In general, a complete finger vein–based biometric recognition system can be divided into four steps: image acquisition, preprocessing, feature extraction, and feature matching. First, vein images are captured with NIR optical imaging techniques, after which quality enhancement is carried out via several preprocessing steps, such as image filtering [
6], region of interest (ROI) extraction [
7], and image normalization [
8]. The enhanced images are then subjected to feature extraction, in which discriminative features are extracted from the individual vein images to enable good recognition performance during feature matching. To this end, several studies have been conducted to develop finger vein recognition systems based on conventional mathematical models [
9,
10,
11,
12,
13,
14,
15,
16,
17,
18], machine learning (ML) [
19,
20,
21,
22,
23,
24,
25], and deep learning (DL) [
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36].
2.1. Conventional Finger Vein Recognition
Different types of conventional mathematical models have been utilized for finger vein recognition tasks. The Gabor filter [
9] is a popular feature extraction method employed for finger vein recognition. Due to its ability to detect oriented features by tuning in to a specific frequency, the Gabor filter has been used widely for various pattern recognition tasks [
10]. Similarly, line tracking [
11] methods extract features based on repeated tracking of black pixels in the vein image. The maximum curvature method [
12] extracts features based on the fact that the vein patterns appear like a valley, with a high curvature within the cross-sectional area of the vein image. Furthermore, local feature descriptor–based methods, such as local binary pattern (LBP) and local derivative pattern (LDP), are also widely used methods of feature extraction [
13]. They extract features based on binary codes obtained by comparing the gray value of the center pixel with the neighboring pixels. However, due to low robustness, high computational complexity, and poor feature extraction capabilities, these techniques are at a great disadvantage when implementing practical finger vein recognition systems. Furthermore, these conventional approaches utilize distance-based, trivial feature–matching algorithms, such as Hamming distance [
14], Euclidean distance [
15], cross correlation matching [
16], template matching [
17], and histogram intersection matching [
18] to obtain a matching score for verification purposes. These types of feature matching techniques are not suitable for providing reliable recognition performance when the capture devices and image acquisition environment vary according to various applications or the authentication service.
2.2. Deep Learning Based Finger Vein Recognition
With the breakthrough of big data and DL in several image processing tasks, such as classification [
26], object detection [
27], and digital image processing [
28], the application of DL has also been considered for fast and automatic feature extraction from finger vein images [
29,
30,
31,
32,
33,
34,
35,
36]. Due to the robustness of feature representations, a DL technique can be a novel candidate for finger vein recognition, irrespective of the shape and orientation of the vein patterns. Using large amounts of training samples, a DL algorithm such as the convolutional neural network (CNN) can provide powerful feature extraction capabilities with vein images and can quickly adapt to learning those feature representations. In [
29], a densely connected convolutional neural network (DenseNet) was used for finger vein recognition where the matching score was generated by the score level fusion of shape and texture images. A similar study was investigated in [
30], where a three-channel composite image was used as input to the DenseNet-based recognition network and provided good recognition performance. To achieve robust recognition performance from finger vein biometrics, the common CNN architecture has been extensively used in recent research [
31,
32,
33]. Furthermore, to learn more robust features directly from the raw pixels of the finger vein image, the convolutional autoencoder (CAE) [
34], recurrent neural networks (RNNs) [
35], and generative adversarial networks (GANs) [
36] have been researched as well.
Although previous DL-based finger vein recognition techniques have offered promising recognition performance, they still suffer from relevant shortcomings, especially associated with mediocre feature extraction procedures. The finger vein images may include not only vein patterns but also irregular noise and intensity degradation due to the various finger shapes and muscles. Due to infirmly designed feature extraction networks in existing methods, the models cannot properly learn distinctive features of finger vein patterns, and thus, a unique representation of the vein patterns of each subject cannot be accessed, and this ultimately results in poor accuracy. Besides, currently available finger vein image databases acquired via infrared imaging offer significantly poor visual quality in the vein patterns. Thus, for higher recognition performance, poor image quality must be complemented by designing an effective preprocessing pipeline and a robust feature extractor.
To overcome such limitations, in this paper, we propose FVR-Net, which is a novel CNN-based hybrid pooling network for finger vein recognition system that supports exquisite feature extraction to enable accurate recognition of finger vein images, regardless of the acquisition procedures of existing datasets. FVR-Net was designed to capture intricate vein features from the input images through several convolutional and subsampling layers. Unlike previous studies, FVR-Net introduces block-wise feature extraction with hybrid pooling where two subsampling layers (maxpooling and average pooling) in each block are placed in parallel after the convolutional layer, whose output activation maps are concatenated before passing features to another block. In hybrid pooling, the subsampling layers placed in parallel concurrently activate the most discriminative features of each input and provide excellent localization of those features. Upon forward pass, these blocks tend to extract multilevel and discrete interclass features of the input, which means they are able to uniquely represent the vein samples from different categories when subjected to classification with three fully connected layers (FCLs). In the whole process, the finger vein images are first subjected to preprocessing where ROI cropping and quality enhancement is achieved, along with proper segmentation of vein patterns from the background. Subsequently, clear vein images are fed into the feature extraction network, which consists of five blocks for low-level feature extraction followed by three FCLs for the classification task. Each block comprises a 2D convolutional layer and two subsampling operations: 2D average pooling and 2D maxpooling. The features learned from the blocks facilitate robust vein classification through the FCLs, where the probability score of each input is generated through a SoftMax classifier. To verify the effectiveness of the proposed model, it was trained and tested on publicly available finger vein databases. In particular, the image samples from Hong Kong Polytechnic University (HKPU) [
3] and Finger Vein Universiti Sains Malaysia (FVUSM) [
37] datasets are characterized according to their visual quality (good and poor), with poor-quality images being likely to yield lower recognition performance. During inference, the test images of the corresponding datasets provide discriminating recognition accuracy, compared to the conventional schemes. Overall, FVR-Net enhanced the recognition accuracy with HKPU and FVUSM datasets by up to 13% and 30%, respectively, for good quality images, and 9% and 31%, respectively, for poor quality images.
The rest of this paper is organized as follows.
Section 2 presents the proposed model, describing data preprocessing and the network architecture. In
Section 3, the experiments and results are presented. Finally, concluding remarks are provided in
Section 4.




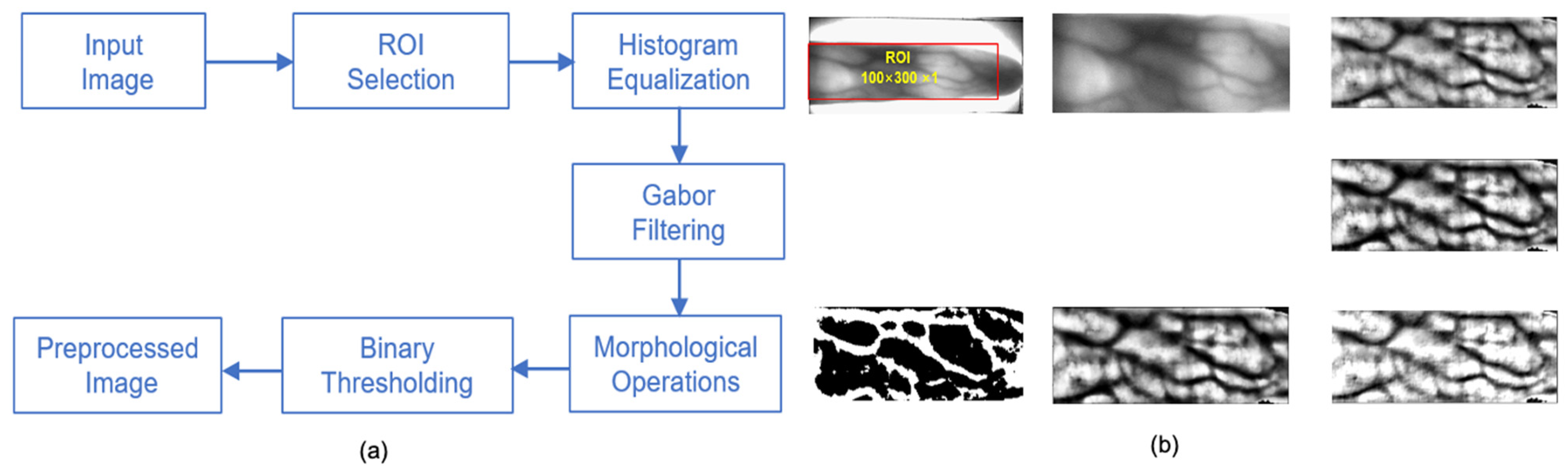





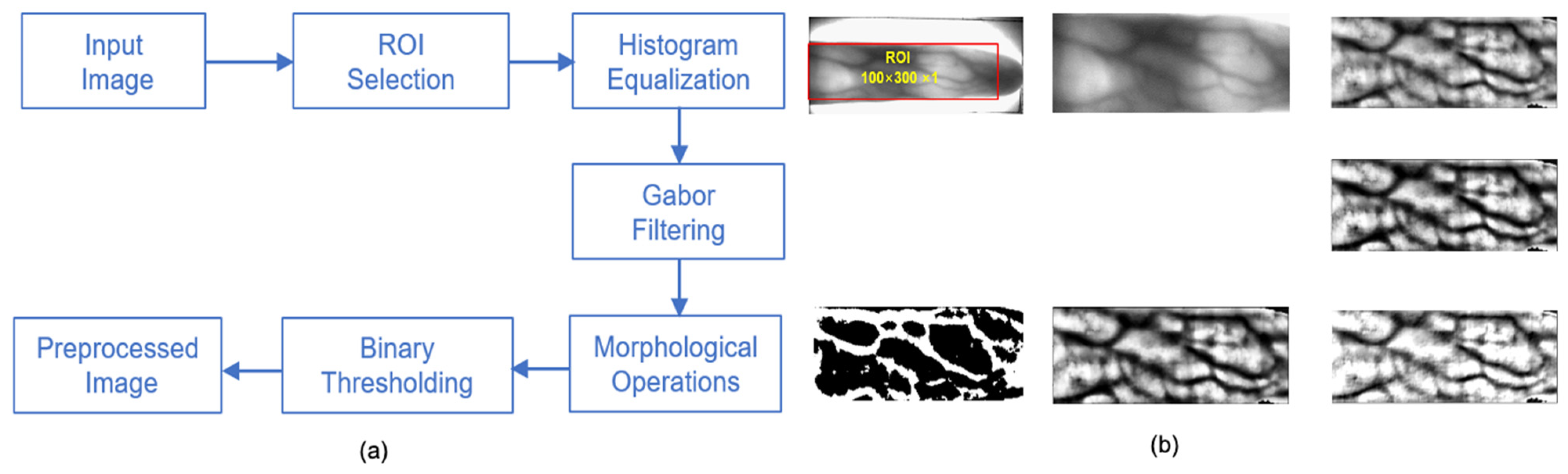{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}