
An Intelligent DOA Estimation Error Calibration Method Based on Transfer Learning

Abstract
:1. Introduction
- We propose an intelligent DOA estimation error calibration method based on transfer learning, which learns error knowledge of the actual environment from a small number of signal samples and improves the DOA estimation accuracy in practical application.
- We generate a large number of ideal simulation signal samples to train an intelligent DOA estimation model constructed based on CNN. Then, we fine tune the model with a small number of actual signal samples collected in the actual environment. Before and after transfer learning, the model’s tasks are the same, and the working environment is transferred from the ideal condition to the actual environment.
- We experimentally show that transfer learning can effectively improve the DOA estimation accuracy in practical application. We further discuss the impact of different fine-tuning approaches (freezing different network layers) and different numbers of actual samples used for fine-tuning. The experimental results indicate that the intelligent DOA estimation model performs better when freezing the first convolutional layer. The more actual signal samples are used for fine-tuning, the better the model performs.
2. Background
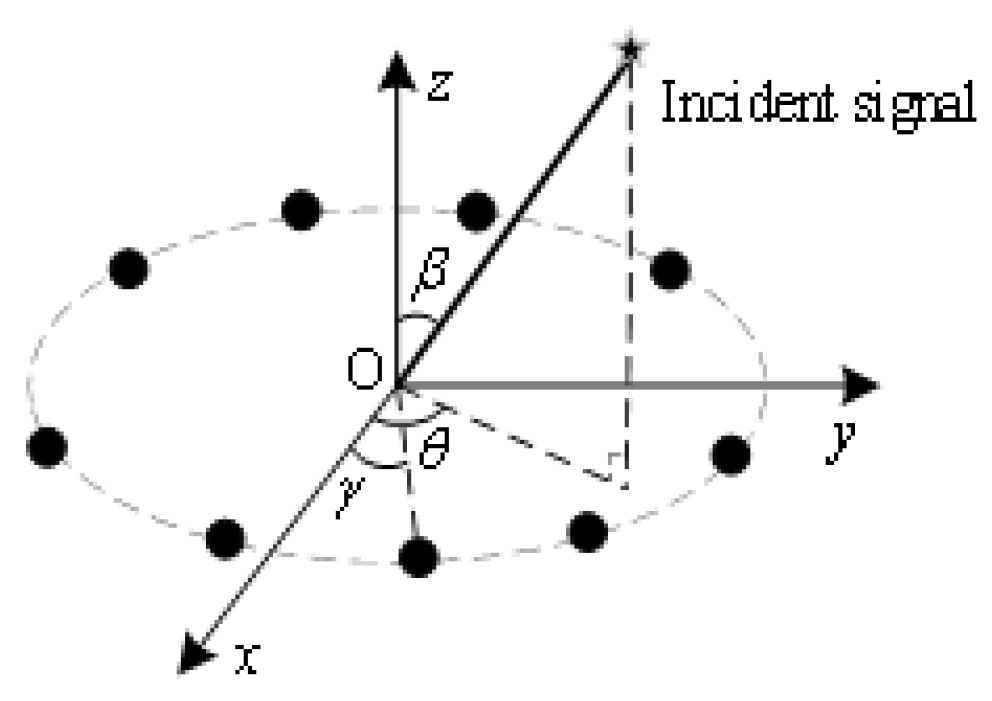
2.1. Signal Model
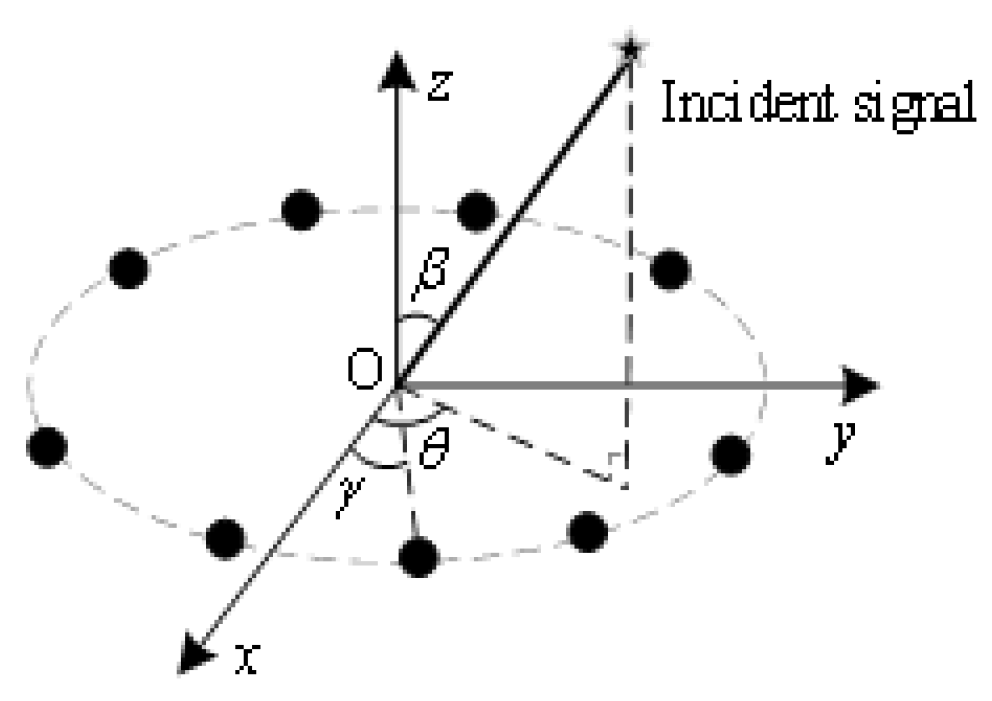
2.2. The Error of Signals
3. Models and Methods
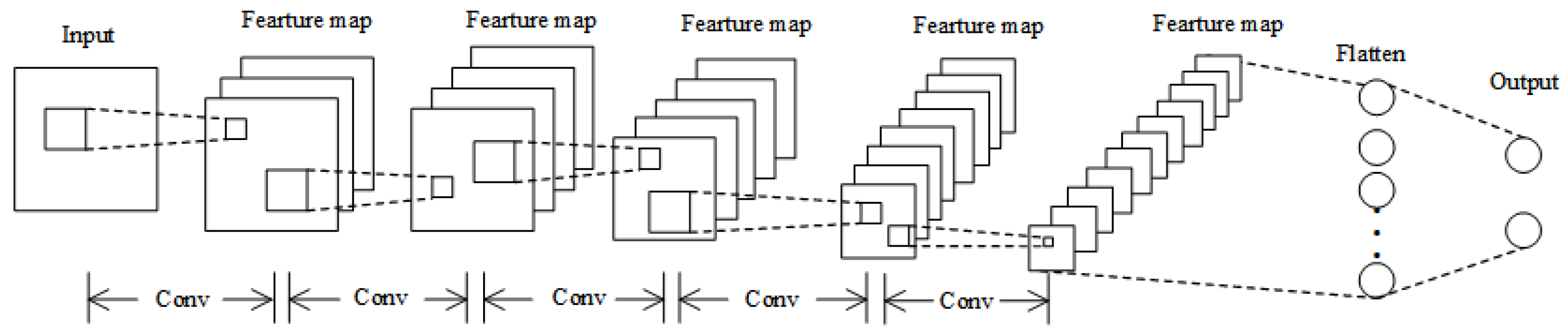
3.1. The DOA Estimation Model Based on CNN
3.2. Error Calibration Method Based on Transfer Learning
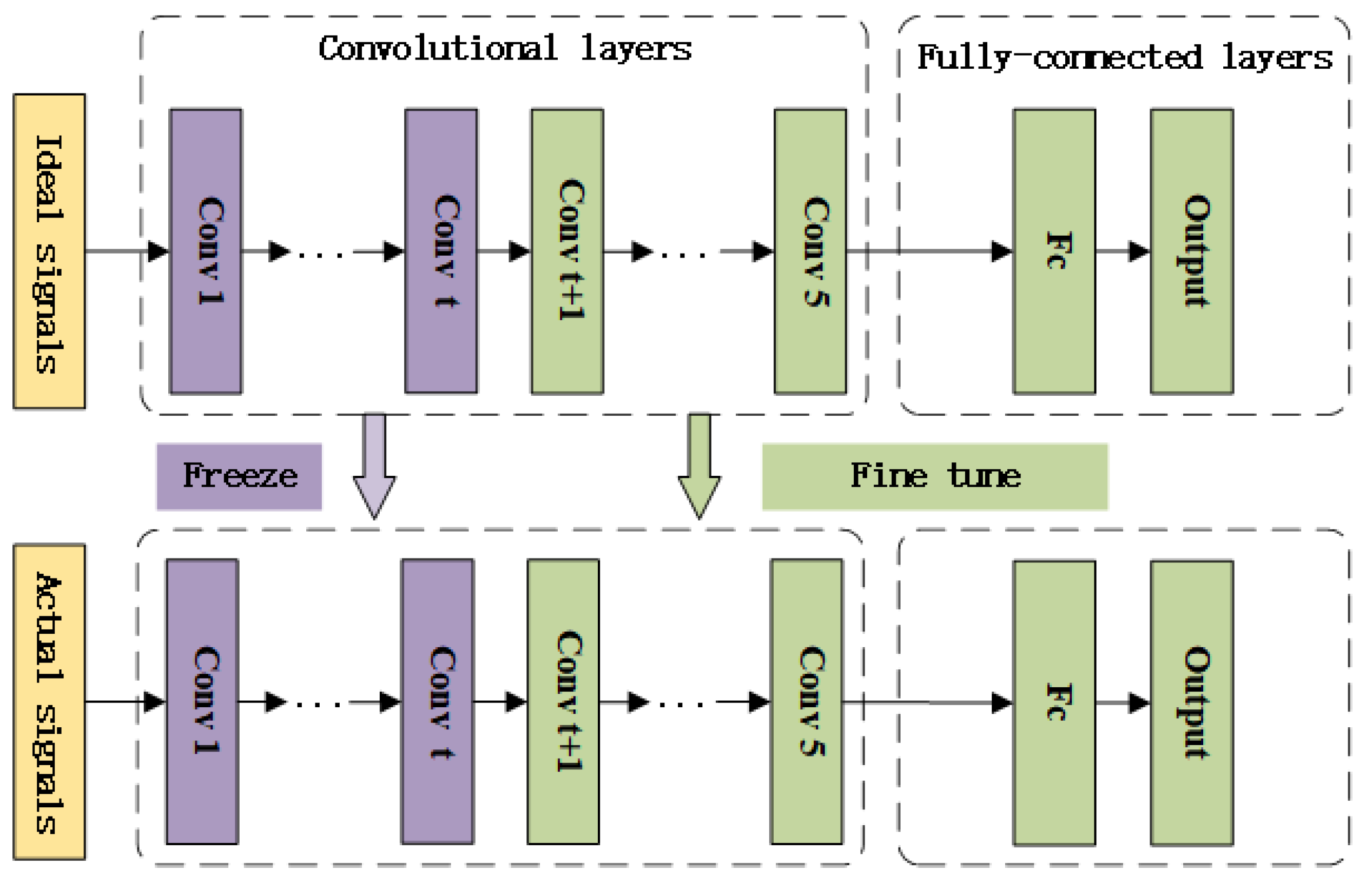
| Algorithm 1: Error calibration method based on transfer learning |
| Input: A large number of ideal simulation signal samples , A small number of actual samples . |
| Output: Fine-tuning trained DOA estimation model |
Process:
|
4. Simulation and Result Analysis
- Experiment environment. The ideal array signal sample is a five-element uniform circular array signal with a frequency range of 100 MHz–200 MHz, signal-to-noise ratio set to 0–25 db, angle range of 0–360°, and interval of 1°. The actual signal sample is a five-element uniform circular array signal collected in the actual environment, with a frequency range of 150 MHz–200 MHz, an angle range of 0–360°, and an interval of 5°.Collection of actual signals. We use a circular array of five-channel ultrashortwave correlation interferometer direction finding equipment to collect the actual signal samples, and the data obtained is the phase difference data of the actual signal.The receiving antenna array of the ultrashort wave direction-finding equipment we used to collect actual signal samples is five-element uniform circular array. The antenna array is divided into upper and lower layers. The upper layer is used to receive ultrashort wave spatial signal source and the working frequency band is vertical polarization 800~3000 MHz. The lower layer is used to collect a short-wave spatial signal source and the working frequency band is vertical polarization 30~800 MHz. We use the five-element uniform circular array of the lower layer to collect the actual signal samples. Figure 8 shows the positions of the five elements, the five antenna elements are evenly distributed on the circumference with radius m, and the included angle between adjacent elements is 72°. The frequency range is 151~200 MHz, the azimuth range is 0~360°, the angle step is 5°, and the frequency interval is 1 MHz. A total of 3600 samples of actual signal samples were collected, and some of them are shown in Table 1, where represents the phase difference between the array element i and array element j.Table 1. The phase difference between the elements of some actual signals.
Frequency
(MHz)Azimuth
(°)151 −81.397 −131.6 −0.24426 131.66 81.587 0 151 −71.317 −135.07 −12.096 127.76 90.726 5 151 −60.364 −137.2 −24.359 122.38 99.546 10 151 −49.47 −138.45 −35.756 116.07 107.61 15 Frequency
(MHz)Azimuth
(°)151 147 −131.85 131.41 −146.75 0.19037 0 151 153.61 −147.17 115.66 −141.51 19.409 5 151 162.43 −161.56 98.021 −138.07 39.182 10 151 172.08 −174.21 80.31 −136.32 58.141 15 Figure 8. The ultrashort wave direction-finding antenna array.![Applsci 12 07636 g008]() Generation of simulation signals. We generate the simulation signal samples of a five-element uniform circular array with radius m by computer. The frequency range is 100~200 MHz, the azimuth range is 0~360°, the angle step is 1°, and the frequency interval is 0.5 MHz, and the signal-to-noise ratio is 0~25 db. A total of 72,000 samples of actual signal samples were generated.
Generation of simulation signals. We generate the simulation signal samples of a five-element uniform circular array with radius m by computer. The frequency range is 100~200 MHz, the azimuth range is 0~360°, the angle step is 1°, and the frequency interval is 0.5 MHz, and the signal-to-noise ratio is 0~25 db. A total of 72,000 samples of actual signal samples were generated. - Evaluation metrics. There are four evaluation metrics for the intelligent DOA estimation model: average absolute angle error (MAE), root mean square angle error (RMSE), maximum absolute angle error (MAXE), and the ratio of absolute angle error less than 1° (Ratio-1).The MAE is calculated as follows:The RMSE is calculated as follows:The MAXE is calculated as follows:The Ratio-1 is calculated as follows:Among them, is the test angle, is the actual angle, N is the number of test samples, and is the operation of counting quantity.
- Datasets. Training Dataset : 72,000 ideal simulation signal samples are generated under ideal conditions, with a frequency range of 100 MHz–200 MHz. Training Dataset : 1800 actual signal samples are collected in the actual environment, with a frequency range of 150 MHz–200 MHz. Test Dataset D: 1800 actual signal samples, which are different with , with a frequency range of 150 MHz–200 MHz. Angular values of all signal samples are replaced by sine and cosine values, which are the labels.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4.1. Model Structure and Parameters
4.2. Experimental Results
4.2.1. Test Performance on MAE, RMSE, MAXE, and Ratio-1
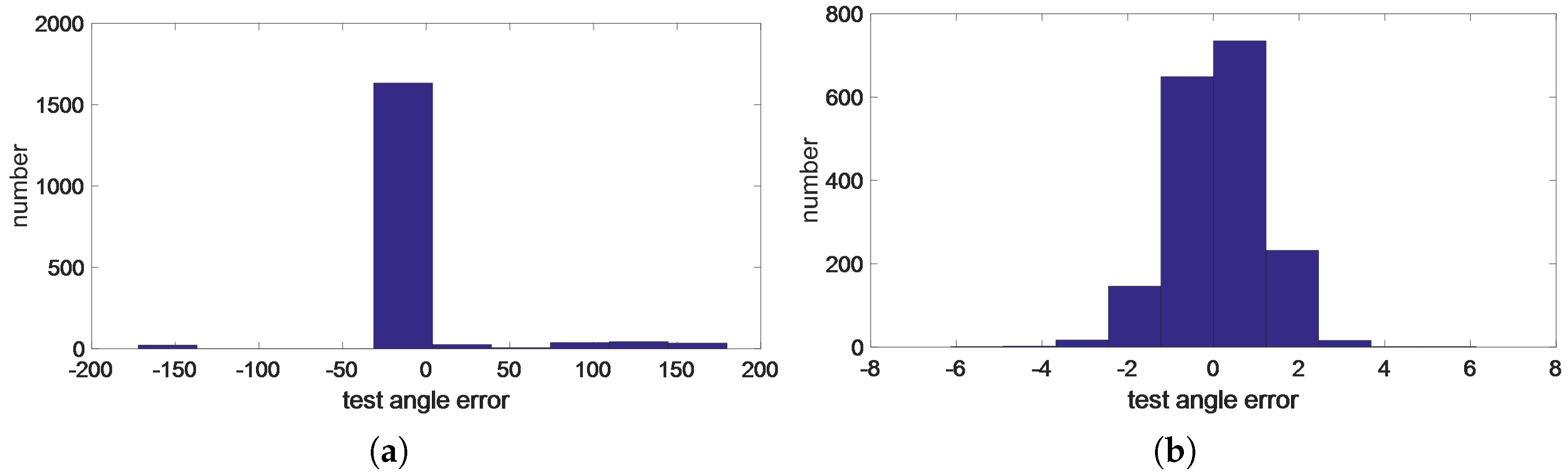
- Transfer learning enables the model to learn the error knowledge in the actual environment with a small number of actual signal samples.
- The error calibration method we proposed based on transfer learning can effectively improve the DOA estimation performance of the model in practical application.
4.2.2. Test Angle
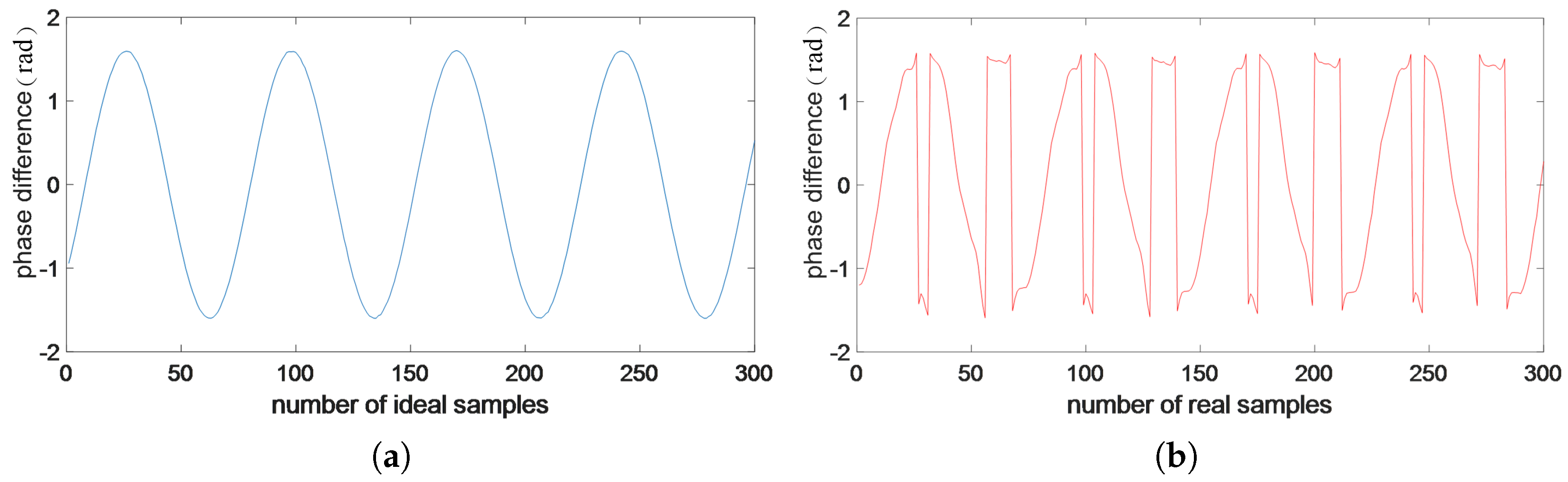
4.2.3. Test Error Distribution
5. Further Analysis
5.1. Freeze Different Layers
- The convolutional layer is the main feature extraction module, and the fully connected layer is the classification module. When all convolutional layers are frozen, the test results of the model are poor, while when some convolutional layers are opened, the test results of the model are significantly improved. This is because the feature extraction module is needed to be fine-tuned when training samples are transferred from the ideal condition to the actual condition.
- In CNN, different convolutional layers extract different features from the input data. The first few convolutional layers extract the common features (bottom features) of the data, and the last few extract the individual features (high-level features), and the transition from the common features to the individual features occurs on some middle layers.
5.2. Different Numbers of Actual Samples
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schmidt, R. Multiple emitter location and signal parameter estimation. IEEE Trans. Antennas Propag. 1986, 34, 276–280. [Google Scholar] [CrossRef] [Green Version]
- Bilik, I. Spatial compressive sensing for direction-of-arrival estimation of multiple sources using dynamic sensor arrays. IEEE Trans. Aerosp. Electron. Syst. 2011, 47, 1754–1769. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, Y.; Shi, B. Gain-phase errors calibration of nested array for underdetermined direction of arrival estimation. AEU-Int. J. Electron. Commun. 2019, 108, 87–90. [Google Scholar] [CrossRef]
- Wang, D.; Wu, Y. A novel array errors active calibration algorithm. Acta Electonica Sin. 2010, 38, 517. [Google Scholar]
- Sellone, F.; Serra, A. A Novel Online Mutual Coupling Compensation Algorithm for Uniform and Linear Arrays. IEEE Trans. Signal Process. 2007, 55, 560–573. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, H.; Huang, W.; Liu, W. Self-calibration of mutual coupling for non-uniform cross-array. Circuits Syst. Signal Process. 2019, 38, 1137–1156. [Google Scholar] [CrossRef]
- Zhang, X.; He, Z.; Zhang, X.; Yang, Y. DOA and phase error estimation for a partly calibrated array with arbitrary geometry. IEEE Trans. Aerosp. Electron. Syst. 2019, 56, 497–511. [Google Scholar] [CrossRef]
- Qin, L.; Li, C.; Du, Y.; Li, B. DoA estimation and mutual coupling calibration algorithm for array in plasma environment. IEEE Trans. Plasma Sci. 2020, 48, 2075–2082. [Google Scholar] [CrossRef]
- Deli, C.; Gong, Z.; Huamin, T.; Huanzhang, L. Approach for wideband direction-of-arrival estimation in the presence of array model errors. J. Syst. Eng. Electron. 2009, 20, 69–75. [Google Scholar]
- Wahlberg, B.; Ottersten, B.; Viberg, M. Robust signal parameter estimation in the presence of array perturbations. In Proceedings of the ICASSP 91: 1991 International Conference on Acoustics, Speech, and Signal Processing, Toronto, ON, Canada, 14–17 April 1991; pp. 3277–3280. [Google Scholar]
- Nikolić, V.N.; Marković, V.V. Determining the DOA of received signal using RBFNN trained with simulated data. In Proceedings of the 2016 24th Telecommunications Forum (TELFOR), Belgrade, Serbia, 22–23 November 2016; pp. 1–4. [Google Scholar]
- Gao, Y.; Hu, D.; Chen, Y.; Ma, Y. Gridless 1-b DOA estimation exploiting SVM approach. IEEE Commun. Lett. 2017, 21, 2210–2213. [Google Scholar] [CrossRef]
- Barthelme, A.; Utschick, W. DoA Estimation Using Neural Network-based Covariance Matrix Reconstruction. IEEE Signal Process. Lett. 2021, 28, 783–787. [Google Scholar] [CrossRef]
- Zhao, A.; Jiang, H.; Zhang, Q. Large Array DOA Estimation Based on Extreme Learning Machine and Random Matrix Theory. In Proceedings of the 2020 IEEE Radar Conference (RadarConf20), Florence, Italy, 21–25 September 2020; pp. 1–5. [Google Scholar]
- Sun, F.Y.; Tian, Y.B.; Hu, G.B.; Shen, Q.Y. DOA estimation based on support vector machine ensemble. Int. J. Numer. Model. Electron. Netw. Devices Fields 2019, 32, e2614. [Google Scholar] [CrossRef]
- Liu, W. Super resolution DOA estimation based on deep neural network. Sci. Rep. 2020, 10, 19859. [Google Scholar] [CrossRef]
- Ge, S.; Li, K.; Rum, S.N.B.M. Deep learning approach in DOA estimation: A systematic literature review. Mob. Inf. Syst. 2021, 2021, 6392875. [Google Scholar] [CrossRef]
- Cong, J.; Wang, X.; Huang, M.; Wan, L. Robust DOA estimation method for MIMO radar via deep neural networks. IEEE Sens. J. 2020, 21, 7498–7507. [Google Scholar] [CrossRef]
- Chen, M.; Gong, Y.; Mao, X. Deep neural network for estimation of direction of arrival with antenna array. IEEE Access 2020, 8, 140688–140698. [Google Scholar] [CrossRef]
- Xiang, H.; Chen, B.; Yang, T.; Liu, D. Phase enhancement model based on supervised convolutional neural network for coherent DOA estimation. Appl. Intell. 2020, 50, 2411–2422. [Google Scholar] [CrossRef]
- Xiang, H.; Chen, B.; Yang, T.; Liu, D. Improved de-multipath neural network models with self-paced feature-to-feature learning for DOA estimation in multipath environment. IEEE Trans. Veh. Technol. 2020, 69, 5068–5078. [Google Scholar] [CrossRef]
- Shi, B.; Ma, X.; Zhang, W.; Shao, H.; Shi, Q.; Lin, J. Complex-valued convolutional neural networks design and its application on UAV DOA estimation in urban environments. J. Commun. Inf. Netw. 2020, 5, 130–137. [Google Scholar] [CrossRef]
- Zhu, W.; Zhang, M.; Li, P.; Wu, C. Two-dimensional DOA estimation via deep ensemble learning. IEEE Access 2020, 8, 124544–124552. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Tammina, S. Transfer learning using VGG-16 with deep convolutional neural network for classifying images. Int. J. Sci. Res. Publ. (IJSRP) 2019, 9, 143–150. [Google Scholar] [CrossRef]
- Yang, L.; Hanneke, S.; Carbonell, J. A theory of transfer learning with applications to active learning. Mach. Learn. 2013, 90, 161–189. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2018; pp. 270–279. [Google Scholar]
- Zhang, M.; Zhang, M.; Wu, C.; Zeng, L. Broadband direction of arrival estimation based on convolutional neural network. IEICE Trans. Commun. 2019, E103.B, 148–154. [Google Scholar]




| Layer | Type | Kernel Size | Input | Output |
|---|---|---|---|---|
| 1 | Conv | 1 × 1 | 5 × 5 × 1 | 5 × 5 × 8 |
| 2 | Conv | 3 × 3 | 5 × 5 × 8 | 2 × 2 × 16 |
| 3 | Conv | 1 × 1 | 2 × 2 × 16 | 2 × 2 × 32 |
| 4 | Conv | 1 × 1 | 2 × 2 × 32 | 2 × 2 × 64 |
| 5 | Conv | 1 × 1 | 2 × 2 × 64 | 2 × 2 × 64 |
| 6 | Fc | 256 | 2 |
| Evaluation Metrics | MAE (°) | RMSE (°) | MAXE (°) | Ratio-1 |
|---|---|---|---|---|
| Method | ||||
| Before transfer learning | 13.770 | 34.720 | 179.827 | 0.043 |
| After transfer learning | 0.716 | 0.912 | 3.775 | 0.737 |
| Evaluation Metrics | MAE (°) | RMSE (°) | MAXE (°) | Ratio-1 |
|---|---|---|---|---|
| Freeze Method | ||||
| Freez_0 | 0.716 | 0.912 | 3.775 | 0.737 |
| Freez_1 | 0.678 | 0.860 | 4.020 | 0.766 |
| Freez_2 | 0.791 | 1.050 | 17.415 | 0.699 |
| Freez_3 | 0.780 | 1.186 | 13.830 | 0.707 |
| Freez_4 | 0.908 | 1.186 | 8.713 | 0.643 |
| Freez_5 | 3.992 | 6.807 | 179.662 | 0.168 |
| Evaluation Metrics | MAE (°) | RMSE (°) | MAXE (°) | Ratio-1 |
|---|---|---|---|---|
| Number | ||||
| 360 | 1.232 | 1.902 | 45.178 | 0.547 |
| 720 | 1.106 | 1.843 | 34.857 | 0.619 |
| 1080 | 0.944 | 1.571 | 33.678 | 0.715 |
| 1440 | 0.872 | 1.048 | 36.724 | 0.727 |
| 1800 | 0.662 | 0.848 | 5.72 | 0.785 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Wang, C.; Zhu, W.; Shen, Y. An Intelligent DOA Estimation Error Calibration Method Based on Transfer Learning. Appl. Sci. 2022, 12, 7636. https://doi.org/10.3390/app12157636
Zhang M, Wang C, Zhu W, Shen Y. An Intelligent DOA Estimation Error Calibration Method Based on Transfer Learning. Applied Sciences. 2022; 12(15):7636. https://doi.org/10.3390/app12157636
Chicago/Turabian StyleZhang, Min, Chenyang Wang, Wenli Zhu, and Yi Shen. 2022. "An Intelligent DOA Estimation Error Calibration Method Based on Transfer Learning" Applied Sciences 12, no. 15: 7636. https://doi.org/10.3390/app12157636
APA StyleZhang, M., Wang, C., Zhu, W., & Shen, Y. (2022). An Intelligent DOA Estimation Error Calibration Method Based on Transfer Learning. Applied Sciences, 12(15), 7636. https://doi.org/10.3390/app12157636