1. Introduction
Computer vision is becoming essential to smart devices such as smartphones and self-driving cars [
1,
2]. Smart devices especially require well-performing object tracking techniques from computer vision [
3,
4]. Programs for object tracking convert images from input devices such as cameras into data that can be manipulated to recognize objects, calculate the movement, and track them. The Open Computer Vision library (OpenCV) [
5] is a representative library supporting such image processing. OpenCV is open-source and supports various programming languages, including C/C++. Furthermore, OpenCV operates on a variety of platforms. Therefore, many applications adopt OpenCV to implement their computer vision applications [
6,
7,
8,
9].
Parallel computing devices are suited to processing images, such as the GPU, which can process large amounts of data in parallel. Thus, many studies have targeted utilizing the GPU to improve the performance of computer vision algorithms. OpenCV is also being developed to use GPGPU environments utilizing the open computing language (OpenCL) [
10] framework or a vendor-specific computing platform [
11], which can process data using parallel computing devices. Moreover, OpenCV 3.0 introduces a transparent API [
12], in which the library itself runs appropriate parallel computing APIs according to available computing devices on a system. This alleviates the burden on application developers of explicitly selecting and manipulating parallel computing devices.
Although the OpenCV library is widely used in many applications because of its high portability, low computing power demands, and easy-to-use characteristics, its implementation has the performance potential to be further optimized on OpenCL GPU platforms. The library basically includes various well-known performance optimization techniques, such as local memory utilization, vectorization, and loop unrolling [
13,
14]. However, our profiling results showed that the application’s performance deteriorates owing to (1) failure to efficiently utilize GPU resources and (2) kernel call overhead when operating many kernels with short execution times sequentially.
This paper proposes techniques to improve the performance of object tracking algorithms in OpenCV. Especially, we focused on object detection and optical flow algorithms. Object detection is an important step to track objects [
15,
16,
17]. However, using only object detection causes poor accuracy in tracking moving objects. Therefore, previous studies applied optical flow techniques to object detection for increasing the tracking accuracy of moving objects [
1,
2].
For the performance optimization, we analyzed two object detection algorithms and one optical flow algorithm. Based on the analysis, the paper presents two optimization techniques. The first is allowing the OpenCL kernel to maximize the device’s parallelism by optimizing GPU occupancy and adjusting the number of work-items. The second technique reduces the cost of OpenCL API calls and data transfers by avoiding unnecessary kernel calls.
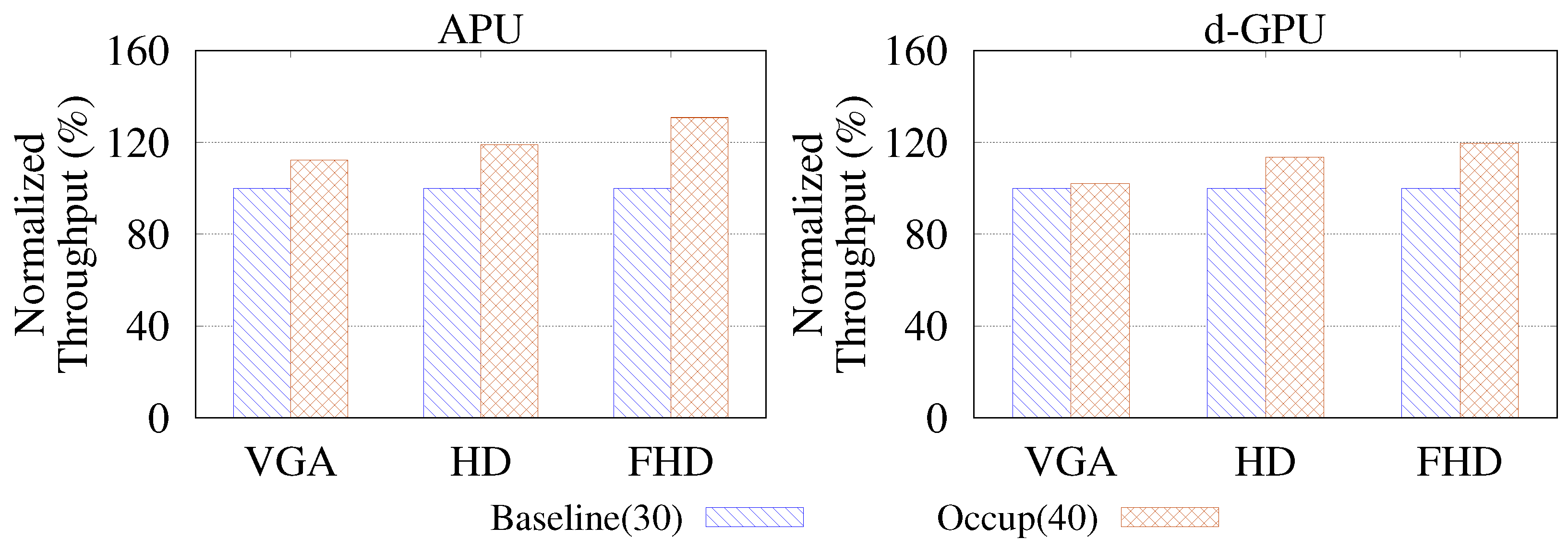
The proposed techniques were applied to two GPU computing environments: an accelerated processing unit (APU) in which the CPU and GPU share the main memory, and a discrete GPU, whose memory is separate from the CPU’s main memory. Our experiments show that the proposed optimization techniques improve the throughput of the object detection algorithms by up to 73% and 86% on the APU and the discrete GPU, respectively. In addition, our method to remove unnecessary kernel calls achieves 10% performance improvement.
Our contributions are as follows. First, we analyzed OpenCV’s object tracking algorithms running on parallel computing devices in terms of hardware level and investigated major factors affecting the algorithm’s performance. Next, we propose efficient schemes to better utilize the hardware resources of a parallel computing device for each object tracking algorithm: remapping variables, increasing global work size, and kernel merging. Finally, by applying the proposed schemes to OpenCV’s object tracking algorithms, we showed performance improvement per each scheme and analyzed them at the hardware usage level.
This paper is organized as follows.
Section 2 describes the background, previous studies related to our work, and our motivation with the profiling results of the target algorithms. Then, in
Section 3, we analyze the OpenCV object tracking algorithms: object detection with Haar/LBP classifiers and Farneback optical flow. Based on the analysis,
Section 4 introduces optimization methods for object tracking algorithms in OpenCV.
Section 5 demonstrates and analyzes the performance improvements gained by our optimization methods. Finally,
Section 6 presents the conclusions of this paper with future work.
2. Background and Motivation
2.1. OpenCV and OpenCL
OpenCV [
5] is a representative computer vision library developed by Intel. This library is open-source and used extensively in many companies and research groups. It implements various computer vision algorithms ranging from simple image filters to object tracking and a wide range of machine learning algorithms, from statistical ones to deep neural networks.
Processing images is more suitable for parallel computing devices such as GPUs because of its high data parallelism in computation. Hence, OpenCV has also developed to leverage GPGPU computing platforms, such as OpenCL [
10] or vendor-specific platforms [
11]. From OpenCV v3.0, the APIs in OpenCV are unified to transparently support available computing platforms (e.g., CPU, GPU, FPGA, etc.) on a system [
12]. Hence, developers do not need to build multiple codes each specific to an accelerator, but can share a single code for various accelerators.
OpenCL [
10,
13] is a programming framework for efficiently exploiting computing accelerator platforms such as GPUs or FPGAs. OpenCL aims to produce applications independent of the execution platform. An OpenCL application consists of two types: a host program and kernel programs. On a CPU, a host program mainly preprocesses data for kernel programs. The host program checks device information in the platform, selects devices to run kernels, compiles kernel codes, and allocates memory space for kernels. The host program also commands computing devices to execute kernels or handles the data after kernels finish their operation [
10].
The kernel program processes data on computing devices and operates through many threads in parallel. In OpenCL, a thread is referred to as a
work-item, and a group of work-items is called a
work-group. When running a kernel, the programmer allocates the number of work-items in an N-dimensional range called
NDRange. NDRange is mapped to input or output data into one-, two-, or three-dimensional address spaces.
Figure 1 shows an example of a work-item, a work-group, and NDRange. A
local work size determines the number of work-items per work-group, and a
global work size determines the total number of work-items in a workspace. Hence, the two values determine the number of work-groups in a workspace.
The OpenCL kernel can operate on various hardware, but each hardware can have different architectures, especially memory systems. Therefore, for the compatibility of the kernel program, OpenCL defines an abstract memory model, as shown on the left side of
Figure 2. All work-items running on a computing device are accessible to global memory. In addition, data transferred from the host to the device are stored in global memory. A part of the global memory is dedicated to constant memory, which holds data that do not change, such as constant variables. Local memory is local to a work-group and is shared by work-items in a group. Local memory is generally faster than global memory in terms of latency and bandwidth. Each work-item has its private memory for its private values/variables. Private memory is usually backed by registers of computing units.
2.2. GPU Architecture
In this section, we explain a GPU architecture and then describe how OpenCL kernels and memory regions are mapped and executed on a GPU architecture. Although each vendor has its own implementation of GPUs, their high-level architecture is common. This section is based on a state-of-the-art GPU architecture for OpenCL execution [
18]. The basic execution unit of GPU is a
compute unit (CU). Generally, a high-performance GPU can process a huge amount of data with many CUs.
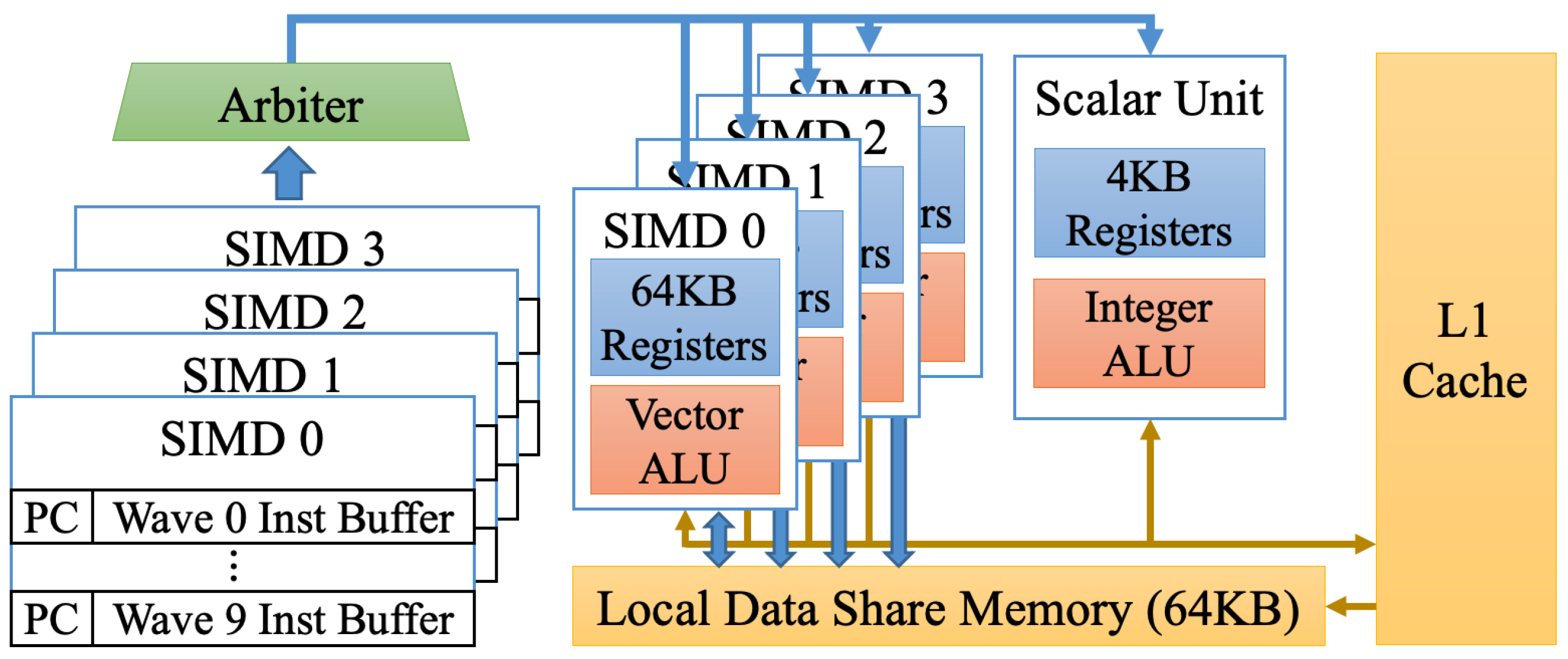
Figure 3 shows the architecture of a CU. A CU generally includes multiple single instruction, multiple data (SIMD) vector units, scalar units, local data share (LDS) memory, cache memory, texture units, and schedulers. For example, a CU in the GPUs used in this paper has four SIMD vector units, one scalar unit, and LDS memory. An SIMD unit consists of 16-lane vector arithmetic logic units (ALUs), and each lane is designed to compute four work-items. Thus, an SIMD unit can process 64 work-items, which is referred to as a
wavefront. In addition, an SIMD unit has a buffer for ten wavefront instructions, as shown on the left side of
Figure 3. The reason for this instruction buffer is to maximize the utilization of CUs. If data accessed by the work-item are not in memory, the work-item must wait until data are loaded to memory; this decreases the CU utilization. In this case, the execution of the next wavefront instruction can hide the latency derived from the memory load.
A CU can activate at most 40 wavefronts simultaneously because it has four SIMD units, and each unit has ten wavefront instruction buffers. Therefore, a GPU having eight CUs can process up to 320 wavefronts concurrently. Furthermore, since a wavefront handles 64 work-items, the GPU can compute up to 20,480 work-items simultaneously (320 wavefronts × 64 work-items per wavefront).
As described in
Section 2.1, the abstract memory structure of OpenCL supports various computing devices.
Figure 2 shows the correlation between the OpenCL memory abstraction and the GPU’s memory structure. In OpenCL, global and constant memories are accessible from all work-items, and these memories are mapped to the GPU memory (graphics double data rate (GDDR) memory of a discrete GPU or the system memory of an APU). Furthermore, local memory is local to work-items within the same work-group and is mapped to the GPU’s LDS memory, which is a fast memory private to each CU. Finally, private memory is mostly mapped to registers in a CU, but if registers are not enough to hold private memory, data on private memory can spill onto the GPU memory.
2.3. GPU Occupancy
Occupancy is one of the metrics to measure the GPU’s computing resource utilization. From the kernel’s perspective, resource utilization corresponds to the number of active wavefronts. Therefore, occupancy refers to the theoretical maximum percentage of wavefronts that can be activated simultaneously in a CU. As described in
Section 2.2, each CU can execute 40 wavefronts simultaneously, and a 50% occupancy means 20 wavefronts are activated simultaneously in the CU. High occupancy generally shows high throughput in GPU computation since the more active wavefronts, the higher memory latency can be hidden, thereby reducing the stall cycles of SIMD units.
The occupancy can be limited when the kernel’s particular resource usage is large because the available resources are limited in a GPU. The following factors limit the occupancy:
- –
The number of vector general purpose registers (VGPRs) and scalar general purpose registers (SGPRs) required by each work-item;
- –
The work-group size (or the number of work-items in a work-group);
- –
The amount of LDS memory used by each work-group.
An SIMD vector unit has a finite number of VGPRs (256 in our tested GPUs). This limits not only the number of VGPRs a wavefront (or a work-item) can use, but also the number of wavefronts that can be activated simultaneously in a CU [
19]. The number of active wavefronts equals dividing the total number of VGPRs by the number of VGPRs used in a kernel [
19]. For example, a kernel that uses 67 VGPRs can run with three (256/67) active wavefronts. At most 10 wavefronts can be active if each work-item (i.e., a kernel) uses no more than 25 VGPRs. If a kernel uses more than 128 VGPRs, only one wavefront can be active.
Table 1 shows the number of active wavefronts by the usage number of VGPRs in the kernel, measured in our environment.
SGPRs can also limit the number of active wavefronts, but it hardly happens because the use of scalar values is not significant in typical image processing workloads. In our analysis, we found that SGPR was not a major contributor to limiting active wavefronts; this will be described in
Section 2.4.
The number of active wavefronts is also limited by the size of a work-group. A CU can activate up to eight work-groups simultaneously [
19]. The CU scheduler fetches wavefronts from the activated work-groups and schedules them to the SIMD vector units. Hence, if the size of a work-group is too small, a CU cannot activate the maximum number of wavefronts. For example, if one work-group is activated and the group has 256 work-items, each SIMD unit has only one active wavefront (64 work-items). Hence, the occupancy becomes only 10%. Hence, it is necessary to have a sufficient work-group size so that a CU can find a sufficient number of wavefronts to schedule.
The number of work-groups that can be activated is limited by the size of LDS memory usage per work-group. Whenever a work-group is activated in a CU, its local memory is allocated from the LDS memory. Hence, if the LDS memory is full, no more work-groups can be activated until a work-group completes. Therefore, the amount of local memory used by a work-group limits the number of activated work-groups in a CU. As mentioned above, the occupancy can be limited when a few work-groups are scheduled and each work-group has a few work-items. Hence, if LDS memory usage is high, only a few work-groups can be activated, thereby increasing the possibility of low occupancy.
2.4. GPU Profiler
The GPU profiler provides information for the occupancy. It also identifies factors restricting the occupancy by inspecting the resources such as registers and LDS memory. In general, because improving the performance of an application requires understanding its behavior, application profiling is required. Traditionally, profilers such as Linux
perf [
20] and
gprof [
21] have been used to improve the performance of applications. However, these profilers can only analyze operations running on the CPU. For this reason, GPU vendors provide the GPU profiler [
22,
23] to profile kernels. Those profilers can also leverage the hardware performance counter in the device to gather information while the kernel executes.
Table 2 is a profiling result of the kernel provided by OpenCV by using a GPU profiler. The profiler provides three categories: device information, GPU kernel information, and kernel occupancy summary. The device information includes GPU hardware specifications such as the number of CUs and the maximum number of wavefronts per CU. In addition, information related to the kernel is provided. For example, the kernel’s hardware resource usage is identified, such as the VGPR usage per work-item and LDS memory usage per work-group. Lastly, the occupancy information is offered. Categories of
number of waves limited by * indicate the number of wavefronts that are activated under the influence of the corresponding factor. Among them, the category of
limiting factor(s) means factors affecting the kernel’s performance significantly. Estimated occupancy is given at the bottom of the profiling results. In
Table 2, the kernel has 30% occupancy because only up to 12 of the 40 wavefronts are activated owing to the VGPR. As described in
Section 2.3, no results showed the SGPR as a limiting factor.
2.5. Previous Studies on Optimizing GPU Kernels for Computer Vision Algorithms
Various studies have been presented to improve the throughput of computer vision algorithms, but most of them focused primarily on the algorithm itself. Borja et al. [
24] utilized multidimensional scaling for optimizing object tracking algorithms. This work optimized the algorithms used for infrastructure and object positioning using multidimensional scaling at the software framework level. Favyen et al. [
25] accelerated object tracking queries by adapting video frame rates. This work applied a hybrid machine learning model consisting of a convolutional neural network and a graph neural network to resolve the object tracking failure problem at low frame rates. The above studies modified the algorithm for object tracking optimization, so they have the advantage of being independent of the hardware. However, optimal performance may not be achieved in systems with scarce hardware resources due to no consideration of the hardware resource level.
Even for improving performance with accelerators such as a GPU, a major research topic is splitting and parallelizing the task of algorithms. Pramod et al. [
4] presented a throughput optimization scheme for computer vision algorithms in embedded system environments and compared several hardware environments. Aby et al. [
26] optimized the Viola–Jones algorithm used for face detection provided by OpenCV. This work targeted processing images on mobile platforms. Although those studies have the advantage of considering scarce hardware resource environments, they regarded only software optimization without profiling hardware utilization.
Moreover, most research applied well-known optimization methods to improve the GPU’s performance, such as leveraging local memory, loop unrolling, vectorization [
3,
27,
28], etc. Hsiang-Wei et al. [
3] optimized gesture recognition in OpenCV running on embedded heterogeneous multicore systems. However, the proposed techniques focused on optimizing the algorithm by applying such well-known optimization methods mentioned above without profiling hardware utilization.
The following are typical OpenCL kernel optimization techniques covered in previous studies.
Leveraging local memory. OpenCL adopted an abstract memory model to support various types of devices. OpenCL memory is classified as global, local, constant, and private. Leveraging local memory can improve the performance of the OpenCL kernel because accessing local memory is faster than global memory [
28].
Figure 4 is the
gaussianBlur5 kernel function code in OpenCV. A
__local indicator is required to use local memory in OpenCL, as shown in Line 6 in
Figure 4. When an indicator is used in front of a variable, the variable is placed in local memory.
Loop unrolling. Loop unrolling is a common optimization technique that copies the body statement of the loop multiple times. In general, loop unrolling improves performance by reducing executions of such instructions as incremental, comparative, and branch [
30] and by exposing instruction-level parallelism if no loop-carried dependency exists. In OpenCL, all loop body statements can be re-written manually for loop unrolling. Furthermore, loop unrolling can simply apply by writing
#pragma unroll in front of the loops, as shown in Lines 14 and 19 in
Figure 4.
Vectorization. The SIMD unit supports computations with a vector (an array of primitive data types, such as integer or float) [
27]. Hence, by transforming an array of values into a vector, multiple values can be computed at once in parallel. In our target GPU architecture, an SIMD unit supports up to 16 integer/floating-point operations in parallel. To alleviate vectorization, sometimes, the structure of an array is transformed to make it more fit to the vector instructions [
3].
4. Performance Optimization of the OpenCV Object Tracking Algorithm
Based on the analysis in the previous section, we propose two optimization strategies. First, we improve the utilization of the GPU hardware by improving the parallelism of the OpenCL kernels. This strategy can be applied to the object detection algorithm since it shows low kernel occupancy, which is a major culprit of under-utilizing the parallelism of GPU hardware. Second, we propose to alleviate the frequent kernel call overheads of an OpenCL program. The frequent kernel calls not only incur the direct cost of kernel call overhead, but also waste unnecessary time to transfer data between consecutive kernels. This strategy is suitable for the optical flow algorithm. The following two subsections describe the two proposed optimization strategies, respectively.
Briefly, our performance optimization framework can be summarized as follows:
When the VGPR usage is high and the LDS memory has free space, our optimization strategy is to remap variables from VGPRs to LDS memory (
Section 4.1.1).
When the number of generated active wavefronts is lower than the total capacity available in the GPU, our optimization strategy is to increase the number of wavefronts to fully utilize the SIMD (
Section 4.1.2).
When many kernel invocations are observed from the profiling results, our optimization strategy is to merge consecutive kernels that have an identical global/local work size into one merged kernel (
Section 4.2).
4.1. Improving the Occupancy
The occupancy is the most effective metric for measuring the resource utilization of GPU hardware [
19,
40]. Therefore, increasing the occupancy generally leads to improving the kernel’s performance [
40]. In particular, optimizing the kernel can significantly improve the application’s overall performance when a specific kernel accounts for a high execution time ratio. This section presents optimization schemes to increase the parallelism, thereby increasing the occupancy, of the kernels, which accounts for the largest fraction in the execution time of the object detection algorithm.
4.1.1. Mapping Data from the VGPR to LDS Memory
The VGPR usage is the most influential factor in limiting the occupancy. Even though the size of the work-group is large enough to supply a sufficient number of wavefronts, if the VGPR usage of the kernel is high, only a few wavefronts can be active. Hence, when LDS memory usage does not restrict the occupancy, variables can be moved from the VGPR to LDS memory to relieve the VGPR usage. However, mapping data from the VGPR to LDS memory can lead to occupancy degradation due to the LDS memory shortage. In addition, all work-items in a work-group share LDS memory data. Therefore, data selection to map to LDS memory must be carefully performed. We demonstrate the properties of variables that can and cannot be mapped to LDS memory by using the code in
Figure 8.
LDS memory can contain variables that store the same data within the work-group because work-items in a work-group share LDS memory. This is the most effective approach to lowering the VGPR usage and not significantly expanding the LDS memory usage. If a variable is not the same across work-items, the variable movement from the VGPR to LDS requires a vector array, rather than a scalar variable in the LDS memory. For example, functions
get_group_id() and
get_global_size() return a value that is static and shared in a work-group. Therefore, variables storing the return values of them can be mapped to LDS memory, such as
groupIdx and
ngroups in Lines 10 and 11 in
Figure 8.
In addition, LDS memory can include variables storing the same calculation results across all work-items. Two types of calculations correspond to returning the same result. The first is the calculation of a constant and a kernel function argument. The examples are the sumstep and invarea variables in Lines 10 and 17 in the figure. The second is the variable storing the result of calculation only among the arguments of the kernel function. The example is the normarea variable in Line 16. Furthermore, LDS memory can contain variables storing the result obtained by calculating between the above variables and non-private data of a work-item.
Work-item private data must be excluded from storing in LDS memory. For example, the lx and ly variables correspond to private data returned by the get_local_id() function in Lines 5 and 6 in the figure.
Table 4 shows the
runHaarClassifier kernel’s occupancy according to transferring variables from the VGPR to LDS memory.
Baseline means the case without any variable movement. When only one variable is moved to LDS memory, the kernel uses 51 to 59 VGPRs (next five rows in the table). As shown in
Table 1, the four wavefronts are active in this VGPR usage range. Because a CU provides ten wavefront buffers, the occupancy is 40% in this case. Furthermore, the table demonstrates that the more variables are moved to LDS memory, the less the VGPR usage becomes. The minimum VGPR usage is 44 when six variables are mapped to LDS memory (the bottom row). For 44 VGPR usage, the occupancy is 50%. Therefore, the
runHaarClassifier kernel can achieve the maximum occupancy of 50% when moving the six variables from the VGPR to LDS memory. Moving two variables,
nofs and
nofs0, to LDS memory also acquires 50% of occupancy, as shown in the table (the row with boldface). Therefore, transferring only these two variables to LDS memory can achieve the maximum achievable occupancy while minimizing the increase in LDS memory usage. As described in
Section 2.5, the variables are mapped to LDS memory by using the
__local indicator front of the variables.
4.1.2. Securing Sufficient Wavefronts
As described in
Section 2.2, an SIMD unit can handle 64 work-items, which is referred to as a wavefront. Since a CU has four SIMD units and each SIMD unit can concurrently execute ten wavefronts, a CU can theoretically activate up to 40 wavefronts simultaneously. The APU device, one of the environments used in this paper, has eight CUs. Therefore, the APU device can activate 320 wavefronts at the same time and process 20,480 work-items (320 × 64 work-items) simultaneously. This characteristic is important in achieving high occupancy because if the global work size is lower than 20,480 work-items, the GPU hardware has no more wavefronts to fill up all the wavefront buffers.
Most OpenCV computer vision algorithms perform parallel data operations to the individual pixel datum of the input images. Therefore, the input image size determines the number of kernel’s work-items. For example, 307,200 work-items can be created when a 640 × 480 VGA image is the input. Most OpenCV algorithms do not need to consider the number of work-items because many wavefronts are already active.
However, some kernels failed to activate all wavefronts provided by the GPU despite increasing the occupancy in
Section 4.1.1; the
runHaarClassifier kernel is an example of this case. As depicted in
Section 3.1, the
runHaarClassifier kernel generates only 96 active wavefronts. Although the input data size is large to process at once, the kernel configures a global work size (i.e., 6144 work-items) too small to utilize the total wavefronts supported by the GPU. Therefore, due to the necessity to generate more wavefronts in the kernels, we expand the global work size to 20,480 so that the
runHaarClassifier kernel generates a total of 320 wavefronts. For this, we modified the fixed value assigned to the variable deciding the global work size. Note that when the global work size is set to generate more wavefronts, the algorithm’s performance will be improved more because the SIMD units are more utilized. However, when the global work size is set to generate more than 320 wavefronts, the performance will not be significantly improved. This is because instruction buffers in SIMD units are fully occupied, so increasing the global work size does not improve the algorithm’s parallelism.
4.2. Minimizing Kernel Call Overhead
An OpenCL program consists of host and kernel programs. A host program performs many preprocessing operations such as selecting computing devices, reserving a memory space, transferring data, and queuing kernels to execute. In addition, a host program must handle the output data after kernels finish their operations.
Computer vision algorithms generally process input images to produce output images, and such operations may consist of multiple consecutive operations. Subsequently, a series of computing operations is performed, and in this case, the output of a previous operation becomes the input of the next operation. When each operation is implemented as an individual kernel in the OpenCL framework, a host program needs to relay the output of a previous kernel to the input of the next one. This computing structure is natural and intuitive to a developer of a computer vision algorithm. Frequent kernel invocation, however, incurs high overheads, which are associated with OpenCL API calls, buffer allocation/management, and unnecessary data movement between kernels. As described in
Section 3.2, the Farneback optical flow algorithm is such a case, launching many kernels.
Kernel merging is an effective method to alleviate such overheads. If adjacent kernels share data and have no data dependency between work-items, they can be unified into one kernel. Consequently, the overheads associated with kernel invocation, such as buffer allocation and data transfer, can be eliminated.
Figure 9 shows the flowchart of our kernel merging algorithm. This algorithm merges kernels if consecutive kernels have data dependency with each other and identical global/local work sizes.
Table 5 shows the kernels in the main loop of the Farneback algorithm shown in
Figure 5b. The table includes the kernel names and their global and local work sizes. In the table, four kernels are candidates of kernel merging:
updateFlow,
updateMatrices,
resizeLN, and
KF. These kernels are executed in a row, have identical global and local work sizes, and transfer data from a previous kernel to the next. Therefore, we modified the
resizeLN and
KF kernels so that the
resizeLN kernel executes the operation of the
KF kernel. Please note that the two pairs of the two kernels process two different (consecutive) frames. Hence, merging the two kernels does not affect the result of the algorithm. Furthermore, we introduced a new
updateFM by merging the two kernels,
updateFlow and
updateMatrices. The kernel after the kernel merging is shown in the table as well.
6. Conclusions
This paper proposed the optimization techniques for the object tracking algorithms in the OpenCV library. We targeted two object tracking algorithms, object detection with the Haar/LBP classifier and Farneback optical flow, which are affordable solutions to resource-constrained computing systems, such as smart devices. Based on careful profiling of the algorithms implemented in the OpenCV library, we proposed and applied various optimization techniques. The evaluation results demonstrated that the proposed optimization techniques successfully improved the performance (throughput) of the object tracking algorithms.
The constraint of our research is that programmers should manually locate the algorithm’s performance bottleneck and apply an appropriate optimization scheme. This may undermine the advantage of OpenCV’s transparent API introduced for the programmer’s convenience. Therefore, our future work is developing a profiler that automatically profiles OpenCV/OpenCL applications and applies such optimization strategies to them.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}