
Comparison of Principal-Component-Analysis-Based Extreme Learning Machine Models for Boiler Output Forecasting

 , ,
, ,  ,
,
Abstract
:1. Introduction
- Forecasting and Prediction.
- Monitoring and Controlling.
- Clustering.
- Others [1].
- i.
- to investigate the prediction of boiler output power in a thermal power plant using an extreme learning machine
- ii.
- to reduce the dimensionality of the input dataset by performing principal component analysis
- iii.
- to validate the effectiveness of the combined approach of PCA–ELM over ELM and
- iv.
- to determine the simulation time and testing accuracy of PCA–ELM designed for various ELM network architectures.
2. Methodology
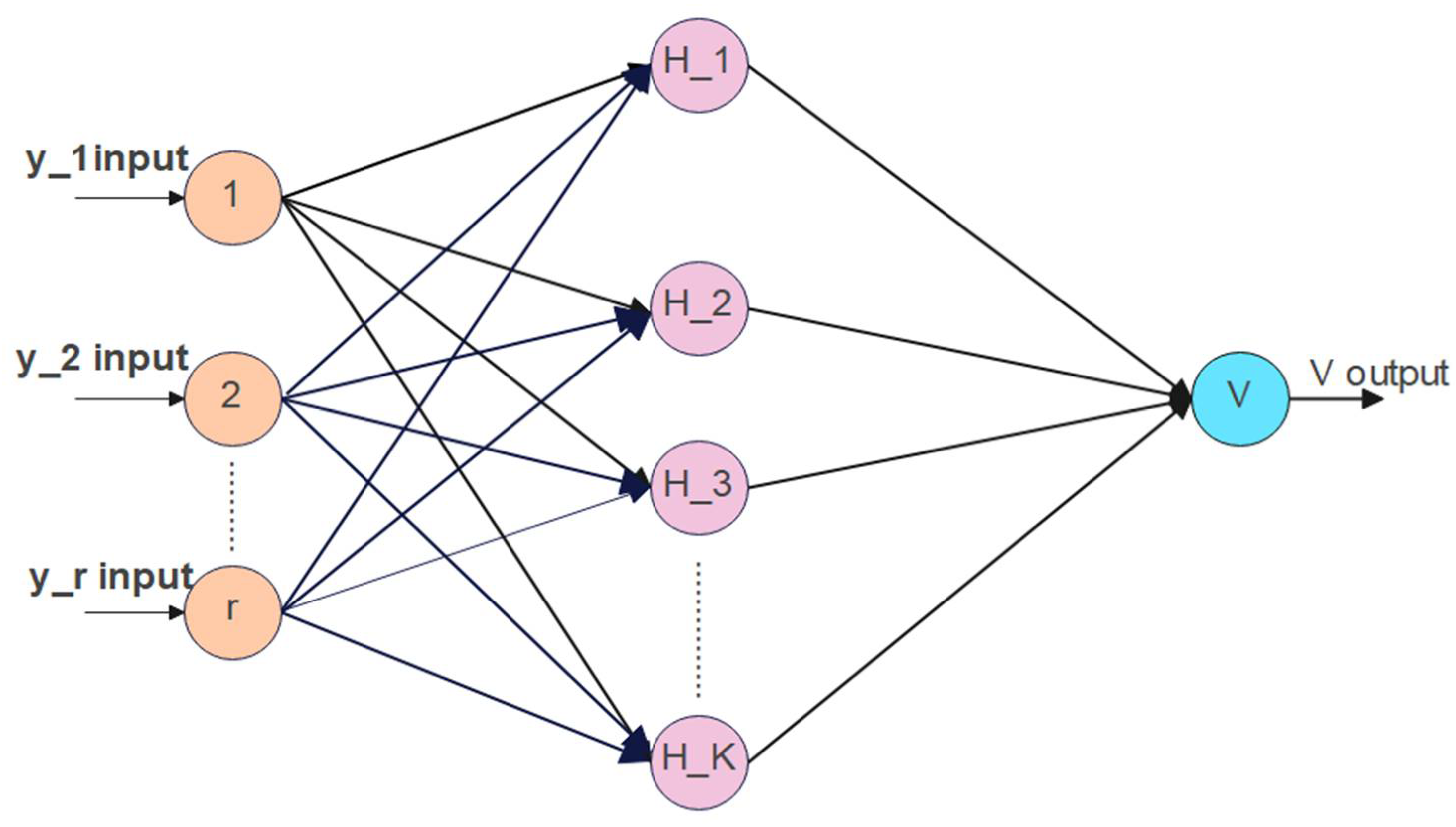
2.1. Extreme Learning Machine
ELM Algorithm
2.2. Principal Component Analysis
- (a)
- Data standardization
- (b)
- Calculating covariance matrix
- where
- X’ = Arithmetic mean of data X.
- Y’ = Arithmetic mean of data Y.
- = Number of observations.
- (c)
- Eigenvalues are determined by solving
- (d)
- Choosing new components
2.3. PCA–ELM
3. Model Approach
4. Results and Discussion
- The performance of the conventional ELM has been compared with that of PCA–ELM.
- The PCA–ELM network was compared by varying the range of hidden neurons.
- The two PCA–ELM networks using the hyperbolic tangent function and sigmoid function are developed and compared.
5. Conclusions
- i.
- To predict the boiler output power in a thermal power plant, PCA–ELM is superior to ELM in predicting accuracy and learning speed. This is because with PCA, the dimension of the inputs is reduced while maintaining the properties of the data points using variance, thereby reducing the computation time.
- ii.
- In terms of prediction precision, PCA–ELM shows superior performance over ELM because of the eigenvalue decomposition technique for the input data covariance matrix. In this way, correlated input parameters are carefully converted into linearly uncorrelated ones. Thus, this shows the necessity for dimensionality reduction methods to enhance forecasting.
- iii.
- The generalization ability of the ELM is corroborated with changes in ELM parameters’ activation function and the number of hidden nodes. In a comparison of PCA–ELM models with a hyperbolic tangent function and those with a sigmoid function, the latter shows better performance in terms of errors. However, the performance of the hyperbolic tangent function deteriorates with the increasing number of hidden neurons.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vom Scheidt, F.; Medinová, H.; Ludwig, N.; Richter, B.; Staudt, P.; Weinhardt, C. Data analytics in the electricity sector—A quantitative and qualitative literature review. Energy AI 2020, 1, 100009. [Google Scholar] [CrossRef]
- Bhangu, S.N.; Singh, R.; Pahuja, G.L. Availability performance analysis of thermal power plants. J. Inst. Eng. India Ser. C 2019, 100, 439–448. [Google Scholar] [CrossRef]
- Tüfekci, P. Prediction of full load electrical power output of a base load operated combined cycle power plant using machine learning methods. Int. J. Electr. Power Energy Syst. 2014, 60, 126–140. [Google Scholar] [CrossRef]
- Lorencin, I.; Anđelić, N.; Mrzljak, V.; Car, Z. Genetic Algorithm Approach to Design of Multi-Layer Perceptron for Combined Cycle Power Plant Electrical Power Output Estimation. Energies 2019, 12, 4352. [Google Scholar] [CrossRef] [Green Version]
- Kesgin, U.; Heperkan, H. Simulation of thermodynamic systems using soft computing techniques. Int. J. Energy Res. 2005, 29, 581–611. [Google Scholar] [CrossRef]
- Ma, J.; Xia, D.; Guo, H.; Wang, Y.; Niu, X.; Liu, Z.; Jiang, S. Metaheuristic-based support vector regression for landslide displacement prediction: A comparative study. Landslides 2022, 1–23. [Google Scholar] [CrossRef]
- Ma, J.; Wang, Y.; Niu, X.; Jiang, S.; Liu, Z. A comparative study of mutual information-based input variable selection strategies for the displacement prediction of seepage-driven landslides using optimized support vector regression. Stoch. Hydrol. Hydraul. 2022, 1–21. [Google Scholar] [CrossRef]
- Dong, Y.; Gu, Y.; Yang, K.; Zhang, J. Applying PCA to establish artificial neural network for condition prediction on equipment in power plant. In Proceedings of the Fifth World Congress on Intelligent Control and Automation (IEEE Cat. No.04EX788), Shenyang, China, 15–19 June 2004; Volume 2, pp. 1715–1719. [Google Scholar] [CrossRef]
- Fei, W.; Mi, Z.; Shi, S.; Zhang, C. A practical model for single-step power prediction of grid-connected PV plant using artificial neural network. In Proceedings of the 2011 IEEE PES Innovative Smart Grid Technologies, Perth, WA, Australia, 13–16 November 2011; pp. 1–4. [Google Scholar] [CrossRef]
- Mei, R.; Lv, Z.; Tang, Y.; Gu, W.; Feng, J.; Ji, J. Short-term prediction of wind power based on principal component analysis and Elman neural network. In Proceedings of the 2021 IEEE Sustainable Power and Energy Conference (iSPEC), Nanjing, China, 23–25 December 2021; pp. 3669–3674. [Google Scholar] [CrossRef]
- Ma, L.; Wang, X.; Cao, X. Feedwater heater system fault diagnosis during dynamic transient process based on two-stage neural networks. In Proceedings of the 32nd Chinese Control Conference, Xi’an, China, 26–28 July 2013; pp. 6148–6153. [Google Scholar]
- Chen, G.; Shan, J.; Li, D.Y.; Wang, C.; Li, C.; Zhou, Z.; Wang, X.; Li, Z.; Hao, J.J. Research on Wind Power Prediction Method Based on Convolutional Neural Network and Genetic Algorithm. In Proceedings of the 2019 IEEE Innovative Smart Grid Technologies—Asia (ISGT Asia), Chengdu, China, 21–24 May 2019; pp. 3573–3578. [Google Scholar] [CrossRef]
- Dong, Y.; Ma, X.; Fu, T. Electrical load forecasting: A deep learning approach based on K-nearest neighbors. Appl. Soft Comput. 2020, 99, 106900. [Google Scholar] [CrossRef]
- Malhotra, R. Comparative analysis of statistical and machine learning methods for predicting faulty modules. Appl. Soft Comput. 2014, 21, 286–297. [Google Scholar] [CrossRef]
- Zhou, H.; Huang, G.; Lin, Z.; Wang, H.; Soh, Y.C. Stacked extreme learning machines. IEEE Trans. Cybern. 2014, 45, 2013–2025. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, G.-B.; Zhu, Q.; Mao, K.Z.; Siew, C.; van Saratchandran, P.; Sundararajan, N. Can threshold networks be trained directly? IEEE Trans. Circuits Syst. II Express Briefs 2006, 53, 187–191. [Google Scholar] [CrossRef]
- Miche, Y.; Sorjamaa, A.; Lendass, A. OP-ELM: Theory, experiments and a toolbox. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2008; pp. 145–154. [Google Scholar]
- Tan, P.; Xia, J.; Zhang, C.; Fang, Q.; Chen, G. Modeling and reduction of NOX emissions for a 700 MW coal-fired boiler with the advanced machine learning method. Energy 2015, 94, 672–679. [Google Scholar] [CrossRef]
- Zhao, H.; Zhao, J.; Zheng, Y.; Qiu, J.; Wen, F. A Hybrid Method for Electric Spring Control Based on Data and Knowledge Integration. IEEE Trans. Smart Grid 2019, 11, 2303–2312. [Google Scholar] [CrossRef]
- Shi, X.; Kang, Q.; An, J.; Zhou, M. Novel L1 Regularized Extreme Learning Machine for Soft-Sensing of an Industrial Process. IEEE Trans. Ind. Inform. 2021, 18, 1009–1017. [Google Scholar] [CrossRef]
- Yu, H.; Yang, L.; Zhou, Y. Navigation System Research and Design Based on Intelligent Image Classification Algorithm of Extreme Learning Machine. In Proceedings of the 2020 IEEE International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 28–30 July 2020; pp. 930–933. [Google Scholar] [CrossRef]
- Patnaik, S.; Tripathy, L.; Dhar, S. An Improved Water Cycle Optimized Extreme Learning Machine with Ridge Regression towards Effective Maximum Power Extraction for Photovoltaic based Active Distribution Grids. In Proceedings of the 2020 International Conference on Computational Intelligence for Smart Power System and Sustainable Energy (CISPSSE), Keonjhar, Odisha, 23–35 April 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Giri, M.K.; Majumder, S. Extreme Learning Machine Based Cooperative Spectrum Sensing in Cognitive Radio Networks. In Proceedings of the 2020 7th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 27–28 February 2020; pp. 636–641. [Google Scholar] [CrossRef]
- Tang, Z.; Wang, S.; Chai, X.; Cao, S.; Ouyang, T.; Li, Y. Auto-encoder-extreme learning machine model for boiler NOx emission concentration prediction. Energy 2022, 256, 124552. [Google Scholar] [CrossRef]
- Mishra, P.S.; Sarkar, U.; Taraphder, S.; Datta, S.; Swain, D.; Saikhom, R.; Panda, S. MenalshLaishramMultivariate statistical data analysis-principal component analysis (PCA). Int. J. Livest. Res. 2017, 7, 60–78. [Google Scholar]
- Yang, J.; Zhang, D.; Frangi, A.; Yang, J.-Y. Two-dimensional pca: A new approach to appearance-based face representation and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 131–137. [Google Scholar] [CrossRef] [Green Version]
- Gottumukkal, R.; Asari, V.K. An improved face recognition technique based on modular PCA approach. Pattern Recognit. Lett. 2004, 25, 429–436. [Google Scholar] [CrossRef]
- Draper, B.A.; Baek, K.; Bartlett, M.S.; Beveridge, J. Recognizing faces with PCA and ICA. Comput. Vis. Image Underst. 2003, 91, 115–137. [Google Scholar] [CrossRef]
- Daffertshofer, A.; Lamoth, C.J.; Meijer, O.G.; Beek, P.J. PCA in studying coordination and variability: A tutorial. Clin. Biomech. 2004, 19, 415–428. [Google Scholar] [CrossRef] [PubMed]
- Choi, S.W.; Lee, C.; Lee, J.-M.; Park, J.H.; Lee, I.-B. Fault detection and identification of nonlinear processes based on kernel PCA. Chemom. Intell. Lab. Syst. 2005, 75, 55–67. [Google Scholar] [CrossRef]
- Yu, J.; Yoo, J.; Jang, J.; Park, J.H.; Kim, S. A novel plugged tube detection and identification approach for final super heater in thermal power plant using principal component analysis. Energy 2017, 126, 404–418. [Google Scholar] [CrossRef]
- Ferracuti, F.; Giantomassi, A.; Ippoliti, G.; Longhi, S. Multi-Scale PCA Based Fault Diagnosis for Rotating Electrical Machines. In Proceedings of the European Workshop on Advanced Control and Diagnosis, 8th ACD, Ferrara, Italy, 18–19 November 2010; pp. 296–301. [Google Scholar]
- Filho, J.M.; Filho, J.M.D.C.; Paiva, A.P.; de Souza, P.V.G.; Tomasin, S. A PCA-based approach for substation clustering for voltage sag studies in the Brazilian new energy context. Electr. Power Syst. Res. 2016, 136, 31–42. [Google Scholar] [CrossRef]
- Bhutto, J.A.; Lianfang, T.; Du, Q.; Soomro, T.A.; Lubin, Y.; Tahir, M.F. An Enhanced Image Fusion Algorithm by Combined Histogram Equalization and Fast Gray Level Grouping Using Multi-Scale Decomposition and Gray-PCA. IEEE Access 2020, 8, 157005–157021. [Google Scholar] [CrossRef]
- Serna, I.; Morales, A.; Fierrez, J.; Obradovich, N. Sensitive loss: Improving accuracy and fairness of face representations with discrimination-aware deep learning. Artif. Intell. 2022, 305, 103682. [Google Scholar] [CrossRef]
- Castaño, A.; Fernández-Navarro, F.; Hervás-Martínez, C. PCA-ELM: A robust. Neural Processing Lett. 2013, 37, 377–392. [Google Scholar] [CrossRef]
- Miao, Y.Z.; Ma, X.P.; Bu, S.P. Research on the Learning Method Based on PCA-ELM. Intell. Autom. Soft Comput. 2017, 23, 637–642. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, S.; Yin, Y.; Su, X. Application of the improved the ELM algorithm for prediction of blast furnace gas utilization rate. IFAC-PapersOnLine 2018, 51, 59–64. [Google Scholar] [CrossRef]
- Yuan, B.; Wang, W.; Ye, D.; Zhang, Z.; Fang, H.; Yang, T.; Wang, Y.; Zhong, S. Nondestructive Evaluation of Thermal Barrier Coatings Thickness Using Terahertz Technique Combined with PCA–GA–ELM Algorithm. Coatings 2022, 12, 390. [Google Scholar] [CrossRef]
- Sun, W.; Sun, J. Prediction of carbon dioxide emissions based on principal component analysis with regularized extreme learning machine: The case of China. Environ. Eng. Res. 2017, 22, 302–311. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component Number | Eigenvalue | % of Variance | Cumulative % |
|---|---|---|---|
| 1 | 75.245 | 32.433 | 32.433 |
| 2 | 54.165 | 23.347 | 55.780 |
| 3 | 34.359 | 14.810 | 70.590 |
| 4 | 19.495 | 8.403 | 78.993 |
| 5 | 11.663 | 5.027 | 84.020 |
| 6 | 5.936 | 2.559 | 86.579 |
| 7 | 4.683 | 2.018 | 88.597 |
| 8 | 3.185 | 1.373 | 89.970 |
| 9 | 2.416 | 1.042 | 91.012 |
| 10 | 2.184 | 0.941 | 91.953 |
| 11 | 1.697 | 0.731 | 92.685 |
| 12 | 1.625 | 0.701 | 93.385 |
| 13 | 1.550 | 0.668 | 94.053 |
| 14 | 1.370 | 0.591 | 94.644 |
| 15 | 1.252 | 0.540 | 95.184 |
| 16 | 1.056 | 0.455 | 95.639 |
| Parameters/Approach | ELM | PCA–ELM |
|---|---|---|
| training sum of squares error | 0.02 | 0.015 |
| training time (in milliseconds) | 13 | 2 |
| training relative error | 0.009 | 0.01 |
| the testing sum of squares error | 0.05 | 0.023 |
| testing relative error | 0.065 | 0.017 |
| MSE | 39.932 | 14.711 |
| MAE | 3.902 | 2.969 |
| MAPE | 0.696 | 0.526 |
| RMSE | 6.319 | 3.835 |
| Parameters/Approach | ELM | PCA–ELM |
|---|---|---|
| training sum of squares error | 0.002 | 0.015 |
| training time (in milliseconds) | 45 | 2 |
| training relative error | 0.001 | 0.01 |
| testing sum of squares error | 0.038 | 0.023 |
| testing relative error | 0.053 | 0.017 |
| MSE | 25.269 | 22.380 |
| MAE | 2.726 | 3.626 |
| MAPE | 0.481 | 0.639 |
| RMSE | 5.026 | 4.730 |
| Parameter/Model | S-3 | S-30 | S-50 | S-80 | S-100 |
|---|---|---|---|---|---|
| training sum of squares error | 0.094 | 0.022 | 0.015 | 0.018 | 0.015 |
| training time (in milliseconds) | 0 | 0 | 2 | 2 | 2 |
| training relative error | 0.045 | 0.012 | 0.01 | 0.013 | 0.01 |
| testing sum of squares error | 0.158 | 0.018 | 0.023 | 0.034 | 0.023 |
| testing relative error | 0.278 | 0.018 | 0.017 | 0.027 | 0.017 |
| MSE | 160.063 | 23.487 | 14.714 | 33.224 | 22.379 |
| MAE | 8.0185 | 3.531 | 2.969 | 4.282 | 3.626 |
| MAPE | 1.436 | 0.621 | 0.526 | 0.767 | 0.639 |
| RMSE | 12.655 | 4.841 | 3.835 | 5.764 | 4.730 |
| Parameter/Model | H-3 | H-30 | H-50 | H-80 | H-100 |
|---|---|---|---|---|---|
| training sum of squares error | 0.288 | 0.021 | 0.008 | 0.125 | 2.268 |
| training time (in milliseconds) | 2 | 2 | 6 | 5 | 9 |
| training relative error | 0.037 | 0.002 | 0.001 | 0.025 | 0.288 |
| testing sum of squares error | 0.386 | 0.272 | 0.415 | 0.733 | 1.939 |
| testing relative error | 0.135 | 0.019 | 0.135 | 0.094 | 0.678 |
| MSE | 107.124 | 42.206 | 61.051 | 110.047 | 668.565 |
| MAE | 7.249 | 3.200 | 3.141 | 6.609 | 21.095 |
| MAPE | 1.300 | 0.572 | 0.557 | 1.180 | 3.668 |
| RMSE | 10.350 | 6.496 | 7.813 | 10.490 | 25.857 |
| H/S | H | H | H | H | H | S | S | S | S | S |
|---|---|---|---|---|---|---|---|---|---|---|
| Number of hidden neurons | 3 | 30 | 50 | 80 | 100 | 3 | 30 | 50 | 80 | 100 |
| training sum of squares error | 0.288 | 0.021 | 0.008 | 0.125 | 2.268 | 0.094 | 0.022 | 0.015 | 0.018 | 0.015 |
| training time (ms) | 2 | 2 | 6 | 5 | 9 | 0 | 0 | 2 | 2 | 2 |
| training relative error | 0.037 | 0.002 | 0.001 | 0.025 | 0.288 | 0.045 | 0.012 | 0.01 | 0.013 | 0.01 |
| testing sum of squares error | 0.386 | 0.272 | 0.415 | 0.733 | 1.939 | 0.158 | 0.018 | 0.023 | 0.034 | 0.023 |
| testing relative error | 0.135 | 0.019 | 0.135 | 0.094 | 0.678 | 0.278 | 0.018 | 0.017 | 0.027 | 0.017 |
| MSE | 107.12 | 42.206 | 61.051 | 110.04 | 668.56 | 160.063 | 23.487 | 14.711 | 33.224 | 22.3799 |
| MAE | 7.2494 | 3.2004 | 3.1415 | 6.6091 | 21.095 | 8.01854 | 3.5317 | 2.9691 | 4.2829 | 3.62697 |
| MAPE | 1.3001 | 0.5720 | 0.5574 | 1.1800 | 3.6681 | 1.43662 | 0.6339 | 0.5260 | 0.7671 | 0.63997 |
| RMSE | 10.35008 | 6.496684 | 7.813519 | 10.49037 | 25.85701 | 12.6516305 | 4.846391 | 3.835549 | 5.764049 | 4.73075014 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deepika, K.K.; Varma, P.S.; Reddy, C.R.; Sekhar, O.C.; Alsharef, M.; Alharbi, Y.; Alamri, B. Comparison of Principal-Component-Analysis-Based Extreme Learning Machine Models for Boiler Output Forecasting. Appl. Sci. 2022, 12, 7671. https://doi.org/10.3390/app12157671
Deepika KK, Varma PS, Reddy CR, Sekhar OC, Alsharef M, Alharbi Y, Alamri B. Comparison of Principal-Component-Analysis-Based Extreme Learning Machine Models for Boiler Output Forecasting. Applied Sciences. 2022; 12(15):7671. https://doi.org/10.3390/app12157671
Chicago/Turabian StyleDeepika, K. K., P. Srinivasa Varma, Ch. Rami Reddy, O. Chandra Sekhar, Mohammad Alsharef, Yasser Alharbi, and Basem Alamri. 2022. "Comparison of Principal-Component-Analysis-Based Extreme Learning Machine Models for Boiler Output Forecasting" Applied Sciences 12, no. 15: 7671. https://doi.org/10.3390/app12157671
APA StyleDeepika, K. K., Varma, P. S., Reddy, C. R., Sekhar, O. C., Alsharef, M., Alharbi, Y., & Alamri, B. (2022). Comparison of Principal-Component-Analysis-Based Extreme Learning Machine Models for Boiler Output Forecasting. Applied Sciences, 12(15), 7671. https://doi.org/10.3390/app12157671