Vision-based Web Scraping for Internet Forums. In Proceedings of the International Conference on Optimization and Applications, Wolfenbüttel, Germany, 19–20 May 2021. [Google Scholar]
- Persson, E. Evaluationg Tools and Tecniques for Web Scraping. Master’s Thesis, School of Electrical Engineering and Computer Science, KTH Royal Institute of Technology, Stockholm, Sweden, 2019. [Google Scholar]
- Antonio, R.; Paolo, R. Making objective decisions from subjective data: Detecting irony in customer reviews. Decis. Support Syst. 2012, 53, 754–760. [Google Scholar]
- Gerani, S.; Carman, M.; Crestani, F. Aggregation Methods for Proximity-Based Opinion Retrieval. ACM Trans. Inf. Syst. 2021, 30, 1–36. [Google Scholar] [CrossRef]
- Loia, V.; Senatore, S. A fuzzy-oriented sentic analysis to capture the human emotion in Web-based content. Knowledge-Based Syst. 2014, 58, 75–85. [Google Scholar] [CrossRef]
- Vechtomova, O.; Karamuftuoglu, M. Lexical cohesion and term proximity in document ranking. Inform. Process. Manag. 2008, 44, 1485–1502. [Google Scholar] [CrossRef]
- Vechtomova, O. Facet-based opinion retrieval from blogs. Inform. Process. Manag. 2010, 46, 71–88. [Google Scholar] [CrossRef] [Green Version]
- Banea, C.; Mihalcea, R.; Wiebe, J. Multilingual subjectivity: Are more languages better? In Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), Beijing, China, 23–27 August 2010; pp. 28–36. [Google Scholar]
- Sharma, D.; Sabharwal, M.; Goyal, V.; Vij, M. Sentiment analysis techniques for social media data: A review. In First International Conference on Sustainable Technologies for Computational Intelligence; Springer: Singapore, 2020; pp. 75–90. [Google Scholar]
- Dandannavar, P.S.; Mangalwede, S.R.; Deshpande, S.B. Emoticons and their effects on sentiment analysis of Twitter data. In EAI International Conference on Big Data Innovation for Sustainable Cognitive Computing; Springer: Cham, Switzerland, 2020; pp. 191–201. [Google Scholar]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- Qiu, G.; He, X.; Zhang, F.; Shi, Y.; Bu, J.; Chen, C. DASA: Dissatisfaction-oriented advertising based on sentiment analysis. Expert Syst. Appl. 2010, 37, 6182–6191. [Google Scholar] [CrossRef]
- Shekhar, S. Text Mining and Sentiment Analysis. Int. Res. J. Eng. Technol. 2021, 8, 282–290. [Google Scholar]
- Zhang, W.; Yoshida, T.; Tang, X. Text classification based on multi-word with support vector machine. Knowledge-Based Syst. 2008, 21, 879–888. [Google Scholar] [CrossRef]
- Al-Shiakhli, S. Big Data Analysis: A Literature Review Perspective. Master’s Thesis, Department of Computer Science, Electrical and Space Engineering, Luleå University of Technology, Luleå, Sweden, 2019. [Google Scholar]
- Palacios, H.J.G.; Toledo, R.A.J.; Pantoja, G.A.H.; Navarro, Á.A.M. A comparative between CRISP-DM and SEMMA through the construction of a MODIS repository for studies of land use and cover change. Adv. Sci. Technol. Eng. Syst. J. 2017, 2, 598–604. [Google Scholar] [CrossRef] [Green Version]
- Parthvi, S. Sentiment Analysis Using TextBlob. Towards Data Science June 2020. Available online: https://towardsdatascience.com/my-absolute-go-to-for-sentiment-analysis-textblob-3ac3a11d524 (accessed on 14 May 2022).
- Laksono, R.A.; Sungkono, K.R.; Sarno, R.; Wahyuni, C.S. Sentiment analysis of restaurant customer reviews on TripAdvisor using Naïve Bayes. In Proceedings of the 2019 12th International Conference on Information & Communication Technology and System (ICTS), Surabaya, Indonesia, 18 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 49–54. [Google Scholar]
- Qader, W.A.; Ameen, M.M.; Ahmed, B.I. An overview of bag of words; importance, implementation, applications, and challenges. In Proceedings of the 2019 International Engineering Conference (IEC), Erbil, Iraq, 23–25 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 200–204. [Google Scholar]
- Thangaraj, M.; Sivakami, M. Text classification techniques: A literature review. Interdiscip. J. Inf. Knowl. Manag. 2018, 13, 117. [Google Scholar] [CrossRef] [Green Version]
- Bhuta, S.; Doshi, A.; Doshi, U.; Narvekar, M. A review of techniques for sentiment analysis of twitter data. In Proceedings of the 2014 International Conference on Issues and Challenges in Intelligent Computing Techniques (ICICT), Ghaziabad, India, 7–8 February 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 583–591. [Google Scholar]
- Sperandei, S. Understanding logistic regression analysis. Biochem. Med. 2014, 24, 12–18. [Google Scholar] [CrossRef] [PubMed]
- Sutton, O. Introduction to k nearest neighbour classification and condensed nearest neighbour data reduction. Univ. Lect. Univ. Leic. 2012, 1, 1–10. [Google Scholar]
- Kanstrén, T. A Look at Precision, Recall, and F1-Score. Towards Data Science September 2020. Available online: https://towardsdatascience.com/a-look-at-precision-recall-and-f1-score-36b5fd0dd3ec (accessed on 20 May 2022).
- Pannakkong, W.; Thiwa-Anont, K.; Singthong, K.; Parthanadee, P.; Buddhakulsomsiri, J. Hyperparameter Tuning of Machine Learning Algorithms Using Response Surface Methodology: A Case Study of ANN, SVM, and DBN. Math. Probl. Eng. 2022, 2022, 8513719. [Google Scholar] [CrossRef]
- Borg, A.; Boldt, M. Using VADER sentiment and SVM for predicting customer response sentiment. Expert Syst. Appl. 2020, 162, 113746. [Google Scholar] [CrossRef]
- Fersini, E. Sentiment analysis in social networks: A machine learning perspective. In Sentiment Analysis in Social Networks; Morgan Kaufmann: Burlington, MA, USA, 2017; pp. 91–111. [Google Scholar]
- Khattak, A.; Asghar, M.Z.; Saeed, A.; Hameed, I.A.; Hassan, S.A.; Ahmad, S. A survey on sentiment analysis in Urdu: A resource-poor language. Egypt. Inform. J. 2021, 22, 53–74. [Google Scholar] [CrossRef]
- Cho, S.B.; Lee, J.H. Learning neural network ensemble for practical text classification. In International Conference on Intelligent Data Engineering and Automated Learning; Springer: Berlin/Heidelberg, Germany, 2003; pp. 1032–1036. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Website | URL | Element | Selector | Type | Value |
|---|---|---|---|---|---|
| Indeed.com | https://www.indeed.com/cmp/Amazon.com/reviews | author | h2 | itemprop | author |
| Glassdoor | https://www.glassdoor.com/Reviews/Amazon-Reviews-E6036.htm | author | span | class | authorInfo |
| Method | Time | Number of Records | Cluster Type |
|---|---|---|---|
| Using metadata | 3.40 h | 66,854 | Runtime version: 10.3 Worker type: 14 GB Memory, 4 cores Driver type: 14 GB Memory, 4 cores |
| Without metadata | 1.58 h | 67,141 |
| Year | No of Records | Avg Overall Rating | Avg Work-Life Balance | Avg Pay Benefits | Avg Job Security | Avg Management | Avg Culture |
|---|---|---|---|---|---|---|---|
| 2012 | 539 | 3.71 | 2.99 | 3.38 | 2.92 | 2.98 | 3.19 |
| 2013 | 1265 | 3.78 | 2.99 | 3.32 | 2.85 | 3.01 | 3.24 |
| 2014 | 2032 | 3.74 | 3.05 | 3.33 | 2.9 | 2.91 | 3.15 |
| 2015 | 2981 | 3.67 | 3.05 | 3.41 | 2.94 | 2.93 | 3.15 |
| 2016 | 4224 | 3.67 | 3.1 | 3.52 | 3.04 | 2.97 | 3.21 |
| 2017 | 10,168 | 3.67 | 3.2 | 3.61 | 3.14 | 3.12 | 3.31 |
| 2018 | 13,552 | 3.55 | 3.17 | 3.55 | 3.03 | 3.07 | 3.24 |
| 2019 | 16,820 | 3.52 | 3.07 | 3.46 | 2.93 | 2.91 | 3.12 |
| 2020 | 15,187 | 3.47 | 3.17 | 3.46 | 2.98 | 2.91 | 3.15 |
| 2021 | 10,688 | 3.05 | 2.88 | 3.32 | 2.71 | 2.57 | 2.76 |
| 2022 | 45 | 3.38 | 2.98 | 3.42 | 2.89 | 2.82 | 2.78 |
| Overall | 77,501 | 3.49 | 3.1 | 3.47 | 2.96 | 2.92 | 3.13 |
| Algorithm | TN | FP | FN | TP | Accuracy | Precision | Recall | F1-score |
|---|---|---|---|---|---|---|---|---|
| TextBlob lexion method | 71 | 25 | 35 | 77 | 71% | 75% | 69% | 72% |
| Algorithm | Dataset | TN | FP | FN | TP | Accuracy | Precision | Recall | F1-score |
|---|---|---|---|---|---|---|---|---|---|
| Naïve Bayes | Dataset 1 | 3329 | 1235 | 1094 | 6943 | 82% | 85% | 86% | 86% |
| Dataset 2 | 6562 | 7254 | 1063 | 21,751 | 77% | 75% | 95% | 84% | |
| Logistic Regression | Dataset 1 | 3986 | 578 | 551 | 7486 | 91% | 93% | 93% | 93% |
| Dataset 2 | 12,575 | 1241 | 1482 | 21,332 | 93% | 95% | 94% | 94% | |
| K-NN | Dataset 1 | 3176 | 1388 | 3227 | 4810 | 63% | 78% | 60% | 68% |
| Dataset 2 | 8043 | 5773 | 4203 | 18,611 | 73% | 76% | 82% | 79% | |
| SVM | Dataset 1 | 3947 | 617 | 594 | 7443 | 90% | 92% | 93% | 92% |
| Dataset 2 | 12,526 | 1290 | 1499 | 21,315 | 92% | 94% | 93% | 94% |
| Algorithm | Method | TN | FP | FN | TP | Best Accuracy |
|---|---|---|---|---|---|---|
| Naïve Bayes | Grid Search | 7009 | 6797 | 1308 | 21,516 | 77.75% |
| Random Search | 12,216 | 1590 | 3209 | 19,615 | 77.67% | |
| Logistic Regression | Grid Search | 12,820 | 986 | 1384 | 21,440 | 93.44% |
| Random Search | 12,526 | 1277 | 1452 | 21,372 | 92.51% | |
| K-NN | Grid Search | 8503 | 5303 | 4596 | 18,228 | 72.89% |
| Random Search | 7712 | 6094 | 4896 | 17,928 | 72.43% | |
| SVM | Gird Search | N/A | N/A | N/A | N/A | N/A |
| Random Search | N/A | N/A | N/A | N/A | N/A |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tanasescu, L.G.; Vines, A.; Bologa, A.R.; Vaida, C.A. Big Data ETL Process and Its Impact on Text Mining Analysis for Employees’ Reviews. Appl. Sci. 2022, 12, 7509. https://doi.org/10.3390/app12157509
Tanasescu LG, Vines A, Bologa AR, Vaida CA. Big Data ETL Process and Its Impact on Text Mining Analysis for Employees’ Reviews. Applied Sciences. 2022; 12(15):7509. https://doi.org/10.3390/app12157509
Chicago/Turabian StyleTanasescu, Laura Gabriela, Andreea Vines, Ana Ramona Bologa, and Claudia Antal Vaida. 2022. "Big Data ETL Process and Its Impact on Text Mining Analysis for Employees’ Reviews" Applied Sciences 12, no. 15: 7509. https://doi.org/10.3390/app12157509
APA StyleTanasescu, L. G., Vines, A., Bologa, A. R., & Vaida, C. A. (2022). Big Data ETL Process and Its Impact on Text Mining Analysis for Employees’ Reviews. Applied Sciences, 12(15), 7509. https://doi.org/10.3390/app12157509